제가 이번에 리뷰할 논문도 로봇의 파지를 위한 인식연구로, 해당 내용은 사람처럼 쥐는 방식으로 물체를 잡는 게 아닌, 흡입 방식으로 물체를 파지하는 경우를 위한 연구입니다. 각 point에 대한 불확실도를 모델링하는 방식이 어떻게 설계되었는 지 궁금하여 읽게 되었으며, 해당 논문은 suction 방식에 대한 uncertainty를 모델링하였으나, 다양한 grasping방식으로도 적용이 가능할 것이라 생각하여 리뷰하게 되었습니다. (또한 suction grasping을 예측하는 것이 결국 grasp pose [R|t]라는 점에서 6D와 상당히 유사하다고 판단하였습니다..ㅎㅎ)
Abstract
해당 논문은 흡입 방식으로 물체를 파지하기 위한 지점을 예측하는 것으로, 기존의 방식들이 unseen 객체에 대한 일반화가 어렵고, depth나 point cloud 데이터에 존재하는 노이즈에 의한 예측 어려움이 있다는 문제를 해결하기 위한 일련의 파이프라인을 제안하였습니다. 저자들은 Unseen Object Instance Segmentation(UOIS) 기술을 활용하고 point별로 suction에 대한 score를 생성하는 Uncertainty-aware Instance-level Scoring Netowrk(UISN)를 제안하여 이러한 문제에 대응하고자 하였습니다. uncertainty는 예측에 대한 조정에 사용되었으며, 이를 통해 unseen과 노이즈에도 신뢰도를 높일 수 있도록 하여 더 높은 확률로 파지에 성공할 수 있도록 하였으며, 저자들은 SubctionNet-1Billion이라는 밴치마크에서 SOTA를 달성하였으며, 실제 로봇 파지를 통해 해당 방법론의 정확도와 강인성을 입증하였다고 합니다.
Introduction
robotic grasping은 환경과의 상호작용과 작업을 수행하기 위해 필수적인 능력으로, 그중 suction 방식의 grasping은 표면이 매끈하거나 평평한 경우에도 잘 작동한다는 점에서 인기를 끌고있다고 합니다. 그러나, 이러한 방식의 grasping도 다른 grasping과 비슷하게 복잡하고 밀집된 scene에서 객체의 크기, 형태, 질감, 재질의 범위가 넓어 어려움이 존재합니다. 더 구체적으로는 (1)unseen 객체로의 일반화 어려움과 (2) depth나 point cloud 등의 데이터에 존재하는 노이즈로 정리할 수 있습니다. 먼저 unseen 객체로의 일반화 어려움은, 이 외의 다양한 분야에서도 중요한 논의거리입니다. 저자들은 기존의 방식들이 seen객체와 unseen 객체 사이의 분포가 다르다는 것을 고려하지 않고 one-shot 방식으로 접근하여 RGB-D scene으로부터 로봇 작업을 위한 heat map을 예측하는 방식으로 이루어졌다는 것을 지적하며, 이로 인해 정확도가 저하되었다고 이야기합니다. 또한, 두번째 문제점인 depth와 point cloud에 존재하는 noise에 대해, 기존 연구들은 heuristic한 방식으로 suction score를 모델링하였으나 이러한 방식은 노이즈에 취약하며, 일부의 네트워크 기반의 score를 예측하는 방식도 이러한 노이즈에 대응하기 위한 방식을 고려하지 않고 있다고 합니다.
