
Abstract
CNNs기반의 PD는 2가지 큰 문제에 봉착한다.
첫쨰,
보행자 일반적인 물체 분류와 비교하여 보행자는 배경과의 구분이 힘들다.
따라서 낮은 해상도에서 사람도 구분하기 힘든 positive와 비슷하게 생긴 negative들이 존재한다.

둘째,
crowded scene에서 사람 각각의 위치를 찾는데 어려움이있다. 많은 False positive를 만들게 된다.
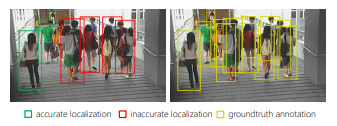
이를 위해 논문은 더 다양한 feature들의 인풋 채널을 만들고 학습하는 모델을 제안하고, Hyper Learner라 명한다. 어떤 추가적인 특징이 CNN기반의 detector에게 적합하고, 어떻게 적용해야 좋은 효율을 내는지를 연구한다.
Hyper Learner
Hyper Learner는 세가지의 추가적인 채널을 제안한다.
Apparent-to-semantic channel, depth channel, temporal channel이다.

Hyper Learner는
KITTI datase을 학습에 사용한다.
Faster R-CNN 모델이다.
Image Net으로 pretrain시킨 VGG-16을 backbone으로 사용한다.
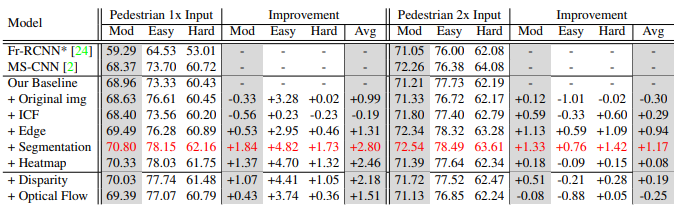
여러 추가적인 channel을 추가시켰을때의 성능
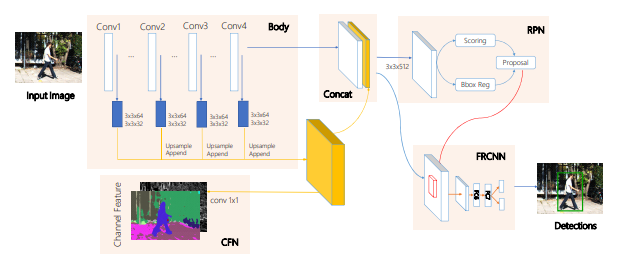
Hyper Learner의 구조
어떤 추가적인 정보를 사용하는지, 그것을 어떻게 얻는지에 대한 설명은 논문에 나와있었지만, 이를 모델에 어떻게 적용하는지에 대한 설명은 자세히 나와있지 않았아(내가 미쳐 못 읽었거나, 읽었는데도 모를 수도 있다.) 아쉬웠다.
학습할때, 이러한 Edge, Segmentation과 같은 low level feature들을 CNN에 함께 학습시키면 성능이 오를 것이라고 생각했었는데, 생각만큼 큰 향상을 보이진 않아 아쉬웠다.
보행자 인식은 자율 주행 자동차에 적용하기위함이 가장 큰데, 이를 위해선 detection 속도 또한 따라주어야 한다. 이렇게 여러 단계의 과정을 거쳐 detect하면 정확도는 높을지라도, 속도대비 performance는 한참 떨어지지 않을까 생각한다. 처리속도는 논문에 나와있지 않았지만, 정확도의 상승폭이 아주 크게 높지 않았기 때문에 좋은 모델이라고 보긴 힘들지 않을까 생각한다.
결국 논문에서 이야기하는건 보행자인식을 위해서 더 많은 정보를 제공하기위해 다양한 채널(depth, edge, segmentation, heatmap 등등)을 추가하겠다는건가요?? 전통적인 보행자인식 방법론에서도 Integral channel features라는 방법으로 비슷한 효과를 나타냈던 논문있었습니다. 해당 논문도 비슷한 컨셉으로 생각되는데 중요한건 저런 다양한 채널은 어디서 얻어오는건가요? 논문에 나와있다고 했는데 리뷰에는 나타나지 않아서 질문드립니다.
성능 표 위에 여러 추가적인 channel을 추가하였다고 하였는데 무엇인지 더 자세히 말씀해 주시면 감사하겠습니다!