안녕하세요, 이번 주 X-Review에서는 24년도 CVPR에 게재된 논문 <VicTR: Video-conditioned Text Representation for Activity Recognition>을 소개해드리겠습니다. 잘 편집되어있는, 즉 하나의 비디오에서는 하나의 action만 등장하는 trimmed video에서 어떠한 action이 등장하는지 분류하는 Activity Recognition (AR) task를 수행하는 논문입니다.
CLIP의 image-text 표현력을 video-text 도메인으로 끌고 올라오기 위해 텍스트 정보를 조금 더 적극적으로 활용하는 컨셉을 가지고 있습니다. 자세한 내용은 아래에서 이야기해보겠습니다.

1. Introduction
앞서 말씀드린대로 본 논문이 수행하는 AR task는 가공된 비디오를 분류하는, video understanding 분야에서는 가장 기본적인 task에 해당합니다. 분류해야하는 클래스는 데이터셋에 따라 ‘축구 공 차기’, ‘화장하기’, ‘잔디 깎기’ 등등이 해당합니다. 그만큼 오랜 기간동안 연구되어 왔고, 다양한 방법론들이 이미 존재합니다. 최근에는 대부분의 task들이 그럴 것 같긴 한데, 여기도 마찬가지로 CNN을 넘어 Transformer 구조는 물론 Fully-supervised 부터 Self-supervised까지 연구되고 있고 멀티모달로 바라보는 관점도 존재합니다.
이 중에서 멀티모달로 AR을 바라보는 방법론들은 Vision Language Models (VLMs)을 활용합니다. 즉, 이제는 모두들 알고계실 CLIP은 이미 비전 내외로 엄청나게 많은 도메인에 적용되고 있고 이 task에서도 빠지지 않습니다. 최소한 저희 연구실에서 살펴보고 있는 모든 분야엔 이미 적용되고 있는 것 같네요. 논문에선 CLIP의 사전학습 방식을 간단히 설명하고 있는데, 이 부분은 방법론에서 또 살펴보기에 여기선 넘어가도록 하겠습니다.
CLIP이 다양한 변형을 통해 여러 분야에 적용되고 있는 것은 맞지만, 비디오 분야에 적용하기엔 꽤 까다로운 부분이 있습니다. 우선 CLIP의 기본 아이디어를 비디오 분야로 옮기는 방법은 거대 비디오-텍스트 쌍으로 사전학습한 모델을 만들어내는 것입니다. 근데 우선 거대 쌍을 구축하는 것부터 코스트가 굉장히 크고, 이를 가지고 학습하는 것 또한 연산량이나 시간적 측면에서 굉장히 무거울 것입니다. 논문에선 VideoCLIP이라는 모델이 언급되는데 정확한 이유는 모르겠지만 해당 모델이 limited success를 거뒀다고 하네요.
첫 번째 이유를 극복하고자 하는 연구는 위험 부담이 너무 크기에 잘 이뤄지지 않고있고, 주류를 이루는 연구는 지금 말씀드릴 두 번째 방식, 즉 기존 CLIP의 Image encoder를 비디오 다루기에 적합한 모델로 개선하는 것입니다. CLIP은 이미지-텍스트 쌍으로 학습되어있기 때문에 비디오의 시간적 구조를 이해하지 못합니다. 최근 방법론들은 이를 보완하기 위해 Self-attention을 통한 프레임간 관계 모델링 등 여러 temporal modeling을 추가하고 있는 경향입니다.
저자도 방금 말씀드린 두 번째 갈래에서 발전된 방법론입니다. 그럼 다시 두 번째 갈래의 기존 방법론들이 어떠한 문제점이 있는지 봐야할 것 같습니다. 저자가 지적하는 기존 방법론들의 가장 큰 문제점은 텍스트 feature의 활용 방안입니다. 기존엔 텍스트를 아예 사용하지 않고 visual feature로만 action을 분류하거나, 활용한다고 해도 freeze된 텍스트 인코더를 사용하거나, 반대로 이미지 인코더와 동시에 모델이 업데이트되는 형태였습니다.
