안녕하세요 두 번째 x-review입니다. 저번주에 이어서 Amodal Completion 주제를 읽고있는데, 이번 논문의 저자 역시 Diffusion을 이용해 문제를 해결하려고 했습니다. Diffusion을 채택한 이유 또한 인간이 가려진 물체의 나머지 모양을 상상해서 인식하는 방식과 유사하게 채우도록 하기 위해서 라고 합니다.
Introduction
인간의 시각을 담당하는 시스템은 연속성과 대칭성을 활용해 가려진 물체를 복원한다고 합니다. AI를 활용해 가려진 물체를 복원함에 있어서 저자가 주장하는 이상적인 접근은 두 단계로 이루어져 있습니다. 첫번째는 binary amodal mask(가려진 부분을 예측한 마스크)를 완성하는 것, 두번째는 해당 마스크에 RGB픽셀을 채워 넣는 것 입니다. 하지만 amodal mask를 직접 추론하는 모델을 만드는 것은 쉽지 않다고 주장합니다. 일단 데이터셋을 구하기 힘든데, 아무리 잘 만들어도 synthetic 이미지와 natural 이미지 사이에 domain gap이 있고, 인간이 직접 라벨링한 natural 이미지는 너무 비싸기 때문입니다. 하지만 작가는 기존 틀에서 벗어난 혁신적인 과정을 통해 amodal mask를 만들지 않고 문제를 해결하고자 했습니다. 먼저 복원해야 할 대상의 Bounding Box를 확장하여 배경 정보를 포함시키고, 대상을 가리고 있는 것들을 다 제거한 후 사전 학습된 diffusion 모델을 사용하여 복원한 뒤 배경을 제거한다고 합니다. 저번 논문도 그렇고 diffusion 자체가 엄청난 힘을 가진 것 같습니다.
하지만 기존의 사전학습된 diffusion 모델을 그대로 사용한다고 해서 저자들이 원하는 결과를 안정적으로 얻을 수는 없었다고 합니다. 가려진 부분을 올바르게 채우는것이 아닌 가려진 부분에 전체 물체를 채워 넣는다던지, 컵을 들고있는 손을 지우고 싶은데 아예 하나의 손을 더 추가하는 문제가 있었고, diffusion모델이 contextual bias을 반영해서 원래 객체와 자주 등장한(손과 컵)물체를 무의식적으로 추가하는 문제가 그 이유라고 합니다. 따라서 저자는 본인의 방법론에서 없애고 싶은 물체를 오히려 또 만들어 버리는 문제를 해결하고자 합니다.
이를 위해 수행해야 하는 task는 크게 diffusion 모델이 적절하게 context를 고려하지 않게 하는것, amodal completion이 성공적으로 수행됐는지 판단하는것 두가지라고 합니다. 이를 위해 mixed context diffusion을 제안했는데, 해당 방법은 샘플링을 수행할 때 배경을 없애고 시작해 당장 이미지의 contextual bias에서 벗어날 수 있게 만들어 줍니다. 이렇게 시작한 복원이 점점 진행되는 한 순간 어느정도 미완성된 (노이즈가 남아있는) pseudo-complete object를 추출해 디코더를 통해 unsupervised 클러스터링을 통해 객체를 추출한다고 합니다. 완전하게 복원된건 아니지만, 목표한 객체와 유사한 형태를 띄고 있어 이 객체를 기준으로 처음에 없애버렸던 배경을 다시 넣어서 복원을 진행하는 방식입니다. 정리하면 contextual bias를 이끌어낼 수 있는 배경을 없앤채로 시작을 해서, bias에서 벗어난 적절한 타이밍에 다시 배경을 넣어서 diffusion을 수행하는 것 같습니다.
이 방법을 통해 저자는 아래 그림과 같 이미지에서 가려져있는 객체의 경계를 넘어선 영역의 픽셀도 복원할 수 있고, 여러가지 버전들을 만들어낼 수 있을 뿐만 아니라, 무엇보다 별도의 추가적인 학습이나 fine tuning 없이도 강력하고 일반화된 amodal completion을 수행할 수 있다고 합니다.

