
안녕하세요, 허재연입니다. 오늘 다룬 논문은 2020년에 Google Research에서 NeurIPS에 게재한 논문으로, FixMatch라는 대표적인 Semi-Supervised Learning 방법론 중 하나 입니다. 지금껏 Active Learning이나 Self-Supervised Learning 계열 논문들을 많이 읽어왔었는데, 처음으로 Semi-Supervised Learning(이하 SSL) 논문을 다뤄보게 되었습니다. 리뷰 시작하겠습니다.
Introduction
컴퓨터 비전 어플리케이션에 있어 이제 딥러닝 기술을 빼놓고 말할 수 없게 되었습니다. DNN 기술은 다양한 분야에 적용되어 좋은 결과를 보여주었고, 아직도 활발히 발전하고 있습니다. 이러한 딥러닝 기술의 성공에는 대량의 학습 데이터가 필요합니다. 더욱 크고 질 좋은 데이터셋을 확보할수록 딥러닝 모델의 성능이 개선되기에, 좋은 데이터셋을 확보하는것이 아주 중요해졌습니다. 문제는 취득한 raw data에 대한 annotation에 시간과 비용이 많이 발생한다는 것입니다. task가 고도화되어 복잡한 label이 필요할수록, annotation을 수행하는데에 있어 전문적인 지식이 필요할수록 이러한 cost는 급증합니다. 이러한 문제를 해결하기 위해 AI 연구자들은 다양한 기법을 기발해왔습니다. Active Learning 연구는 labeling 효율이 좋은 고가치 데이터를 선별하고자 하며, Self-Supervised Learning 연구는 라벨링 없이 데이터 자체만으로 좋은 representation을 확보하고자 합니다. 그리고 Semi-Supervised Learning(SSL)은 labeled data와 unlabeled data를 함께 이용하는 방법으로 labeling cost에 대한 부담을 완화하고자 합니다.
논문이 제안될 당시 다양한 계열의 SSL 방법론들이 제안되고 있었다고 합니다. 대표적으로는 pseudo-label(self-training)을 생성하여 모델을 학습시키거나, consistency regularization을 활용해 입력이나 모델 함수를 무작위로 수정하여(일종의 augmentation) 인공적인 라벨값을 얻어 사용합니다. 본 논문에서는 FixMatch라는 간단한 방법론을 제안하여 SSL을 수행합니다. 약하게 증강된(flip이나 shift) unlabeled image를 활용하여 인공 라벨을 생성하고, 이렇게 생성한 인공 라벨을 강한 augmentation을 적용한 이미지을 입력했을 때에 대한 target으로 사용합니다. 강한 증강 기법에는 Cutout, CTAugment, RandAugment 등이 활용되어 주어진 이미지를 심하게 왜곡하게 됩니다. 수도라벨링 기법을 따라서, 모델이 예측한 확률값이 큰 경우에만 인공 라벨을 유지하도록 하였습니다.
방법론이 간단함에도 불구하고 FixMatch는 당시 일반적으로 연구되는 많은 SSL benchmark에서 SOTA를 달성하였습니다.
Method
FixMatch는 1.Consistency regularization 과 2.pseudo-labeling이라는 두가지 기존 SSL 접근법의 조합으로 볼 수 있다고 합니다.
Consistency regularization은 당시 SOTA SSL 알고리즘들에서 활발히 사용되면 방법으로 동일한 이미지에 서로 다른 augmentation을 가해 모델에 입력했을 때 모델이 비슷한 예측 값을 출력할 것이라는 가정을 기반으로 합니다. 일반적으로 모델은 supervised classification loss(cross-entropy를 일반적으로 사용하겠죠)와 다음의 손실함수를 활용해 unlabeled data를 학습합니다:
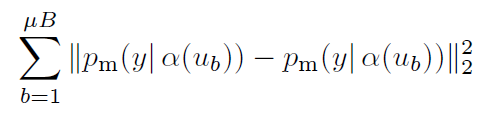
여기서 α와 p_{m}은 모두 stochastic function이기 때문에 위 수식에서 두 p_{m}(y|α(u_{b}))는 서로 다른 값을 가지게 됩니다.
