안녕하세요, 마흔세 번째 X-Review입니다. 이번 논문은 2023년도 CVPR에 게재된 DPText-DETR: Towards Better Scene Text Detection with Dynamic Points in Transformer 논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
DETR이 나오면서, 이 DETR을 기반으로 성능을 개선시고자 하는 많은 논문들이 나오고 있습니다. 예를 들어 DAB-DETR이라고 하는 논문은 query를 content 부분과 positional 부분으로 나눠서 이 중 positional 부분이 학습 수렴에 필수적이라는 점을 입증하였습니다. 하지만, 기존에 이런 DETR 모델은 주로 axis-aligned boxes 즉 축에 정렬된 bbox를 prediction하는 데 집중이 되어 있는데요,, 이런 접근은 임의의 모양을 가진 (curved라던가.. 등) text를 처리하는데는 한계가 있습니다. 이에 대한 해결책으로 최근 DETR을 기반으로 하는 모델은 polygon control point나 bezier curve control point를 예측하는 방식을 사용하고 있습니다. bezier curve control point 같은 경우 제 이전 X-Review를 참고하면 되겠습니다. 그 중 한 모델인 TESTR이라는 모델은 본 논문이 base로 삼고 있는 모델인데요, 이 TESTR은 Deformable DETR 모델을 사용해 폴리콘 형식의 좌표를 예측하는 모델입니다. 좀 더 구체적으로 이 TESTR은 트렌스포머 인코더에서 생성한 anchor box proposal들을 사용해서 positional query를 생성하며, 이 potisional query는 content query에 대한 위치 정보를 제공하는 식으로 동작합니다.
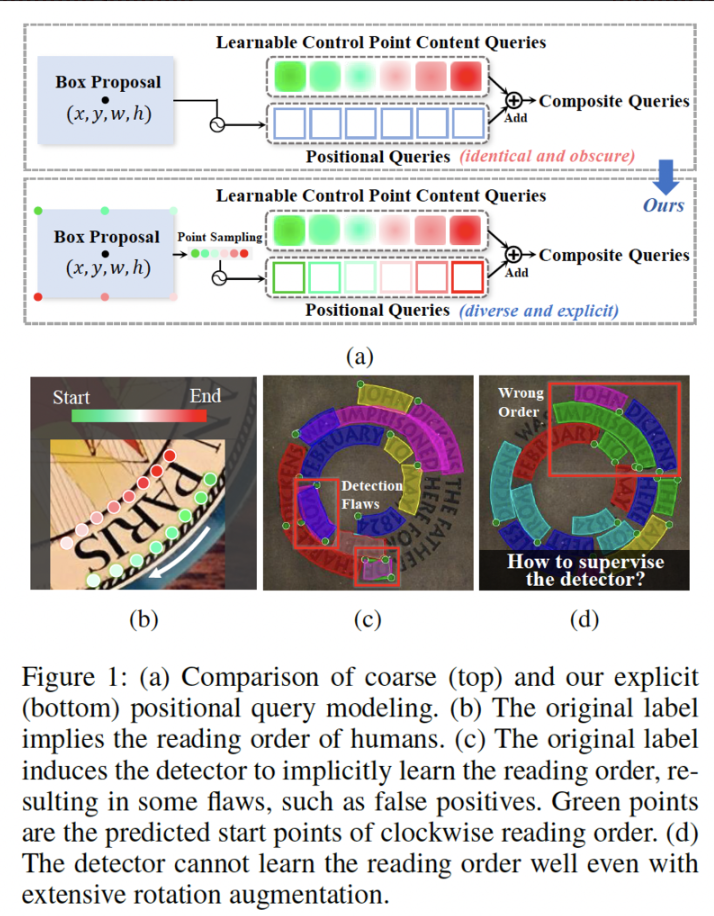
그림 1-(a)에 방금 말한 부분이 도식화 되어 있습니다. box proposal들로부터 positional 쿼리를 생성하고, 최종적으로 control point prediction에 필요한 content query와 더해져서 최종적으로 prediction하게 하는 식이죠. 하지만, box proposal에서 나온 box 정보는 텍스트의 정확한 모양을 나타내고 있지 않은 정밀하지 않은 정보이기 때문에 결국 모델이 예측하고자 하는 control point와의 차이가 있어 학습이 잘 되지 않는다고 합니다. 본 논문에서는 이런 문제를 query formulation issue라고 명명합니다.