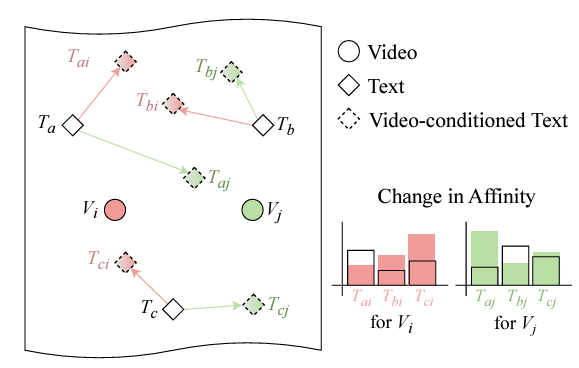
CLIP을 기반으로 하는 모델은 어떠한 텍스트이든 입력되었을 때 시각적으로 매칭할 수 있는 능력을 갖추고 있기에, 텍스트를 잘 활용하는 것이 굉장히 중요합니다. 기존과 같이 텍스트 표현력에 소홀하다면 최적의 성능을 낼 수 없다는 것이 저자의 주장입니다. 이러한 문제점을 극복하기 위해 저자는 위 그림 1과 같은 Video-conditioned Text representation을 제안하였고, 학습할 각 비디오의 텍스트 토큰을 클래스 이름 그대로 사용하는 것이 아니라 해당 비디오 각각의 unique한 텍스트 토큰을 만들어 사용하게 됩니다. 그림에 나타난 affinity는 곧 cosine 유사도를 의미합니다. 비디오-텍스트 유사도를 기반으로 텍스트 토큰을 갱신해 사용한다는 이야기입니다.
2. Background: image-VLMs to video
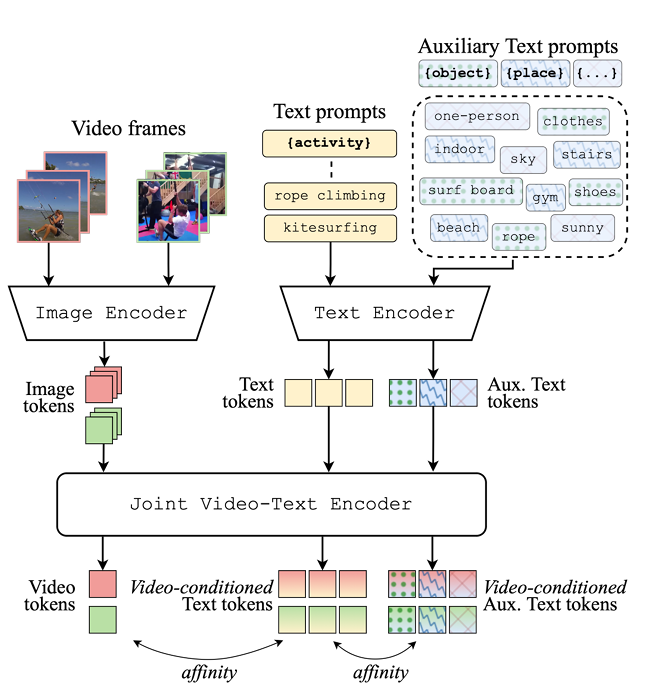
위 그림 2는 저자가 제안하는 방법론 VicTR의 간단한 구조도입니다. 현재 보고있는 비디오와, 텍스트 토큰 간 유사도를 기반으로 텍스트 토큰을 새롭게 갱신하게 되고, 이를 통해 비디오 내 발생하고 있는 action을 분류하는 것이 방법론의 큰 컨셉입니다. 이제 자세한 내용을 알아보도록 하겠습니다. 그림 2에 나타나있는 Auxiliary Text prompts는 추가적인 LLM이나 모델을 가져와 뽑은 것은 아니고, 그냥 데이터셋 annotation에서 바로 얻을 수 있는 텍스트 단어들을 가져온 것이라고 합니다. 아무래도 Real-world에서 사용하긴 좀 어려운 부분이라고 볼 수 있겠네요. 일종의 성능 향상을 위한 추가 정보에 해당합니다.
