오늘 리뷰할 논문은 Test-Time Adaptation과 Active Learning 을 결합한 Active Test-Time Adaptation (ATTA) 라는 분야를새롭게 제안한 논문입니다.
본 논문에서는 앞서 활발히 연구되고 있는 Test-Time Adaptation (TTA) 방법론이 크게 i) gaussian noise 와 같은 마이너한 domain shift 상황만을 다루며, ii) 방법론 설계 시 휴리스틱하고 실험적인 결과에만 의존하게 된다는 문제점이 있다고 주장합니다. 그리하여 TTA 에 active learning 을 결합한 ATTA 컨셉을 새롭게 제시합니다. 크게 2가지 핵심 사항을 짚고 Introduction으로 넘어가겠습니다.
- active learning 을 통해 test sample 일부를 labeling 한 후 TTA 를 수행하게 되면, test domain 전반적인 성능이 향상된다는 것을 이론적으로 입증
- TTA의 고질병 중 하나인 Catastrophic Forgetting 을 피하면서 ATTA 를 구현하기 위한 entropy balancing sample selectinon 기법 설계
1. Introduction
Distribution shift, out-of-distribution (OOD) 문제에 대한 해결을 위해 domain adaptation (DA), domain generalization (DG) 등과 같은 많은 연구들이 수행되고 있습니다. 해당 연구들은 집중적으로 수행되는 학습 단계를 통해 target domain 에 대한 일반화된 능력을 갖추게 됩니다. 하지만 resource 제한, 효율성 제한, 데이터의 privacy 이슈 등 실제 application관점에서 마주할 수 있는 제약 상황들에 대해서는 간과하고 있습니다.
조금 더 application 적인 접근을 고려한 방법론이 TTA 입니다. TTA는 크게 i) source data로 재학습하는 과정이 포함된 test-time training (TTT), 그리고 ii) source data에 대한 접근 없이 target domain으로 adaptation을 바로 수행하는 Fully TTA 이렇게 2가지로 나뉘어집니다.
하지만 대부분의 TTA 방법론은 리뷰 첫 문단에서 설명드렸다시피 gaussian noise 와 같은 마이너한 domain shift 상황만을 주로 다루며, 방법론 설계 시 휴리스틱하고 실험적인 결과에만 의존하게 된다는 문제점이 존재한다고 합니다. 그리하여 본 논문에서는 이론적 인사이트를 통해 test time에 마주하는 domain shift를 실시간으로 처리하는데에 중점을 둔 방법론을 설계하게 됩니다.
본 논문에서는 TTT보다 더 실용성 측면이 강한 Fully TTA를 메인으로 설정합니다. Fully TTA는 source data에 대한 접근 없이 gt가 없는 target data만을 사용하여 adaptation을 수행하는 분야이죠.
이전 연구 (Y. Lin et al., 2022) 에서 밝힌 바에 의하면, 추가적인 정보 없이 OOD generalization 능력을 얻는 것 자체가 이론적으로 불가능하다고 합니다. environment partisions 와 같은 추가적인 정보를 사용하는 방식도 이전에 존재하긴 했습니다만, 이를 얻기 위해서는 heavy한 pretraining 과정이 필요하게 되고 이는 효율성, 실시간성과 같은 TTA의 핵심 모토에 어긋난다고 본 논문에서는 언급합니다.
그리하여 저자들은 OOD generalization 능력을 얻기 위해 모델에게 추가적인 정보를 부여하고자 하였고, 이에 active learning 기법을 적용해서 target test sample 일부를 라벨링하는 과정을 TTA 파이프라인에 통합하게 됩니다. 그리고 이를 active test-time adaptation (ATTA) 라고 이름짓습니다. 직관적입니다.
ATTA 는 크게 2가지 챌린징한 문제점이 있다고 합니다.
우선 일반적인 TTA 방법론들에서도 자주 다뤄지는 catastrophic forgetting (CF) 입니다. CF 문제는 연속적으로(continual) adaptation을 수행하고 있는 모델이 source dataset과 이전 time에 마주한 target dataset 에 접근할 수 없기 때문에, 이전에 마주한 domain 에 대한 성능이 급락하는 현상을 의미합니다.
