
논문 : 링크 / Github : 링크 / 참고 : 링크
안녕하세요, 허재연입니다. 오늘 다룰 논문은 2019년 POSTECH CVlab에서 CVPR에 게재한 Relational Knowledge Distillation 입니다. 평소에 논문을 서베이 하거나 새로운 방법론을 고민하면서 검색을 할 때면 Knowledge Distillation에 대한 내용이 자주 나왔지만 제가 해당 개념을 잘 몰라서 이해가 힘들었는데요, 이에 대한 기본적인 컨셉을 이해하기 위해 내용이 어렵지 않고 인용 수도 많은 관련 논문을 읽어보았습니다. 그럼 리뷰 시작하겠습니다.
Introduction
먼저 Knowledge Distillation이 무엇인지부터 간단하게 짚고 넘어가겠습니다. Knowledge Distillation은 주로 특정 모델에 representation을 학습시키거나, 모델 압축을 목적으로 사용될 수 있습니다. 일반적으로 딥러닝 모델은 그 구조가 크고 깊을 수록 잘 동작하는(성능이 좋은) 경향성이 있는데, (edge device에서 동작시키기 위해 계산 자원이 적은 모델이 필요한 상황 등) 보다 작은 모델을 활용해야 하는 상황이 있습니다. Knowledge Distillation은 이 때 크기가 큰 Teacher Model을 학습시키고 이 Teacher Model의 지식을 작은 크기의 Student Model에 증류(전이)시키는 것을 목표로 합니다.
(특히 pruning 및 quantization과 함께 edge device를 위한 computation resource를 줄이는 방법 중 하나로 자주 사용됩니다)
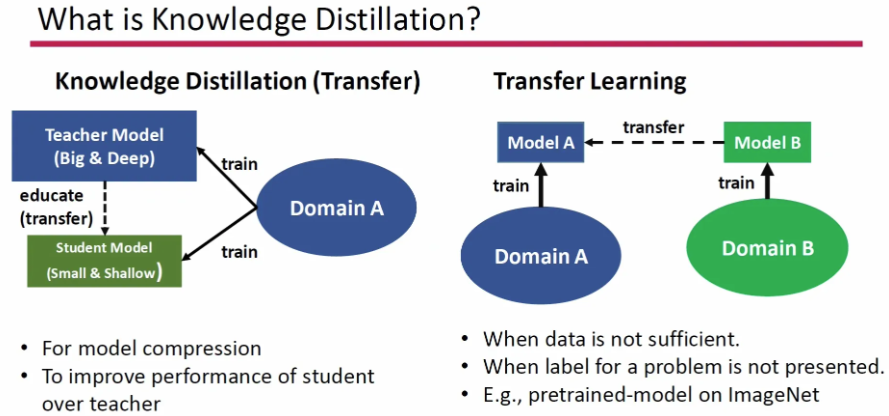
여기서 우리는 두 가지 질문을 던질 수 있습니다. (1) 학습된 모델의 knowledge는 무엇으로 구성되는가? (2) 그렇게 학습된 지식은 다른 모델에 어떻게 전이 할 것인가? Knowledge Distillation 방법론 들은 학습된 input-output간의 매핑 관계를 knowledge라고 가정하고, teacher model (마지막 layer 혹은 hidden layer 등 다양한)output을 target으로 삼아 student 모델을 학습 시켜 왔습니다.
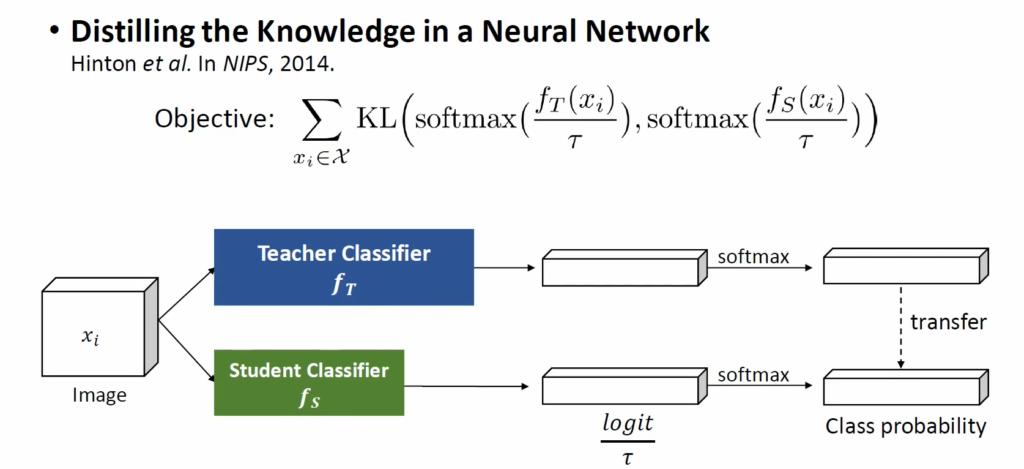
그럼 실제 학습은 어떻게 진행될까요? 제프리 힌튼 교수 연구팀이 2014년 NIPS에 게재한 Distilling the Knowledge in a Neural Network 논문에서 딥러닝 KD의 기초가 될 수 있는 방법론을 제안했는데, 해당 방법론은 위 그림에서 보다시피 classifier의 output(class probability)를 transfer하는 방식이었습니다. 큰 teacher classifier와 작은 student classifier가 있을 때, teacher classify logit과 student classify logit을 (temperature parameter로) 정규화 한 뒤 class probability를 transfer하는 방식으로 teacher-student 간 class probability가 동일하게 되도록 학습을 진행했습니다. 위에 보면 KL divergence를 objective로 활용했는데, KL divergence가 두 확률 분포 간 차이를 모델링한다는 것을 생각해보면 결국 동일 input에 대해 student model의 output이 teacher network의 output 분포를 따라가도록 학습을 진행한다고 생각하시면 되겠습니다. 해당 방법을 통해 크기는 작지만 teacher network와 유사한 성능을 내는 모델을 학습하는 방법을 제안하였습니다.
