안녕하세요. 저번주 목요일에 KRoC에 LLM, VLM을 활용한 매니퓰레이터 제어 정책 생성 관련 서베이 논문을 작성하고 제출하는 동안 여러 논문도 훑어봤겠다, 정신을 가다듬고 리뷰를 작성해보고자 합니다. 서베이 논문의 레퍼런스로도 언급한 논문인데, 이번 리뷰는 embodid AI 즉, robot mainpulation의 제어 정책 생성을 위한 prompt 연구 중 꽤나 경험적인 prompt 기법들을 짬뽕한 논문입니다. 리뷰 시작하겠습니다.

1. Introduction
저희 로보틱스 팀 외의 팀 분들은 해당 분야에 사실 큰 그림이 잘 안 그려지실 수 있을 것 같습니다. 물론 과거 태주님의 세미나를 통해서도 Embodied AI 연구의 굵직한 흐름을 느낄 수 있었음에도 막 태동하고 있는 꽤나 최신 연구이기 때문에 이런 연구에 대한 스토리 정립이 잘 필요하다고 생각합니다. 그래서 인트로에서 순차적으로 흐름을 짚어가보겠습니다.
우선 오늘날 GPT와 같은 대규모 언어 모델(LLM)은 NLP 분야의 여러 굵직한 연구들을 통해 다양한 언어 생성 태스크(코드 생성, 번역 등)에서 잠재적인 능력을 입증해왔습니다. 그 중에서도 특히 복잡한 추론 태스크(산술 추론, 상식 추론, 기호 추론 등)에 대한 능력은 CoT(Chain-of-Thought) 연구를 기점으로 발전되었습니다. few-shot prompting 기법을 통해 LLM을 fine-tuning 하는 것에 대한 cost 문제를 해결하면서, <input, CoT, output>의 인간이 사고하는 것과 유사한 step-by-step reasoning path를 생성하는 방식으로 LLM 추론 능력을 끌어올리기 위한 더 고도화된 prompt engineering 방식에 대해 점차 연구가 일어나게 됩니다.
<다양한 방식으로 점차 고도화되어 온 Prompt Engineering 방법론들>
- Zero-shot-CoT(Let’s think step by step 으로 few-shot prompting CoT와 유사한 능력 입증.)
- Self-consistency(top k prompting)
- Tree-of-Thought(경우의 수가 더 복잡한 추론 문제를 tree search 방식으로 해결)
- Program-of-Thought(python code를 활용한 prompting으로 알고리즘적 추론 능력 입증)
- Chain-of-Code(python code + program state(주석) 기법을 활용해 LLM을 마치 python interpreter처럼 코드를 실행시킬 수 있게 흉내내는 방식을 구현)
그래서 최근엔 위와 같은 연구들을 통해 LLM prompt engineering 기법들이 발전하고 코드 생성과 이를 활용한 추론 성능까지 준수해짐에 따라, 이 prompt engineering을 활용해서 로봇 제어와 관련된 여러 작업을 “작업에 대한 코드 정책을 생성”하는 방식으로 처리할 수 있게 되었습니다.
이런 연구의 대표주자는 바로 CaP(Code as Policies)(태주님 리뷰)였습니다. CaP는 로봇이 작업을 수행하는 데 필요한 사전정의된 API를 만들어놓고, LLM은 이를 참고하여 코드를 생성하고 이 코드에 맞게 로봇을 동작시키게끔 하는 방법론입니다.
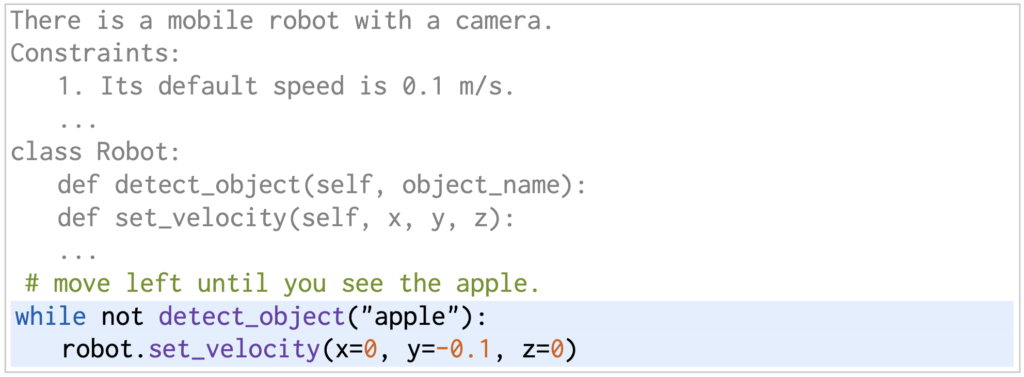
본 리뷰에서 소개하고자 하는 논문이 CaP의 전반적인 정책 코드 생성을 기반으로 하기에 이를 잠깐 짚고 넘어가자면, LLM에게 파이썬 API를 활용한 로봇 액션 코드의 예제 몇 개를 prompt로 던져주면서(few-shot prompting), 주석으로 설명된 명령(instruction)과 그에 맞는 정책코드(policy code)를 보여주게 됩니다. 예를 들면 아래와 같이, 회색부분의 few shot 예제로는 detect_object에 관한 함수를 prompt로 주고, 그 다음으로 초록색 부분의 명령을 사용자가 입력했을 때, 그에 맞는 적절한 python action code를 생성하는 것입니다.

