안녕하세요 이번에 소개할 논문은 사전 학습된 비전-언어 모델(VLMs)이 단순한 시각적 상식을 넘어선 복잡한 추론 능력을 평가하기 위해 새로운 데이터셋인 ROME과 평가 프레임워크를 제안한 논문입니다. 연구의 목적은 VLM이 단순히 이미지에 나타난 객체를 인식하는 것을 넘어서, 사물의 속성 및 관계에 대한 상식적이지 않은 상황에서도 정확하게 추론할 수 있는지를 검증하는 것입니다.
1. Introduction
이 논문에서 다루는 연구 주제는 ‘Reasoning beyond Visual Common Sense’입니다. 시각적 상식(Visual Common Sense)이란 사람이 이미지를 보고 즉각적으로 이해할 수 있는 상식적 지식을 의미합니다. 예를 들어, 사람이 노란색 바나나를 보면 바나나의 일반적인 색이 노란색임을 알 수 있고, 사자가 토끼보다 크다는 사실을 상식적으로 알고 있습니다. 즉, 사람은 이미지에 등장하는 사물들의 속성(색깔, 모양, 크기, 재질 등)과 이들 간의 관계(위치, 상대적인 크기, 상호작용 등)를 직관적으로 파악할 수 있습니다.
이처럼, 비전 모델도 단순히 객체를 인식하는 것을 넘어 인간 수준의 이미지 이해 능력을 갖추어야 합니다. 이러한 문제를 정의하여 발표한 논문이 2019년 CVPR에서 oral 발표된 , ‘From Recognition to Cognition: Visual Commonsense Reasoning‘입니다. 이 논문에서는 새로운 Visual Commonsense Reasoning (VCR) 태스크를 제안하고, 이를 위한 데이터셋과 추론 모델을 소개합니다. VCR 데이터셋은 이미지, 객체 영역, 질문으로 구성되어 있으며, 모델은 주어진 데이터에 대해 4개의 선택지 중 정답을 고르고, 선택한 답의 이유도 함께 선택해야 하는 구조입니다.
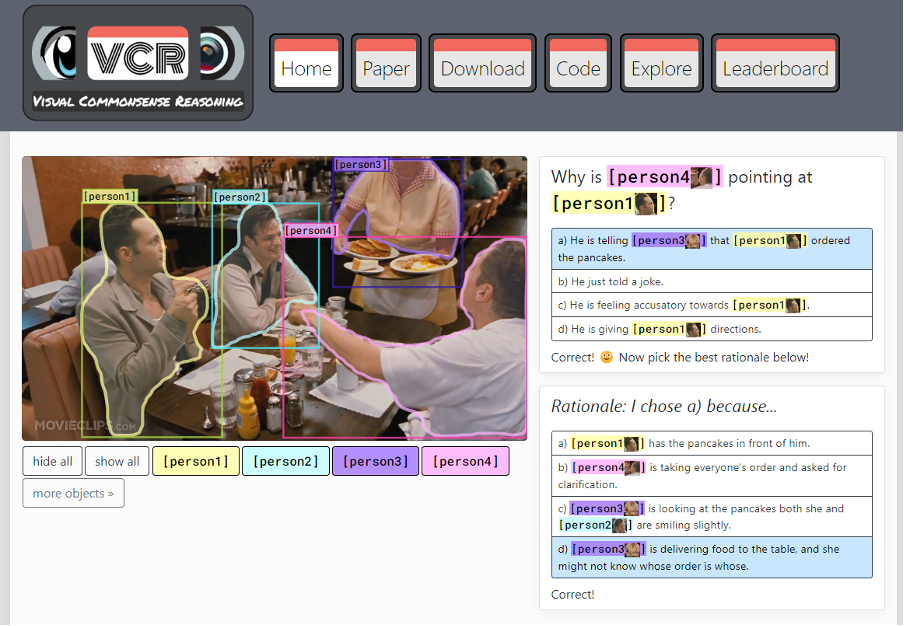
위 이미지가 VCR 데이터셋의 한 예시입니다. 우리는 이 이미지를 보고 객체 인식을 넘어 어떤 상황인지 추론할 수 있습니다. 이미지 속 상황은 아마 세 사람이 식당에서 함께 식사하며 음식을 주문한 상태일 것 입니다. 여기서 person3은 음식을 서빙하고 있고 그 음식은 person1이 주문한 것이다라고 person4가 직원에게 알려주고 있는 모습이라고 추론할 수 있습니다. 이처럼 모델 또한 Why is [person4 ] pointing at [person1 ]?라는 질문에 a) He is telling [person3 ] that [person1 ] ordered the pancakes이라는 답변을 골라야하고 d) [person3 ] is delivering food to the table, and she might not know whose order is whose.와 같이 답변을 고른 이유도 맞춰야합니다. 이처럼 이미지가 어떤 상황인지 추론하고 그 답에 대한 근거도 옳바르게 선택하는 것이 VCR task입니다.
