오늘 소개해드릴 논문은 Novel Class에 대한 Feature의 분포 학습을 통해 Few-shot Learning 성능을 개선시킨 논문입니다. 그럼 논문 소개를 시작해보겠습니다.
소개

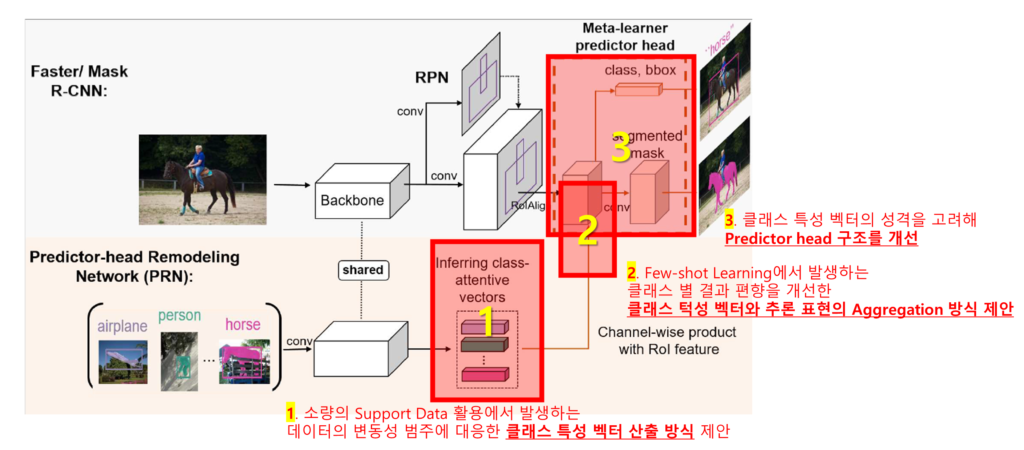
소개하는 논문은 Few-Shot Object Detection(FSOD)문제를 다루고 있습니다. FSOD 분야의 기본적인 아키텍쳐를 소개하기 위해 해당 분야의 기본 구조를 잘 나타내고, 논문에서도 Baseline 모델로 소개된 Meta R-CNN[1]의 구조를 [그림1]을 통해 살펴보겠습니다. Meta R-CNN에서는 새로운 클래스에 대한 Support Data로 class-attentive vectors를 생성합니다(아래, 주황색 영역). 해당 벡터를 통해 추론 시에 특정 클래스로 예측하려면 feature의 어느 채널에 집중해야 하는지 명시함으로서, 간단한 가중치의 변환으로 Base class로 학습한 backbone의 표현력을 novel class에 대한 예측을 위해 활용하게 됩니다. 즉 novel class에 대한 적은 수의 support data를 활용하여 base data에 대한 표현력을 변환할 수 있는 벡터들(class-attentive vectors)을 클래스 별로 생성하고, 이를 활용해 추론 데이터의 backbone 출력값에 앞서 생성한 가중치 변환을 통해 생성한 최종 벡터에서 regression과 classification(위, 파란색 영역의 점선 박스)을 수행하는것이 일반적인 FSOD가 문제를 해결하는 방법입니다.
본 논문은 위의 구조에서 support data를 활용한 클래스 특성 벡터(그림1의 class-attentive vectors)를 생성하는 방법과, 클래스 특성 벡터를 추론 데이터의 출력값에 결합하는 방식을 새롭게 하였으며, 클래스 특성 벡터의 성격을 고려하여 최종 predictor head의 추론 방식을 달리하였습니다. 즉, 기존 방법론인 [그림1] 대비 해당 논문의 제안을 정리하면 [그림2]와 같습니다. 그럼 제안한 방법의 구현이 어떻게 되었는지 이어서 소개하겠습니다.
