제가 이번에 리뷰할 논문은 CVPR2024 논문으로, 다양한 task로의 task-agnostic한 사전학습된 encoder-decoder를 만드는 논문입니다. 미학습물체파지 과제에서 기하정보를 기반으로 미학습 물체 후보 선정 및 의사(pseudo) 라벨 생성 기술 개발이라는 목표가 있어 어떻게 할 지 찾아보다가 읽게 된 논문입니다. 제가 생각했던 방법론은 아니지만 다양한 vision task에 일반화를 위한 연구라는 점에서 한번 리뷰해보았습니다….(근데 코드는 따로 없네요..ㅠㅠ)
Abstract
해당 논문은 다양한 downstream task로 적용을 위한 GeneraLIst encoder-Decodr(GLID) 사전학습 방식을 제안한 논문입니다. 저자들은 기존의 다양한 self-supervised 사전학습 방식이 전이학습에서 좋은 결과를 보였으나, 각 task에 맞는 구조를 추가적으로 설계해야한다는 점에서 대규모 데이터로 사전학습되었다는 장점을 활용하지 못한다는 점을 문제점으로 보았습니다. 해당 논문은 범용적인 encoder-decoder를 설계하여 최소한의 수정을 통해 다양한 하위 task로 적용 가능하도록 네트워크를 사전학습합니다. 이때 task-agnostic하기 위해 하위 task들을 “query-to-answer”문제로 모델링하였고, fine-tuning시에는 task별로 최상단의 linear transformation layer만 변경하여 적용할 수 있도록 하였다고 합니다. 이러한 GLID를 통해 object detection, segmentation, pose estimation(여기서는 사람의 자세 추정을 위한 keypoint 예측을 의미합니다), depth estimation에서 각 task에 특화된 모델과 비교했을 때 더 좋거나 경쟁력있는 성능을 달성하였다고 합니다.
Introduction
대량의 unlabeled 데이터를 활용한 self-supervision이 컴퓨터비전에서 좋은 성능을 보였으며, Masked Image Modeling(MIM) 방식은 classification, detection, segmentation, pose estimation, depth estimation 등의 작업에서 성능을 크게 개선시킬 수 있음을 보였습니다. 그러나, 대부분 백본의 학습에 초점을 맞추었으며, downstream task에 적용하기 위해선 각 task에 맞는 sub-architecture가 필요하다는 한계가 존재합니다. 이러한 sub-architecture는 복잡한 구조를 가지고 있으며, 각 task별 데이터로 스크레치 레벨부터 학습을 진행해야 한다는 점에서 대규모 데이터로 사전학습되었다는 장점을 활용할 수 가 없게 됩니다. 최근 vision 분야에서도 일반화된 구조를 위한 연구가 진행되었으나, 대부분 backbone에 집중하고있고, decoder는 여전히 downstream task별로 스크레치 레벨의 학습이 요구되며, 성능을 보장하기 위해 task별로 대규모 데이터가 요구되기도 한다는 문제가 존재합니다.
이러한 문제를 해결하기 위해 해당 논문은 self-supervised 사전학습 방식인 GeneraLIst encoder-Decodr(GLID)를 제안하였습니다. GLID는 약간의 수정을 통해 다양한 vision task에 적용 가능하며, 핵심 아이디어는 task들을 “query-to-answer” 문제로 모델링하여 일반화된 encoder-decoder model을 학습하는 것입니다. 이를 위해 ImageNet 데이터 셋에서 저자들이 설계한 masked image modeling pretext task로 전체 encoder-decoder를 학습합니다. 구체적으로, 먼저 각 query들을 masking된 패치 위치와 연관시키고, 해당 위치의 embedding으로 설정합니다. 각 query에 대한 “answer”는 masking된 패치의 픽셀값이며, encoder와 decoder를 함께 학습하여 reconstruction pretext task를 사전학습합니다. 이후, fine-tuning시에는 사전학습된 encoder-decoder와 query들은 유지하고, task별로 최상단의 linear transformation layer만을 변경하여 task별로 원하는 output을 출력합니다. 이를 통해 사전학습된 가중치는 최대한 유지하며, 기존의 방식에 비해 사전학습과 fine-tuning 사이의 갭을 줄일 수 있었다고 합니다.