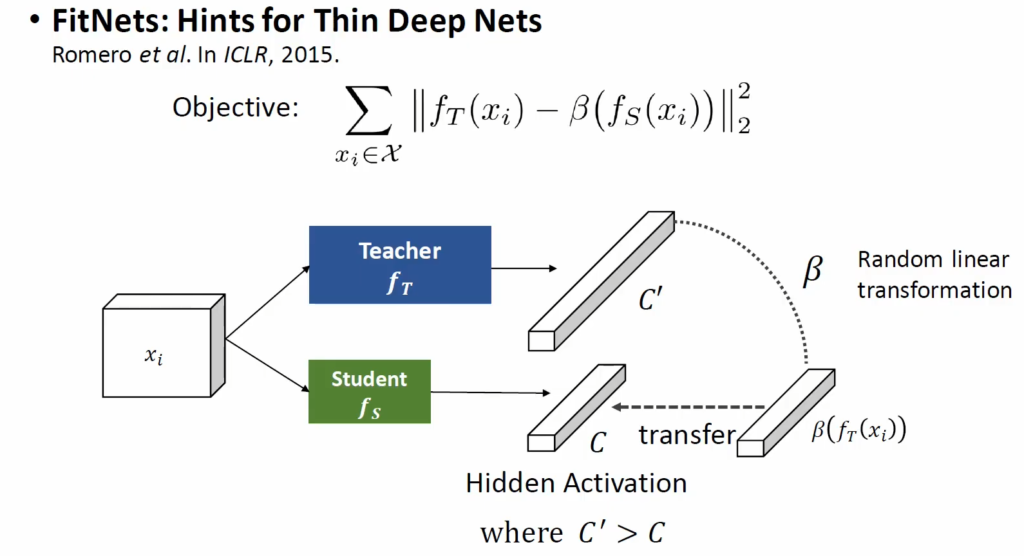
또 다른 방법으로는 output logit이 아니라 hidden activation을 transfer 하는 방법이 있습니다. 큰 teacher의 hidden activation에 해당하는 벡터 C’과 student의 hidden activation C가 있을 때, C와 C’가 동일하게 만드는 것입니다. FitNets 라는 방법론에서는 이 때 C와 C’ 벡터 간 차원 수가 달라 L2 loss로 바로 학습시킬 수 없어서 random linear transformation을 수행하는 random linear layer β를 사용해 C’를 C와 같은 크기를 가지는 벡터로 변환한 다음 둘이 같은 값을 가지도록 학습시켜 hidden activation 값을 transfer하였다고 합니다.
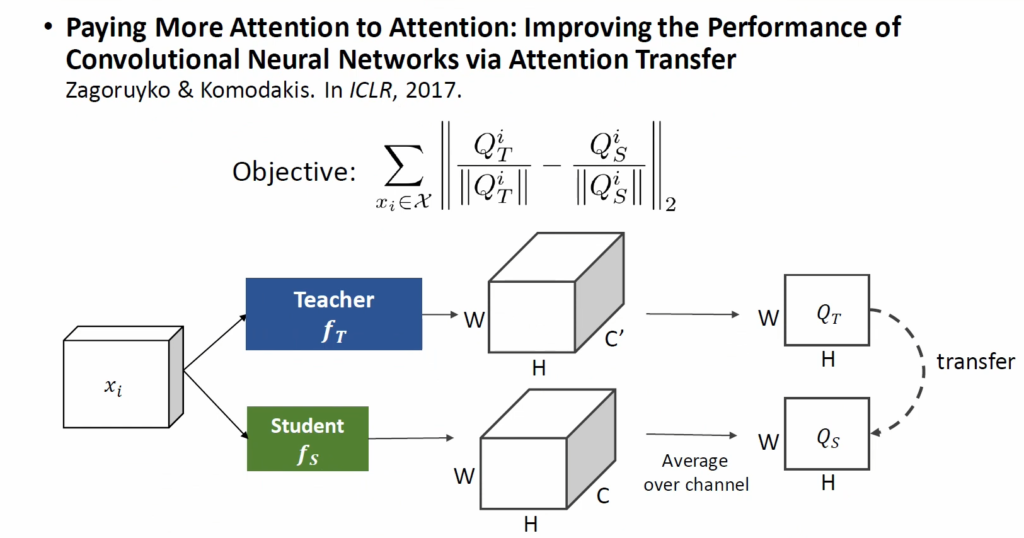
또 다른 방법으로는 attention을 transfer하는 방법이 있습니다. teacher와 student의 3D convolution output에 대해 channel-wise dimension 방향으로 average시켜 일종의 spatial attention map을 만듭니다. 이 attention map에는 모델이 이미지의 어느 부분에 집중하는지에 대한 정보가 담겨 있다고 가정하고 해당 정보를 transfer함으로써 크기가 큰 teacher network의 convolution layer knowledge를 작은 student network에 transfer하였습니다.