방법론
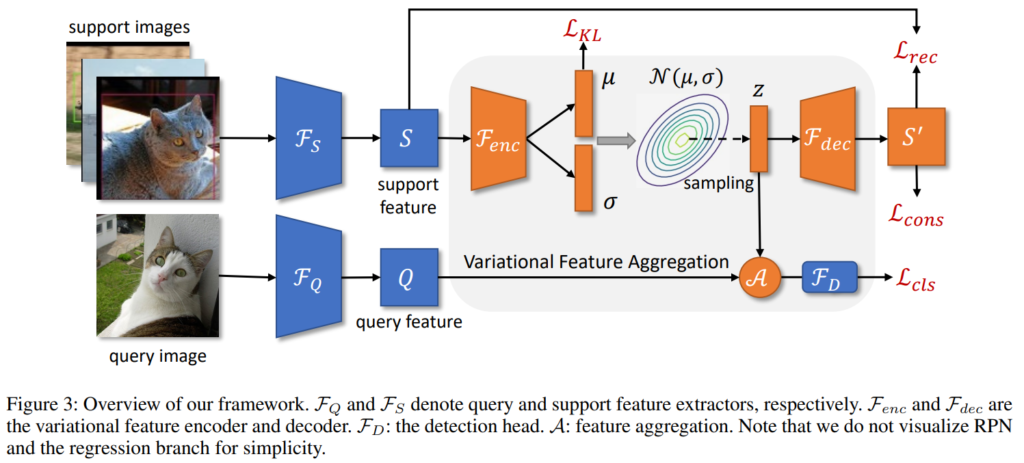
위의 [그림3]은 제안된 방법론의 전체 구조입니다. 본 논문에서 가장 중요한 contribution은 새롭게 제안한 클래스 특성 벡터를 생성하는 방법인데요, [그림3]에서도 회색 박스로 하이라이트 된 부분입니다. 본 리뷰에서도 논문이 가장 핵심으로 제안한 클래스 특성 벡터 생성 방식에 대해 먼저 다루어보겠습니다.
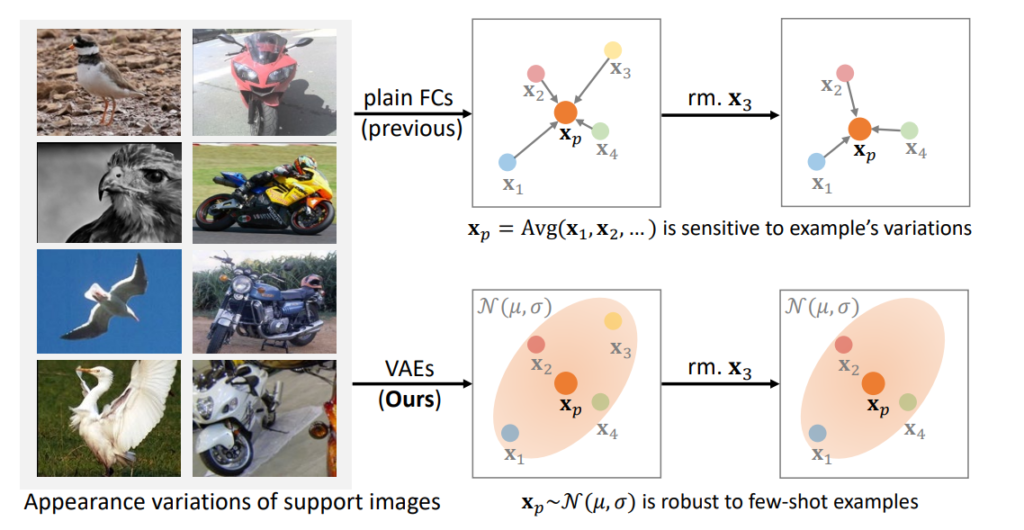
[그림4]는 논문의 overview 이미지 입니다. 기존 방법론에서는 [그림4]의 위처럼, Support image의 임베딩 feature 평균을 클래스 특성 벡터로 사용했습니다. 한편, Few-shot learing에서는 소량의 Support image를 활용하기 때문에, 평균을 통해 클래스를 대표하는 특성을 구하는 방식은 Support image의 구성에 영향을 크게 받았습니다. 예를 들어 그림의 우측처럼 노란색 데이터(x3)가 Support image에서 빠진다고 가정하면 클래스 특성 점이 표현 공간내에 위치 변동이 발생합니다. 그러나 제안하는 방식은 분포를 고려한 클래스 대표 선출방법을 적용하여, 노란색 데이터(x3)가 제거된다고 해도 기존에 산출했던 클래스 대표의 위치에 큰 변동이 발생하지 않는것이 장점이라고 합니다.