우선 비디오를 다루는 방법론이기에 기존 CLIP을 image-VLM이라 칭하고 있습니다. 여기서는 기본적인 notation과 CLIP의 학습 방식을 짚고 넘어가겠습니다. CLIP은 두 개의 인코더 {Enc_{img}}, {Enc_{txt}}로 이루어져있습니다. 이미지 I \in{} \mathbb{R}^{H \times{} W \times{} 3}는 패치로 쪼개진 뒤 ViT 기반의 {Enc_{img}}에 입력되고, 출력으로 얻은 [cls] 토큰을 {e_{img}}로 두고 추후 학습에 사용합니다.
본 task에서 텍스트는 잘 갖춰진 문장이 아니기에, CLIP과 동일하게 “a photo of {class}.”와 같은 프롬프트로 감싸집니다. 이후 BPE (Byte Pair Encoding) 기법을 통해 토큰 단위로 전처리된 후 트랜스포머 기반의 {Enc_{txt}}에 입력되며, 전처리 과정에서 붙은 [EOS] 토큰을 {e_{txt}}로 두게 됩니다. 위 과정은 아래 수식과 같습니다.
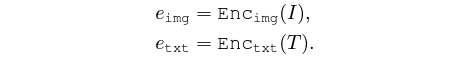
이후엔 두 모달리티의 최종 feature 간 유사도를 조정해줍니다. 아래 수식과 같이 유사도를 구한 뒤 일치하는 쌍이라면 유사도를 높게, 아니라면 유사도를 낮추도록 학습합니다. 아래 수식과 같이 추후 본 논문에서 언급하는 affinity는 cos 유사도를 의미합니다.
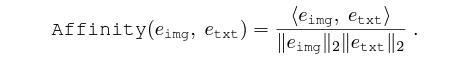
이제 위 모델을 비디오에 적용해야 합니다. 기본적인 인코더들과 학습 방식은 변할 것이 없지만, 아무래도 입력 자체가 이미지에서 비디오 V \in{} \mathbb{R}^{\mathcal{T} \times{} H \times{} W \times{} 3} = [I^{1}, \cdots{}, I^{\mathcal{T}}]로 변경된다는 점이 가장 크겠죠. 우선 총 \mathcal{T}개의 각 프레임은 기존과 동일하게 이미지 인코더를 통과하게 되고, 이렇게 얻은 각 프레임별 {e_{img}^{i}}는 텍스트 인코더와 concat되어 Video Head {Head_{Vid}}를 거치게 됩니다. 이는 아래 수식과 같습니다.
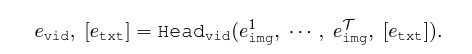
당연하겠지만 비디오 내 프레임들 간 시간 관계성을 잘 파악하는 것이 중요하기에 위 {Head_{Vid}}는 보통 프레임 간 Self-attention 등의 구조를 갖게 됩니다. 프레임들끼리 어떻게 엮여있는지 파악하는 과정인 것입니다. 이 때 텍스트의 feature도 같이 추출되었다면 CLIP과 동일하게 {e_{vid}}와 {e_{txt}}의 유사도를 기반으로 학습합니다. 텍스트 feature를 사용하지 않는 몇몇 방법론들도 있는데, 그럼 {e_{vid}}를 MLP에 태워 분류를 수행하는 것입니다. 이 과정에서 기존 방법론들과 다르게 텍스트 토큰의 표현력을 비디오 기반으로 개선하는 것이 VicTR의 컨셉입니다.