저자들이 제안한 GLID는 6가지 하위 task에서 복잡한 구조 변경 없이 최상단의 linear transformation layer만을 변경하여 적용이 가능함을 입증하였으며, 다양한 실험을 통해 GLID가 간단하지만 강력한 일반화가 가능하다는 것을 보였다고 합니다.
본 논문의 contribution을 정리하면,
- 다양한 하위 task로 적용 가능한 generalist encoder-decoder 사전학습 방식인 GLID 제안
- pre-train과 fine-tuning을 “query-to-answer” 문제로 모델링하여 gap을 최소화
- 다양한 실험을 통해 GLID가 각 task에 특화된 모델을 능가하거나 비등한 성능을 보임을 확인하였으며, 데이터 효율성이 향상됨을 입증
Method
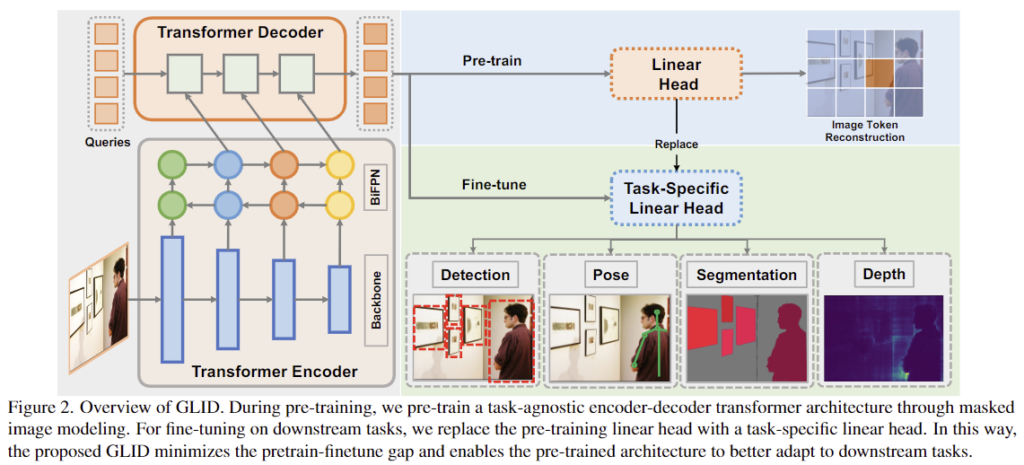
사전학습된 encoder를 통해 다양한 vision task에서 발전이 이루어졌으나 다양한 downstream task에는 task-specific한 decoder가 요구된다는 한계가 여전히 존재합니다. 따라서 해당 논문의 저자들은 GeneraLIst encoder-Decoder (GLID)라는 사전학습 방식을 제안하여 다양한 task에 최소한의 구조 변경을 통해 fine-tuning이 가능한 구조를 제안합니다. GLID는 위의 Figure 2에서 확인하실 수 있습니다.
1. Generalist Encoder-Decoder Pre-training
pre-training과 fine-tuning 모델의 구조 gap을 최소화하며 pre-training의 장점을 최대한 가져가기 위해 본 논문은 downstream task에 바로 적용이 가능한 generalist encoder-decoder 구조를 제안합니다. 입력 이미지 x \in \mathbb{R}^{H⨉W⨉3}가 주어졌을 때, 이미지 인코더 Enc로 시각적 feature를 추출하고, query 기반의 transformer deocder인 Dec를 통해 최종 feature를 생성하고 linear head H에 따른 target predictionP를 생성합니다.
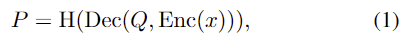
Q는 query를 의미하며, 모든 task를 위의 식(1)로 공식화합니다.
