안녕하세요, 마흔여섯 번째 X-Review입니다. 이번 논문은 2023년도 CVPR에 게재된 Towards Unified Scene Text Spotting based on Sequence Generation 논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
Text Spotting은 Text 존재하는 영상 내에서 text의 위치를 검출하고 그 검출된 영역 내의 text가 무엇인지 인식하는 task입니다. 본 논문은 이 scene text spotting을 sequence generation task로 풀고한 논문인데요, image와 text prompt를 사용하여 vision task를 language modeling task로 풀고자 했다고 보면 되겠습니다. Object detection을 sequence generation task로 푼 대표적인 방법론인 pix2seq를 생각해보면 될 것 같은데요,

이 모델은 바운딩 박스와 클래스 라벨을 시퀀스로 바꿔서 이 시퀀스를 예측하도록 하였는데, 그림에서 보이는 것과 같이pixel data인 이미지를 입력으로 넣어서 마치 언어 모델이 텍스트를 생성하듯 prediction 결과라 나오는 것을 확인할 수 있습니다. 이와 같이 모델이 discrete token으로 구성된 sequence를 output으로 뱉도록 함으로써 transformer decoder를 사용해 vision task를 수행하는 것입니다.
오늘 리뷰하는 논문이 text spotting을 sequence generation으로 푼 가장 첫 논문은 아니고, 이전 SPTS라고 하는 논문이 있는데요, 이 SPTS를 base로 삼고 있기 때문에 간략하게만 살펴보도록 하겠습니다.

위 그림이 SPTS의 전반적인 아키텍처 그림입니다. 보통 일반적인 text spotting 모델같은 경우사각형의 box 혹은 polygon 형식의 annotation을 사용하는데 이 SPTS는 text instance의 center point 즉 단 하나의 좌표만을 사용하기에 엄청 단순하다는 이점을 갖고 있는 모델입니다.
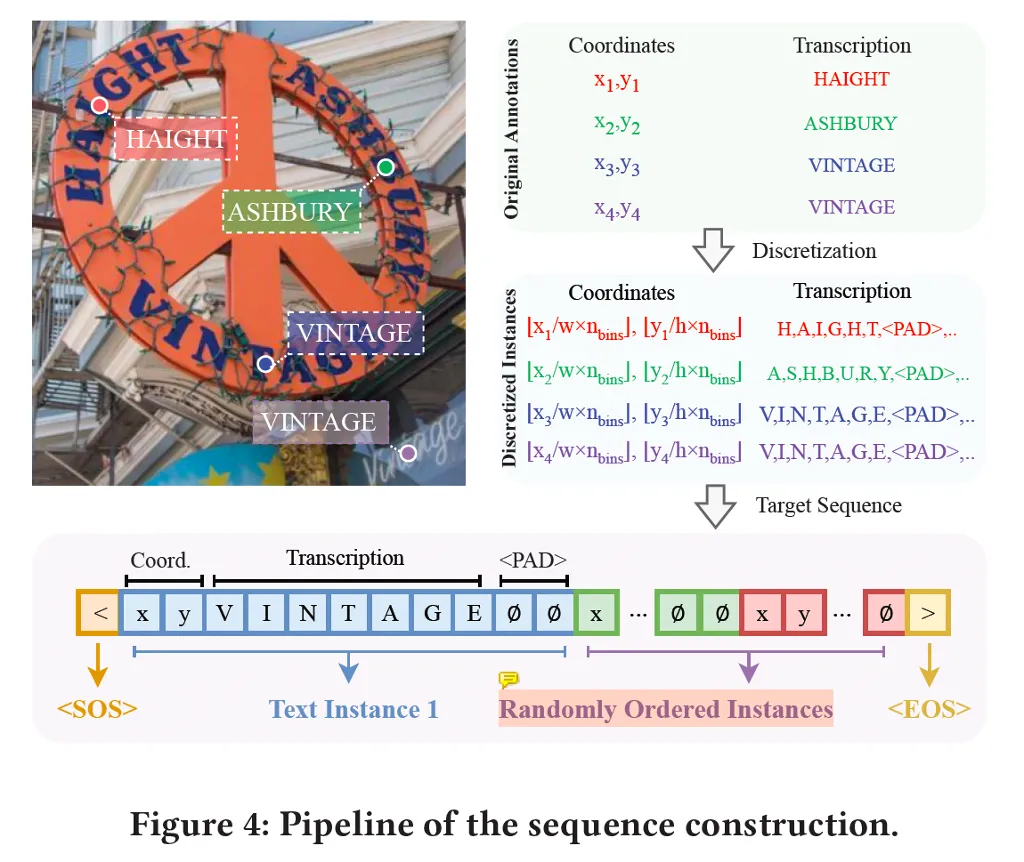
이 SPTS가 sequence를 어떻게 구성했는지 위 그림 4에서 살펴볼 수 있습니다. 먼저 한 영상에 vintage, ashbury 등등의 text instance가 존재할 때 각각의 text instance들의 좌표는 하나의 single point 좌표로 나타내져 있겠구요, 그에 대한 transcription이 있습니다. 이때 sequence generation task로 풀기 위해서는 모든 data가 discrete token으로 표현할 수 있어야 하겠지만 실제로 영상 좌표 같은 경우는 continuous하기 때문에 이를 discrete하게 바꿔주어야 하며, 동시에 각각의 text instance 마다의 길이도 다 다르기 때문에 padding token으로 길이를 맞춰주는 전처리를 수행하게 됩니다.
