
안녕하세요, 허재연입니다. 요즘에는 VLM과 OD의 결합으로 발전되고 있는 OVOD의 연구 동향을 팔로업 하고 있습니다. 제가 NLP쪽은 잘 몰라서 VLM의 prompt는 어떻게 사용하는지 항상 의문을 가지고 있었는데요, 마침 서베이 도중 OVOD의 prompting 관련 논문이 있어 읽어보게 되었습니다. 리뷰 시작하겠습니다.
Introduction
기존의 Object Detection은 주어진 영상에서 객체의 class와 location을 판별하는 작업으로, 학습한 데이터셋에 대해서만 탐지가 가능해 일반적인 상황으로 확장이 제한적이라는 근본적인 한계가 있었습니다. 탐지할 수 있는 물체의 종류를 늘리기 위한 기본적인 방법은 학습할 데이터의 class 종류 및 그 수를 늘리는 것이었지만, detection의 annotation 비용에 의한 scale up의 한계 및 그 클래스 분포에 있어 long-tail 문제가 있어 직접적인 적용이 쉽지 않았습니다. 검출기가 학습 데이터셋의 물체만을 검출할 수 있는 이러한 기존 OD를 closed-set problem이라고 합니다.
검출할 수 있는 클래스의 종류를 늘리기 위해 최근 CLIP의 등장으로 빠르게 발전하고 있는 vision-language model의 대규모 사전학습 지식을 활용하고자 하는 시도가 이어졌고, VLM을 활용하여 detection을 수행하는 open-vocabulary object detection(OVOD)가 제안되어 base class에서 학습한 검출기가 새로운 novel class를 검출할 수 있도록 하였습니다.
당시에 CLIP, ALIGN과 같이 사전 학습된 vision-language model의 지식을 detector에게로 knowledge distillation하여 open-vocabulary object detection을 수행하는 ViLD가 제안되었습니다. CLIP과 ALIGN은 다들 아시다시피 image encoder와 text encoder 간 출력 임베딩을 contrastive learning으로 정렬하는 대규모 사전학습을 통해 좋은 zero-shot 성능을 보여주었습니다. ViLD는 CLIP의 텍스트 인코더에 기본 클래스(base class)의 텍스트 설명(prompt)을 입력하여 클래스 텍스트 임베딩을 생성한 다음, 이 임베딩을 활용하여 object proposals을 분류하고 detector를 학습합니다. base class 텍스트 임베딩은 open-set OD를 수행하기 위해 base class 및 novel class embedding으로 대체되도록 구현되었습니다.

VLM의 동작에서는 language 입력에 사용되는 사용되는 프롬프트의 설계가 매우 중요합니다(보통 우리가 prompt engineering이라고 하죠).위의 Fig.1은 2022년 IJCV에 게재된 논문 Learning to Prompt for Vision-Language Models의 figure인데, 프롬프트의 작은 차이로도 그 성능 결과가 크게 달라질 수 있음을 보여줍니다. 마찬가지로 OVOD를 수행하기 위한 프롬프트를 설계할 때에도 최적의 프롬프트를 찾아내는것이 중요하지만, 적절한 프롬프트를 설계하는 과정에서 도메인에 대한 지식을 가지고 있는 사람이 시행착오를 겪으며 심혈을 기울여 작업해야 하기에 상당히 비효율적입니다. 이런 한계를 완화하기 위해 자동적으로 prompt의 context를 학습하고자 하는 시도가 있어왔고, 본 논문의 연구에서 OVOD에 prompt representation learning을 최초로 적용하였습니다. (위의 IJCV 논문에서 제안한 CoOp은 classification에 대한 프롬프트를 학습한 방법론이었습니다)
본 논문에서 저자들은 사전학습된 Vision-Language Model을 활용한 OVOD 세팅에서 prompt representation을 학습하는 DetPro(Detection Prompt)라는 방법론을 제안합니다. 당시 사전학습된 VLM을 기반으로 이미지 분류 정확도를 향상시키는것을 목표로 하는 prompt representation learning 방법론인 CoOp과 같은 연구가 있긴 했지만, CoOp을 OVOD-VLM환경에 바로 적용시키는것은 적합하지 않았습니다. 이미지 분류에서는 그냥 전체 이미지 인스턴스에 대한 올바른 라벨값 하나를 예측하면 되지만, detection에서는 background / foreground를 구분하고 foreground 내 region proposal들을 적절한 object class로 분류해야하기에 다른 부분이 있기 때문입니다. 이에 따라, 저자들은 OVOD-VLM에서 영상의 positive / negative proposal의 프롬프트 프롬프트 표현(prompt representation)을 자동으로 학습하는 방법론을 제안하였습니다.
논문에서 object detection에서의 prompt learning을 설계하는 과정에서 다음과 같은 두 가지 이슈가 있었다고 합니다:
- Nagative Proposal은 object detection에 있어서 매우 중요한 정보이지만 명확한 클래스가 부여되지 않기 때문에 prompt learning 과정에 포함시키기 쉽지 않다.
- Classification의 데이터에도 대부분 물체가 영상의 가운데에 크게 있던 것과 달리, detection에서 Positive Proposal들은 보통 다양한 맥락(그 위치나 크기 등)에 위치하기 때문에 이런 proposal들에 대해 하나의 prompt context만을 학습하는 것은 충분하지 않다.
이런 점에 있어, 저자들은 각각 다음과 같은 사항을 도입하였습니다 :
- Negative Proposal을 학습에 포함하기 위해 negative proposal들에 대한 embedding들을 모든 다른 class embedding으로부터 멀어지도록 최적화하는 background interpretation 기법.
- 다른 context level에 따라 다른 positive proposal set을 사용해 prompt representation learning을 조정하는 맞춤형 positive proposal을 활용한 context grading 기법.