Amodal Completion이 완료 되었는지는 반사실적인 추론을 통해 확인합니다. 반사실적 추론(counterfactual reasoning)은 일어나지 않은 상황을 가정하고 그 상황에서 어떤 결과가 발생할지를 추론하는 과정입니다. 해당 논문의 경우 Amodal Copmletion이 된 객체를 사용해 outpainting 했을 때 객체에 아무런 변화가 없어야 한다는 점을 활용해 outpainting 전후의 segmentation 결과를 비교하여 성공 여부를 판단합니다.
Method
앞에서 말씀드렸듯 핵심 방법론은 Stable Diffusion입니다. Latent Diffusion Model을 사용해 Latent Space에서 노이즈를 추가하고 제거하는 과정을 통해 데이터를 학습하고, 가려진 부분을 복원함에 있어서는 Naive Outpainting의 한계를 해결한 Progressive Occlusion-aware Completion과 Mixed Context Deffusion Sampling, Counterfactual Completion Curation System의 파이프라인을 통해 복원을 진행하고 완성도를 판단합니다. 하나하나 살펴보도록 하겠습니다.
Preliminaries
해당 논문에 사용된 Stable Diffusion 모델은 데이터 분포 p(I)를 반복적인 denoising 과정을 통해 학습합니다. Forward 과정에는 모델이 이미지 I에 N단계의 노이즈를 추가하여 output이 대략적인 가우시안 노이즈를 갖도록 만듭니다. Reverse과정에서는 모델이 노이즈를 제거하는 방법을 N단계에 걸쳐 학습합니다. 각 단계 t=[1,N]에서 학습된 신경망은 노이즈가 포함된 이미지 It 를 바탕으로 노이즈 ϵθ(It,t) 를 예측합니다. 즉, 각 단계마다 모델은 이미지에 포함된 노이즈를 예측하여 제거 과정에 활용합니다. 또한 Stable Diffusion은 Latent Diffusion Model이기 때문에 이미지의 픽셀공간을 활용하지 않고 pretrain된 오토인코더를 통해 잠재공간에서 작동합니다. 디퓨전 하는 과정에서 오토인코더는 time-conditional UNet과 같이 사용됩니다. 이 때 cross attention레이어를 추가해 inpainting 마스크와 같은 조건을 UNet의 인코딩과 디코딩 사이에 전달할 수 있다고 합니다.
Problem Setup
저자들은 Amodal Completion을 임의의 query object와 modal mask가 주어졌을 때 modal mask를 기반으로 전체 형상과 마스크를 예측하는 것으로 정의했습니다. 이 때, 성공적으로 수행하기 위해서는 occluder만 제거하고 배경은 그대로 두어야 하며 (필요 이상의 큰 범위의 예측하면 안 됨), 객체의 모든 부분이 온전하게 표현되어야하고, 완성된 객체는 배경이나 주변 상황과 어우러지는 형태로 예측되어야 한다고 합니다. 이를 위해 앞의 두 요소를 평가하기 위해 자연 이미지에서 가려지지 않은 객체 데이터셋을 통해 기준을 만들고, 인위적으로 가린 pseudo-occluded버전을 만들어 테스트했다고 합니다. 이미지의 문맥상에 어울리는지는 계량화 하기 힘든 관계로 user study를 수행했습니다.
Naive Outpainting
Naive outpainting이라는 방법은 Modal Mask(현재 보이는 영역)을 제외한 모든 영역을 복원 대상을 가리는 물체라고 판단하고 이를 복원(outpainting)하는 방법입니다. 이 방법은 문맥적인 부분을 고려하지 않기 때문에 객체가 주변정보를 고려하지 않은 채 그림상에서 잘못된 형태나 방을 가지고 복원될 수 있습니다. 아래 그림과 같이 오토바이의 방향이 이상하게 복원되는 것이 그 예 입니다.