즉, 기존 방법은 Support image의 평균을 통해 클래스를 대표하는 특성 벡터를 산출했다면, 본 논문에서는 Support image를 통해 전체 데이터의 분포를 예측해서, 분포에서 특성 벡터를 산출하였습니다. 이렇게 추가적인 절차를 적용하여 Support image 구성 변화에도 안정성 있는 대표 특성을 산출하는 방법을 제시하였습니다.
해당 방법을 설계하기 위해 논문은 모든 클래스가 표현 공간 내에서 N(0, I)라는 다변량 정규분포의 분포를 띤다는 가정을 적용합니다. 즉, 클래스 특성 벡터 설계에서 Support image의 feature representation 뿐 만 아니라 전체 데이터의 분포라는 정보를 추가적으로 사용하는 것이죠. 이러한 가정은 variational feature learning이라는 분포기반의 feature 학습 방법 연구에서 주로 사용되는 가정이라고 합니다. 즉, 제공된 support image가 N(0, I)라는 정규분포에서 샘플링된 데이터 중 일부라고 가정하고, 추론하려는 데이터의 분포q가 p=N(0, I)라는 목적에 가까워 지도록 분포를 학습합니다. 분포의 학습에서는 주로 평균(μ)과 분산(σ)을 예측하는 encoder를 활용하는데, 이는 [그림3]에서도 확인할 수 있습니다(주황색 인코더와 그 예측).
즉, 아키텍처는 support vector로 부터 분포 q를 예측하는 F_encoder를 구성하고, F_encoder 예측한 분포 q=N(μ, σ)에서 샘플링을 통해 생성한 벡터 z=μ+σ가 클래스 특성 벡터가 됩니다. 이때 F_encoder의 학습을 위해 support vector S와 z를 reconstruct 한 S'(이때, reconstruct를 위해 F_decoder 구조가 필요)가 동일한 클래스에 대한 벡터가 되도록 consistency loss(수식1)를 적용하며, S와 S’ 자체도 가까워지도록 L2 distance loss(수식2)를 적용합니다. 또한 예측 분포(q=N(μ, σ))가 목적 분포(p=N(0, I))와 같아지도록 KL loss(수식3)를 적용합니다.
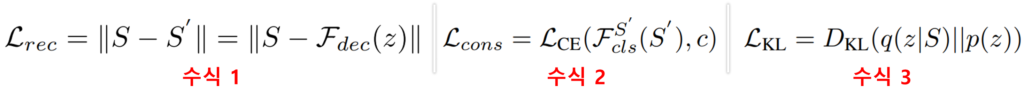
위의 방식으로 Support image를 통해 클래스에 대한 전체 데이터의 분포를 모사한 분포 q를 생성했습니다. 이제 q에서 샘플링을 통해 클래스 특성 벡터 z를 생성할 수 있습니다. 다음으로는 클래스 특성 벡터를 활용해 prediction head인 F_D(detection head, 그림3의 파란색 구조)를 학습하는 방식을 설명하겠습니다.
