이번에 소개할 논문은 CLIP 모델을 대규모 비디오 데이터로 post-pretraining하여 비디오-텍스트 작업에서 성능을 향상시키는 방법을 제안한 논문입니다. 먼저, 기존 CLIP 모델을 비디오 데이터로 학습할 때 발생하는 한계와 문제점을 분석하고, 이를 해결하기 위해 CLIP-ViP라는 새로운 접근법을 제안합니다. 그러면 바로 리뷰 시작하겠습니다.
1. Introduction
비전-언어 사전 학습 모델은 대규모 웹 크롤링 데이터에서의 크로스 모달 표현 학습을 통해 좋은 모습을 보이고 있습니다. 그중 이미지-텍스트 사전 학습 모델은 다양한 downstream 태스크에서 좋은 능력을 보여주었습니다. 잘 학습된 시각적 표현을 바탕으로, 일부 연구는 비디오 데이터에 대한 추가 사전 학습 없이 직접 이미지-텍스트 사전 학습 모델을 비디오-텍스트 downstream 태스크에 적응시키고 있습니다. 기존의 이미지-텍스트 사전 학습 모델을 활용하여 비디오-텍스트의 post-pretraining을 수행하는 것은 이미지로부터 학습된 지식을 잘 활용함으로써 필요한 훈련 비용을 줄일 수 있습니다. 그러나 이미지-텍스트 사전 학습 모델을 비디오-텍스트 데이터에 적응시키는 것은 아직까지 눈에 띄는 이점을 보여주지 못하고 있으며, 당시 해당 분야의 연구가 많이 진행되지 않았다고 합니다.
이 논문은 비디오-텍스트 태스크을 위한 비디오-언어 표현 학습에 CLIP과 같은 이미 학습된 이미지-텍스트 모델을 어떻게 효과적으로 조정할 수 있는지를 연구한 논문입니다. 비디오 데이터를 활용하여 post-pretraining에 적합한 이미지-텍스트 사전 학습 모델을 조정하기 위해, 사전 실험을 수행하고 post-pretraining을 방해하는 요소를 파악합니다.
이 방해요소를 찾기 위해 저자는 두가지 실험을 진행합니다.
첫째, 저자는 WebVid-2.5M 및 HD-VILA-100M과 같은 여러 규모의 비디오-텍스트 데이터셋에서 평균 풀링을 사용하여 이미지-텍스트 사전 학습 모델의 post-pretraining을 분석합니다.. 결과는 데이터의 규모가 비디오-텍스트 post-pretraining에 Critical 하다는 것을 보여줍니다. 작은 규모의 데이터는 모델이 새로운 데이터에 쉽게 과적합되도록 하여 학습된 지식이 억제되고 성능이 감소하는 모습을 보입니다.
둘째, 저자는 post-pretraining 데이터와 다운스트림 데이터 간의 언어 도메인 갭을 분석합니다. 이는 텍스트 피처의 클러스터에서 Normalized Mutual Information(NMI)를 계산함으로써, 대규모 비디오-텍스트 post-pretraining 데이터에서 사용되는 subtitles 과 다운스트림 태스크의 description간에 도메인 간극이 존재함을 발견합니다.
위의 요인들의 영향을 완화하기 위해, 저자는 비디오-텍스트 pretraining을 위해 사전 학습된 이미지-텍스트 모델 CLIP을 조정하는 CLIP-ViP를 제안합니다. 먼저, 다운스트림 데이터와 도메인 갭이 적은 보조 캡션을 기존의 대규모 비디오-텍스트 데이터에 도입합니다. 보조 캡션의 생성은 각 비디오의 중간 프레임을 사용해서 캡션을 생성하고 이를 위해 이미지 캡셔닝 모델을 사용합니다.
CLIP-ViP은 이미지와 비디오를 모두 처리할 수 있도록 Transformer 기반 비전 인코더를 학습시키기 위해, video proxy tokens과 ViT를 위한 proxy-guided video attention mechanism을 설계합니다. 또한 저자는 캡션-프레임 , 비디오-자막 데이터의 cross-modal representation learning 을 동시에 하기 위해, Omnisource Cross-modal Learning(OCL) 방법을 제안합니다.
따라서 저자의 contributions는 다음과 같이 정리할 수 있습니다.