3. Video-conditioned Text Representations
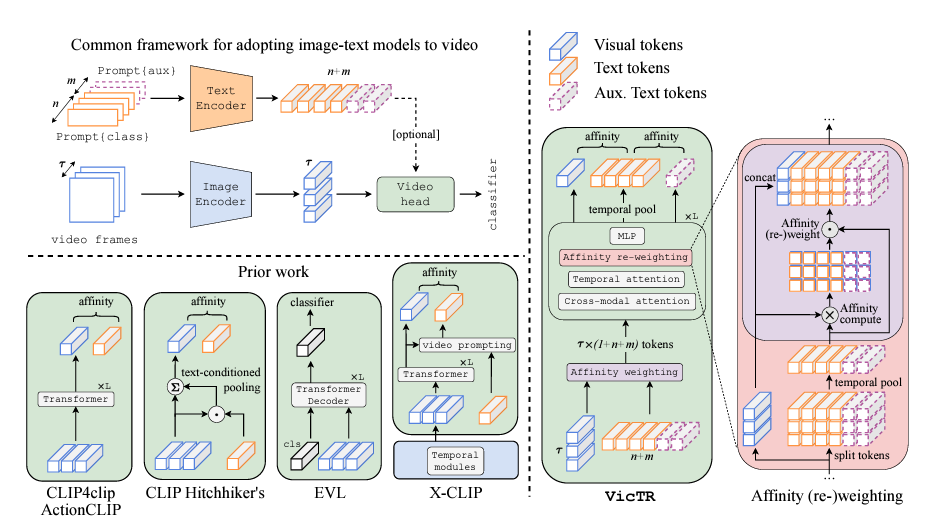
이제 지금까지 설명드린 비디오를 다루는 CLIP 프레임워크를 기반으로 저자가 제안하는 VicTR에 대해 말씀드리겠습니다. 우선 그림 3의 왼쪽 부분은 기본적인 프레임워크와 기존 방법론들, 오른쪽에는 VicTR이 나타나있습니다. VicTR은 아래와 같은 3단계로 구성되어있습니다.
- Token boosting
- Cross-modal attention
- Affinity (re-)weighting
총 n개의 단어 (데이터셋의 라벨 activity classes)로 구성된 텍스트 [T^{1}, \cdots{}, T^{n}], 또 데이터셋에서 가져올 수 있는 m개의 auxiliary semantic categories [A^{1}, \cdots{}, A^{m}]이 존재합니다. 각각의 embedding은 \{e_{txt}^{x} | x = 1, 2, \cdots{}, n\}, \{e_{aux}^{y} | y = 1, 2, \cdots{}, m\}으로 표현할 수 있습니다. \mathcal{T}개 프레임으로 구성된 i번째 비디오 V^{i}의 임베딩은 e_{img}^{i, t} | t=1, 2, \cdots{}, \mathcal{T}에 해당합니다.
결국 e_{img}^{i, t}, e_{txt}^{x}, e_{aux}^{y}가 {Head_{Vid}}에 입력되는 것입니다. 임베딩은 각각 프레임, 프롬프트 단위로 뽑았기 때문에 아직까지 프레임-프레임, 프레임-텍스트 간 어떠한 상호작용도 없었습니다.
3.1 Token-boosting
여기선 텍스트 인코더의 출력값을 가져와, 현재 보고있는 비디오에 적합한 텍스트 토큰을 만들어줍니다. 각 프레임과 텍스트 토큰 간 유사도를 모두 구해 이를 텍스트 토큰에 곱해주는 것이죠. (n+m)개의 텍스트 토큰을 활용해 최종적으로 각 프레임에 상응하는 텍스트 토큰들 \mathcal{T} \times{} (n+m)을 아래 수식과 같이 만들어줍니다.

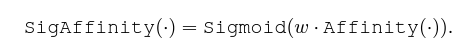
i번째 비디오의 t번째 프레임의 클래스 x에 대한 텍스트 토큰 e_{txt}^{i, t, x}를 만들어주기 위해 프레임과 텍스트 간 cos 유사도에 Sigmoid를 태워 이 값을 다시 텍스트 토큰에 곱해주는 것입니다. Aux 토큰들에 대해서도 마찬가지로 만들어내줄 수 있습니다.
학습 iteration을 거치며 토큰은 좀 더 visual 정보를 잘 고려할 것이고, 저자는 이와 같은 방식의 3가지 장점을 언급합니다. (1) 먼저 토큰 개수를 늘림으로써 모델의 capacity를 늘릴 수 있습니다. 비디오의 프레임마다 토큰을 둔다는 것은 꽤나 연산량을 늘릴 수 있는데, 그만큼 모델의 표현력을 늘려줄 수 있다고 합니다. 연산량 관련해선 실험 부분에서 따로 보여주고 있습니다. (2) 두 번째는 visual embedding을 기반으로 텍스트 토큰을 refine함으로써 일종의 soft-selection 과정을 거칠 수 있다는 점입니다. 모듈 초반부터 중요한 토큰과 그렇지 않은 토큰을 갈라내줄 수 있다는 것입니다. (3) 마지막으로 모델이 시간축에 대한 텍스트의 다양한 의미론적 모습을 잡아낼 수 있다는 점이라고 합니다. 정적인 이미지와 텍스트 토큰간 유사도를 연속적으로 계산하고, 이를 곱해준 텍스트 토큰을 활용하다보면 특정 attribute가 등장하고 사라지는 것 등과 같은 motion cue를 자연스럽게 잡아낼 수 있다는 것이죠.
