
논문: PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
이번 논문은 point clouds data만을 사용하여 classification과 segmentation을 성공적으로 선보였던 PointNet입니다. 이 논문의 저자는 이후 PointNet++[1], VoteNet[2], ImVoteNet[3]과 같은 연구를 진행하고 있고 차례대로 논문을 리뷰할 계획입니다. (PointNet의 코드는 https://github.com/charlesq34/pointnet에 저자가 직접 구현하였습니다.)
Point clouds data는 geometric 정보 포함하고 있지만 본 그대로의 입력값으로 사용하지 못 했습니다. 그래서 이전의 3D object detection 또는 segmentation 연구는 image grid 또는 3D voxel로 변경하여 사용하였고, 자연스럽게 geometric 정보를 잃게 되거나 데이터가 매우 커지는 단점이 있었습니다. PointNet에서는 point clouds data 자체를 사용하여 classification, 사물별 segmentation, 공간 전체의 segmentation을 수행할 수 있습니다. 물론 raw data 자체를 사용하게 되므로 기존 방법들에 비해 network의 parameter를 매우 적게 사용합니다.
기존 연구들이 3D object detection을 하기 위해 사용한 방법은 CNN을 사용하는 것이었습니다. 그도 그럴것이 2D object detection의 성능이 매우 잘 나오고 있는 상황에서 그 방법들을 그대로 옮겨오거나 응용해서 활용할 수 있는 연구로 진행되고 있었기 때문입니다. 이 논문에서는 point clouds data의 (x, y, z)를 사용하여 k개의 class를 구분할 수 있고, n x m개의 score output으로 subcategory를 결정할 수 있습니다. (n은 point clouds data의 개수, m은 subcategory의 개수입니다.)
이 논문에서 주목하는 point clouds data의 속성은 point간 순서가 없는 것과 근접한 points는 서로 관련이 있다는 점입니다. 순서가 없다는 점(unordered)은 다시 말해 data transformation에 강인할 수 있다는 뜻이 됩니다.
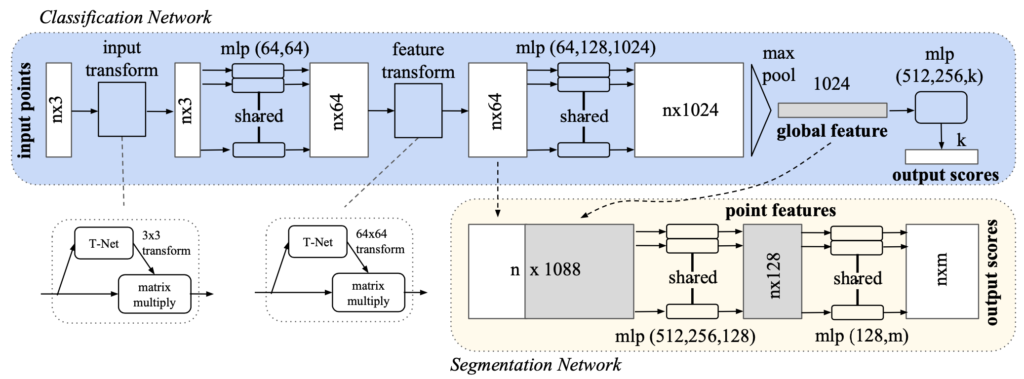
Network의 구조는 그림 1과 같으며, 논문에서 말하는 핵심 부분은 3가지 입니다. (1) classification network의 max pooling layer로 모든 points로부터 정보를 모아 global feature로 만드는 것, (2) segmentation network의 입력값을 local feature를 성격을 가지는 classification 중간 단계와 global feature를 conatenate를 하는 것, (3) transformation에 강인함을 주기 위해 T-Net이라는 affine transformation matrix를 사용하는 것입니다.
핵심 부분을 조금 더 살펴보겠습니다.
(1) Symmetry function for unordered input
고차원의 데이터를 정렬하는 알고리즘은 존재하지 않으며, 1차원으로 projection을 시킬 경우 복원할 수 없다는 점이 기존에 raw data를 입력값으로 사용할 수 없었던 이유입니다. 이 논문에서는 points간의 연관성을 주는 symmetric function을 식 1과 같이 정의하는데 MLP와 single variable를 가진 함수 g, max pooling을 이용해 함수 h를 근사하는 방법을 사용합니다.
