
논문: Compact Deep Invariant Descriptors for Video Retrieval
2014년 Motion Picture Experts Group (MPEG)은 Compact Descriptor for Video Analysis (CDVA) 표준화 작업을 시작했습니다. 이 작업을 위해 Ling-Yu Duan 등의 연구진은 CNN 모델을 이용한 Nested Invariance Pooling (NIP) 방법을 제안하여 bitrate를 낮추면서 performance도 올리는 연구를 2017년 Data Compression Conference (DCC)에서 발표 했습니다.
CDVA를 알기 전에 Compact Descriptors for Visual Search (CDVS)에 대한 이해도 필요한데요. 마찬가지로 MPEG에서 2009년 시작한 표준화 작업으로 모바일에서 visual search가 동작하기 위해 이미지(or 비디오 프레임) 특징점을 잘 추출하는 handcraft 방법을 사용하면서 전송이 용이한 방법을 개발하는 것입니다.
이 논문에서는 아래의 3가지 성과를 발표하였습니다.
- NIP를 제안하여 translation, scale, rotation에 강인하게 만들었다.
- NIP 방법으로 CNN 특징 차원을 크게 줄였다.
- NIP 방법이 CDVA Ad-hoc 그룹에 의해 CDVA core 실험에 적용되었다.
연구진은 NIP의 backbone으로 AlexNet과 VGG-16을 비교 실험을 하여 최종적으로 VGG-16을 선택하였습니다. 이 실험 결과의 발표가 2017년이므로 ResNet이 보편적으로 backbone으로 쓰이기 이전이기 때문에 상황에 맞게 backbone을 교체해보는 것도 좋을 것 같습니다. 이 기고문에서도 저자는 네트워크의 깊이가 깊을 수록 표현력이 높아지기 때문에 AlexNet 대신 VGG-16이 좋은 표현력을 가진다고 언급했습니다.
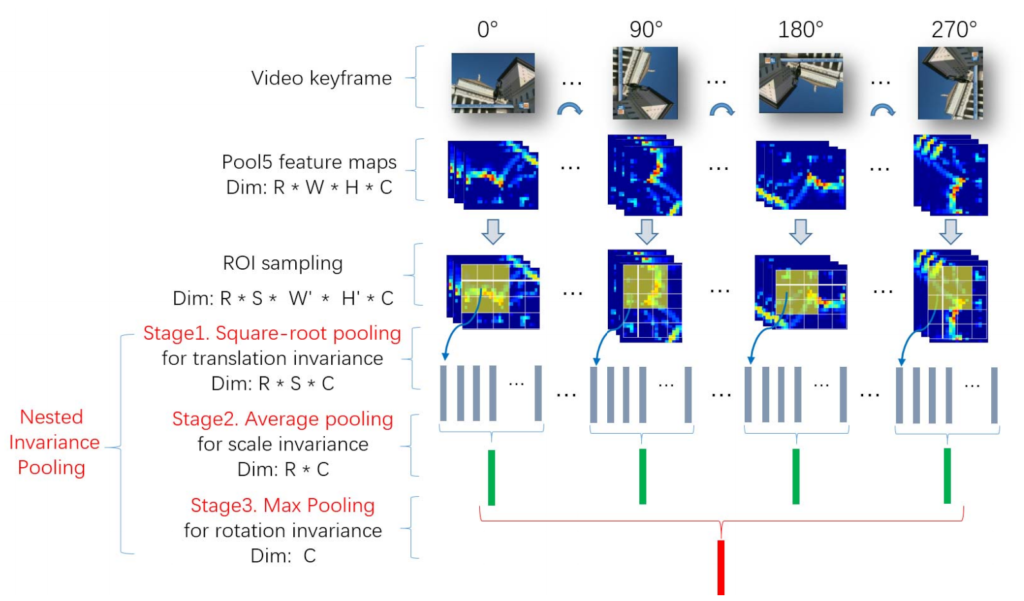
일반적인 CNN filter는 특징을 잘 학습하고 위치 정보를 가지고 있지 않지만 Pooling을 통해 object의 translation에 강인한 정보를 얻을 수 있는 아이디어에서 출발합니다. 그림 1과 같이 1개의 Video keyframe (=이미지)가 input으로 들어오면, 이미지를 90도씩 회전하여 VGG-16의 pool5결과를 가지고 NIP방법을 적용합니다. 식 1은 NIP의 Pooling에 관한 식이며, n의 값을 변경하여 square-root, average, max pooling을 실행하게 됩니다.