Progressive Occlusion-aware Completion
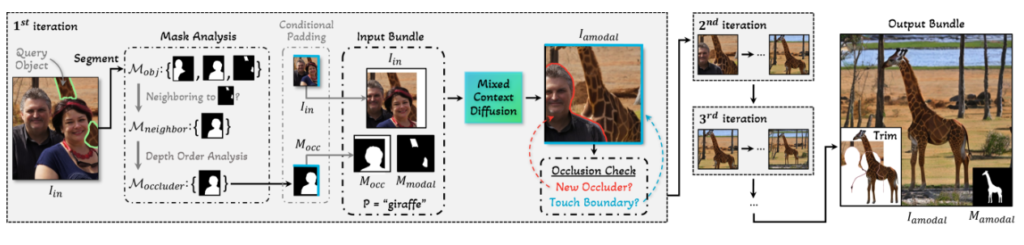
Naive outpainting의 문제를 해결하기 위해서 가려진 부분만 복원을 하고, 반복적인 복원을 통해 완성도를 높이는 Progressive Occlusion-aware Copmletion이라는 방법을 사용합니다. 입력 이미지 Iin에서 모든 객체 마스크를 식별하고 객체 마스크 집합 Mobj={M1,M2,…,Mn}를 생성합니다.관심 객체의 모달 마스크 Mmodal과 인접한 객체 마스크만을 선별하여 이웃 마스크 집합 Mneighbor로 필터링합니다. 깊이 순서 분석을 통해 카메라에 더 가까운 마스크들을 가리개(occluder)로 간주하고, 이들로부터 단일 binary 가리개 마스크 Mocc를 생성하여 diffusion 과정에서 사용할 입력 마스크로 활용합니다. 이 때 관심 객체가 이미지 경계에 닿아 있다면, 경계도 가리개로 간주하여 Iin와 입력 마스크 Mocc에 패딩을 적용합니다. 이후 목표 객체의 Bbox 기준으로 이미지를 잘라낸 후 Iin, Mocc, Mmodal 을 활용해 Mixed Context Diffusion을 수행해 이미지를 생성합니다. 만약 결과물이 여전히 Mocc 에 가려져 있다면 반복적으로 진행합니다.
Mixed Context Diffusion Sampling
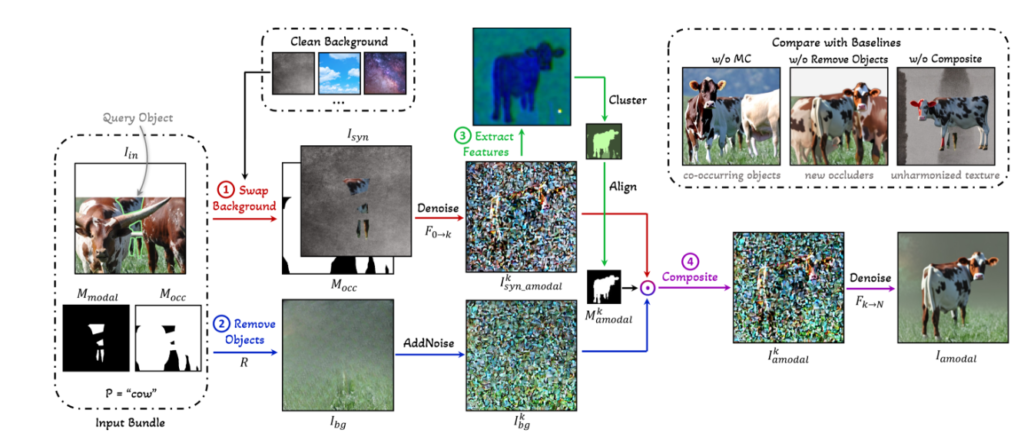
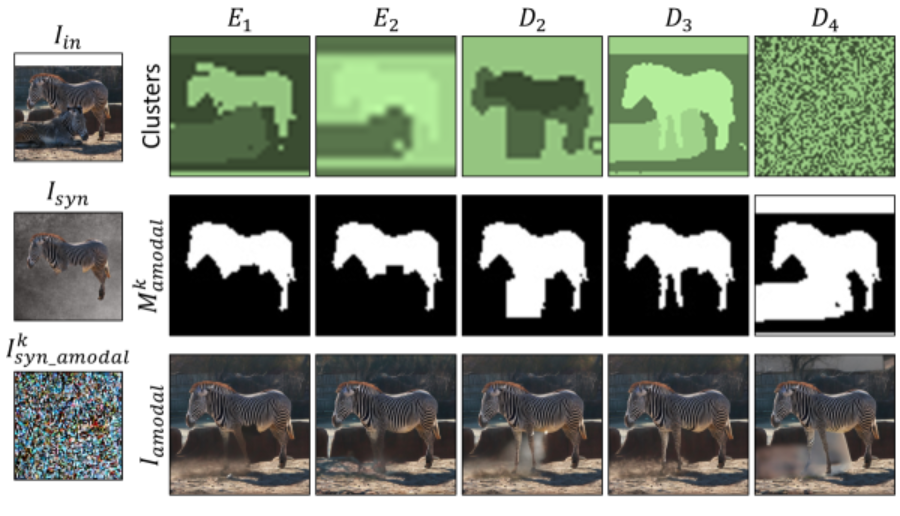
Mixed Context Diffusion Sampling의 가장 핵심인 부분은 그림의 문맥상의 영향을 받아 의도치 않은 복원을 막는 것 입니다. 이를 위해서 먼 대상 객체와 배경을 중간에 분리시킵니다. Mmodal 외부 영역을 물건의 제품 촬영에 사용되는 회색 배경과 같은 깨끗한 배경으로 대체하여 합성된 이미지 Isyn 을 만들어 분리시키고, Isyn과 Mocc를 사용해 inapinting을 k번 진행하여 Iksyn_amodal를 생성합니다. 