안녕하세요, 마흔 다섯번째 x-review 입니다. 엄청 오랜만에 엑스리뷰를 쓰는 것 같은데요, 이번 논문은 2024년도 ECCV에 게재된 SegPoint: Segment Any Point Cloud via Large Language Model입니다.
그럼 바로 리뷰 시작하겠습니다.

1. Introduction
3D segmentation은 여러 세분화된 task로 한번 더 나눌 수 있는데요, 가령 기본적인 instance, semantic segmentation이나 명시적인 텍스트 설명을 기반으로 하는 referring segmentation, 그리고 open vocabulary segmentation이 있습니다. 이런 segmentation 분야에서는 각 task에 맞게 특정하게 설계된 모델을 통해 물체를 정확하게 segmentation하는데 집중해왔으나, 그렇게 발전된 모델들은 특정 하나의 segmentation만을 처리할 수 있어 비효율적이며 실제 application 관점에서는 활용도가 부족하다는 한계가 있었습니다. 또한 언어적인 요소를 활용할 때는 미리 정의된 클래스 텍스트나 명시적인 표현에 의존하고 있었다고 합니다. 이러한 언어적 접근은 사람의 말이 보통 문장 안에 암묵적인 instruction이 존재하는데 그걸 해석하지 못하고, 해석하지 못하기 때문에 그에 따른 행동을 하는데도 부족함을 보입니다. 그래서 저자는 이렇게 언급한 모든 3D task를 사람이 하는 것과 유사한 지시어를 해석하여 포괄적으로 처리할 수 있는 통합된 모델을 설계할 수는 없는지에 대한 질문을 던집니다. 이런 질문에 대한 해답을 저자는 본 논문에서 제안하는 SegPoint라는 모델을 통해 찾고자 했습니다.
SegPoint는 사용자의 지시를 추론해서 이해하는 LLM의 기능을 활용하였습니다. 그리고 3차원 장면의 이해도를 높이기 위해서 포인트의 로컬한 영역에 대한 정보를 추출하는 Geometric Enhancer Module을 제안하여 장면의 기하학적인 표현력을 feature extractor 과정에 추가하고자 하였습니다. 또한 Geometric-guided Feature Propagation은 기하학적인 prior와 LLM에서 파생된 semantic flow를 활용할 수 있도록 설계하여 정확한 dense prediction을 하고자 하였습니다.
추가적으로 암시적인 표현과 복잡하게 구성된 지시어를 활용하는 segmentation 분야 연구를 발전시키기위해 Intruct3D라는 벤치마크를 새롭게 제안한다고 합니다. 실제 사람의 미묘한 지시어를 이해하려면 모델이 추론 능력과 포괄적인 지식을 필요로 하게 되는데, 이를 반영해서 총 2,565개의 다양한 지시어와 포인트 pair를 포함하고 있습니다. 이 벤치마크에 대해서는 여러 실험을 통해 입증하였다고 하네요. 이런 지시어나 텍스트와 쌍을 이룬 포인트 클라우드가 포함된 데이터셋이 없었는데 본 논문을 통해서 드디어 3D에서도 이런 텍스트-포인트 데이터셋이 등장한 것 같습니다. 마지막으로 SegPoint를 통해 LLM과 여러 segmentation task별 프롬프트를 활용해서 넓은 범위의 segmentation task에 대한 작업을 수행하였습니다. 여기서 본 논문에 대한 contribution을 정리하면 다음과 같습니다.