(1) 저자는 사전 학습된 이미지-텍스트 모델에서 비디오 post-pretraining을 방해하는 요소를 분석한 최초의 연구 중 하나
(2) 저자는 사전 학습된 이미지-텍스트 모델을 post-pretraining에 효과적으로 활용할 수 있는 CLIP-ViP를 제안함
(3) 저자는 저자의 방법의 효과를 검증하기 위해 다양한 실험을 수행하고 네 가지 벤치마크에서 sota를 달성함.
2. PRELIMINARY ANALYSIS
그럼 먼저 image-text pre-training을 video-text post-pretraining에 적용시키기 어려운 이유를 파악하기 위한 실험을 살펴보겠습니다.
2.1 POST-PRETRAINING WITH DIFFERENT DATA SCALES
이 실험을 위해 CLIP-ViT-B/32 모델을 이미지-텍스트 사전 훈련 모델로 사용하고, 비디오의 피처를 추출하기 위해 평균 풀링을 사용하여 여러 프레임 특징을 평균내어 비디오 특징으로 사용합니다. 데이터셋은 WebVid-2.5M과 HD-VILA-100M, HD-VILA-10M을 사용하고, post-pretraining을 하는 동안 MSR-VTT text-to-video retrieval task에서 사전 훈련된 모델을 파인튜닝하여 평가합니다.

결과는 그림 1에 나와있습니다. 그래프를 보면 지속적인 post-pretraining이 성능 저하로 이어지는 과적합 현상을 관찰합니다. 이는 WebVid-2.5M, HD-VILA-10M와 같이 데이터 규모가 작은 경우에 더욱 두드러집니다. CLIP은 4억 개의 이미지-텍스트 쌍으로 사전 훈련되었기 때문에, 작은 데이터에 대한 추가 훈련은 모델이 새로운 데이터에 과적합하는 경향을 갖게 하며, 이미지-텍스트 쌍에서 얻은 지식을 잃어버리는 모습을 보입니다. 그 결과 성능이 저하되고, 사전학습된 CLIP을 직접 사용하는 것보다 나빠질 수 있습니다. 따라서 저자는 대규모의 다양한 범주를 가진 HD-VILA-100M을 post-pretraining으로 선택합니다.
2.2 LANGUAGE DOMAIN GAP WITH DOWNSTREAM DATA
같은 도메인에서 데이터에 대한 사전 훈련이 다운스트림 태스크에 유익하다는 것은 직관적입니다.
video-text retrieval과 같은 대부분의 비디오-텍스트 태스크에서는 텍스트가 비디오에 대한 설명 문장입니다. 그러나 HD-VILA-100M에서는 텍스트가 자동 생성된 자막으로, 이는 비디오의 시각 정보와의 관련성이 매우 다릅니다. 따라서 사전 훈련 데이터와 다운스트림 데이터 간의 language domain gap을 분석하기 위해 피처 간의 유사성을 계산하여 불일치를 측정합니다.
다운스트림 데이터의 경우 MSR-VTT와 DiDeMo를 사용합니다.
사전 학습의 경우, HD-VILA-100M의 비디오 자막, WebVid-2.5M의 비디오 캡션, MS-COCO의 이미지 캡션, 그리고 Conceptual Caption 12M의 웹 수집 대체 텍스트의 네 가지 유형을 선택합니다.
과정은 다음과 같습니다. 먼저 CLIP의 Transformer Encoder를 사용하여 사전 학습 데이터와 다운스트림 데이터 간의 텍스트 피처를 추출합니다. 이후 텍스트 피처를 혼합한 다음 K-means을 사용하여 두 개의 클러스터를 생성합니다. 그런 다음, 클러스터된 피처가 어떤 그룹에서 왔는지 사전 학습, 다운스트림의 실제 레이블 간의 비교로 Normalized Mutual Information(NMI)을 계산합니다. NMI 값이 클수록 두 유형의 특징이 구별되기 쉽다는 것이고 이는 도메인 차이가 더 크다는 것을 의미합니다. 각 비교는 먼저 각 데이터 유형에서 1000개의 텍스트를 무작위로 샘플링하고 10회 반복하여 10개의 결과의 평균 냅니다. 결과는 표 1에 나와있습니다.

사전 학습 데이터 유형의 값을 비교한 결과, HD-VILAsub와 다운스트림 데이터 간의 NMI 점수가 다른 데이터보다 훨씬 크며, 특히 MSR-VTT 다운스트림 데이터셋에 대해 그러합니다. 이는 subtitles으로 직접 훈련하는 것이 다운스트림 태스크에서 성능 저하를 일으킬 수 있음을 나타냅니다.
