사전 학습된 모델을 특정 작업에 맞게 최적화하는 파인 튜닝(fine-tuning)은, 사전 학습에 사용된 정보를 손실하는 catastrophic forgetting 문제가 있다고 알려져 있습니다. 그러나 본 논문에서는 다른 관점을 제시하는데요, 제목부터 흥미로운 논문 리뷰를 시작하겠습니다.
Introduction: Fine-Tuning is Fine
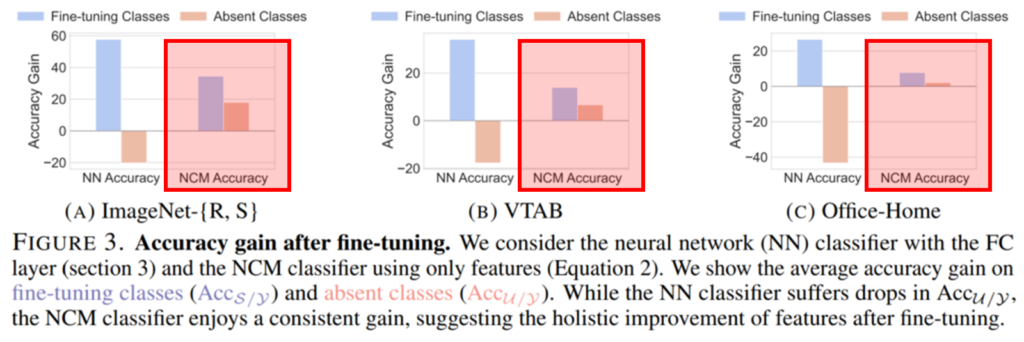
본 논문은 사전학습에 사용했던 데이터의 subset으로 Fine-tuning을 진행했을때(데이터셋 구성 우측 [보충자료1] 참조), 사전학습에만 사용한 absent classes data에 대한 표현력을 잊어버리는 catastrophic forgetting 현상에 대해 분석한 논문입니다. 논문의 실험에 따르면, Fine-tuning을 하더라도 사전학습한 데이터에 대한 표현력을 잃지 않는다고 하며, 어떠한 이유로 Fine-tuning 이후에 absent classes에 대한 성능이 하락하는지에 대한 분석과 해결책을 제시합니다.
위의 Figure3 은 Fine-tuning 이후에도 모델이 absent classes에 대한 표현력을 잃지 않음을 보이는 실험입니다. 실험은 ImageNet-R/S , VTAB, Office-Home의 다양한 데이터에 대해 이루어졌으며, 추가적인 학습 없이 Feature간의 거리를 통해 분류하는 NCM 평가 방식으로 absent classes에 대한 분류 예측 평가를 진행했을 때, Fine-tuning이후에 absent classes에 대한 분류 정확도가 오히려 올랐음을 보였습니다. 자세한 실험 방식은 뒤에서 소개하겠습니다.
Fine-tuning 이후에도 feature distance를 기반으로 absent classes에 대한 구분 능력이 유지되었는데도, 기존 연구[1]가 Fine-tuning으로 인한 정확도 손실을 확인하고 분석할 수 있었던 이유가 무엇일까요? absent classes에 대한 이러한 종류의 성능 하락은 Figure3의 NN(neural network) classifier를 활용한 성능 평가에서도 확인할 수 있습니다. 이어서 논문에서 분석한 현상의 원인과 해결책을 소개하겠습니다.