위에서 살펴본 3개의 논문은 모두 model compression을 목표로 하여 teacher model보다 작은 student network에 knowledge를 distillation했었습니다. 근데 관점을 바꾸어서 Student의 크기가 Teacher보다 작지 않다면 어떻게 될까요? 신기하게도 동일한 크기의 모델에 대한 KD를 수행했을 때 student의 성능이 teacher를 뛰어넘는 것을 발견한 논문들도 있었습니다(학생이 선생님보다 우수해진 청출어람으로 볼 수 있죠).
[논문1] [논문2] 에서는 student와 teacher의 크기를 동일하게 하였을 때 knowledge distillation 결과를 리포팅합니다. classification task에 대해 teacher classifier의 class probability를 student model의 GT 삼아 student를 학습시키면 student 모델이 teacher classifier보다 작지 않은 폭으로 성능이 개선되는 현상을 발견하였습니다. 두 논문에도 정확히 원인을 밝히진 않고 teacher의 class probability가 원핫 벡터가 아니라 일종의 class간의 상관관계에 대해 정보를 담고 있는 soft label의 역할을 하여 해당 값을 활용하는게 더 학습에 도움이 될 수 있다.. 이런 느낌입니다.
논문으로 돌아와서, 결국 위의 논문들은 각각의 data example들에 대해 teacher의 output과 student의 output이 동일하게 되도록 학습하는 것을 목표로 합니다. 저자는 새로운 패러다임을 제시하는데요, 바로 ‘model의 output 그 자체가 아닌 각각의 example들이 어떻게 관계되는가’ 라는 관점으로 Knowledge Distillation 문제를 바라봅니다.
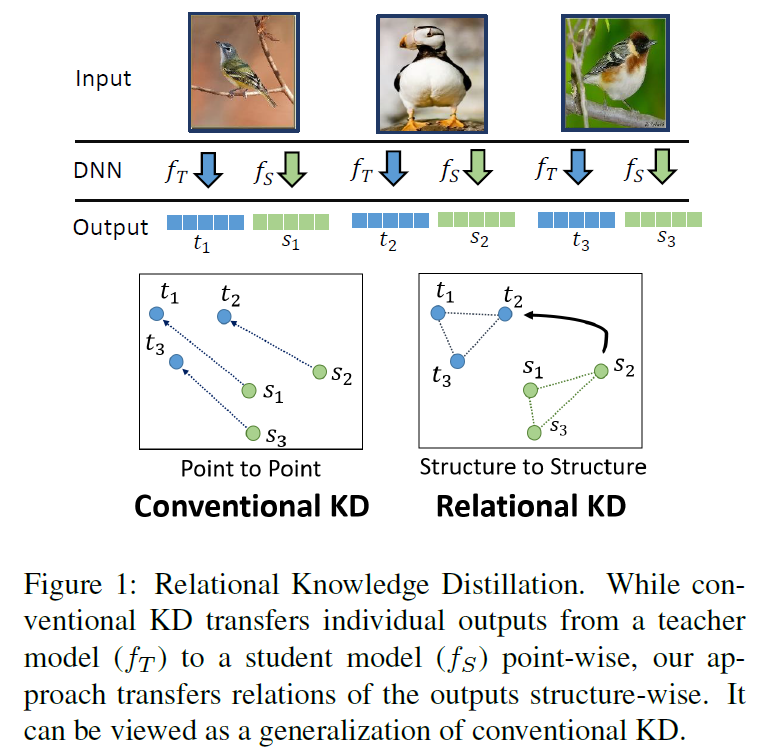
앞서 살펴본 conventional knowledge distillation은 teacher model의 individual output을 student model에 전이하고자 하며, 다음의 objective function을 최적화 하는 것으로 요약할 수 있습니다 :
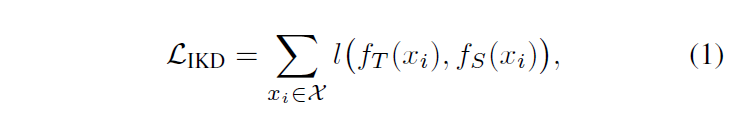
저자는 이런 기존 방법론들을 Individual Knowledge Distillation(IKD)로 부르고, 해당 논문에서 제안하는 KD의 패러다임을 Relational Knowledge Distillation(RKD)라고 지칭합니다.
이 둘은 학습된 모델의 knowledge가 무엇으로 구성되는지에 대한 관점을 다르다고 생각할 수 있는데, 각각 패러다임은 다음과 같습니다 :
- IKD : teacher에 의해서 각각 data point들이 어떤 output 값을 가지느냐를 knowledge로 해석
- RKD : output뿐만 아니라 teacher에 의해서 각각의 data point들이 어떻게 관계되는지 정보를 knowledge로 해석하고 해당 정보를 transfer.