Pseudo-labeling은 unlabeled data에 대한 인공 라벨을 얻는 데 모델 자체를 활용한다는 아이디어를 활용합니다. 모델의 예측 출력값의 arg max값인 hard label을 사용하며, class probability가 사전에 설정된 threshold보다 큰 경우에만 수도라벨로 사용하게 됩니다. 모델 input x에 의해 생성된 predicted class distribution p_{m}(y|x)에 대해 q_{b} = p_{m}(y|u_{b})라고 했을 때 pseudo-labeling은 다음의 loss function을 활용합니다:
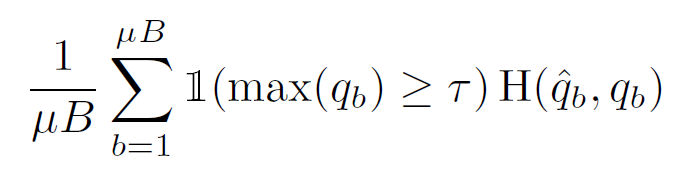
여기서 \hat{q}_{b} = arg max (q_{b})이고 τ는 threshold값입니다. 단순하게 표현하기 위해 확률 분포에 적용된arg max가 유효한 one-hot 확률 분포를 만든다고 가정합니다. 이후 unlabeled data에 대한 모델의 예측값은 hard label을 사용하여 low-entropy(high-confidence)를 갖도록 학습됩니다.
FixMatch
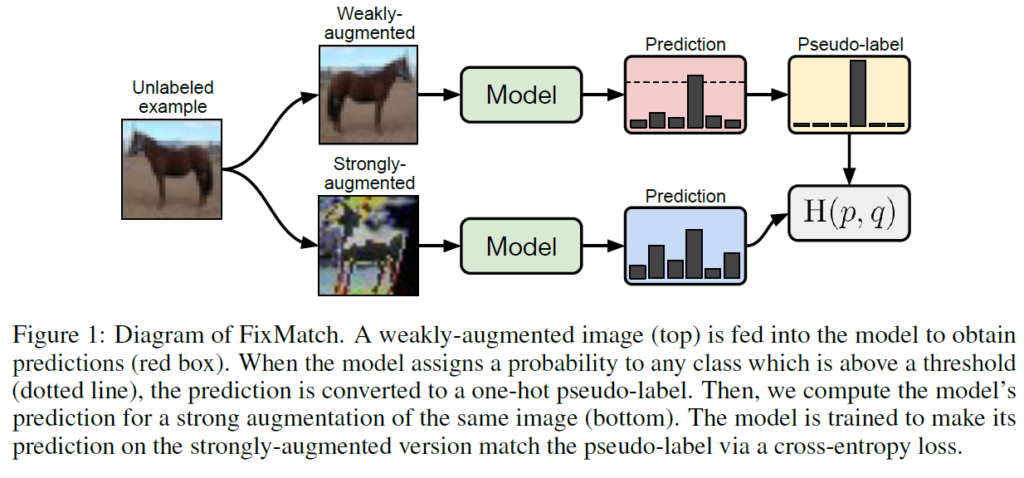
pseudo labeling과 consistency regularization을 살펴보고 나면 FixMatch 프레임워크는 어렵지 않습니다. 요약해보면(Figure1참고), weakly augmented된 입력 이미지에 대해서는 model의 예측 분포에서 arg max confidence값이 사전에 설정된 threshold 이상이라면 이를 one-hot 형태의 hard label로 바꿔 이를 pseudo label로 사용하여, strongly augmented된 입력 이미지에 대한 모델의 예측 확률 분포와 수도라벨을 Cross-Entropy로 학습을 진행하게 됩니다.
FixMatch의 손실함수는 2개의 cross-entropy loss term l_{s}, l_{u}로 구성되며, 각각 labeled data에 적용되는 supervised loss l_{s}와 unsupervised loss l_{u}입니다. l_{s}는 일반적인 cross-entropy loss이며, weakly augmented labeled examples에 대해 적용됩니다. 여기서 H(p,q)는 확률분포 p와 q 간 cross-entropy입니다.