실험 세팅
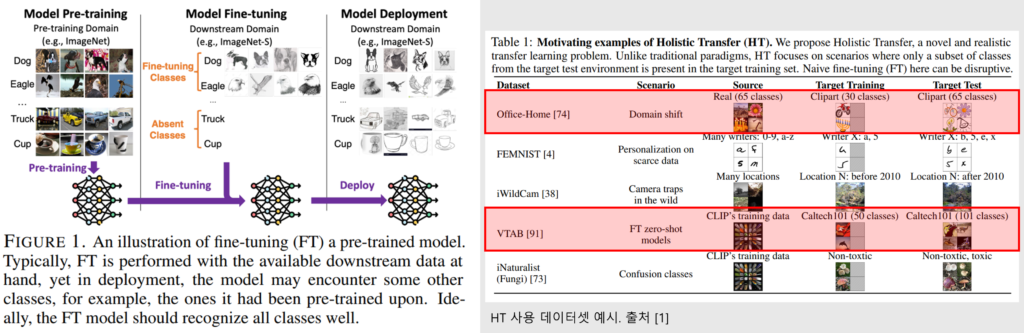
본 논문은 현상을 분석한 systematic study 입니다. 따라서 분석 실험의 세팅을 먼저 소개하겠습니다. Figure1에서 확인할 수 있는 해당 세팅은 [1]에서 제안된 Holistic Transfer (HT) 라고 합니다. 먼저 모든 클래스를 활용에 A 도메인(예시.실제사진)에 대해 사전학습을 합니다. 이후 일부 클래스(Fine-tuning classes)에 대해 Target 도메인인, B 도메인(예시. 스케치)에 대해 Fine-tuning을 합니다. 이후 평가는 다시 모든 클래스에 대해 타겟 도메인(B 도메인)에 대해 진행하게 됩니다. 이때 사전학습에는 사용하였으나, Fine-tuning에는 사용되지 않은 클래스를 absent classes라고 합니다.
본 논문에서는 [1]에서 활용한 Office-Home 데이터와 VTAB 데이터([보충자료2]우측 참조), 그리고 ImageNet의 subset으로 구성된 ImageNet-R/S에 대해 HT를 기반으로 현상에 대한 분석을 진행하였습니다.
분석 대상
본 논문의 분석 대상은 “Fine-tuning으로 인해 발생하는 absent classes에 대한 성능 하락 현상”입니다. 기존 연구에서는 이러한 현상의 원인을 보통 “catastrophic forgetting”으로 분석하여, 해결책을 제시했습니다. 그러나 본 리뷰 상단의 Figure 3에서 확인하였듯이, Fine-tuning 이후에도 Feature space에서 absent classes에 대한 구별 능력은 사라지지(forgetting)않았으며, 오히려 표현력이 개선되었되었습니다.
이러한 관찰을 기반으로 본 논문은 성능 하락의 원인을 forgetting이 아니라, 예측의 최종값(logit)의 scale이 Fine-tuning classes에 편향적으로 강하기 때문임을 밝힙니다. 이러한 편향은 간단한 post-processing calibration으로 해결할 수 있으며, 이러한 현상을 해결하기 위한 기존 방법론(사전학습 모델의 가중치 보존 등)의 방식보다 효과적으로 absent classes에 대한 예측 성능을 개선할 수 있음을 보였습니다.
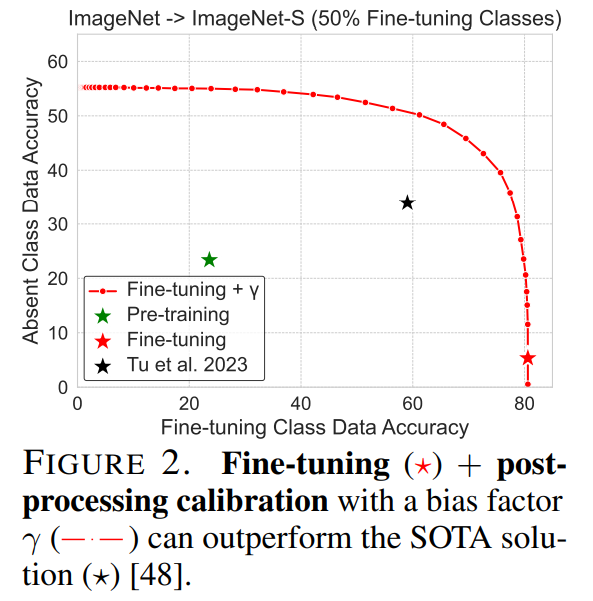
위의 Figure2는 분석 대상인 성능 하락 현상을 보이는 그래프입니다. 초기 사전학습된 초록색 별은 absent class에 대해 약 23의 정확도를 보였는데, Fine-tuning이후(붉은 별) 3% 정보로 하락했습니다. 그러나 간단한 calibration을 적용하였을 때 (calibration 정도에 따라) 붉은 점선의 성능을 보일 수 있으며, 기존 해결책인 [1](검정색 별)에 비해 Fine-tuning 이후, absent class에 대한 구별력도 보존하고, Fine-tuning class에 대한 구별력도 향상할 수 있음을 확인할 수 있습니다.