기존 연구들은 모델의 상식적 추론 능력을 평가하는데 집중해왔습니다. 하지만 저자는 상식을 넘어선 추론 능력을 평가하는 데 초점을 맞추고 있습니다. 상식을 넘어선 추론 능력을 평가하는 연구로는 2023 CVPR에 발표된 ‘Breaking Common Sense: WHOOPS! A Vision-and-Language Benchmark of Synthetic and Compositional Images’ 논문이 있습니다. 이 논문이 제안하는 WHOOPS 데이터셋은 비상식적인 이미지로 구성된 데이터셋입니다.

위 그림처럼 아인슈타인이 스마트폰을 들고 있다던지 산소가 차단된 상태에서 촛볼이 계속 켜저있다던지 하는 비상식적인 이미지에 대해 인간은 이를 이해하고 설명할 수 있습니다. 하지만 모델은 이와 같은 이미지가 무엇이 이상한지 판단하기 어렵습니다. 따라서 AI 모델의 시각적 추론 능력을 향상시키기 위해 지속적인 연구가 진행되고 있습니다.
저자 또한 사전 학습된 vision- language model 의 비상식적 이미지를 올바르게 해석할 수 있는지 평가하기위해 ROME (reasoning beyond commonsense knowledge) 데이터셋을 제안합니다. ROME 데이터셋은 색상, 형태, 재질, 크기 및 위치 관계에 있어서 상식적인 지식을 벗어난 이미지를 포함하고 있습니다. ROME 데이터셋은 비상식적인 문장을 DALL-E-2를 이용하여 생성한 비상식 이미지로 구성되어 있습니다.

위의 이미지가 ROME 데이터의 예시입니다. 인간은 물고기는 물고기는 보통 어항 안에 있다는 상식적 지식을 가지고 있을 뿐만 아니라, 상식적인 사고를 넘어 비상식적인 상황을 이해하고 추론할 수 있습니다. 예를 들어, 그림 1의 왼쪽 이미지를 보고 “물고기가 어항 안에 있습니까?”라는 질문을 받았을 때, 인간은 “아니요”라고 대답할 수 있습니다. 그러나 최근의 사전 학습된 비전-언어 모델들( LLaVA, InstructBLIP) 등은 이러한 질문을 받았을 때 이미지의 내용을 추론하는데 어려움을 겪는다고 합니다. 따라서 저자는 비전-언어 모델의 상식 지식과 비상식 추론 능력을 모두 평가하기 위해 두 가지 질문 세트를 구성합니다.
(1) Commonsense questions – 객체의 일반적인 속성 값이나 두 객체의 전형적인 상대적 크기 또는 위치 관계에 관련된 질문으로 구성.
(2) Counter-intuitive questions – 비상식적인 이미지에서 객체, 그 속성 및 상대적 크기나 위치 관계에 대해 묻는 질문. 이러한 질문을 기반으로 네 가지 평가 메트릭을 정의합니다.
2. Creation of Counter-intuitive Images
2.1 Counter-intuitive Descriptions
그럼 저자가 어떻게 비상식 이미지(Counter-intuitive Images)를 생성하였는지 구체적으로 설명드리겠습니다.
비상식 이미지는 실제로 존재할 확률은 매우 낮습니다. 따라서 이러한 이미지를 생성하기 위해서는 먼저 비상식 문장을 만들고 이를 텍스트-이미지 모델을 사용해 이미지를 생성합니다. 비상식 문장은 상식적인 문장을 참고해 만들어집니다. 저자는 상식적인 문장을 참고하기 위해ViComTe 데이터셋을 활용합니다. ViComTe는 색상, 형태, 재질 및 크기와 관련된 상식 지식을 포함하며, 약 10,000개의 이미지로 구성된 MSCOCO에서 수집되었습니다.
저자는 객체의 특정 속성 값의 빈도가 80% 이상인 경우에 해당하는ViComTe의 데이터만 사용합니다. 예를 들어, 객체 “타이어”와 속성 “색상”이 주어지면, ViComTe에서 가장 낮은 빈도를 가지는 값은 “파란색”입니다. 이를 기반으로 “파란색 타이어”라는 비상식적 문장을 만듭니다.
