
안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 2024년 12월 IEEE Transactions on Intelligent Transportation Systems에 게재된 논문입니다. DETR기반 multispectral detector이 아직 많지 않은 상황에서, DETR 구조를 기반으로 검출기를 제안한 (transaction이라 conference쪽보다는 게재 기간이 길었겠지만)나름 최신 논문이기에 그 내용이 궁금하여 읽어보게 되었습니다. 가벼운 마음으로 읽기 시작했는데 내부 기호 및 요소들이 복잡해서 읽는데 시간이 좀 오래 걸렸네요.
리뷰 시작하겠습니다.
Introduction
Autonomous Driving, Automated Video Surveillance, Robotics 분야에서 보행자 검출은 상당히 주목 받는 분야이고, 활발히 연구가 수행되어왔습니다. 하지만 모두 알다시피, 가시광선 영역의 컬러 카메라로 취득한 RGB 영상은 취득 환경의 조도 변화에 민감하다는 문제점이 있었죠. 저조도 상황에서 RGB 영상 기반 인식의 한계가 명확하기 때문에 이를 보완할 Visible-Thermal 영상을 함께 활용하는 Multispectral Pedestrian Detection이 그 대안으로 주목받았고, 덕분에 주/야간 강건한 객체 및 보행자 탐지를 수행할 수 있게 되었습니다. 하지만 CNN기반 multispectral detector들은 predefined anchor box, 많은 수의 proposal, NMS와 같이 동작 시간 및 정확도에 부정적 영향을 미칠 수 있는 추가적인 모듈을 필요로 했습니다. 최근에는 detection task에서 이러한 요소들을 없애고 detection task를 direct set prediction 문제로 해석하여 고안된 DETR이 제안되었고, 저자들은 이런 맥락에서 DETR 기반의 Multispectral detector인 MultiSpectral pedestrian DEtection TRansformer (MS-DETR)를 제안합니다. 해당 방법론은 단순히 DETR 기반의 멀티스펙트럴 검출기를 제안했다는 것 뿐만 아니라, 멀티스펙트럴 검출기의 대표적인 문제인 1. 영상 도메인 간 misalign, 2. 검출기의 각 도메인에 대한 편향성 문제를 완화한 구조를 제안했다는 점에서 의미가 있습니다.
멀티스펙트럴 영상 데이터는 취득 과정에서 동일 장면에 대해 가시광 카메라와 적외선 카메라로 서로 다른 영상을 촬영하는데, 두 대의 카메라로 촬영하다보니 카메라 간 disparity와 각 파장대의 굴절률 차이 등으로 완전히 정렬된(Aligned) 영상을 얻기 어렵습니다. FLIR 데이터셋 같은 경우는 상당히 misaligned되어있고, align이 잘 맞는 데이터셋으로 분류되는 KAIST, CVC-14와 같은 데이터셋도 본 논문에서는 약간의 오정렬이 포함되어 있다고 합니다(KAIST데이터 같은 경우는 beam splitter를 이용해서 visible-lwir 간 alignment를 최대한 맞추었죠). 하지만 이렇게 misalign된 각 도메인에 대해 기존의 concatenation, addition과 같은 densely coupled fusion전략을 사용하는 것은 검출 성능 저하로 이어질 수 있습니다. 따라서 저자들은 이 대신 Figure 1과 같이 loosely coupled fusion 전략을 사용합니다. 각 도메인의 feature map에 그대로 dense한 fusion을 취하지 않고, 각 모달리티에서 몇몇 keypoint와 각 대응되는 attention weight를 sparse하게 샘플링하여 멀티 모달 특징을 적응적으로 모읍니다(adaptively aggregate). 이를 통해 자연스럽게 visible – thermal 각 모달리티 영상이 완전히 정렬되어있어야 한다는 조건을 피할 수 있게 됩니다.
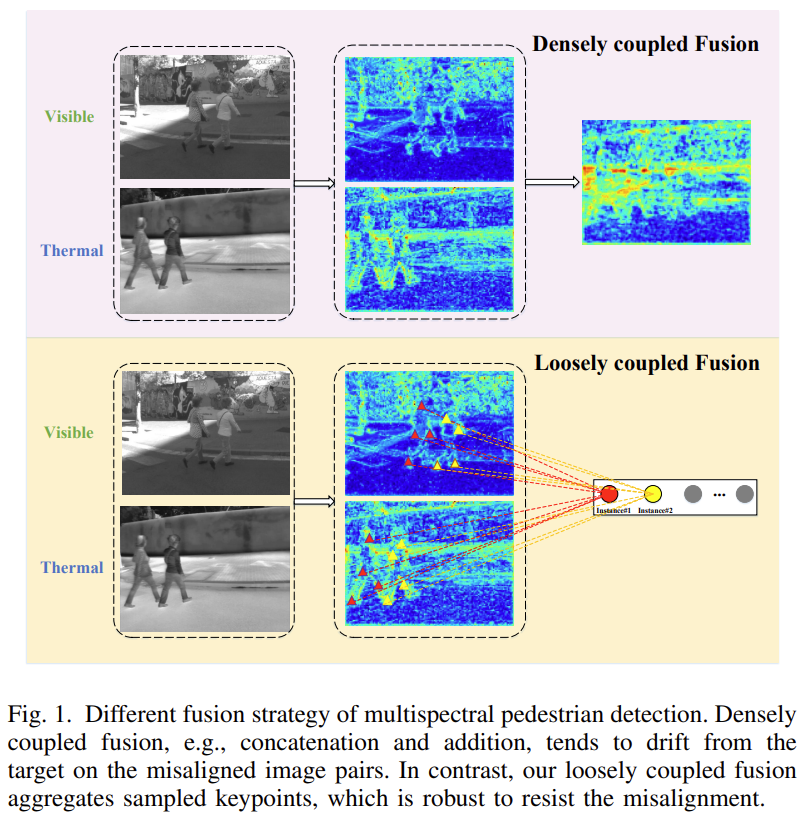
또한, 각 모달리티 간 불균형 문제를 완화합니다. 일반적으로 낮 시간대에는 visible 영상은 좀 더 명확한 질감 정보를 갖고 있고 밤 시간대에는 thermal 영상이 좀 더 명확한 윤곽 정보를 갖고 있습니다. 하지만 visible 영상은 악천후, 그림자, 역광 등의 조도 변화에 취약하기에 이런 상황에서는 thermal 영상이 더 명확한 윤곽 정보를 제공할 수 있습니다. 이에 저자들은 다양한 조명 환경에서 다른 모달리티는 서로 다른 confidence score를 갖게 될 뿐만 아니라, 다른 보행자 instance도 object loss에 동일하지 않은 영향을 미치게 된다고 분석하고, 이러한 문제를 완화하기 위해 instance-aware modality-balanced optimization 전략을 제안합니다. 디코더의 visible, thermal, fusion 3개의 branch로부터 3개의 predicted slot 세트를 얻고, 학습 과정에서 각 보행자 인스턴스의 contribution을 조정하기 위해 instance-wise dynamic loss를 도입하였습니다.