최종적으로 그림의 맨 아래 부분을 보시면 한 영상에 대한 sequence 예시를 볼 수 있는데요, 맨 처음과 마지막에 start, end token을 넣어구고 하나의 좌표 x, y 토큰 이후 그에 대한 transcription, padding token으로 구성된 것을 볼 수 있습니다. 한 text instance token 이후 바로 다음 text instance sequence가 붙게 되구요. 한 영상 마다 하나의 gt sequence를 구성할 수 있겠고 모델이 이런 형식의 target sequence를 예측해야 하는 것입니다. 즉 보통 spotting 모델이 detection을 수행하고 detect되어 나온 결과를 가지고 그에 대한 feature나 input image를 가지고 recognition을 하던 2-step 방식과 다르게 이를 한번에 처리하는 것이죠.
근데 오늘 리뷰하는 논문의 저자는 이런 sequence generation을 곧바로 text spotting에 적용하기에는 몇 challenge한 점이 존재한다고 합니다.

먼저, 그림 1을 보시면 text detection할 때 사용되는 여러 format들을 볼 수 있는데요, text instance의 center 점을 가지고 하나의 좌표로 표현하는 single centeral point format, 일반적인 object detection에서 자주 사용되는 bounding box, 네 꼭짓점 좌표 정보를 담고 있는 quadrilateral 그리고 여러 꼭짓점 좌표 (16개)를 갖는 polygon으로 나뉩니다. 이때 각각의 annotation format들은 cost와 applicability 측면에서 trade off를 갖겠죠. 예를 들어 point 방식은 간단하고 cost가 적게 들겠지만 text의 구체적인 boundary가 필요하거나 위치를 정확하게 파악해야 하는 task에는 적합하지 않겠습니다.

Fig2에서 보이는 것과 같이 text의 style을 그대로 유지하면서 text의 내용을 원하는 text로 바꾸는 scene text editing task나 visual document understanding과 같이 fine한 정보가 중요한 곳에서는 마찬가지로 poitn나 bbox가 아니라 사각형 내지 polygon 형태의 정보가 필요합니다.
근데, 앞서 소개드린 spotting task에 sequence generation을 처음 접목한 논문인 SPTS 방법론은 single point format에만 의존하고 있기 때문에 다양한 task와 상황에 맞춰 적합하게 detection해내지 못한다는 단점이 존재합니다. 결국 하고자 한 말은 각각의 detection format마다 장단점이 있기 떄문에 상황에 맞는 format을 선택해서 사용할 수 있도록 모든 format을 커버할 수 있는 것이 하나의 format에만 의존하는 것보다 낫다는 것입니다.
