안녕하세요. 오늘 제가 리뷰할 논문은 아직 아카이브에만 등재된 논문이지만, 제목을 보고 궁금증이 생겨서 읽게된 LLaVA-MR입니다. 올해 하반기부터해서 Video Moment Retrieval(VMR) task에서도 사전학습된 foundation 모델을 활용하는 연구들이 늘어나고 있는데 이번에는 LLaVA를 활용하여 VMR을 수행한 연구가 있어서 리뷰하게 되었습니다.
Introduction
최근 NLP 분야에서 LLM의 성과가 보이기 시작하면서 LLM을 자연어 분야가 아닌 비전에서도 활용하려는 연구들이 많이 등장했습니다. Multimodal Large Language Model (MLLM)은 LLM을 자연어뿐만 아니라 다른 모달리티에서도 활용할 수 있도록 확장하여 image-text, 나아가 video-text에서도 활용할 수 있어 MLLM에 대한 관심이 늘어나고 있습니다. 하지만, MLLM은 limited context size(본문에서는 긴 영상에 대응하지 못한다는 것을 의미함)와 coarse frame extraction으로 인해 정확한 구간 검색(precise moment retrieval)에는 좋은 효과를 보지 못하고 있었음을 지적합니다. 따라서 저자는 MLLM의 이러한 한계를 극복하는 프레임워크인 Large Language-and-Vision Assistant for Video Moment Retrieval(LLaVA-MR)을 제안합니다.
VMR task는 영상과 텍스트를 입력으로 받아 영상 내에 존재하는 텍스트가 설명하는 구간을 반환하는 task입니다. LLaVA-MR은 이름에서 추측할 수 있듯이 MLLM foundation 모델인 LLaVA모델을 VMR에 활용하는 연구입니다. 앞서 저자가 언급한 한계들로 인해 MLLM을 바로 VMR에 사용하는 것은 효율적이지 못합니다. 실제로 여러 MLLM 연구들이 여러가지 video-text task에서 벤치마킹을 하며 자신들이 제안하는 MLLM 모델이 VMR을 포함하는 여러 task를 동시에 fine-tuning없이 수행할 수 있는 효과적인 모델임을 증명하고 있지만, 단일 task를 수행하는 프레임워크에 비하면 낮은 성능을 보여주고 있었습니다. 저자는 총 3가지 모듈을 통해 MLLM을 단일 task에 수행하면서 생기는 문제점들을 해결하려 했습니다. 3가지 모듈에 대한 설명 전에 기존 VMR 연구들의 흐름을 한번 짚어보겠습니다.
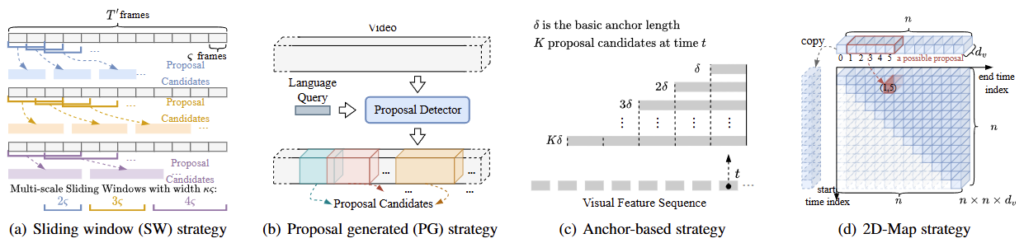
이미지 내에서 객체를 localizing하는 Object Detection과 비슷하게 VMR은 영상의 temporal 축에서 구간을 localizing하는 task이기에 Object Detection에서의 연구의 흐름과 유사하게 흘러갑니다. VMR task가 최초 제안될 때에는 비디오로부터 feature를 추출하고 sliding window(SW)를 활용하는 방식(a)을 통해 VMR이 수행되었습니다. 그 이후 Proposal을 생성하는 Proposal Generated(PG) 방식(b), Anchor box를 통한 예측을 수행하는 Anchor-based 방식(c)으로 연구되었습니다. (d) 2D-Map 방식은 기존 방식과 다르게 영상의 구간을 2차원의 map으로 termpoal relation을 모델링합니다. 가로를 end-timestamp, 세로를 start-timestamp로 생각해 start-timestamp로부터 end-timestamp까지의 유사도가 활성화되는 것을 통한 예측을 수행합니다. 위 4가지 방법 모두 장단점이 존재하지만, 최근에는 위 4가지 방법이 아닌 DETR기반의 프레임워크를 따릅니다.