저자들은 논문의 contribution을 다음과 같이 요약하였습니다 :
- 우리는 단일 모달 검출을 위한 검출기인 DETR에 multi-modal transformer decoder를 도입하여 멀티스펙트럴 데이터로 확장한 MS-DETR을 제안하였다.
- visible-thermal 모달 간 더욱 효율적인 feature fusion을 위해 loosely coupled fusion 전략을 제안하였고, 이는 다른 퓨전 전략들과 비교해 DETR계열 멀티모달 프레임워크에 잘 적용될 수 있는 가능성을 보였다.
- visible, thermal, fusion 3개의 detection branch에서 생성된 3개의 slot 집합을 잘 align하기 위해 instance-aware modality-balanced optimization 전략을 고안하였다. 정렬된 slot들을 기반으로, dynamic loss를 사용하여 각 instance의 contribution을 측정하고 조정한다.
- 멀티스펙트럴 보행자 검출에서 널리 사용되는 KAIST, CVC-14, LLVIP 데이터셋을 활용하여 제안한 방법론의 효과에 대한 실험들을 수행하였다. 실험 결과 MS-DETR의 우수성을 입증하였다.
Method
Overview

Fig. 2.와 같이 MS-DETR은 1.두 modality-specific CNN backbones, 2.두 modality-specific Transformer encoders, 3. 하나의 multi-modal Transformer decoder로 구성됩니다. 주어진 visible 영상 I^{V}, thermal 영상 I^{T}에 대해서 각 modality-specific CNN backbone에서 먼저 multi-scale feature map을 추출하고, 이 feature map들은 대응되는 modality-specific encoder로 입력되어 deformable self-attention을 통해 모달리티 별 multi-scale feature map을 집계하게 됩니다. 이 과정은 다음 수식으로 나타낼 수 있습니다 :
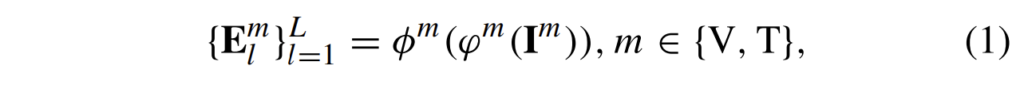
여기서 φ^{m}(·) 와 Φ^{m}(·)는 각각 m 모달리티의 CNN backbone과 Transformer encoder이며, {E_{l}^{m}}_{l=1}^{L}은 정제된 multi-scale feature map을 의미합니다. l은 scale의 index입니다.
이후 multi-modal Transformer decoder는 두 모달리티의 multi-scale feature map {E_{l}^{m}}_{l=1}^{L}를 입력받습니다. 한편, positional encodings(PE)과 결합된 learnable content embeddings(CE)는 디코더로 입력되어 encoded input feature와 cross-attention(CA) 연산을 수행하게 됩니다. 이 때 저자들은 아래의 Fig. 3과 같이 fusion branch만을 사용하지 않고 visible 및 thermal branch를 추가적으로 디코더에 사용하여 3개의 predicted slots 세트를 각각 얻을 수 있도록 하였습니다.
모델을 최적화시키는 과정에서는 modality imbalance 문제를 완화하기 위해 instance-aware modality-balanced 전략을 사용하였습니다. 세부적으로는 디코더에 instance-wise dynamic weighting loss를 적용하여 각 보행자 인스턴스에 대한 두 모달리티의 기여도를 적응적(adaptively)으로 조정하게 하였습니다.
이제 저자들이 제안하는 멀티모달 트랜스포머 디코더와, instance-aware modality-balanced optimization 전략에 대해 좀 더 자세히 살펴보겠습니다.