또, sequence generation model의 기존 한계점으로 모델을 학습할 때 maximum sequence 길이를 정해놓고 이보다 더 긴 sequence는 생성하지 못하는 문제가 있었습니다. 즉 모델이 학습한 최대 길이를 초과하는 sequence는 생성할 수가 없다는 것이죠. 이런 limitation은 특히 scene text spotting에서 더 문제가 되는데 object detection에서의 경우를 생각해보면 cat, dog 등의 class가 있다고 할 때 이 각각을 하나의 token으로 삼을 수 있다면 spotting에서는 cat이라는 transcription이 있으면 ‘c’, ‘a’, ‘t’를 하나 하나의 token으로 삼아야 하기 때문에 보다 sequence가 길어질 수밖에 없습니다. 그렇게 되면 document와 같이 한 영상에 text가 엄청 많은 경우에는 모든 text를 읽지 못하게 되겠죠.
본 논문은 이런 문제를 해결하는 UNIfied scene Text Spotter(이하 UNITS)를 제안하고 있습니다. 이 UNITS는 우선 첫번째 limitation을 해결하고자 다양한 format(point, bbox, quadrilateral, polygon)의 annotation을 통합하여 단일 모델에서 학습할 수 있도록 하였습니다. 또 starting-point prompting 방식을 제안함으로써 기존 maximum decoding 길이를 초과하는 긴 sequence를 생성할 수 있도록 하였습니다. 보다 구체적인 방식은 아래 method 단에서 다루도록 하겠습니다.
본 논문의 contribution은 아래와 같습니다.
- 다양한 detection format을 통합하여 임의의 shape을 갖는 text 영역을 추출할 수 있는 새로운 sequence generation 기반의 spotting 방식 제안
- Starting-point prompt를 제안함으로써 정해진 maximum decoder 길이보다 더 많은 text를 추출할 수 있도록 함
- 경쟁력 있는 성능
2. Method
2.1. Unified Interface for Text Spotting
우선 spotting을 sequence generation으로 풀기 위해 sequence를 구성해야 합니다. 먼저 각 text instance에 대한 location과 tarnscription 정보가 있을 때 이들을 discrete token으로 바꿔야 하고, 각각을 이어붙여서 하나의 sequence로 만들어야 합니다. 좌표 정보를 담고 있는 location token같은 경우 x, y 좌표들은 우선 영상의 width, height로 정규화가 되구요 그 다음 [0, n_{bins}] 범위 내로 변환합니다. n_{bins}는 1000으로 설정하였습니다.
서로 다른 detection format을 다루는 기존 방법론들은 각각의 task-specific한 head를 사용했었는데요, 본 논문에서는 이들을 오직 하나의 단일 모델로 다루기 위해서 각 text instance마다의 prompt를 더하는 새로운 sequence를 제안하였습니다. 모델이 어떤 format을 사용해야 하는지 알려주는 prompt를 입력으로 받은 다음, 이를 통해 text 영역의 shape을 결정하게 되고 각각의 output을 뱉게 되는 것입니다.
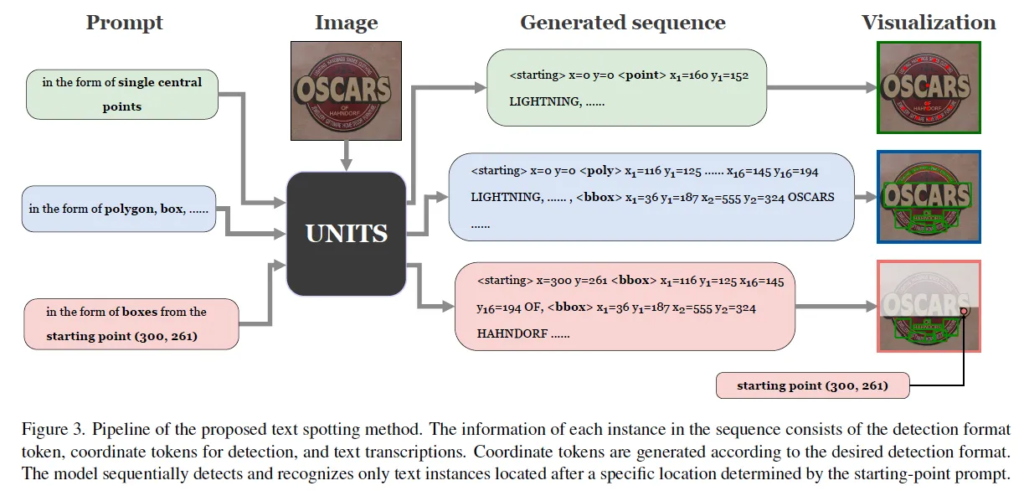
이 그림이 제안된 파이프라인인데요, 보시면 한 모델에서 다양한 annotation format을 다룰 수있도록 하기 위해 모델의 입력으로 image와 함께 prompt를 함께 넣어주도록 하였습니다. prompt는 in the form of single central point 혹은 in the form of polygon, box 이런 식으로 되어 있는데 이렇게 함으로써 모델이 각각의 text instance에 대해 output format을 어떻게 뱉어야할지 지정해주는 것이라고 보면 됩니다. 생성된 sequence를 보아도 <point>, <bbox>, <poly>와 같이 shape에 대한 token이 location token 전에 들어가 있는 것을 볼 수 있습니다. 이렇게 detection format token이 들어가게 되면 location 정보가 이 format에 맞춰서 추출되고 그 다음 text transcription token이 생성됩니다.