이후 Iin에서 Mmodal 과 Mocc를 결합한 영역을 제거함으로써 배경만 추출하고, 배경 이미지에 k단계의 노이즈를 추가해 노이즈가 추가된 배경 Ikbg 를 얻습니다. 이후 각각 Iksyn_amodal과 Ikbg 에서 복원하려는 대상의 구역을 UNet 디코더의 latent feature를 활용해 클러스터링 합니다. 클러스터링된 잠재 정보 중 각 클러스터의 픽셀을 Mmodal 과 겹치는 영역으로 비교하여, Mmodal 과 가장 잘 일치하는 클러스터를 대상 객체로 식별합니다. 이렇게 선택된 클러스터가 노이즈 이미지에서 대상 객체의 아모달 마스크 Mkamodal 를 정의합니다. 마지막으로 Mkamodal를 사용하여 대상 객체를 Ikbg 에 다시 결합하여 최종 합성 이미지 Ikamodal 를 생성합니다. 요약하자면 그림상에 존재하는 문맥의 편향을 줄이기 위해 배경과 객체를 따로 처리한 뒤 결합하는 방법입니다.
Counterfactual Completion Curation System
앞서 저자가 이야기한 핵심 중 하나인 이미지 복원을 하고 난 뒤 완성된 이미지가 성공적으로 생성됐는지, 아니면 아직 불완전한 상태인지를 판별하는 시스템으로, 설정된 규칙을 통해 성공 여부를 판별하는 시스템 입니다. 이 시스템은 만약 객체의 복원이 온전히 끝나지 않았다면 outpainting을 할 때 불완전한 부분이 추가로 painting되고, 온전하다면 그렇지 않을 것이라는 원리를 사용합니다. 대상 객체의 아모달 마스크 영역 이외의 부분인 새로운 배경을 만들고, 그렇게 만들어진 이미지에서 배경을 제거한 새로운 마스크를 추출한 뒤, 새로운 마스크가 원래에 비해 얼마나 커졌는지를 통해 평가합니다. 아래 사진과 같이 임계값 보다 차이가 더 많이 난다면, 새롭게 inpainting된 부분이 많다고 판단해 온전한 amodal completion이 수행되지 않았다고 간주합니다. 이 임계값을 설정하기 위해 100장의 이미지로 구성된 validation set을 사용했습니다. 이 시스템은 따로 training이 필요하지 않은 시스템임을 강조했습니다.