하지만 이런 식으로 예제를 통해 prompt를 던져주려면 사전정의된 primitive action 코드들(low-level의 원시 제어 코드)이 필요하고, 사람이 직접 로봇의 모든 속성과 제약 조건을 충분히 이해하고, 이것을 모두 고려한 충분한 예제를 prompt로 제공해야한다는 점에서 한계가 있습니다. 또 그렇다고 오히려 예제를 너무 많이 추가해버릴 경우는 LLM이 추론하는 데 있어 복잡성이 증가해버립니다.
그래서 본 논문에서는 instruction-based prompting이 주목받고 있음을 언급하며 이를 활용하고자 했습니다. 이 방법은 태스크를 예제 prompt 방식이 아닌, 간단한 텍스트 설명으로 단순히 지정하는데요. PDDL(Planning Domain Definition Language; 객체(Object), 술어(Predicate), 행동(Action), 초기 상태(Initial State), 목표 상태(Goal State) 등의 요소를 포함한 로봇 planning 태스크에서 기초가 되는 일종의 전략.) 기반 계획 생성부터, 예측 제어를 위한 reward 함수 합성에 이르기까지 모델에 로봇의 상태 및 함수, 제약 조건 및 액세스 가능한 API에 대한 간략한 언어적 description이 제공되고, 새로운 태스크가 주어졌을 때 새로운 로봇 코드를 직접 완성토록하는 기반의 instruction-based prompting이 있겠다고 할 수 있겠습니다.
아래를 보면 회색 부분에서, 자연어 instruction으로 상황에 대한 description을 주고, 순차적으로 제약조건, robot에 대한 함수를 담은 class를 prompt로 제공하면, 초록색의 사용자 명령어가 들어왔을 때, 아까와 마찬가지로 LLM이 적절한 함수를 사용하여 액션 코드를 생성하는 것을 확인할 수 있습니다.
그런데 이 기존 연구들은 로봇 코드를 생성하는 것에는 좋은 모습을 보여줬지만, 프롬프트의 선택이 LLM의 자의적인 판단으로만 이루어지기에 평가가 명확하지 않았다는 아쉬움이 있었습니다. 그래서 본 논문에서는 다양한 로봇 설정(고정된 single-arm pick and place task, bi-arm pick and place, a single-arm mobile manipulator의 3가지 real HW 플랫폼)과 LLM(in-context pre-trained PaLM 2-L, fine-tuning된 동일한 LLM instruction, 코드 데이터에서 미세 조정된 더 작은 in-context pre-trained 24B LLM) 간의 프롬프트 방법의 차이에 대한 체계적인 평가를 도입하는데요. 그 결과 저자들은 다음과 같은 결과를 보였습니다.
- Instruction-tuned 모델 + example-based 프롬프트는 서로 시너지가 발휘되어 효과가 좋으며, 때로는 non-instruction-tuned 모델의 전체 성능을 능가하기도 합니다.
- CaP 프롬프트에 추가적으로 Instruction+ Example 프롬프트를 같이 쓰면 두 방식이 가진 장점을 모두 얻을 수 있고, 소규모 모델을 포함한 모든 LLM에서 성능 향상이 있습니다.
- 로봇의 제약 조건(ex; 도달 가능성)은 Instruction-based 프롬프트를 통해 명시적으로 지정할 수 있는 반면, Example-based 프롬프트에서는 암묵적으로만 표시되는 경향이 있었습니다. 제약 조건과 관련된 오류를 정량화할 때, instruction 기반 프롬프트는 instruction-tuned 모델에서, example 기반 프롬프트는 non-instruction-based 모델에서 더 나은 성능을 보였습니다.
- mobile manipulator 등의 더 복잡한 환경에서는 instruction, example prompt 모두 좋은 성능을 내기는 어려울 수 있었습니다. 실험을 통해 (i) instruction 기반 프롬프트는 human-feedback 수정을 통해 LLM이 자체 프롬프트를 개선하도록 지시할 수 있으며, (ii) 프롬프트의 example은 생성된 로봇 코드 라인 사이에 예측된 로봇 state에 대한 설명을 interleaving함(짜넣음)으로써(VLM으로부터) 이점을 얻을 수 있음을 보였습니다.
후술하겠지만 실험 결과, instruction-based와 example-based prompt를 feedback 및 interleaved states와 결합하면 로봇 코드를 생성할 때 더 강력한 planning 성능을 얻을 수 있다는 사실을 보일 수 있었다고 합니다.
이러한 프롬프트 방식은 새로운 motion primitive(low-level perception and control APIs)를 구축하는 새로운 방법이 될 수 있다고 합니다. 예를 들면 추가적인 사람의 개입, 데이터 수집 또는 모델 훈련 없이 ‘서랍 열기/닫기’ 또는 ‘냉장고 문 열기’와 같은 완전히 새로운 모션에 대해 표현할 수 있게 된 것입니다.
이러한 기능은 오늘날 task specialized한 알고리즘을 대체하기에는 충분하진 않겠지만, 그럼에도 불구하고 low-level motion primitive를 구성할 수 있는 LLM의 역량을 엿볼 수 있다고 볼 수 있습니다.