저자들은 DetPro를 OVOD 검출기인 ViLD와 결합하여 다양한 실험을 수행하여 좋은 결과를 보였습니다. (ViLD의 자세한 학습법 및 동작법이 궁금하신 분들은 권석준 연구원님의 이전 리뷰가 있으니 참고하시기 바랍니다)
Method
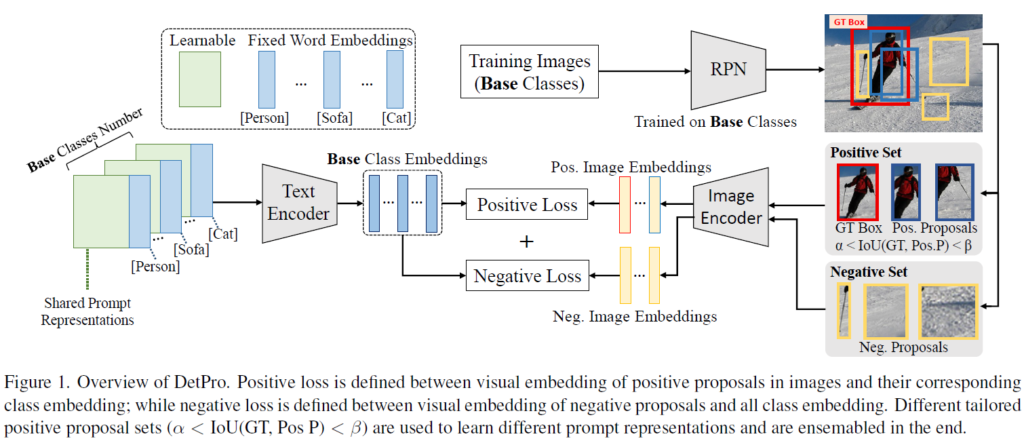
DetPro의 목표는 OVOD-VLM을 위한 continuous한 prompt representation을 학습하는 것으로, 그 개요를 아래의 Figure 1에 나타내었습니다. 해당 프레임워크의 핵심 요소 두 개는 다음과 같습니다 :
- negative proposal을 포함하기 위한 background interpretation
- 적절한 positive proposal을 활용한 전경 문맥 등급화(foreground context grading)
이 두 요소는 각각 그림에서 positive loss 및 negative loss로 학습됩니다. 이후, 저자들은 Figure 2와 같이 당시 SOTA OVOD 파이프라인인 ViLD를 기반으로 DetPro를 구현하였습니다. 여기서 DetPro는 ViLD의 proposal classifier를 대체하여 자동 프롬프트 엔지니어링을 구현하는 역할을 하게 됩니다.
vision-language model로는 text encoder 및 image encoder로 구성된 CLIP을 사용하였는데, 이 때 텍스트 인코더는 클래스에 대한 prompt representation을 입력으로 받고 이에 해당하는 text embedding(class embedding)을 출력합니다. 이미지 인코더는 224×224 크기의 영상을 입력으로 받고 이에 해당하는 image embedding을 출력하게 됩니다. Detection Framework에서는 FPN이 있는 ResNet-50기반 Faster RCNN을 사용했다고 합니다.
이제, 기존에 제안되었던 방법론인 classification에서의 prompt representation learning을 간단하게 리뷰하고, object detection을 위한 프롬프트 러닝 기법인 DetPro를 살펴보도록 하겠습니다.
Prelimiaries : Prompt
본래 CLIP은 “a photo of [CLASS]”와 같은 형태의 사람이 정의한 프롬프트를 텍스트 인코더의 입력으로 주어 image classification을 위한 class embedding을 생성합니다. 여기서 [CLASS]부분은 ‘person’이나 ‘cat’과 같은 특정한 클래스 명칭으로 대체됩니다. 이 때 고정된 형태의 프롬프트가 아닌 최적의 프롬프트를 설계하는 작업은 단어 튜닝을 위한 상당한 시간이 필요로 하는 작업이기에 CoOp은 이를 해결하기 위해 자동으로 prompt representation을 학습하는 방법을 제안하였습니다. 주어진 클래스 c에 대한 학습가능한 프롬프트 표현 {V}_{C}은 {V}_{C} = [{v}_{1}, {v}_{2}, {v}_{3}, ... , {v}_{L}, {w}_{c}]과 같이 정의됩니다. 여기서 {v}_{i}는 i번째 learnable context vector이고, {w}_{c}는 base class c에 대한 고정된 클래스 토큰을 의미합니다. L은 context 길이입니다. 여기서 {v}_{1}, {v}_{2} ... {v}_{L}은 사람이 정의한 프롬프트 context인 “a photo of”에 대응되고, {w}_{c}는 클래스 이름인 [CLASS]에 해당합니다. {v}_{i}는 word embedding {w}_{c}와 동일한 차원(해당 논문에서는 512)의 벡터이며, 처음에 random initialize됩니다. 학습된 prompt context [{v}_{1}, {v}_{2}, {v}_{3}, ... , {v}_{L}]은 클래스 간 공유되게 해서 새로운 클래스가 들어왔을 때 이의 prompt representation을 {V}_{C} = [{v}_{1}, {v}_{2}, {v}_{3}, ... , {v}_{L}, {w}_{c}] 형태로 활용할 수 있게 설계하였습니다. c 클래스에 대한 class embedding {t}_{c}은 {V}_{c}를 CLIP text encoder T(·)에 입력하여 다음과 같이 생성합니다 :
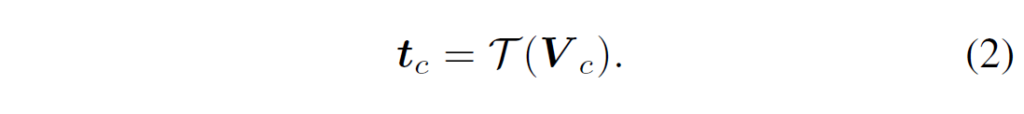
image classification에서 image embedding f를 얻기 위해 주어진 이미지 x를 CLIP image encoder에 입력합니다. 그리고 해당 이미지의 각 클래스에 해당하는 확률값은 다음과 같이 계산됩니다 :
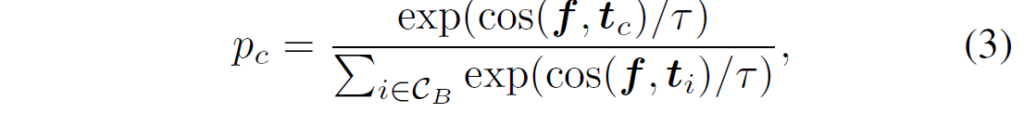
여기서 τ는 temperature parameter이고, cos(·, ·)는 코사인 유사도를 나타냅니다. image embedding과 text embedding(class embedding) 간 코사인 유사도에 대한 softmax라고 생각하시면 됩니다. 이제 여기에 [{v}_{1}, {v}_{2} ... {v}_{L}]를 최적화하기 위해 이미지 및 텍스트 인코더를 고정하고 cross entropy를 사용하여 학습을 진행합니다.