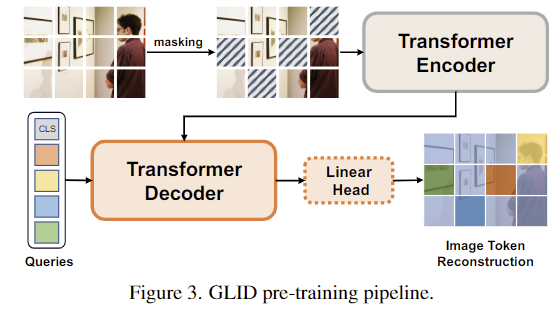
GLID의 사전학습 파이프라인의 위의 Figure 3을 통해 확인하실 수 있으며, 저자들은 Masked Image Modeling(MIM) 방식을 통해 encoder-decoder를 사전학습합니다. 입력 이미지가 주어졌을 때, 이미지를 패치로 나누고, 이를 이미지 토큰으로 변환한 뒤, random mask M를 적용하여 입력 토큰의 일부를 마스킹합니다. 이후, visual encoder를 통해 마스킹되지 않은 영역에 대해 MAE(masked auto encoder)를 적용합니다. decoder의 구조를 downstream task에 사용되는 decoder와 일치시키기 위해 MIM을 “query-to-answer”문제로 재구성하고 query기반의 transformer decoder를 활용하여 마스킹 된 토큰을 decoding합니다.
decoder의 입력 query로 여러 mask tokens [M]을 이용하며, 이때 위치 정보를 함께 임베딩합니다. 또한, 전체적인 representation을 파악하기 위해 0번째 위치에 [CLS] token을 추가합니다. 즉, pre-training을 수행하는 동안의 query Q=[CLS, M_1, M_2,...,M_N]이 되며, 이때 N은 마스킹된 패치 수를 의미합니다. decoding 이후에는 linear transformation head를 이용하여 decoding 된 query representation을 target prediction으로 변환합니다. pre-training에서는 이미지를 reconstruction하는 것을 목표로 하며, 예측된 prediction P를 target 픽셀값 P^t와 비교하여 MSE loss를 적용하여 학습을 수행합니다.
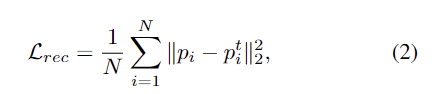
- p_i: reconstruction된 값
- p_i^t: 원본 픽셀 값
이러한 방식으로 generalist encoder-decoder를 사전학습을 진행하며, 기존의 MAE 기반의 방식들이 decoder를 사용하지 않는 것과는 다르게 해당 방법론에서는 decoder 또한 downstream task에 활용하여 fine-tuning을 수행합니다. 저자들은 기존의 MAE 기반의 방식들이 decoder를 스크레치 레벨에서 다시 재학습하기 때문에 대규모 데이터로 사전학습된 모델의 장점을 충분히 활용할 수 없다는 것을 다시 한번 언급하며, 이러한 방식과 비교했을 때, 해당 방법론은 decoder에 최상단 레이어만 변경하므로 사전학습의 장점을 충분히 가져갈 수 있음을 강조합니다.(방법론상 pre-training과정은 크게 다른점은 없는 것으로 보입니다.)
2. Fine-tuning on Downstream Tasks
앞의 과정을 통해 사전학습된 GLID 모델을 downstream task인 object dtection, segmentation, pose estimation, depth estimation에 적용하기 위해 “query-to-answer”문제로 모델링합니다. GLID task를 fine-tuning하기 위해, 최상단 레이어를 task에 특화된 linear layer로 변경한 뒤, 각 task별로 다른 query-answer쌍을 이용해 학습을 수행합니다.
downstream task의 query 수를 M이라 하고(task마다 다름), M개의 query는 사전학습 모델을 더 잘 반영하기 위해 global representation을 나타내는 [CLS] token값을 이용하여 초기화됩니다. 초기화는 아래의 식(3)으로 이루어지며, [CLS] token에 학습가능한 embeddings를 더하여 표현됩니다.