2. Related work
언어라는 것은 세상 속에 주어진 high-level의 의도나 행동 상식 등을 이해하는 데 생각보다 강력한 힘을 가집니다. 그래서 LLM의 능력을 입증하듯이 다양한 연구가 쏟아져나왔습니다. 수학프로그램 작성 능력(21년), 앞서 언급한 CoT(22년) step-by-step 추론 능력, zero-shot high-level task planning(SayCan, Language models as zero-shot planners, Text2Motion, SLAP, 22-23년) 능력, RL 기반의 reward function 디자인 방식(Language-to-Reward, Reward design with LM, instructRL, 23년), gesture나 demonstration 같은 vision을 활용한 멀티모달 인풋 방식(GIRAF, TTP, 23년) 등이 있습니다. 저도 아직 많은 논문을 깊게까지 살펴본 적은 없어 혹여나 궁금하신 분들은 한번 슥 보시라고 링크 첨부했습니다.
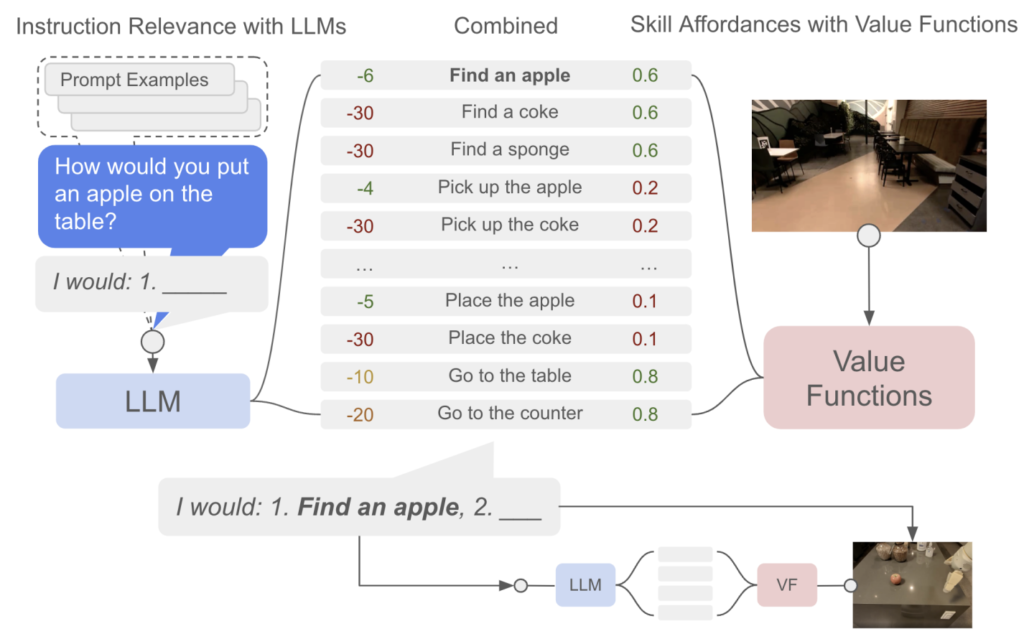

아무튼 앞서 언급했듯이 대규모 web-scaled 데이터를 통해 학습된 LLM은 다방면에서 인상적인 성능을 보였습니다. 하지만 그럼에도 새로운 태스크 세팅에 있어서는 아직까진 일반화된 성능을 보이지는 못하고 있습니다.(근래에 발표된 GPT4o 등을 적용한 연구는 아직 보이지 않는 것 같아 현재 시점의 GPT4o는 잠시 논외로 하겠습니다.) 그래도 로봇 작업에 있어 새로운 태스크 세팅에도 일반화된 성능을 보이기 위해 LLM을 활용한 로봇 제어 시도는 주로 구글 등의 대기업을 필두로 이전 연구들에서 많이 수행되고 있었습니다. 위에서 링크를 달고 그랬던 논문들은 주로 Instruction-tuned model로써 unseen task에 zero-shot 작업 수행능력을 보이는 연구였고, 대부분 instruction-response pair로 직접적인 low-level의 동작값을 유추하는 방식도 많이 포함되었습니다. 혹은 언어 instruction-feedback 으로 language→motion primitive로 다이렉트하게 매핑지어 학습하는 방식이 있었습니다. 이외에도 RT-1같이 로봇 학습용 지시 데이터를 이용해 language-conditioned policies를 학습하는 방식도 있었습니다.
이 중 앞서 introduction에서 언급한 prompting 방식의 연구는 Example-based prompting이랑 Instruction-based prompting 연구로 나뉘는데요. Example-based prompting 로는 CaP, Prog-prompt 등의 few-shot 예제 기반 프롬프트 연구이고, 이는 보통 low-level policies 학습에 기반해서 high-level의 task planning을 수행합니다. Instruction-based prompting 로는 ChatGPT for Robotics 처럼 특히 환경에 대한 feedback과 실행 에러, self-verification을 고려한 반복적인 지시 prompting 기반 연구입니다. 또는 knowledge acquisition 과 progress monitoring을 위한 prompt design 테크닉입니다. 최근에는 Auto-CoT 등을 활용해서 이런 방식도 자동화된 prompt 생성으로 변화하려는 시도도 보이기도 합니다. 근데 이건 real robot setting에는 잘 적용되지 못하던 방식이었습니다.
저자들은 task와 motion planning 둘 다를 실행하기 위한 code example 방식을 내세웠고, 이는 example-based prompting으로 인해 LLM에 implicitly 한 가이딩을 주면서, real world setting에서도 잘 적용되게끔 in-context learning으로 API 가이드와 example을 모두 prompting 하는 방식을 취합니다. 말은 복잡하지만, 결국은 CaP 보다 조금 더 고도화된 형태의 어떤 자기들만의 경험적인 prompting을 구축한 것이란 생각이 강하게 들었습니다.