Multi-Modal Transformer Decoder
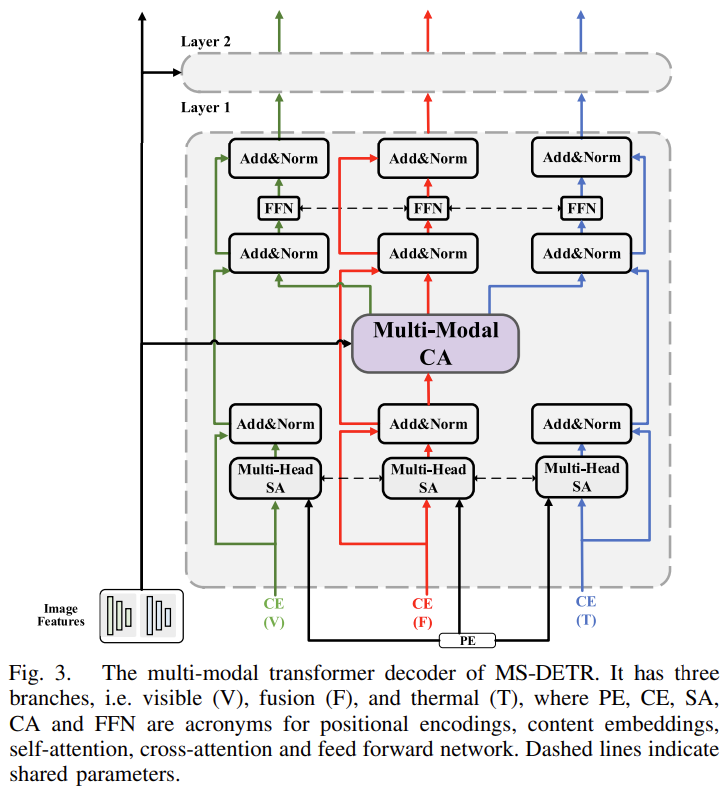
저자가 제안하는 multi-modal Transformer decoder 구조에는 visible(V), fusion(F), thermal(T) 3개의 branch가 있습니다. 따라서 3개의 content embeddings(CEs)가 있으며, 하나의 positional encoding(PE)를 갖게 됩니다. 각 layer에서 visible, fusion, thermal branch의 multi-head Self-Attention(SA)와 Feed-Forward Network(FFN)는 동일한 파라미터를 가지며, 모든 세 branch는 공동 multi-modal cross-attention(CA) 모듈을 공유합니다. 제안하는 loosely coupled fusion은 multi-modal cross-attention(CA)모듈에서 수행됩니다.
Loosely Coupled Fusion in Multi-Modal CA Module
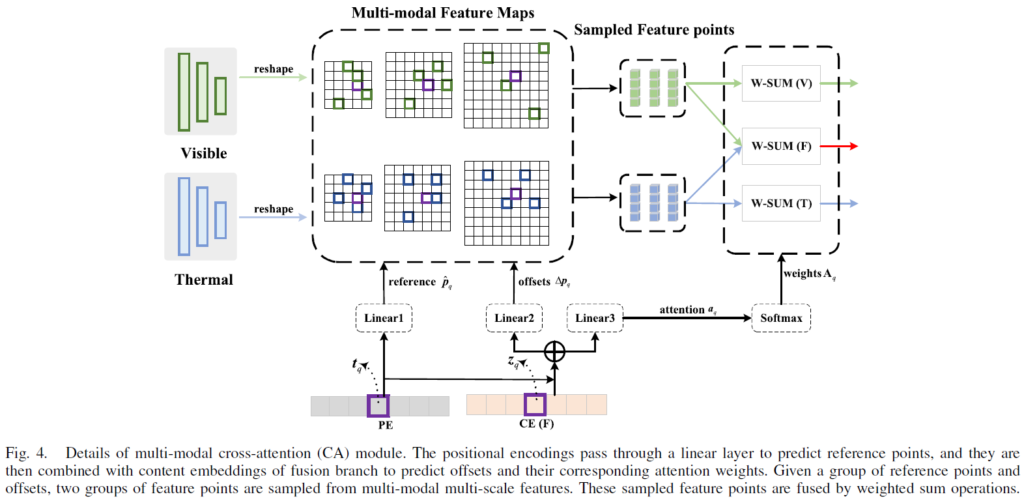
multi-modal cross attention은 특징맵의 공간적 크기에 관계없이 reference point 주변의 key sampling point들의 small set만을 고려하는 deformable attention을 기반으로 하게 됩니다. Fig.4에서 multi-modal cross-attention module의 세부 사항을 확인할 수 있는데, 해당 그림은 Fig 3의 decoder 내부 Multi-Modal CA 모듈 부분에서 수행되는 것으로 생각하면 됩니다. 세부적으로, q번째 positional encoding {t}_{q} 는 Linear1로 들어가 reference point의 좌표 \hat{p}_{q}를 얻게 됩니다.
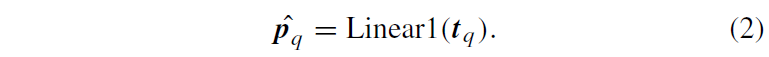
한편, q번째 positional encoding {t}_{q}도 fusion branch의 content embedding {z}_{q}과 결합되어 샘플링 포인트 Δ{p}_{q}의 offset을 바로 예측하게 되고, 이들의 corresponding attention weights {a}_{q}는 두 독립된 linear layer를 거치게 됩니다.
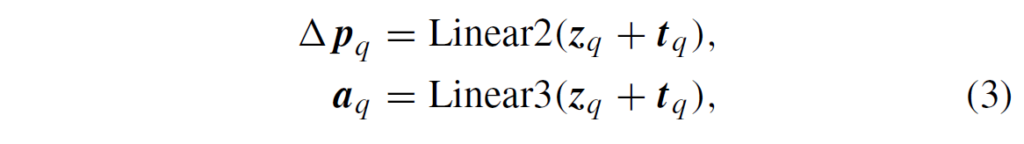
다양한 피쳐 스케일과 모달리티의 주요한 key elements와 이에 대응되는 attention weights를 얻고 난 다음, 이 가중치들을 정규화하기 위해 softmax를 사용하게 됩니다({A}_{q} = Softmax({a}_{q})). loosely coupled fusion은 이 sampled point와 이들의 normalized attention weights에만 수행됩니다. fused features는 다음과 같이 얻어집니다.