위 그림은 처음으로 VMR에 DETR기반 방법론을 도입한 Moment DETR 모델의 프레임워크입니다. 영상과 텍스트의 feature를 VLM의 인코더를 통해 추출한 후에 concat한 후 Transformer의 인코더를 통해 Video Feature와 Text Feature의 상관관계를 모델링합니다. 그 후에 학습가능한 임베딩인 Moment Queries를 Transformer 디코더에서 인코더를 거친 fused feature(영상의 정보와 텍스트의 정보가 혼합된 feature)의 정보와 Cross-Attention을 거친 후 각 task 별 Prediction Head를 거쳐 예측을 수행합니다. Moment DETR은 기존의 CNN 기반 방법론들보다 연산속도로 빠른 동시에 성능도 더 좋아 Moment DETR의 공개 이후로는 위 구조를 따르면서 video의 feature와 text의 feature를 naive하게 concat하는 것이 아닌 어떻게 더 잘 상호작용할까의 관점에서 연구가 많이 진행되었습니다(실제로 현 SOTA 모델도 Moment DETR의 구조를 따릅니다).
설명이 좀 길어졌지만, 2021년도에 Moment DETR이 공개된 이후로 Moment DETR의 구조를 따르는 DETR기반 연구들이 많이 공개되고 또 좋은 성능을 보여주고 있었습니다. 예상하셨겠지만, 저자는 위 DETR의 구조를 따르지 않습니다. 저자는 위와 같은 DETR 기반의 구조는 frame-level의 feature extraction에 의존하고(VLM으로부터 feature를 추출할 때 frame-level로 추출함) 각 task별 Prediction Head를 통한 예측은 새로운 데이터에 대한 일반화 능력이 떨어진다고 지적합니다. 따라서 저자는 위와 같은 한계를 해결하고자 일반화 능력이 강하고 robust한 MLLM의 거대한 지식을 활용하여 downstram task에 어떻게 잘 fit할 수 있을까를 연구합니다.
하지만, Introduction 초반부에 언급했던 것처럼 MLLM을 그냥 가져오는 것에는 limited context size와 coarse frame extraction의 한계가 있습니다. limited context size 문제로 긴 영상(untrimmed video, 무편집 영상)에는 잘 대응하지 못하는 문제를 해결하기 위해 긴 영상을 여러 개의 짧은 영상을 분할하는 경우 연산량이 지나치게 늘어난다는 문제가 있고, coarse frame extraction으로 인해 정확한 구간의 시작점, 끝점을 localizing하지 못한다는 문제를 해결하기 위해 frame level로 fine-grained level의 feature extraction을 하게되면 마찬가지로 연상량이 지나치게 늘어난다는 문제가 생기기 때문입니다. 따라서 저자는 연산량이 늘어나는 문제를 해결할 수만 있다면 MLLM을 활용하는 데에 있어 생기는 문제를 해결하고 장점만 활용할 수 있다고 결론을 내립니다. 연산량을 줄이는 방법은 당연하게도 효율적으로 연산하는 것입니다. 문제는 효율적인 연산을 위해서 MLLM의 구조를 건드리는 순간 MLLM이 가지고 있는 사전 지식이 망가질 수도 있다는 점입니다.