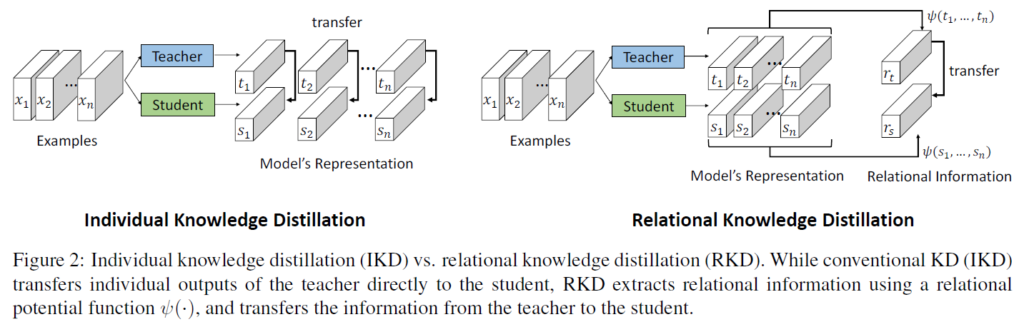
Method
저자들은 각각의 example 그 자체가 아닌, example 간 관계를 knowledge로 보고 이 관계를 transfer할 수 있는 새로운 Knowledge Distillation을 제안했습니다. 이를 Relational Knowledge Distillation(RKD)라고 지칭하는데, RKD는 input example들에 대한 teacher network의 출력값들의 상호 관계를 사용하여 structural knowledge를 transfer하는 것을 목표로 합니다. teacher의 output 간 relation을 모델링하는 potential function ψ을 이용해 relation 정보를 가지는 벡터를 얻고, student 또한 동일한 관계를 가지도록 학습을 시키게 됩니다. teacher와 student의 입출력을 각각 t_{mi} = f_{T}(x_{i}), s_{mi} = f_{S}(x_{i})로 표기하면 RKD의 손실함수는 다음과 같이 나타낼 수 있습니다 :
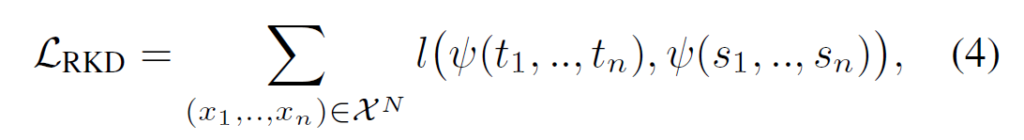
여기 수식에서 (x_{1}, x_{2}, .. ,x_{n})은 input들의 tuple입이며, ι은 teacher와 student 간 차이를 줄이도록 합니다. 결국 RKD의 핵심은 example들의 관계를 표현하는 potential function ψ이라고 할 수 있습니다. 해당 논문에서 저자들은 수많은 relation 중 embedding space 상에서의 간단한 구조를 transfer하는 distance-wise loss function과 angle-wise loss function을 제안하였습니다.
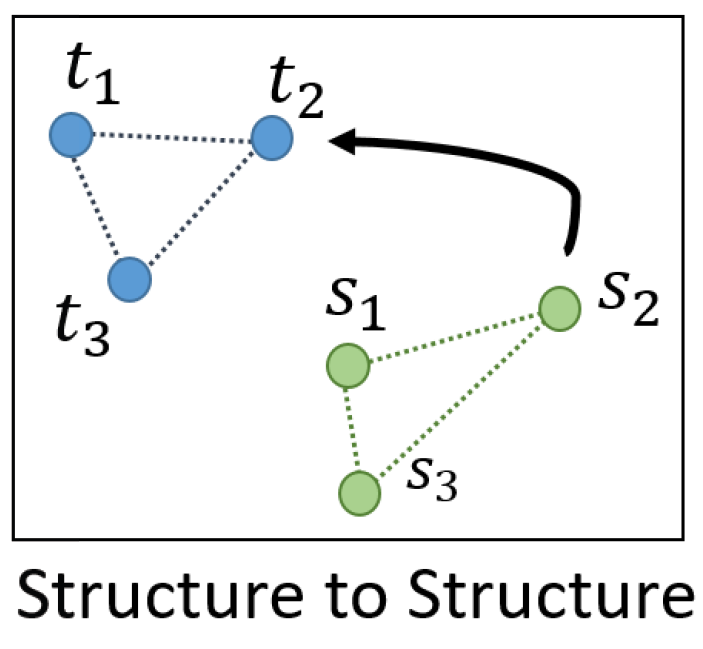
Distance-wise distillation loss(RKD-D)
distance-wise potential function은 주어진 example들의 pair 에서, angle-wise potential function은 주어진 example들의 triplet 간에서 계산됩니다. 임베딩 공간에서 point들의 상대적 거리를 transfer하기 위해, distance-wise function [/latex]ψ_{D}[/latex]는 output representation space에서 주어진 학습 example pair에 대해 다음과 같이 Euclidean distance를 측정합니다 :
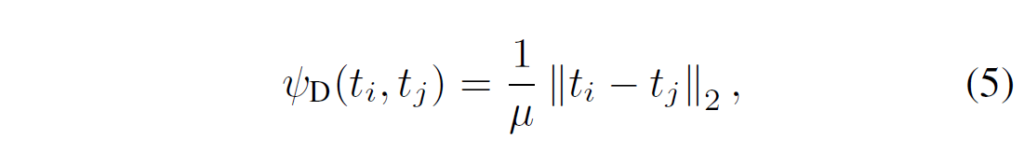
μ는 거리에 대한 normalization factor입니다. 다른 pair 사이에서 relative distance를 고려하기 위해, 저자들은 μ를 미니배치 내에서 샘플링되는 모든 pair의 평균 거리로 설정했다고 합니다.