또, box 형식의 point를 예측하는 것 대신 바로 control point를 예측하는 방식이 novel한 해결책이긴 하지만 이 경우 poitn의 순서와 관련된 문제가 발생합니다. 이전 연구들은 그림 1-(b)에서 볼 수 있는 것과 같이 control point label을 사람이 text를 읽는 순서에 맞춰 설정을 했습니다. 이 방식은 직관적이긴 한데, 정말 궁금한 점은 모델이 text를 이해하기 위해 꼭 사람이 글자를 읽는 방식과 같은 방식으로 detector를 구상해야 한다는 점입니다. 이런 의문과 관련하여 control point label 형식에 대한 영향을 알아보고자 하는 논문은 없었다고 합니다.
본 논문의 저자가 이와 관련한 실험을 해 보았는데, 기존의 이런 사람의 읽는 방식과 같은 point 순서를 사용할 경우, 학습 데이터셋에 inverse-like text 즉 거꾸로 써져있는 텍스트가 포함되어 있을 때 검출 성능이 떨어진다는 점을 확인하였습니다. 물론, Total-text라고 하는 데이터셋에서 2.8%, CTW1500 데이터셋에서 5.2% 정도밖에 없을정도로 그 비율은 낮다고 합니다. 이런 문제를 저자는 label form issue 라고 명명하고 있으며 이런 문제로 인한 검출을 못하는 결과는 그림1-(c)에서 확인해볼 수 있습니다. 기존 벤치마크에는 이런 역방향 텍스트가 거의 없기 때문에 본 논문에서는 추가로 이런 역방향 텍스트가 미치는 영향을 더 알아보고자 inverse-text test set을 제안합니다. 이 set은 약 40%의 거꾸로 되어있는 텍스트가 포함된 500장으로 구성이 되어 있습니다.
무튼 앞서 저자가 명명했던 query formulation issue와 label form issue를 해결하기 위해, 본 논문에서는 DPText-DETR이라고 하는 새로운 Dynamic Point Text DEtection Transformer 네트워크를 제안하고 있습니다. query formulation issue와 관련해서는 Explicit Point Query Modeling 방식을 제안을 하는데요, 간단하게만 말하면 Fig1-(a)의 아래 부분의 ours에서 볼 수 있듯이 기존과 같은 box 형식을 사용하는 것이 아니라 point 좌표를 직접 사용해서 positional query를 얻어내고자 하는 방식입니다. label form issue같은 경우에는 text의 semantic한 content 내용과 상관없이 시작점을 설정하도록 하는 label form을 제안하엿습니다. 이와 관련해서는 아래 method 부분에서 자세히 다루도록 하겠습니다.