- LLM의 추론 능력을 활용하여 인간의 암시적인 지시어를 이해함으로써 처음으로 하나의 프레임워크 안에서 여러 segmentation task를 수행할 수 있는 SegPoint 모델 제안
- Geometric Enhancer Module과 Geometric-guided Feature Propagation을 통해 전체 장면 안에서 누락된 로컬 정보를 보완하고 fine-grained feature을 찾아서 dense prediction task를 수행
- 3D instruction segmentation이라는 새로운 task를 도입하기 위해 Instruct3D 벤치마크를 구축하여 segmentation을 위한 암시적인 지시어를 해석하는 모델의 self 추론 능력 평가
- 실험 결과 semantic, referring segmentation에서 모두 높은 성능을 보일 뿐만 아니라 3D instruction segmentation에서도 안정적인 성능을 보이며 다양한 segmentation task에서의 활용성과 효율성 입증
2. Approach
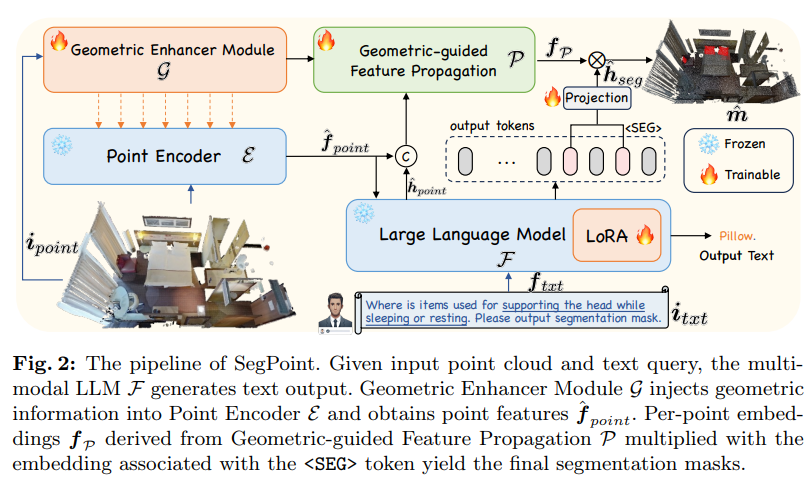
2.1. Architecture Overview
SegPoint의 전체적인 구조는 Fig.2와 같으며, 크게 4가지 구성으로 나누어 볼 수 있습니다.
- 텍스트 데이터와 정렬하도록 사전학습된 포인트 인코더 \mathcal{E}
- 지시어에 대한 추론 능력을 위한 LLM \mathcal{F}
- 입력 포인트에서 기하학적인 표현력을 추출하여 포인트 인코더에 제공하는 Geometric Enhancer Module \mathcal{G}
- 정확한 segmentation 마스크 생성을 위한 Geometric-guided Feature Propagation \mathcal{P}
2.2. Vanilla Baseline
먼저 프레임워크의 입력으로는 텍스트 지시어 i_{txt}와 포인트 클라우드 i_{points} \in \mathbb{R}^{N \times (3+F)}가 들어갑니다. 여기서 포인트는 인코더 \mathcal{E}의 입력이 되어 포인트 feature f_{points} \in \mathbb{R}^{N_1 \times D}를 추출합니다. 이와 동시에 텍스트 지시어는 \mathcal{F}_{tokenize}를 통해 토큰화 되고 나서, LLM \mathcal{F}의 입력으로 들어가서 텍스트 응답 y를 생성합니다. 여기까지의 과정을 식으로 표현하면 (1)과 같습니다.
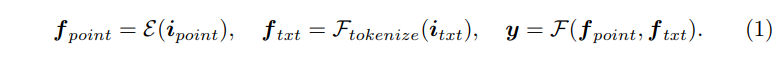
그 다음에는 LLM의 segmentation 성능을 향상시키기 위해 본 논문에서는 추가적인 토큰으로 <SEG>를 활용합니다. 모델이 출력 시퀀스 안에서 <SEG> 토큰을 발견하면 그 뒤로 나오는 segmentation 마스크 예측을 위한 정보로 간주하라는 신호로 인식하고 예측하기 위한 수단으로 사용하는 것이죠. <SEG> 토큰을 한번 발견하면 다시 <SEG> 토큰이 나타나기 전까지 그 사이에 해당하는 출력 시퀀스를 추출하고 MLP \gamma를 통해 마스크 임베딩 h_{seg}를 생성할 수 있게 됩니다. 그 다음으로는 h_{seg}를 f_{point}에서 나오는 포인트 별 임베딩 사이의 내적을 통해 이진 마스크 m \in \mathbb{R}^N을 예측하게 됩니다. 이러한 과정을 수식적으로 정의한 것인 식(2)를 의미합니다.
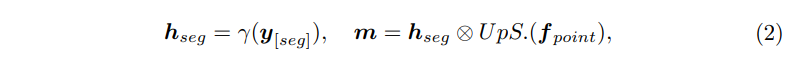
여기서 UpS. 는 f_{point}에 PointNet++과 같은 엄샘플링을 수행하는 것을 의미합니다.