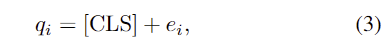
- q_i: i번째 query
- e_i: i번째 학습 가능한 embeddings, 0으로초기화되어있음
이제 각 task별로 answer를 어떻게 구성하였는 지 살펴보겠습니다.
- Object Detection
- DETR 방식을 따라 객체 instance를 query로 표현하며,
- target prediction은 바운딩 박스와 클래스의 확률로 나타납니다. P=\{[bbox_i, cls_i]\}^M_{i=1}
- Image Segmentation
- Mask2Former 방식을 따라 쿼리와 feature map 사이의 내적을 통해 각 픽셀마다 특정 마스크(클래스)에 속하는지를 예측하게 됩니다.
- 즉, query로부터 카테고리 수 만큼의 차원을 가진 mask embeddings와 클래스를 예측합니다. P=\{[f^s_i, cls_i]\}^M_{i=1}, f^s_i \in \mathbb{R}^C
- 이렇게 예측된 mask embeddings는 1/4 크기의 backbone feature f^b \in \mathbb{R}^{ {H \over 4} ⨉ {W \over 4} ⨉ C}와 내적한 뒤 시그모이드 activation을 적용하여 이진 마스크 S를 얻게 됩니다.
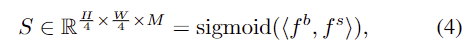
- Depth Estimation
- AdaBins와 BinsFormer는 depth regression 문제를 “classification-regression” 문제로 공식화 한 방식으로, 연속적인 값을 바로 예측하기보다 depth에 대한 bin에 대한 확률 분포를 예측한 뒤, bin center를 구해 이를 선형결합하여 depth를 추정하는 방식입니다.
- 즉, query로부터 depth 를 추정하기 위한 bin과 embeddings를 예측합니다. P=\{[l_i, z_i]\}^M_{i=1}, l_i \in \mathbb{R}, z_i \in \mathbb{R}^C
- 이렇게 예측된 값은 AdaBins의 depth maps을 구하는 방식에 따라 먼저 bin의 centers를 아래의 식(5)로 구합니다. 이때, c(l_i), d_{max}, d_{min}은 각각 i번째 bin의 중심,최대,최소 depth를 의미합니다.
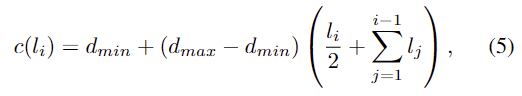
- 그 다음, 확률분포 P^d는 bin embeddings와 1/4 크기의 backbone feature f^b \in \mathbb{R}^{ {H \over 4} ⨉ {W \over 4} ⨉ C}와 내적 후 softmax함수를 적용하여 구합니다.
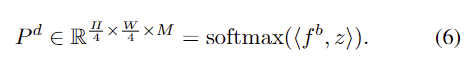
- 최종 depth map은 bin center의 선형결합을 통해 구해집니다.
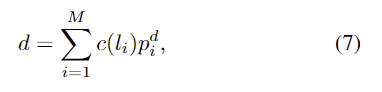
- Pose Estimation
- heat map 기반의 pose estimation 방법론인 ViTPose를 기반으로 진행됩니다.
- 즉, query로부터 keypoint에 대한 heat map을 구하기 위한 C차원의 feature vector를 출력합니다. P=\{f^k_i\}^M_{i=1}, f^k_i \in \mathbb{R}^C
- 이때 pose heatmap은 1/4 크기의 backbone feature f^b \in \mathbb{R}^{ {H \over 4} ⨉ {W \over 4} ⨉ C}와 내적하여 구해집니다.
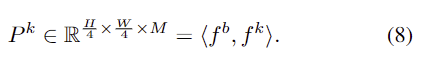
앞서 설명한 downstream task로 예측된 값을 GT와 비교하여 fine-tuning을 수행합니다.