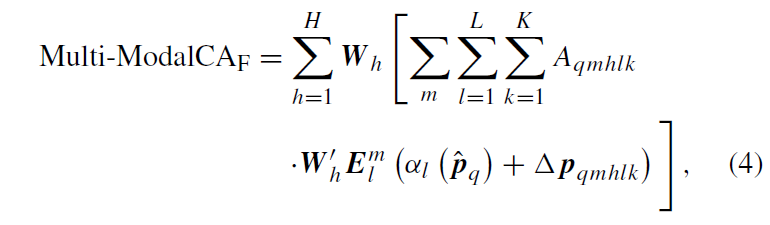
\hat{p}_{q}은 q번째 쿼리의 reference point이고, m은 modality를, 그리고 h는 attention head, l은 feature scale, k는 sampling point를 의미합니다. {α}_{l}(\hat{p}_{q})는 \hat{p}_{q}를 l번째 scale의 input feature map으로 re-scale하게 됩니다. Δ{p}_{qhlk}와 {A}_{qhlk}는 h번째 attention head의 l번째 feature level 안에 있는 k번째 sampling point의 sampling offset과 scalar attention weight를 의미합니다(복잡하네요..). Fig 4에서 visible 및 thermal feature의 퓨전은 두 모달리티의 prominent key elements aggregating 과정에서만 수행되는 것을 확인할 수 있습니다. 이 과정을 본따 “loosely coupled fusion”으로 이름 붙였다고 합니다. Fig 4의 과정에서, offset Δ{p}_{q}는 Δ{p}_{q}^{V}와 Δ{p}_{q}^{T}로 나뉘고, attention weight {a}_{q}도 modality specific component {a}_{q}^{V}와 {a}_{q}^{T}로 나뉘게 됩니다. softmax 정규화 이후, 각 모달리티 특화 어텐션 가중치 {A}_{q}^{V} = Softmax({a}_{q}^{V})와 {A}_{q}^{T} = Softmax({a}_{q}^{T})를 얻게 됩니다. 따라서, multi-modal cross-attention module CA 내의 uni-modal 특징의 두 extra group은 다음과 같이 얻어집니다.
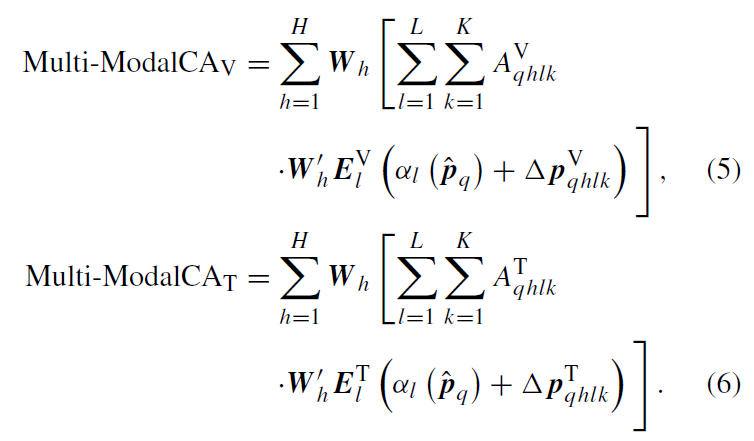
Instance-Aware Modality-Balanced Optimization
디코더의 출력값을 modality-specific detection head에 전달해서, 3세트(Visible, Thermal, Fusion)의 예측값 \hat{y}_{n}^{i}, i ∈ {V, T, F}을 얻게 됩니다. 각 모달리티마다 다른 특성을 가지고 있기에 예측값들은 일관적이지 않을 것입니다. 다른 모달리티 간 기여도 밸런스를 맞추기 위해, 저자들은 해당 iteration에서 slot predictions의 최적의 permutation을 비교한 다음 선택하도록 하였습니다. 이후에는 선택한 permutation \hat{σ}에 따라 모든 세 branch의 예측값들을 재배였하도록 하였습니다. \hat{σ}를 얻기 위해, 먼저 각 branch에서 최적의 permutation을 계산합니다.
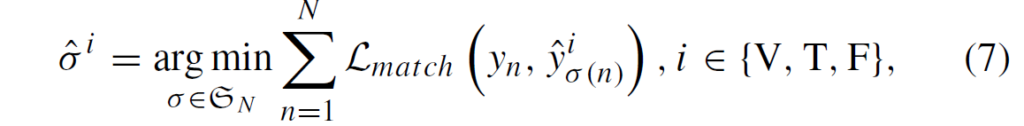
7번 수식에서 {L}_{match}()는 Ground Truth와 예측값 사이의 matching cost이고, 다음과 같이 계산됩니다. 여기 부분들은 DETR의 학습 과정을 연상하시면 이해가 어렵지 않을 것입니다.
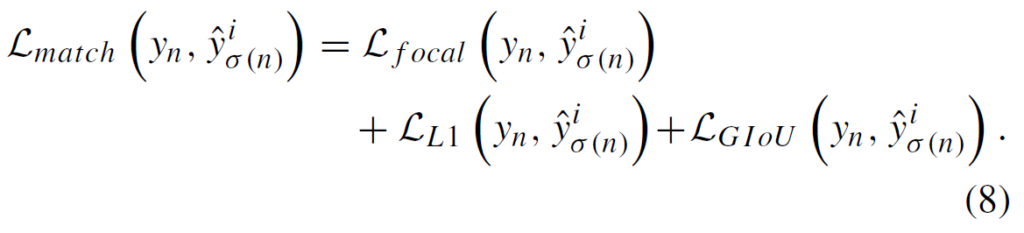
각 모달리티의 permutation의 matching cost를 비교하여, optimal permutation \hat{σ}을 얻습니다. 이후, \hat{σ}에 따라 다른 branch들의 slot들을 재정렬하고, 새로운 permutation 에 따라 matching cost를 업데이트 하게 됩니다.