또, 앞서 starting point prompting 방식을 제안함으로써 이미지 내의 text instance 수가 많을 때 제한된 decoder 길이로 인해 모든 text를 spotting하지 못하는 해결하고자 했다고 했는데요. 그림 핑크색 prompt의 from the starting point (300, 261)이 그에 해당하는 prompt인데 이렇게 넣어줄 경우 모델이 이 좌표부터 시작해서 그 아래부분을 검출하도록 가이드하는 방식이라 생각하면 됩니다. Detection format token과 Starting-point prompting에 대해 좀 더 자세히 살펴보도록 하겠습니다.
Detection format token
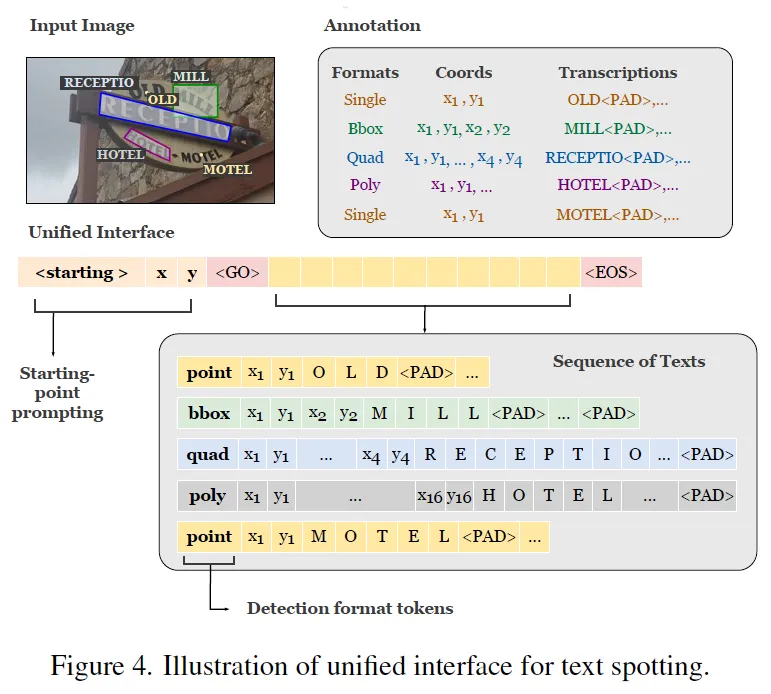
먼저 detection format token인데, 이 token는 하의 모델이 여러 detection format을 사용할 수 있는 용도로 사용이 됩니다. 위 그림 4를 보면 영상에 ‘OLD’, ‘MILL’, ‘HOTEL’ 등 5개의 text가 있을 때 영상 내에서 좌상단 부터 우하단 순으로(보통 사람이 책을 읽는 순) 나열되어 1차원 sequence가 나오게 됩니다. 각 text instance에 대해서 start token이후 맨 앞에 들어가게 되는 <point> <bbox>와 같은 detection format token이 bbox로 표현해야 할지 혹은 그 외의 형식으로 표현해야 할지를 결정하게 되구요 이 detection format token에 해당하는 box annotation이 나오게 됐다면 그 옆에 이어 바로 transcription이 붙게 됩니다. 이런 식으로 sequence를 구성하도록 해서 여러 detection format을 동시에 통합하여 다룰 수 있게 되는 것입니다.