해당 섹션의 Vanilla Baseline은 LLM이 segmentation 지시어를 이해하고 이를 포인트 클라우드 레벨에서의 segmentation task와의 갭을 줄이기 위한 가장 기본적인 구조라고 할 수 있습니다. 하지만 Vanilla Baseline만으로는 두 가지 한계점이 발견되는데요, 먼저 포인트 인코더는 장면 레벨에서의 classification task에 맞춰 학습되어 segmentation과 같은 dense prediction을 위해 특별히 학습되진 않습니다. 단순히 하나의 장면이 들어오면 모델은 “이 장면은 침실이다”고 예측할 수 있는 것이죠. 게다가 인코더의 첫번째 레이어에서는 포인트 샘플링 방식인 FPS를 사용해서 입력으로 들어오는 N개의 포인트를 N_1개로 다운 샘플링하기 때문에 dense prediction을 정확하게 하기 위한 세부적인 포인트 정보가 손실될 위험이 있다고 합니다. 두번째로 포인트 feature에서 포인트별 임베딩을 얻기 위해 N_1을 다시 N으로 직접 업샘플링을 하게 되면 본래 포인트 클라우드의 구조적인 정보를 잃고 상당한 노이즈가 발생하게 되어 모델의 정확도를 떨어뜨릴 수 있습니다.
아래 섹션부터는 이런 Vanilla Baseline의 한계를 보완하기 위한 두 가지 구조를 추가하게 됩니다.
2.3. Geometric Enhancer Module
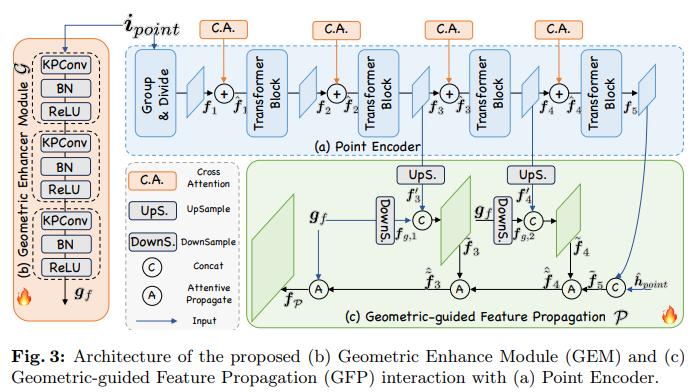
해당 모듈은 인코더가 dense prediction에도 적용할 수 있으면서, 다운 샘플링으로 발생하는 구조적 정보 손실을 보완하는 것을 목적으로 합니다. 포인트 인코더의 기존 구조를 그대로 유지하면서 다운 샘플링으로 인해 손실되는 로컬한 영역들의 기하학적인 정보를 파악할 수 있도록 Geometric Enhancer Module (GEM)을 설계하였다고 합니다.
Fig.3의 가장 왼쪽 (b)를 보면 GEM \mathcal{G}은 세 개의 블럭으로 구성되어 있으며 각 블럭은 KPConv 레이어, BN, 그리고 ReLU 함수로 이루어져 있습니다. KPconv는 포인트 클라우드를 어떠한 변환 없이 그대로 컨볼루션에 적용할 수 있는 방법으로, 포인트의 density에 강인하고 들어오는 포인트의 표현력을 학습하는데 도움이 됩니다. 그래서 이 KPConv를 사용해서 기존 포인트 인코더의 트랜스포머 구조에서 부족했던 로컬한 영역의 기하학적 구조를 효과적으로 파악할 수 있도록 하였습니다. GEM을 타고 나오는 출력값인 g_f \in \mathbb{R}^{N \times D}는 장면 내 모든 포인트에 대한 feature가 포함되어 있어 인코더에서 놓치던 로컬한 정보까지 보완하여 담고 있을 수 있다고 합니다. g_f는 식(3)과 같이 cross attention을 통해 인코더의 feature에 기하학적인 정보를 추가적으로 제공할 수 있게 됩니다.
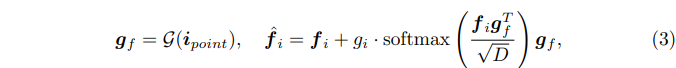
- f_i : 인코더의 i번째 블럭에 해당하는 feautre
GEM이 제공하는 기하학적 정보를 합치는 과정을 fine tuning 하기 위해 attention 레이어의 출력값과 입력으로 들어가는 f_i 사이의 밸런스를 조절하기 위해 학습 가능한 gating factor g_i를 추가적으로 사용하였습니다. g_i는 처음에는 0으로 설정되어 GEM의 기하학적 정보가 합쳐진다고 해서 기존에 사전 학습된 포인트 인코더의 feature의 분포가 갑자기 바뀌지 않도록 도와주며 학습 초기에 모델의 학습 안정성을 확보할 수 있습니다.