원인 분석 실험
실험에서는 현상의 원인을 찾기위해, 모델의 어느 부분이 원인이 되는지를 먼저 분석합니다. 이어서 논문에서 제시하는 실험에 대해 소개하겠습니다.
본 실험에서 정확도의 리포팅 방식은 Acc_A/B 입니다. 이때 B는 분류기가 분류가능한 label space이고, A는 데이터셋이 정의한 label space 입니다. S는 Fine-tuning class/U는 absent class/y는 S와U를 포함한 전체 데이터셋 class이며, 리포팅은 Acc_S/y,Acc_U/y, Acc_S/S, Acc_U/U과 같이 다양한 방식으로 리포팅 되었습니다.
Fine-tuned feature extractor가 손상되는가? -> No! (Figure3, 4 참조)
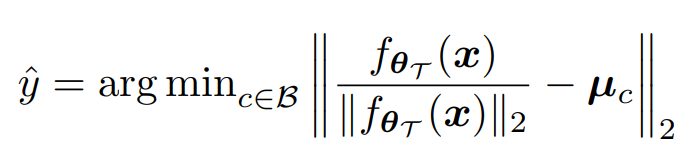
해당 분석 결과에 앞서 실험에 사용된 가정은 다음과 같습니다. 논문에서는 모델을 feature extractor(fθ, θ는 파라미터)와 분류기(W)로 구성되었다고 가정합니다. 해당 실험에서는 분류기를 제외한 feature extractor(f)의 영향력을 확인하기 위해 NCM classifeier([[수식2]])를 적용하였는데요, 전체 분류가능한 label space를 B(베타)라고 하며, 클래스 c에 해당하는 데이터의 feature 평균 µ_c을 활용해 x의 embedded feature인 f(x)를 특정 클래스 y^으로 분류합니다. 이때 모든 데이터를 활용하여 클래스의 평균(µ)을 생성했다고 합니다. (또한 사전학습 모델의 파라미터는 θO, fine-tuning이후의 파라미터를 θ_T라고 합니다.)
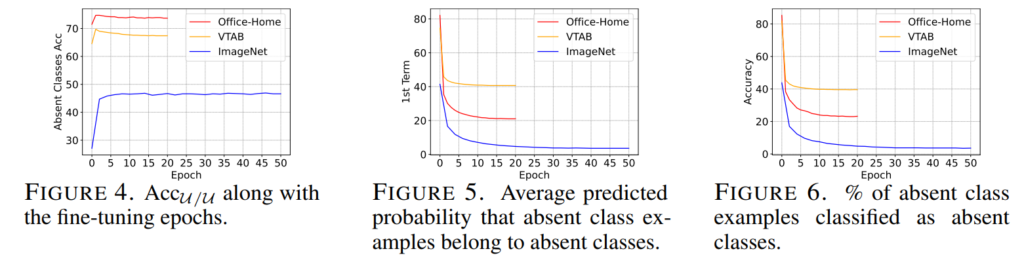
본 의문에 대한 실험의 결과는 위와 같습니다. 가장 주목할 실험은 Figure4 입니다. Fine-tuning이 진행되더라도 분류기의 label space가 absent class(U)에 한정된다면, 각 데이터셋에서 구분의 성능은 오히려 증가하고, 학습이 진행되더라도 하락하지 않음을 보였습니다. 즉 f는 fine-tuning 이후에도 absent class 간의 관계, 구분력은 손실되지 않았습니다.