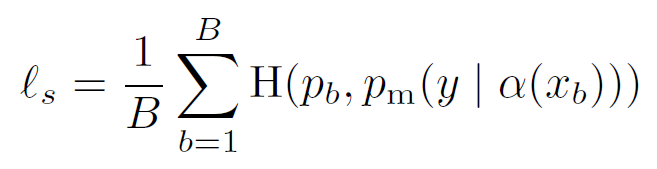
각 unlabeled example에 대해서는 인공 라벨을 계산한 뒤 cross-entropy를 적용합니다(여기서 저자는 unlabeled dataset을 구성할 때 labeled data들도 함께 사용하였다고 합니다. 라벨값을 버리고 unlabeled pool에 넣었다고 생각하시면 됩니다). 인공 라벨은 위에서 설명했던 것처럼 unlabled image에 weakly-augmentation을 적용하여 모델의 예측 확률 분포 q_{b} = p_{m}(y|α(u_{b}))를 얻은 뒤 \hat{q}_{b} = arg max (q_{b})를 pseudo label로 사용하게 됩니다. 수도 라벨은 unlabeled image에 strongly-augmented를 적용한 후 모델을 거쳐 나온 예측 확률 분포와의 cross-entropy 계산에 활용됩니다.
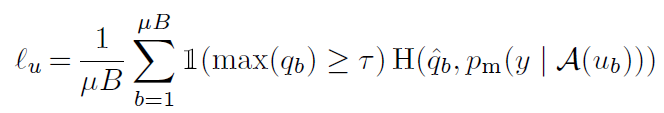
τ는 위에서 설명했던 것과 같이 hard label에 대해 수도라벨로 유지할 것 인지를 결정하는 threshold parameter입니다. 최종적으로 FixMatch의 loss는 l_{s} + λ_{u}l_{u}입니다. λ_{u}는 각 loss term에 대한 가중치입니다. 당시 일반적인 SSL 방법론들은 unlabeled loss term에 대한 가중치 λ_{u}를 학습이 진행되면서 증가하도록 하였는데, FixMatch의 경우 학습 초기에는 max(q_{b})가 보통 τ보다 작았으며 학습이 진행됨에 따라 모델의 예측값이 더욱 confident해져 점점 max(q_{b}) > τ인 빈도가 높아져 loss의 가중치를 조정하는 것이 필요가 없음을 발견했다고 합니다.
결과적으로 FixMatch의 의사코드는 다음과 같이 나타낼 수 있습니다.

FixMatch의 학습 전반 과정에는 약한(weak) 증강 기법과 강한(strong) 증강 기법이 함께 사용되는데, 여기서 약한 증강은 flipping과 shifting을 적용한 것입니다. 강한 증강 기법에는 AutoAugment 기반의 두 증강 기법인 RandAugment와 CTAugment라는 증강 기법이 적용된 뒤 Cutout을 적용했다고 합니다. 이외 디테일한 부분으로는 간단한 weight decay regularization을 사용했으며, Adam optimizer를 사용하면 성능이 저하되어 SGD with momentum을 사용했고 LR scheduler로는 cosine learning rate를 사용했다고 합니다.
Experiment
experiment에서는 이미지 분류 벤치마크를 통해 FixMatch의 효율성을 평가하였습니다. CIFAR-10/100, SVHN, STL-10, ImageNet데이터셋에 대해 다양한 증강 기법으로 다양한 labeled data 양에 대해 성능이 평가되었습니니다. FixMatch가 데이터 레이블이 매우 적은 세팅에서 가능성을 보여주었기 때문에 많은 경우 이전보다 적은 수의 label로 실험하였다고 합니다.
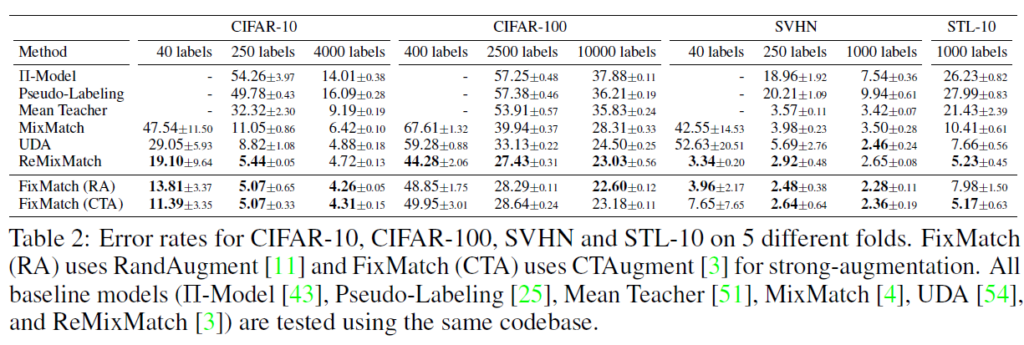
CIFAR-10, CIFAR-100, and SVHN
저자들은 모든 베이스라인을 재구현해 동일한 코드베이스에서 실험을 수행하였다고 합니다. 실험에서 네트워크 구조, 학습 프로토콜(optimizer, lr schedule, data preprocessing 등)은 동일하다고 생각하시면 됩니다. Table2에서 결과를 확인할 수 있는데, 5-fold로 labeled data를 사용하여 정확도의 평균과 표준편차를 계산하였습니다. FixMatch는 CIFAR-100 세팅을 제외하고서는 모든 세팅에서 가장 좋은 성능을 달성하였습니다. Error rate를 나타냈으므로 성능 수치가 낮을수록 좋은 것으로 생각하시면 됩니다. CIFAR-100에서는 ReMixMatch가 가장 좋은 성능을 보였는데, 저자들은 모델 예측이 labeled set과 동일한 클래스 분포를 갖도록 하는 Distribution Alignment(DA)가 그 원인이라고 분석하였습니다. FixMatch에 DA를 결합하였을 때 400 labeled examples에 대해 40.14% error로 ReMixMatch의 44.28%보다 좋은 결과를 보였다고 합니다.