이러한 문제를 해결하고자 저자들은 복잡한 환경에서도 suction grasping를 위해 multi-stage의 프레임워크를 제안하였으며, 해당 네트워크는 Unseen Object Instance Segmentation 네트워크(UOIS)와 Uncertainty-aware Instance-level Scoring 네트워크(UISN)로 이루어집니다. 먼저 unseen 객체 인식이 가능하며 객체 수준의 정보를 얻기 위해 UOIS를 통과한 뒤, 저자들이 제안한 UISN을 통해 포인트별로 suction score를 예측하게 됩니다. UISN은 데이터의 노이즈가 존재해도 scoring 정확도와 강인성을 높이기 위해 aleatoric uncertainty(데이터 자체의 불확실성)를 loss로 도입하였다고 합니다. 또한, epistemic uncertainty(모델의 지식의 한계로 인한 불확실성)를 활용하여 새로운 객체에 대한 모델의 불확실성을 명시적으로 측정하였다고 합니다. 이후 모델의 불확실성으로 조정된 score를 통해 grasping 지점 후보들에 순위를 매기고 선택을 한다고 합니다. 이러한 파이프라인을 통해 저자들은 SuctionNet-1Billion 벤치마크에서 SOTA를 달성하였으며 기존의 방식의 성능을 크게 능가하였다고 합니다. 또한, 실제 시나리오에서 저자들의 방법론의 효과를 입증하였다고 합니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- 복잡한 장면에서의 suction grasping을 위한 multi-stage의 framework 제안
- dense prediction 방식으로 각 point에 대한 suction score를 매기는 모듈을 모델링하고 새로운 UISN 모듈을 도입. UISN은 데이터 자체의 불확실성과 모델의 불확실성을 모두 고려함.
- 실험적으로 SuctionNet-1Billion benchmark와 실제 로봇 플랫폼에서의 실증을 통해 프레임워크의 효과를 입증
Related work
<Suction Grasps for Cluttered Scenes>
복잡한 장면의 suction grasping 문제의 접근 방식 중 하나는 객체의 6D pose를 추정하여 이를 기반으로 grasping을 수행하는 방식이 있으며, 이러한 방식은 CAD 모델로부터 사전에 정의된 grasping 위치를 파악하는 방식이며, 이러한 방식은 사전에 정의되지 않은 unseen 객체에는 일반화가 어렵다는 한계가 존재합니다. 또 다른 방식은 semantic segmentation을 통해 객체에 해당하는 영역의 point를 찾은 뒤 score를 할당하는 방식으로, 이러한 방식은 CAD모델에 대한 사전 정의 등의 작업이 필요하지 않다는 점에서 효과적이지만, 노이즈가 많은 point 데이터로 인해 예측에 어려움이 존재합니다.
최근 suction grasping을 위한 end-to-end 방식의 네트워크가 연구되며 복잡한 RGB-D 이미지로부터 2D suctionable region을 예측하는 방식이 제안되었으며, heuristic하게 suction영역을 파악하는 방식보다 개선된 성능을 보였으나, 객체 수준의 특징을 모델링하지 않아 복잡한 형상과 객체의 특성을 파악하는 데 여전히 어려움을 겪고 있다고 합니다.
Method
Problem formulation and Pipeline overview
suction grasping을 위한 gasp pose는 g=[R|t] \in SE(3)로, 해당 suction grasping synthesis는 복잡한 장면에서 다양한 물체에 대한 정확한 n개의 6-DoF suction grasps G= \{g_1, g_2, ..., g_n \}를 예측하여 성공적으로 파지하는 것을 목표로 합니다.
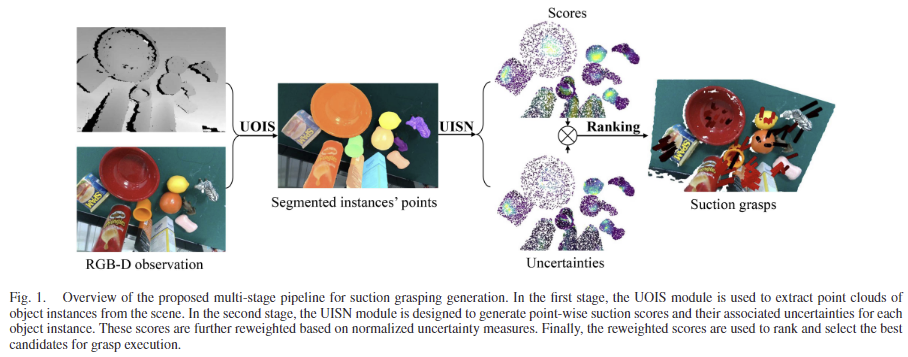
저자들이 제안하는 파이프라인은 [Fig. 1]에서 확인할 수 있듯이 크게 3 stage로 구성됩니다.