따라서, 저자는 MLLM의 사전지식을 잘 활용하는 동시에 효율적인 연산을 위해서 먼저 영상을 fine-grained level로 인코딩하고 중요한 구간과 중요하지 않은 구간을 나눕니다. 그리고 나서 중요하지 않은 구간의 정보를 압축하는 것으로 정보의 누락을 최소화시키면서 동시에 연산량을 줄입니다. 위 과정을 통해 저자는 연산량이 기하급수적으로 늘어나지 않게 하면서 동시에 fine-grained level에서의 구간을 localizing할수 있는 프레임워크를 제안할 수 있게됩니다.
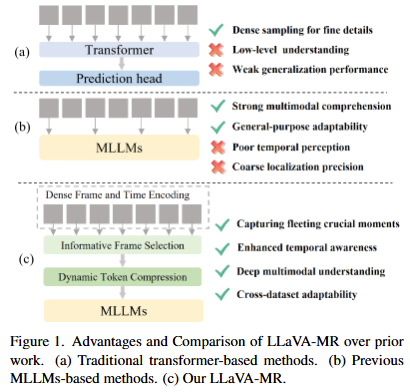
Figure 1.은 저자가 제안하는 방법이 기존의 DETR기반의 방식(a)과 MLLM기반의 방식(b)과의 비교를 통해 저자가 제안하는 방식이 효과적임을 보여주는 figure입니다. 저자의 Contribution은 다음과 같습니다.
- 저자는 MLLM을 VMR에 접목시켜 시각 정보를 향상시키고 긴 영상에서의 중요한 시간적 특징과 일시적인 특징을 잘 포착할 수 있습니다.
- 저자는 Dense Frame and Time Encoding(DFTE)를 통해 MLLM의 coarse frame extraction 문제를 해결하고 Informative Frame Selection(IFS)를 통해 중요한 프레임과 중요하지 않은 프레임을 선별합니다. 그 후에 Dynamic Token Compression(DTC)을 통해 중요하지 않은 프레임의 정보를 압축하는 것으로 연산량 문제르 해결합니다.
- 위 과정을 통해 저자는 두 벤치마크 (Charades-STA 데이터셋, QVHighlights 데이터셋)에서 SOTA를 달성합니다.
Method
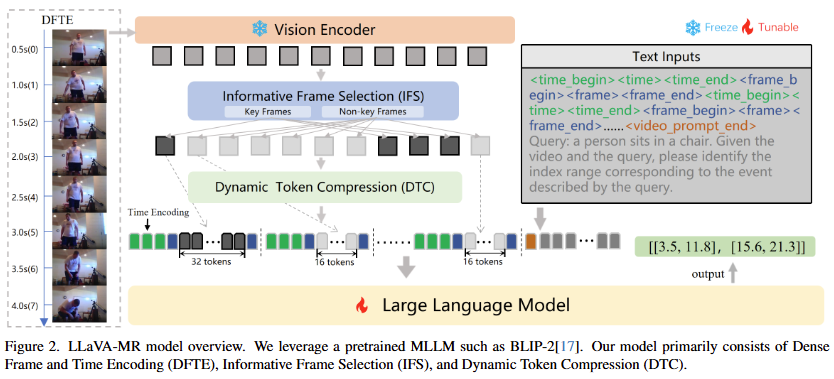
Figure 2는 저자가 제안하는 프레임워크의 전반적인 모습을 보여줍니다. 먼저 MLLM의 DETE방법과 Vision Encoder를 통해 비디오의 feature를 추출하고 IFS를 통해 feature중에 중요한 frame과 중요하지 않은 frame을 구분합니다. 그 후 중요하지 않은 frame들의 정보를 압축합니다. 이때 중요한 프레임과 중요하지 않은 프레임을 선정하는 기준은 동적인 변화가 얼마나 큰 지로 판단한다고 합니다. 이는 동적인 변화가 크지 않다면 특정 행동(쿼리가 설명하고 있는 구간을 의미함)이 진행되고 있다는 것을 의미하고 동적인 변화가 크다면 장면이 전환되고 다른 행동을 취하는 것이라는 관점에서 텍스트 쿼리가 설명하는 구간의 정확한 boundary를 localize하는 VMR에서는 장면이 전환되는 지점이 중요하다고 저자는 생각하기 때문입니다. 아무튼 중요하지 않은 frame들의 정보를 압축한 후에는 저자가 제안하는 입력 sequence prompt를 통해 LLM에 입력하는 것으로 예측을 수행합니다.