3. The PromptBook Recipe
저자들의 가장 큰 목표는 역시 로봇이 자연어로 지정된 다양한 작업을 수행할 수 있게 하는 것입니다. 여기서 LLM을 활용해 자연어 명령을 로봇 코드로 매핑하는 CaP의 방식을 기본적으로 차용합니다. 코드 작성용 LLM은 제어 구조(loop 등) 및 third-party 라이브러리(예;numpy 등) 같은 요소를 활용할 수 있는 능력이 기본적으로 검증되었습니다. 하지만, LLM의 학습 데이터에 포함되지 않은 개념이나 API가 포함된 도메인 특화된 로봇 코드의 경우에는 코드를 직접적으로 만들어낼 수는 없죠. 외부 지식이나 추가적인 근거를 사용하는 것 외에 로봇 작업 코드 생성을 위해서는, 입력으로 주어질 작업 명령 앞에 LLM의 autoregressive한 생성 과정을 유도하는 prompt를 추가해서 원하는 출력 코드를 생성하도록 합니다.
저자들은 LLM 로봇 코드 생성을 개선하기 위해 LLM 프롬프트 레시피인 PromptBook이라는 방법을 제안합니다. 다음이 prompt에 대한 자세한 레시피(?)를 나열하는데요. 이제 여기서부터 CaP Prompt의 약간 고도화인 것 같네.. 라는 생각이 스멀스멀 들었습니다.
A. PromptBook Elements
우선 크게 7가지 요소를 따릅니다.
1) Examples

주석에 작업에 대한 명령을, 그것에 대한 response로써 action에 대한 code block이 옵니다.
이런 식으로 예제를 구성하면, example-based prompt라고 하는데, 이는 로봇 명령을 어떻게 real world에 grounding할 것이냐(ex; ‘backwards’와 같은 공간적인 설명을 코드로 어떻게 매핑할 것이냐)와 first-party API를 사용하는 방법에 대해 정보를 암시적으로(implicitly) LLM에 보여줍니다. 이런 example-based prompting은 autoregressive in-context learning에 있어서 개념적으로는 직관적이고 CaP에서 쓰이기도 합니다.
하지만 로봇에 대한 constraints와 같이 LLM에게 example만으로는 가르치기 어려운 개념도 있습니다. 예를 들어 로봇의 속도가 1m/s를 초과해선 안된다는 constraints가 있다고 할 때, 로봇이 동작할 때 속도의 L2 norm이 1을 안 넘는 것을 암시적으로만 추론하려면 robot.set_velocity를 호출하는 여러가지 예제를 보여줘야합니다. 그렇기 때문에 암시적인 예제 prompting만으로 LLM의 행동을 유도하려 하는 것보단, 목표나 constraints 같이 작업의 최종 해결에 관련된 기타 정보들을 설명하는 명시적인 자연어 지침을 따르도록 LLM을 유도하는 방식이 있는데, 그걸 바로 Instruction-based Prompting이라고 합니다. 다음의 2~5까지의 요소가 이 Instruction-based prompting 방식을 사용합니다.
2) High-level Robot and Task Description

high-level의 robot embodiments와 작업 정보를 직접 지정하면, 작업 계획을 수행할 때 LLM에게 유용한 context 정보를 제공하는 셈이 됩니다. 위 예시처럼, 양팔로봇이라고 로봇과 환경을 특정지으며 자연어로 얘기하면 그 만큼의 context를 잘 반영한다는 것입니다. 더불어 위 예시에서는 LLM에게 특정 종류의 가정을 해도 좋다고 지시하는데, 암시적인 example-based prompting에서는 이런 식으로 동작을 유도하는 것이 더 어렵기 때문에 Instruction-based prompting은 이런 점에서 명시적이라는 것이 장점이라는 것을 생각해 볼 수 있게 됩니다.
3) Robot API Documentation

Instruction-based prompting에는 2번의 high-level task description 말고도, 도메인 별 로봇 코드를 작성하는 디테일한 방식에 대한 low-level 코드 정보도 명시되어야 합니다. 그러기 위해, 저자들은 위 예시처럼 robot perception과 action에 해당하는 API를 먼저 제공하고, 이는 python skeleton code 형식으로 제공됩니다. 예를 들면 6D pose를 사용하는 로봇 API의 경우 위처럼 포즈 형식과 표준 방향에 대한 instruction을 줄 수 있습니다.
4) Robot Policy Constraints
3번같은 API 화 외에도 API에서 즉각적으로 명확하지 않았던 로봇 정책 constraints를 더 자세히 표현할 수도 있습니다. 예를 들어, 양팔 로봇 설정의 경우라면 두 팔 별로 주어진 작업 공간의 바운더리에 대한 제약 조건과 각 팔 별로 수행될 수 있는 low-level action 코드를 추가 지시하게 되는 것입니다.
5) Code Guidelines

마지막 많은 example로써 설명하지 않아도, instruction-based prompting은 원하는 정책 코드의 속성/규제를 직접적/명시적으로 구체화하기에 제 생각엔 few-shot에 대한 prompting 양을 줄이는 이점이 있는 것이라고 생각이 드네요.