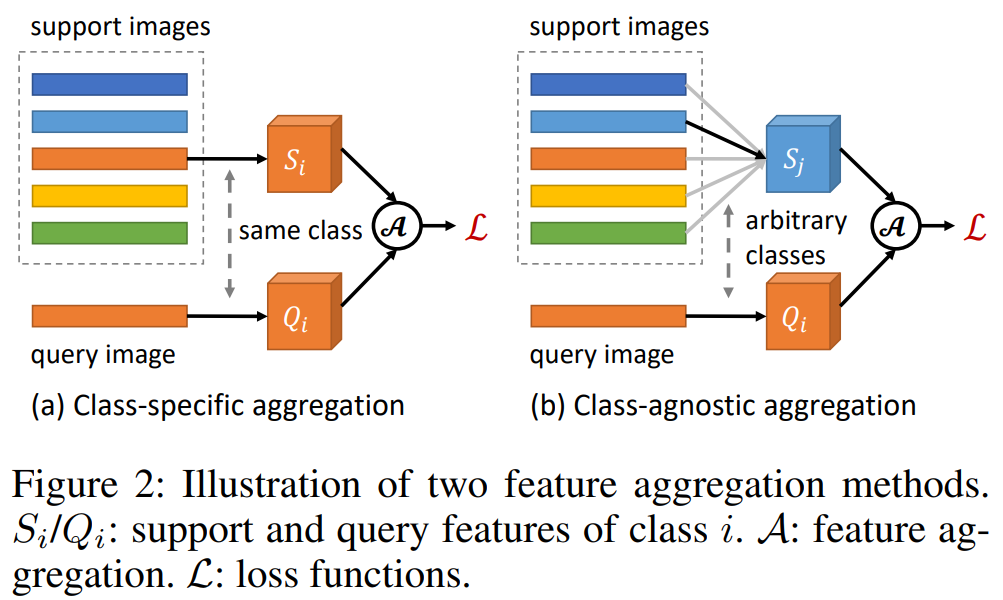
본 논문에서는 meta-learning 기반의 Few-shot learning(즉, 클래스 특성 벡터를 활용하는 학습) 구조에서 detection head(F_D)의 효과적인 학습을 위해 Class-agnostic aggregation (이하, CAA)를 제안합니다. 쿼리 Feature의 채널별 가중치 재편성을 위해 쿼리 이미지의 클래스에 해당하는 클래스 특성 벡터를 활용하는 class-specific aggregation (이하, CSA) 방식을 활용했습니다([그림 5]의 a). CSA 방식은 쿼리 이미지의 특징과 동일한 클래스의 지원 특징만을 결합하기에 F_D가 클래스 간 상호작용을 학습하는데 어려움이 있었습니다. 따라서 F_D가 기존에 학습했던 base 클래스에 치우친 예측을 개선할 수 없었으며 novel 클래스에 대한 예측 정확도가 떨어졌다고 합니다. 이러한 현상에 대한 실험 결과는 실험 파트의 [그림8]에서 확인할 수 있습니다
반면, 제안하는 CAA는 클래스에 상관없이 쿼리와 렌덤으로 선정한 클래스 특징 벡터의 결합(aggregation, channel-wise product operation)으로 채널별 가중치를 재편성하여 F_D의 학습 입력으로 하였고, 이러한 학습 방식은 클래스 간의 정보 상호작용을 가능하게 하여 class-agnostic한 학습을 유도하므로서 Base class에 대한 편향을 해결하고 novel class에 대한 예측 개선을 하였다고 합니다. 즉, 제안하는 방식으로 클래스간 상호작용을 통해 특정 클래스에 치중된 표현력을 습하던 detection head(F_D)가 조금 더 일반적인 표현을 학습하게 개선했습니다. 예제로 설명하자면, 기존에는 3번째 체널이 강하게 활성화 되면 강아지로 예측했지만, 이러한 치중된 특성을 완화시켜 입력값의 전체적인 표현을 고려하는 detection head(F_D)를 설계한 것입니다.
이처럼 본 논문은 클래스 특성벡터와 쿼리(추론이미지)값에을 aggregation 하는 새로운 방법을 제시하였으며 다른 클래스(j)의 특성 벡터로 활성화 되더라도 쿼리에 해당하는 클래스(i)로 예측하도록 학습합니다.

마지막으로 논문이 제안한 구조는 Classification-Regression Decoupling(CRD)입니다. 이는 클래스 특성벡터를 활용한 기존 방법에서 놓쳤던 문제를 간단한 방법으로 해결했습니다. 기존의 prediction head는 classification과 regression의 두가지의 태스크를 위해서 공통된 feature extractor인 F_share와 classification을 위한 F_cls, regression을 위한 F_reg로 구성됩니다([그림6] 참조).