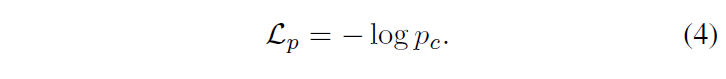
결론적으로, cross-entropy를 사용해 text encoder의 입력으로 들어가는 prompt vector를 학습한다고 요약할 수 있겠습니다. VLM에 대한 기본적인 prompt learning에 대해 더 자세한 부분이 궁금하긴 분은 이전에 김현우 연구원님이 리뷰로 자세히 다뤄주신 적이 있으니, 참고하시면 좋을 것 같습니다.
Detection Prompt
Naive Solution
object detection은 각 학습 이미지 전체에 대해 클래스 라벨이 주어지는 image classification과 다르게, 학습 이미지마다 객체의 정확한 위치를 나타내는 GT bounding box 및 이에 해당하는 class label이 제공됩니다. 추론 단계에서도 영상 내 객체의 위치를 찾아야 하며 예측한 각 박스에 대한 class label을 예측해야 합니다. CoOp의 prompt representation learning 전략을 OD로 확장하는 가장 직관적인 방법은 CoOp가 동작하는 이미지 분류 시나리오를 활용하는 것일 겁니다. 주어진 이미지 x에 대해 영상 전체를 입력하는것이 아닌, 해당 이미지의 GT bounding box를 crop하여 이를 CLIP의 이미지 인코더에 입력하여 각각의 bounding box embedding f를 얻어낼 수 있습니다. 각 정답 bounding box는 하나의 object class c에 속하게 되므로 위의 식 3,4를 활용한 학습으로 region-level classifier를 구축할 수 있습니다.
이런 나이브한 방법은 확장이 손쉽긴 하지만, GT box 내부의 정보만을 가지고 학습을 진행하기 때문에 다양한 객체 상황에 대해 강건한 검출기를 구축하는데 필수적인 background의 풍부한 맥락을 학습에 활용하지 못하는 한계가 있었습니다.
Fine-Grained Solution
다양한 image proposal을 활용하기 위해, 우선 저자들은 Base class C_B에 대한 RPN을 학습시켜 region proposal을 할 수 있는 능력을 확보하였습니다. 이 제안 박스들 중 GT와 IoU가 threshold(0.5)이상인 것은 foreground, threshold 미만인것은 background로 설정하고, foreground와 gt의 합집합을 positive proposal set P로, background를 negative proposal N으로 설정하여 학습에 활용하였습니다. GT가 너무 타이트하게 쳐진게 아니면 일반적으로 proposal P 안에 object의 주변 맥락을 가진 큰 부분이 포함되어 있을테니 positive proposal들은 GT에 따라 문맥적으로 다양하게 형성되어 이미지 인코더에 입력할 때 visual embedding 이 달라질 수 있게 됩니다. 따라서 서로 다른 프롬프트 맥락에 해당하는 서로 다른 프롬프트 representation도 학습해야 합니다. 이러한 이슈를 해결하기 위해 저자들은 context grading scheme with tailored positive proposals를 제안하였습니다. 또한 negative pooposal에는 target object의 작은 부분이 포함되어있거나 포함되어 있지 않을 텐데, background에는 명시적인 class name이 없으므로 앞의 방법으로 prompt representation 및 class embedding을 곧바로 얻을 수 없습니다. negative proposal은 object detection에서 매우 중요한 역할을 하므로, detection prompt에 활용하기 위해 저자들은 background interpretation scheme for negative proposal inclusion을 도입하였습니다.
Background interpretation for negative proposal inclusion
background가 약간의 object class를 포함하고 있을 가능성이 있긴 하지만 일번적으로 너무 작거나 모호한 맥락을 갖게 될 것입니다. 이를 다르게 해석하면 nagative proposal n에 대한 이미지 인코더 출력값인 이미지 임베딩 {f}_{n}은 어떠한 class embedding {t}_{n}와도 유사성을 찾기 어려울 것입니다. {f}_{n}에 대한 클래스 확률 {p}_{nc}는 위의 수식 3(cos 유사도에 대한 softmax)로 계산되는데, 저자들은 이 {p}_{nc}가 항상 작아지도록 학습시키고자 했습니다. 이 때 base class의 크기가 충분히 크니, {p}_{nc}를 단순히 1/(base class의 크기)에 가까워지도록 학습을 진행했습니다. 만약 base class의 수가 1000개라면 모든 {p}_{nc}가 1/1000에 가까워지도록 최적화를 진행한 것이죠. 이 학습은 다음과 같은 loss 로 진행되었ㅅ브니다.