크기와 관련된 상식 지식은 “사슴은 접시보다 큽니다 “와 같이 두 객체의 상대적인 크기로 표현됩니다. 저자는 관계를 반대로 하여 비상식적 문장을 생성합니다. 예를 들어” 접시보다 작은 사슴”와 같은 문장이 있습니다. 위치 관계의 경우 문장의 전치사를 교체하여 비상식 문장을 생성합니다.
2.2 Image Generation
사전 실험 결과, 색상, 형태 및 재질의 경우 DALL-E-2를 사용한 자동 이미지 생성과 두 번의 필터링을 거치는 방식이 효과적이었습니다. 그러나 크기와 위치 관계의 경우, 자동 생성은 저품질 이미지가 너무 많이 생성되기 때문에 수작업 방법을 사용합니다.
색상, 형태 및 재질에 대한 비상식적 이미지를 자동 생성하기 위해, 저자는 DALL-E-2에 비상식 문장을 입력하고 설명당 20개의 이미지를 생성합니다. 그런 다음, CLIP을 사용해 1차 필터링을 수행하여 저품질 이미지를 제거합니다. 구체적으로, 생성된 각 이미지에 대해 CLIP을 사용해 해당 이미지의 비상식 문장과의 코사인 유사도를 계산하고, 상식 문장과의 코사인 유사도도 계산합니다. 그런 다음 두 유사도 점수를 확률로 정규화하고, 비상식 확률이 0.8이하인 이미지는 제거를 합니다. 이 단계를 통해 이미지 수를 2만 1천 개 이상에서 약 3천 5백 개로 줄였다합니다.
크기와 위치 관계에 대한 비상식적 이미지를 수동으로 생성하기 위해, 두 명의 연구자가 Bing Image Creator(DALL-E-2 기반)를 사용해 고품질의 비상식적 이미지를 얻을 때까지 반복합니다.
2.3 Human Annotation
CLIP을 통한 필터링 후에도, 여전히 인간이 인식할 수 없는 객체가 포함된 이미지가 남아 있습니다. 따라서 저자는 객체 인식과 속성 확인의 두 단계로 나누고 추가로 사람이 필터링합니다. 객체 인식 단계에서는 이미지가 주어졌을 때, 세 명의 주석자가 객체를 세 가지 옵션 중 하나로 식별합니다. 주석자가 객체를 인식할 수 있는 경우, 속성 확인 단계로 넘어가 세 명의 주석자가 객체가 비상식 문장과 일치하는지 판단합니다. 세 명의 주석자가 모두 동의하는 경우에만 이미지를 유지합니다. 인간이 필터링 한 후 이미지 수는 약 3천 5백 개에서 1,263개로 줄였다고합니다.
3. Probing Questions and Evaluation Metrics
저자는 사전 학습된 VLM 모델이 비상식 이미지를 잘 처리할 수 있는지 확인하고자 합니다. 하지만 그 전에 모델이 시각적 상식 정보를 학습했는지 확인을 해야합니다. 따라서 저자는 두 그룹의 질문을 만듭니다.
(1) VLM의 시각적 상식 지식을 테스트하는 질문과 (2) 시각적 상식을 넘어선 추론 능력을 테스트하는 질문입니다. 그리고 저자는 테스트를 간편하게 하기위해 “yes” 또는 “no”로 답할 수 있는 질문만 설계했습니다.

3.1 Probing Questions
위 그림의 Commonsense questions을 보면 두 쌍의 yes/no 질문 템플릿을 설계한 것을 확인할 수 있습니다. Q1a, Q1b는 모델이 상식적 지식을 가지고 있는지 판단하는 질문으로 Q1a에 “yes”라고 답하고 Q1b에 “no”라고 답해야만 합니다. 두 번째 질문 쌍은 상식 속성 값과 비상식 속성 값의 가능성을 비교하도록 설계된 질문입니다. 예를 들어 “ In general, is the color of a clementine more likely to be orange than to be black”이란 질문은 clementine의 색상이 orange에 더 가까운지 black에 더 가까운지 비교하도록 합니다. 모델이 Q2a에 “yes”라고 답하고 Q2b에 “no”라고 답하면 모델이 해당 상식적 지식을 가지고 있다고 판단합니다.