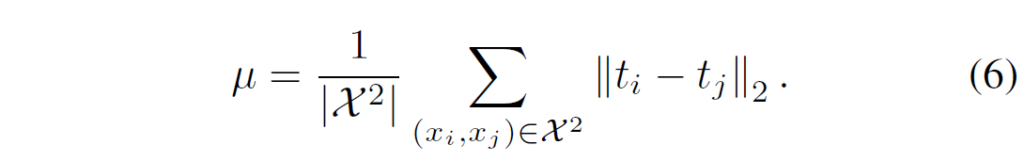
위 data point 간 관계를 나타낸 예시 그림에서 만약 t1,t2,t3 간 거리가 각각 3,4,5라면 (그 distance 값 자체가 아니라) point 간 distance 비율 관계가 student에서도 유지되도록 합니다. output dimension이 다른 경우 등 teacher distance와 student distance 값 자체의 scale이 다른 경우들이 있을 수 있기에 해당 정규화가 data point 간 관계를 잘 유지하도록 하는데 중요한 역할을 한다고 합니다.
결론적으로, 각 teacher와 student 모두의 distance-wise potential을 활용하여 distance-wise distillation loss는 다음과 같이 정의됩니다 :
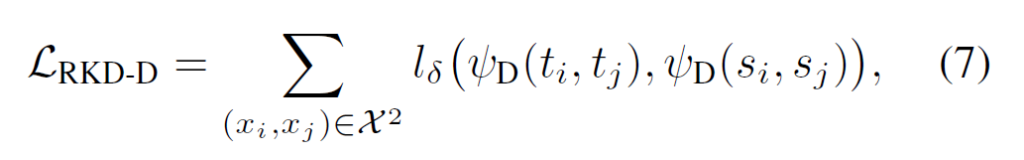
distance-wise distillation loss는 기존의 conventional KD와 달리 student의 output이 teacher output에 직접적으로 매칭되도록 강제하지 않고 출력값의 거리 관계 구조를 학습할 수 있도록 하였습니다.
Angle-wise distillation loss (RKD-A)
Angle-wise potential function은 말 그대로 3개의 point에 대해서 정의되는 각도 관계(cosine)에 대한 potential function니다. 점 t1,t2,t3에 대해 각 점 θ1,θ2,θ3의 각도를 다음과 같이 측정할 수 있을 것입니다 :
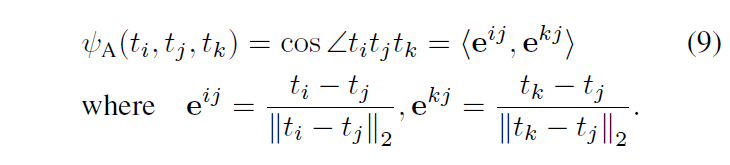
저자들은 teacher와 student 모두에서 angle-wise potential을 사용하여 다음과 같이 student와 teacher가 출력 값에 대해 동일한 각도 구조 관계를 갖도록 하는 Angle-wise distillation loss를 정의하였습니다 .
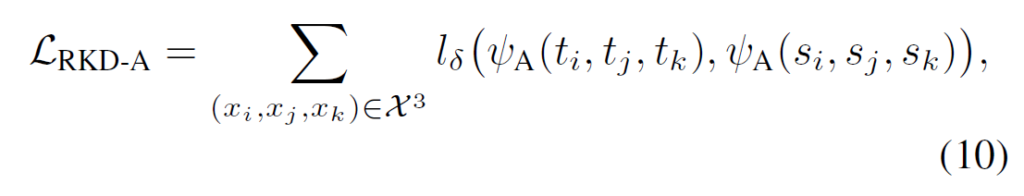
Training with RKD
RKD를 포함한 distillation loss function은 학습 과정에서 혼자서 사용할수도 있고, cross-entropy와 같은 task-specific loss function과 다음과 같이 함께 사용할 수도 있습니다.
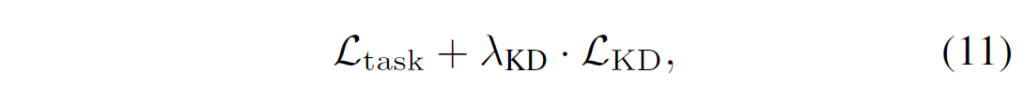
이 때 loss 간 비율은 람다 값으로 조정 가능합니다.
Distillation target layer
위와 같이 정의된 2개의 loss function은 relational knowledge가 중요한 embedding space나 hidden activation에 대해서는 적용이 가능하지만, 각각 individual 값이 중요한 layer에서는 적합하지 않다고 합니다. RKD 자체는 output들이 가지는 relation을 transfer하는 방식이지 그 output값들 자체는 보존하지 않기 때문입니다. 예를 들어 classification을 수행하는 softmax layer같은 곳에 RKD loss function을 이용해서 지식을 전이시키면 관계 정보들이 사라지기에 적용이 적합하지 않을 것입니다.