3. Method
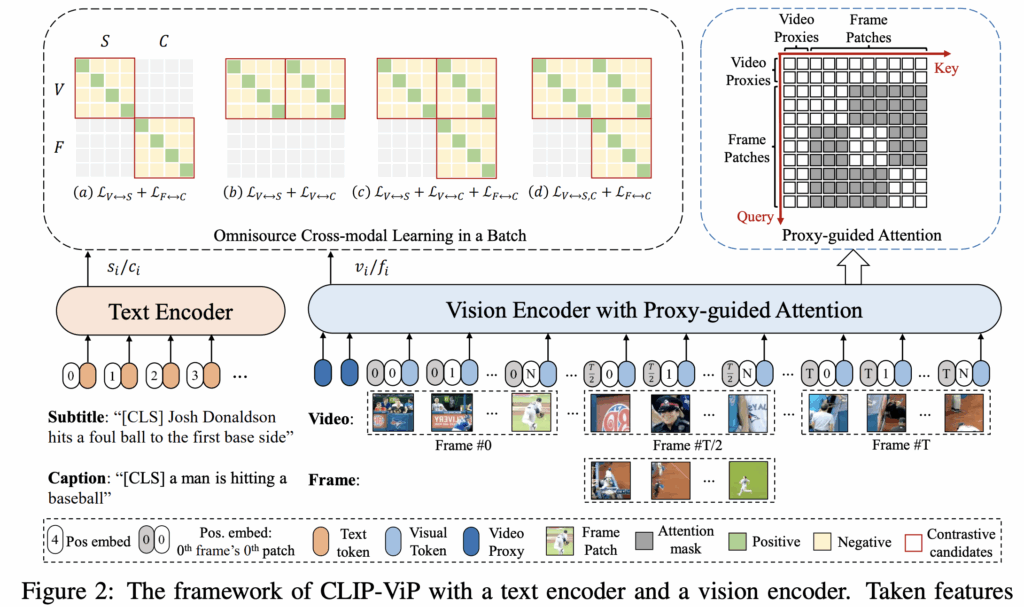
이 섹션에서는 CLIP-ViP video pre-training framework를 소개합니다. 먼저 이미지와 비디오 데이터셋 간의 domain gap을 해결하기 위한 auxiliary data 생성과 ViT가 이미지와 비디오 모두를 인코딩할 수 있도록 하는 Video Proxy 메커니즘, 비디오-텍스트와 이미지-텍스트 데이터로부터 cross-modal representation을 함께 학습할 수 있는 Cross-modal Learning (OCL) 방법을 포함한 프레임워크입니다.
3.1 IN-DOMAIN AUXILIARY DATA GENERATION
이전 실험 분석의 결과를 통해 저자는 도메인 격차를 줄이기 위한 auxiliary captions을 도입합니다. 저자는 캡션을 생성하기위해 비디오 캡셔닝 모델이 아닌 이미지 캡셔닝 모델을 선택합니다. 이유는 두 가지입니다.
1) 대부분의 SOTA 비디오 캡셔닝 모델은 비디오-텍스트 데이터셋( ex) MSR-VTT, ActivityNet)으로 훈련되며, 이는 다운스트림 태스크에도 사용됩니다. 저자는 다운스트림 데이터와 무관한 사전 훈련을 위해 이미지 캡셔닝 모델을 선택합니다
2) 기존 비디오 캡셔닝 모델의 성능은 이미지 모델보다 훨씬 낮습니다. 따라서 저자는 HD-VILA-100M의 각 비디오 중간 프레임에 대한 하나의 캡션을 생성하기 위해 이미지 캡셔닝 모델인 OFA-Caption을 사용합니다.
3.2 VIDEO PROXY MECHANISM
비디오는 프레임의 순차적인 배열로 이루어져 있으므로 프레임의 집합과 시간성(temporality) 을 학습하는 것이 중요합니다. 또한 Vision Transformer(ViT) 백본의 일반성과 확장성을 유지하기 위해, 저자는 최소한의 수정을 통해 이미지를 인코딩하고 비디오를 인코딩할 수 있는 방법을 제안합니다.