또한, 클래스당 4개의 label이 있는 세팅을 제외하고서는 CTAugment를 사용한 것과 RandAugment를 사용한 것의 FixMatch 성능이 비슷했다고 합니다. 이는 클래스당 4개의 label을 활용하는 경우 분산이 너무 커지기 때문이라고 합니다(4 labels per class일때 CIFAR-10에서 분산은 3.35%, 25 labels per class일때는 분산 0.33%). 또한 클래스당 라벨이 작은 경우에는 랜덤시드에 의해 error rate가 크게 달라지는 결과를 보였다고 합니다.
STL-10
STL-10데이터셋은 96×96이미지 크기를 가지며, 5000개의 labeled image가 10개 클래스로 분류되어 있고 100,000개의 unlabeled images를 가집니다. unlabeled set에는 out of distribution 이미지가 포함되기 때문에 SSL 성능에 있어서 더욱 어려운 데이터셋이라고 합니다. 해당 데이터셋에 대해 FixMatch는 그 프레임워크가 단순함에도 불구하고 ReMixMatch의 성능을 뛰어넘습니다.
ImageNet
이미지넷에 대한 실험 결과는 딱히 표 없이 줄글로 정리되어 있습니다. 학습 데이터의 10%를 labeled를 사용하였고 나머지는 unlabeled를 사용하였습니다. 신경망은 ResNet-50이 사용되었고 강한 증강 기법으로는 RandAugment가 사용되었습니다. FixMatch는 28.54%의 top-1 error rate를 달성하여 기존 UDA(Unsupervised data augmentation for consistency training)보다 2.68% 개선된 성능을 보였다고 합니다. top-5 error에 대해서는 당시 SOTA였던 S4L이 2단계 학습으로 이미지넷에서 26.79%라는 성능을 기록했던 반면 FixMatch는 10.87%라는 성능으로 크게 능가하였습니다.
Sharpening and Thresholding
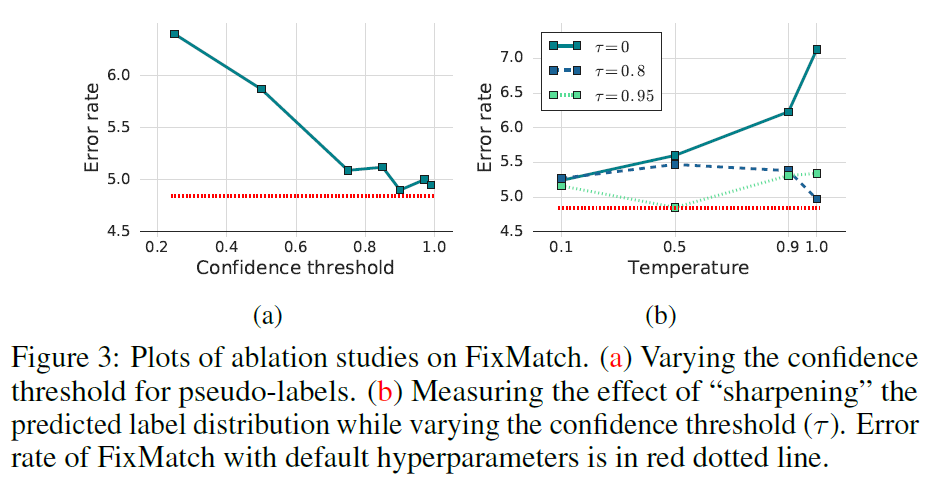
저자들은 temperature T와 confidence threshold τ에 대한 연구도 진행하였습니다. threshold τ는 0.95에서 가장 낮은 error rate를 보였으며, threshold값 조정에 따른 pseudo-label의 품질과 양에 대한 trade-off 경향을 보였습니다(수도라벨의 양보다는 질이 좋아야 높은 정확도를 달성하는게 도움 되는 것으로 볼 수 있습니다). Temperature parameter의 경우 예측 확률 분포를 sharpening/smoothing하는 정도를 결정하는 하이퍼파라미터인데, τ가 0.95일때 T=0.5인 경우 가장 낮은 error rate을 보였습니다.