그럼 이러한 문제 현상의 발생하는 이유는 무엇인가? -> 최종 예측(logit)에서 absent classes에 대한 예측 확률 감소/손상(Figure 5, 6 참조)
Fine-tuning 이후에 feature extractor의 absent classes에 대한 구분능력이 강화된다면, Figure2에서 관찰한 성능 하락이 원인은 이후 분류기인 W(FC layer)에 있을것입니다. 본 논문은 W를 분석하기 위해, W의 예측인 P(c|x)를 [수식3]과 같이 나누어 접근하였습니다.

실험의 결과 absent classes에 속하는 입력 데이터(x)를 absent classes로 구분할 확률([수식3]의 1st term)은 점차 감소하였고(Figure 5), 이로 인해 fine-tuning이 진행됨에 따라 absent classes를 absent classes라고 예측한 비율이 감소하였음을 Figure 6을 통해 확인하였습니다.
즉, 현상의 원인은 수식3의 term 1 (데이터가 absent라고 분류될 확률)의 예측 성능 하락임을 밝혔습니다.
해결 방법: Fine-Tuning is Fine if Calibrated
앞선 분석한 결과, Fine-tuning 모델은 두 가지 특성을 가집니다:
- absent classes에 대한 분류 성능은 유지되거나 오히려 개선됨.
- 하지만, fine-tuning classes와 absent classes 간의 최종 예측값(logit) 값이 편향되어, absent classes에 속하는 데이터를 잘못된 fine-tuning class에 할당하는 문제가 발생함
논문에서는 logit 편향 현상을 간단한 후처리 calibration으로 해결할 수 있으며, 이러한 해결 방법은 기존 해결 방법 대비 더욱 효과적임을 보였습니다. 보정의 방식은 매우 간단한데 예측한 logit 값에서 absent classes에 해당하는 값을 키우는 것입니다. 보정의 수식은 아래의 [수식4]와 같습니다.
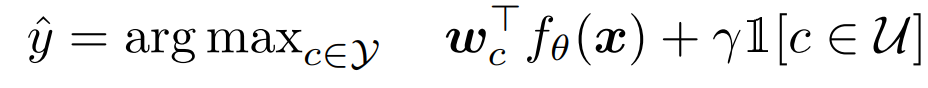
위에서 언급한 것처럼, 최종 예측(logit=wf(x))에서 U에 속하는 확률(softmax 기반 예측)값을 γ만큼 키우는 것입니다. γ의 값은 logit의 평균(ALG, Average logit gap), Fine-tuning classes를 두 개의 그룹으로 나누어(Pseudo Fine-tuning classes, Pseudo Absent classes) 임의로 absent classes를 생성하고, 이렇게 분할한 두 그룹 간의 성능 균형을 맞추는 값(PCV, Pseudo class-validation)으로 설정하고, Calibration 방식으로 해결 할 수 있는 상한값 제시를 위해 테스트 데이터를 기반으로 직접 설정한 보정값을 사용한 γ⋆로 logit을 callibration 하여 아래의 실험을 진행하였습니다.