2. Methodology
2.1. Overview
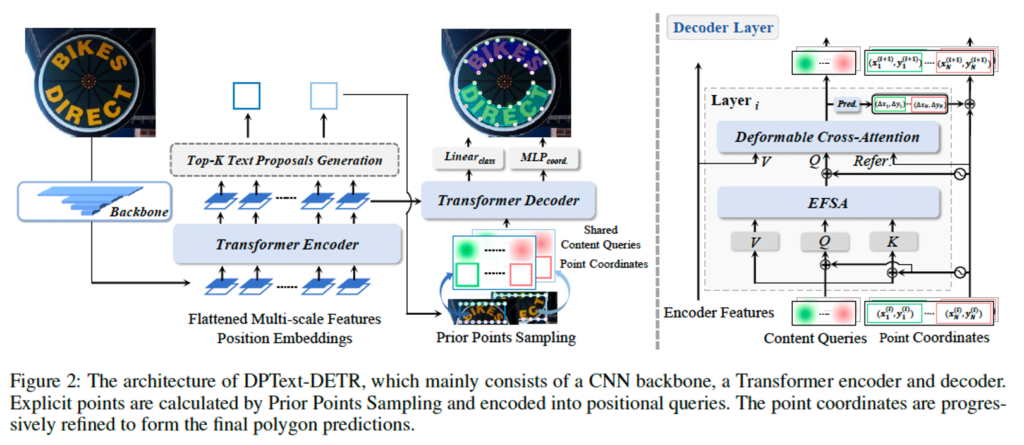
Deformable-DETR을 베이스로 한 모델 아키텍처는 위 그림2에서 살펴볼 수 있습니다. 입력 scene text image가 들어오면 먼저 CNN backbone을 태운다음 transformer encoder를 통해 feature를 추출하게 됩니다. 마지막 encoder layer를 통과하게 되면, axis-aligned boxes들이 생성되게 되는데요, 이 anchor box의 center 점과 크기 정보를 사용해 상단 부분과 하단 부분에서 일정한 수의 초기 control point 좌표를 uniform하게 sampling할 수 있습니다. 이렇게 sampling된 point 좌표는 deformable cross attention model의 reference point로 사용이 되며, decoder에서는 이 point 좌표가 인코딩되구, 해당되는 control point content query에 더해져서 새로운 composite query를 형성하게 됩니다. 이 composite query는 저자가 제안한 enhanced factorized self-attention 모듈에 들어가서 query들간의 관계를 학습한 후 deformable cross-attention으로 들어가게 됩니다. 그 다음 control point 좌표를 prediction하는 head로 들어가서 최종적으로 임의의 모양을 갖는 scene text에 더 잘 맞는 reference point를 업데이트 해 나가게 됩니다. 마지막으로 이 prediction head는 각 text instance에 대해 class confidence score와 N개의 control point 좌표를 생성해내는 식으로 동작합니다.
2.2. Positional Label Form
이제, intro에서 언급했었던 모델이 text를 검출할 때 사용했던 기존 label form의 문제점과 이를 해결하기 위해 제안한 부분에 대해 설명드리겠습니다. 간단하게 다시 언급해보자면 그림1(b)에 보이는 기존 label 형식은 사람이 text를 읽는 순서와 동일했었죠. 하지만 이 형식은 detector가 순서를 학습하도록 유도함으로써 학습을 더 어렵게 했고, 학습 중에 text가 다른 순서로 있을 때 더 모델이 학습하기 어렵게 합니다. 게다가 학습 중에 rotation 관련 aug가 있다고 하더라고 모델이 visual feature만으로 읽는 순서를 제대로 예측하는 것은 어려운데요 이와 관련해서는 그림 1(d)부분에 나와있습니다.
본 논문에서는 이런 점을 개선하기 위해서, detector가 text의 content를 고려하지 않고 순수하게 spatial 측면에서 위아래를 구분하도록 유도하는 positional label 형식을 제안합니다.