처음으로 Semi-Supervised Learning 방법론을 살펴보았습니다. 방법론이 굉장히 간단하면서도 좋은 성능을 낼 수 있는 연구였습니다. data labeling 효율을 다루는 분야인 만큼, 앞으로도 종종 논문을 찾아보며 인사이트를 얻고자 합니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
저자가 적용한 strong augmentation 중 하낭니 CTAugment가 무엇인지 간략하게 설명해주실 수 있나요 !?
또, weakly augmented한 영상을 모델에 태워 뽑은 prediction과 strong aug태워 뽑은 prediction간의 cross entropy가 아닌, one-hot 형태의 hard label로 바꿔 사용하는 건 보통 그렇게 하는 것인지 궁금합니다.
감사합니다.
저도 해당 논문에서 CTAugment를 처음 보는데, 논문에 있는 설명으로는 각 샘플마다 적용할 변형 기법을 무작위로 선택하는 학습 기반 증강 방법이라고 합니다. 다양한 transformation 크기 값을 bin으로 나누고 각 bin마다 가중치를 할당해 확률 분포 기반으로 증강을 적용한다고 하네요. 더 자세한 내용은 CTAugment 논문을 읽어봐야 할 듯 합니다.
제가 semi-supervised learning분야의 흐름을 아직 충분히 파악하지 못해서 해당 세팅이 일반적인 프로토콜인지는 잘 모르겠습니다. soft label이 아닌 hard label을 사용하는 것은, 수도라벨로 one-hot 을 사용해 weak aug에 대한 모델의 예측값을 따라가는게 아닌, (threshold를 걸어놓았으므로 어느정도 정제되어있어서 믿을 수 있는) 수도라벨 자체를 학습하기 위함으로 보입니다. 기존의 수도라벨링 계열 semi-supervised 방법론에서는 이런 방식으로 학습을 진행하는 것 같네요.
안녕하세요. 좋은 리뷰 감사합니다.
weakly augment와 strong augment를 비교하여 학습하는 것이 본 논문의 주요 contribution이라 이해했는데요. 여러 augment가 있을 텐데 이를 weakly와 strong으로 어떻게 구분하였는지가 궁금합니다. 또한 augment을 뭐를 사용했는지에 따라 결과도 많이 달라질 것 같은데 이에 대한 실험결과가 따로 있는지도 궁금합니다.
감사합니다.
리뷰 본문에 적혀있듯, weak augmentation은 flip 및 shift의 단순한 변형을 가하며 strong augmentation은 RandAugment와 CTAugment라는 증강 기법을 사용했습니다. 증강 기법에 대한 ablation은 논문 본문에는 없고 supplementary 에 있습니다. 둘 중 하나가 무조건 더 우세하지는 않습니다.
안녕하세요. 좋은 리뷰 감사합니다.
consistency regularization에서 regular term 내의 수식리 완전 동일해보이는데, stocastic이 어떤 것이길래 두 값이 달라지나요?
수식이 동일하긴 하지만 augmentation과 모델의 예측 distribution이(랜덤성에 의해) 다르기 때문에 결국 출력값 사이 차이가 생깁니다. contrastive learning에서 두 data view를 처리하는 것을 연상하시면 이해가 편할 것입니다. contrastive learning에서 positive pair는 동일한 이미지에 증강 및 모델 예측을 거치지만 결과값인 임베딩 벡터가 다르기에 코사인 유사도를 측정해 그 거리가 가까워지게 만들죠. 이는 증강 기법 및 모델 내부에 stochastic한 요소가 있기 때문입니다.