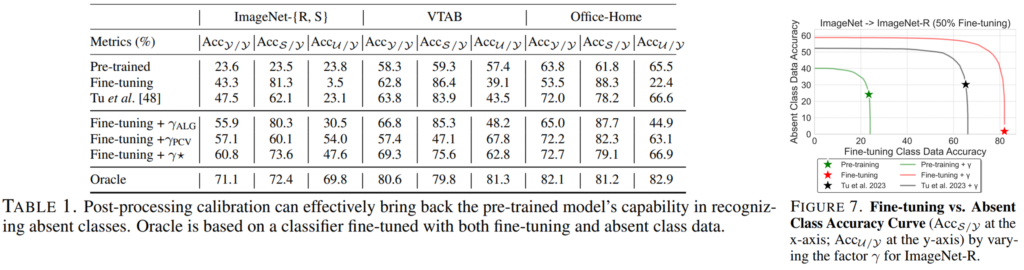
먼저 Table1에서는 제시한 Calibration 방식을 SOTA 방법론[1]과 비교하였으며, 제시한 방법을 기존 방법[1]에 부가적으로 적용한 결과를 Figure7로 보였습니다.
Ablation Study
마지막으로 이러한 현상이 분석된 세팅에서만 발생하는것인지 확인하기 위해 다양한 absent/fine-tuning classes 세팅과 optimizer, hyper-parameter 세팅에서 동일 실험을 진행하였습니다. 확인 결과 분석된 현상(fine-tuning 이후에도 모델은 absent classes에 대한 지식을 보유하고 있음)은 모든 세팅에서 일관되게 나타남을 보였습니다.
아래의 실험에 Acc_U/U외에 추가적으로 사용된 지표인 AUSUC(Area Under the Seen-Unseen Curve)는 Fine-tuning 이후의 모델이 Fine-tuning classes와 absent classes에 대해 얼마나 잘 균형 잡힌 성능을 보여주는지 측정하는 지표로, Figure7에 사용된 커브의 면적을 의미합니다. 즉 면적이 넓을수록(AUSUC 스코어가 높을수록) absent classes에 대해서도 잘 예측을 수행함하는 모델입니다.
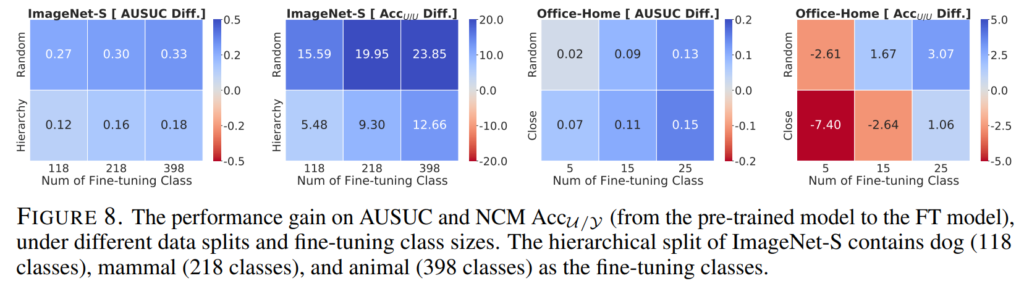
먼저 Figure8 Fine-tuning classes가 실험된 세팅보다 더욱 적고, 체계적으로 구성된 상황에 대해 리포팅했습니다. Fine-tuning classes가 적고, 체계적으로 구성(ex, Fine-Grained setting)되면 Fine-tuning 시에 해당 데이터셋에 더욱 맞춤형으로 파라미터 변형이 일어날 수 있기에 absent classes에 대핸 forgetting이 발생할 수도 있다는 가정에서 추가된 실험입니다. 실험에 사용된 ImageNet-S의 경우 본래 500개의 fine-tuning class를 활용했지만 FIgure8에서는 118, 218, 398개의 더욱 적은 classses로 설정했을때도 absent classes에 대한 표현력이 보존됨을 실험으로 증명했습니다. 또한 본래 30개의 Fine-tuning classes를 구성했던 Office-Home datasets도 5/15/25로 극단적으로 줄이더라도 absent classes에 대한 구분 능력이 강화되거나 거의 보존함을 보였습니다.