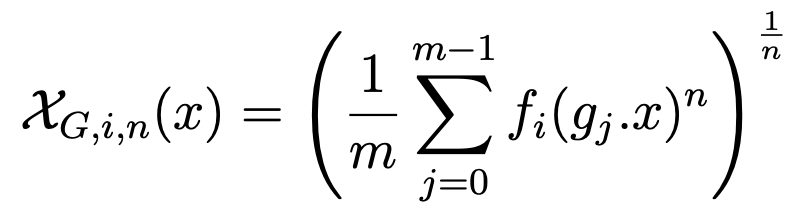
조금 더 자세히 살펴보게 되면 pool5를 통해 feature map을 4개의 rotation에 대하여 얻고 (R * W * H * C), 미리 정해놓은 20개의 ROI 크기와 위치에 따라 feature map을 (R * S * W’ * H’ * C)로 확장합니다. 1번째 pooling을 수행할 때 n=2인 값으로 수행하여 차원의 크기가 R * S * C를 가지게 하여 translation에 invariance 하게 해줍니다. 2번째 pooling은 n=1을 가지는 average pooling을 해주면서 차원의 크기가 R *C로 줄여주고, S의 크기만큼 차원을 줄여준 것으로 scale에 invariance 하다고 합니다. 3번째로 n=∞ 를 가지게 하여 max pooling을 해주고 차원의 크기를 C로 만들어 rotation에 invariance하게 해주는 동시에 bitrate에 알맞게 줄여주게 됩니다. 마지막으로 NIP를 통해 얻은 descriptor를 L2 normalized 해준 뒤 PCA를 사용하여 32차원으로 변경시켜줍니다.

그림 2를 보면 (a), (b)에서는 NIP의 결과가 좋지만 (c), (d)에서는 CDVS의 성능이 더 좋은 것으로 보입니다. 이 문제를 해결하기 위해 NIP와 CDVS의 hybrid 방법을 식 2와 같이 제안하였습니다. 식 2의 Sc는 NIP의 descriptor를 의미하고, St는 CDVS의 descriptor를 의미하며 실험을 통해 α=0.75 값을 가지게 됩니다.
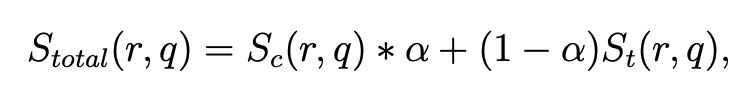

실험은 표 1과 같이 MPEG CDVA dataset을 사용하였으며, 표 2는 NIP와 다른 방법의 비교를 나타낸 것이며, 표 3은 서두에서 언급한 backbone network의 비교 및 hybrid 방법의 비교를 나타낸 것입니다.
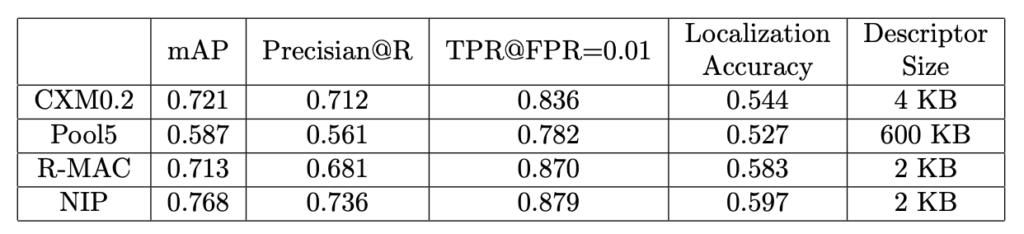
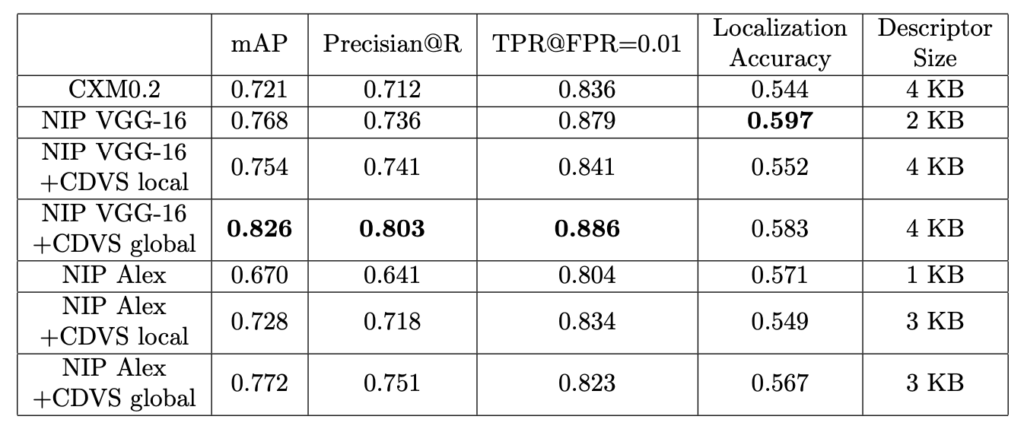
성능이 월등하게 좋아진 것은 물론이고, CDVA에서 중요하게 생각하는 bitrate 전송을 위해서는 descriptor의 크기도 중요합니다. 기본적으로 pool5를 통과하고 나오는 feature map의 channel 크기는 AlexNet이 256, VGG-16이 512이므로 각 1KB, 2KB의 크기를 가지고, CDVS의 local, global descriptor의 크기는 2KB입니다.