Dense Frame and Time Encoding
저자는 MLLM의 시간적 인식의 향상을 위해서 또한 coarse frame extraction의 단점을 해결하기 위해서 Dense Frame and Time Encoding(DFTE)를 사용합니다. 기존의 MLLM은 coarse frame extraction으로 인해 짧지만 중요할 수 있는 정보를 놓칠 가능성이 있었습니다. 저자는 이러한 짧지만 중요한 정보들을 놓치지 않기 위해서 샘플링된 프레임 수를 늘리는 것으로 fine-grained에서의 시각적 정보를 효과적으로 포착할 수 있게끔 설계합니다. 여기서 저자는 프레임 샘플링 비율 R_{frame}를 총 프레임수와 비디오의 길이의 비율을 통해 정의합니다. R_{frame} = N/T 여기서 N는 샘플링된 프레임의 수이고 T는 비디오의 길이 입니다.
저자는 추가로 샘플링 레이트 R_{frame}를 단순히 조정하는 것뿐만이 아니라 R_{frame} \ge 1인 경우와 R_{frame} < 1인 경우 총 두가지의 시나리오를 나누어 설계합니다. 먼저 전자의 경우 frame의 index를 time token으로 사용합니다. 만약에 timestamp를 time token으로 사용하게 된다면 timestamp가 반올림하여 사용하게 되는데 timestamp를 초단위로 반올림을 하게 된다면 모델로 하여금 혼란을 초래할 수 있다고 합니다. 예를 들어서 timestamp가 [2.8, 3.3](모델의 예측 구간의 시작점, 끝점)이라면 초단위로 반올림을 하게된다면 [3,3]이 되어 정확한 모델링을 할 수 없게 됩니다. 따라서 저자는 저자는 R_{frame} \ge 1인 경우 timestamp를 그대로 사용합니다. 후자의 경우에는 timestamp를 time token으로 사용하여 timestamp를 초단위로 반올림하여 사용합니다. 이 경우에는 timestamp의 시작점과 끝점의 사이가 길어지게 되기 때문에 timestamp를 time token으로써 사용하는 것에 큰 문제가 없기 때문이라고 합니다.
Informative Frame Selection
Dense Sampling을 통해서 coarse frame sampling의 문제를 해결했지만, fine-grained level에서 dense하게 frame을 샘플링하기 때문에 비슷한 의미를 갖는 여러 프레임을 샘플링하게되어 중복을 추가하게 되는 문제가 발생한다고 합니다. 예를 들어 영상 내에서 크게 변화없이 같은 장면이 반복되는 경우 이를 dense하게 샘플링하는 경우 같은 시각적 혹은 공간적 의미를 갖는 프레임을 많이 샘플링하게 되어 쓸모없이 연산이 늘어나는 문제를 야기할 수 있습니다. 따라서 저자는 이러한 중복을 줄이고 중요한 키 프레임을 선별하는 과정을 거칩니다. Introduction에서 먼저 언급했었지만, 저자가 여기서 말하는 중요한 키 프레임이란 인접 프레임과의 유사도가 많이 떨어지는 구간으로 장면이 전환되거나 영상 내 유의미한 semantic 변화가 있는 지점을 얘기합니다. 이는 영상 내에서 큰 변화가 존재하는 구간이 쿼리가 설명하는 구간의 boundary가 될 확률이 높다는 것을 전제로하고 있기에 나올 수 있는 생각입니다.
