안녕하세요, 이번 주 X-Review에는 24년도 AAAI에 게재된 논문 <Exploiting Auxiliary Caption for Video Grounding>을 소개해드리겠습니다. 비디오 도메인의 Video Grounding task를 수행하며, 중국 북경대의 연구 결과지만 특정 사유로 신뢰도는 좀 떨어지는 논문입니다..
최근 Moment Retrieval (=Video Grounding) task와 관련해, 주어지는 텍스트 쿼리 문장에 대한 이해를 바탕으로 성능 개선을 시도중인데, 같은 맥락으로 연구된 몇 없는 논문 중 하나라 리뷰하게 되었습니다. 자세한 내용은 뒤에서 살펴보기로 하고, 리뷰 바로 시작하겠습니다.

1. Introduction
Video Grounding (VG)은 비디오와 사용자의 텍스트 쿼리를 쌍으로 입력받아, 쿼리에 의미론적으로 상응하는 비디오의 일부 구간을 예측하는 task입니다. 우선 서로 다른 두 모달 간의 상호작용을 수행해야한다는 점도 어려움을 주지만, 이러한 상호작용을 하며 심지어는 의미론적 정합까지 맞춰야 한다는 점에서 여간 쉬운 task 아닙니다.
저자가 지적하는 문제점은 사실 방법론적 테크닉에 대한 것은 아니고, 이 task에 근본적으로 존재하나 기존 방법론들이 크게 신경쓰지 않았던, 즉 어떻게 보면 아예 새로운 문제에 해당합니다. 바로 Sparse annotation 문제입니다. 문제 이름이 직관적이라 바로 어떤 뜻인지 예상이 가실 것 같은데, 아래 그림 1과 함께 살펴보겠습니다.

위 그림 1은 ActivityNet Captions라는 데이터셋에 존재하는 하나의 비디오를 보여주고 있는데요. 우선 초록색 글씨로 표시되어 있는 것은 비디오의 실제 GT로서, annotation 되어있는 구간과 상응 텍스트 쿼리입니다. 비디오에 라벨링되어있는 텍스트 쿼리는 어떤 여자가 자신의 머리를 땋고, 이후 땋은 머리끼리 다시 묶는 내용을 포함하고 있습니다. 그러나 라벨링되어있는 구간 이외에도 비디오에서는 많은 일이 벌어지고 있습니다. 이를 표현하는게 붉은 글씨의 텍스트 캡션이고, 여자가 고무줄을 집는 등의 행위를 서술하고 있습니다.
위 비디오가 실제로 218초라고 하는데, 라벨링 되어있는 초는 거의 180초 가까이 됩니다. 그림 1에 따르면 라벨링되어있지 않은 38초의 구간에서도 자연어로 서술 가능한 행동이 발생하고 있습니다. “고무줄을 꺼내는” 구간은 “머리 땋는 구간”을 찾기 위해 보조적인 역할을 할 수 있으나 기존 방법론에서는 전혀 활용되고 있지 않았다는 것이 바로 저자가 지적하는 Sparse Annotation 문제점입니다.
위 예시에서는 218초 중 약 38초라, 이 정도면 크게 와닿지 않으실 수도 있는데 최근 활발히 벤치마크되고 있는 QVHighlights 데이터셋의 학습 split을 살펴본 결과 전체 비디오의 약 30% 구간만이 라벨링되어있었습니다. 풍부한 정보를 담고 있는 비디오의 70%는 학습에 거의 사용되지 않는다고 봐도 무방합니다. 최근 활발히 연구되는 DETR 기반의 Video Grounding 프레임워크에선 특정 프레임이 GT 구간인지 아닌지에 대한 이진 라벨, 즉 0, 1을 예측해 BCE loss로 학습하는 것이 전부인데요, 라벨링되어있지 않은 구간의 시각적 정보가 활용된다고 보기에는 어렵다는 것이죠.
주어진 정보를 기존보다 더 풍부하게 활용하기 위해 저자는 Auxiliary Caption Network (ACNet)을 제안합니다. 이 ACNet을 적용하기 위해선 우선 GT 구간 외에서 그림 1의 붉은 글씨로 표현되어있는 Auxiliary caption을 추출해야 합니다. 저자는 이를 위해 기존의 Dense Video Captioning의 모델을 그대로 가져와 활용하게 됩니다.