Experiments
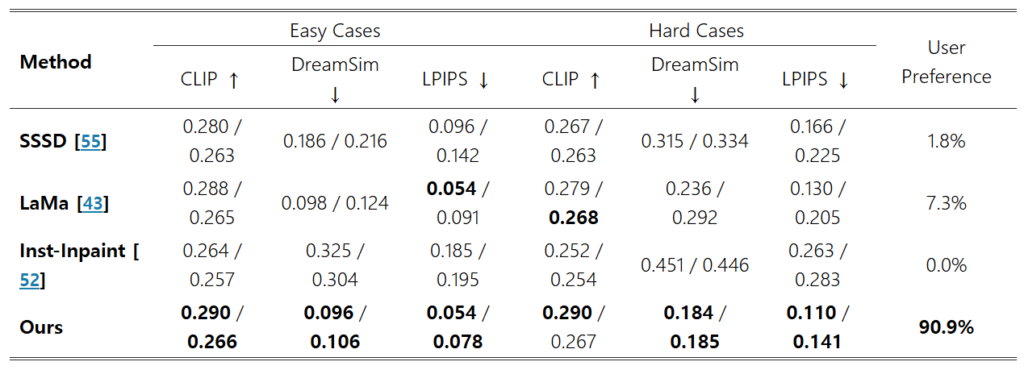
저자는 기존의 GAN기반의 모델들인 SSSD와 LaMa, 그리고 diffusion 기반 모델인 Inst-Inpaint와 결과를 비교했습니다. 여러 수준의 occlusion을 가지고 있는 데이터셋을 만들어 평가했고, 이 때 기존의 방법들은 원본 이미지 구역 안에서만 amodal completion을 수행했기 때문에 공정한 비교를 위해 이미지 경계 내에서 객체를 완성하는 것에 두었다고 합니다. 이 때 데이터셋을 만든 이유는 기존에 amodal completion에 대한 ground truth가 존재하는 natural 이미지로 구성된 데이터셋이 없을 뿐 만 아니라 기존 amodal 데이터셋의 gt 마스크는 amodal completion이 여러 방향으로 이루어질 수 있는데 그 다양성을 반영하지 못 하는 한계가 있기 때문이라고 합니다. 이러한 한계를 극복하기 위해 저자는 COCO와 Open Images의 자연 이미지를 사용해 아래 사진과 같이 단순히 한 객체를 다른 이미지의 객체로 가리면서 3000개의 amodal 데이터셋을 만들었다고 합니다. 직접 만든 데이터셋에는 가려진 비중이 20~50 퍼센트인 쉬운 케이스와 50~80 퍼센트인 어려운 케이스로 나누어져 있습니다.

또한 생성된 이미지와 Ground Truth이미지의 정량적인 유사도를 평가하기 위해 high level은 CLIP, mid level은 DreamSim, low level은 LPIPS를 사용해 평가했습니다. CLIP에서는 생성된 이미지의 임베딩과 쿼리 객체 카테고리의 텍스트 임베딩 간 유사도를 계산했고, DreamSim과 LPIPS에서는 생성된 이미지와 Ground Truth 간의 perceptual distance를 계산합니다. 이 때 배경을 검은색으로 바꿔 객체에 더 집중할 수 있게 만들었습니다.
이를 통해 나온 결과를 보면 저자의 방법은 기존의 방법들보다 전반적으로 더 높은 성능을 보입니다. 하지만 여기서 LaMa는 amodal completion을 위한 방법이 아님에도 불구하고 비슷한 점수를 얻었는데, 작가는 이를 inpainting된 영역 내에서 쿼리 객체와 유사한 색상의 픽셀을 생성하기 때문이라고 추정했습니다. 정성적인 부분을 살펴보면 확실히 저자의 방법이 더 우수함을 볼 수 있고, 이를 어필하기 위해 사람에게 쉬운 경우와 어려운 경우에서 각각 55가지 케이스에 대한 결과물을 보고 투표를 받아서 수치화한 User Preference 항목을 추가했습니다. 정성적 결과물을 보시면 아시겠지만 User Preference에서는 확실한 차이가 보여집니다.