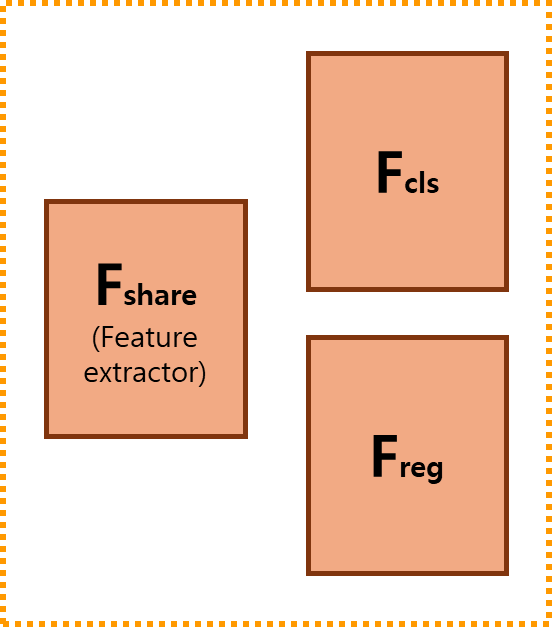
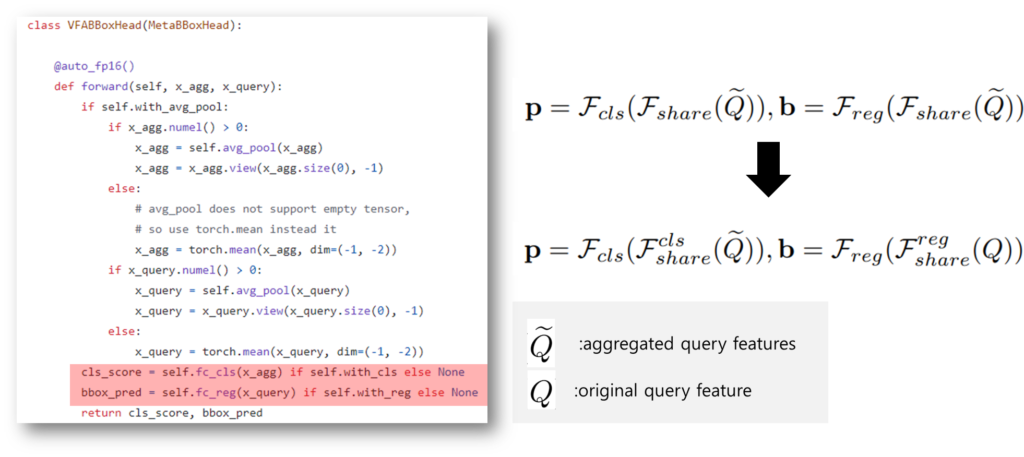
한편, 기존의 meta learning 기반의 Few-shot learning에서는 쿼리의 feature에 클래스 특성 벡터를 결합한 최종 feature를 활용하여 prediction head의 입력으로 사용했습니다. 이는 클래스 특성 벡터가 갖는 성격을 고려하지 않은 구조인데요, 여기서 클래스 특징 벡터는 class 분류에 사용되는 시각적 정보를 주로 의미하며, 따라서 translation-invariant feature로 분류됩니다. 즉, 클래스 특성 벡터 자체는 이미지가 우측으로 5픽셀 움직여도 동일하게 하나의 클래스로 구분되는, 변환에 불변한 특징이라는 성격을 갖습니다. 이러한 특징은 변환에 불변한 특징을 캡쳐하도록 학습하는 F_cls에는 영향을 미치지 않을 수 있습니다. 그러나 F_reg는 입력에서 부터 변환에 민감한 translation-covariant 특징을 캡쳐해야 하기 때문에(bbox의 location, 픽셀 변화 등 이동에 민감) 변환에 불변한 특징에 집중하도록 강화된 입력값으로 예측을 수행하도록 학습하는 것은 성능에 악영향을 미칠 수 있습니다. 이렇게 meta-learning based few-shot learning에서 기존에 놓쳤던 부분에 대해 지적하며 저자는 prediction head에서 classification과 regression 수행 시에 입력값을 분리하도록 설계했습니다. 구현은 [그림7]의 좌측처럼 단순하게 입력을 다르게 한것이며, 동일한 구조에 classification 수행시에는 입력 쿼리 feature에 클래스 특성 벡터를 aggregation(channel-wise product operation 수행)한 feature Q^~을, regression 수행시에는 입력 쿼리의 원본 feature인 Q를 입력으로 하였습니다.