6) Chain of Thought Policy Reasoning
사실 위의 2~5까지의 instruction-based prompting은 너무나도 경험적인 prompting이라고 생각이 들고, prompting을 작성하는 엔지니어나 LLM 모델의 종류, prompting의 어순 등에 따라 성능이 천차만별이 될 수도 있기에 사실 무언가 거창한 원리가 있다고 표현하긴 어려워 보이는데, 6번의 내용 같은 경우에는 CoT를 코드 주석의 형태로 사용하면서 step-by-step으로 reasoning을 가능하게 하여 추론 성능을 더 높일 수 있다가 되는 것 같습니다. 즉, CoT 방식을 코드 주석 prompting에 통합해서 썼다.가 되겠네요.
7) Interleaved State Predictions with Policy Code
해당 7번은 논문에선 복잡하게 설명하려고 하지만 사실상,, ScratchPad 에서 사용하던 방법론이었습니다. ScratchPad가 뭐냐함은, 다음과 같이 저희가 코딩할 때 background에서 흘러가는 변수값 등의 프로그램 상태를 주석으로 처리해주는 방식으로 좀 더 잠재적인 코드 내용을 이해할 수 있다는 방법론입니다.

사실 저자들은 ScratchPad라고 방법론을 명시하지는 않았지만,
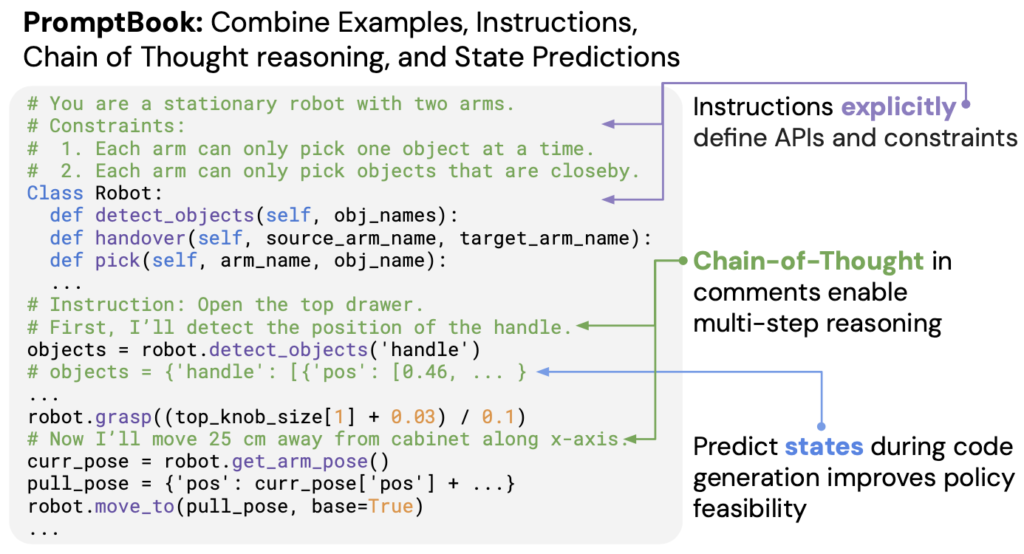
위의 Predict states 에서 보이는 것처럼 # objects = { ‘handle’ : [{ ‘pos’ : [ 0.46, … } 이런 식으로 코드 내의 상태를 중간중간 주석으로 명시해주는 것입니다. 이로써 생성된 정책코드에 대한 feasibility 근거를 보일 수 있게 됩니다.
B. How to Develop PromptBook Prompts
위의 A에서 보았듯이 PromptBook은 여러 요소를 통해서 조합되었습니다. 그럼 그냥 마냥 이 요소들을 조합하기만 하면 PromptBook이 되는 것일까요. 그것은 아니었고, CaP가 작업별로 primitive API와 prompting을 정의하는 것이 달라졌듯이, PromptBook 또한 작업 영역이나 로봇의 구현에 따라 서로 다른 프롬프트가 필요하게 될 것이기 때문에, 초기에 구성된 Prompt를 점진적으로 개선하는 과정이 필요했습니다. 특히 이 땐 언어 feedback을 활용하여 즉각적인 출력과 초기 프롬프트 모두 개선하는 LLM의 회고(retrospection) 기능을 활용하게 됩니다. 다음의 크게 3단계로 개선 과정이 이루어집니다.
- Step 1. Initial Prompt Draft
- Step 2. Human-in-Loop Code Improvement
- Step 3. LLM-aided Prompt Improvement
즉, 우선 초기에 주어진 새로운 로봇 태스크 도메인에 대해 이해하는 로봇 엔지니어로부터, CaP low-level primitive API code base + example-based + Instruction(constraints, description) prompting 기반의 initial prompt를 구성합니다. –> 이후 주어진 초안에서 로봇 엔지니어에게 prompt book의 유효성 검사를 한번 수행하도록 맡깁니다. –> 그 후 로봇의 동작 과정 중 액션 정책이 실패하거나 오류가 발생한 경우 엔지니어가 오류를 피드백하는 과정을 거칩니다.(썩 구체적이진 않은 피드백입니다. ex; “로봇 파지가 문 손잡이에서 너무 멀리 떨어졌어”.[너무 멀리의 정도가 애매], “이전 잡기 동작이 손잡이에 수직으로 접근했어야 해” 등) –> 그 후 피드백을 받은 LLM은 정책 코드를 개선해서 작업이 성공할 때까지 이 과정을 반복하게 됩니다. 각 시도가 끝나면 엔지니어는 최종적으로 (task, code, feedback) tuple 형태를 얻게 됩니다. –> 아까의 human-in-the-loop 피드백이 에러의 반복을 줄이기 위해 프롬프트를 수정하고 나면 얻어지는 튜플 히스토리가 다시금 LLM에게 제공이 되고, 그러면서 엔지니어는 LLM에게 “기존 contraints를 유지하면서 앞선 오류를 피하려면 초기 프롬프트 어떻게 수정할래?” 혹은 “앞으로 이런 실수 피하려면 어떤 constraints를 어떻게 추가할래?” 등을 질문으로 던지면서 LLM이 결과로 내뱉는 수정 사항을 initial prompt에 통합 반영하면서 점진적으로 성능을 개선해나간다고 합니다. 전 개인적으로 랜덤성이 크고 매우 휴리스틱한 과정이라고 생각이 드는 바입니다…
4. Experiments
A. Example vs. Instruction Prompting across LLMs
4-A에선 (i) 예제 기반 프롬프트, (ii) 명령어 기반 프롬프트, (iii) 두 가지를 결합한 프롬프트(명령어 다음에 예제)를 사용하여 다양한 언어 모델의 계획 성공률을 비교합니다.