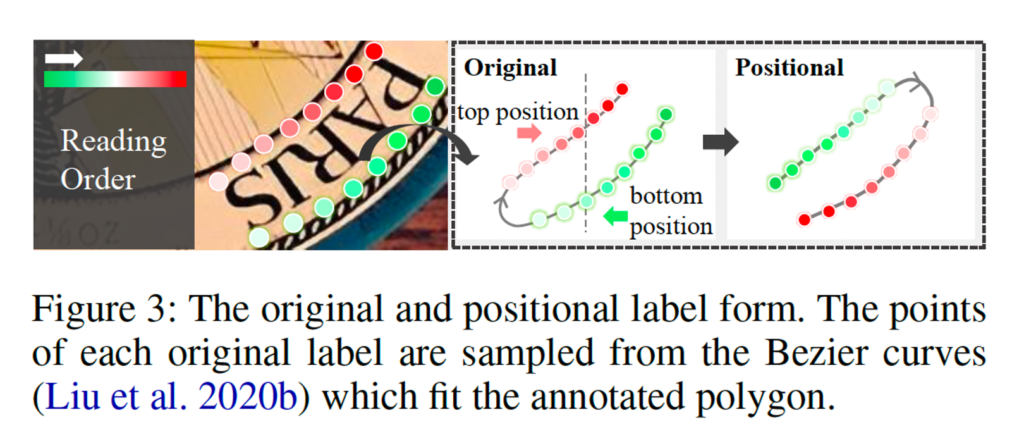
위 그림3에 설명된 바와 같이, positional label 형식은 크게 2가지의 간단한 규칙을 따르는데요, 먼저 시계방향 순서일 것과 text의 내용과 무관할 것.입니다. 구체적으로, 기존 point label의 순서를 먼저 모두 시계방향으로 만들구요, 만약 text instance가 뒤집혀 있는 경우 기존 시작 지점을 반대로 조정하였습니다. 즉, 기존에 아래부터 시작하던 시작점을 위로 옮긴 것이죠. 그 다음 text 좌표 중 y축이 더 작은 쪽, 만약 우상단이 좌상단보다 낮게 있다면 이를 시작점으로 삼도록 하였습니다. 이렇게 함으로써 모델이 text의 내용과 무관하게 일관된 규칙을 적용함으로써 방향과 순서를 더 잘 이해할 수 있도록 하였습니다.
2.3. Explicit Point Query Modeling
이제 base로 삼은 모델인 TESTR에서 제안한 방식을 확장해서 새롭게 제안한 point query modeling에 대해 살펴보겠습니다.
Prior Points Sampling
먼저 기존 TESTR의 point sampling방식에 대해 간단히 살펴보겠습니다. TESTR 모델의 최종 encoder layer후에 top k개의 proposal generator에서 각 anchor box가 인코딩되게 되고 N개의 control point content query에 공유가 됩니다. 다시 말하면 encoder가 text의 위치를 나타내는 box를 생성한 후, 이 box가 여러 쿼리로 나눠져서 각각의 control point를 prediction하는데 사용된다는 의미입니다. 결과적으로 나오는 composite query Q(i)(i=1, ., K)는 아래와같이 수식으로 나타내 볼 수 있습니다.
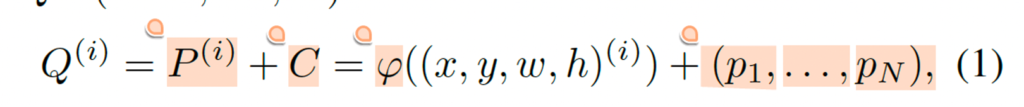
여기서 P(i)는 positional 정보, C는 content 정보를 나타내구요 이는 anchor box의 중심 좌표 x, y와 크기 정보 w, h 그리고 N개의 learnable한 control point content qeury (p1, … PN)으로 구성이 됩니다. 저자는 이 식(1)의 query 형식을 사용하는 TESTR을 base model로 삼았구요. 위 식1에서 볼 수 있듯이, 서로 다른 control point content query p1, ~~ PN들이 동일한 anchor box 정보 (x, y, w, h)를 공유하는 것을 확인할 수 있습니다. 이런 anchor box 정보는 control point의 위치를 prediction하는것을 도울 수는 있지만, 정확한 point를 예측하는데는 도움이 되지 않는다고 합니다. 즉, 저자는 각 query의 point를 정확히 예측하기 위해 필요한 위치 정보가 부족하다는 점을 지적하는 것입니다.
저자는 text가 이미지 안에 어떤 모양으로 있더라도, 그 text의 상단과 하단은 일반적으로 그 text를 둘러싼 anchor box의 상단과 하단에 가까이 위치한 점을 motive로 삼아서 anchor box의 상단과 하단에서 point를 균일하게 sampling해 text의 윤곽을 좀 더 정확하게 파악하고자 하였습니다.