Starting-Point Prompting
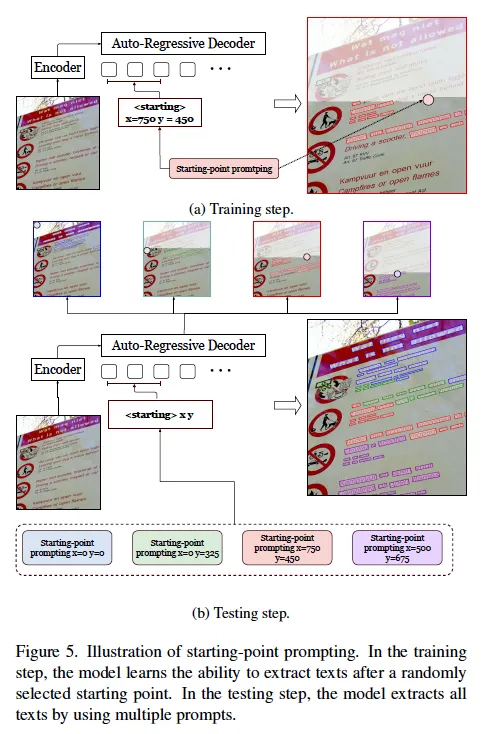
다음은 starting-point prompintg에 대한 설명입니다. 앞서 언급했듯이, 이 방식은 이미지에 텍스트가 너무 많아 모델이 한 번에 모두 예측할 수 없는 경우를 해결하기 위해 제안되었습니다. 모델은 기본적으로 좌상단에서 우하단으로 스캔하면서 텍스트를 읽게 되는데요. 그림 5를 보시면 학습 단계에서는 랜덤하게 시작점을 지정하여, 해당 지점에서 시작해 그 아래로 존재하는 모든 텍스트를 읽도록 학습됩니다. 이렇게 하면 모델이 특정 지점에서부터 시작하는 prediction을 자연스럽게 처리할 수 있게 되죠.
그 후 테스트 때는, 이미지의 좌상단을 시작점으로 지정하여 ****sequence를 generation하다가 ****생성된 시퀀스가 끝나지 않았다면 그러니까 end token <eos>이 나오지 않고 max 길이를 다 써버렸다면, 마지막으로 검출된 텍스트 위치를 다음 starting point로 설정하여 남아 있는 텍스트들을 이어서 예측합니다. 이 과정을 end token이 나타날 때까지 반복하여, 모델이 전체 이미지에 존재하는 모든 텍스트를 부분 부분 검출해 연결하는 방식으로 spotting을 수행하게 됩니다.
2.2. Architecture and Objective
Architecture
본 모델은 기본적으로 encoder-decoder 구조를 따르는데 encoder로는 swin transformer를 사용하였구요, text sequence를 생성하기 위해서는 transformer decoder를 사용하였습니다.
Multi-way Decoder
이때 Mixture of Expert의 컨셉을 가져와 multi-way decoder를 사용하도록 했는데요, 제안된 모델이 여러 annotation format을 예측할 수 있도록 모델을 학습하기 때문에 text location token의 개수가 매번 다르게 됩니다. 그렇기에 여러 format을 학습하는 것이 고정된 패턴의 단일 format을 학습하는 것보다 더 어렵기 때문에 detection expert와 recognition expert를 따로 두어서 detection 부분에 대한 sequence를 detectio n expert가 예측하도록 한 다음 recognition expert로 recognition부분의 sequence를 generation할 수 있도록 하였습니다. 그냥 transformer decoder를 태우는데 multi-head attention는 공유하되 각 task에 대한 feed forward network가 각각 있다고 보시면 되며, 초기 time stamp에서 detection expert가 활성화되어 text instance의 위치 정보를 예측하고, 그 후 다음 time stamp에 recognition expert가 활서오하되어 recognition 관련 sequence를 generation하는 것입니다.