실험
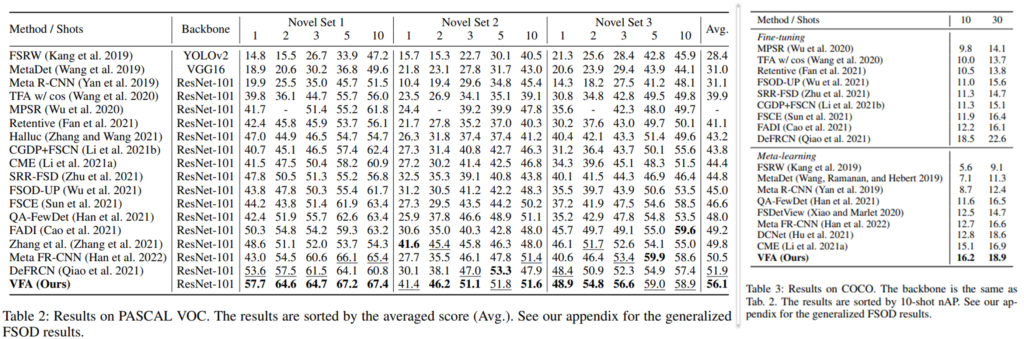
실험은 State-of-the-Art(SOTA)와의 비교를 통해 제안된 방법론의 성능적 우수함을 증명하였으며, 제안한 모듈 별 Ablation 실험으로 구성되었습니다. 먼저 SOTA와의 비교를 위해서는 Few-shot learing에서 많이 사용되는 데이터인 Pascal VOC와 COCO로 진행되었으며 Pascal VOC는 총 20개의 클래스 중 랜덤으로 5개의 클래스를 학습에 사용하지 않는 Novel class로 구성하였고, 남은 15개의 클래스를 Base class로 학습해 성능을 리포팅 하였습니다. Novel Set 1/2/3은 Novel 클래스를 서로 다르게 구성한 3가지 세팅에서의 실험이며, Support set을 1장/2장/3장/5장/10장으로 하여 성능을 리포팅하였습니다. 또한 COCO 데이터에서는 80개의 클래스 중 60개의 클래스를 Base class로, 20개의 클래스를 Nove class로 구성하였고, Support set을 10장/30장으로 하여 Few-shot learning 실험을 한 결과를 리포팅 했습니다. 실험 결과를 통해 제안한 VFA가 모든 세팅에서 SOTA 대비 가장 좋은 성능을 보이거나(16개 세팅 중 13개), 적어도 두번째로 좋은 성능(16개의 세팅 중 3개)보임으로서 성능적 우수성을 보였습니다.
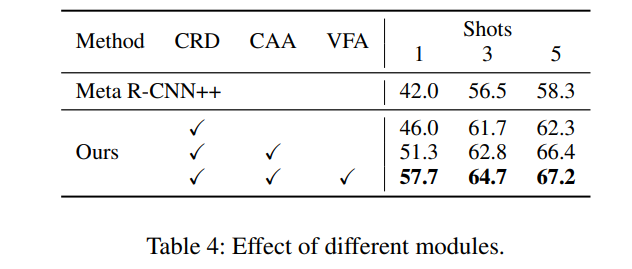
다음으로는 제안하는 모듈의 효과를 보여주는 ablation 실험입니다. VFA 방법 뿐 만 아니라 CAA(Class-agnostic aggregation)방법과 CRD(Classification-Regression Decoupling)가 모두 적용시에 확실한 성능 개선을 보였습니다. Ablation study의 실험은 PASCAL VOC에서 실행되었으며, Support set을 1장/3장/5장으로 한 실험 결과를 리포팅했습니다.