Experiment
Metric Learning
저자들은 이렇게 정의한 RKD loss function을 1. metric learning, 2. classification, 3. few-shot learning에서 평가하였습니다. 여기서 Metric Learning은 임베딩 네트워크를 학습하여 2개의 이미지가 주어졌을 때 두 이미지 사이 similarity distance를 측정하는것을 목표로 합니다. pair image가 주어졌을 때 각각의 relation이 얼마나 중요한지 평가할 수 있는 task이기 때문에 실험을 진행하였다고 합니다.
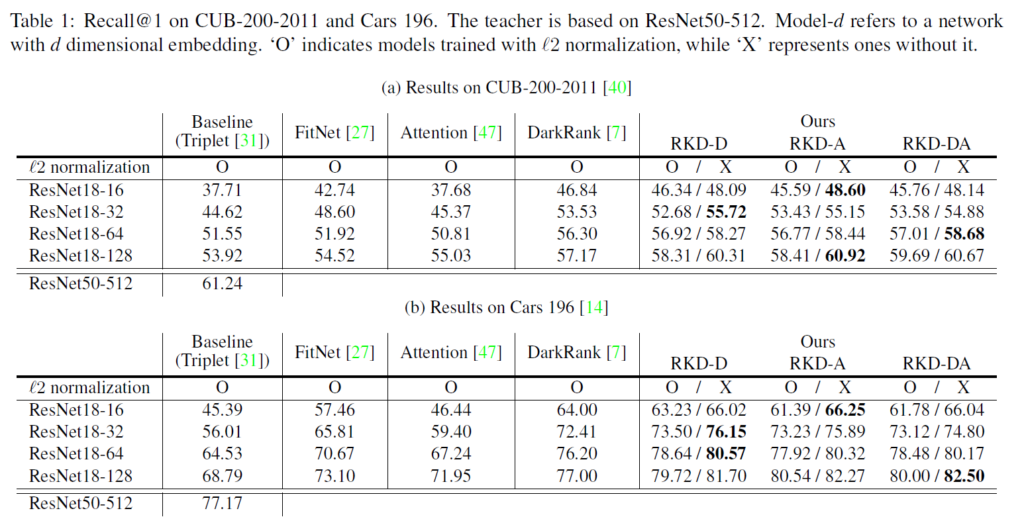
이러한 Metric Learning은 Image Retrieval을 이용하여 평가되었습니다. 임베딩 네트워크를 잘 학습시켰다면 쿼리가 주어졌을 때 가장 유사한(가까운) 이미지를 잘 retrieval 할 수 있을 것입니다. 데이터셋은 Cars 196, CUB-200-2011, Stanford Online Products라는 데이터셋을 사용하였다고 합니다. teacher network는 ResNet50을 백본으로 하여 embedding layer로는 512d fc layer를 활용했습니다. student는 ResNet18을 백본으로, 다양한 차원의 fc layer를 임베딩 계층으로 사용하였습니다. teacher는 metric learning에서 널리 사용되는 Triplet loss르 ㄹ사용하고, student의 경우 베이스라인으로는 triplet loss를, 그리고 추가적으로 제안된 distance, angle loss function transfer를 비교하였습니다.
결과적으로, Triplet 을 사용하면 차원 수를 낮출수록 retrieval recall이 급격히 떨어짐을 확인할 수 있었고, triplet과 RKD loss를 잘 조합하면 성능이 어느정도 유지됨을 볼 수 있습니다. 임베딩 레이어에서는 값 자체보다는 관계가 중요할 수 있으므로 RKD loss만 사용하여 실험을 진행하였고, triplet을 조합하기 않고 RKD만 사용했을 대 오히려 더 성능이 좋음을 확인할 수 있습니다.
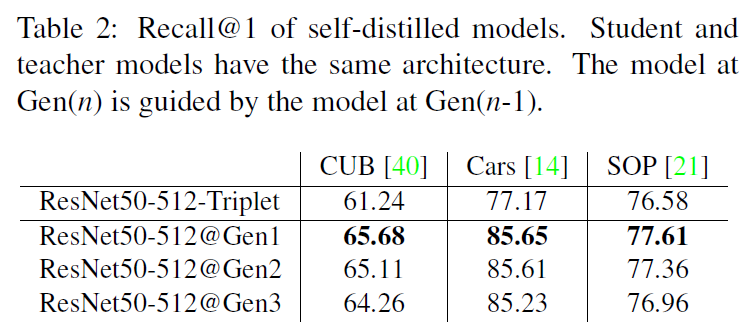
동일 크기 네트워크로 Self-Distillation을 진행한 실험입니다. 가장 윗줄은 Triplet loss로 학습했을 때 teacher model 성능이고, 이 모델을 initial teacher로 사용하여 RKD로 다음 generation 1의 student를 학습시켰습니다. 이후 이 모델을 teacher로 삼고 recursive하게 아래의 모델들을 RKD로 학습시켰습니다. 동일 네트워크로 KD 하였을 대 gen1에서는 gain이 있었지만 그 이후의 반복적 distillation에서는 성능 gain을 얻지 못하였습니다.