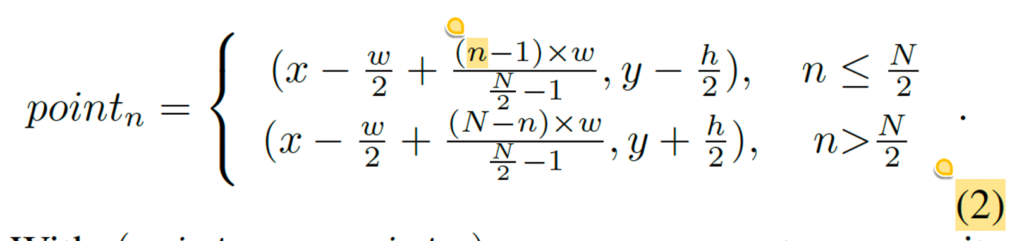
식은 위와 같구요 이렇게 해서 sampling된 좌표들을 이용해서 아래 식3을 통해 composite query를 생성해낼 수 있습니다.
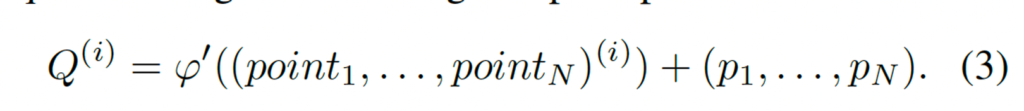
보시면 기존 식1에서 (x,y,w,h)의 동일한 positional 정보를 사용하던것과는 다르게 특정 point 위치 정보를 포함하고, 이 위치에서의 text feature를 반영하는 content 정보를 더함으로써 최종 composite query Q가 나오게 됩니다. 이를 통해 모델이 text의 형태와 위치를 좀 더 잘 예측하도록 한 것이죠.
Point Update
이후, 각 point 좌표를 통해서 layer별로 point 위치를 점진적으로 정교하게 update할 수 있구, 업데이트된 위치를 deformable cross-attention의 새 reference point로 사용하도록 합니다. 반면 TESTR 모델은 anchor box 정보를 직접 사용하여 position query를 생성했었죠. 따라서 이 TESTR은 decoder layer들 사이에서 point 위치를 정밀하게 조정하기 어려웠습니다. 한 번 설정된 point 위치를 각 layer에서 조정하지 않기 때문이죠. 반면 그림2의 우측 decoder 그림을 보면 본 모델에서는 decoder layer에서 prediction head를 통해 각각의 offset (Δx, Δy)을 얻은 후, control point를 업데이트 해 나갑니다. 이로써 다음 layer에서 더 정확한 point 위치를 예측할 수 있게 하는 것이죠.
2.4. Enhanced Factorized Self-Attention
이제, Enhanced Factorized Self-Attention이라는,, 기존 factorized self-attention(이하 FSA)를 개선한 모듈에 대해 설명드리도록 하겠습니다. FSA에서는 각 composite query Q(i)에 속하는 N개의 subqueries간의 relationship을 파악하기 위해 intral-group self attention을 적용합니다. 즉, text instance 내의 각 point 간의 관계를 분석하는 것이겠죠. 이 SAintra후에는 서로 다른 instance들간의 관계를 파악하기 위해 inter-group self-attention (SAinter)가 수행됩니다. 이는 여러 text instance들간의 관계를 파악하는 것이라고 보면 되겠습니다. 저자는 이 non-local SAintra가 polygon contrl point의 원형 shape 정보를 파악하는데 부족할 수 있다고 하는데, 이는 곧 text의 shape이 원형이거나 곡선일때 이 shape을 잘 파악하지 못할것이라고 지적합니다. (구체적인 이유는 언급하지는 않았습니다 .. )