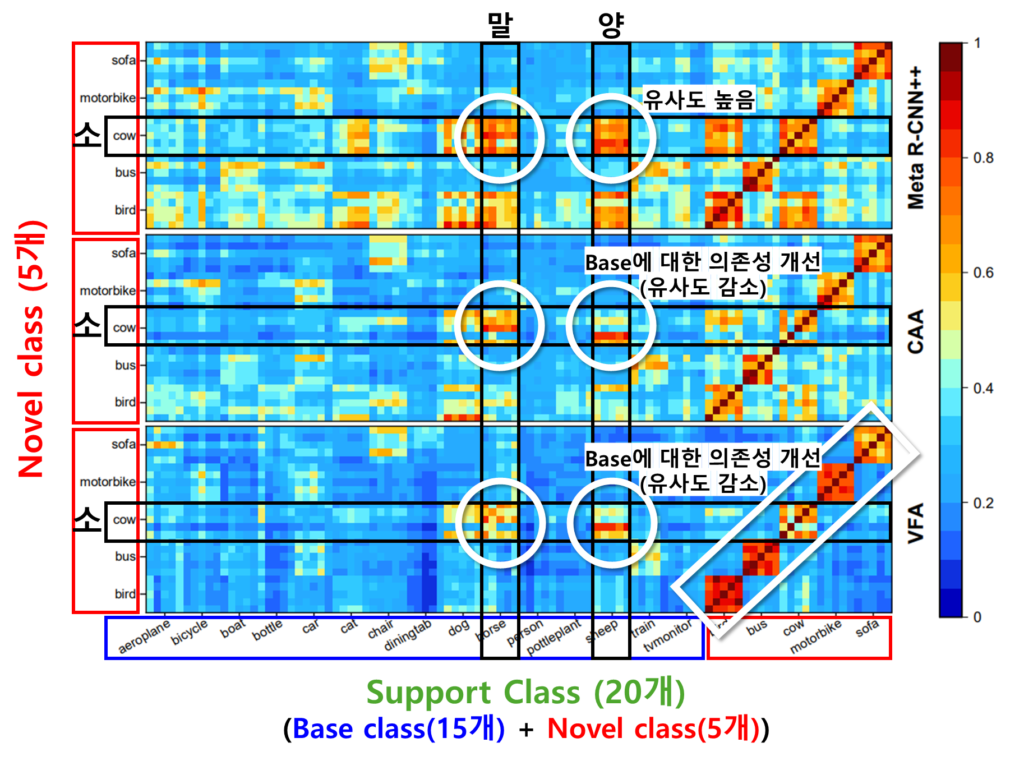
[그림8]은 마지막으로 소개드릴 정성적 분석 결과입니다. [그림8]은 앞서 언급했던 것 처럼 CAA 구조가 base class에 편향된 예측을 하는 기존 방법론을 개선했음을 보이는 실험입니다. CAA 를 적용하지 않은 1열의 Meta R-CNN++ 구조는 기존 방법론인 CSA 방식을 사용했을 때의 결과를 보여줍니다. 이 방식에서는 새로운 클래스와 기존 클래스 간의 유사도가 높아, 서로 다른 클래스들이 혼동되는 경향이 나타납니다. 예를 들어, Novel class인 소(cow)와 Base class인 양(sheep) 및 말(horse) 간의 유사도가 매우 높아 강하게 활성화 된것을 확인할 수 있습니다.
한편, 중간의 CAA 방법의 시각화 결과에서는 소와 양/말 간의 유사도를 감소되었음을 확인할 수 있습니다. 이를 통해 CAA 본래 설계 의도처럼 클래스에 구애받지 않는(Class-agnostic) 표현 학습을 통해 Base class 정보에 대한 의존성을 완화할 수 있음 을 예측할 수 있습니다.
마지막으로 하단의 시각화는 VFA 방식을 사용한 결과입니다. VFA는 CAA처럼 Base class에 대한 의존성을 개선했을 뿐 만 아니라, Support image의 변동성이 고려된 견고한 클래스 특성 벡터 설계를 통해, 서로 다른 클래스 간 유사도를 더욱 줄였음을 확인할 수 있습니다. VFA를 적용한 결과 CAA 대비 쿼리 클래스와 이에 해당하지 않는 클래스들 간의 유사도가 더욱 감소하였고, 정답 영역(3행 시각화의 흰색 네모박스 영역)에 강한 유사도(비교군 대비 더욱 붉음) 점수를 보임을 확인할 수 있습니다.