Vanilla Baseline에서 포인트 인코더의 출력 feature가 아니라 GEM에서 나오는 기하학적 정보를 통합한 새로운 feature를 사용했을 때 LLM과 마스크 임베딩 결과까지 새로 정의하면 식(4)와 같습니다.
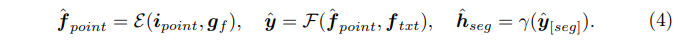
이제는 이진 마스크를 구하는 과정에서 수행하던 업샘플링이 노이즈를 유발하고 본래 feature의 정보를 손실한다는 한계를 해결하기 위한 Geomtric-guided Feature Propagation에 대해 살펴보도록 하겠습니다. GEM에서 나오는 g_f는 전체적인 장면 내 포인트의 정보를 가지고 있어서 업샘플링 과정을 향상 시킬 수 있는, 논문에서는 “gold message” 역할을 한다고 말하고 있습니다. 포인트 인코더 뿐만 아니라 업샘플링 과정에서도 역시 GEM에서 나오는 feature를 활용하여 dense한 포인트별 임베딩을 얻고자 하는 것이죠.
다시 Fig.3을 보면, 먼저 그냥 기존 PointNet++의 방식을 사용해서 N_1개의 포인트 집합에서 더 큰 범위의 집합 N3, N2로 상위 레이어 feature인 f_3, f_4를 업샘플링 해서 각각 f’_3 \in \mathbb{R}^{N_3 \times D}, f’_4 \in \mathbb{R}^{N_2 \times D}를 생성합니다. 그 다음에 GEM에서 나오는 g_f를 FPS를 사용해서 원래 포인트 개수 N개에서 N_2, N_3으로 다운 샘플링을 합니다. 다운 샘플링한 각각의 feautre들을 f_{g,1} \in \mathbb{R}^{N_3 \times D}와 f_{g,2} \in \mathbb{R}^{N_2 \times D}로 정의합니다.
여기까지 하고 나면 포인트 인코더에서는 업샘플링된 feature들을 만들게 되고, GEM에서는 다운 샘플링되어 결과적으로 같은 포인트 수를 가진 feature들이 생성됩니다. 그 다음에는 이렇게 업/다운 샘플링된 feature들을 concat하고 fc layer와 felu 함수를 타고 나와 각각 featuer 벡터인 \tilde{f}_3 \in \mathbb{R}^{N_3 \times D}와 \tilde{f}_4 \in \mathbb{R}^{N_2 \times D}로 업데이트 하게 됩니다. 그리고나서 LLM의 hidden embedding에서 나오는 \hat{h}_{point}를 f_5와 합쳐서 LLM과의 멀티 모달 정보를 인지할 수 있습니다. 마지막으로는 서로 다른 density를 가진 feature vector들 사이에 정보를 교환할 수 있도록 논문에서는 attentive propagation을 제안한다고 합니다. \tilde{f}_5와 \tilde{f}_4를 예시로 들어보면, \tilde{f}_4가 더 낮은 해상도를 가지고 있기 때문에 마치 로컬의 센터 포인트로 구성된 집합처럼 사용을 하는 것 입니다. 그래서 그 로컬 센터 점에 대해 KNN 알고리즘을 사용해서 \tilde{f}_5에서 인접한 포인트를 찾으면 f_{54} \in \mathbb{R}^{N_2 \times k \times D}가 됩니다. 그런 다음에 \tilde{f}_4를 query, f_{54}를 key, value로 사용하여 cross attention을 하게 되면 다양한 포인트 density를 가진 feature들 간에 정보를 효과적으로 교환할 수 있고 관련된 세부적인 정보를 쿼리 포인트로 추출할 수 있게 된다고 합니다. 이런 \tilde{f}_4와 \tilde{f}_5 사이의 attentive propagation을 통해 만들어지는 최종적인 feature는 식(5)와 같이 \hat{\tilde{f}}_4로 정의할 수 있습니다.