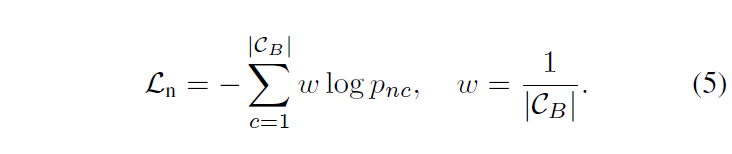
여기서 |{C}_{B}|는 base class의 크기입니다.
저자들은 아예 명시적인 background embedding을 생성하는 시도도 해 보았지만, 위의 방법이 더 효과가 좋았다고 합니다.
Context grading with tailored positive proposals.
positive proposal은 target object에 대해 서로 다른 context를 포함할 수 있고, 이러한 차이는 prompt context에도 유사하게 나타날 수 있습니다. 예를 들어, 객체 클래스의 ground truth bounding box가 주어졌을 때, 이를 “a photo of [CLASS]”라고 표현할 수 있는 반면, 객체의 일부만 포함된 foreground proposal of a partial object이 주어졌을 때는 “a photo of partial [CLASS]”라고 표현하는 것이 더 적절할 것입니다. 이처럼 학습된 prompt context representations은 “a photo of”와 “a photo of partial”에 대해 서로 다르게 형성되며, 결국 두 프롬프트 유형에 대해 서로 다른 class embedding을 생성하게 됩니다. 따라서, 각각의 문맥 수준(context level)에 대응되는 적절한 positive proposal과 함께 최적화되어야 합니다. 이를 위해, 저자들은 맞춤형 양성 제안을 활용한 전경 문맥 등급화(foreground context grading scheme with tailored positive proposals) 기법을 도입합니다.
구체적으로, 저자들은 positive proposal의 IoU 범위 [a,b]를 t개 IoU간격의 K개의 그룹으로 나눠 (K = (a-b)/t ) foreground context가 다른 그룹으로 나뉘게 해서 각 그룹안에 있는 proposal 들은 유사한 context level을 갖도록 합니다. 이후 K개의 그룹의 prompt representation을 독립적으로 학습합니다. k개의 그룹에서, 저자들은 vivsual embedding을 추출하여 각 확률값인 {p}_{nc}을 구한 다음에 위의 3,4번 수식으로 동일하게 학습하여 positive loss {L}_{p}를 학습합니다. negative proposal도 이런 group에 속하게 되며 각 그룹에 대한 최종 loss function은 다음과 같이 구성되게 됩니다.
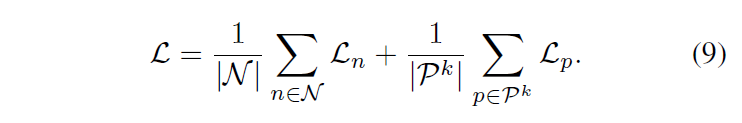
prompt representation 은 각 그룹의 클래스 c에 대해 학습이 진행되고, 학습된 representation은 K개의 그룹에서 평균을 내어 앙상블됩니다.
Assembling DetPro onto ViLD
ViLD는 당시 OVOD의 최신 프레임워크였습니다. CLIP의 knowledge를 2-stage detector(Faster RCNN)에 distillation을 진행하여 구성된 프레임워크입니다. 저자들은 Figure 2와 같이 DetPro를 ViLD와 결합하였습니다.
학습된 DetPro는 base class에 대한 prompt representation을 생성할 수 있습니다. 이렇게 생성된 prompt representation은 text encoder를 타고 나와 base class embedding으로 변환되고, 이 embedding은 detector의 proposal classifier로 사용됩니다. ViLD의 방법론을 따라서, 저자들은 image head와 text head라는 두개의 R-CNN head를 구현하였습니다. image head는 CLIP image encoder로부터 knowledge를 distillation하고, text head는 본래 R-CNN 분류기를 저자들의 base class embedding(고정) + learnable background embedding로 대체하였습니다. 아래 Figure 2를 참고하면 이해가 쉬울 것입니다.
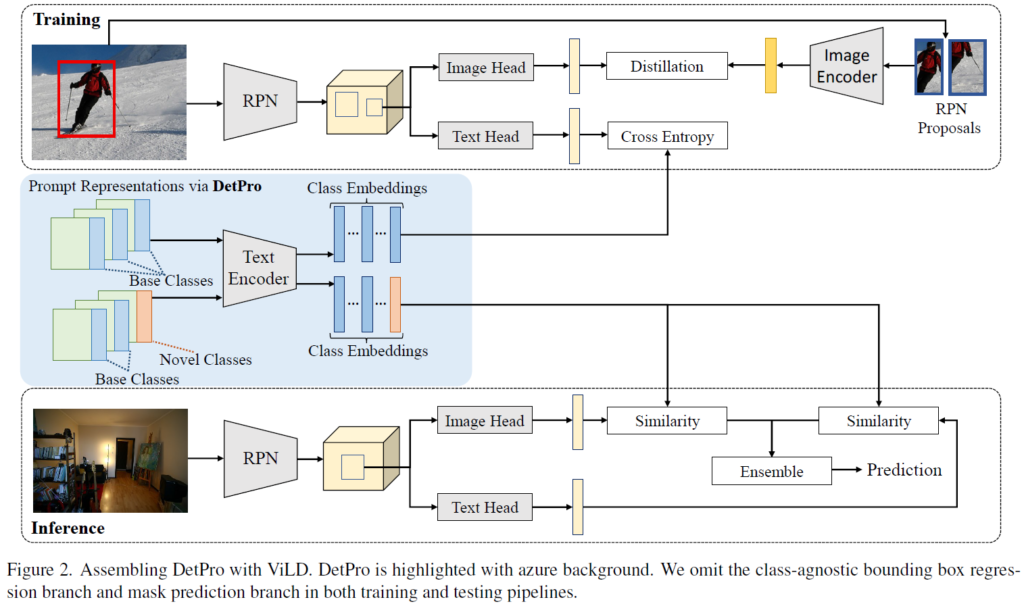
학습 과정에서는, RPN에서 생성된 각 region proposal들을 text head 및 image head를 각각 통과시켜 두 개의 RoI feature를 추출해 이후 loss 계산에 활용합니다. text head에서는 분류를 위해 RoI feature와 base class embedding 간 cosine 유사도를 계산한 뒤 cross-entropy를 적용합니다. image head에서는 RPN에서 생성된 proposal들을 crop 및 resize하여 이미지 인코더에 입력해 이미지 임베딩을 만듭니다. 이후 이미지 임베딩과 이에 해당하는 image head에서 추출한 RoI feature 간 거리를 L1 loss를 활용하여 줄이게 됩니다. 이 때 이미지 임베딩 생성은 사전학습된 RPN을 통해 오프라인으로 수행할 수 있습니다. 전체적인 분류 loss는 text loss와 image loss의 weighted sum으로 구성됩니다.