Objective
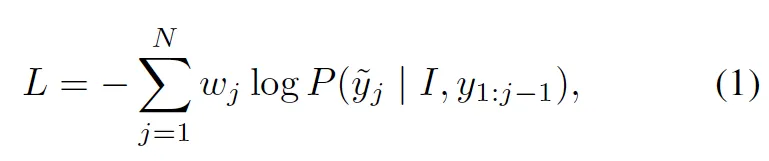
본 UNITS 모델이 task-specific한 head없이 decoder를 통해 token을 predict하는 식으로 동작하기 때문에 Loss는 단순히 gt sequence와 target sequence간의 cross entropy loss를 사용하였습니다. 식에서 j는 time stamp이구요 y와 \tild{y}y는 각각 input, target sequence입니다.
3. Experiments
3.1. Results on Text Spotting Benchmarks
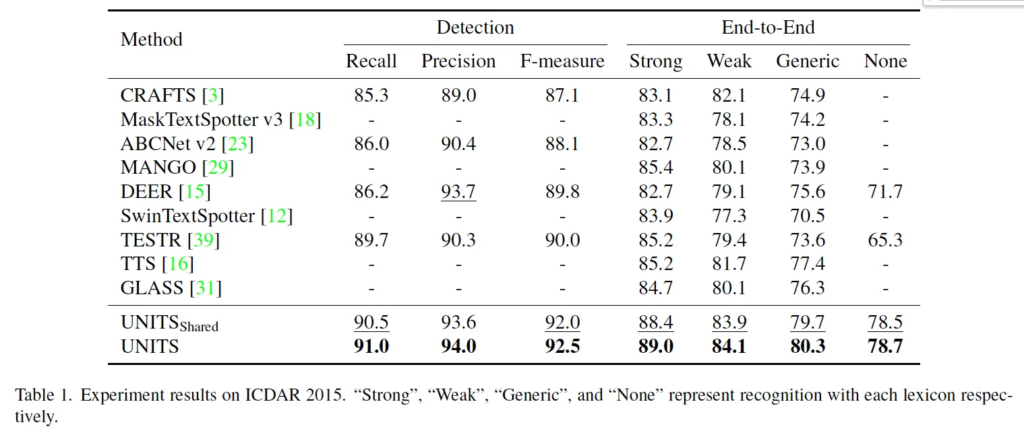
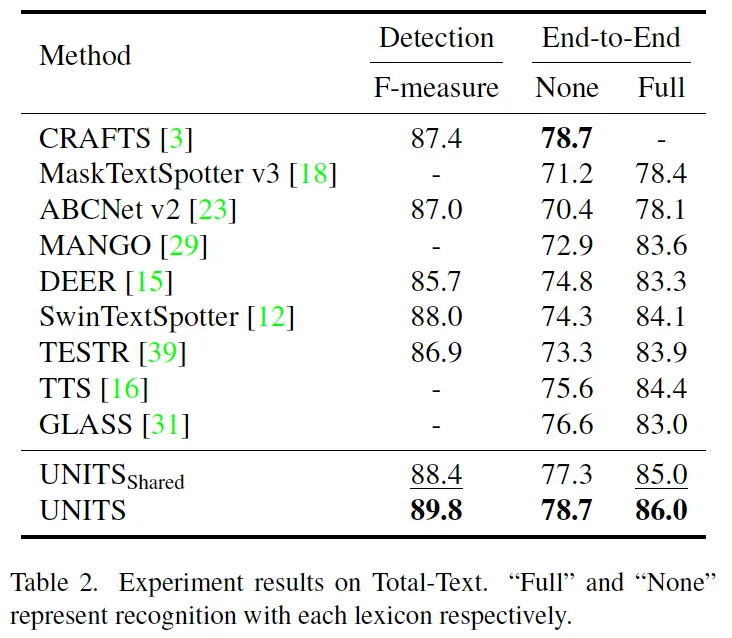
이제 실험 결과를 살펴보도록 하겠습니다. 이 두 테이블은 메인 실험 결과 table로 각각 사각형 형식의 annotation을 갖는 ICDAR 2015데이터셋과 polygon 형식의 어노테이션을 갖는 total text 데이터셋에 대한 실험 결과입니다. 여기서 UNITS shared는 여러 어노테이션 format을 다 합쳐서 사용한 unified model이고 그 아래 그냥 UNITS는 각 데이터셋에 맞게 fine-tuning된 모델입니다. 이 UNITS shared와 fine-tuning한 UNITS 사이를 비교해봤을 때는 역시 데이터셋에 맞게 한 annotation만으로 tuning한 모델이 약간 성능이 더 높은 것을 확인할 수 있습니다. 또, 벤치마크 데이터셋에서 UNITS가 end-to-end 기준 SOTA를 달성한 것을 볼 수 있는데 이로써 본 모델의 사각형과 polygon output이 기존 방법론에 비교했을 때 경쟁력있다고 말할 수 있겠습니다.