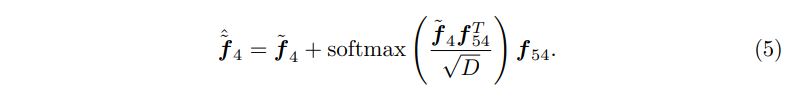
결국 Geometric-guided feature propagation을 통해 생성되는 높은 퀄리티의 포인트별 임베딩 f_{\mathcal{P}}는 식(6)과 같이 정의되며, vanilla baseline에서 직접적으로 업샘플링을 하는 것보다 정확하게 segmentation 마스크를 생성할 수 있도록 기반을 마련할 수 있다고 합니다.
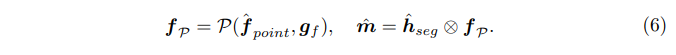
2.5. Training Objectives
SegPoint는 텍스트 classification loss와 segmentation mask loss를 활용해서 end-to-end 방식으로 학습합니다.
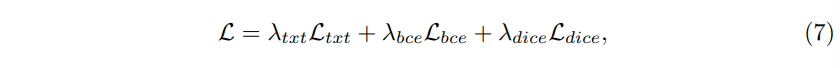
\mathcal{L}_{txt}는 텍스트 생성의 정확성을 목적으로 하는 auto regressive cross entropy loss를 의미하며 segmentation mask los에는 BCE loss인 \mathcal{L}_{bce}와 \mathcal{L}_{dice}가 포함됩니다.
2.6. Instruct3D Dataset Collection
3D instruction segmentation과 referring segemntation은 모두 언어 기반의 segmentation이지만, 그 중에 referring segemntation은 “의자”와 같이 명시적인 대상 객체의 클래스로 segmentation하지만, 그 이상으로 “방에서 어디에 앉을까요?”와 같이 더 복잡한 추론을 위한 명령어가 없다고 합니다. real world에서의 복잡한 상황을 반영하기 위해 단순한 객체 이름을 넘어서 더 복잡한 추론을 위한 segmentation 방식이 필요합니다. “방에서 어디에 앉을까요?”와 같은 질문은 단순히 “의자”라는 객체를 찾는 것 이상의 추론 능력을 필요로 하고, 또 “컴퓨터 게임을 하는 방법”과 같은 질문은 여러 개의 객체를 찾고 그 객체들 간의 상호 작용을 이해해야 하는 복잡한 지시어에 해당합니다.
이렇게 실 세계의 복잡한 사람의 지시어를 더 잘 반영할 수 있는 segmentation을 수행하기 위해 본 논문에서는 Instruct3D라는 벤치마크를 새로 제안합니다. 이 벤치마크는 ScanNet++에서 사용되는 280개의 scene을 합쳐서 만들었습니다. 각 scene에는 약 10개의 서로 다른 segmentation 지시어가 포함되어 있으며 약 2,565개의 지시어-포인트 클라우드 쌍으로 이루어져 있습니다. 또한 이 데이터셋은 multi target과 zero target 시나리오에 모두 활용할 수 있도록 구성되어 텍스트 쿼리에 대한 응답으로 여러 대상 객체를 식별하고 텍스트에 언급된 대상이 pair한 포인트에 존재하지 않을 수도 있는 상황까지 고려해야 하는 real world 시나리오까지 포함하고 있습니다.
3. Experiments
3.1. Datasets
학습 데이터는 semantic segmentation에는 ScanNet200, S3DIS를 사용하였으며 referring segmentation에는 ScanRefer, ReferIt3D, 그리고 Muti3DRefer라는 데이터셋들을 사용하였습니다. 또한 본 논문에서는 통합된 프레임워크 안에서 다양한 task의 joint training을 위해 task별 프롬프트를 설계하였다고 합니다.
Semantic Segmentation Dataset
템플릿을 생성하기 위해 먼저 특정 클래스를 세분화 합니다.
“USER: <POINT> Can you segment the {category} category in this point cloud? ASSISTANT: {category} <SEG>.”
→ 여기서 <POINT>는 포인트 클라우드 패치 토큰의 placeholder를 나타냅니다.
다음으로는 모든 카테고리를 세분화 합니다.
“USER: <POINT> Can you segment all the semantic masks in this point cloud and output separate masks for each category in the alphabetical order of the categories? ASSISTANT: {category}<SEG>, {category} <SEG>, …”
→ 출력을 단순화하고 딱 한 가지 가능한 답변만 나오도록 하기 위해서 “카테고리의 알파벳 순서대로”라는 제약 사항을 추가하였습니다.