Architecture
GLID는 Swin Transformer를 visual encoder로 사용하여 여러 scale의 feature map을 만들어냅니다. (이렇게 만들어진 feature map 중 1/4 scale의 backbone feature가 downstream task에서 활용됩니다.) 여기에 추가로 서로 다른 scale의 feature map들 사이의 상호작용을 위해 Bi-FPN 구조를 적용하였으며, multi-scale feature map들은 decoder를 거쳐 최종 prediction을 생성하게 됩니다.
Experiments
GLID가 다양한 task에서 효과가 있는 지 검증하기 위해 먼저 ImageNet-1K 데이터 셋으로 self-supervised 방식으로 사전학습한 뒤, 각 task별로 fine-tuning을 수행합니다. object detection과 pose estimation은 COCO 데이터 셋을 이용하였으며, semantic/instance/panoptic segmentation에는 ADE20K, depth estimation에는 NYUDepth-v2 데이터 셋을 이용하였다고 합니다.
Evaluation Metrics
- Semantic/Instance/Panoptic Segmentation
- Semantic : mean Intersection over Union(mIoU) _GT와 예측 마스크 사이의 IoU
- Instance : mean average precision (mAP)_mIoU를 구한 뒤, 0.5~9.5까지 0.05 간격으로 임계치를 설정하여 AP를 계산함
- Panoptic : panoptic quality (PQ)_segmentaion 퀄리티인 mIoU와 recognition 퀄리티인 F1 score를 곱하여 구한 값
- Depth Estimation
- root mean square error (RMSE)
- mean absolute relative error (REL)
- Pose Estimation
- mAP(AP^{kp})
- Object Detection
- mAP(AP^{bbox})
1. Comparison with pre-training methods
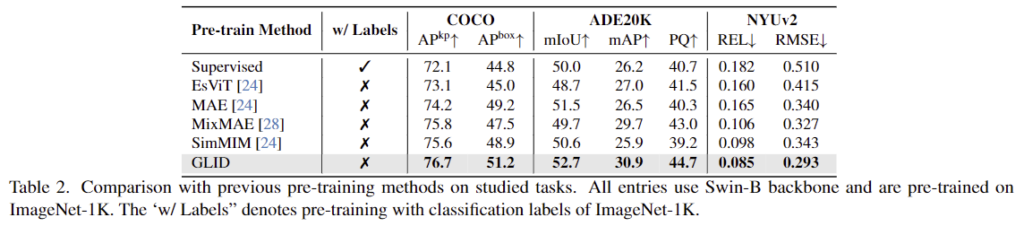
우선 해당 논문은 기존의 사전학습 방식의 장점을 충분이 활용하지 못한다는 점을 해결하기 위한 논문이므로 사전학습 방법론들간의 비교를 수행하였습니다. 동일한 구조의 backbone으로 다양한 downstream task에 적용한 결과를 Table 2에 리포팅하였으며, 모든 방법론에서 GLID가 SOTA를 달성하였습니다. 이를 통해 저자들이 제안한 방식이 다양한 vision 작업에 일반화 가능한 사전학습 방식임을 입증하였습니다.