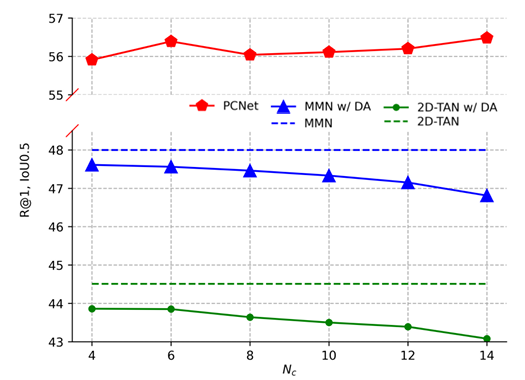
Dense Video Captioning 모델에 비디오를 입력하면 자동으로 Event 구간을 잘라내고, 각 구간의 caption을 자연어 형태로 내뱉게 됩니다. 그러면 저희는 하나의 비디오 샘플에 대해 기존 annotation+captioning 모델이 만들어낸 event 구간과 상응 캡션을 가지고 있게 됩니다. 그러나 annotation+캡션을 다듬지 않고 학습에 모두 활용하면 오히려 성능의 하락을 불러오게 됩니다. 방금 말씀드린 학습 방식은 일종의 DA(Data Augmentation)라 볼 수 있는데, 그 2를 통해 볼 수 있듯 기존 방법론인 MMN과 2D-TAN에 DA를 적용하는 경우 오히려 성능이 떨어지고 있습니다.
(위 그림 2에서 붉은색으로 표시된 PCNet은 저자가 제안한 ACNet을 의미합니다. 이 논문의 arXiv 버전을 보니 23년도 초부터 다른 학회에 계속 제출되며 수정을 거듭한 것 같은데, 초기에는 PCNet이었던 제안 모델 이름이 ACNet으로 변경되었음에도 그림엔 반영이 제대로 안되어있는 것 같습니다. 그리고 아래에서 설명드릴 N_{c}라는 변수 또한 현 버전 나머지 절에서는 l_{c}로 표현되고 있는데, 그림에 잘못 나타나 있어 추후 방법론 설명 때 혼동을 주의해주시기 바랍니다. AAAI 사이트에 있는 CamReady 버전인데도 이러한 오류가 있네요.)
그림 2 가로 축의 N_{c} (타 절에서는 l_{c})는 캡셔닝 모델로부터 뽑아 학습에 활용하는 캡션의 개수를 의미하는데, 오히려 캡션을 많이 가져오면 가져올수록 성능이 떨어지고 있습니다. 반면 저자가 제안하는 ACNet의 경우 추가 캡션을 사용함으로써 큰 성능 향상을 이뤄내었습니다. 그렇다면 기존 방법론들이 캡셔닝 모델로부터 추출한 캡션을 그대로 학습했을 때 성능이 떨어지는 이유는 무엇일까요?
이에 대해 저자는 두 가지 원인을 언급하고 있습니다. 첫 번째는 캡셔닝 모델이 예측한 이벤트 구간과 해당 구간의 캡션 신뢰도가 떨어지기 때문입니다. 예측된 캡션과 구간을 그대로 다 쓰기에는 퀄리티가 그닥 좋지 않다는 것입니다. 두 번째로 추출한 캡션의 구간이 실제 사람이 라벨링한 원본 GT 구간과 겹칠 수 있다는 것입니다. 모든 task가 대부분 그렇겠지만, 어떠한 방식으로 pseudo label을 만들어낸다 한들 실제 사람이 만들어놓은 GT 라벨을 일종의 성역처럼, 즉 무조건 더 좋은 퀄리티를 갖고 있을 것이라 가정하게 됩니다. 그러다보니 캡셔닝 모델의 구간과 GT 구간이 겹치는 경우 기존 모델이 학습하던 GT 구간 표현력이 어그러지며 원래만 못한 성능이 달성되는 것이라고 이해해볼 수 있겠죠.
저자가 제안하는 ACNet 프레임워크에선 본격적 학습 이전 위 두 가지 문제점을 해결하기 위해 캡셔닝 모델로부터 추출한 구간을 정제해줍니다. 이를 위해 일종의 시간 축에서 NMS인 Non-Auxiliary Caption Suppression (NACS) 기법을 제안하고 이를 적용해 GT와 겹치지 않으면서 퀄리티 좋은 예측값들만을 실제 학습에 활용하게 되는 것입니다.