Referring Segmentation Dataset
“USER: <POINT> Can you segment the object {description} in this point cloud? ASSISTANT: {category} <SEG>.”
→ {description}은 referring segmentation 데이터셋에서 주어진 명시적인 description을 의미합니다.
semantic 마스크를 출력할 때 출력 클래스 이름이 예측하는 라벨이 될 수 있도록 출력 형식을 통일하기 위해 <SEG> 앞에 {category}를 추가합니다.
3.2. Result on Instruct3D
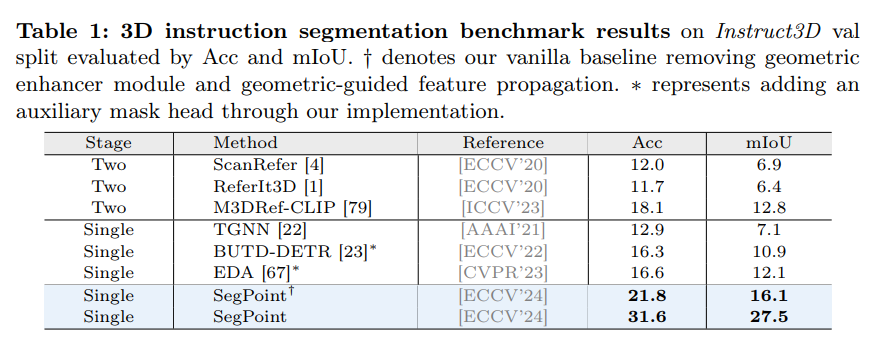
먼저 Tab.1에서 Instruction segmentation 결과를 보여주는데, 기존 방법론에서 복잡한 지시어가 들어왔을 때와 비교하면 본 논문의 방법론은 복잡한 추론이 필요한 상황에서도 mIoU가 15% 이상 개선된 것을 확인할 수 있습니다. Instruction Segmentation은 인지 뿐만 아니라 지시어에 대한 이해까지 요구하기 때문에 모델의 추론 능력과 넓은 범위의 지식을 필요로 합니다. 명시적인 reference에 국한된 기존 방법론들은 이러한 능력들의 부족으로 한계가 있지만 본 논문에서는 LLM을 활용해서 이를 해결하고자 했고 결과적으로 보다 높은 성능을 달성할 수 있었습니다.
또한 Vanilla baseline 대비 최종 SegPoint 역시도 많은 성능 향상을 이루었는데, 이는 GEM과 Geometric-guided Feature Propagation이 중요한 역할을 한다는 것을 보여주고 있습니다.
3.3. Results on Semantic Segmentation
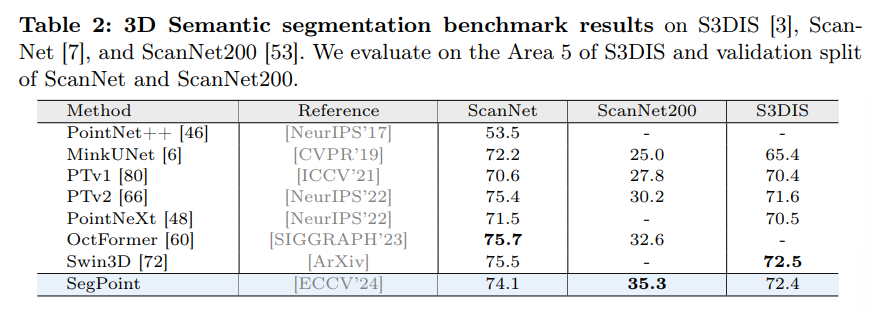
다음 Tab.2는 semantic segmentation 결과로, 간단하고 효과적인 답변 형식인 category <SEG>를 사용해서 카테고리 이름을 예측할 라벨로 사용합니다. ScanNet200과 같이 다양한 클래스를 가진 데이터셋에서 SegPoint는 기존 SOTA 방식을 2.1% mIoU를 넘는 성능을 보여주고 있습니다.
