안녕하세요, 이번 주 X-Review는 24년도 EMNLP에 게재된 논문 <Interpretable Composition Attribution Enhancement for Visio-linguistic Compositional Understanding>을 주제로 작성하겠습니다. 연구 중인 Video Moment Retrieval task도 결국 사람이 입력한 자연어 쿼리의 의미를 잘 파악하는 것이 중요한데, 기본적으로 CLIP 모델의 text feature를 추출해 사용합니다. 본 논문은 최근 많은 분야에 활발히 적용되고 있는 CLIP과 같은 VLM도 텍스트 캡션 내 단어 간 의미를 잘 파악하지 못한다는 점을 개선한 방법론이라 읽게 되었습니다. Moment Retrieval task와 직간접적 연관성이 있다고 볼 수 있습니다.
방법론이 굉장히 간단하면서도 효과적으로 동작하기에 좋은 학회에 붙은 논문이라고 생각합니다.

그럼 바로 리뷰 시작하겠습니다.
1. Introduction
CLIP과 같은 거대 Vision-Language Model들은 굉장히 많은 분야에 접목되고 있습니다. 사실 CLIP을 시작으로 적용 도메인이나 해결하고자 하는 task가 더욱 fine-grained한 모델들도 발전하며 쏟아져나오고 있는데, 이 논문에서는 기본적인 바닐라 CLIP의 문제점을 지적하고 있습니다.
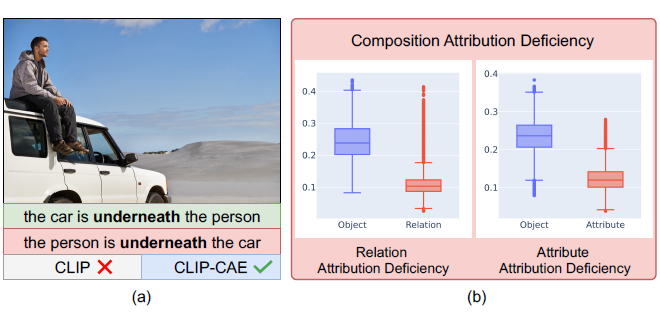
저자는 CLIP 모델이 시각적인 정보를 이해하는 과정에서 언어 정보 중 object 이상의 단어를 제대로 이해하지 못한다고 주장합니다. 위 그림 1-(a)를 보시면 바로 이해할 수 있는데, 사람이 차 위에 앉아있는 사진을 보고 기존 CLIP은 “the car is underneath the person”과 “the person is underneath the car”를 별 차이 없이 이해한다는 것입니다. 즉 이미지와 두 문장의 유사도가 모두 높다는 것이죠. 사실 두 문장을 보고 사람은 전혀 다른 시각적 상황을 떠올리겠지만, CLIP 모델은 문장 속 “the car”, “the person”에 집중할 뿐, “underneath”와 같은 compositional reasoning에는 취약하다는 뜻입니다.
방금 설명드린 문제를 저자는 Composition attribution deficiency 문제라 칭합니다. 이는 그림 1-(b)에서 좀 더 정량적으로 살펴볼 수 있습니다. 말이 어렵지만 결국 CLIP의 텍스트 인코더가 문장을 처리할 때, Object에 대한 attention score와 Relation 또는 Attribute에 대한 attention score가 크게 차이난다는 점을 보여주고 있습니다. 즉 모델이 앞서 이야기한대로 명사 자체에만 집중하고 명사 간의 관계 또는 명사의 속성은 별로 중요하게 생각하지 않는다는 것을 모델의 정량적 값으로 보여준 것입니다. 이는 CLIP 모델의 사전학습 과정에서 모델이 정말 사람이 밑인지 차가 밑인지 몰라도, 물체의 등장 여부만 어느정도 파악한다면 Contrastive loss 값을 떨어뜨리는 것이 어렵지 않았기 때문일 것입니다.