그리고 두번째 문제점은 active sample selection에 대한 실시간성 입니다. 효율성있는 TTA를 위해 active learning 알고리즘은 test (target) distribution에 대한 접근 없이 test data중 일부 버퍼에서 라벨링을 할 수 있는 값진 샘플 (informative samples) 을 선정해야 합니다. 해당 문장은 원문 첨부하겠습니다.
(Real-time active sample selection requires AL algorithms to select informative samples from a small buffer of streaming test data for annotation, without a complete view of the test distribution.)
2. The Active Test-Time Adaptation Formulation
ATTA 수행과정 속 모델은 adaptation 성능 향상을 핵심점으로 두고, 연속적으로 들어오는 unlabeled test batch에 대해 명시적 (human annotation) 또는 암시적 (self-supervised signals) 인 방식으로 label을 부여한 후 모델을 학습 (적응) 해 나갑니다. 이때 성능 향상에 가장 도움이 되는 test sample을 지속적으로 선정하는 것이 중요하겠죠.
그리고 real-world application 에서의 labeling cost를 고려하여 “budget” 이 설정됩니다. 모델은 이 budget의 distribution을 효과적으로 관리해야 하고, test 단계 전체에서 총 label requeust 수가 budget을 초과하지 않아야 합니다.
Definition을 위한 수식 정리를 하고 가겠습니다. source dtataset D_S=(x,y)_{|D_S|} 로 미리 pretrained 된 모델을 f(x;\phi), 이때의 초기 (t=0) 모델 파라미터를 \phi 라고 칭합니다. 그리고 t=1 이후 시점부터 ATTA 수행 시 입력으로 들어오는 unlabeled target data stream을 사용하여 초기 모델 파라미터 \phi를 \theta 로 업데이트 해 나갑니다 (\theta(0)=\phi). 이때 active learning algorithm ActAlg(\cdot)에 의해 test sample이 actively하게 선택되고, 라벨링이 수행되게 됩니다. 수식으로는 D_{te}(t)=ActAlg(U_{te}(t)) 입니다.
매 time t 마다 라벨링되어지는 labeled samples D_{te}(t)는 이후 ATTA training set D_{tr}(t) 에 반복적으로 통합되게 됩니다. 최종적으로 time step=t 일때 이전 단계의 최종 모델 \theta(t-1)을 \theta(t)로 update하게 되는데, 이때 D_{tr}(t) 을 사용하게 되는것이죠.
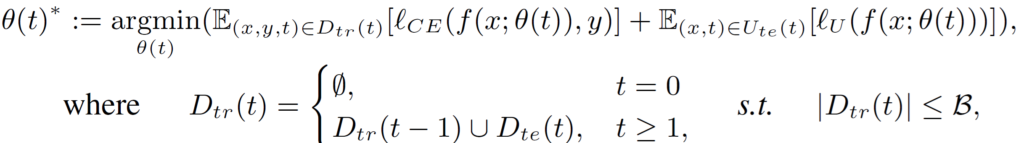
위 수식을 통해 모델 parameter \theta(t) 가 계속해서 update 되어지게 됩니다. active algorithm에 의해 선택되어 라벨링 되어진 samples 에 대해서는 cross-entropy loss l_{CE}를, 선택되지 못한 samples에 대해서는 unsupervised learning loss l_U가 계산되게 됩니다. 그리고 B는 budget 입니다.