Stage 1) Unseen Object Instance Segmentation(UOIS)
UOIS는 가장 먼저 unseen 객체에 대한 segmentation을 수행하는 것으로 저자들은 이 부분에 다양한 방식을 적용할 수 있다는 점을 이야기하며, UOIS-Net[1]과 UOAIS-Net[2] 두 방식을 적용하였다고 합니다. UOIS-Net은 먼저 voting 방식을 통해 객체의 중심을 생성한 뒤, 각 instance에 대한 초기 마스크를 생성합니다. 이후 Region Refinement Net(RRN)을 통해 초기 마스크의 가장자리를 RGB 이미지의 객체의 가장자리와 일치하도록 조정하여 최종 mask를 구하게 되며, 영상 내 파악된 객체 수 만큼의 최종 마스크 M = \{ m_1, m_2, ... m_n\}를 구하게 됩니다. UOAIS-Net은 비슷한 방식으로 이루어지며, 추가적으로 가려진 영역도 포함하는 amodal mask A와 가려진 영역에 대한 마스크 O까지 예측하여 객체들 사이의 공간적 관계를 더 잘 이해하고자 제안된 방식입니다.
[1]C. Xie, Y. Xiang, A. Mousavian, and D. Fox, “Unseen object instance segmentation for robotic environments,” IEEE Trans. Robot., vol. 37, no. 5, pp. 1343–1359, Oct. 2021.
[2]S. Back et al., “Unseen object amodal instance segmentation via hierar- chical occlusion modeling,” in Proc. Int. Conf. Robot. Automat., 2022, pp. 5085–5092
Stage 2) Point cloud Based Instance Scoring
그 다음 point별로 suction score를 예측하는 단계로, 저자들은 UISN을 설계하였고, 이 네트워크에 대한 자세한 설명은 UISN 섹션에서 설명합니다. 우선 RGB-D scene S와 카메라 intrinsic 파라미터가 주어지면, 역투영을 통해 3D Point cloud P_s \in \mathbb{R}^{H⨉W⨉ 6}를 생성합니다. 이후 앞서 구한 mask를 적용하여 해당 장면에서 o번째 instance에 대한 point cloud P_o \in \mathbb{R}^{N_o ⨉ 6}를 구합니다. (N_o는 o번째 instance의 point cloud 개수) 그 다음 UISN을 활용하여 불확실도로 사용되는 평균 점수 S \in \mathbb{R}^{N⨉1}와 이에 해당하는 분산 \sigma^2 \in \mathbb{R}^{N⨉1}을 예측합니다.
Stage 3) Suction Ranking and Direction Estimation
각 객체에 대한 top-k개의 grasp를 선택하는 과정으로, 해당 논문에서는 불확실성을 고려한 score를 기반으로 k개의 grasp(Rotation & Translation)를 선정하게 됩니다. 이를 위해 앞서 예측한 suction score에 불확실도 u ∈ [0,1]를 가중치로 활용하여 업데이트 된 suction score S'를 아래의 식을 통해 구하여 상위 k개의 grasp를 선정하게 됩니다.
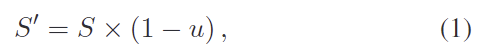
Uncertainty-aware Instance-level Scoring Netwhork(UISN)
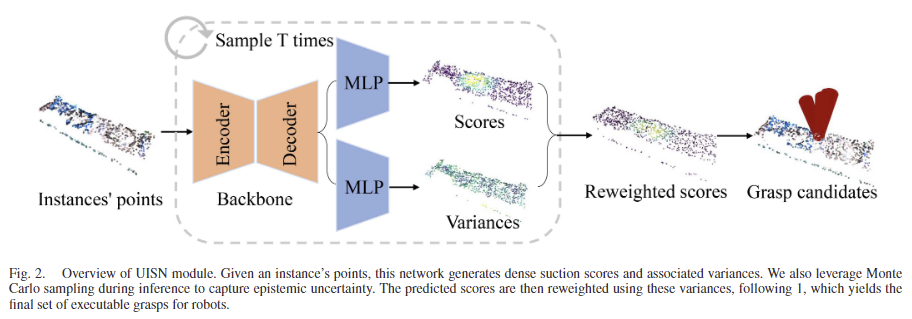
UISN, \Phi의 구조는 [Fig. 2]에서 확인할 수 있으며, backbone과 2개의 MLP로 구성됩니다. 먼저 Backbone은 3D 분야에서 다양하게 사용되는 MinkowskiEngine을 활용하였으며, sparse convolution backbone을 활용하였다고 합니다. 색상이 포함된 point cloud P \in \mathbb{R}^{N⨉6}이 주어지면 이를 M개의 voxel V \in \mathbb{R}^{M⨉3}로 quantize한 뒤, backbone을 통해 C-채널의 feature \mathbf{F} \in \mathbb{R}^{N⨉C}를 추출합니다. 이후 \mathbf{F}를 활용하여 suction에 대한 score와 uncertainty를 예측하게 됩니다.