따라서 저자는 이 FSA를 보완하기 위해서 local circular convolution을 사용한 Enhanced Factorized Self Attention (EFSA)를 제안하였습니다. 좀 더 text의 곡선형 poitn를 잘 파악할수 있도록 한 것이겠죠. 구체적으로 먼저 하나의 text instance 내에서 각 point 간의 관계를 파악하기 위해 SAintra를 사용을 했었죠. 이 과정에서 입력된 쿼리 Q에서 position 정보를 제외한 나머지 정보들로 새로운 query Qintral를 생성합니다. 즉 Q_{intra} = SA_{intra}(Q). 이와 동시에 locally enhanced query가 생성이 됩니다. Q_{local} = ReLU(BN(CirConv(Q))). 그 다음 이 두 local query와 intra query를 fusion합니다. Q_{fuse} = LN(FC(C + LN ( Q_{intra} + Q_{local})))로 식을 써볼 수 있겠습니다. 식에서 C는 content query를 의미하구요, FC는 fully connected layer BN은 batchnorm, LN은 layernorm입니다. 그 다음에 이 fusion된 쿼리 Q_fuse를 사용해 SAinter를 태우게 됩니다. 이렇게 생성된 Q_inter는 deformable cross attention 모듈로 들어감니다. 저자가 말하기를 모델의 성능과 속도를 다 고려해봤을 때 단 한 개의 circular convolution layer를사용하고 이 layer에서 각 point가 주위 4개의 이웃 point 와 정보를 교환하는것이 가장 효과적이었다고 말하고 있습니다.
3. Experiments
3.1. Comparison with State-of-the-art Methods
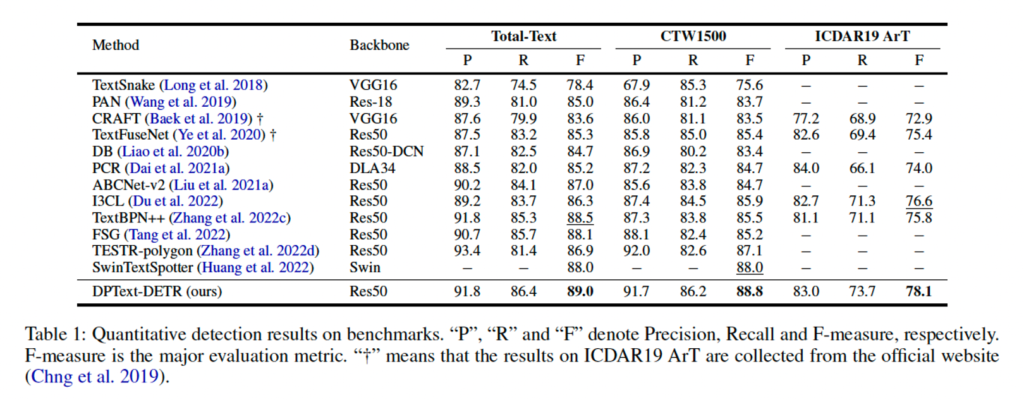
제안된 DPText-DETR 모델은 Total-Text, CTW1500, ICDAR2019 ArT 데이터셋에서 평가되었는데, 표1을 보시면 세 데이터셋 모두에서 가장 높은 성능을 보이고 있습니다. 본 논문이 나올 당시의 최신 모델인 SwinTextSpotter과 비교해봤을 때 total-text 데이터셋에서 1.0%, CTW1500에서 0.8% 더 높은 성능을 보였네요.

시각화 결과는 fig4에서 확인할 수 있습니다. 보시면 직선 text나 곡선 text, 그리고 오른쪽과 같이 여러 text가 밀집되어 있는 경우에도 잘 검출하고 있습니다. 하지만, 맨 오른쪽 아래에 있는 이미지처럼 엄청 밀집되어 있는 곡선 텍스트에 경우에는 polygon 예측에 어려움을 겪는 경우도 있다고 합니다.