학습의 균형을 맞추고 검출 성능을 높이기 위해 저자들은 instance-wise dynamic loss를 제안하였습니다. 우선 instance 단위 optimal permutation 에서 matching cost를 계산하고, 이를 활용하여 다양한 인스턴스에 대한 예측 신뢰도를 측정하여 세 가지 branch의 instance-level 가중치를 적응적으로 조정(adaptively adjust)한다고 합니다. T개의 보행자 인스턴스가 있을 때, optimal permutation \hat{σ}의 모달리티 i에 대해 j번째 instance의 instance-level matching cost를 c_{\hat{σ}(j)}^{i}라고 할 때 dynamic fusion parameters λ_{\hat{σ}}^{i}는 다음과 같이 얻어집니다 :
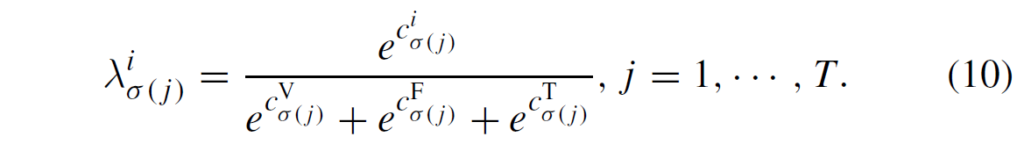
그리고 modality i의 loss는 예측된 보행자의 dynamic loss 항과 예측된 보행자가 아닌 것의 focal loss 항에 대해 다음과 같이 구성됩니다 :
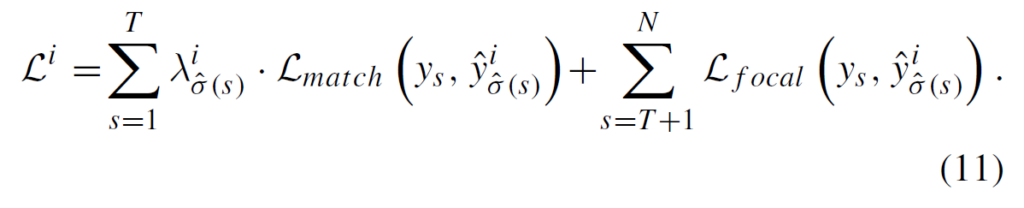
따라서, MS-DETR 학습의 total loss는 다음과 같이 구성됩니다.
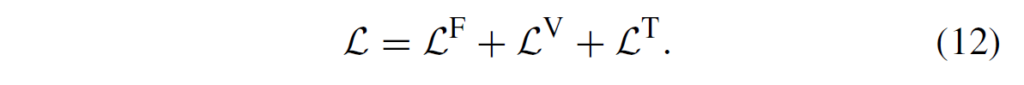
훈련 과정에서 visible, thermal, fusion branch를 보존하는데, modality-balanced optimization 이후에는 3 branch 모두 각각 정확한 탐지 결과를 얻을 수 있습니다. 따라서 추론 단계에서는 3개의 branch 중 하나를 사용하면 됩니다. 저자들은 기본적으로 fusion branch를 사용했다고 합니다.
Experiment
visible, thermal에 대한 두 backbone은 ResNet50이 사용되었으며, 트랜스포머의 인코더-디코더 layer는 각각 6개가 사용되었습니다. DETR계열의 검출기들은 학습에 많은 데이터가 소요되므로, 저자들은 COCO 데이터셋에서 사전학습한것을 사용하였습니다. 실험에는 대표적인 multispectral pedestrian detection dataset인 KAIST, CVC-14, LLVIP이 사용되었습니다. KAIST 데이터셋에는 “Reasonable”, “All” 두 평가 세팅을 사용하였는데, “Reasonable은 occlusion이 없거나 부분적이며 보행자가 55pixel보다 큰 것만을, “All”은 평가 데이터셋에 있는 작은 보행자 및 occlusion이 심한 것 모두를 사용한 것입니다.

다양한 멀티스펙트럴 검출기와 비교한 결과, 저자들이 제안한 MS-DETR이 기존 방법론들보다 상당히 우수한 결과를 보여주며 SOTA를 달성하였습니다. 특히 저자들은 “All”에서 기존보다 상당히 뛰어난 성능을 보여주어 small object 검출 성능이 뛰어남을 보였다고 설명하고 있습니다. 이에 대한 뒷받침을 위해, 보행자의 거리 및 occlusion 수준에 따라 수행한 실험 결과를 Table 2에 나타내었습니다.
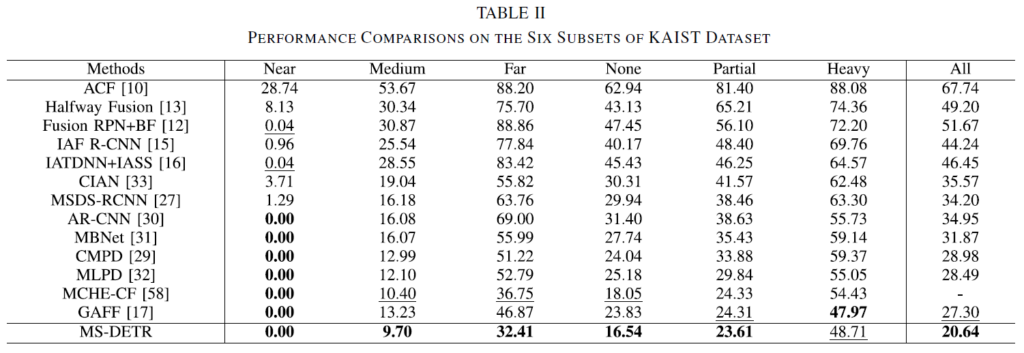
Table 2 의 실험 결과, 대부분의 subset에서 miss rate를 개선한 점을 확인할 수 있습니다.