2. Comparison with specialists and generalists
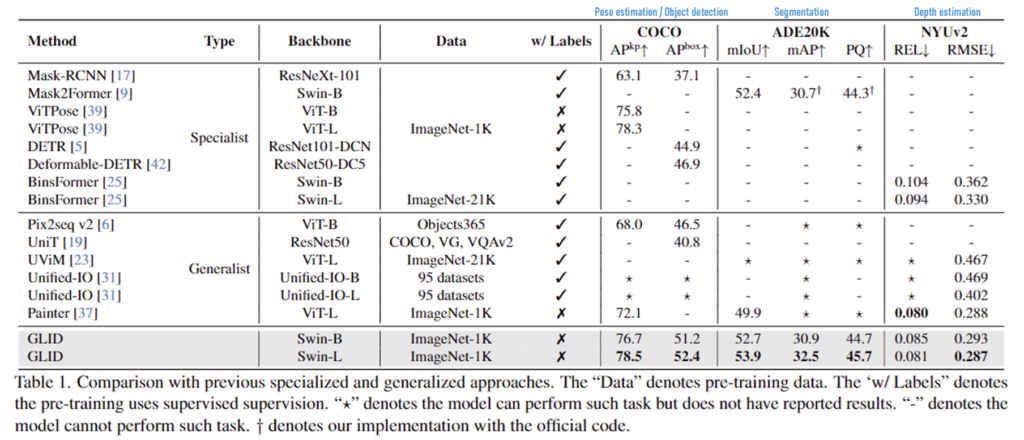
또한 저자들은 각 downstream task별로 특화된 모델들과의비교를 수행하였습니다. 상단의 파란색 글씨가 각 task에 해당하며, 대부분의 방법론이 task에 특화된 모델보다 좋은 성능을 보였으며, Depth estimation에서는 REL 지표에서 최대 성능과 유사한 성능을 달성하였다는 것을 통해 해당 방법론이 범용성을 검증하였습니다. 또한, 사전 학습을 위해 대규모 데이터 세트를 사용하는 기존의 방식과 비교했을 때, GLID는 ImageNet-1K만을 사용하여 더 적은 사전 학습 데이터로도 성능이 더 능가할 수 있음을 어필합니다.
3. Results of Multitask fine-tuning
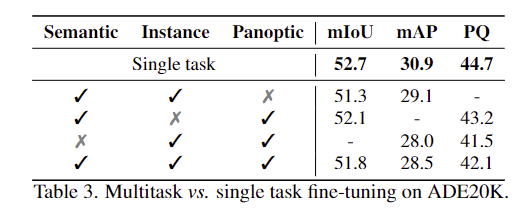
다른 task와 다르게 segmentation은 학습 과정에서 3가지 Segmentation을 multitask fine-tuning을 하였다고 합니다. 이는 task별로 linear head를 제외하고 나머지는 모두 파라미터를 공유하도록 함께 학습을 진행한 것으로, 이러한 multitask fine-tuning방식의 효과를 확인하기 위한 실험입니다. Table 3을 통해 각 task를 별도로 학습할 경우(Single task) 가장 좋은 성능을 보이는 것을 확인하였으며, 이를 통해 각 task가 학습에 서로 방해가 된 것으로 분석하였습니다.
4. Ablation studies
Load partial pre-trained weights
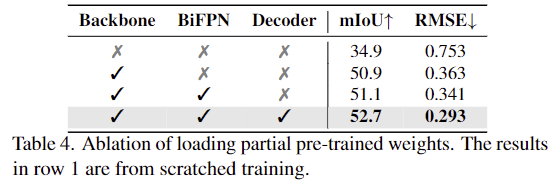
사전학습된 모델을 부분적으로 load하는 실험을 통해 generalist encoder-decoder의 사전학습 중요성을 분석하기 위한 실험으로, 가중치를 불러오지 않는 경우는 랜덤한 값으로 초기화하여 fine-tuning을 수행하였다고 합니다. 실험 결과 사전학습된 모델을 많이 load 할 수록 성능이 점차 향상되었으며, 기존 연구들처럼 backbone만을 사전학습하는 것에 비해 decoder도 함께 사전학습하여 사용하므로써 성능이 개선됨을 보였습니다.
Decoder depth
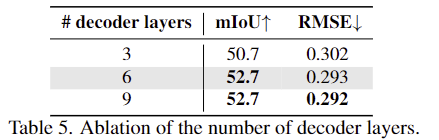
decoder의 layer 수에 따른 성능을 분석한 실험결과로, 3,6,9 개의 decoder layer로부터 fine-tuning을 수행하였다고 합니다. 실험결과 3개를 사용하는 것은 성능의 저하를 가져오며, 6개를 9개로 늘릴 경우 성능에는 유의미한 개선이 이루어지지 않고 연산량이 증가하게 된다는 것을 확인할 수 있습니다.