3.2. Ablation Studies
Positional Label Form
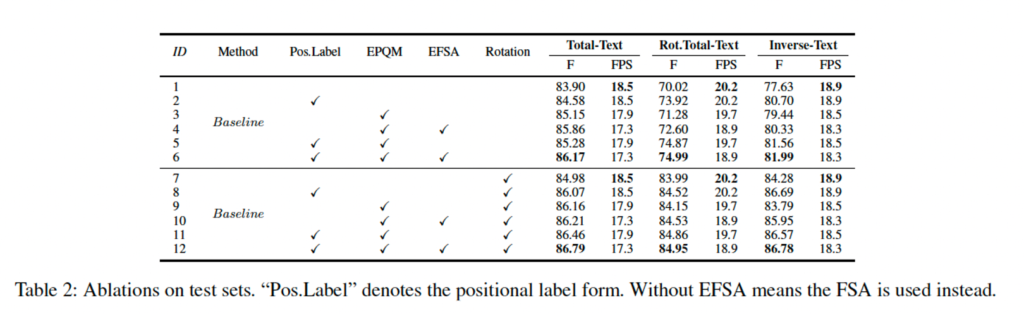
table2를 보면 positional label form을 적용했을 때 모든 test set에서 f-measure가 향상된 것을 확인할 수 있습니다. TT데이터셋에서는 0.68%, Rot.TT에서는 3.9% Inverse-Text에서 3.07%향상이 된 것을 보아 이 저자가 제안한 positional label form이 어느정도 모델을 robust하게 했음을 입증하네요.
EPQM
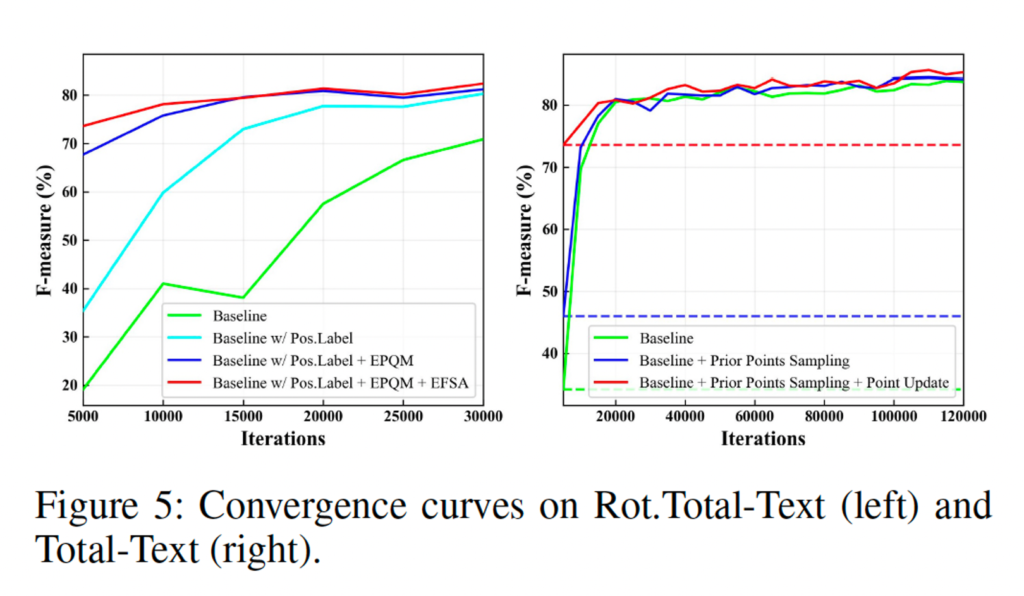
위 그림을 보면 기존 청록색? 그래프에서 저자가 제안한 EPQM을 추가한 것이 중간에 보라색 그래프인데요, 학습 초기부터 성능이 거의 30이나 오르기도 하고 직관적으로 봤을 때 성능 향상과 수렴하는데에도 많은 역할을 하고 있습니다.