추론 과정에서는, base class와 novel class에 대한 prompt representation을 class token 없이 다음과 같은 형태로 생성해서 활용하게 됩니다 : [{v}_{1}, {v}_{2}, .. , {v}_{L}]. 이 prompt representation은 텍스트 인코더를 거쳐 클래스 임베딩으로 변환되며, context vector를 공유하기에 DetPro로 최적화된 prompt representation은 base class만으로 학습되었지만 novel class에도 잘 일반화된다고 합니다. 주어진 text image x에 대해 RPN이 proposal들을 생성하고 이렇게 생성된 proposal들을 text head 및 image head에 통과시켜 두개의 RoI feature를 얻습니다. 이 두 feature 각각에 모든 클래스 임베딩과의 코사인 유사도를 계산하여 confidence score를 얻고, 두 confidence score의 평균값을 최종 확률값으로 사용합니다.
Experiment
주요한 실험은 LVIS v1데이터셋으로 수행되었습니다. DetPro 및 open-vocabulary object detector는 LVIS base classes로 학습되었고, 제안하는 방법론을 LVIS novel class에서 평가를 진행했습니다. 또한 제안하는 방법론의 일반화 능력을 확인하기 위해 transfer 실험도 진행하였습니다. transfer 실험은 LVIS에서 학습한 모델을 Pascal VOC test set, COCO validation set, Object365 validation set에서 검증을 진행했습니다. 이 때 LVIS v1은 long-tail 데이터 분포를 갖는 대규모 object detection 데이터셋입니다. 각 카테고리는 training set에서 ‘frequent’, ‘common’, ‘rare’로 나뉘는데, ViLD의 실험과 마찬가지로 frequent와 common class는 base class(866개의 클래스)로 사용되었고 rare class는 novel class(337개의 클래스)로 사용되었습니다.
detector로는 FPN ResNet-50을 백본으로 하는 Mask R-CNN을 사용했으며, 이 때 기존의 사전학습 ResNet-50을 OD를 위한 self-supervised learning 방법론인 SoCo로 사전학습한 것으로 교체하였습니다. pretrained vision-language model로는 CLIP을 사용하였으며, image encoder로는 ViT-B/32를 사용하였습니다.
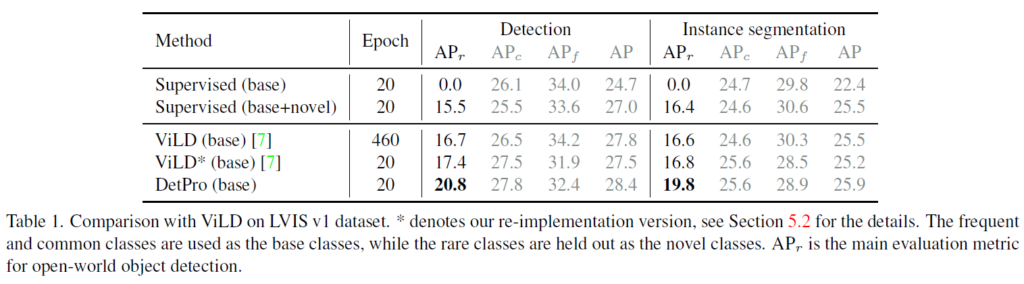
Table 1은 LVIS v1에서 ViLD의 결과를 보여주는 메인 실험 결과입니다. 이 때 ViLD*는 저자들이 재구현한 보전입니다. 이 때 SoCo 사전학습법을 사용한 ViLD는 사전학습 epoch를 460->20으로 줄이면서 기존의 ViLD에 견주는 성능을 보인다고 어필합니다. 저자들이 제안한 DetPro를 적용하였을 대, ViLD* baseline보다 object detection에서 +3.4 APr을, instance segmentation에서 +3.0 APr 결과를 보였습니다.

ViLD와 마찬가지고, 저자들은 LVIS에서 사전학습한 DetPro를 다른 데이터셋에 transfer한 실험을 수행하였습니다. Pascal VOC 2007, COCO, Object365에서 class token을 교체하여 평가를 진행했습니다. Table 2에 결과가 나타나있는데, DetPro를 적용했을 때 좋은 일반화 성능을 보이며 적용에 효과적임을 확인할 수 있었습니다.