우선 실험을 위한 로봇 플랫폼은 다음과 같습니다. 기본적으로 pick and place 작업을 수행합니다.
단일팔 로봇 셋업 : UR5 + 흡착 그리퍼 + realsense d435 + 주방용품, 플라스틱 식품 + overhead table top view
양팔 로봇 셋업 : 2개 Kuka IIWA 7 로봇팔 + 2지 그리퍼 + 각 팔 옆에 각각 쓰레기통 + table top view + 플라스틱 식품, 나무블록, 봉제 장난감, 음료수 캔. + 양팔 어깨 위에 realsense d435
태스크 도메인은 다음과 같습니다.
두 로봇 모두 “녹색 접시에 야채를 올려 놓으세요.” 또는 “부드러운 물체를 오른쪽 쓰레기통으로 옮기세요.”와 같이 다양한 속성에 따라 장면의 여러 물체(무작위로 선택 및 배치)를 정렬하는 100개의 자연어 명령어를 사용해야 합니다. 언어 instruction과 장면에 대한 설명(object와 pose에 대한 dictionary 형태)이 입력으로 주어지면 LLM은 대상 location(또는 object name)와 사용할 팔(양팔만 해당)에 따라 선택, 배치 또는 전달 동작(양팔만 해당)을 순서대로 수행하는 motion primitive API를 호출하는 코드를 출력합니다. scene의 이해를 위한 OVD 모델로써는 OWL-ViT를 사용했다고 합니다.
평가를 위한 LLM 모델은 다음과 같습니다.
(i) in-context pre-trained vanilla PaLM 2-L (340B)
(ii) instruction-tuned PaLM (Instruct-PaLM 2-L)
(iii) smaller code-writing language model PaLM 2-S* (24B) (code-related token으로 fine-tuning된)
저자들은 instruction-tuning이 있는 경우와 없는 경우의 사전 학습된 LLM과 동일한 인프라로 학습된 더 작은 사전 학습 코드 작성 모델을 나란히 비교하기 위해 PaLM-2를 사용하기로 결정했으며, 이는 성능 저하 대신 추론 속도(즉, planning latency 단축) 등 이점을 제공할 것으로 보인다고 합니다.
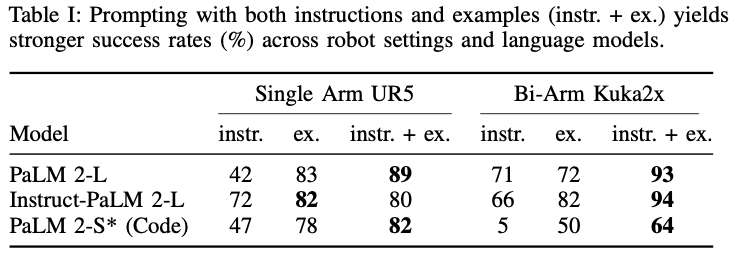
테이블 1은 모델별, 프롬프트 방식 별 평균 planning 성공률을 보입니다. 여기서 알 수 있는 점은 단일 prompt 종류만 사용한다면 instruction 단일 보단 example 단일 prompting이 더 효과가 좋으며, instruction과 example 방식을 섞어서 사용하면 가장 좋은 성능을 낸다는 것을 입증했습니다. 특히 더 어려운 로봇 세팅이라고 할 수 있는 양팔로봇에서 더 좋은 결과를 냈다는 점에서 어려운 도메인의 어려운 태스크에서 더 의미있다고 생각이 듭니다. 실패한 작업 경우에 대해서는 코드는 실행되나 작업 제약조건을 못 지키는 경우(Feasibility) , 코드가 문법에러로 실행되지 않음(Syntax), 코드는 실행되지만 작업은 실패함(Semantic). 으로 정의하였다고 합니다.