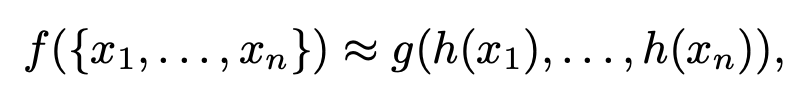
(2) Local and Global information aggregation
그림 1의 classification network에서 보듯이 local feature와 global feature를 구분해 얻을 수 있도록 설계하였고, global feature가 계산 된 후에 각 point들의 특징과 global feature를 결합하여 전체 points 특징을 얻을 수 있습니다.
(3) Joint alignment network
Point clouds의 sementic labeling은 transfromation에 대해 강인해야 하는데 이를 위해 위에서 언급한 T-Net을 사용합니다.
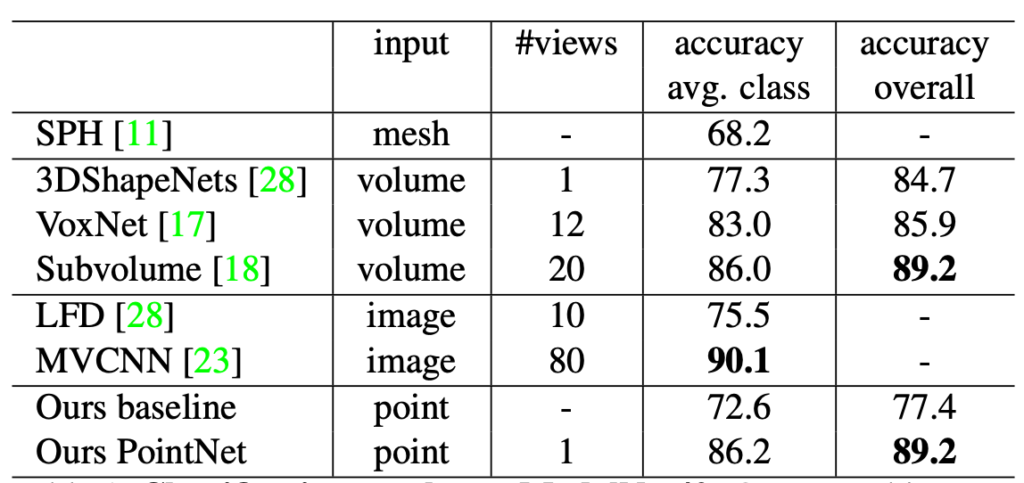
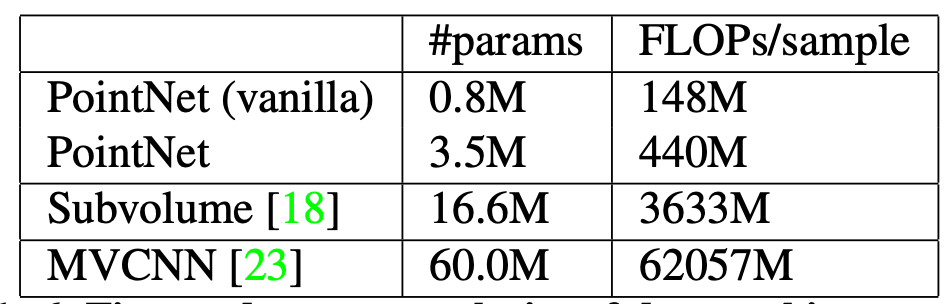
표 1은 기존 연구들과의 classification 성능 비교이며 큰 성능 차이가 나이 않다는 것을 알 수 있고, 표 2는 parameter 개수와 sample당 필요한 연산량을 나타낸 것으로 PointNet이 다른 방법에 비해 현격하게 적은 양의 parameter와 연산량만이 필요한 것을 알 수 있습니다. 그리고 그림 2는 Stanford 3D dataset[4]를 사용하여 PointNet의 결과를 나타낸 것입니다.

PointNet 논문을 시작으로 point clouds data를 raw data로 사용하는 연구가 많이 나오고 있으며 같은 저자[5]의 연구 논문을 연재 시리즈로 쭉 살펴볼 예정입니다.
참고:
[1] PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
[2] Deep Hough Voting for 3D Object Detection in Point Clouds
[3] ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
[4] 3D Semantic Parsing of Large-Scale Indoor Spaces
[5] Waymo LLC: Charles Ruizhongtai Qi