CLIP 모델이 이미지에 올바르게 상응하지 않는 텍스트 캡션에 대해 구별력 없이 높은 유사도를 내뱉는 것은 여러 task 관점에서 문제가 될 수 있기에, 저자는 이를 해결하고자 하는 방법론 CAE (Compositional Attribution Enhancement) 프레임워크를 제안합니다. CLIP 학습 과정에서 Composition understanding을 강화할 수 있는 기법을 하나 추가하는 것입니다. 이 문제를 해결하고자 시도했던 기존 방법론들은 배치 내 샘플을 섞거나 LLM을 활용해 hard negative를 인위적으로 만들어 학습했습니다. 또는 합성 데이터를 가져와 사용하기도 했는데, 이러한 기존 방법론들은 모델의 attribute에 대한 구별력을 직접적으로 높이지는 않고있어 sub-optimal하고, 추가 샘플을 만들어내야 한다는 단점이 있었습니다.
저자가 제안하는 프레임워크 CAE는 추가적인 학습 샘플을 만들지도 않을 뿐더러, task-specific loss에 추가로 간단한 loss를 하나 붙여 직접적으로 attribution에 대한 학습을 극대화하고자 하였습니다. 한 문장 내에서 자체적으로 attribution의 의미를 고민하게 만듦으로써 단순 object를 넘어선 fine-grained한 정보까지 볼 수 있도록 만드는 것이죠. 자세한 방법론은 아래에서 알아보겠습니다.
2. Method
방법론의 목적은 모델의 attribution score를 높여 텍스트 캡션의 의미를 세부적으로 정확히 이해하는 것입니다. 단순한 Object를 넘어 그들의 관계나 특성에 대한 단어에도 집중하는 것이죠. 이를 위해 우선 CLIP의 학습 방식 및 notation을 간단하게 정리해보겠습니다.
Preliminary
이미지 I와 이에 상응하는 텍스트 캡션 T가 존재할 때, CLIP의 기본적인 학습은 각각의 인코더 f_{i}, f_{t}를 통해 인코딩한 d차원의 두 모달 feature를 먼저 만들어주며 시작합니다. 이후 두 feature간 유사도를 아래 수식 (1)과 같이 구할 수 있습니다.
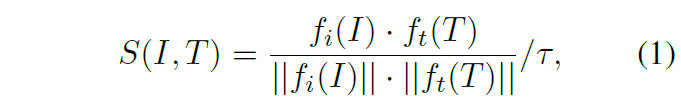
이후 학습 배치사이즈 \mathcal{B} 내에서 positive, negative 쌍을 알고 있으니 아래 수식 (3), (4)와 같은 contrastive loss를 정의할 수 있고 두 loss를 더해 최종적인 학습 loss를 만들어냅니다.
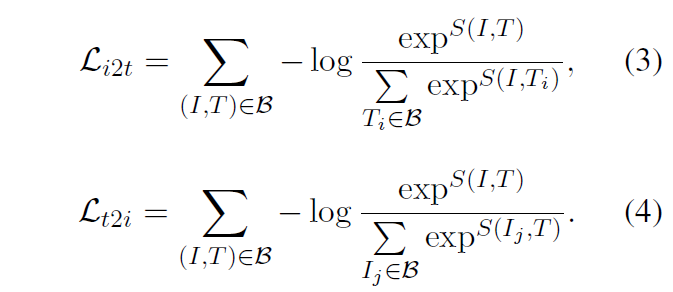
Formulation
CAE 프레임워크의 목적은 단순한 Object에만 집중하는 CLIP 모델이 그 사이사이 존재하는 Attribution에도 집중할 수 있도록 만들어주는 것입니다. 이를 위해 문장 내 각 단어가 Object인지 Attribution인지를 먼저 알아둬야 학습하겠죠. 별다른 학습 모듈을 통해 둘을 분류하는 것은 아니고, 기존 학계에 존재하는 scene graph parser를 통해 문장 내 단어가 Object인지 Attribution인지 파악할 수 있습니다. 이 scene graph parser는 학습 때만 사용되고, 학습을 마친 이미지 인코더와 텍스트 인코더는 기존 CLIP과 동일하게 downstream task에서 활용됩니다.
텍스트 캡션 T 내에 존재하는 각 토큰(=단어) T_{i}의 attribution score a_{i}를 측정합니다. 이 a_{i}는 추후 말씀드릴 4가지 방식으로 추출되는데, 모델의 attention score 기반, Grad-CAM 기반, gradient 기반, perturbation 기반이 해당하며 자세히는 아래에서 또 설명드리겠습니다. 어떤 방식으로든 토큰의 attribution score a_{i}가 크다면 최종적인 task를 수행하는 데에 있어 높은 영향력을 가진다고 해석해볼 수 있습니다.