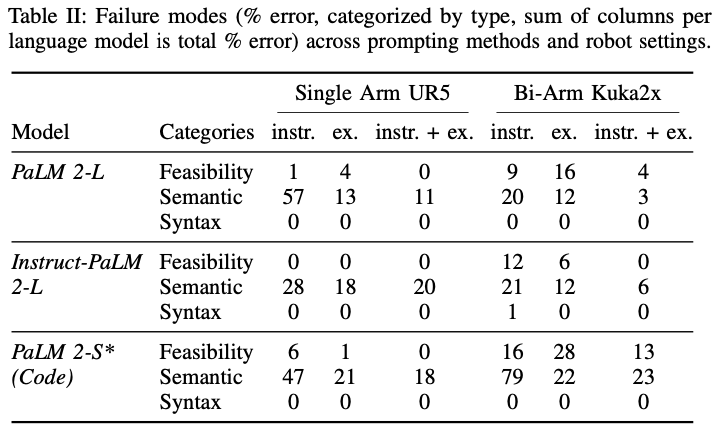
테이블 2는 위에서 언급했듯이 실패의 유형별로 작업 error 비율을 보인 것입니다. 대부분의 오류가 Semantic한 오류가 많은 모습을 보였습니다. 그럼에도 instruction+example 기반의 prompting이 오류 비율이 가장 낮은 모습을 확인할 수 있었습니다.
B. Interleaving State Predictions with Policy Code
테이블 3에서는 로봇 코드 줄 사이에 시스템 state에 대한 언어적 설명을 삽입함으로써 더 복잡한 로봇 시스템의 CaP가 향상될 수 있음을 보였습니다.

C. Improving Instruction-Based Prompts with Human Feedback
테이블 4는 Instruction-based 프롬프트 방식에 사람의 언어 피드백으로부터 반복 코드 개선을 한 것의 효과성을 입증하기 위한 결과였습니다. 실험은 2,3회의 피드백 iteration을 거친 후의 결과이며, feedback을 사용하는 것이 역시 prompt 개선을 이루는 데 큰 도움이 된 것을 확인할 수 있습니다. (사실 당연해보이는 결과를 있어보이게 reporting 한 느낌이 강합니다.)

D. Building Low Level Motion Primitives On-The-Fly
결론적으로 프롬프트에 Instruction+example+state+feedback 방식을 모두 조합하면 real world low-level control을 위한 완전히 새로운 동작 primitives(즉, LLM 스크립팅 정책)를 표현할 수 있는 코드를 생성할 수 있음을 입증했습니다. 즉, 로봇을 학습하기 위한 도메인 특화된 데이터 수집이나 LLM fine-tuning 없이 zero-shot 방식으로 real-world에서 새로운 모션까지 생성할 수 있게 되는 것입니다. 아래 그림은 real-world에서 이를 검증한 정성적 결과입니다.

마지막으로는 저자들이 mobile manipulator의 real-world에서의 작업 성공률 또한 reporting하는데, 다른 방법론을 비교하지 않아 객관적인 성능 판단은 어려운 것 같다는 생각이 들었습니다.

5. Conculsion
CaP 기반의 Instruction-based + example-based + state prompt + feedback prompt 로 구성되는 매우 경험론적인 짬뽕 prompting 방법론이 효과가 있음을 보인 연구인데요. 그래도 의미가 있다면 초기에 잘 정의된 promptbook 하나가 점차 개선되면서 다른 새로운 태스크에 zero-shot prompting으로써 적응적으로 적용이 가능하다는 점이 PromptBook이라는 방법론의 이름과 나름 잘 매칭이 되어 논문의 제목과 이름 하나는 인상깊다는 생각이 들었으나, 현재 공개된 논문 버전에서는 appendix가 제대로 갖추어지지 않은 상황이라 디테일한 prompt 를 살펴볼 수 없어서 리뷰하면서 깊이 있는 고찰은 하지 못했단 점이 아쉬웠습니다. 또한 논문이 제시하는 연구의 limitation이 있었는데요, 새로운 로봇 모션이 사전정의된 primitive 모션과 비전 정보를 통해 얻어진 객체의 포즈에 의존됨이 한계라고 합니다. 즉 이 둘이 error가 있으면 본 방법론을 활용한 로봇의 작업도 성공률이 낮다는 것입니다. 이는 결국 LLM-re-planning 방식으로 LLM이 직접 계획을 최적화하는 방향으로 나아가야할 것이라고 하는 저자들의 언급을 마지막으로 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
본 논문의 내용적인 분야에 대한 질문이라기 보다는 재찬님께서 꾸준히 관심을 가지고 계시고 리뷰해주시는 Embodied AI, Prompt Engineering 쪽의 분야에 대한 개인적인 견해에 대한 질문입니다.
최근 굵직한 기업들에서 로봇, 그 중에서도 부엌 등의 가정 상황에 대한 로봇 연구를 활발하게 진행하고 있는 것으로 알고 있습니다. 다만 제 생각으론 가정에 로봇을 들인다는 것 자체가 고객 입장에서 좀 꺼려질 수도 있고 (마치 감시로봇같은 느낌..) 안전상의 문제도 생길 수 있을 거 같은데, 이쪽 산업계 전망에 대한 개인적인 생각이 궁금합니다. ㅎ
추가적으로, 본 리뷰를 읽다보니 아직은 여러 feedback 들을 기반으로 수정하는 과정들이 수반되어야 정확한 동작(?)이 가능한 것으로 보이는데요, 아직은 이쪽 분야의 연구적 한계점으로 생각하면 될까요? (기술 성숙도 부족?)
감사합니다.
안녕하세요 석준님, 리뷰 읽어주셔서 감사합니다.
지금으로썬 석준님께서 말씀하신 것처럼 굵직한 기업들(Google DeepMind, Nvidia, Microsoft 등등 중 특히 Google)에서 이 Embodied AI 분야를 선도하고 하고 있는 느낌이 듭니다. 임팩트 있는 논문 중 절반 정도 혹은 절반 이상이 google이더라고요.