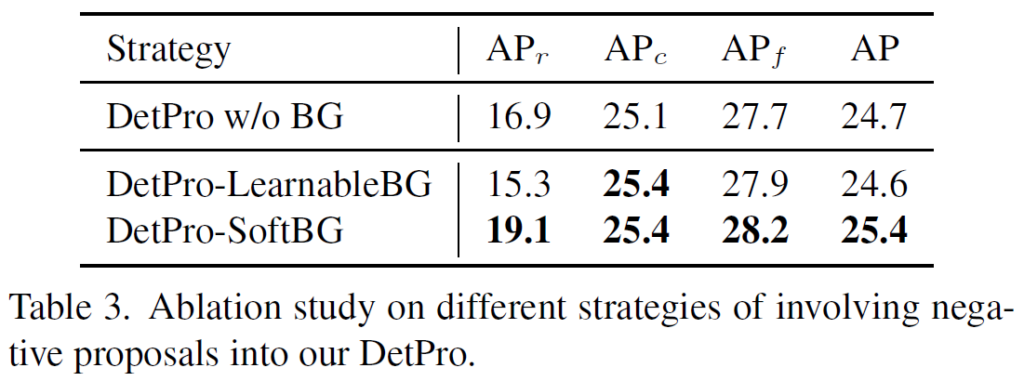
저자들은 제안하는 Soft background interpretation(모든 base class의 확률값과 멀어지도록 softmax 학습) 이외에 다른 background interpretation 방법들을 비교하였습니다. background를 learnable하게 학습했을 때는 크게 좋지 못한 성능을 보였는데, 굉장히 다양한 background의 상황을 하나의 범주로 묶어 가까워지도록 하는 전략이 효과적이지 않은 것 같다고 저자들은 분석하고 있습니다.
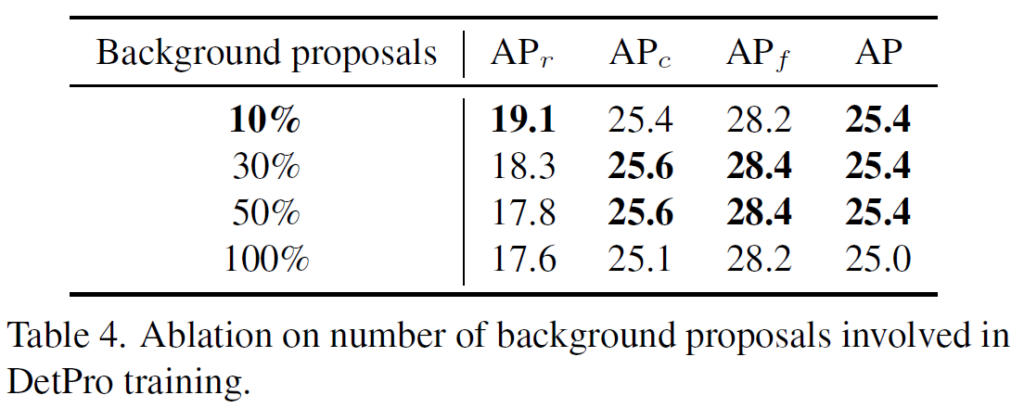
negative proposal을 활용하는것이 중요함은 알았지만, 이를 얼마나 사용해야 하는지에 대한 결정이 필요해 이에 대해 실험 또한 수행되었습니다. 결과적으로 negative sample이 늘어날수록 좋지 않은 결과를 보였습니다. negative를 줄이는것이 학습의 속도를 높일 수 있을 뿐만 아니라, background에 편향되는 것을 완화할 수 있다고 합니다. 저자들은 기본 값으로 10%를 사용하였습니다.
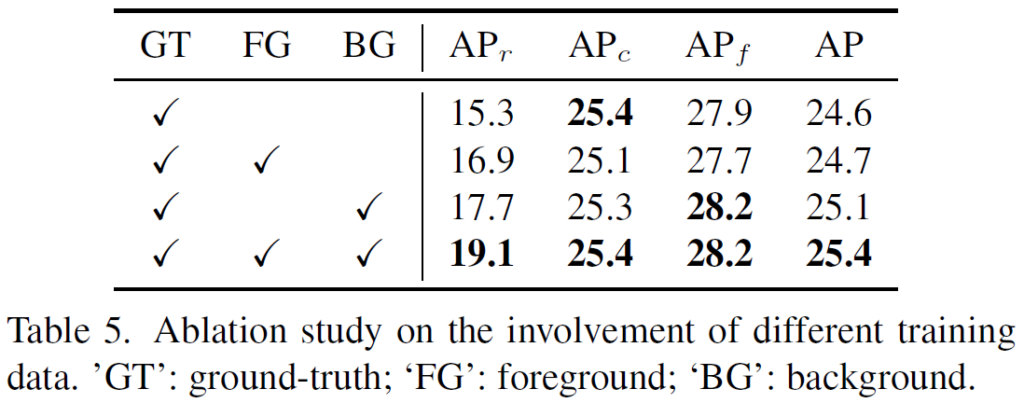
학습에 GT, Foreground, Background를 어떻게 조합하는것이 좋은지에 대한 실험도 수행되었습니다. 결과적으로는 foreground나 background를 제외하면 성능이 저하되었으며, GT, Foreground, Background를 모두 조합하여 활용하는것이 효과적임을 확인할 수 있었습니다.