Ablation Studies
저자는 Progressive Occlusion-aware Completion과 Mixed Context Diffusion Sampling의 효과를 입증하기 위해 100개의 이미지를 골라서 Naive Outpainting과 각각 비교하는 과정을 거쳤는데, 쉬운 케이스와 어려운 케이스를 각각 50개씩 준비하고 완성된 이미지를 실제 사람에게 피드백을 통해 성공 여부를 판단했습니다. 완성도, 현실성에 대한 부분을 평가했고, Mixed Context Diffusion을 사용하지 않았음에도 불구하고 더 우수한 평가를 받았습니다. 어려운 케이스인 경우 Mixed Context Diffusion Sampling을 사용하면 성공적인 완성 비율이 18% 증가하는 것을 보여줌으로써 어려운 케이스의 경우 Mixed Context Diffusion Sampling이 amodal completion의 성공률을 유의미하게 높인다는 것을 어필했습니다.
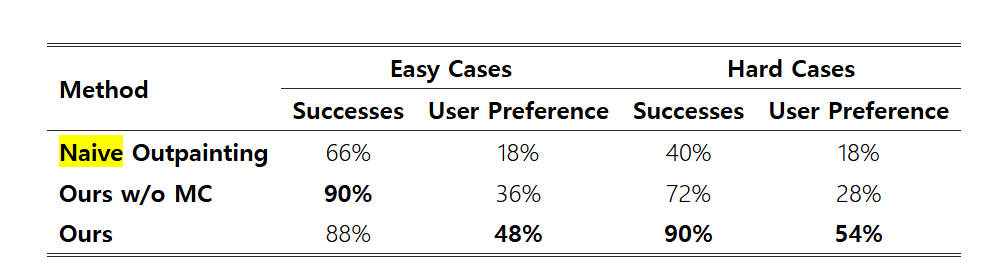
또 amodal complition을 진행하면서 배경을 없애버리는 것의 효과를 입증하기 위해 다섯가지 배경을 가지고 테스트 했을 때, 회색 배경을 사용한 경우 성공 비율이 20퍼센트 늘어났고, 숲이나 하늘과 같은 배경을 사용했을때는 각각 16퍼센트와 9퍼센트 감소했다고 합니다. 회색 배경으로 대체하는 것이 객체 구분을 하는데 확실한 도움을 주는 것 같습니다. 더 나아가 UNet의 디코더 레이어 중 몇번째 레이어가 Mkamodal 를 구성할 때 유리한지에 대한 실험도 진행했는데, 초기 인코더 레이어는 때때로 인페인팅 마스크 영역을 클러스터링하는 문제가 있고, 마지막 디코더 레이어는 노이즈가 많은 문제가 있어 세번째 디코더 레이어 선택이 가장 좋은 결과를 만들어 준다고 합니다. 이는 아래 그림을 통해 눈으로도 확인할 수 있습니다. 다른 레이어에서는 얼룩말의 다리가 잘 구분되지 않는 모습을 보여줍니다.
Counterfactual Completion Curation System의 경우 학습된 시스템이 아닌 그저 특정 규칙에 의존해서 평가하는 시스템임에도 불구하고 0.7의 정확도를 기록했고, 저자는 학습이 추가될 경우 더 높은 성능을 기대할 수 있다고 합니다. 어떻게 학습시킬지에 대한 내용은 없는 것 같습니다. 인간의 정확도가 83퍼센트로 나온것을 보면 그래도 어느정도 성공 여부를 분류할 수 있는 시스템인 것 같습니다.
Discussion
저자는 기존의 amodal mask를 예측하고 외형을 복원하는 방식과 달리 외형을 직접 예측하는 방법을 택함과 동시에 그 과정에서 mixed context diffusion sampling이 co-occurence 문제를 해결할 수 있고, 이러한 방법은 많이 가려진 물체임에도 불구하고 dense correspondence와 novel view synthesis를 아래와 같 문제없이 구현할 수 있다고 합니다.