T 프레임을 포함하는 비디오가 주어지면: {f1, f2, …, fT }, 저자는 CLIP을 따라서 각 프레임을 N개의 패치로 나눕니다: {f1t,f2t,⋯,fNt|t∈[1,T]}. 그 다음, 각 flattened 2D 패치에 시공간 위치 임베딩을 추가합니다:

여기서 Linear()는 선형 레이어이고, Pos_s(n), Pos_t(t)는 각각 학습 가능한 spatial, temporal positional embedding입니다. 한 영상의 비디오는 T × N 크기의 패치 토큰으로 나눠집니다.
다중 프레임으로부터 공간 정보를 모델링하기 위한 한 가지 간단한 방법은 모든 토큰을 CLIP의 비전 인코더에 직접 입력하고 모든 토큰 간 attention across를 수행하는 것입니다. 그러나 이 방법은 이미지와 텍스트 쌍으로 사전 훈련된 CLIP에게는 좋은 방법이 아니라고 합니다. 대신, 저자는 각 로컬 패치가 비디오 level의 시간 정보를 인식하도록 도와주는 비디오 Proxy 토큰을 도입합니다.
CLIP에 입력하기 전에, 저자는 패치 토큰을 비디오 Proxy 토큰이라는 학습 가능한 파라미터와 연결합니다: P = {p_1, p_2, …, p_M}, 여기서 M은 비디오 Proxy 토큰의 수입니다. 그런 다음 모든 T x N + M의 토큰이 CLIP의 ViT에 입력됩니다. 이때 첫 번째 비디오 프록시 토큰의 출력은 비디오의 표현으로 간주합니다.
저자는 또한 일반적인 ViT에 대한 proxy-guided attention mechanism을 설계합니다. ViT에서는 기본적으로 어텐션을 사용하여 토큰 간 관계를 학습합니다. proxy-guided attention mechanism는 비디오 프록시 토큰과 패치 토큰이 다르게 어텐션을 계산하도록 설계합니다. 비디오 프록시 토큰의 경우 모든 토큰에 어텐션을 사용하여 비디오 전체의 사간적 정보를 통합하고, 패치 토큰은 같은 프레임의 패치 토큰들과 비디오 프록시 토큰만 참조합니다. 이 메커니즘은 attention 마스크M_{ViP}로 표현됩니다:
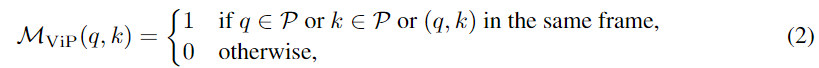
여기서 q와 k는 어텐션 계산에서의 키와 쿼리입니다. 패치 토큰은 비디오 프록시 토큰을 참조함으로써 글로벌 정보를 얻을 수 있고 CLIP의 계산 구조를 유지하기 때문에 계산의 불일치를 줄일 수 있습니다.
입력으로 이미지/프레임이 들어왔을때 이를 linear interpolation을 사용하여 middle temporal positional embedding을 얻습니다. 또한 입력으로 들어온 이미지/프레임을 하나의 프레임 비디오로 간주하게 됩니다. 이러한 방법은 비디오와 이미지를 같은 배치에서 학습 가능하도록 만들어주고 proxy-guided attention에서 계산 차이를 줄일 수 있는 특징을 가집니다.
3.3 OMNISOURCE CROSS-MODAL LEARNING
비디오-자막 쌍의 alignment를 학습하고, 상응하는 프레임-캡션 쌍과의 도메인 갭을 줄이기 위해, omnisource 입력에 대한 joint Cross-Modal Learning을 연구합니다. 대부분의 이중 인코더를 학습하는 방법들과 비슷하게 저자 또한 info-NCE loss를 이용한 contrastive learning을 진행합니다. 이때 학습 데이터에는 두 가지 형태의 visual source: 비디오 시퀀스와 단일 프레임, 그리고 두 가지 유형의 text source: 자막과 캡션이 있습니다. 이를 각각 V, F, S, C로 나타낼때 info-NCE loss는 다음과 같이 표현됩니다.
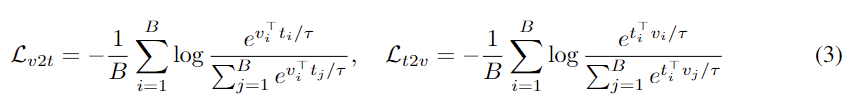
여기서 v_i와 t_j는 각각 배치 크기 B에서 X ∈ {V, F} 의 i번째 시각적 피처 Y ∈ {S, C}의 j번째 텍스트 피처의 정규화된 임베딩입니다. 전체 손실 LX↔Y는 L_{v2t}와 L_{t2v}의 평균으로 구해집니다.