다음으로 아래 수식과 같이 방금 개선한 텍스트 토큰을 기존 이미지 토큰에 concat합니다.
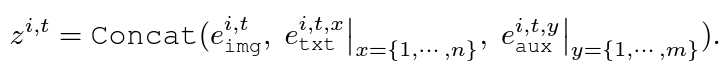
이렇게 얻은 프레임별 토큰을 concat하여 비디오에 대한 feature Z_{0}^{i} = [z^{i, 1}, \cdots{}, z^{i, \mathcal{T}}를 만들어줍니다. 이는 L개 transformer layer로 구성된 Video Head에 입력되고, 각 layer는 cross-modal attention, temporal attention, affinity (re-)weighting, MLP layer로 구성됩니다.
3.2 Cross-modal and Temporal attention
본 절에선 Video Head에서 진행되는 두 가지 관점의 attention을 설명합니다. 사실 TimeSformer라고 기존에 제안되었던 spatio-temporal attention과 동일한 개념입니다. 앞서 이미지와 텍스트가 concat 되어있는 값을 Video Head에 넣어준다고 말씀드렸습니다. 이러한 입력에 대해 Self-attention을 수행하면 사실 그게 Cross-modal attention이 되겠죠. 이후 TimeSformer에서 제안한 temporal attention을 거쳐 출력 \bar{Z}_{l}^{i}를 얻습니다. 대략적으로는 동일 프레임 내에서만 attention 연산을 하는 것이 아니고, 다른 프레임 토큰도 연산에 관여하는 것을 의미합니다. 여기서 처음으로 temporal modeling이 이루어지게 됩니다.
3.3 Affinity (re-)weighting
3.1에서 수행한 Token-boosting 과정에 대해 여러 장점을 말씀드렸지만, 사실 꽤 noisy한 attention 과정이라고 볼 수 있습니다. 따라서 학습 과정에서도 확실하게 weighting을 해주어 좀 더 구별력 있는 토큰을 만들어줄 필요가 있겠죠. Temporal attention 과정에서 처음으로 프레임 간 관계가 고려되었으니 이렇게 고려된 토큰을 바탕으로 weighting한다는 의미도 분명히 있을 것입니다.
우선 비디오와 텍스트, aux 토큰을 다시 아래 수식과 같이 쪼개줍니다.
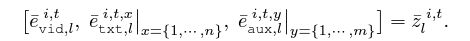
텍스트 토큰 또한 프레임 당 하나가 선언되어있는 상황이니, 시간 축에 대해 평균 pooling을 수행해 아리 수식과 같이 i번째 비디오의 x번째 클래스의 텍스트 토큰 e_{txt, l}^{i, x}를 얻을 수 있습니다. 그리고 다시 이 텍스트 토큰을 기준삼아 프레임 간 유사도 score를 구하고, weighting을 진행할 수 있습니다. 이제는 temporal modeling을 거치기도 했고, 프레임 별 텍스트 토큰을 평균내어 이를 기준으로 삼으니 비디오의 모든 프레임을 고려한 weighting이라고도 볼 수 있겠죠. 기준만 달라졌을 뿐 연산 과정은 Token-boosting과 동일합니다.

최종적으론 위 방식으로 개선된 텍스트 토큰을 다시 visual 토큰과 concat하여 아래 수식과 같이 MLP에 태워 다음 layer의 입력으로 넘겨줍니다.
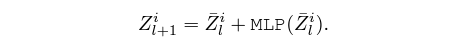
3.4 Classifier
총 L개의 transformer layer를 거치고 나오면, 이미지와 클래스, aux 토큰을 모두 시간 축에 대해 평균내어줍니다. 학습 땐 현재 보고 있는 비디오의 정답 클래스, 정답 aux text를 알고 있으니 CLIP과 동일한 방식으로 유사도를 최대화, 최소화해줍니다.