Limitations
작은 쿼리 객체가 큰 물체로 가려졌을 때 가끔 너무 과대하게 completion을 하거나 쿼리 객체에 그림자가 있을 때, 인간의 특정 자세가 다른 객체와의 상호작용을 할 때 occluder가 무엇인지 잘 구분하지 못 하는 한계가 있지만, 그럼에도 불구하고 해당 amodal completion 방법은 기존 방법에 비해 새로운 기준이 되었다고 저자는 말합니다. 더 복잡한 상황에서의 amodal completion은 향후 연구에서 다룬다고 합니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
amodal completion이라는 task는 처음 접해봐 새롭네요. 생성형 이미지를 통해 이미지 내 객체의 가려진 구간을 예측하는 task인 것으로 이해했습니다. 아무래도 라벨이 정해진 task가 아니다보니 평가를 하는 것이 까다로울 것 같은데 평가지표에서 perceptual distance는 어떻게 계산되는건가요? 또 평가지표로 CLIP, DreamSim, LPIPS가 사용되는 이유도 궁금합니다.
감사합니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
amodal completion 태스크가 확실히 새로운 용어를 많이 사용해서 리뷰를 이해하며 읽는 데 꽤나 시간을 들인 것 같습니다.
결과론적으론 배경과 객체를 분리해서 diffusion 처리하면서 image의 context bias 영향을 받은 이미지 생성을 완화할 수 있었다가 핵심인 것으로 이해했습니다. 질문 몇가지 드리겠습니다.
1.
Progressive Occlusion-aware Completion에서 관심 객체의 모달 마스크 M_modal과 인접한 객체 마스크만을 선별하여 이웃 마스크 집합 M_neighbor 로 필터링한다고 하셨는데, 필터링은 어떤 방식으로 진행하나요?
2.
그 다음 문장의 깊이 순서 분석은 DFS를 뜻하나요?깊이 순서 분석이 논문 상으로는 depth ordering 기법이라면서 이전의 어떤 논문에서 제시한 방법론인 것으로 파악되는데요. 그렇다면, 해당 깊이 순서 분석(depth ordering)을 통해 카메라에 더 가까운 마스크들을 가리개(occluder)로 간주하고~ 라고 하셨는데카메라에 더 가까운 마스크들은 어떻게 판단하는 건가요?
3.
Ik_{syn_amodal} 과 Ik_{bg} 에서 복원하려는 대상의 구역을 UNet 디코더의 latent feature를 활용해 클러스터링한다고 하셨는데, 구역을 클러스터링 한다는 게 무슨뜻인지?! segmentation 영역을 의미하는지? 궁금합니다.
4.
Counterfactual Completion Curation System
의 경우에는 임계값을 어느정도로 설정하는 지 리포팅 되었나요? 단순 마스크 영역이 얼마나 커졌는지 비율로만 따지면 너무 주관적일 것 같단 생각이 들었습니다. 왼쪽 영상의 어린아이도 없던 머리띠가 생기긴 했으니까요.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
progressive occlusion aware completion 파트에서 깊이 순서 분석이라는 게 나오는데, 이미지에서 segment 나오는 저 map이 그럼 depth map이 되는건가요 ?? figure 상으로는 단순히 segmentation을 하고 나온 binary map 같은데 .. 카메라에 더 가까운 마스크라는 것을 어떤 정보로 판단할 수 있다는 건지 헷갈립니다.
다음으로 성공 여부를 판별하는 시스템에서 오른쪽 그림과 같이 임계값보다 새로운 마스크가 커질 경우에 불완전한 completion이 됐다고 판단한다고 말씀해주셨습니다. 그런데 이 임계값과 마스크의 차이라는게 이미지마다, 복원할 객체에 따라 매우 상이할 것 같다는 생각이 드는데, validation set 100장만으로 임계값을 설정하는 것이 과연 정확할지 조금 의문이 드는 것 같습니다. 혹시 이에 대한 ablation study가 따로 있지는 않았을까요?
마지막으로 amodal completion task를 계속 리뷰하시는 이유가 있을까요 ?? 하고 계시는 task와 amodal completion이 어떤 연관성을 가지고 있는지 궁금합니다.
감사합니다.