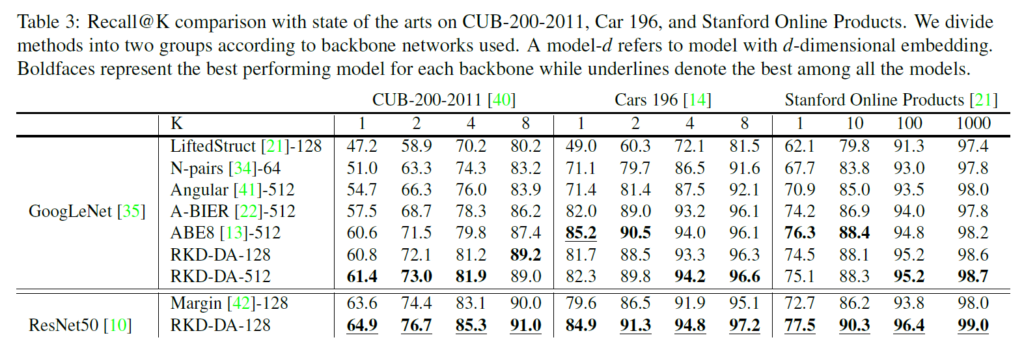
이렇게 성능이 오른 self-distillated 모델을 기존은 SOTA metric learning method들과 비교하면, backbone을 GoogLeNet, ResNet 사용했을 때 CUB 데이터셋에 대해서는 가장 높은 성능 기록하였습니다. Car 196과 Stanford Online Products에서는 두번째로 높은 성능을 달성하였습니다. 하지만 SOTA 모델의 경우 8개의 branch와 branch마다 각각 별도의 attention이 있는 복잡한 구조라고 하며, 제안한 구조보다 훨씬 많은 computing resource가 필요하다고 하네요.
Classification
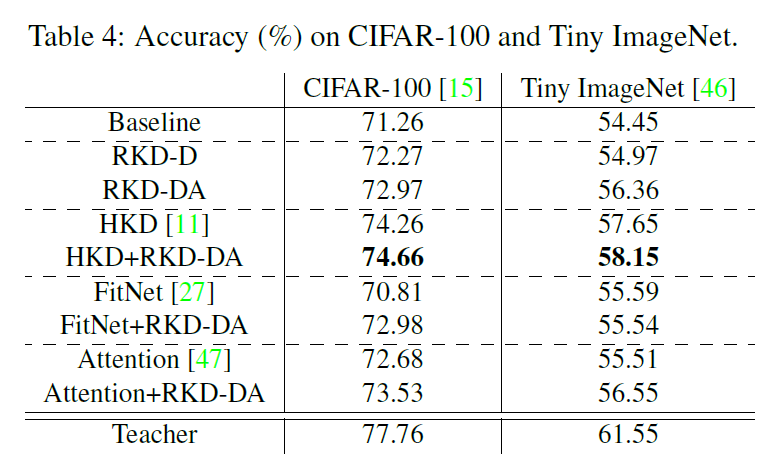
Classification Dataset은 CIFAR-100과 Tiny ImageNet이 사용되었습니다. 두 데이터셋 모두 RKD-DA와 HKD를 결합한 것이 가장 좋은 결과를 보였습니다.
Few-Shot Learning
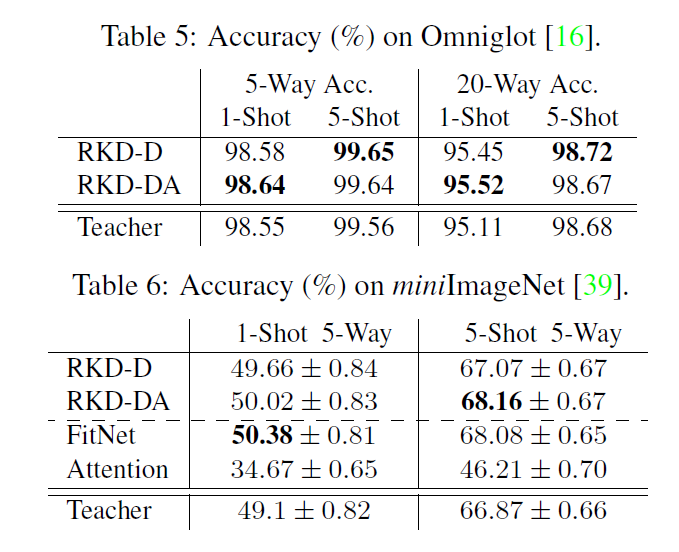
마지막으로 Omniglot, miniImageNet이라는, 저에게는 조금 생소한 데이터셋에서 few-shot learning이 평가되었는데요, Omniglot에서는 저자가 제안한 방법을 결합하였을 때 가장 좋은 결과를 보였으며, miniImageNet에서도 5-shot에서는 가장 좋은 결과를, 1-shot에서는 SOTA에 근접한 결과를 보였습니다.