Uncertainty Estimation
저자들은 aleatoric uncertainty과 모델의 epistemic uncertainty을 함께 고려하여 예측값에 대한 강인성과 정확도를 강화하는 것을 목표로 합니다. aleatoric uncertainty는 센서의 노이즈나 데이터 자체의 노이즈를 다루고 epistemic uncertainty는 새로운 객체나 unseen object에 대해 모델이 예측에 대해 가지는 신뢰도를 측정합니다. 이러한 두가지 불확실성을 하나의 모델에 활용하기 위해 모델은 몬테카를로 드롭아웃(Monte Carlo Dropout, MCD)을 이용한 베이지안 nueral Network(BNN) 근사를 사용하였다고 합니다.(MCD는 드롭아웃을 활용하여 BNN을 근사하는 기법으로, test과정에도 dropout을 활성화하여 여러 버전의 신경망을 샘플링하므로써 같은 입력으로부터 조금씩 다른 예측 결과를 얻고, 이로부터 불확실성을 추정할 수 있도록 하는 것이라 합니다.) Dropout기반의 네트워크를 T번 샘플링하여 구한 네트워크의 가중치 \widehat{\mathbf{W}} 분포를 Monte Carlo(MC) 샘플로 해석하여 scoring network를 아래의 식으로 정의합니다.
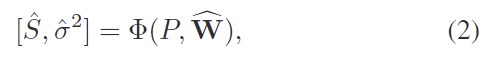
- \hat{S}: predicted score
- \hat{\sigma}^2: predicted variances (epistemic uncertainty)
여기에 aleatoric uncertainty를 모델링하기 위해 L1 distance를 이용하는 loss를 도입합니다. loss fuction은 아래의 식으로 정의되며, N은 i번째 instance의 point 개수를 나타냅니다.
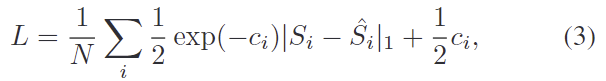
- c_i = \log_{} {\hat{\sigma_i}^2}로, 안정적으로 학습하기 위해 분산에 log를 취한 것
loss의 첫번째 항은 L1 distance를 통해 score 사이의 오차를 최소화하도록 하는 것이며, 두번째 항은 각 점에 대한 uncertainty 예측값이 무한대의 값이 되는 것을 막아주는 규제를 위한 항이라고 합니다. (첫번째 항만 존재할 경우, \hat{\sigma}^2이 무한대로 커지면 loss가 0에 수렴하게 되므로 모델이 uncertainty에 대해 항상 큰 값만 예측하게 됨)
test시에는 uncertainty u를 예측하기 위해 T번 output을 샘플링한 \{\hat{S}_t, \hat{\sigma}^2_t \}^T_{t=1}를 사용하여 아래의 식을 활용하여 uncertainty를 근사시켜 구하게 됩니다.
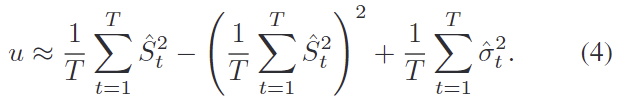
위의 식(4)에서 앞의 두 항은 샘플링된 score의 variance를 나타내며, 마지막 항은 샘플링된 분산의 평균을 의미합니다.