여러 방식으로 각 토큰의 attribution score a_{i}를 추출했다면 앞서 scene graph parser를 통해 현재 토큰 T_{i}가 Object인지 Attribution인지 알 수 있었습니다. 그렇다면 문장 T_{i} 내 존재하는 Object들의 a_{i}들을 평균 내어 a_{obj}^{i}를, Composition들의 a_{i}들을 평균내어 a_{comp}^{i}를 얻을 수 있습니다. 이를 전체 배치에 대해 쭉 구해주면, 전체 배치 사이즈를 n이라 했을 때 A_{obj} = [a_{obj}^{0}, \cdots{}, a_{obj}^{n-1}], A_{comp} = [a_{comp}^{0}, \cdots{}, a_{comp}^{n-1}] 또한 얻을 수 있습니다.
기본적인 Contrastive loss에 추가로, CAE 프레임워크에선 방금 추출한 score를 활용해 아래 수식 (5)와 같은 \mathcal{L}_{Attr}을 적용합니다. Triplet loss와 같이 구성되어 결국 Composition 단어에 대한 모델의 집중도가 Object와 유사해지거나 그 이상으로 만들어주는 역할을 수행합니다. 우선 모든 실험에서 \epsilon{} = 0으로 설정하여 최소한 두 score가 같아지도록 학습해줬다고 합니다. 아래 \mathcal{L}_{Attr}는 기존 CLIP의 Contrastive loss에 더해져 같이 학습됩니다.
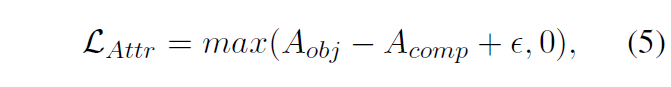
그럼 이제 각 단어의 attribution score a_{i}를 추출하는 4가지 방법에 대해 각각 알아보겠습니다.
2.1 Attention-Based Attribution
CLIP의 text encoder도 일반적인 Transformer 구조이기에, 여러 개의 layer와 head로 이루어져 있습니다. 먼저 문장의 [CLS] 토큰을 뗀 뒤 각 layer의 여러 head에서 얻은 attention score를 평균 내어주고, 다시 여러 layer에 대해 score를 또 평균 내어 최종적인 a_{i}를 얻을 수 있습니다. 이 score를 가지고 위 수식 (5)의 loss를 계산해주는 것입니다. 모델의 attention score를 보는 것이 가장 직관적이고 간단하게 적용해볼 수 있는 방법일 것입니다.
2.2 GradCAM-Based Attribution
여기선 a_{i}를 구하기 위해 기존 방법론을 따라 GradCAM의 개념을 가져옵니다. 최종적으로 구할 수 있는 이미지와 텍스트의 유사도 S(I, T)로부터 각 토큰의 gradient를 활용합니다. 먼저 shape은 텍스트 인코더 각 layer의 attention map과 유사하며 값은 Identity matrix로 초기화된 text attribution map R을 만들어줍니다. 이후 아래 수식을 따라 attention weight의 gradient 값을 계산해줍니다.
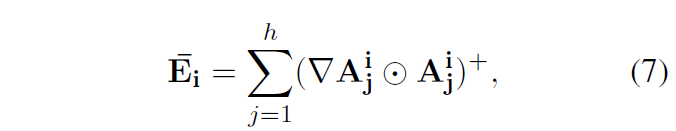
위 수식에서 \bar{E}_{i}는 각 i번째 layer의 explainability map이며 A_{j}^{i}는 positive 쌍에 대한 j번째 head에서의 attention matrix를 의미합니다. \triangledown{}A_{j}^{i}는 positive 쌍의 유사도에 대한 각 attention weight의 gradient를 의미합니다. 이 둘을 아다마르 곱 연산하여 모든 head에 대한 평균 내어 현재 layer의 \bar{E}_{i} 만들어 주는 것입니다.
이후 아까 초기화했던 R에 각 layer별 \bar{E}_{i}를 아래 수식 (8)과 같이 aggregate 해줍니다.