처음으로 KD 분야를 다뤄보았습니다. 개념이나 task가 낯설어서 리뷰를 작성하는데 많은 시간이 걸렸네요.. 그래도 앞으로 KD 관련 개념이 나왔을 때 기본적인 컨셉을 알고 있으니 많은 도움이 될 것 같습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
최근에 Knowledge Distillation을 활용하는 연구들이 많아 궁금했던 내용인데 다뤄주셔서 흥미롭게 읽었습니다. 논문에서는 거리 기반과 각도 기반의 손실함수를 소개하고 있는데, Table1에서는 거리기반과 각도기반의 성능이 비슷한 것으로 보이는데 이후에는 각도기반의 성능에 대한 리포팅이 없네요. 특정 상황에서 거리기반과 각도 기반 중에 어떤 것을 사용하는 게 좋은 지에 대한 분석이 논문에 있었는지 궁금합니다.
추가로 KD 방법 자체가 연산량이 늘어날 것으로 예상되는데 추가적인 손실함수를 도입함으로 인해서 생기는 파라미터의 증가 혹은 연산 속도에 관한 저자의 고찰이 있었는 지도 궁금합니다.
감사합니다.
실험 성능표에서 RKD-DA는 distance, angle loss 2개를 모두 적용한 것입니다. RKD-D가 좋은 결과를 낼 때도 있지만 distance loss와 angular loss를 함께 적용한 RKD-DA가 좋은 결과를 보여주어 집중적으로 리포팅한 것으로 생각됩니다. RKD-D와 RKD-A각 loss에 대한 각각의 적용 분석 실험은 없었습니다.
연산량 관련해서도 각 sample들간의 각도 및 거리를 계산하는데 연산량이 늘 수 있을거라는 생각이 들긴 하지만 관련 언급이 없는것을 보니 아무래도 low-level의 코어 연구이다보니 그런 실용적인 요소들에 대한 고려는 덜한 것 같습니다.
좋은 리뷰 감사합니다.
성준님과 비슷한 질문이긴 합니다만, 개인적으로 distillation 관련 실험을 진행하면서도 항상 각도 관련 loss를 줘야할지 거리 관련 loss를 줘야할지 매번 고민이 됩니다. feature dimension이 매우 큰 (1024,,) 상황에서는 각도 기반이 더 안정성이 있다는 등의 이야기는 들은 적이 있긴 한데, 본 논문에서 언급하는 이론적인/실험적인 분석 혹은 고찰이 있다면 궁금합니다.
감사합니다.
본 논문에서 각도/거리 기반 loss 설정에 따른 분석적인 결과는 없는 것으로 보입니다. 하지만 normlization 관련 고찰은 있습니다. 기존의 triplet loss같은 경우 벡터 크기 자체를 줄여버리는 trivial한 최적화를 막기 위해 L2 norm을 적용합니다. 하지만 L2 norm을 적용하면 representation vector들이 모두 unit hypersphere위에 올라가버려 표현력에 제약이 생기는 한계점이 있습니다.
하지만 저자가 제안한 거리 비율 및 각도를 모델링하는 loss에서는 구조를 transfer하기 때문에 scale의 영향을 받지 않아 L2norm을 적용하지 않았습니다. Table1을 보시면 L2norm 적용 여부에 따른 성능이 있는데 적용하지 않은 것이 더 좋은 결과를 보여줌을 확인할 수 있습니다.
해당 내용이 distillation 방법을 고민할 때 도움이 되면 좋겠네요.
안녕하세요 재연님,
최근에 knowledge distillation 개념을 처음 접하게 되어 공부하던 중 리뷰를 통해 RKD 방식까지 확장해서 이해할 수 있게 되었습니다. 특히 기존 방법과 달리 두 feature 간 거리뿐만 아니라
세 feature를 묶어 angle까지 학습 대상으로 삼는 방식이 흥미로웠습니다.
그런데 궁금한것은 ..
feature 간 각도까지 학습하는 것이 왜 성능 향상에 기여하는지 잘 이해가 되지 않습니다…개인적으로는 하나의 class 내에서의 분포나 밀집도가 더 중요한 요소라고 생각되어 angle 정보가 그다지 큰 영향을 미치지 않을 것 같은데 각도를 학습함으로써 어떤 이점이나 표현력의 확장이 이루어지는지 궁금합니다 혹시 distance만으로는 놓치는 중요한 정보가 있다면 알려주시면 감사하겠습니다^^^^^
감사합니다.
embedding space를 잘 만든다고 생각하시면 됩니다. 어떤 visual feature를 벡터 형태로 잘 임베딩하였다면, 해당 임베딩 공간에서 두 데이터 포인트 간에 얼마나 유사하나는 단순한 의미로 볼 수도 있겠지만(두 점 사이 정의되는 거리가 중요하겠죠), 다양한 data feature point간의 관계를 복합적으로 고려할 때는 teacher의 embedding 능력을 student가 잘 모방해서 유사한 embedding feature 구조를 구축할 수 있어야 할 것입니다. 이 때 수많은 feature vector point간의 관계성을 기술할 때 필연적으로 3개 이상의 점 사이에서 정의되는 각도 정보가 중요하게 됩니다. 단순히 classification의 관점에서 생각하지 마시고, visual feature를 embedding space에 얼마나 잘 투영할 수 있는지, 벡터 공간 형태로 표현되는 teacher network의 embedding space를 student가 어떻게 학습해야 효율적으로 모방할 수 있을지의 관점으로 생각하시면 각도 정보의 중요성이 와닿을 것 같습니다.