Fine-tuning with limited data
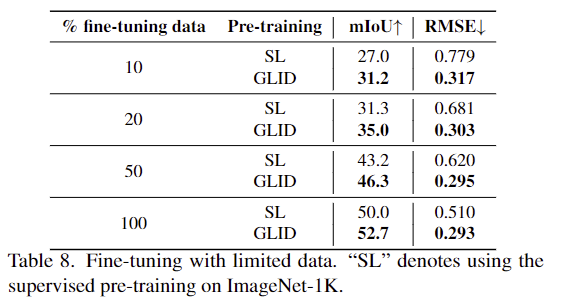
해당 실험은 fine-tuning 시 데이터의 제한이 있을 경우의 성능 변화를 supervised 방식(SL)과 비교한 것으로 저자들에 따르면 fine-tuning 시 적은 데이터를 사용할 경우 GLID는 사전학습된 정보를 활용할 수 있어 디코더를 처음부터 학습해야하는 SL보다 좋은 성능을 달성할 수 있다고 분석합니다.
Qualitative Evaluation
1. Query’s cross-attention maps on different tasks
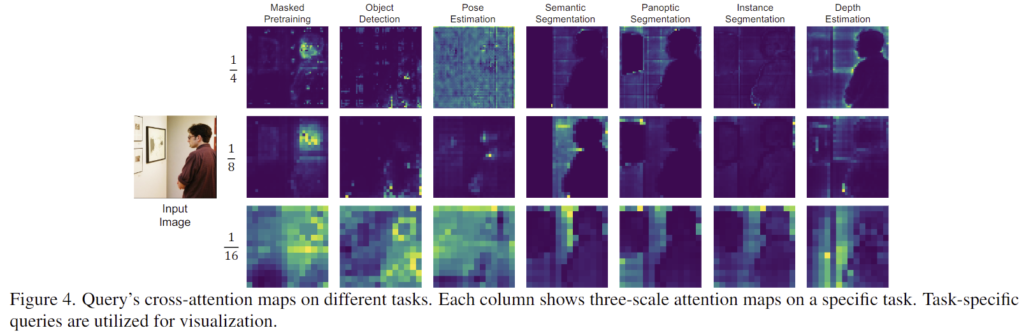
다양한 query의 cross-attention map을 시각화 한 것으로, 각 task별로 다른 영역에 활성화가 되어있는 것을 볼 수 있습니다. 특히 사전학습 과정인 Masked Pretraining에서는 reconstruction을 위해 local한 영역에 집중이 되도록 학습되었으며, object detection과 pose estimation은 특정 지점에 집증된 결과를 보입니다. 또한 segmentation과 depth estimation은 전경과 배경 영역이 구분되는 결과를 보여줍니다.
2. Convergence curves
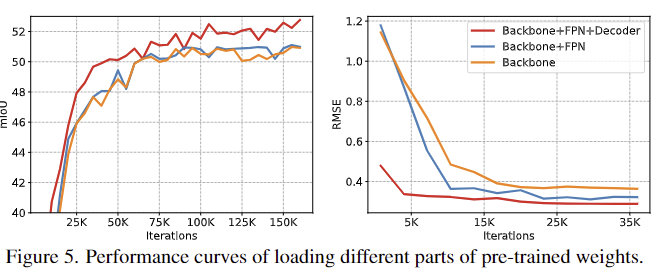
Figure 5는 segmentation과 depth estimation에 사전학습된 가중치를 부분적으로 활용하였을 때 수렴 속도를 나타낸 것으로, 더 많은 pre-trained weight을 사용했을 때 빠르게 수렴하고 성능이 더 좋은 경향을 보이는 것을 확인할 수 있습니다. 이를 통해서도 pre-training의 장점을 활용하기 위해 구조를 최소한으로 변경한 저자들의 방식이 효과가 있음을 보였습니다.