Prediction Heads
최종적으로 uncertainty를 고려한 point 별 suction score를 구하기 위해 score를 dense regression문제로 공식화합니다. 이를 위해 score 예측과 variance 예측을 위한 2개의 MLP head를 이용하며, 두 MLP는 backbone으로 추출한 global feature \mathbf{F}를 입력으로 받아 각각의 dense한 score \hat{S}와 variances \hat{\sigma}^2를 예측합니다.
Experiments
<Benchmark>
해당 논문은 suction grasping synthesis 태스크를 평가하기 위해 SuctionNet-1Billion 데이터 셋을 활용합니다. 해당 데이터 셋은 190개의 scene이 포함되어있으며, 각 장면에 대해 realsense와 Kinect 센서를 활용하여 촬영한 256개의 view로 구성됩니다. 일반화 성능 평가를 위해 test 장면은 객체의 카테고리에 따라 seen, similar, novel 3가지 subset으로 구성된다고 합니다. 평가지표는 AP를 이용하며, 이는 score가 특정 임계치 이상일 경우, {성공횟수}/{시도횟수}를 의미하는 것으로 보입니다.
<Comparison to Several Representative Methods>
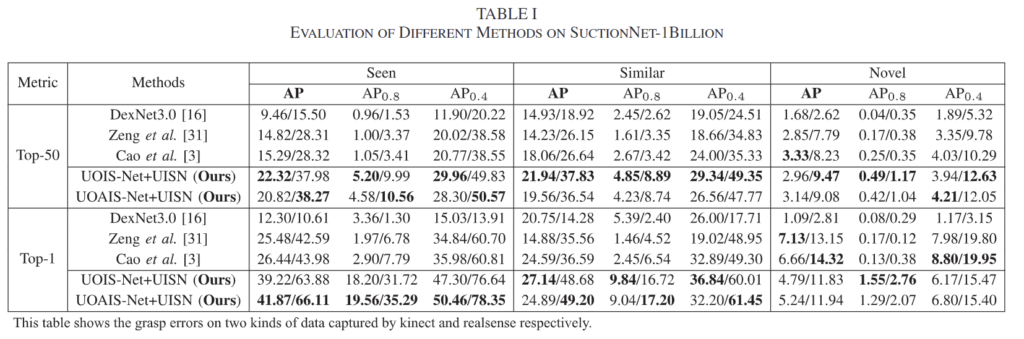
먼저 suction grasping에서 SOTA인 방법론들과 성능을 비교한 것 입니다. 예측된 suction grasp pose 중 상위 50개와 1개에 대한 AP를 구한 것으로, DexNet3.0은 depth 이미지로부터 grasp score를 예측한 것이며, Zeng et al.은 fully convolutional network를 활용하여 RGBD로부터 scene-level의 suction heatmap을 예측하는 방식, Cao et al.은 앞의 방식의 유사하지만 흡착이 잘 되는지를 나타내는 seal score heatmap과 center score heatmap을 예측한 뒤 이를 곱해 secne-level의 score를 구하는 방식이라합니다.
Table 1을 통해 SuctionNet-1Billion 밴치마크에서 저자들이 제안한 방식이 대체로 좋은 성능을 보이는 것을 확인할 수 있습니다. 특히 Top-1에서 상당한 개선을 보였으며, 이를 통해 복잡한 장면에서 적절한 후보를 찾을 수 있다는 것을 정량적으로 보였습니다. 아래의 [Fig. 3]은 정성적 결과로, top-50에 대한 grasp pose를 보여주며, 빨간색은 잘 작동하는 경우, 검정색은 잘 작동하지 않는 경우를 나타낸다고 합니다.