저자는 또한 OCL의 여러 변형을 연구합니다
(a) LV ↔S + LF ↔C: 비디오-자막과 프레임-캡션 쌍에 대한 손실 조합
(b)LV ↔S +LV ↔C : 비디오-자막과 비디오-캡션 쌍에 대한 손실 조합
(c) LV ↔S + LV ↔C + LF ↔C : (a)와 (c)의 조합
(d) LV ↔S,C +LF ↔C : 하나의 비디오와 자막,캡션 + 프레임-캡션 쌍에 대한 손실 조합
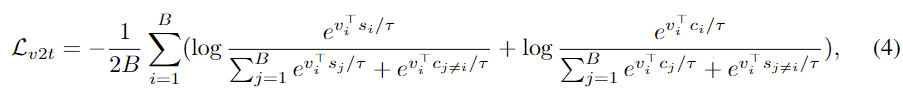
si ∈ S, ci ∈ C인 경우. LV ↔S,C에서의 Lt2v는 (c)와 같습니다. 모든 변형들은 베이스라인 LV ↔S와 비교하고 결과를 리포팅합니다.
4. EXPERIMENT
4.1 EXPERIMENTAL DETAILS
Fine-tuning Training : CLIP-ViP를 다운스트림 테스크에 사용하기 위해, 파인 튜닝 시 post-pretraining의 대부분의 하이퍼파라미터를 재사용합니다. CLIP-ViP 모델은 모든 다운스트림 테스크에 대해 배치 크기 128로 설정되었고 learning rate와 weight decay는 각 값을 각각 1e-6과 0.2로 설정합니다. MSR-VTT, DiDeMo, LSMDC, ActivityNet의 데이터셋에 대해 에포크 수는 각각 5, 20, 10, 20으로 설정합니다. 그리고 ActivityNet Captions를 제외하고 프레임 수를 12로 설정하여 Fine-tuning을 진행합니다.
4.2 ABLATION STUDIES
Video Proxy Mechanism : 이 실험에서는 비전 인코더에 대한 Video Proxy(ViP) 메커니즘을 평가합니다. ViP를 다른 수의 프록시로도 평가하고 MeanPool, SeqTransformer, Full Attention과 같은 다른 모델 구조와도 비교합니다. MeanPool은 프레임 특징의 평균을 구해 전체 비디오의 피처를 뽑는 방식입니다. SeqTransformer은 CLIP4Clip의 seqTransf와 CLIP4Clip에서의 residual connection을 따릅니다. Full Attention은 모든 패치 토큰을 비전 인코더의 입력으로 사용하며 모든 토큰에 걸쳐 attention 이 이루어집니다.
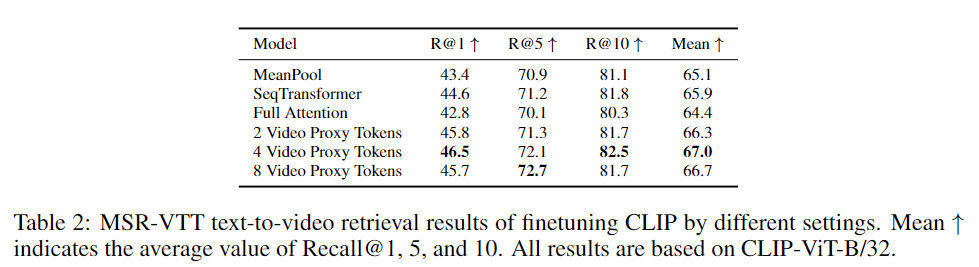
결과는 표 2에 나타나 있습니다. 시간적 정보를 무시하는 MeanPool과 비교할 때, SeqTransformer는 평균 Recall@1, 5, 10 값에서 개선된 모습을 보입니다. Full Attention은 성능이 저하되었으며 저자는 실험 중 초기 상태가 더 나쁘고 수렴 속도가 다른 설정보다 느리다는 것을 관찰했다고 합니다. 이는 모든 패치의 Attention 계산을 위해 CLIP을 직접 사용하는 것이 CLIP의 이점을 감소시킨다는 저자 분석과 일치하는 결과입니다.