물론 인접한 프레임과의 차이가 크다고해서 무조건 쿼리가 설명하는 구간의 boundary가 되는 것도 아니고 인접 프레임과 차이가 적다고해서 쿼리가 설명하는 구간의 boundary가 아니라는 것도 아니지만 일반적인 상황에서 그럴 확률이 높다는 것을 저자는 전제하고 있는 것 같습니다. 아무튼 리뷰로 돌아와서 저자는 키 프레임과 키 프레임이 아닌 프레임을 구분하기 위해서 Informative Frame Selection(IFC) 과정를 프레임워크에 추가합니다. 먼저 저자는 frame의 feature가 앞 뒤 frame의 feature와의 차이를 계산합니다. 그 후에 그 변화량을 나타내는 벡터를 생성하고 이를 가우시안 스무딩을 통해 스무딩합니다. 가우시안 스무딩은 아웃라이어의 영향을 줄여주어 일반화 성능을 올리기 위합니다.
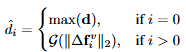
수식에서 d는 프레임간의 변화를 의미하고 단순하게 d = ||f_t - f_{t-1}||_2 연산(빼고 L2 norm)을 통해 계산됩니다. 그 후 상위 d값을 갖는 K개의 프레임을 선정하여 key frame(키 프레임)으로 선정하고 나머지 프레임은 not key frame(중요하지 않은 프레임)으로 결정합니다.
Dynamic Token Compression
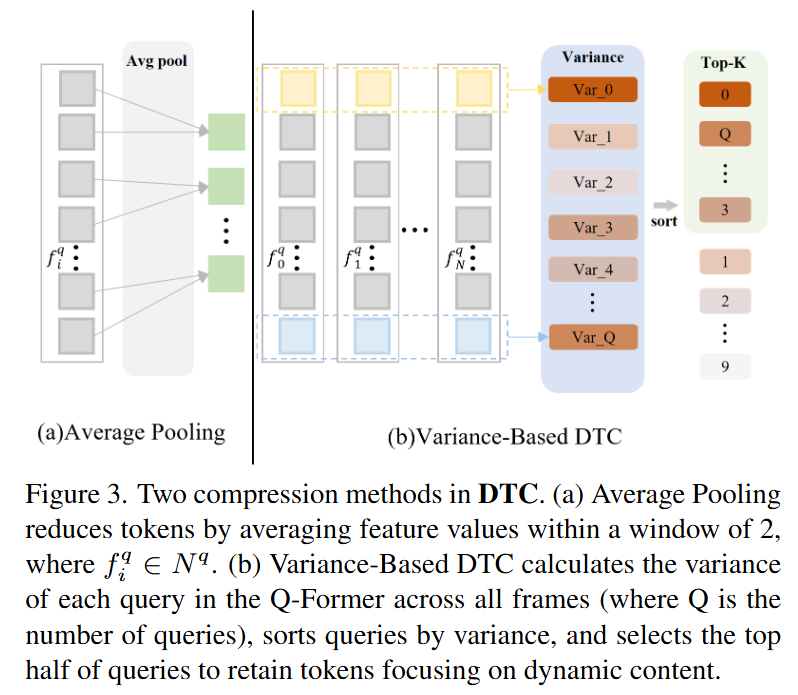
앞선 IFC 과정을 통해 중요한 프레임(키 프레임)과 중요하지 않은 프레임을 나눴습니다. 중요하지 않은 프레임은 일반적으로 적은 동적 변화를 보이고 있기에 같은 시각적 혹은 시간적 특징이 반복적으로 보이는 특징이 있습니다. 이러한 반복적이거나 정적인 연속성을 보이는 프레임은 LLM의 성능을 저하시키는 동시에 cost(시간, 연산, 리소스 모두를 말함, 자원 소모 정도의 의미로 이해하면 됨)가 커진다는 단점이 있습니다. 따라서 저자는 이러한 중요하지 않은 프레임들을 압축하는 과정을 통해 시퀀스를 줄이고 중요한 정보를 보호합니다.