Counter-intuitive questions은 생성된 비상식 이미지를 기반으로 합니다. 저자는 (1) 객체 인식과 (2) 속성/관계 인식의 두 하위 그룹의 질문을 설계했습니다. Q3은 객체의 존재 여부를 묻는 질문입니다. VLM이 Q3에 “yes”라고 답하면, VLM은 비정상적인 색상, 형태, 재질 또는 비정상적인 상대적 크기나 위치를 가진 객체와 같이 있어도 객체를 인식할 수 있습니다. Q4a와 Q4b는 이미지 속 객체의 색상, 형태, 재질, 또는 두 객체 간의 상대적 크기나 위치 관계에 대해 묻습니다. 이전 질문과 마찬가지로, VLM이 Q4a에 “no”라고 답하고 Q4b에 “yes”라고 답하면, 비상식적 속성 값을 올바르게 식별했음을 나타내며, 시각적 상식을 넘어 추론할 수 있는 능력을 보여줍니다.
3.2 Evaluation Metrics
다음은 평가 메트릭에 대한 설명입니다. 저자는 R을 ROME 데이터셋에 포함된 이미지 집합으로 정의합니다. 이미지 I ∈ R과 질문 템플릿 Q가 주어졌을 때, Q(I)는 이미지 I에 나타난 객체, 속성 및/또는 관계와 관련된 시각적 상식 지식을 기반으로 템플릿 Q에서 파생된 질문을 나타냅니다. 예를 들어, 파란 바나나가 있는 이미지 I와 바나나의 상식적인 색상이 노란색이라는 지식이 주어졌을 때, Q1a(I)는 “일반적으로 바나나의 색상은 노란색인가요?”가 되고, Q1b(I)는 “일반적으로 바나나의 색상은 파란색인가요?”가 됩니다. M은 VLM을 나타내며, M(I1, Q(I2))는 VLM M이 이미지 I1에 대해 이미지 I2에서 정보를 얻어 템플릿 Q에서 파생된 질문 Q(I2)에 대해 제공한 답변을 나타냅니다.
3.2.1 Metrics for Commonsense Knowledge
저자는 VLM의 상식 지식을 테스트하기 위해 두 가지 평가 기준을 도입합니다.
- Commonsense score based on language (CS-L): 템플릿 Q1a, Q1b, Q2a, Q2b에서 파생된 상식 질문을 VLM에 물을 때, 이 질문들은 특정 이미지가 아닌 일반적인 경우에 대해 묻고 있습니다. 이를 위해 VLM에 blank image(비정보성 이미지)를 입력하여 질문에 대해서만 평가합니다. 비정보성 이미지를 Inull이라 정의하면 모델 M이 주어졌을 때, 메트릭은 다음과 같이 정의됩니다:

여기서 CS-L1(M, I)는 M(Inull, Q1a(I))가 “yes”이고 M(Inull, Q1b(I))가 “no”인 경우 1로 점수가 매겨집니다. 즉, 모델 M이 비정보성 이미지를 가지고 상식 지식에 따라 Q1a(I)와 Q1b(I)에 모두 올바르게 답할 때만 CS-L1(M, I)는 1이 됩니다. CS-L1(M)은 모든 I ∈ R에 대해 CS-L1(M, I)의 평균입니다. 저자는 모델의 답변을 기반으로 유사하게 CS-L2(M)를 계산하고, 최종 CS-L(M)은 max(CS-L1(M), CS-L2(M))로 설정합니다.
- Commonsense score based on vision and language (CS-VL): VLM이 상식 질문을 받을 때 비상식적인 이미지의 영향을 받는지 테스트하기 위해, 저자는 CS-VL을 CS-L과 동일하게 정의하지만, 비정보성 이미지 대신 비상식 이미지를 사용합니다.
3.2.2 Metrics for Reasoning beyond Common Sense
저자는 시각적 상식을 넘어선 추론에 대해 두 가지 평가 기준을 정의합니다. 하나는 객체 인식, 다른 하나는 속성/관계 인식입니다.
- Counter-intuitive score based on object recognition (CI-Obj): 만약 VLM이 비상식적 객체를 인식할 수 없다면, 이는 상식을 넘어 추론할 수 있는 능력이 없음을 의미합니다. k개의 객체가 포함된 이미지 I에 대해, Q3(I)는 I에 있는 각 객체에 해당하는 k개의 질문 집합입니다. CI-Obj(M, I)는 모델 M이 I에 있는 모든 객체를 인식할 수 있을 때만 1이 됩니다. CI-Obj(M)는 모든 이미지에 대한 CI-Obj(M, I)의 평균입니다.