즉, CAA를 통해 Base class에 대한 표현 의존성을 줄였을 뿐 만 아니라, 견고한 클래스 특성 벡터 생성으로 클래스간의 분류도 더욱 잘 수행함을 시각적으로도 확인할 수 있었습니다.
참고문헌
[1] Meta R-CNN: Towards general solver for instance-level low-shot learning, ICCV2019
본 논문에서 제안한 요소들을 통해, 기존의 Few-shot Learning 연구들이 어떤 문제들을 고민하고 있었는지 알 수 있었습니다. 특히 본 논문에서는 meta-learning을 접목한 few-shot learning의 연구 흐름에서 클래스 특성 벡터의 산출 방식에서 어떤 고민을 하고있는지 알 수 있었습니다. 특히 저는 CAA 방법에서 다른 클래스의 특성 벡터로 attention 한것으로 학습을 확장한 것이 base class에 대한 표현 의존성을 해결한것이 인상깊었습니다. 이상으로 리뷰를 마치겠습니다 감사합니다.
좋은 리뷰 감사합니다.
몇 가지 질문 남기고 가겠습니다!
Q1. 해당 연구의 실험 세팅이 궁금합니다. few-shot 연구들에서는 사전 학습을 수행한 모델을 기반으로 추가적인 프레임워크를 구성하여 세팅하는 것이 일반적인 것 같아요. 해당 기법은 COCO에서 실험이 진행되는 것 같은데… 어떤 데이터셋으로 사전학습된 모델을 쓰는지 궁금해요. 그리고 epoch도 궁금해요.
OWOD처럼 평가 데이터 셋의 일부 클래스만 scratch로 학습하여 쓰는 걸까요?
Q2. VAE가 확률 분포 자체를 학습하는 기법이기는 하나… 일반적으로 큰 단점으로 학습 데이터가 많이 필요하고 노이즈 데이터에 예민한 것으로 알려져 왔습니다. support images가 적절하지 못하면 성능 하락이 클 것 같아요. 적절하지 못한 경우는 가려지거나, support images 내에 유사한 클래스가 존재하는 경우라고 보면 될 것 같아요. 이러한 문제가 있을 거라고 생각이 드는데도, 성능이 높은 것을 보니 이를 방지하는 무언가가 있는 것 같습니다. 연구원 님께서는 어떤 것이 이를 방지 하는 것이라 생각하시는지 궁금합니다.
좋은 리뷰 감사합니다.
전체 아키텍쳐 구조 (그림3) 에서 RPN 부분이 표현이 안된거같은데, 결국 저 구조에서 query feature vector F_Q 가 의미하는 바가 detector 쪽에서 RoIAlign에 의해 추출된 object box에 대한 feature 라고 생각하면 될까요?
사용되는 support image 는 실험 세팅에 따라 10/30장으로 사용하는 거 같은데, 이는 gt bbox에 대해 crop된 object-centric한 image 인가요? 아니면 그냥 일반적인 input image 인가요? 이에 따라 추출되는 support feature가 상당히 상이할 거 같아 질문드립니다.
안녕하세요 리뷰 읽어주셔서 감사합니다.
query feature vector는 말씀해주신 것처럼 최종 예측된 object bbox에 대한 feature 입니다.
다음으로 support image는 클래스 별로 n개(1~10)개를 사용합니다. 즉 class가 20개인 Pascal VOC의 경우 1 shot setting에서는 20개의 bounding box가, 10shot setting의 경우 200개의 bounding box가 support datasets으로 활용됩니다.
또한 support image은 모델 입력 시에 3채널 RGB 이미지에 GT mask(1채널, 이진마스크)가 결합되어 입력됩니다. 즉, 전체 이미지가 입력되며 GT 정보를 함께 입력합니다.
감사합니다.