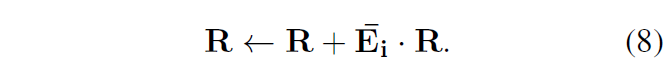
최종적으로는 이 R의 각 행에는 단어별 원소가 존재하는데, 이를 각 토큰의 score로 정의하게 됩니다.
2.3 Perturbation-Based Attribution
Perturbation이라는 단어가 생소하여 검색해봤더니 ‘섭동’이라는 뜻이 나오는데, 설명을 읽을수록 더 이해가 안되어 우선 구체적 방식에 대해 설명드리겠습니다. 이상적으로 학습중인 모델의 경우, 한 이미지에 대해 상응하는 positive 캡션과, 그 캡션을 임의로 변형한 캡션이 들어오면 전자는 유사도가 높아야 하고 후자는 낮아야 할 것입니다. Perturbation 기반의 방식은 이 점을 이용해 상응 캡션 내 단어의 중요도를 파악합니다.
상응 캡션 내의 Object, Relation, Attribution 토큰을 데이터셋 내에 추려져있는 의미가 전혀 다른 토큰으로 변형해줍니다. 이 과정을 위해 우선 문장에서 “of”, “which”와 같이 큰 의미가 없는 단어는 변형 대상에 포함하지 않았고, 변형 시 “on”->”above”처럼 유사한 의미의 단어로 변형되는 경우를 방지해줬다고 합니다.
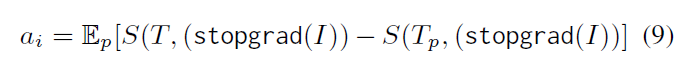
변형된 캡션을 T_{p}라고 했을 때, 원본 캡션과의 유사도 대비 변형된 캡션과의 유사도가 얼마나 떨어지느냐를 기준으로 각 토큰의 attribution score를 계산할 수 있습니다. 수식 (9)에서 \mathbb{E}_{p}는 여러 번의 perturbation에 대한 drop 수치를 평균내는 연산을 의미합니다. Object를 변형하고 유사도 drop을 구하면 그게 곧 a_{obj}가 되고, Relation과 Attribution도 마찬가지로 계산해줄 수 있습니다.
2.4 Gradient-Based Attribution
마지막은 Gradient-Based 방식입니다. 앞서 GradCAM 방식에선 이미지-텍스트 유사도에 대한 attention score의 gradient를 활용했다면 여기선 유사도에 대한 텍스트 토큰의 gradient를 그대로 사용합니다. 이는 아래 수식 (10)과 같습니다.
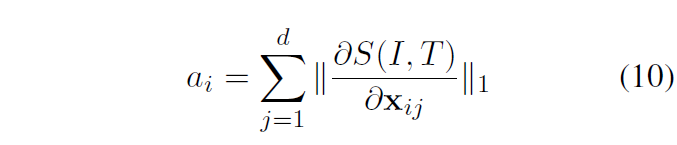
구한 gradient에 softmax를 태워 normalize해주고 최종적으로 활용합니다.
여기까지 설명드린 4가지 방식으로 attribution score를 구하고, 이를 활용해 Object에만 집중하는 것이 아닌 relation이나 attribute에도 집중할 수 있는 모델을 만들어줄 수 있었습니다.
3. Experiments
위 CAE 프레임워크로의 사전학습은 MSCOCO에 대해 진행되었습니다. 학계 데이터셋 중 noise가 적은 편이며 영상에 많은 콘텐츠를 포함하고 있어 선택했다고 합니다. 사전학습을 마쳤으면 ARO, Sugar-Crepe, VL-Checklist, Winoground, VALSE, SVO-Probes 등의 데이터셋에 대해 fine-tuning을 진행하고 평가하였다고 합니다. 사실 하나 빼고는 전부 처음보는 데이터셋이라 생소했지만, 결국 이미지 내 존재하는 Object의 relation, attribution을 분류 형태로 맞추는 정확도를 측정한다고 보시면 됩니다.