이 문서에서 CDVA의 전체 설명이 아닌 NIP 방법을 제안하고 CDVS와 결합하여 성능이 향상된 것을 알 수 있었습니다. 성능을 높이기 위해 NIP의 backbone을 ResNet 등으로 교체해 보는 방법이 있을 수 있겠고, CDVA에서 가장 중요하게 여기는 bitrate 전송 크기 역시 그림 2에서 보여주는 모습과 다르게 개선된 NIP로 CDVS에 비해 특정 사물, 위치에 더 강인할 수 있다면 hybrid 방법을 쓸 필요가 없을 것이고, 결과적으로 CDVS descriptor 크기인 2KB 만큼 전체 descriptor의 크기를 줄일 수 있을 것입니다.
위의 그림1을 보면 학습과정에서는 하나의 이미지를 여러 각도로 회전시켜 모델의 입력으로 넣고, 이러한 것들을 통합해 새로운 descriptor로 제작하는것으로 보이는데 테스트시에는 하나의 입력만 넣으면 되는 것인지, 아니면 테스트 진행시에도 해당 이미지를 여러각도로 회전시켜 가면서 입력으로 넣어줘야하는것인지 궁금합니다!
좋은 질문입니다. 이 논문에서는 VGG-16의 pretrained 모델을 가져다 쓰는 형식이고 별도의 학습을 진행하지 않습니다. Pooling layer 5 이후의 작업인 ROI도 크기와 위치를 미리 지정해 놓았고, 이 후 수행하는 작업들도 pooling 작업이기 때문에 별도의 학습이 필요한 parameter가 없습니다. 따라서 테스트 진행시에 이미지를 90도씩 회전하여 입력으로 넣어주게 되어있습니다.
그럼 결국 테스트마다 하나의 이미지를 여러번 처리해야하는데 비효율적인게 아닌가라는 생각이 듭니다. 이러한 관점에서도 논문에서 이야기하고 있는지 궁금합니다. 그리고 추가로 지금 대부분의 이미지가 R,G,B 3채널인데 위의 컨셉이라면 90도 회전한 이미지 3채널씩 총 12채널의 이미지를 하나로 concat해서 모델에서 처리해도 되지 않을까요?
논문에서는 비효율적인 면에 대해서 언급하지 않고 회전에 강인하게 만든다는 장점만 어필하고 있습니다. 회전한 이미지들을 concatenate 하는 방법도 생각해볼 수 있지만 이 논문에서는 각 회전한 이미지가 VGG의 pool5의 feature map으로 나왔을 때 미리 지정된 ROI를 통해 나온 값이 회전된 feature에 scale까지 강인하게 만든다는 것을 강조하고 있습니다. 여타 다른 연구 논문과 달리 제안하는 방법이 이렇게 했더니 성능이 올랐어라기보다 어떤 문제를 해결하기 위해 제안한 방법이 수학적(?)으로 이렇게 해결 가능하다라는 문구로 설명되어 있습니다.