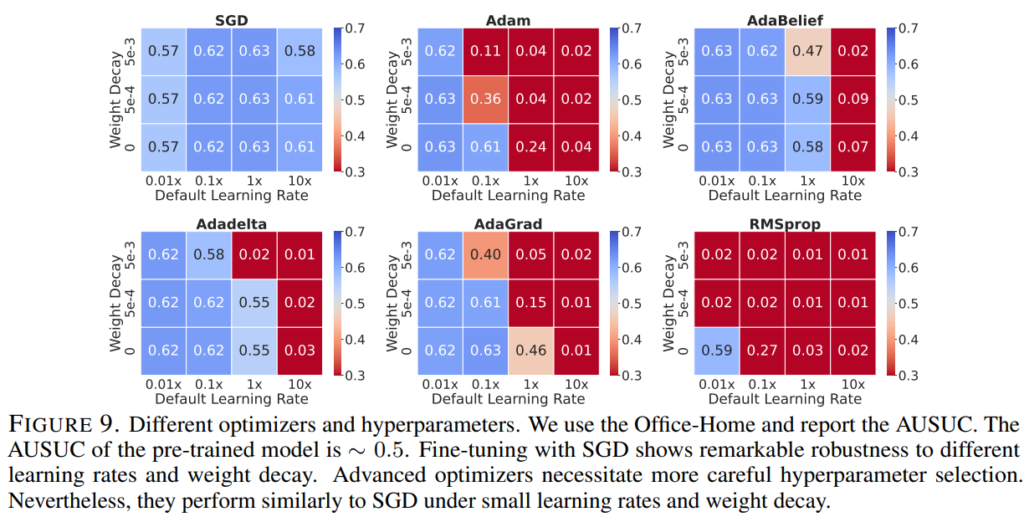
다음으로 Figure9는 optimizer와 hyperparameter같은 특정 세팅에 의해 이러한 현상이 발생한것인지 확인하기 위한 실험으로 기본 실험 세팅인 SGD 뿐만 아니라 Adam/AdaBelief/Adadelta/AdaGrad/RMSprop 에서 Learning rate를 다양히 하여 AUSUC 를 측정하였습니다. 그 결과 모든 세팅에서 absent classes에 대한 극단적인 성능하락은 발생하지 않았음을 확인하였으며 분석된 현상이 특정한 세팅에서만 발생하는 현상이 아님을 밝혔습니다.
Additional Analysis
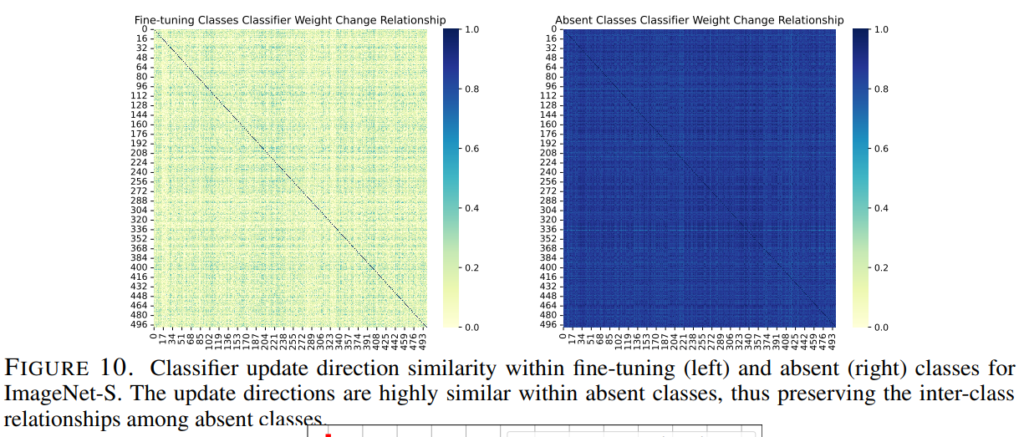
마지막으로 논문은 이러한 현상의 추가적인 분석들을 제공합니다. 먼저 Figure10은 FIne-tuning 이후에도 absent classes에서 클래스 간의 구별력이 유지되는 이유를 명시합니다. 즉, Fine tuning 이전과 이후에 대해 classifer(linear layer, W)의 가중치 변화 방향의 클래스별 연관성을 시각화 합니다. 분석은 1,000개의 클래스로 구성된 ImageNet-S에서 이루어졌으며, 500개의 Fine-tuning class에 대한 가중치 변화량(Figure10 좌측), 500개의 absent class에 대한 가중치 변화량(Figure10 우측)을 시각화 했습니다.