이어 저자는 Regression branch와 Contrastive learning branch로 나누어 학습을 진행합니다. Regression branch에서는 제안하는 Caption Guided Attention (CGA) 모듈을 통해 캡션을 고려한 GT 구간의 (시작, 끝) 지점에 대한 회귀 학습을 진행합니다. 두 번째로 Contrastive Learning branch에서는 Asymmetric Cross-modal Contrastive Learning (ACCL)을 제안합니다. 캡션과 해당 구간을 아무리 정제했다 해도 실제 GT 라벨의 신뢰도를 따라갈 수 없다는 가정 하에, Contrastive Learning 수행 시 캡셔닝 모델의 예측값은 GT와 동등한 수준으로 보지 않게 됩니다. 즉 InfoNCE에 들어갈 positive / negative set이 기존과 좀 달라진다는 의미입니다.
그럼 이제 논문의 Contribution을 정리하고 방법론으로 넘어가보도록 하겠습니다.
Contribution
- We present the sparse annotation dilemma in video grounding and propose to extract information about potential actions from unannotated moments to mitigate it.
- We propose Caption Guided Attention (CGA) to fuse auxiliary captions with visual features to obtain prior knowledge for video grounding. Moreover, we propose Asymmetric Cross-modal Contrastive Learning (ACCL) to mine potential negative pairs.
- Extensive experiments on three public datasets demonstrate the effectiveness and generalizability of ACNet.
2. Method
2.1 Problem Formulation & Feature Extraction
Video grounding은 비디오 V = \{x_{i}\}_{i=1}^{T}, 텍스트 쿼리 Q = \{w_{i}\}_{i=1}^{N_{q}}를 입력받아 상응 구간의 timestamp (t^{s}, t^{e})를 예측하는 것입니다. T는 비디오 내 샘플링된 프레임 개수, N^{q}는 문장 내 단어 개수를 의미합니다.
최근 DETR 기반 방법론들이 많이 연구되고 있지만, 본 논문의 ACNet은 꽤 예전 방식인 2D map 방식입니다. 비디오 모달과 관련해서는, C3D 백본을 활용해 2D Map feature F_{v} \in{} \mathbb{R}^{N_{v} \times{} N_{v} \times{} d_{v}}를 추출합니다. F_{v}의 (0, 3) 위치 원소는 C3D로 뽑은 feature의 0초부터 3초까지 구간을 maxpooling한 d_{v}차원짜리 feature입니다. 텍스트와 관련해서는 문장을 사전학습된 BERT에 입력하여 문장 feature F_{q} \in{} \mathbb{R}^{1 \times{} d_{s}}를 추출합니다.
이후 제가 학습을 위해 ACNet에는 regression branch와 contrastive learning branch가 존재한다고 말씀드렸었는데, 여기까지 추출한 비디오와 텍스트 feature에 각각의 MLP를 태워 (V_{r}, Q_{r}), (V_{c}, Q_{c})를 추출합니다. MLP를 태우면서 차원은 모두 d_{n}으로 맞춰지게 됩니다.
2.2 Auxiliary Caption Generation
우선 비디오 내 라벨링 되어있지 않은 구간에 대한 캡션을 추출하기 위해 사전학습된 Dense Video Captioning task의 모델 PDVC를 그대로 가져와 활용합니다. Dense Video Captioning 모델은 Event detection + Caption generation을 순서대로 진행합니다. 즉 캡셔닝 할만한 구간을 먼저 찾고 찾은 각 구간에 대해 캡션을 만들어내는 것이죠. PDVC 모델에 비디오를 입력하면 E = \{s_{i}, t_{i}, c_{i}^{s}, c_{i}^{p}\}_{i=1}^{M}을 얻을 수 있게 됩니다. 여기서 각각의 출력은문장, 해당 문장의 구간, 문장의 confidence score, 구간의 confidence score입니다.