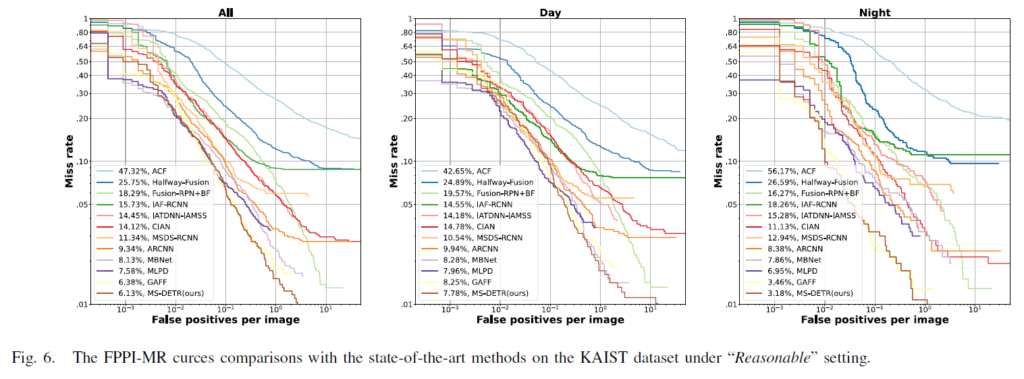
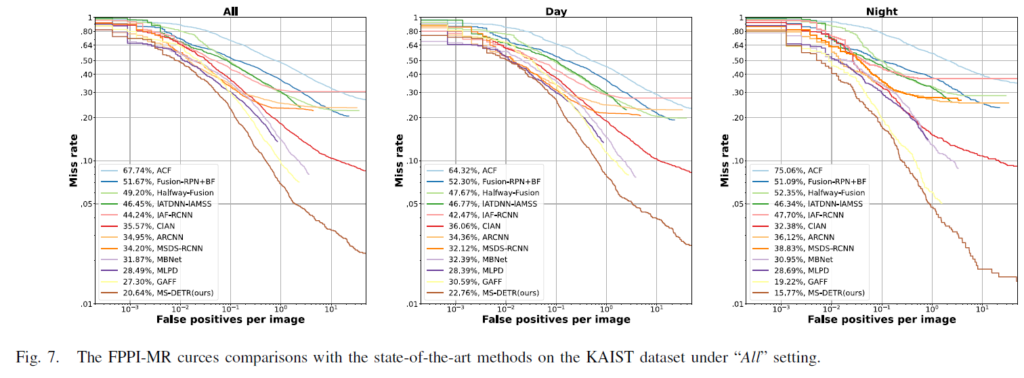
더욱이, “Reasonable”및 “All” 세팅에서 FPPI-MR 커브를 나타낸 그림 Fig 6, Fig 7를 참고하면 Reasonable 세팅에서 저자들의 MS-DETR이 넓은 범위에서가장 작은 Miss Rate를 기록해 밤 상황의 성능을 상당히 개선했음을 확인할 수 있으며, All 세팅에서 는 주/야간 모든 상황에서 타 방법론들보다 좋은 결과를 보여주고 있습니다.
마지막으로, Fig 8에서는 몇몇 detection 결과를 시각화하여 나타내었습니다. 노란 박스는 GT를, 초록 박스는 MBNet, MLPD, GAFF, MS-DETR의 검출 결과를 나타낸 것입니다. 빨간 사격형은 검출 결과 놓친 것을 나타낸 것입니다. 다른 검출기의 경우 몇몇 보행자를 놓쳤지만, MS-DETR은 매우 높은 검출률을 보여주는것을 확인할 수 있습니다.

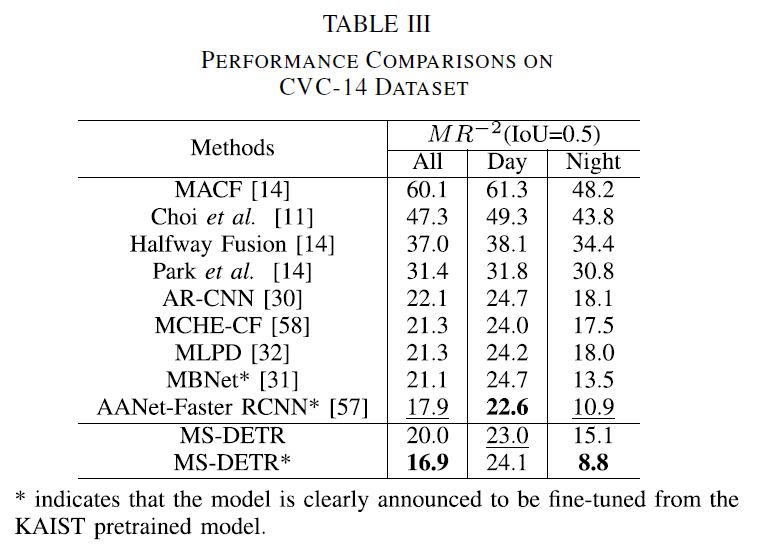
CVC-14 데이터셋에서는 특이하게 KAIST로 사전학습을 하고 CVC-14로 fine-tuning을 진행했다고 합니다. 결과는 Table 3에서 확인할 수 있습니다. CVC-14 데이터셋의 경우에도 MS-DETR은 All, Night에서 가장 좋은 결과를 보여주었습니다. day에서 성능 저하가 일어나는것이 loosely coupled fusion strategy에서 selected point들만 고려하는 과정에서 텍스쳐 정보 일부가 손실되어서 그런 것으로 분석된다고 합니다. 해당 방법론에는 딱히 추가적인 alignment를 위한 요소가 없음에도 비교적 낮은 miss rate를 보여주며, 특히 Night 검출 결과가 좋은 것ㅇ르 강조합니다.