저자는 크게 두가지 방법을 통해 Dynamic Token Compression(DTS)를 진행합니다. Figure 3.에서 보이는 Average Pooling과 Variance-Based DTC입니다. Average Pooling은 주어진 window(key frame 사이의 구간으로 중요하지 않은 프레임들의 집합을 window라 표현) 내에서 특징 값을 평균 풀링하여 압축하는 방법입니다. 저자는 이 방법이 naive하면서도 동시에 꽤나 효과적인 방법이라고 강조하고 있습니다. 두번째는 분산 기반의 DTC로 Q-Former를 이용합니다.
Q-Former의 역할은 입력된 프레임 임베딩의 중요한 정보를 query를 기반으로 추출하는 것이라고 합니다. 여기서의 query는 입력 텍스트를 의미하합니다.
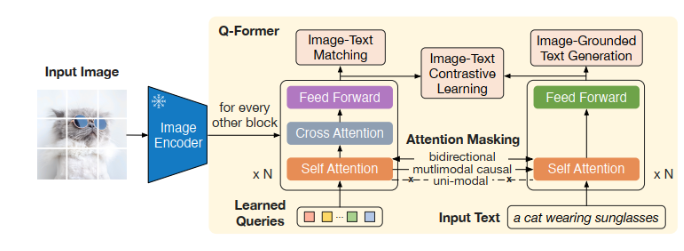
위의 그림은 Q-Former의 구조도입니다. 여기서 Image Encoder를 통해 들어오는 feature 대신에 IFC를 거친 중요한 프레임과 중요하지 않은 프레임이 들어오고 저자가 말하는 query는 왼쪽 하단의 학습 가능한 learned query가 아니라 input text에 들어가는 쿼리입니다. 저자가 입력된 프레임의 중요한 정보를 쿼리를 기반으로 추출하는 것으로 일종의 필터링 역할을 수행한다고 언급하고 있습니다.
즉, 입력 텍스트의 정보를 통해 프레임 임베딩 내에서 중요한 정보를 추출한다고 보시면 됩니다. 그러면 왜 Q-Former를 사용하냐가 궁금하실 수 있는데 Q-Former의 목적은 learned query가 가중치를 공유하는 두 pathway를 통해 image의 특징과 text의 특징을 모두 얻을 수 있게 하는 데에 있습니다. 즉, 논문에서는 학습 가능한 쿼리(learned query)가 프레임의 특징과 input text의 특징을 모두 얻을 수 있도록 하는 것이고 Q-Former의 출력은 두 모달리티의 특징을 모두 학습한 learned query입니다. learned query의 크기는 하이퍼파라미터로 사용자가 설정할 수 있기에 frame의 길이에 상관없이 고정된 길이의 두 모달리티의 정보를 학습한 learned query를 얻을 수 있게 되는 것입니다. 따라서 정보를 압축하는 것과 같은 효과를 볼 수 있습니다.
Training and Inference
결국 마지막에는 DFTE, IFC, DTC를 통해 얻은 feature로 input sequence를 생성해 LLM에 입력합니다. input sequence는 text input을 마지막에 추가해 LLM에 입력합니다. text inputs은 Figure 2 우측으로 아래의 그림과 같습니다.

LLM의 출력은 [[0,1],[3,5],…[s,e]]의 형태로 구성됩니다. 학습은 이 출력을 maximum likelihood objective를 통해 학습된다고 합니다.
Experiments
저자는 LLaVA-MR을 두 데이터셋에서 벤치마킹합니다. Charades-STA 데이터셋과 QVHIghlights 데이터셋으로 두 데이터셋 모두 VMR에서 자주 벤치마킹되는 데이터셋입니다.