3. An ATTA Algorithm
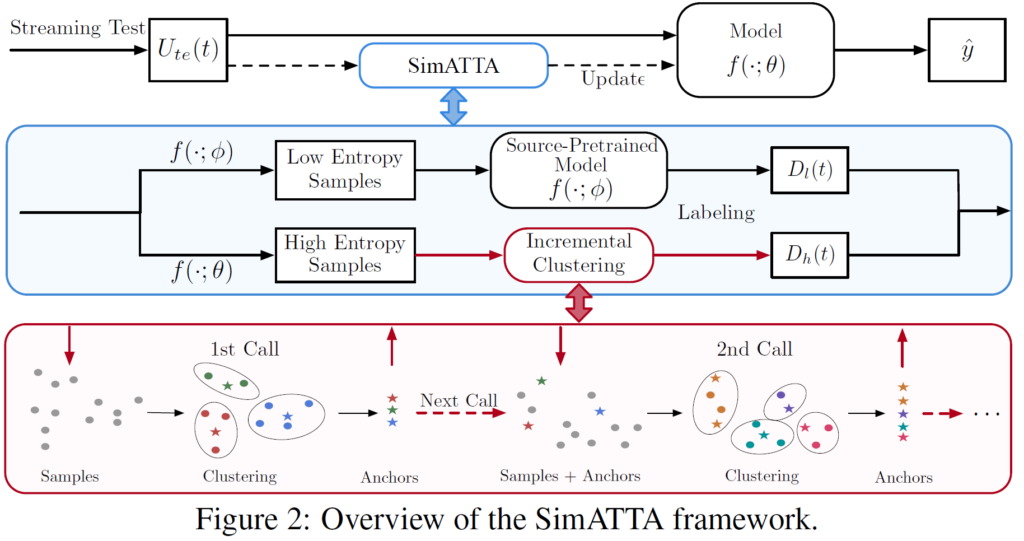
저자들이 설계한 SimATTA 프레임워크의 전체 흐름도입니다.
효과적인 active selection 수행을 위한 incremental clustering 기법, 그리고 catastrophic forgetting (CF) 방지를 위한 selective entropy minimization 기법이 이에 포함됩니다.
3.1. Algorithm Overview

source dataset으로 미리 pre-trained 된 모델이 있습니다.
test 단계에 입력으로 들어오는 test streaming data에 대해 active learning 기법으로 라벨링할 sample을 선택하고 labeled/unlabeled test sample을 통해 TTA를 수행하게 됩니다.
test time t 때 입력으로 들어오는 unlabeled target data U_{te}(t)를 특정 entropy threshold e_l, e_h를 기준으로 각각 low entropy samples U_l(t)와 high entropy samples U_h(t)로 나누게 됩니다. 위 전체 pipeline에서 파랑색 부분에 해당합니다. 이 중 low entropy samples U_l(t)에 대해서는 앞선 source pre-trained 모델의 예측을 사용하여 pseudo-labeling을 통해 labeled low-entropy datat D_l(t)로 만들게 됩니다.
(이에 대한 이론적 기반은 low-entropy sample 은 source와 유사하여 CF 문제를 완화할 수 있고, high-entropy sample 은 source와 분포가 다른 test distribution shift를 해결할 수 있는 정보가 풍부한 sample이라는 것입니다. 이에 대한 이론적 증명이 논문에 있긴 한데, 수식이 너무 복잡하여 제가 이해를 잘 하지 못해서 리뷰에 반영하지 못하였습니다.)
반면 high-entropy sample은 source와 상이한 data distribution의 데이터이기 때문에 source pre-trained 모델로 pseudo-labels를 예측하게 되면 정확도가 매우 부정확하게 됩니다.
그리고 만일 target data 전체에 대한 distribution 정보를 알고 있다면 좋겠지만, TTA의 특성 상 전체 test dataset으로의 접근이 불가능 하기 때문에 이러한 추가적인 정보 없이 실시간으로 sample selection을 수행해야 합니다. 이를 위해 incremental clustering sample selection 과정을 진행하고, 이를 통해 선택되는 sample들 끼리의 중복성을 줄임과 동시에 분포 coverage 를 증가시킬 수 있습니다. 해당 clustering 알고리즘은 다음 섹션에서 설명드리겠습니다.