<Ablation Analysis>
Geometry-based Scoring vs. Network-based Scoring
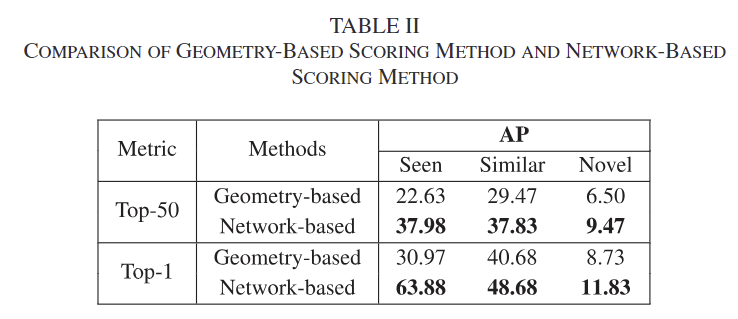
제안된 네트워크 기반의 scoring 방식과 기하학적 정보를 기반으로 heuristic하게 score를 구하는 방식을 비교한 것으로, Table 2를 통해 네트워크 기반의 방식이 더 좋은 성능을 보이는 것을 확인할 수 있습니다. 저자들은 이에 대해 기하학적 방식의 경우 노이즈가 많거나 point cloud가 많이 가려질 경우 성능이 크게 저하된 것이라 분석하였습니다.
Uncertainty Modeling Approaches
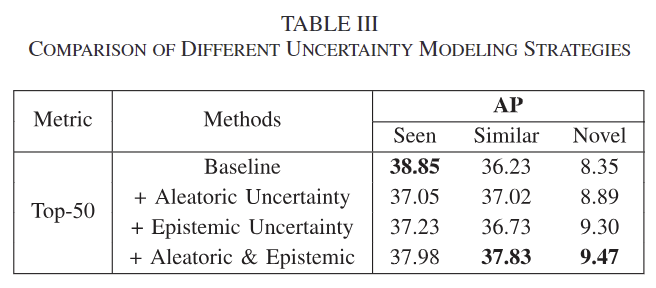
불확실성을 모델링하는 방식에 대한 평가를 수행합니다. 단일 MLP를 이용하여 suction score를 구하는 것을 베이스라인으로 설정하였을 때, Aleatoric Uncertainty와 Epistemic Uncertainty를 고려하는 시나리오로 평가를 수행하였습니다. Aleatoric Uncertainty는 MLP를 하나 더 추가하여 variance 예측을 수행한 것으로 예측 score에 대한 불확실성을 고려할 수 있도록 하였으며, Epistemic Uncertainty는 teset 과정에 dropout을 사용하여 예측 점수에 대한 가중치를 수정하는 방식을 통해 모델과 데이터분포로 인해 발생하는 불확실성을 고려할 수 있도록 하였다고 합니다. 또한 두가지를 모두 고려하는 방식에 대한 평가도 함께 수행하였습니다. 이에 대한 결과는 Table 3에서 확인할 수 있으며, Seen에서는 성능이 감소하는 것을 통해 모델의 성능에 영향을 미칠 수 있으나 similar와 novel에서 모두 성능이 개선되는 것을 통해 불확실성을 제대로 모델링할 수 있다는 것을 어필합니다.
Effect of Different Sample Numbers
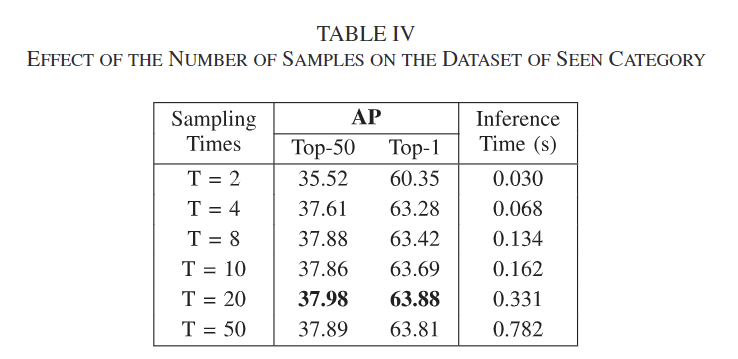
drop out을 T번 반복하여 샘플링을 수행할 때, 반복 횟수에 대한 ablation 실험 결과로, T가 20일 때 가장 좋은 성능을 보이는 것을 확인할 수 있습니다. 대체로 T 횟수가 늘어날수록 성능이 개선되는 경향을 보이지만, 추론 시간도 늘어나며 성능이 일정하게 증가하는 것이 아니므로, 트레이드오프 관계를 고려했을 때 적절한 횟수를 선택하는 것이 필요하며, 저자들은 20을 기본 횟수로 선정하였습니다.