이렇게 얻은 집합 E를 그대로 학습에 활용하면 앞서 Introduction에서 살펴본 그림 2와 같이 성능 하락을 불러올 수 있습니다. 이를 방지하고자 신뢰도 있는 캡션 구간만을 걸러내고, GT와 겹치는 부분을 최대한 배제해야 합니다. 저자는 위 목적을 달성하고자 Non-Auxiliry Caption Suppression (NACS) 알고리즘을 제안합니다. (아래 알고리즘 1)

알고리즘은 우선 문장과 구간을 담은 e_{i}의 집합 \mathcal{E}, 아래 수식 1에 따른 confidence score의 집합 \mathcal{C}, GT의 구간 정보를 담은 집합 \mathcal{F}를 입력받습니다. 정제된 구간, 즉 실제 학습에 활용할 캡션-구간의 집합 \mathcal{U}를 만들어내는 것이 목적입니다.
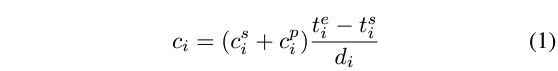
위 수식 1은 confidence score 집합 \mathcal{C}의 원소를 계산하는 수식인데, 기존 캡셔닝 모델에서 얻은 confidence score 2와 전체 비디오 길이 d_{i}에 대한 구간의 길이 비율 고려해주는 것을 볼 수 있습니다. 캡셔닝 모델이 내뱉은 구간 길이가 길수록 높은 점수를 주고 있습니다. 기존 방법론의 scoring 방식을 따른 것으로 보입니다.
가장 높은 score를 갖는 캡션 및 구간 인덱스 m으로 두고, NMS와 동일하게 해당 인덱스의 구간 e_{m}을 출력할 집합 \mathcal{U}에 포함시키고 원래 있던 구간과 점수는 각각 \mathcal{E}, \mathcal{C}에서 삭제해줍니다. 이후 GT 구간으로 초기화되어있던 집합 \mathcal{F}에 timestamp t_{m}을 추가해주고 \mathcal{E}에 남아있는 모든 구간은 GT와의 IoU가 클수록 가우시안 분포 기반의 낮은 점수를 갖도록 갱신해줍니다. GT와 크게 겹칠수록 낮은 score를 할당하여 걸러내어지도록 조정해주는 것이죠.
이 과정은 \mathcal{E}가 공집합이 되거나 \mathcal{U}의 원소 개수가 사전 정의한 캡션 구간의 개수 l_{c}와 일치할 때까지 반복합니다. 위와 같은 방식을 통해 학습에 활용할 캡션 구간이 신뢰할 수 있으며 최대한 GT와 겹치지 않도록 만들어 주는 것입니다.
위 NACS 알고리즘을 거쳐 얻은 l_{c}개의 캡션 구간에 대해, 2D-TAN 방법론을 따라 2D temporal map F_{t} \in{} \mathbb{R}^{l_{c} \times{} N_{v} \times{} N_{v}}를 만들어 줍니다. 만약 특정 캡션의 구간이 (3, 10)이라면, N_{v} \times{} N_{v}차원에 대해 (0, 5) 위치의 원소에는 (0, 5)와 캡션 구간 (3, 10)의 temporal IoU인 0.2가 들어가게 됩니다. 2D Map의 (3, 10) 좌표 원소는 1이 되겠죠.
2.3 Caption Guided Attention (CGA)
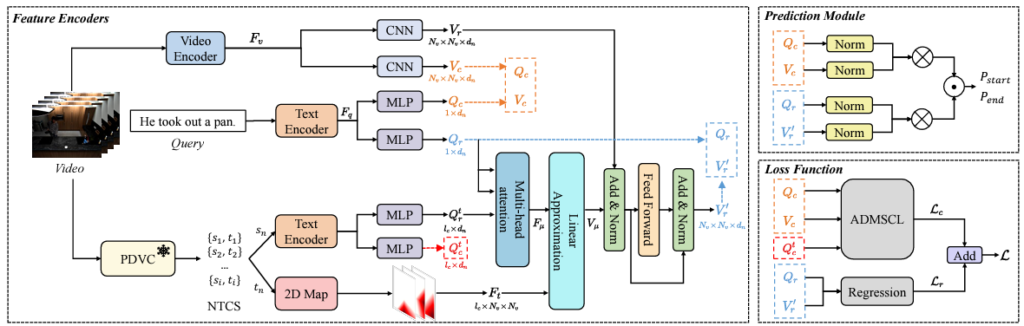
위 그림 3은 ACNet의 전체 프레임워크입니다. 우선 비디오와 텍스트 쿼리의 feature 추출, 그리고 PDVC 모델로 얻은 캡션의 전처리 및 2D Map F_{t} 생성까지 살펴보았습니다. CGA 모듈은 그림 3에서 V_{r}, Q_{r}, Q_{r}^{t}가 관여하는 cross-attention 연산에 해당하며, 여기서 Q_{r}^{t}는 캡셔닝 모델로부터 얻은 캡션(텍스트)을 의미합니다.