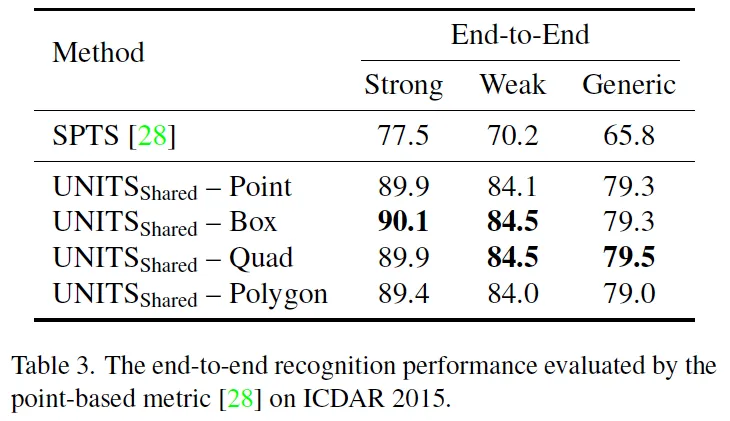
위 table3은 본 UNITS와 동일하게 sequence generation 방법론이면서 하나의 single central point 형식만 사용하는 SPTS에 대한 비교입니다. SPTS가 point 기반의 evaluation metric을 제안하였다고 하여 동일한 metric을 따라 성능을 측정하였다고 합니다. 표를 보시면 UNITS는 single point를 포함하여 box, quadrilateral, polygon format을 output으로 뱉을 수 있는 모델이기에 각각에 대한 성능을 리포팅해두고 있습니다. 모든 output에 대한 e2e 성능을 보면 같은 형식인 poitn와 비교해보았을 때도 제안된 UNITS가 훨씬 좋은 성능을 보이고 있으며 그외의 format도 그와 유사한 양상을 띕니다.
3.2. Ablation studies
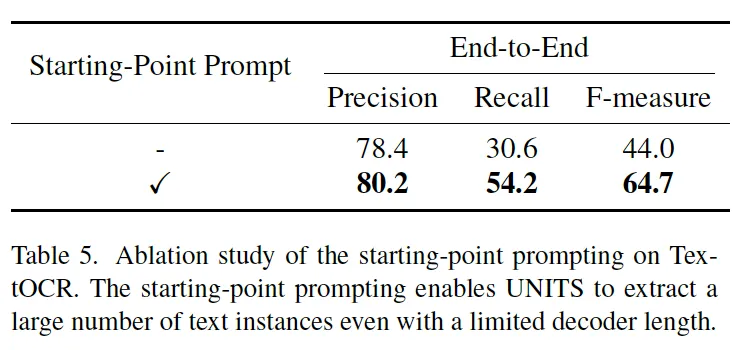
다음은 starting point prompting에 대한 ablation study입니다. 본 방식은 decoder의 길이가 제한되어 있을 때 이 길이를 초과하여 더 많은 text instance를 detection하고 recognition할 수 있게 도와주는 방법이었는데, 이에 대한 효과를 확인하기 위해 UNITS 모델을 starting point prompting을 사용하지 않았을 경우와 사용했을 경우의 성능을 비교해보았습니다. 이 실험은 상대적으로 text instance를 많이 포함하고 있는 데이터셋인 TextOCR 데이터셋에서 수행이 되었고 이때 사용한 format으로는 single poitn를사용하도록 해서 베이스로 삼았던 모델 SPTS와 유사하도록 하였습니다. 결과를 보시면 starting prompting을 사용하면 model의 recall이 엄청 향상된 것을 확인할 수 있는데, 이는 sequence lengh의 한계를 넘어 더 많은 instance를 검출할 수 있기 때문이라고 볼 수 있겠습니다.