Effect of Different Inputs
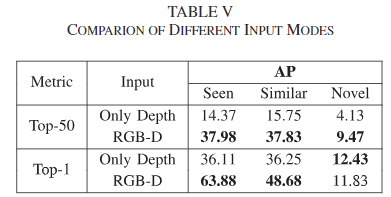
입력 데이터 타입에 대한 실험 결과로, depth 만 이용할 경우와 RGBD를 이용할 경우에 대한 실험 결과를 통해 RGBD를 사용하는 것이 대체로 좋은 성능을 나타냄을 보였습니다. 이를 통해 RGB를 고려하는 것의 중요성을 강조하였는데, Top-1의 경우 novel에서는 depth만을 사용하는 게 좋은 점에 대한 별도의 분석은 없었습니다. RGB 데이터가 완전 다른 경우 모델에 노이즈로 작동하였을 수 있을 것이라는 생각이 들며, 이에 대해 uncertainty를 분석한 것 처럼 분석을 해보았다면 좋았을 것 같다는 아쉬움이 있습니다.
Real Robot Evaluation

다음은 실제로 로봇에서 실증을 수행한 것으로, [Fig. 4]에서 세팅을 확인하실 수 있습니다. Franka Panda 매니퓰레이터와 Intel RealSense D415로 구성되며, SuctionNet-1Billion 데이터에 존재하는 객체 중 16개의 객체를 무작위로 선정하였다고 합니다. Easy scenes은 8개의 seen 객체로 이루어지며, Hard scenes은 8개의 similary와 novel 카테고리의 객체들로 구성되며, 각 scene은 그 중 5~6개의 객체들로 이루어집니다.
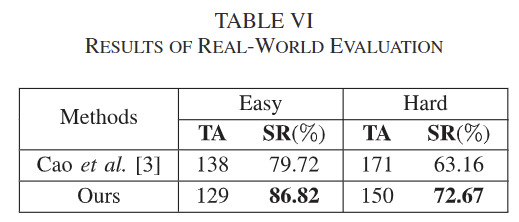
20개의 clutter한 scenes에 대해 총 시도 횟수(TA)와 파지 성공률(SR %)을 리포팅하였으며, SR은 총 시도 횟수 중 성공 횟수를 의미합니다. 또한, 같은 물체에 대해 3번 연속으로 파지를 실패할 경우는 해당 장면에서 제거하고 파지를 다시 수행하였다고 합니다. 실험 결과 기존 방식에 비해 두 경우 모두 더 좋은 성공률을 보였으며, 이를 통해 실제 활용에서 저자들이 제안한 네트워크가 활용 가능하다는 점을 시사하였습니다.
안녕하세요. 리뷰 잘 읽었습니다.
저자의 핵심은 불확실성을 모델링 하는 것으로 이해하였습니다.
이 지점에서 불확실성에 대해 두 지점, 데이터 자체의 불확실성과 모델의 불확실성을 설명해주셨는데요,
정확히 데이터 자체의 불확실성이란 센서의 노이즈 등에 국한되는지, 또는 다른 측면도 존재하는지 궁금합니다.
두 번째로 모델의 불확실성이 어떤 측면에서 모델링 하였는지에 대해 궁금합니다.
AL에서의 uncertainty의 측면인지, 또는 초반 부에서 설명하신 Unseen으로 인해 발생하는 불확실성인지에 대해 잘 이해하지 못하였습니다
질문 감사합니다.
우선 해당 논문에서는 aleatoric uncertainty에 대해 센서의 노이즈를 언급하며, 다양한 원인이 있을 수 있으나, 데이터 자체에 존재하는 노이즈를 의미합니다. 다른 측면을 고려한 것이 Epistemic uncertainty라고 이해해주시면 좋을 것 같습니다.
해당 논문에서는 모델의 불확실 성에 대하여 상인님이 언급하신 두가지를 모두 의미하는 것으로 이해하였습니다. 우선 Epistemic uncertainty자체가 모델의 구조나 학습 과정에 발생할 수 있는 불확실성을 의미한다고 합니다. 데이터의 전체 분포를 다 고려하지 못한 모델일 경우 AL 측면에서의 uncertainty를 고려한 것으로 볼 수 있고, 이를 미학습 객체라 확장해 보았을 때도, 이 미학습 객체에 대한 분포를 고려하지 못한 모델이라는 점에서 Epistemic uncertainty를 고려해야 한다고 이해하였습니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
상인님의 말씀처럼 uncertainty estimation이 핵심인 방법론 같습니다.