Fine tuning 클래스 간의 가중치 변화 방향(좌측)은 서로 연관성이 없음을 확인할 수 있는데, Fine-tuning 과정에서 각 클래스가 더 잘 구분되도록 클래스간의 관계가 변화되었음을 알 수 있습니다. 반면, absent classes 간의 관계는 거의 보존되었는데, absent classes에 대한 학습 데이터가 없기 때문에, 추가적인 구별력 향상 없이, 동일한 관계성이 보존되었음을 나타냅니다.
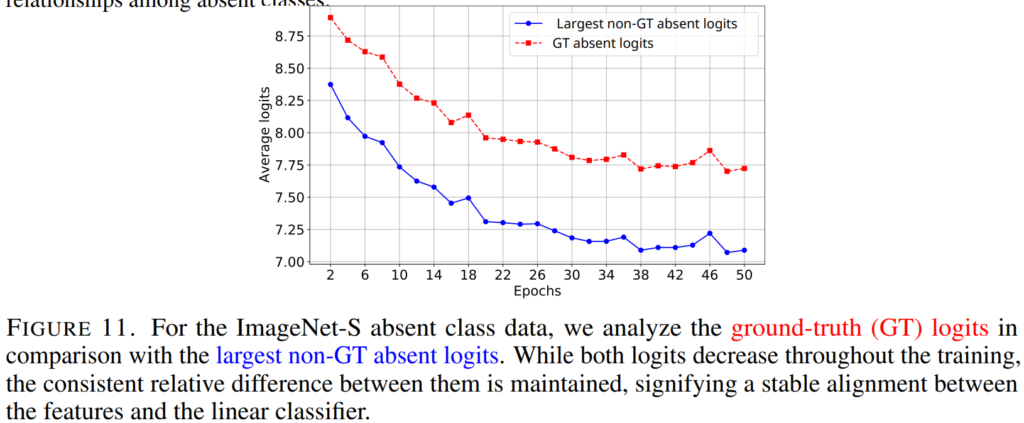
다음으로 Figure11은 absent classes에 대한 모델의 구분 능력 보존을 더욱 공고히 하였습니다. Fine-tuned 모델에 대해 absent classes에 속하는 데이터의 예측 logit을 시각화 했을 때, Fine-tuning epoch가 증가할 수록 logit의 스칼라 스케일이 작아지기는 하나, absent classes 내에서 GT에 대한 예측 확률(붉은색)과 GT가 아니면서 가장 높은 확률로 예측된 값(파란색)간의 차이(margin score)가 안정적으로 유지됨을 통해, absent classes간의 관계성이 FIne-tuning 이후에도 변하지 않았음을 확인할 수 있습니다.
본 논문은 Fine-tuning이 pretrain에 사용된 datasets에 대한 정보를 손실한다는 일반적인 믿음에 균열을 주는 논문이였습니다. 실험된 HT 세팅에서 도메인 변화(Office-Home datasets)가 있었음에도 absent classes 구별력에 손실이 없었다는것도 놀라웠습니다. 실험에 사용된 코드[Github]가 공개되어 있으니, 필요하시면 확인하실 수 있습니다.
참고문헌
[1] Holistic transfer: Towards non-disruptive fine-tuning with partial target data. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
좋은 논문 리뷰 감사합니다.
fine-tunning을 진행하면 이전 사전 학습 정보를 잊게된다는 알려진 바와 다르게
logit이 편향되는 것이라는 것을 분석 실험을 토대로 발견한 논문이네요.