CVC-14에 대한 시각화 결과는 Fig.9에 나타내었습니다. GT, True Positive, False Positive 박스를 각각 노랑, 초록, 파란색으로 나타내었습니다. 논문에서는 MBNet과 비교하여 False Positive 의 비율이 적다는 것을 강조하고 있습니다.

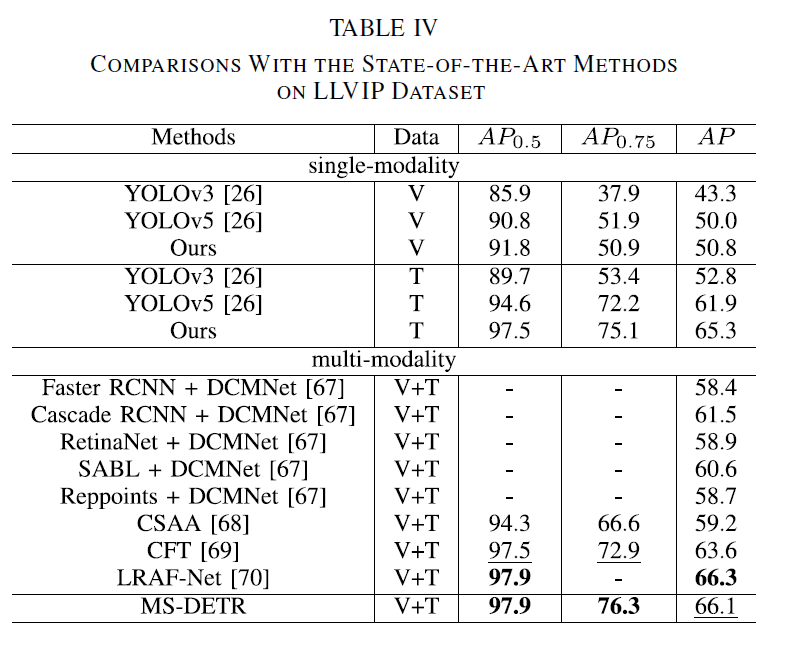
마지막으로 LLVIP에 대한 실험 결과는 Table 4에 나타내었습니다. 해당 데이터셋은 주로 Average Presicion(APiou)를 주로 사용하는 듯 하네요. 해당 실험에서는 단일 모달리티 모델 검출 결과도 함께 나타내었습니다. LLVIP가 야간 장면 데이터셋인 만큼, 전반적으로 thermal의 검출 결과가 비교적 우수하다고 합니다. 멀티모달 세팅에서는 SOTA인 LRAF-Net과 겨의 견줄 수 있는 성능을 내었습니다. 여기서는 단일 모달리티의 성능이 다른 모델들의 멀티스펙트럴 성능에 견주거나 우수함을 어필하며, DETR 기반 멀티스펙트럴 검출기의 가능성을
Ablation Study
Ablation Study 에서는 Loosely Coupled Fusion 전략 및 Modality-Balanced Optimization의 영향을 실험하고, 추가적으로 DETR의 구성 요소에 대한 실험을 수행하였습니다.
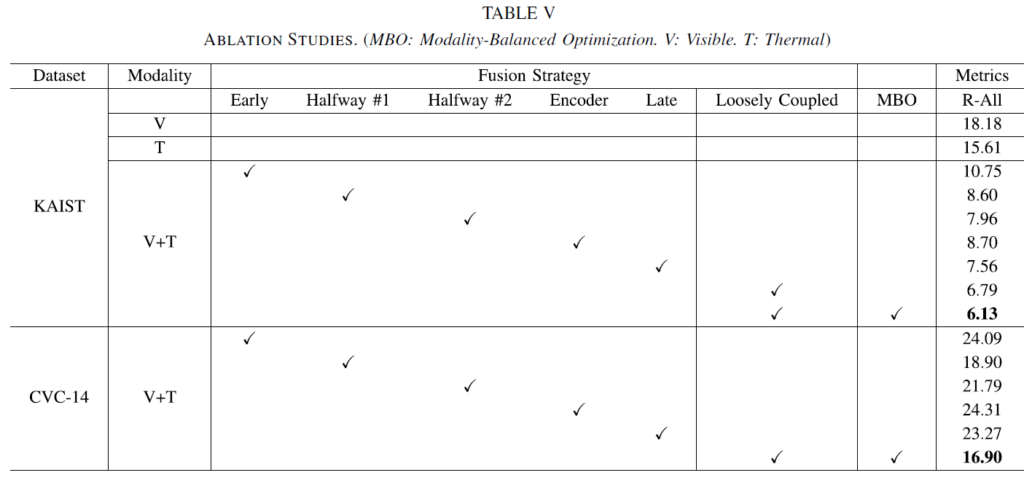
Table 5의 실험 결과, Loosely Coupled Fusion 및 Modality-Balanced Optimization의 결합이 가장 좋은 결과를 나타내었습니다. early, halfway, late fusion는 우리가 아는 CNN 백본에서의 퓨전 방법이고, encoder fusion은 transformer encoder에서 fusion을 수행하는 기존이 방법이라고 합니다. halfway도 중간 어디서 퓨전하는지에 따라 버전을 나누었네요.