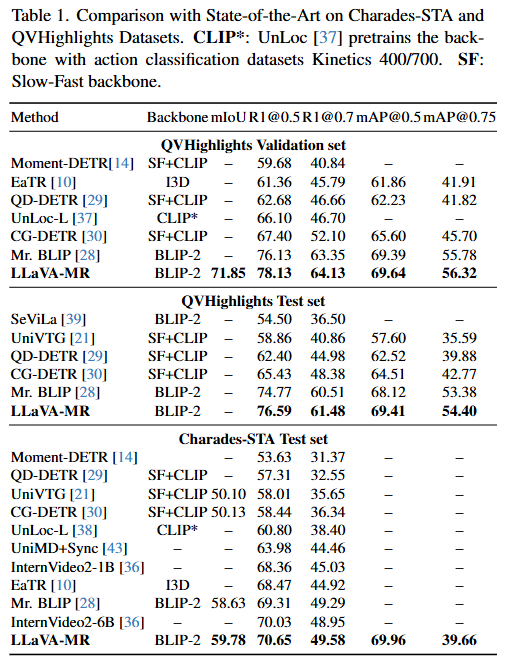
Charades-STA 데이터셋과 QVHighlights 데이터셋 모두에서 SOTA를 달성한 모습을 보여줍니다. 성능이 다른 DETR기반 방법론들보다 높은 것은 좋은 backbone을 사용했기 때문이라고 생각되긴 하지만, 확실히 성능이 많이 오르긴 했습니다. fair comparison을 위해서 기존 방법론들을 같은 backbone으로 실험하는 것이 더 좋지 않았을까 하는 생각은 있긴 합니다… 성능이 높다는 것을 강조하면서 자신들의 방법론이 좋다라고 말하고 있고 특별한 언급은 없습니다.
Ablation Study

(a) 는 베이스라인 모델입니다. 기존 coarse frame sampling을 사용하는 기존의 MLLM을 활용하는 방법입니다. 저자는 (a) 실험을 통해 MLLM을 활용한 VMR의 feasibility를 실험했다고 말하고 있습니다. “MLLM만을 사용해도 성능이 잘 나오네? 한번 잘 다듬어서 논문 써봐야겠다” 정도로 생각한 것 같습니다. (b) 실험은 단순지 프레임 샘플링 수를 늘린 실험이라고 합니다. 얼마나 늘린 것인지에 대한 언급은 없지만, MLLM의 coarse frame extraction 문제를 실험을 통해 보여주고자 한 것 같습니다. (c) 실험은 input sequence에 대한 실험입니다. temporal representation을 강화하는 것으로 성능이 많이 올랐다고 말하고 있습니다. (d)는 저자가 제안하는 모든 모듈을 포함하는 성능입니다. 성능이 높은 폭으로 올랐음을 강조하며 각각의 모듈이 서로 잘 상호작용하고 있다고 강조하고 있습니다.
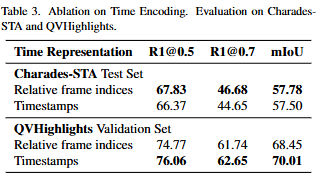
Table 3.은 DFTE에서 두가지 시나리오가 있다고 설명드렸었는데 그 부분에 대한 ablation study입니다.DFTE에서 time encoding을 어떻게 하느냐에 따른 성능 차이를 보여주는 실험결과입니다.

Figure 4.는 정성적으로 저자의 방법론이 굉장히 효과적임을 보여주는 figure입니다.
Conclusion
LLaVA-MR은 MLLM이 긴 untrimmed video에서 moment retrieval이 가능하도록 최적화한 새로운 접근법이라는 것을 저자가 강조하고 있습니다. 특히 기존의 MLLM이 약했던 긴 영상에서의 순간 검색 능력을 올렸다는 것을 LLaVA-MR의 가장 큰 contribution이라고 하고 있습니다.
리뷰를 마치며 LLaVA foundation모델을 어떻게 활용해서 VMR을 한 것인지 궁금했었는데 음….. 생각보다는 그리 도움이 많이 되는 논문은 아니었던 것 같으면서도 MLLM을 활용하는 방법을 하나 제안한다는 점에서 도움이 되는 것 같기도 하고 약간 애매한(?) 논문인 것 같다는 생각이 듭니다. 아직 아카이브에만 등재되어있어서 어떤 학회에 올라갈 지는 지켜봐야하겠지만, 문제정의가 새롭지 않았고 문제를 해결하는 방법이 기존의 방법들을 짬뽕시킨 느낌이라서 좋은 학회에 올라가는 것은 어렵지 않을까하는 생각이 드네요… 성능이 많이 올라서 어쩌면 또 가능할지도?