3.2. Incremental Clustering
high-entropy samples 중에서 정보가 풍부한, informative samples를 고르기 위해 새롭게 제안한 continual clustering 기법입니다. 앞서 말씀드렸듯이 TTA의 특성 상 전체 test dataset에 대한 접근이 불가능합니다. 그렇기 때문에 제안하는 기법을 사용하여 현재 time step t 까지 봤던 데이터 분포에 대한 대표적인 (representative) samples를 저장하는 것이 핵심 목표입니다. 이를 위해 cluster 기법을 도입하여 이때까지 봤던 모든 distribution을 커버하는 동시에, 만약 새로운 distribution data가 등장했다면 이 또한 커버하기 위해 새로운 cluster를 추가하게 됩니다. 메모리 적으로 cluster budget이 제한되어 있기 때문에 무한하게 cluster를 만드는 것은 아니고, 기존 cluster와 병합이 되기도 합니다. clustering 을 위해 대표적으로 사용되는 K-Means 기법을 base clustering 기법으로 삼았다고 합니다. 알고리즘은 아래와 같습니다.

4. Experiment
실험은 아래와 같은 여러 research question 의 관점에서 대해 대응하는 식으로 설계하였다고 합니다.
RQ1: 기존 TTA 방법론이 domain distribution shift를 잘 해결하는지
RQ2: ATTA가 TTA 대비 효율적인지
RQ3: 제안하는 SimATTA 기법의 요소들이 어떻게 동작하는지
RQ4: ADA(atctive domain adaptation) 과 동등한 성능 달성이 가능한지
또한 실험에 사용한 dataset 종류는 아래와 같습니다.

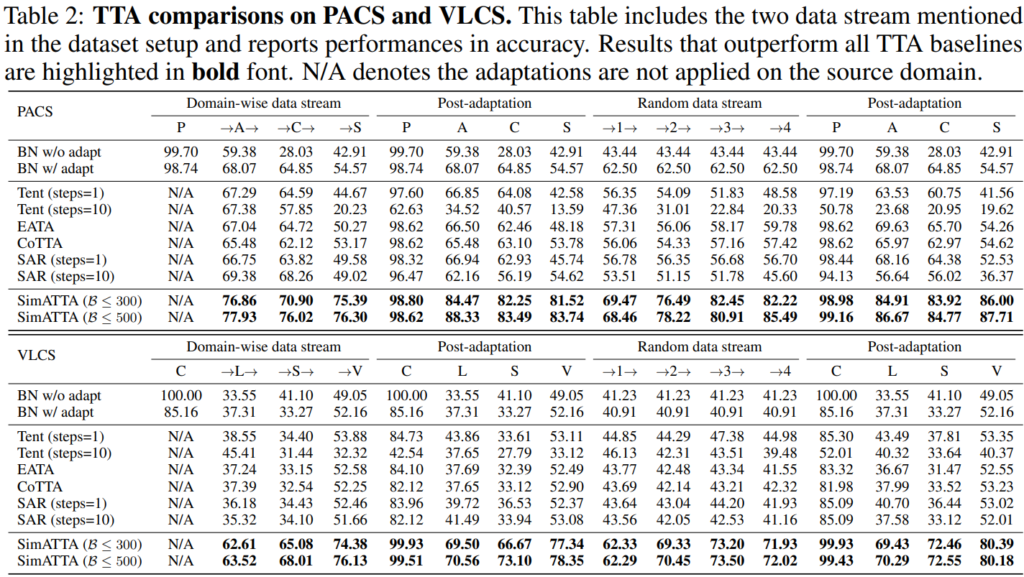
위는 PACS 데이터셋, 아래는 VLCS 데이터셋에 대한 실험입니다.
PASC는 각각 P: photos, A: art, C: cartoons, S: sketches 의 줄임말이고,
VLCS에서는 V: VOC2007, L: LabelMe, C: Caltech101, S: SUN09 데이터셋을 의미합니다.