위 Fig8의 정성적인 결과에서도 볼 수 있듯이 starting prompt가 없는 경우에는 수많은 text instance를전부 검출해내지 못하고 있으며 제안된 방식은 전체를 다 검출하고 있음을 보여줍니다.

마지막으로 multi-way transformer decoder에 대한 ablation study입니다. 저자가 여러 decoder format의 sequence를 generation해야 함을 고려하여 transformer decoder에서 attention까지는 공유하고 FFN을 detection expert, recognition expert로 나눠 사용하도록 했었는데요. 이의 효용성을 확인하기 위해 vanilla decoder를 사용했을 경우와 비교를 해 보았습니다. 위 표7을 보시면 결과가 나와있는데, multi-way decoder를 사용했을 때 vanilla에 비해 detection과 e2e 성능이 많이는 아니지만 약간 상승한 것을 볼 수 있습니다. 엄청난 성능 향상이 있지는 않지만 이 multi-way decoder를 사용했을 경우에 각각의 expert가 detection token, recognition token을 생성하도록 함으로써 수렴 속도가 더 빠르기 때문에 사용하는 것이 이점이라고 볼 수 있겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
starting-point prompting 방식을 제안한 것이 흥미로웠는데, 이에 대한 ablation이 조금 부족한거 같아 아쉬웠습니다. 해당 방법론이 랜덤으로 시작점을 찾아서 학습하는 것이다보니 여러 seed로 실험했을 때의 성능의 평균이 궁금한데요. 여러 랜덤으로 실험한 경우에 대해서는 따로 리포팅한 것이 없을까요?
감사합니다.
댓글 감사합니다.
네 ㅠ 아쉽게도 여러 랜덤으로 실험한 경우에 대해서 따로 리포팅한 것을 없습니다.
안녕하세요, 좋은 리뷰 감사합니다.
프레임워크의 전반적인 설명을 읽다 궁금한 점이 있는데요, 학습 과정에서 입력으로 함께 넣어주는 프롬프트는 데이터셋에서 함께 제공이 되는 것인가요?
댓글 감사합니다.
프롬프트 중 form of <> 부분을 말씀하신 것 같은데, 데이터셋에 따라 각 text instance annotation이 polygon인지 quad인지 지정된 것도 있고, 아예 통으로 dataset이 quad anno만 존재하는 것 등등이 데이터셋마다 다른데, 기본적으로 사전에 anno form 정보는 알 수 있습니다. 구체적으로 이 prompt안에 들어가는 anno form이 어떻게 들어가는지는 언급되지는 않는데, 임의로 quad anno만 있어도 poly로 변형해서 poly gt를 얻어낼 수 있을테고 이때는 prompt에 poly form을 넣어주는 식으로 동작할수도 있을 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문의 선행 논문인 SPTS같은 경우 다양한 task와 상황에 맞춰 적합한 detection을 해내지 못한다는 단점이 있는 것 같고, 제안된 본 논문이 다양한 annotation format을 다룰 수 있도록 image와 함께 입력으로 prompt를 넣어줌으로써 해결하는 것 같은데 inference시에 이런 prompt는 직접 하나하나 이미지를 보고 지정해줘야 하는 부분인건지 궁금합니다.
감사합니다.
댓글 감사합니다.
프롬프트 중 form of <> 부분을 말씀하신 것 같은데, 데이터셋에 따라 각 text instance annotation이 polygon인지 quad인지 지정된 것도 있고, 아예 통으로 dataset이 quad anno만 존재하는 것 등등이 데이터셋마다 다른데, 기본적으로 사전에 anno form 정보는 알 수 있습니다. 구체적으로 이 prompt안에 들어가는 anno form이 어떻게 들어가는지는 언급되지는 않는데, 임의로 quad anno만 있어도 poly로 변형해서 poly gt를 얻어낼 수 있을테고 이때는 prompt에 poly form을 넣어주는 식으로 동작할수도 있을 것 같습니다.