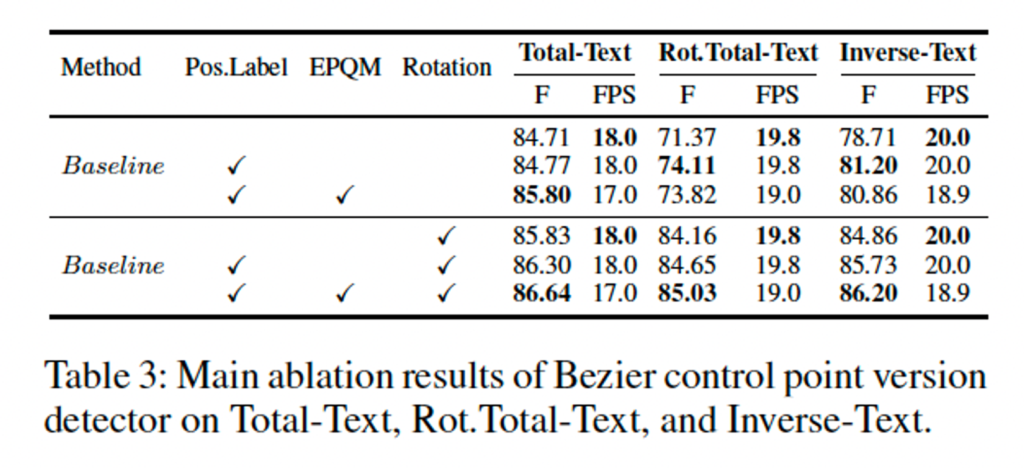
이건 bezier control point를 사용한 버전의 성능인데요 여기서도 볼 수 있듯이 일관성있게 EPQM을 추가한 경우 성능이 향상된 것을 확인할 수 있습니다.
탭. 2에서는 EPQM의 효과를 조사합니다. 그림 5(a)에서 볼 수 있듯이 EPQM은 직관적으로 성능을 향상시키고 수렴에 크게 기여합니다. 또한 EPQM은 표에서 보는 바와 같이 전체 텍스트에 대한 Beziervariant의 성능을 지속적으로 향상시킵니다. 3. 또한, EPQM은 소수 샷 학습성을 크게 향상시킵니다. 탭. 4에서 볼 수 있듯이, 훈련 반복 횟수와 데이터 양이 줄어들면 기준 모델의 성능이 크게 저하되는 반면, EPQM을 사용한 모델은 그 영향이 훨씬 적습니다.
EFSA
마지막으로 EFSA에 대한 ablation study 결과를 확인하고 마치도록 하겠습니다. table2를 보면 EFSA를 추가한 경우 추가하지 않았을 때와 비교하여 성능이 약간씩 상승한 것을 확인할 수 있습니다. 또 그림 5(a)에서 볼 수 있듯이 이 EFSA까지 추가한 그래프가 핑크색 그래프인데 최종적으로 수렴을 더 빠르게 하는 것을 볼 수 있습니다. 이건 baseline에 비해 약 6배나 빠른 수렴 속도라고 하네요.
안녕하세요 정윤서 연구원님 리뷰 감사합니다
설명이 눈에 쏙쏙 들어오네요
질문이 하나 있습니다. Methodology에서 position label form 단락에서 우상단과 좌상단 중 낮은 점을 시작점으로 둔다고 하였는데요 제가 이 논문을 읽으면서 잘 이해가 안 갔던 부분으로 텍스트가 수직 방향으로 나 있는 경우에 대한 설명이라고 이해했는데요 그렇게 되면 한 변에 시작점과 끝점이 옆에 나란히 붙어있게 되는 걸까요?
감사합니다!!
댓글 감사합니다.
넵 y값이 더 작은 점을 시작점으로 즉, 상단에 가까운 점을 시작점으로 해서 시계방향으로 돌리기 때문에 결과적으로 시작점과 끝점이 가깝게 위치할 수 있습니다. 하지만, 이 방식은 사람의 읽는 순서를 따르는 방식이 아니라 polygon을 안정적으로 구성하고자 하는 목적으로 설계한것이기에 시작점이 어디든, 끝점과 가까이 위치하든간에 시계 방향으로 배열되기만 하면 모델이 일관된 방식으로 학습할 수 있게 됩니다.