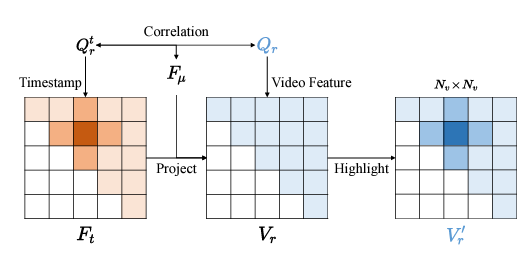
CGA 모듈의 목적은 우선 추출한 캡션과 GT 텍스트 쿼리 간 관계를 모델링하고, 이 정보를 비디오 feature에 주입하여 enhance된 비디오 feature V'_{r}을 추출하는 것입니다. 이 연산은 그림 4와 같으며 한 단계씩 설명드리겠습니다. 위 그림 3에서는 연두색 상자에 Linear Approximation이라 적혀있는데, 이는 23년도 버전으로 현 방법론에서는 단순한 Linear projection이라고 이해하시면 됩니다.
먼저 아래 수식 (2)와 같이 캡션과 기존 GT 텍스트 쿼리 간 관계 F_{\mu{}}를 모델링합니다. 대단한 연산은 아니고, 단순한 cross-attention 연산을 의미합니다. 이후 아래 수식 (5)와 같이 아까 추출한 2D Map F_{t}에 matrix multiplication을 수행해 V_{\mu{}}를 얻어줍니다. 마지막으로 수식 (6)과 같이 원본 비디오 feature V_{r}에 V_{\mu{}}를 더하고 FC-ReLU-FC를 태워 캡션과 텍스트 쿼리의 상호작용 정보를 담은 enhanced video feature V'_{r}을 얻어줍니다.
이렇게 얻은 V'_{r}을 만드는 과정에서 캡션이 텍스트 쿼리와 어떤 관계를 갖는지, 즉 도움을 줄 수 있는 관계인지 살펴보게 되었고 이를 실제 GT 구간 찾기에 보조적으로 사용하게 되는 것입니다. 이후 실질적으로 이 feature는 구간 regression 학습에 활용됩니다.
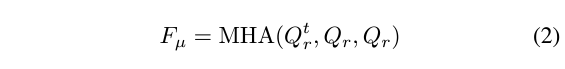
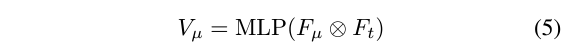
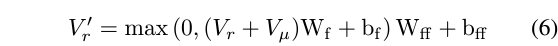
2.4 Asymmetric Cross-modal Contrastive Learning (ACCL)
앞서 구간 regression을 위한 feature를 만들었다면, 여기서는 캡션을 활용한 contrastive learning을 수행합니다. 기존 cross-modal contrastive learning에선 라벨링되어있는 GT 구간을 활용해 positive와 negative를 지정하여 비디오와 텍스트 feature 간 contrastive learning을 수행하였습니다. 다만 캡셔닝 모델이 만들어낸 구간은 사실 완전히 신뢰하기에 어려움이 있기에 그 부분을 고려해 positive, negative set을 기존과 다르게 조정해줍니다.
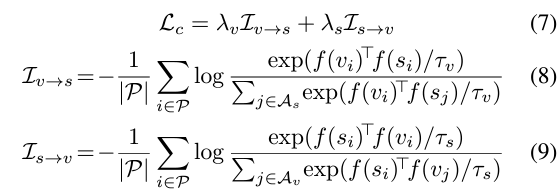
일단 수식 (7), (8), (9)에 제안하는 ACCL 과정이 나타나있습니다. video와 sentence 간 유사도를 조정해주고 있는데, 이 수식까지만 봐서는 제안하는 asymmetric 성질이 어디에서 오는지 알 수 없습니다. 이를 이해하기 위해서는 \mathcal{P}, \mathcal{A}_{s}, \mathcal{A}_{v}가 어떻게 정의되는지 살펴봐야 합니다. 총 2가지 관점에서의 비대칭성이 존재하는데 이는 아래 그림 5와 함께 설명드리겠습니다.