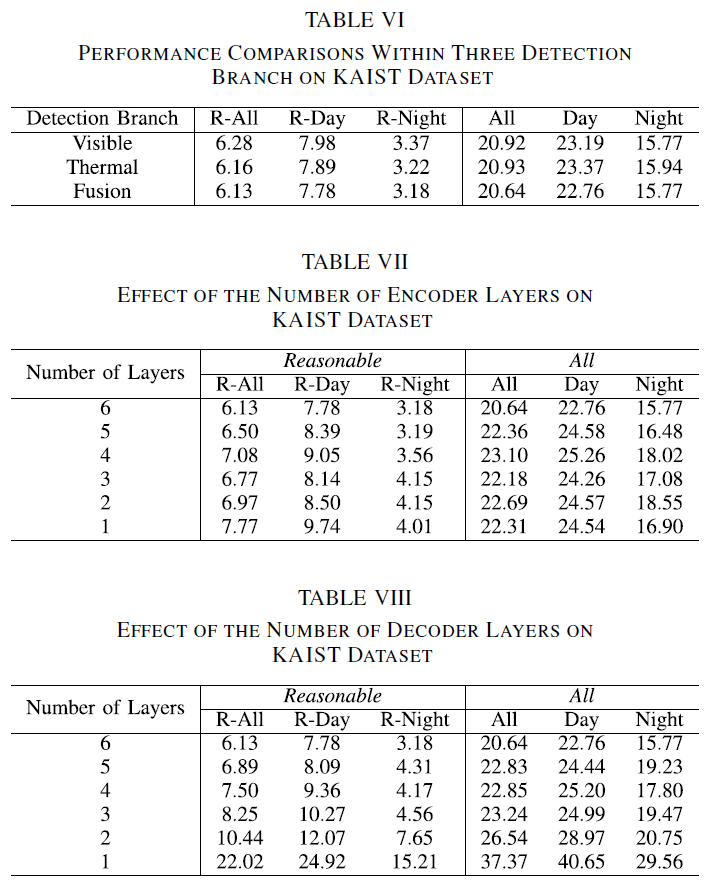
Table 6~8은 검출기 구성을 어떻게 하는지에 따른 실험 결과입니다. 6은 3개의 branch중 어떤 것을 사용했는지, 7,8은 트랜스포머의 인코더, 디코더 구성에 대한 ablation입니다.
Loosely Coupled Fusion 의 시각화
test set에 대한 MS-DETR의 selected point를 시각화하여 Fig.10에 나타내었습니다. 각 selected point는 빨간 점으로 표시되었고, 크기는 weights의 크기를 나타냅니다. 첫번째 및 두번째 열은 KAIST 데이터셋을 나타낸 것으로 보행자가 많은 상황, 멀리 있는 상황에서도 MS-DETR이 잘 동작함을 확인할 수 있습니다. 마지막 열 두개는 misalignment가 심한 CVC-14 데이터셋의 것으로, 여전히 보행자의 point를 잘 잡아내어 MS-DETR이 잘 동작함을 보여줍니다. 보행자가 한 모달리티에 있는 장면에서 MS-DETR은 다른 모달리티의 간섭을 잘 처리하여 현재 모달리티에만 있는 포인트를 선택하는것을 확인할 수 있다고 설명할 수 있습니다. 이 시각화 결과를 통해 loosely coupled fusion 전략의 강점을 다시 한번 강조합니다.

어느 정도의 misalignment를 잘 처리할 수 있긴 하지만, 오정렬이 너무 심한 경우에는 잘 동작하지 않는 한계가 있다고 설명하고 있습니다.
DETR 기반 멀티스펙트럴 보행자 검출기인 MS-DETR에 대해 살펴보았습니다. 분량도 길고 내부 동작 구조가 꽤나 복잡하여 읽고 리뷰를 작성하는데 굉장히 많은 시간이 걸렸네요. 최근 DETR 기반 멀티스펙트럴 검출이 어떻게 수행되는지 살펴 볼 수 있어 의미 있는 논문이었던 것 같습니다. 아마 한동안은 이 쪽 논문을 리뷰하지 않고, 이후 수행한 연구 분야를 탐색하는 리뷰를 작성할 것 같습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Instance-Aware modality-balanced optimization 부분 설명에서 각 모달리티의 permutation matching cost를 비교하여 optimal permutation을 얻는다고 하셨는데, 어떻게 비교를 해서 최적의 permutation이 선택되는 것인지 자세히 나와있지 않은 것 같아,, 질문 드립니다.
또, instance-wise dynamic loss에서 dynamic fusion parameter를 구하는 식에서 나와있는 e는 각 모달리티별 matching cost를 나타내는 것인가요 ? 본문에는 c로 언급되어 있길래 헷갈려 질문드립니다.
감사합니다.
1. 수식 (7), (8)번 이후, V, T, F에 대한 L_match를 각각 계산한 뒤, 각 3가지 permutation에서의 매칭 코스트를 비교하여 optimal permutation을 얻게 된다고 생각하시면 될 것 같습니다.
2. 10번 수식에서 e는 자연대수로 보여집니다. matching cost c에 대한 softmax를 생각하시면 됫 것 같습니다.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
읽었을 때 전체 이미지 픽셀이 아니라 reference point에 해당하는 픽셀 주변의 small wet만을 고려한다고 말씀해주셨는데, 그럼 이 reference point의 개수나 어떻게 구하는 지에 따라서 성능이 변하는 지에 대한 ablation study는 없었을까요 ?
q번째의 positional encoding t_q ~~ 라고 notation이 되어있는데, q라는건 하이퍼 파라미터에 해당하는지 아니면 고정된 기준이 있는 것인지가 궁금합니다.
감사합니다.
reference point의 경우 deformable detr의 deformable attention module의 설정을 그대로 사용하는것으로 보이며, 그 개수 설정에 대한 실험이나 별도의 언급은 없었습니다. Deformable DETR 논문의 ablation study에 sampling point K의 수를 늘렸을 때 AP가 소폭 상승했다는 실험 결과가 있었는데, MS-DETR에서도 비슷한 경향을 보일 것으로 생각되네요. q의 경우 쿼리의 갯수에 따라 정해진다고 생각하시면 됩니다.