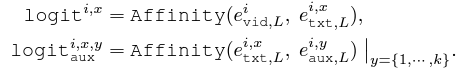
4. Experiments
4.1 Implementation details
실험은 HMDB-51, UCF-101 데이터셋에서 Few-shot, Zero-shot 세팅으로 성능을 측정합니다. 기존 연구와 유사하게, Video Head는 총 4개의 layer로 구성했고 데이터셋에 따라 여러 하이퍼파라미터를 두었다고 하니 궁금하신 분들은 논문을 참고해주시면 감사드리겠습니다.
4.2 Few-shot and Zero-shot Transfer
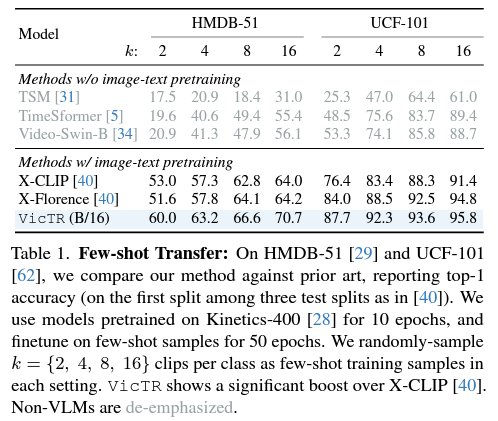

표 1, 2는 각각 Few-shot, Zero-shot 상황에서 HMDB, UCF 두 데이터셋에 대해 측정한 성능입니다. 표에서 VLM 기반이 아닌 방법론들은 회색으로 처리되었습니다. 저자가 뚜렷한 분석을 하고있진 않은데, 우선 Zero-shot 성능도 높지만 Few-shot에서의 기존 방법론 대비 성능 향상 폭이 뚜렷합니다. 이는 VicTR이 few-shot 학습 중 보는 것이 굉장히 큰 도움이 됨을 의미하는데, 학습 과정에서 비디오의 영향을 받은 텍스트 토큰을 만들어낸 다는 점이 유효하게 작동했음을 알 수 있었습니다.
4.3 Ablation Study

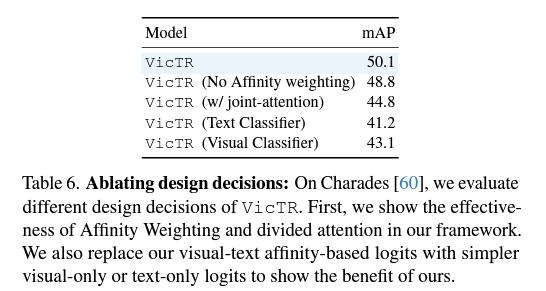
표 5, 6에선 VicTR의 핵심 contribution에 대한 ablation 성능을 보여주고 있습니다. 표 5에서 우선 데이터셋으로부터 얻을 수 있는 Auxiliary token을 추가적으로 활용했을 때 성능이 오른 것을 통해, 이러한 semantic의 잠재력을 보여주고 있다고 이야기합니다. 사실 이 부분은 데이터셋에서 가져오든 LLM을 통해 추출하든 이 추가 정보를 어떻게 활용할지가 성능 변동에 더 크게 관여할 것 같네요. 또한 텍스트 임베딩을 갱신해서 활용해야하고, 더 나아가 VicTR과 같이 만들어주는 것의 효과를 볼 수 있습니다. 텍스트를 활용하지 않는 경우 두 데이터셋에서 각각 -1.1%, -8.4%의 mAP 하락을 불러왔습니다.
제가 실험 부분에서 연산량에 관한 표는 따로 첨부하지 않았는데, 결과적으로 말씀드리면, VicTR은 동일 성능을 내는 방법론보다 더욱 가볍고, 동일 연산량을 갖는 방법론들보다 높은 성능을 보여주고 있었습니다.
5. Conclusion
기존 방법론으로부터의 개선점을 잘 찾아내었고 이를 굉장히 간단한 연산으로 풀어내어 성능을 크게 올린 논문이라고 생각합니다. 제가 지금 보고 있는 task에 적용하려면 또 다른 장치가 필요하겠지만, 충분히 아이디어나 실험 결과를 바탕으로 변형해볼만한 논문이라고 생각합니다.
이상으로 리뷰 마치겠습니다.