3.1 Main Results
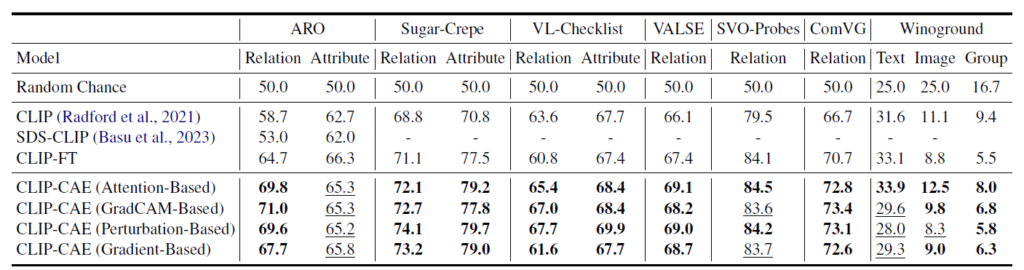
표 1은 메인 벤치마크 결과를 보여주고 있습니다. 베이스라인 방법론으로는 CLIP과 CLIP-FT가 있는데, 이 중 CLIP-FT가 저자들의 CAE 프레임워크 적용 없이 COCO 데이터셋으로 fine-tuning한 경우를 의미합니다. CAE의 직접적인 효과를 알아보기 위해서는 CLIP-FT와 CLIP-CAE를 비교하는 것이 가장 적절합니다.
우선 대부분 데이터셋에 대해 CLIP-FT보다 높은 성능을 보여주고있습니다. 특히 Out-of-distribution 상황을 다루는 Winoground에서 기존보다 많이 향상된 성능을 보여주고 있습니다. 밑줄 친 성능들이 CLIP-FT에 비해 하락한 것인데, 특히 ARO 데이터셋의 Attribute 성능이 CLIP-FT보다 전반적으로 떨어진 것을 볼 수 있습니다. 저자들이 이에 대해 정성적 결과를 직접 살펴봤는데, 실제 캡션을 이미지에 대응시키기 꽤 모호한 경우가 많았다고 합니다. ARO의 Attribute 성능 하락은 hard negative를 쓰는 기존 방법론들에서도 나타나는 경향이라 우리도 동일하게 나왔다고 이야기하고 있습니다.
사실 방법론의 대부분이 4가지 score 생성 방식에 대한 설명이라 이에 대한 성능 추이를 좀 설명해주었으면 좋았을 것 같은데, 딱히 분석은 없었습니다. 개인적으로는 Perturbation 기반 방식에 대해 사실 모델이 relation과 attribute에 집중하고 각각을 이해할 수 있어야 유효하게 동작하지 않을까 하는 걱정이 있었는데, 어느정도 잘 동작하고 있는 모습을 볼 수 있습니다.
3.2 Results on Downstream Retrieval Tasks
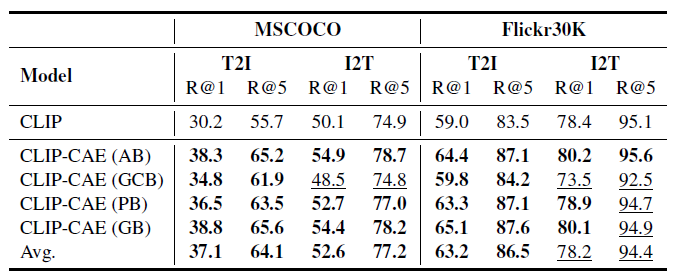
위 표 2는 Image-Text Retrieval task에 대한 전이 성능입니다. MSCOCO와 Flickr30K 데이터셋에 대해 실험을 진행하였으며 평균적으로 CLIP보다 성능 향상이 많이 이루어졌음을 알 수 있었습니다. 다만 기존의 다른 방법론들과 비교를 같이 해줬으면 좋았을 것 같은데 표에는 바닐라 CLIP만이 있네요. 그래도 Moment Retrieval을 비롯한 많은 task에서 바닐라 CLIP으로부터 feature를 추출해 사용한다는 점을 생각해보면 얻어갈 점은 많은 것 같습니다.