3.4. Results on Referring segmentation
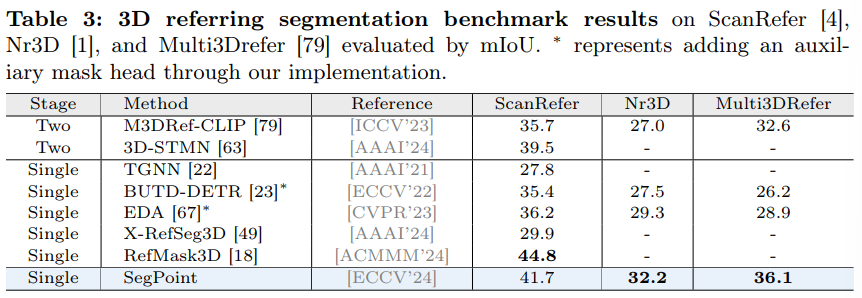
Tab.3은 referring segmentation 데이터셋에 대한 결과 입니다. SegPoint는 Multi3DRefer 데이터셋에서 단일 타겟(ScanRefer, Nr3D)과 멀티 및 zero 타겟 상황에서 모두 높은 성능을 보여주고 있습니다. zero 타겟의 경우에는 “ASSISTANT: There is no mask”으로 나타나는 빈 마스크를 사용한다고 합니다.
그런데 단일 타겟에 대한 성능은 기존 방법론보다 조금 낮은 성능을 보이는데, 이에 대한 분석 내용이 담겨있진 않네요.
3.5. Ablation Study
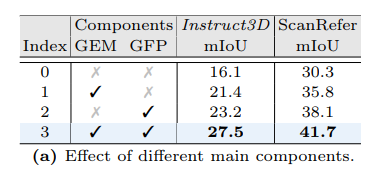
마지막은 ablation study로, 먼저 Tab.5(a)는 Vanilla Baseline과 각 GEM, GFP를 추가했을 때의 성능 변화를 보여주고 있습니다. 먼저 GEM은 각 데이터셋에서 5.3%, 5.5% mIoU가 향상되면서 dense prediction task를 위한 GEM의 효과를 확인할 수 있었습니다. GFP를 추가하면 GEM을 추가하면서 더 큰 폭의 성능 개선 효과를 이룰 수 있었는데, 이는 기존 업샘플링 단계에서 발생하는 정보 손실을 최소화하고 노이즈를 줄이면서 더 정확한 포인트별 임베딩을 구현할 수 있기 때문에 최종 segmentation 성능의 향상을 이루었다고 분석하고 있습니다.
건화님 좋은 리뷰 감사합니다.
다양한 segmentation에서 범용적으로 활용 가능한 모델을 제안하였으며, instruction에 대한 이해 능력을 고려하였다는 것이 해당 논문의 컨트리뷰션이라 이해하였습니다.
먼저 SEG 토큰을 통해 다양한 segemntation에 대한 적용이 가능하도록 한 것이라 이해하였는 데 맞나요? 해당 논문에서는 3가지로 segmentation을 구분한 것으로 이해하였는데, 3D segmentation 분야에서는 해당 논문에서 제안한 3가지 segmentation외의 다른 segmentation task는 없는 것인 지 궁금합니다.
해당 논문에서 instruction을 위한 네트워크 관점에서 텍스트 지시어 i_txt가 지시어이며 이를 토큰화했다는 것으로 이해하였습니다. 기존의 클래스 정보가 들어가는 방식과 다르게 네트워크 구조 측면에서는 복잡한(`의자`가 아니라 `쉴수있는 곳`과 같은) 지시어를 고려하기 위한 별도로 설계된 점이 없는 지 궁금합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
3D segmentation task에 논문에서 언급한 3개의 task만 존재하는 것은 아닙니다.
2D와 마찬가지로 instance, panoptic segmentation 등등의 다른 세부 분야도 존재합니다.
논문에서는 대표적인 semantic segmentation과 text 정보를 활용하는 segmentation task에 한정하여 얘기하고 있습니다.
복잡한 지시어에 대해 고려한 점이라고 하면, 기존에 방법론들은 이런 text 정보를 다루기 위해 CLIP과 같은 모델을 사용한 반면, 본 논문에서는 LLM을 활용한 것이라고 할 수 있을 것 같습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
GEM이 기존 포인트 클라우드의 기하학적 정보가 손실되는 것을 막기 위해 도입한 모듈이라고 이해했는데, 사실 트랜스포머인 인코더에서 KPConv라는걸 사용해서 기하학적 정보를 보완할 수 있다는게 잘 이해가 안 가는데, 조금만 더 설명해주실 수 있을까요 ?
그리고 referring segmentation task에 대해서는 제가 처음 들어봐서 그런데 referring segmentation은 정확히 어떤 정보를 받아서 task를 수행하는 것인지 굼궁합니다.
감사합니다.