아래 그림 5에서 \mathcal{G}, \mathcal{D}는 각각 GT와 캡셔닝 모델의 moment-sentence pair를 의미합니다. 그림 5에서 왼쪽 절반이 기존의 contrastive learning이고, 오른쪽 절반이 저자가 제안하는 ACCL에 해당합니다.
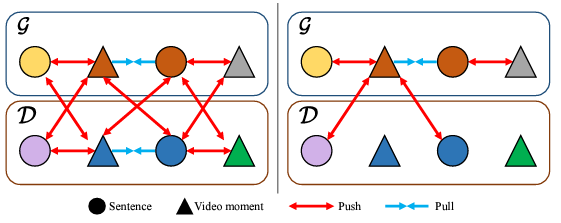
Asymmetry of Positive Pairs and Negative Pairs
우선 기존 contrastive learning과 같다면 캡셔닝 모델로부터 얻은 moment-sentence pair도 GT 쌍과 동등하게 하나의 sample로서 당길 수 있습니다. 그러나 초반부터 계속 언급했듯 캡셔닝 모델이 내뱉은 캡션과 이에 상응하는 구간은 학습까지 하기에는 신뢰도가 떨어지는 상황입니다. 그렇기 때문에 \mathcal{P} = \mathcal{G}, 즉 Positive set은 GT에서만 구축해줍니다. GT와 GT끼리는 유사도가 커지지만 GT와 캡션, 캡션과 캡션끼리는 유사도를 크게 만들지 않는다는 의미입니다.
Asymmetry of Negative pairs in Dual Matching
두 번째 비대칭성은, GT 구간은 캡션과 멀어지도록 학습하지만, 캡션의 구간은 GT 문장과 멀어지도록 학습하지 않는다는 것입니다. 이게 굉장히 말장난같고 헷갈리는데, 그림 5에서 갈색 세모는 보라색, 파란색 동그라미와 멀어지지만 파란색 세모는 유사도 학습을 하지 않는 포인트를 의미합니다. 이렇게 한 이유는 캡셔닝 모델이 기존의 GT 라벨을 고려하지 않고 예측을 내뱉기 때문에, 아무리 NACS 알고리즘을 수행했다고 해도 GT와 캡셔닝 모델의 구간은 겹칠 수도 있기 때문입니다. 즉 캡셔닝 모델이 예측한 구간이 GT 문장과 겹칠 수도 있기에 negative로 두면 안된다는 의미입니다.
사실 첫 번째 비대칭성은 이해가 가는데, 이 부분은 잘 이해가 가지 않습니다. 같은 논리대로라면 GT의 구간과 캡셔닝 모델의 문장도 밀면 안되는 것 같은데,, 완전히 납득되지는 않지만 이러한 방식을 채택했다고 합니다.
여기까지가 학습의 끝이고, 이후 학습은 Regression을 위한 BCE Loss와 방금 설명드린 Contrastive loss로 이루어집니다. 이후 추론은 비디오-텍스트 feature 간 유사도를 각 branch에서 뽑고 둘을 fusion해 수행되는데, 이에 대해서는 질문 주시면 답변드리도록 하겠습니다.
3. Experiments
3.1 Datasets and Evaluation
평가는 ActivityNet Captions, TACoS에 대해 진행되었습니다. 보통 최근 방법론들은 QVHighlights, 예전 방법론들은 Charades-STA 데이터셋을 함께 리포팅하는데 본 논문은 2개에 대해서만 벤치마킹이 진행되었습니다. 평가지표는 R@n, IoU=m으로, 예측 구간들의 confidence score를 정렬했을 때 상위 n개를 보고, GT와 m 이상의 IoU를 갖는 TP로 쳤을 때의 Recall 값을 의미합니다.