- Counter-intuitive score based on attribute/relation recognition (CI-AttrRel): 마찬가지로 비상식 이미지 I가 주어졌을 때, CI-AttrRel(M, I)는 모델 M이 이미지 I의 실제 내용에 따라 Q4a(I)와 Q4b(I)에 모두 올바르게 답할 때만 1이 됩니다. CI-AttrRel(M)는 모든 I ∈ R에 대한 CI-AttrRel(M, I)의 평균입니다.
4. Experiments

Table 3은 네 가지 평가 기준에 따라 전체 ROME 데이터셋에 대한 모델의 성능을 보여줍니다. 저자는 CS-L을 얻기 위해 비정보성(blank) 이미지를 사용합니다. CS-L의 점수는 모델이 비정보성 이미지를 받을 때, VLM은 상식 지식을 보여주는지 확인할 수 있습니다. 모든 모델의 CS-L 점수는 상대적으로 낮으며, 10.89%에서 32.31% 사이입니다. 이는 VLM 모델들이 상식 지식을 보여주지 않는다는 것을 의미합니다.
비정보성 이미지는 정보가 없지만, 이러한 사전 학습된 VLM이 학습 데이터에서 비정보성 이미지를 거의 접한 적이 없다는 점을 고려할 때, 비정보성 이미지는 분포 밖(out-of-distribution) 데이터일 수 있습니다. 따라서, 비정보성 이미지를 선택하는 것이 모델 성능에 영향을 미칠 수 있다는 주장이 있을 수 있습니다. 이 우려를 해결하기 위해, 저자는 무작위로 선택한 이미지를 사용하여 추가 실험을 진행합니다. 구체적으로 비정보성 이미지 대신 Visual Genome 데이터셋에서 무작위로 선택한 이미지를 사용합니다. 모든 모델에 대해 이 과정을 세 번 반복합니다.

결과는 Table 5에 나와 있습니다. 결과는 무작위로 선택된 이미지를 사용하는 것이 비정보성 이미지를 사용할 때와 유사한 CS-L 점수를 생성한다는 것을 보여줍니다.
종합적으로, 저자는 InstructBLIP과 LLaVA가 비정보성 이미지나 무작위 이미지가 주어졌을 때 상식적 질문에 약 30%와 35%의 정확도로 답한다는 것을 발견했습니다. ALBEF, BLIP-2, MiniGPT-4 및 mPLUG-Owl의 경우, 무작위로 선택된 이미지를 사용하는 것이 비정보성 이미지를 사용하는 것보다 약간 더 낮은 CS-L 점수를 생성했습니다(약 5% 차이). 이는 이 모델들이 질문과 관련이 없는 무작위 이미지로 인한 시각적 방해 요소에 취약하다는 것을 보여줍니다.


CS-L 점수와 CS-VL 점수를 비교하면, 비상식 이미지를 제시할때 모든 모델의 상식 추론이 더 손상됨을 알 수 있습니다. 예를 들어, 그림 3에서와 같이 비정보성 이미지를 사용했을때 맞췄던 질문에 대해 그림 4에서는 비상식적인 이미지를 받았을 때 같은 상식 질문조차 틀리게 답합니다. 이러한 문제는 모든 모델에서 관찰됩니다.
모든 모델이 비상식적 객체 인식에서 높은 성능을 보였으며, CI-Obj 점수가 90.79%에서 98.34% 사이였습니다. CI-AttrRel 점수는 전반적으로 낮았으며, InstructBLIP이 63.72%로 가장 높은 점수를 기록했습니다. 이는 모델들이 객체를 잘 인식하더라도, 비상식적 속성과 공간 관계를 인식하는 데 어려움이 있음을 보여줍니다. 모델들은 속성 유형에 따라서도 성능이 달랐습니다. 대부분의 모델은 비상식적 색상을 인식하는 것이 가장 쉬웠으며, 일부 모델에게는 재질 인식이 두 번째로 쉬웠습니다.