아무튼 foundation 모델을 downstream task에 가져와서 성능을 많이 올린 논문들이 점점 많이 보이고 있고 각 연구들마다의 생각과 접근이 다른 것 같아 흥미로운 것 같습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰감사합니다.
본문의 Dynamic Token Compression의 Variance-Based DTC 방법에서 질문이 있습니다.
Variance-Based DTC은 IFC를 거친 중요한 프레임과 중요하지 않은 프레임을 입력으로 하여 Input text와 비교를 하는 것 같은데, 무엇을 비교하는 건가요? Fig3을 참고했을때 최종적으로 Variance-Based DTC은 각 프레임의 분산을 계산해 동적 변화가 큰 프레임만 뽑아내는 것 같습니다. 그렇다면 Variance-Based DTC은 non-key frames의 정보는 아예 사용을 안하는 건가요?
감사합니다.
안녕하세요 의철님 좋은 댓글 감사합니다.
DTC 과정은 여러 프레임의 특징과 Input text의 특징을 learned query가 학습할 수 있도록 하는 과정입니다. 이 과정에서 learned query의 길이는 고정되어 있기에 각 프레임의 길이가 몇개가 들어오더라도 같은 길이로 출력할 수 있어 압축의 효과가 있습니다. Variance-Based DTC의 경우 key-frames와 non-key frames의 정보를 모두 활용하지만 동적 변화가 큰 프레임의 정보를 위주로 뽑아 내기에 non-key frames의 반복적인 정보를 압축할 수 있다고 저자는 말하고 있습니다. 결국 non-key frames의 반복적이고 비교적 필요없는 정보를 압축하는 과정이라고 생각해주시면 될 것 같습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
Mr.BLIP이라는 방법론과 더불어 이 방법론이 학계에 받아들여질지에 따라 앞으로의 연구 방향성이 많이 바뀔 수도 있을 것 같습니다. 만약 accept된다면 아직은 간단한 MLLM 활용 방안들이 코스트도 커지고 복잡해질 수도 있겠네요.
방법론 중 Dense sampling을 수행할 때 R_{frame}은 (비디오의 프레임 개수) / (비디오 길이)로 정의된다고 말씀해주셨는데, 여기서 비디오 길이는 ‘초’ 단위를 의미하는 것인가요? 애초에 (초*fps)가 비디오 프레임 개수이다보니 이게 <1이 될 수 있나 싶은데, 어떻게 정의된 것인지 궁금합니다.
그리고 Charades보다 QVHighlights에서의 성능 향상 폭이 훨씬 큰 것이 인상깊네요. 개인적으로 두 데이터셋의 비디오 도메인은 유사하나 텍스트 쿼리 복잡도의 차이가 크다고 생각하는데, 그게 맞다면 MLLM의 텍스트 처리 능력 덕을 많이 봤다는 이야기일 것입니다. MLLM 기반 모델 실험 결과들을 종합해봤을 때 DETR 기반 방법론들도 텍스트 쿼리에 대한 이해력을 높여주면 성능이 많이 올라갈 수 있다는 가설에 대한 증거일 수 있을 것 같습니다.
안녕하세요 김현우 연구원님 좋은 리뷰 감사합니다.
먼저 좋은 고찰 감사합니다. 텍스트 쿼리의 복잡도에 따른 MLLM 기반 모델들의 성능차이로 보아 복잡한 텍스트에 대한 이해가 MR에서 중요한 요소라고 생각이 되네요. 실험을 통해 검증해봐야할 것 같습니다.
Dense Sampling의 경우 비디오의 길이는 (샘플링하는 프레임 수)/(총 영상의 길이(초))입니다. 즉, 1보다 작으면 1초보다 큰 길이의 segment로 샘플링을 한다는 것을 의미하고 1보다 크다면 1초보다 작은 길이의 segment로 샘플링한다는 것을 의미합니다.
감사합니다.