서로 다른 수의 비디오 프록시 토큰은 모두 R@1에서 성능 향상을 보여줍니다. 다른 셋팅과 비교했을 때, 모든 설정에서 저자의 방법이 가장 큰 개선을 보여 주며 이는 저자가 제안한 비디오 프록시 메커니즘이 비디오-텍스트 사전 훈련 모델을 효과적으로 활용할 수 있음을 나타냅니다.
Omnisource Cross-modal Learning
저자는 비용이 많이 드는 훈련 때문에 각 손실 함수로 모델을 단 한 번의 에폭만큼 사전 훈련한 후, 두 개의 비디오-텍스트 검색 데이터셋인 MSR-VTT와 DiDeMo에서 파인튜닝 합니다. 결과는 제안된 비디오 프록시 메커니즘(CLIP-ViP)을 사용하여 CLIP-MeanPool 및 CLIP와 비교합니다.
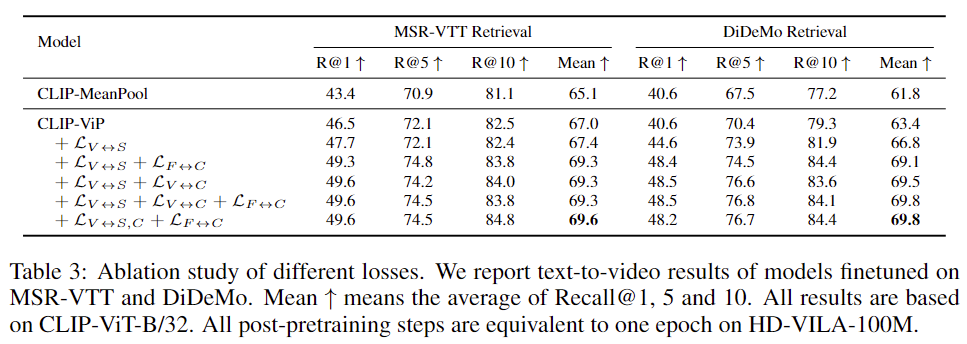
결과는 표 3에 나와있습니다. MSR-VTT 데이터셋에서 저자는 LV ↔S가 평균 Recall@1, 5, 10에서 0.4%의 작은 개선을 가져온다는 것을 발견했습니다. 이는 MSR-VTT와 post-pretraining 데이터 간의 큰 도메인 차이 때문입니다. 캡션과 결합할 경우, OCL 손실의 네 가지 변형 모두 상당한 개선을 가져옵니다. DiDeMo 데이터셋에서는 LV ↔S가 가져온 개선을 기반으로 OCL이 결과를 큰 폭으로 개선합니다. 마지막으로, LV ↔S,C +LF ↔C가 가장 잘 수행되며, 이는 저자의 최종 셋팅으로 적용됩니다.
4.3 COMPARISON TO STATE-OF-THE-ART MODELS