4. Conclusion
이 연구에서 저자는 ROME 데이터셋을 구축하고, 사전 학습된 비전-언어 모델(VLMs)이 상식을 넘어선 추론을 할 수 있는지를 평가하기 위한 프레임워크를 제안했습니다. 저자는 ROME 데이터셋과 자체 정의한 평가 기준을 사용해 VLM 모델들의 성능을 분석했으며, 그 결과 VLM들이 상식을 넘어서는 추론을 수행하는 데 한계를 보인다는 점을 입증했습니다. 이를 통해 기존 VLM의 약점을 강조하며, 모델의 시각적-언어적 이해 능력을 향상시키기 위한 연구 방향을 제시하고 있습니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
VLM의 추론능력을 사람과 비슷하게 하기 위한 데이터셋인 것 같습니다. 굳이 counter intuitive 이미지까지 넣어가면서 VLM의 평향된 정보 습득을 평가하려는 시도가 흥미롭네요. 궁금한 점은 두가지 있는데 첫번째는 논문에서 여러가지 VLM들이 성능이 높은 모델부터 낮은 모델까지 고루 존재하는데 저자가 생각하는 특정 모델의 성능이 높거나 낮은 이유에 대한 고찰이 있는지 궁금하고 두번째는 최근 VLM 연구들이 이 ROME 데이터셋을 활용하고 있는지 궁금합니다.
감사합니다.
안녕하세요 성준님 좋은 질문 감사합니다.
논문에서는 평가표에 대한 특정 모델의 성능 분석이 나와있지는 않았습니다. 실험 목적이 상식 지식을 갖고 있는지 혹은 비상식 이미지로부터 추론 능력이 있는지 확인하는 단순한 태스크이기 때문에 결과 분석도 단순히 VLM들이 상식 지식 및 추론 능력이 있다 없다로 분석한 것 같습니다.
아직까지 VLM 연구들에서 ROME 데이터셋이 많이 활용되고 있지는 않은 것 같습니다.
감사합니다.
안녕하세요 ! 실험 부분에서 모든 VLM에게 동일한 이 ROME이라는 데이터섯에서 실험을 했는데, Tab.3도 그렇고, Tab.5도 마찬가지로 VLM마다의 성능 편차가 좀 있는 것 같습니다. 그런데 분석에서는 전체적인 경향성에 대해서만 언급이 있고 왜 똑같이 비상식적인 데이터가 포함된 ROME으로 평가했음에도 불구하고 큰 편차를 가지는 성능을 내는 건지에 대한 분석이 없는 것 같아서 .. 혹시 비교에 사용한 VLM들의 성능 경향성이 기존 데이터로 평가했을 때와 유사한 편인건가요 ? 아니라면 혹시 각 VLM마다의 성능 차이가 발생하는 이유에 대해서 저자가 언급한 것은 없는지, 없다면 의철님 의견이 궁금합니다.
또한 제가 이 task를 잘 몰라서 그런 것일 수도 있지만 VCR이 선택한 답의 이유도 함께 선택해야 하는 구조라고 말씀해주셨는데, 구성한 데이터셋에 대한 검증을 yes/no 이분법적인 대답으로 나누는 것으로 될까라는 의문이 들긴 합니다. 데이터셋을 제안한만큼 검증 역시 중요해보이는데, 혹시 appendix로라도 데이터셋을 검증할 때 yes/no와 더불어 이유에 대해서도 함께 선택하는 방식의 검증을 수행한 결과가 있을까요 ?
감사합니다.
안녕하세요 건화님 좋은 질문 감사합니다.
일단 논문에서는 평가표에 대한 특정 모델의 성능 분석이 나와있지는 않았습니다. CS의 결과 테이블을 보았을때 모델의 성능이 5%~35% 수준을 달성하고 있습니다. 이를 모델의 성능 편차가 있다고 볼 수 있지만, 제 생각에는 단순히 질문에 대한 답을 yes 또는 no 둘 중 하나로 답하는 태스크에서 무작위로 선택한 확률(50%)보다 떨어지는 성능을 보이는데 이를 각 모델별로 추가 분석하는 것은 의미가 없지 않나 싶습니다.
말씀해 주신 대로ROME 데이터셋을 이진 질문으로만 설계한 것을 논문의 한계점으로 언급하고 있습니다.
본 연구가 아직은 초기 단계이다 보니 데이터셋 구축 및 분석 결과에 있어 추가적인 발전과 개선이 필요해 보입니다.
감사합니다.
좋은 리뷰 감사합니다.
비상식적인 상황에 대한 추론 능력을 검증한다는 개념이 새로웠습니다.
CS-L을 통해 질문에 대해 평가한다고 하셨는데, 기존 VLM들이 CS-L에서 성능이 낮다는 것은 기존 모델들도 상식에 의존하지 않는 것으로 이해할 수도 있지만, 어찌보면 시각 정보의 부재로인한 문제로 볼 수 있지 않을까요? 즉, 상식에 대한 평가로 적절한 지 의문입니다. 이에 대한 의철님의 의견이 궁금합니다.