해당 연구의 경향이 다른 다운스트림에서도 동일하다면 큰 영향이 있을 것 같아요.
적용하면 좋을 것 같은데 세팅에 관련하여 질문을 드리자면
Q. fine-tunning 수행을 위해 분류기 학습을 진행하면서 클래스 수에 맞춰 차원을 맞추는 작업을 수행합니다. 저자가 제안하는 기법은 absent classes을 기억하기 위한 보정 작업을 위해 r을 맞추는 작업을 수행하는데, 추가 학습 일절 없이 r 값만 추가하는 방식을 가지는 걸까요?
직관적으로 질문하면 Num of fine-tunning class N_c를 예측하는 output ^y \in R^ {N_c}로 출력하고 여기에 Num of absent classes N_a는 y^에 고정된 값을 출력하는 방식인지? 출력값이 어떻게 나오는 건지 잘 모르겠어요 ㅜㅠ
안녕하세요 리뷰 읽어주셔서 감사합니다.
우선 본 논문은 방법론을 제안하는 것이 아닌, 분석 논문(systematic study)임을 말씀드립니다. 따라서 γ를 추가한다는것 자체보다는간단한 post-processing calibration으로 기존에 어려움이 있었던 pretrain model의 absent class에 대한 성능 하락 현상을 해결할 수 있음을 중점으로 보시면 더욱 좋을 것 같습니다.
분석을 위한 세팅(HT, [보충자료2] 참조)에서 예측의 출력은 [수식4]에 해당하는데, 전체 클래스(y)가 개, 고양이, 말, 소라고 하고, absent class(개, 고양이), Fine-tuning classes(말, 소)라고 하고, Fine-tuned 모델(f_T)의 예측(logit)이 P라고 하겠습니다.
f_T는 관찰된 현상에 의해 입력된 고양이 이미지(x)에 대해 P=[개0.1 고양이0.2 말0.4 소0.3] 라고 잘못 예측할 가능성이 높습니다. 이때 γ를 이용해 calibration 한다면 아래와 같은 결과를 얻을 수 있습니다.
P_calibrated = [개0.1+γ 고양이0.2+γ 말0.4 소0.3] = [개0.6고양이0.7 말0.4 소0.3] (γ=0.5)
즉, 위의 간단한 post-processing 과정을 통해 logit bise 해결로 absent classes에 대한 올바른 예측을 할 수 있어집니다.
안녕하세요 황유진 연구원님 재밌는 리뷰 감사합니다.
Fine-tuning 이후 forgetting 이슈를 제가 검증해본건 아니라, 막연하게 그거 실제하는거야? 라는 의문을 가지고 있었는데,
이를 분석한 연구가 있다니 덕분에 재밌게 읽었습니다.
다만 본 논문에서 사용한 정확도 리포팅 방식을
“Acc_A/B 입니다. 이때 B는 분류기가 분류가능한 label space이고, A는 데이터셋이 정의한 label space 입니다” 라고 설명해주셨는데, 혹시 예시와 함께 다시 한번 설명해주실 수 있을까요?
안녕하세요 홍주영 연구원님, 질문 감사합니다.
예를 들어 ACC_u/y라면 fine-tuning class에 대한 예측을 전체 labeled space 공간인 y에서 수행하는 것입니다. 일반적인 성능 평가라면 ACC_u/u 혹은 ACC_s/s, ACC_y/y 등을 수행하겠지만, absent class에 대한 예측 성능 보존 가능성을 확인하기 위해 본 논문은 실제 학습한 class와 예측 때 활용되는 classifer의 분류 카테고리를 다르게 하여 모델의 표현력을 확인합니다.
(*S는 Fine-tuning class/U는 absent class/y는 S와U를 포함한 전체 데이터셋 class)