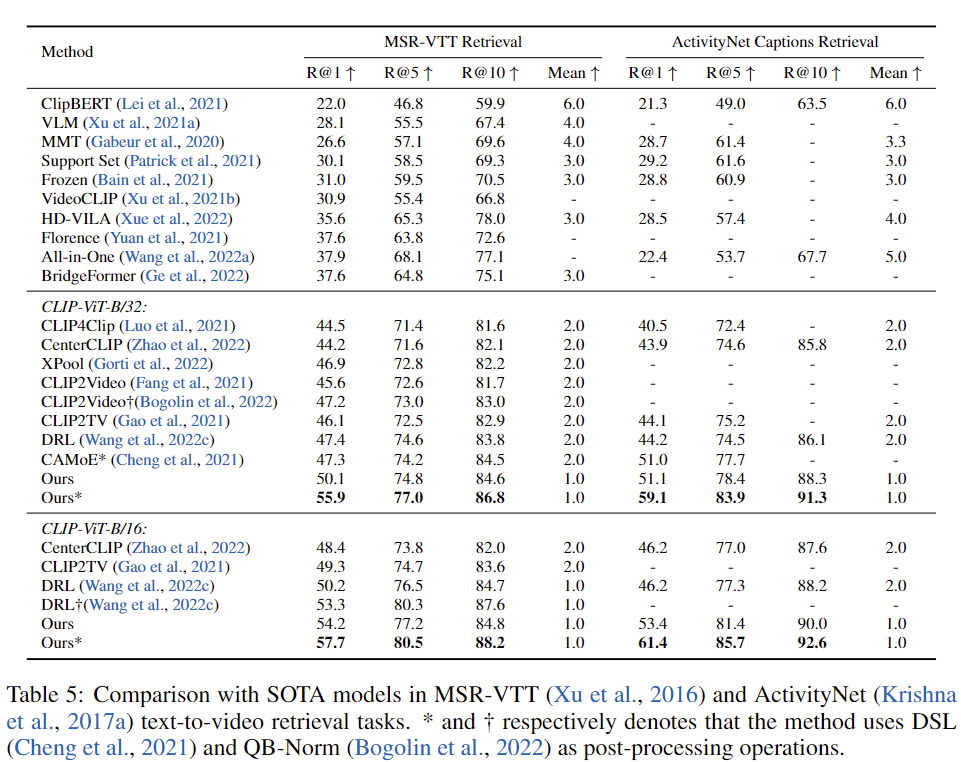
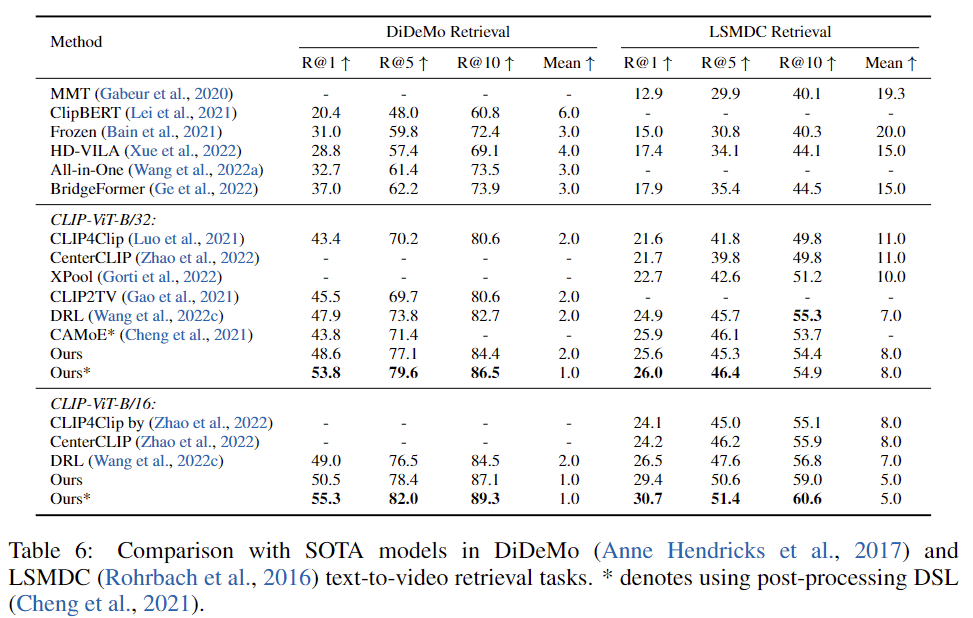
저자는 text-to-video retrieval task에서 다른 모델과 비교합니다. 네 개의 데이터셋( MSR-VTT, DiDeMo, ActivityNet Captions, LSMDC)에 대한 파인튜닝 결과는 표 5와 6에 나타나 있습니다. 저자의 모델은 CLIP-ViT-B/32 및 CLIP-ViT-B/16의 모든 데이터셋에서 가장 좋은 성능을 보여주고 있습니다. 기존 방법은 CLIP 모델을 많이 수정하거나 새로운 구조를 추가해야 적용할 수 있는 경우가 많습니다. 하지만 저자의 모델은 CLIP 모델에 거의 변화를 주지 않았기 때문에, CLIP을 기반으로 설계된 기존 방법에도 쉽게 이 모델 위에 적용할 수 있습니다. 또한 DSL 같은 후처리 작업이 없어도, 저자의 모델은 대부분의 데이터셋에서 이미 후처리를 사용하는 기존 방법보다 더 나은 성능을 보여줍니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
먼저 omnisource가 모든 모달리티 소스를 얘기하는건가요? 맥락상 여러가지 모달리티를 말하는 것 같은데 omnisource라는 단어를 처음보아서 정확한 의미가 무엇인지 궁금합니다. 추가로 Table 3에서 데이터 간의 큰 도메인 차이로 인해서 적은 개선이 있었다고 하는데 그부분이 잘 이해가 안되서 한번만 다시 설명해주실 수 있나요?
감사합니다.