3.2 Comparison with State-of-the-art Methods
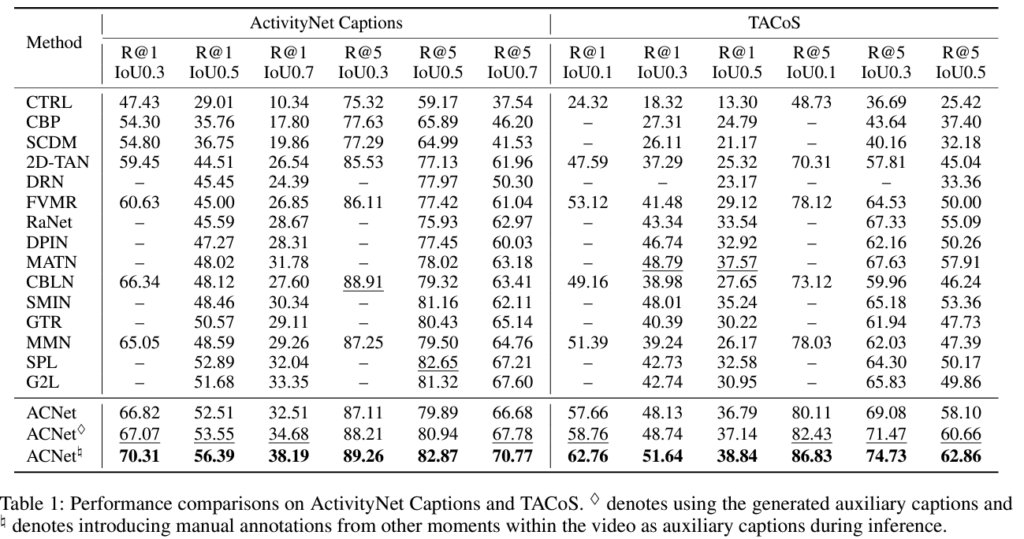
위 표 1은 ActivityNet Captions, TACoS 데이터셋에 대한 벤치마크 성능입니다. 우선 24년도 논문이 23년도 중순에 제출됨을 감안해도 23년도에 publish된 논문이 없어 좀 아쉽습니다. 우선 표 1에 ACNet이 총 3개 존재하는데, 이게 지금 첨부드린 표 1의 캡션을 제외하고는 본문에 아무런 설명이 없습니다. 캡션만 읽어보았을 때는 각 주석이 붙음에 따라 정확히 어떠한 차이가 있다는 것인지 알 수가 없었습니다. 원래 ACNet이라는게 캡셔닝 모델을 가져와 추가 캡션을 활용하는 것이기에 마름모 표시는 캡션을 사용했다는 표시가 정확히 어떤 차이를 의미하는 것인지 잘 파악하기 어려웠습니다.. 또한 #과 같은 표시는 inference 때 manual annotation을 가져왔다는데 다른 표에서의 ablation 성능이 다 # 모델의 성능을 best로 하고 있어, 이게 오라클 실험도 아닌 것같고 정확히 이해하기가 어려웠습니다.. 또한 분석도 다른 방법론들보다 추가적인 signal을 활용하고 있어 큰 성능 향상을 보였다고 이야기 하고있습니다.
아무튼 제가 생각했을 때 이 표에서 얻어갈 수 있는 것은 ANet과 TACoS 데이터셋에서의 성능 향상 폭 차이입니다. ANet에서는 향상 폭이 작지만 TACoS에선 굉장히 큰데, 왜 이런 현상이 발생하는지에 대해 각 데이터셋의 비디오에 대한 annotation 비율 통계량을 살펴보면 좋을 것 같습니다.
사실 리뷰를 맨 처음 시작할 때 AAAI임에도 불구하고 신뢰도가 좀 떨어진다고 말씀드린 이유는, arXiv에 올라와있는 23년도 1월 버전은 지금 버전과 Method가 아예 다름에도 불구하고 그 때 버전과 현재 버전의 표 1 성능이 소수점 하나 차이없이 동일하기 때문입니다. 방법론이 변했는데 성능이 완전 동일하다는 것이 그리 믿을만한 논문은 아니라고 생각합니다..