특별한 기법을 사용하지 않고 오직 test batch에 대한 Batch Norm 통계값 (mean, var) 만 update 하는 BN w/ adapt 방법론을 기본 baseline이라고 보시면 됩니다. TENT의 경우 TTA 분야의 젤 첫 논문인데 TENT (steps=10)의 성능이 (steps=1)에 비해 처참합니다. 여기서 말하는 step이란 layer 가 update되는 횟수, 즉 backprop iteration의 횟수라고 보시면 됩니다. 1번->10번 update 를 하는 동안 모든 도메인들에서 성능이 급락하는것이 보이는 것으로 보아 이는 CF 가 해결해야될 문제 중 하나라는 것을 의미합니다. 앞선 RQ1 의 관점에서 봤을 때 기존 TTA 방법론이 CF 문제를 잘 해결하지 못한 것을 확인할 수 있네요.
이에 반해 저자들이 설계한 SimATTA 에서는 Budget을 300만 사용하고서도 앞선 방법론들의 성능을 큰 폭으로 능가한 것을 확인할 수 있네요. 물론 뭐 일반 TTA가 아닌 ATTA 방법론인것을 감안하고 봐야할것 같긴 합니다.
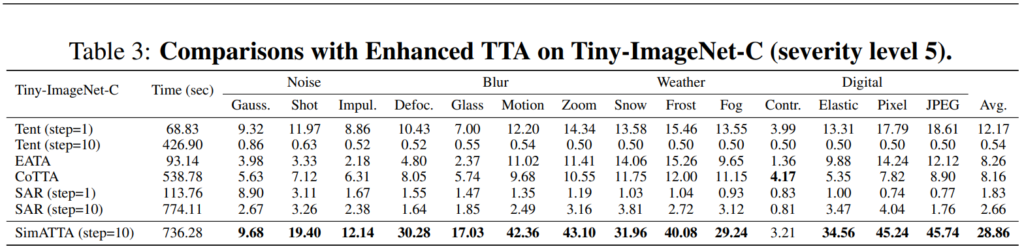
이를 의식했는지 위 Table 3의 실험에서는 TTA 방법론들에 대해서도 랜덤하게 test sample에 대한 라벨을 제공해준 후 fine–tuning 을 수행할 수 있게 합니다. 4,500개의 randomly selected labeled sample을 사용했다고 하구요, 저자들이 제안하는 SimATTA의 경우 4,000개의 budget을 사용했다고 합니다. 데이터셋은 Tiny-ImageNet-C 를 사용했구요.
TTA 방법론에 labeled sample을 부여했음에도 불구하고 SimATTA 거의 모든 domain shift 상황에 대해 압도하는 성능을 보이는 것을 확인할 수 있습니다. 이는 단순 random하게 label을 부여하는 것이 능사는 아니며, 저자들이 설계한 ATTA 기법이 active sample 을 잘 selection 하고 있다는 것을 의미합니다 (RQ2).
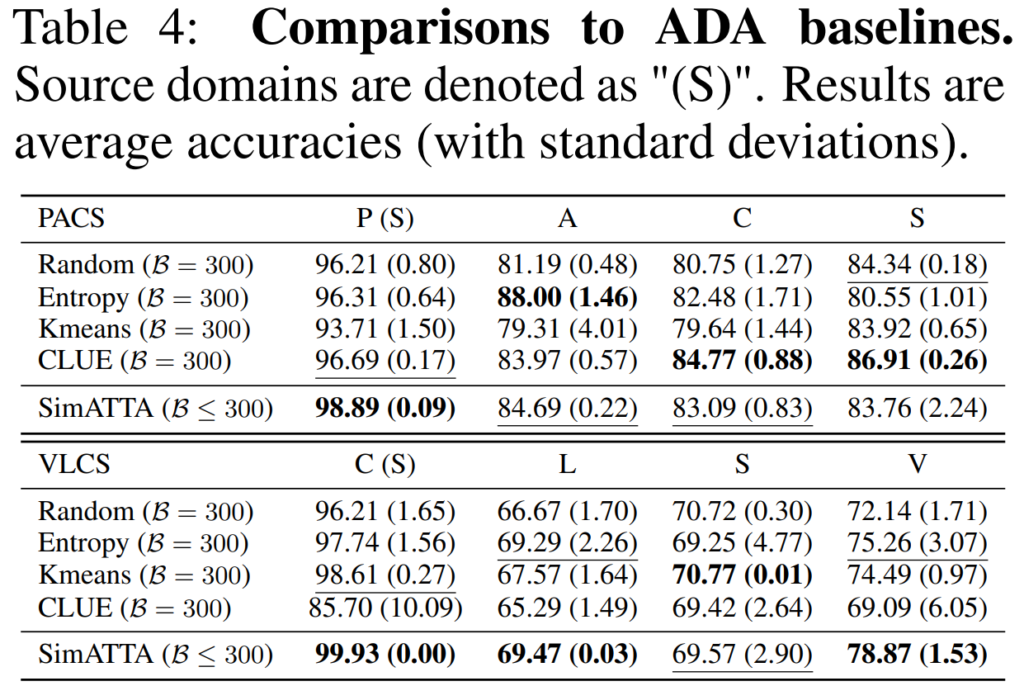