해당 논문은 사전학습된 모델의 이점을 활용할 수 있도록 하는 것에 초점을 맞춘 논문으로, 다양한 task를 유사한 구조로 적용할 수 있도록 architecture를 설계하였으며, 실험을 통해 저자들의 방식의 효과를 입증하였습니다.
안녕하세요, 이승현 연구원님. 좋은 리뷰 감사합니다.
MAE 사전학습을 디코더에 확장해서 다양한 downstream task에 활용할 수 있게 한 것이 흥미롭네요.
어떻게 보면 기본적인 질문으로 느껴질 수 있는데요, 리뷰를 읽다가 다른 task들은 이해하는데 어려움이 없었지만 제가 pose estimation task에 대해 잘 몰라서 GT와 예측값이 어떻게 구성되는지, 또 transformer 구조로 어떻게 예측하는지 감이 잘 안잡힙니다. 간단하게 예측 정답값이 어떻게 주어지는지 설명해주시면 감사하겠습니다.
댓글 감사합니다.
해당 연구에서 의미하는 Pose Estimation은 사람의 keypoint를 예측하는 것 입니다. 여기서 사람의 keypoint는 관절로 설정된 것으로 알고있습니다. 즉, 이미지로부터 사람의 관절에 해당하는 keypoint들을 예측하는 것을 목표로 하며, 여기서 heatmap은 keypoint를 기반으로 가우시안을 적용한 것으로 이해하시면 될 것 같습니다.
pose를 예측하는 것에 대해 설명을 드리자면, 먼저 transformer를 통해 C차원의 feature vector를 생성하고, 이를 backbone의 feature와 내적하여 keypoint를 예측하게 됩니다. H/4 x W/4 의 feature map에 대한 가중치가 생기는 것 입니다.
안녕하세요. 리뷰 잘 읽었습니다.
처음 Introduction에서 설명해주신 부분이 인상 깊어 읽다 보니, 의문점이 드는데요~
본 논문은 설명해주신 “sub-architecture는 복잡한 구조를 가지고 있으며, 각 task별 데이터로 스크레치 레벨부터 학습을 진행해야 한다는 점에서 대규모 데이터로 사전학습되었다는 장점을 활용할 수 가 없게 됩니다. “가 아니라는 의미일까요? 제가 읽기에는 결국 각 Expert(linear layer)에 대해, 태스크 별 학습해야한다는 점은 동일하게 느껴져서요~ 그 스크래치가 백본부터 임을 의미하시는건가요?? 만약 맞다면, 얘네는 그럼 downstream task에서 백본을 freeze한다는 의미일까요?
질문 감사합니다. 각 task별 데이터로 스크레치 레벨부터 학습해야한다는 점에서 사전학습의 장점을 가져갈 수 없다는 의미가 맞습니다. task별 학습하는 점은 동일하지만, encoder와 decoder는 거의 동일한 형태로 사전학습이 되고, 가장 마지막의 일부 레이어만을 변경하였다는 점에서 저자들은 사전학습의 장점을 최대한 가져가고자 하였습니다. 해당 논문에서 이야기하는 스크래치 레벨의 학습은 백본 뿐만 아니라 디코더 전체에 대한 스크레치 레벨의 학습을 포함하고 있는 것으로 이해하였습니다. 또한, 논문에서는 명시적으로 freeze라고 하지는 않지만, LinearHead만을 task별 Head로 변경한다는 점에서 상인님이 이해하신 것 처럼 백본은 freeze하는 것으로 이해하였습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
self-supervision 방식에는 여러 종류가 있는데 그 중 비교적 간단한 Masked Image Modeling(MIM)의 방식을 선택한 이유에 대한 언급이 있나요? 성능이나 설계의 간편성 때문에 MIM 방식을 선택한 건가요?
그리고 기존에는 사전학습된 encoder만 사용을 하고 decoder는 사용을 안한다고 하셨는데, 그렇다면 사전학습을 진행하면서 decoder를 사용하는 논문은 이번 연구가 처음일까요? 그게 아니라면 이전 방법론들과 어떤 차별성이 있는지 궁금합니다.
감사합니다.