일단 단순 부엌이나 테이블탑 뷰 등의 제한된 scene에서의 연구가 많긴 하지만, mobile manipulator가 집이라는 실내 전체구조를 exploring하면서 3D scene grapth searching 방식에 LLM Agent를 활용해서 동작을 planning 하는 연구(SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning)도 있을 정도로, 생각보다 Embodied AI 분야의 연구가 막 태동하고 있긴 해도 굉장히 다양한 형태로 빠른 속도로 진화하고 있었습니다. 서베이 논문 작성하면서 알아본 내용까지로는 그렇습니다. 이외에도 제가 모르는 방식이 있을 수도 있어요!
아무튼 다시 돌아와서 가정상황에 로봇을 들인다는 게 당장은 로봇이 너무 고가이고, 또 사람입장에선 집에 돌아다니면 뭔 일 생기지 않을까 하고 당연히 불안하고, 아직 인지와 동작에 제약도 너무 많은 게 아닌가 싶긴 하지만,.,!
그럼에도 불구하고 로봇에 직접적인 엔지니어링을 하기 위한 고가치 엔지니어 인력의 cost가 줄고, 일반인도 자연어 명령만으로도 로봇을 동작시킬 수 있겠다는 가능성의 측면에서, 매우 큰 도약을 하고 있는 시점이라고 생각합니다. 이렇게 하나하나 가능성을 열어나간다면 안정성이나 일반화 문제도 점차 해결될 수 있으리라 생각이 듭니다.
하지만 결론적으로 학계와 산업계를 불문하고 이 ‘Embodied Agent인 로봇’ 자체의 시장성만 놓고 봤을 때는, 실제로 걱정없이 쓸 수 있는 가정 단위의 로봇이 되는 것은 아직 조금은 멀었다고 생각합니다. 그래도 5~10년 쯤 뒤에는 진짜 무언가가 나올 것 같아요. 근 몇년을 돌이켜보면 자율주행의 상용화도 급속도로 이루어지기도 했고, GPT나 VLM의 존재감도 확 커져버린 것처럼, 놀라운 연구가 세상을 뒤흔들지 않을까 싶습니다. 너무 추상적인 전망이려나요.. 하하
그리고, feedback이나 reward 기반의 prompt 기법이 아닌 방법론들도 있긴 하나, 결국엔 feedback prompting이 있어야 확실히 동작 error 의 개선 측면에서 좋은 모습을 보일 것으로 생각합니다. 사람도 실수를 통해 성장하고, 같은 실수를 반복하지 않기 위해 노력하는 것처럼 로봇도 그런 형태가 될 수도 있을 것 같아요. 지금은 사람의 feedback을 받고는 있지만, 추후엔 GPT등의 LLM 추론 성능의 성숙도가 매우 올라가면, Agent 스스로가 자가진단처럼 feedback을 내릴 수도 있을 것이라고 생각합니다.
아직은 모르는 것들이 너무 많은 학부생의 지식으로 생각해 본 지극히 개인적인 견해이기 때문에,, 다소 추상적일 수 있는 점 양해 부탁드립니다…
감사합니다.
안녕하세요, 이재찬 연구원님. 좋은 리뷰 감사합니다. 잘 모르는 분야인데 관련 동향에 대한 설명이 있어 수월하게 이해할 수 있었습니다. 점점 robot manipulation을 위한 code 생성을 정교하게 하기 위해 LLM을 이용한 프롬프트 엔지니어링이 적극적으로 연구되고 있네요. 볼 때마다 기발한 아이디어라고 생각됩니다. 자세한 instruction을 작성해야 하긴 하겠지만, 나중에는 궁극적으로 비전문가도 로봇 엔지니어의 피드백이 필요하지 않은 코드를 생성할 수 있게 될 것 같네요.
리뷰 읽다보니 궁금한 점이 있어 간단한 질문 몇개 남기겠습니다.
1. 이런 로봇 프롬프트 엔지니어링 평가는 성공률로 측정하는것으로 보이는데, 이를 측정하기 위한 instruction 및 example로 구성된 데이터셋들이 따로 있는 것인가요? (Table의 Single Arm UR5, Bi-Arm KuKa2x 등등..)
2. 코드 생성에 있어서 어떤 LLM들이 사용되나요? experiment에 보면 다양한 PaLM들이 있는데, 이 PaLM이라는 모델을 일반적으로 사용하나요? PaLM이라는 모델이 어떤 특성을 갖고 있는지 궁금합니다.
3. 어떤 로봇을 사용하는지에 따라서도 성공률이 달라질 것 같은데, 성능 평가에서 보통 로봇들이 통일되어있는지도 궁금합니다.
감사합니다.
안녕하세요 재찬님, 리뷰 감사합니다
프롬프팅을 할 때 example-based와 instruction-tuning을 각각 할 때의 가장 큰 차이점은 무엇인가요? 또 example-based 방식을 사용했을 때 코드의 길이나 복잡도에 대한 한계는 없는지 궁금합니다!!
좋은 리뷰 감사합니다.
Q1. 저자가 정의한 primitive motion이 뭔지 궁금합니다.
Q2. “사전 정의된 primitive 모션과 비전 정보를 통해 얻어진 객체의 포즈에 의존됨이 한계”라는 저자의 의견 중, 비전 정보를 통해 얻어진 객체 포즈에 의존적인 문제는 어떻게 개선 가능한지에 궁금합니다.