열심히 uncertainty에 대해 정의하는 부분을 이해해보려 했지만, 이해가 쉽지 않았는데요..
특히 “이러한 두가지 불확실성을 하나의 모델에 활용하기 위해 모델은 몬테카를로 드롭아웃(Monte Carlo Dropout, MCD)을 이용한 베이지안 nueral Network(BNN) 근사를 사용하였다고 했다”고 하셨는데, 왜 두 가지 불확실성을 하나의 모델에 활용해야 하는 것인가요?
질문 감사합니다.
하나의 모델로 두개의 불확실성을 처리한다는 것이 아니라, grasp pose를 예측 하는 과정에 발생할 수 있는 2가지 불학실성을 모두 고려하여 하나의 예측을 수행한다는 의미였습니다. 핵심은 두 uncertainty를 활용하기 위해 베이지안 근사를 이용한다는 것이며, 이를 통합적으로 고려하여 uncertainty를 고려한 socre를 예측할 수 있도록 한 것 입니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Uncertainty 부분을 방법론에서 봤을 때도 센서나 데이터의 노이즈를 모델 안에서 과연 uncertainty로 지정하고 학습을 한다해도 효과적일까라는 의문이 계속 들었습니다. 실제로 실험을 보니까 Simiar와 Novel 물체에 대해서는 어느 정도 향상이 되지만 Seen에서는 하락하는 경향을 보이고 있는데, 사실 센서나 데이터의 노이즈라는 요소를 uncertainty로 지정한 이상 카테고리에 상관없이 동일한 성능 경향성을 보여야 한다고 생각하는데, 이런 관점에서 불확실성을 제대로 모델링하였다고 할 수 있을지 .. 승현님의 의견이 궁금합니다.
또한 로봇 파지에 대해서 성능 평가를 성공 횟수 / 시도 횟수로 하는 것은 알고 있었는데 실제 표로 리포팅한 걸 보니 단순히 동일한 시도 횟수를 기준으로 하는게 아니었네요 ?!?!그럼 표기는 횟수로 하지만 결국에 SOTA라는 기준을 세울 수 있는건 아무래도 비율로 정하는 것이겠죠 .. ? 그런데 시도 횟수를 많이 하는 것도 어떤 메리트가 있는 것인지는 여전히 의아한데 .. 시도 횟수가 가장 많은 방법론을 별도로 강조하는 이유가 있을까요 ?
질문 감사합니다.
건화님이 이야기하신 것처럼 Seen에서의 성능 경향성이 Similar와 Novel와는 다르게 작동하고 있으며, 이에 대해 저도 마찬가지로 의문이 들기는 하였습니다. 그러나 저자들이 이야기하는 uncertainty가 미학습 객체에 적용한다는 과점에서는 실험적으로 개선이 이뤄어지고 있는 것을 보고 어느정도 저자들이 모델링한 방식에 효과를 보였다고 생각합니다. (하지만 Seen 객체에서의 성능 경향에 대한 유의미한 분석이 없는 것은 굉장히 아쉽다고 생각합니다)
또한, 이야기하신대로 로봇 파지에서 시도 횟수를 설정하는 것은 방법론마다 조금씩 차이가 있는 것으로 보입니다. (과제 관련 킥오프에서도 성공여부 판단을 위한 기준이 필요하다는 이야기가 나온적이 있어 확고한 기준이 있는 것은 아닌 것 같습니다…물론 비교를 위해서는 동일 횟수로 진행을 하는 것으로 보입니다.) 또한 시도횟수가 많은 방법론을 별도로 강조하는 결과는 없는것으로 알고있습니다.. SR은 성공률이고 Table 6의 경우는 SR을 강조하고있으며, 기존 방법론보다 더 적은 횟수로 파지에 성공하였다는 것은 장점인 것으로 알고있습니다.