3.3 Ablation Study
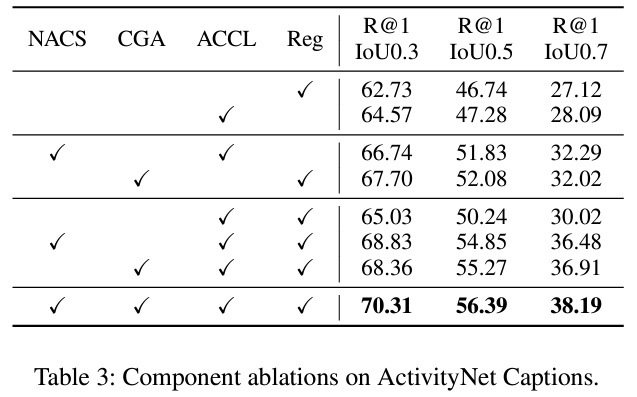
위 표 3은 ACNet의 모듈별 ablation 성능입니다. NACS는 맨 처음 설명드린 일종의 NMS 알고리즘, CGA는 cross-attention 모듈을 의미합니다. 마지막 2개인 ACCL과 Reg는 각각 contrastive learning branch와 regression branch로, 가장 기본이 되는 모듈을 의미합니다. 1, 2행의 single branch 상황에서의 성능을 보여주고 있습니다. 이후 6, 7행에서 볼 수 있듯 각 branch에 NACS와 CGA를 각각 적용한 뒤 함께 학습하면 성능이 크게 오르는 것을 볼 수 있습니다. 사실 커다란 분석은 없고 각 모듈을 적용함에 따라 성능이 오르는 점을 보여주고 있습니다.
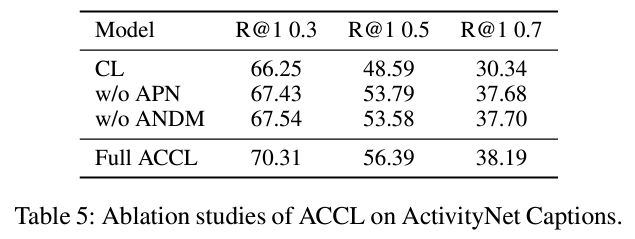
표 5는 Contrastive learning 수행 시 비대칭성에 관련된 ablation 실험입니다. APN과 ANDM은 2.4절에서 설명드린 비대칭성 순서대로입니다. 우선 아무 조건도 고려하지 않은 일반 Contrastive Learning의 경우 성능이 많이 떨어지는데, 확실히 캡셔닝 모델의 구간과 텍스트 문장이 마냥 믿기에는 어렵다는 점을 보여줍니다. 캡션을 포함하는 학습만 떼어줘도 높은 IoU 기준에서 성능이 굉장히 많이 향상하는 것을 볼 수 있습니다. 사실 이 실험에서 대단하다고 생각하는 점은 어떠한 아이디어를 붙였을 때 정확히 어떤 점이 성능 악화를 일으켰는지 분석하고 그 지점을 보완할 수 있는 방식을 만들어 냈다는 것이었습니다.
4. Conclusion
사실 읽으면서 notation도 갑자기 \mu{}가 등장하는 등 꽤 난잡하여 아카이브 버전을 좀 뒤져보게 되었는데, 방법론이 바뀌었음에도 성능이 과거 버전과 동일하고 분석적 측면에서 새롭게 볼만한 점들이 부족하여 AAAI임에도 굉장히 아쉬움이 남는 논문이었습니다. 더구나 제가 보고 있는 방향성과 동일한 관점이라 흥미를 가지고 읽기 시작했는데 조금은 실망스러움이 남게 되었습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요. 좋은 리뷰 감사합니다 !
최근 DETR 기반 방법론들이 많이 연구되고 있는데, 본 방법론이 예전 방식인 2D map을 사용하는 이유에 대한 언급이 있는지 궁금합니다. 또 이 2D map을 사용했을 경우보다 DETR을 사용했을 경우 단순 성능이외에 어떤 이점이 더 있는건가요 ?
또, 저자가 제안한 Non-Auxiliary Caption Suppression 알고리즘이 문장 구간을 담은 e의 집합 E가 공집합이 되거나 U의 원소 개수가 사전정의한 캡션 구간의 개수와 일치할 때까지 반복하는데, 단순 E가 다 비워질때까지가 아닌 사전에 제한 길이를 걸어둔 이유가 궁금합니다.
방법론이 변했는데 소수점 하나 차이 없이 동일한 성능을 리포팅 한 점은 신기하네욤 ㅇㅁㅇ