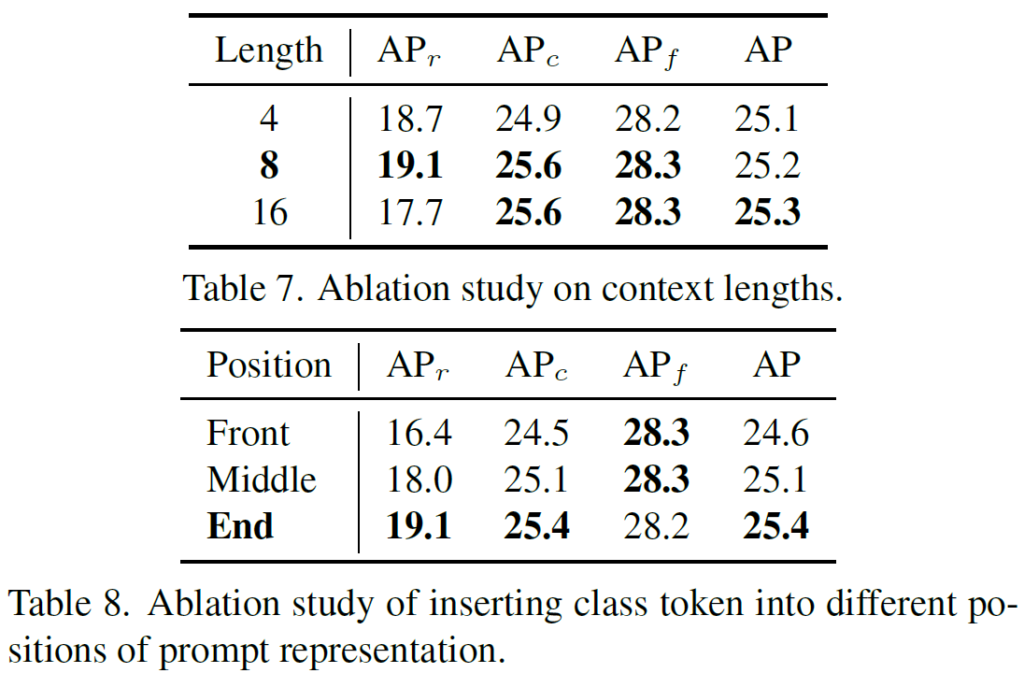
Table 7에서는 context 길이 L에 대한 ablation study결과를 나타내었습니다. CoOp에서는 긴 prompt를 사용하는 것이 close-vocabulary image classification에서 좋은 결과를 낼 수 있음을 보였는데, 저자들은 base class에서도 동일한 결과를 얻을 수 있었습니다. 하지만 novel class에서는 그렇지 못하고 prompt가 길어지면 base category들에 overfitting 될 수 있다고 합니다. 저자들은 context length L의 기본값을 8로 설정하였습니다.
Table 8에서는 Class Token 위치에 대한 비교 수행 실험 결과를 나타내었습니다. 일반적으로 가장 좋은 위치가 dataset마다 다르다고 하는데, 저자들의 실험에서는 class token을 끝에 두는 것이 좋은 성능을 거둘 수 있음을 확인하였습니다.
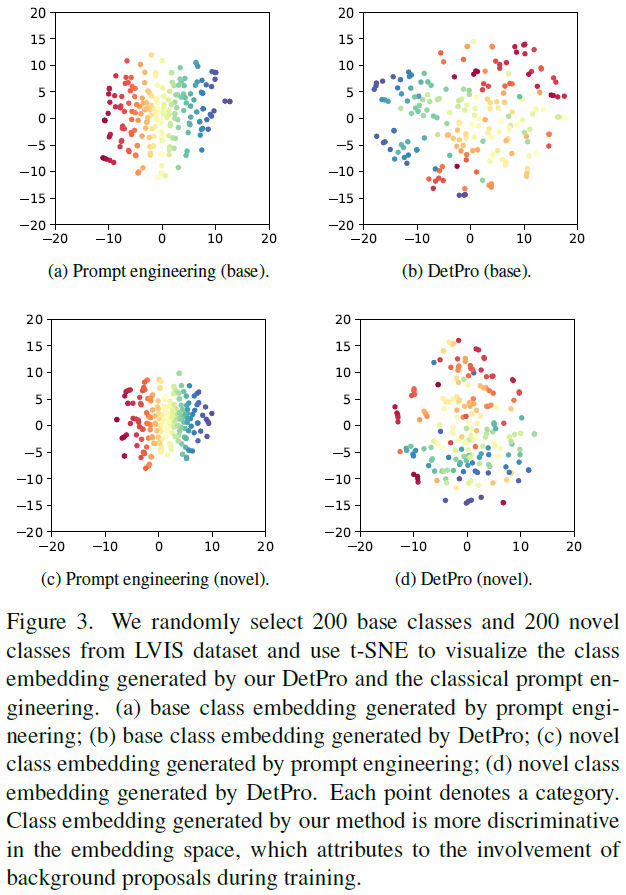
마지막으로, 저자들은 DetPro와 기존의 prompt engineering으로 생성된 class embedding을 t-SNE로 시각화 한 결과를 Figure 3에 나타내었습니다. 이 때, LVIS에서 200개의 base class와 200개의 novel class를 무작위로 뽑아서 사용했습니다. 시각화 결과, DetPro로 생성된 class embedding이 임베딩 공간에서 더욱 구별됨(discriminative)을 확인하였습니다. 이는 open-vocabulary object detector의 region classifier로써 더욱 좋은 능력을 갖춤을 의미한다고 주장하고 있습니다.
Conclusion
OVOD를 위한 prompt representation learning 기법인 DetPro를 살펴보았습니다. 기존의 classification을 위한 prompt learning 방법론인 CoOp을 OVOD 프레임워크인 ViLD에 잘 통합했다는 생각이 들고, 최적의 구조를 탐색하기 위해 다양한 Ablation을 수행한 점이 인상 깊었습니다. 지금까지 비전쪽만 봐왔기에 프롬프트 엔지니어링, 프롬프트 러닝과 같은 NLP 색체가 있는 요소들에 대해 잘 몰랐었는데, 해당 논문을 읽으며 VLM의 프롬프트에 대한 감을 잡을 수 있었습니다.
감사합니다.
안녕하세요 재연님, 쓰신 글 잘 읽었습니다.
관련된 지식이 많이 부족하지만 처음에 나온 기초 설명을 따라가면서 찾아보니 어느정도 이해한 것 같습니다.
DePro 방식을 이용하여 기존 OVOD 의 프롬프트에 따른 성능차이를 해결하려는 시도로 이해했습니다.
제가 정확히 이해하지 못한 부분이 많겠지만 이해한 바가 맞는지 질문을 드리고 싶습니다.
1. 이미 텍스트 기반의 임베딩 벡터가 존재한다.
2. 이미지 – 텍스트 쌍으로 학습을 시킨다.
3. 프롬프트 입력 전에는 학습시킨 class에 대해서만 출력이 나온다.
4. 프롬프트 입력 후에는 학습시키지 않은 class여도 코사인 유사도의 계산을 통해 새로운 class를 찾아낼 수 있다.
이런식으로 이해를 했는데 맞게 생각한걸까요?