다음은 active domain adaptation (ADA) 방법론과의 비교입니다. ADA가 buffer 등의 측면에서 제약 사항이 더 적기 때문에 어떻게 보면 ATTA보다 성능이 당연히 좋을것이라고 생각할 수 있고, 저자들은 ADA 보다 열악한 조건에서 유사한 성능을 달성하고자 노력합니다. ADA의 경우 전체 global test distribution을 알고 있는 상황에서 best active sample 을 고르게 되지만, ATTA 에서는 전체 test sample에 대한 distribution을 알지못한 채 small sample buffer 에서 samples 를 골라야 하는 상황입니다. 하지만 실험 결과는 놀랍게도 ADA 대비 능가하거나, 혹은 유사한 성능이 나오는 것을 확인할 수 있습니다.
이번에는 새롭게 제안된 active test time adaptation (ATTA) 분야의 논문을 읽어보았습니다. 추가적인 정보 없이는 OOD generalization 능력을 얻는 것이 불가능하다는 앞선 연구 결과로부터, 기존 TTA에 active learning 컨셉을 섞어 새로운 연구 키워드를 제안하는 점이 대단하다고 느껴집니다.
안녕하세요. 좋은 리뷰 감사합니다.
첫 단락의 “방법론 설계 시 휴리스틱하고 실험적인 결과에만 의존하게 된다는 문제점이 있다고 주장”는 저자가 현재 실험 세팅이 잘못되었음의 문제를 제시할까요? 위 문장이 “방법론이 학습/테스트 데이터 셋에 대해서만 잘 되게끔 휴리스틱 하게 설게 되었다고 이해되었는데, 그렇다면 그 휴리스틱 한 대표적인 에시가 어떻게 되는지 궁금합니다!
안녕하세요 좋은 리뷰 감사합니다.
저는 지금 Few-shot learning에서 Active Learning 을 적용하고 있는데, 소량의 데이터셋을 선별하여 domain adaptation을 진행하는 테스크가 잘 진행되지 않더군요..
TTA 분야도 인퍼런스 속도가 중요하여 소량의 budget을 가정할 것 같은데, 혹시 budget이 어느정도 되는지, 해당 테스크에 대한 active learning 연구의 부적합성을 다룬 연구를 본 적이 있으신지 여쭤보고 싶습니다.
두번째 질문은 U_l(low)의 활용과 U_h(high)의 활용의 효과에 대해 질문하고 싶습니다. 리뷰에 언급해주신 것처럼 high entropy 데이터를 학습 데이터 풀에 추가하면 성능이 하락하는 경우가 많기에, U_l을 이용한다면 active learning 적용의 시너지가 클 것 같습니다. 다만 SimATTA가 제시한 성능 향상의 원인이 U_l 활용인지, 제안한 알고리즘인 incremental clustering(IC) 인지 궁금합니다. 논문에서 비교에 활용된 ATT의 경우 U_l을 활용하지 않은 듯 한데, IC 자체 효과를 기반으로 기존 방법론들과 비교한 실험도 있는지 궁금합니다..
감사합니다