3.3 Relationship between Attribution Score and Performance
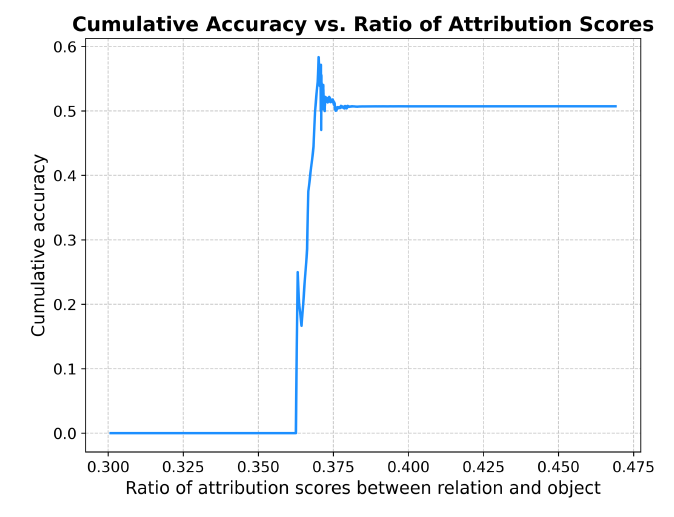
그림 3은 과연 모델이 attribution에 집중함에 따라 정확도가 오르는지 알아보기 위한 실험 결과입니다. 가로 축은 Object score에 대한 Relation score의 비율로, 클 수록 Relation score 또한 크다고 보시면 됩니다. 세로 축은 가로 축의 비율값 미만(cumulative)을 갖는 샘플들의 평균 정확도에 해당합니다. 0.36~0.38의 ratio 범위 내 대부분의 샘플이 포함된다고 하는데, 그림 4의 이 구간에서 정확도가 크게 증가하고 있는 모습을 볼 수 있습니다. 이를 통해 모델이 attribution에 집중할수록 더 높은 정확도를 보여준다는 점을 알 수 있습니다.
3.4 Ablation Study
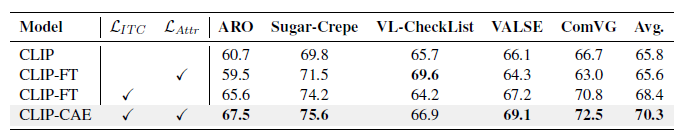
마지막으로 ablation 성능을 보고 마치도록 하겠습니다. 우선 Image-Text Contrastive loss가 아예 없으면 모델의 성능이 많이 떨어지는 것을 볼 수 있습니다. 기본적인 global-level에서의 학습은 필요하다고 볼 수 있지만, 이 상황에서 저자가 강조하는 attribution score까지 함께 고려한다면 더욱 높은 성능을 달성할 수 있다고 이야기하고 있습니다. 사실 모든 실험에서 그랬지만 데이터셋마다 경향성이 너무 다르게 나와 명확한 분석을 하기 어려운 상황이네요.
4. Conclusion
마지막 실험 부분에서 데이터셋마다 경향이 많이 달라 분석이 쉽지 않았지만, 바닐라 CLIP 모델이 캡션의 fine-grained한 정보를 읽지 못한다는 것은 분명한 문제점이라고 생각합니다. Video Moment Retrieval에선 문장 Feature를 뽑아 두고 쓰기에 fair comparison을 위해 백본을 바꿀 순 없겠지만, Object 뿐만 아니라 그들의 특성 및 그들간의 관계가 굉장히 중요한 task이기에 동일한 문제가 존재하는지 살펴볼 필요가 있을 것 같습니다.
리뷰 마치겠습니다. 감사합니다.
안녕하세요 현우님 좋은 리뷰 감사합니다.
저도 perurbation이 무슨 뜻인가 궁금해서 찾아봤는데 머신(딥)러닝에서 사용되는 perturbation은 작은 차이를 의미한다고 합니다. 실제 relation과 의미가 다른 relation간의 차이를 저자가 perturbation이라고 표현한 것 같습니다. CAE가 이미지 내 객체가 주어인지, 목적어인지, relation인지를 구분하는 것을 scene graph parser에 의존하고 있는데 scene graph parser를 통해 pseudo-label을 생성해 학습하는 건가요? 추가로 scene graph parser에 대한 ablation은 없는지 궁금합니다.
감사합니다.
안녕하세요, 답변이 늦어져 죄송합니다.
scene graph parser를 통해 pseudo-label을 생성해 학습하는 건가요?
-> 맞습니다.
추가로 scene graph parser에 대한 ablation은 없는지 궁금합니다.
-> 이에 대한 실험은 따로 없는데, 개인적으로는 scene graph parser가 주어-서술어-동사의 관계를 분류하는 데에 큰 어려움이 없어 모델 전체 성능에 영향을 주지 않을 것 같습니다. 그래서 별다른 추가 실험은 하지 않은 것으로 보입니다.