그리고 이런 OVOD 모델이 결국엔 코사인 유사도에 의한 Threshold 설정이 최종 성능에 영향을 미칠 것 같은데,논문에서는 어떤지 모르겠지만 임계값도 결국 학습시키는 요소인건가요? 아니면 단순히 학습이 완료된 후 하이퍼 파라미터튜닝 과정만 존재하는건지 궁금합니다.
너무 기초적인 질문인 것 같지만 알려주시면 감사하겠습니다.
1,2 질문에 대해서 먼저 답변 드리자면, CLIP과 같은 VLM 모델은 웹상에서 수집한 image-text pair를 활용해서 학습을 합니다. 이 때, image encoder는 ResNet이나 ViT같은 백본을 사용해 이미지 데이터를 image feature vector로 임베딩하는 역할을 하고, text encoder는 BERT같은 모델을 사용해 텍스트 데이터를 text feature vector로 임베딩합니다. 이제 동일 차원 벡터 형태로 임베딩 된 image feature와 text feature를 contrastive learning으로 학습하게 되며, 각 encoder가 좋은 representation을 가질 수 있게 학습합니다. 이 때 image-text contrastive learning으로 joint learning을 하기 때문에 이미지와 텍스트 간 어느정도 정렬된 임베딩을 수행할 수 있게 됩니다. 더 자세한 학습법 및 사용법이 궁금하시면 CLIP, ALIGN 및 이를 활용하는 task에 대한 논문들을 읽어보시기 바랍니다.
3번 질문이 구체적으로 무엇을 질문한 건지 와닿지 않네요. 4번 질문과 함께 답변 드리자면, 일반적으로 CLIP, ALIGN과 같은 VLM을 classifier로 사용할 때, 모든 클래스에 대한 prompt를 text encoder에 통과시켜 text feature를 얻고, 특정 image를 image encoder에 통과시켜 image feature를 얻은 다음 이 image feature를 각 class에 대한 text feature와 유사도를 계산해서 유사도가 가장 높은 text로 분류를 진행한다고 생각하시면 됩니다. 대량의 웹 데이터로 학습하여 이를 기반으로 분류를 수행하기 때문에, detector가 학습하지 않은 novel class에 대해서도 text feature와 유사도를 계산할 수 있으니 분류 수행이 가능합니다.
다음 질문에 대해서 살펴보면, 코사인 유사도에 의한 threshold가 정확히 무엇을 지칭하는지 잘 이해되지 않습니다. 더 자세히 질문 주시면 답변 드리겠습니다. 혹시 background를 판별할 때 사용되는 GT와 IoU와의 threshold를 말하신 것이라면 classifier의 코사인 유사도 계산과는 관련 없는 개념입니다. 그냥 배경/전경 여부를 나누는 일종의 하이퍼파라미터입니다. IoU 0.5를 기준으로 판단하는 것은 detection에서 매우 자주 사용되는 세팅입니다.
안녕하세요 재연님, 좋은 리뷰 감사드립니다.
제가 이해한 부분이 맞는지에 대한 점검을 받고자 댓글 드립니다!
background interpretation 기법이 배경 부분(negative proposal)의 특징을 모든 클래스와 멀어지도록 학습하는 방식이 배경 영역을 하나의 특정한 클래스로 학습하지 않고, 모든 class embedding과의 유사도를 낮추도록 학습하기 때문에 background embedding이 특정 클래스와 가까워지는 것을 방지하고, 오히려 모든 클래스와의 거리를 유지하도록 최적화시키는 학습 방식으로 이해했는데 혹시 제가 놓친 부분이 있다면 알려주시면 감사하겠습니다.
추가적으로 제가 해당 리뷰를 제대로 이해하지 못해서 생기는 질문일 수도 있는데,
배경이 특정 클래스와 유사해지는 것을 방지하는 데 초점을 맞추고 있다면 실제로 배경이 오히려 중요한 단서가 될 경우(예를 들어 탐지하고자 하는 배는 보통 바닷가에서 보이는 경우)에 문제가 될 수도 있겠다 라는 생각이 들었습니다!
위 방법론이 배경과 객체 사이의 연관성을 어느정도 고려하면서 배경이 특정 클래스와 유사해지는 것을 방지하는 것인지 아니면 배경과 객체 사이의 연관성을 완전히 무시하는지 궁금합니다!
감사합니다!
올바르게 이해한 것으로 보입니다. 저자는 제안하는 background interpretation 기법 뿐만 아니라 background를 하나의 class로 취급하여 최적화시키는 전략도 실험했었는데, 다른 모든 class와의 거리가 멀어지도록 학습하는 것이 효율적이었다고 합니다.
만약 어떤 클래스를 판단하는데 주변 맥락이 중요할 수도 있지만, 그렇지 않을수도 있습니다. 배의 주변이 물이 있다는 것은 배를 인식하는데 굉장히 좋은 단서일 수 있지만, 저희는 항상 모델이 편향되는것을 주의해야 합니다. 물 위에 떠있는 것을 배가 아닌데 배라고 인식할 수도, 뭍으로 꺼내놓거나 창고에 보관중인 배를 물 위에 떠있지 않는 상태이기에 배가 아니라고 분류하는 상황은 좋지 않겠죠. 이런 관점에서는 주위 환경들을 크게 고려하지 않는게 좋을 것 같습니다.
또한, 특정 클래스를 학습하는것이 아닌 모든 object와 구분하게 만드는 배경을 학습하고자 하는 경우, 어떤 맥락과 물체의 배경이 올지 너무 다양하니 특정 class를 염두하는 것은 좋지 못한 전략일 수 있습니다.
CLIP과 같은 대규모 VLM의 경우 어느 정도 그 수가 정해져있기는 하지만 매우 많은 class를 다룰 수 있기에, 배경과 객체를 구분하는 일반화 능력이 뛰어나다고 생각됩니다.