제가 이번에 리뷰할 논문은 시각-언어 정보를 기반으로 대상 객체를 인식하며, 이때 미학습 객체도 인식하고 동일 객체가 존재할 경우 이를 구분하여 인식하는 방법론이라는 것에 흥미가 생겨 리뷰하게 된 논문입니다. 객체 인식 관점에서는 GroundingDINO를 조금 개선시킨 정도인 것으로 보이며, Open-Vocabulary Grasping을 위한 벤치마크를 제안했다는 것이 주요 컨트리뷰션인 것 같습니다. 또한 시뮬레이션으로 파지 성공률도 측정하고있어 전체적인 파이프라인을 알아보기에도 좋을 것 같아 리뷰하게 되었습니다.
Abstract
새로운 물체를 인식하고 파지하는 것은 로봇 어플리케이션 분야에서 여전히 어려운 문제이며, 중요한 문제임에도 제한적인 연구가 이루어졌습니다. 해당 논문은 open-vocabulary learning을 로봇의 brasping으로 통합하여 학습되지 않은 새로운 물체도 처리 할 수 있는 새로운 프레임워크를 제안합니다. 해당 논문의 컨트리뷰션을 정리하면 다음과 같습니다. (1) open-vocabulary Grasping 태스크 성능을 평가하기 위한 대규모 벤치마크 데이터 셋을 제안하였고, (2) 학습된 객체와 새로운 객체를 모두 파악하기 위한 통합된 visual-linguistic 프레임워크를 제안하였으며, (3) visual-linguistic 인식 향상을 위한 두가지 alignment 모듈을 제안하였습니다. 다양한 실험을 통해 저자들이 제안한 프레임워크의 효율과 활용성을 검증하였으며, 저자들이 제안한 데이터셋에서 기존 카테고리와 신규 카테고리 에서 각각 71.2%와 64.4%의 정확도를 달성하였다고 합니다.
Introduction
지능형 로봇을 실세계에 활용하고자 하는 요구가 증가하고 있으며, 기존의 방식들은 학습된 카테고리를 인식하는 것으로 제한되어있어 실세계에서 등장할 수 있는 미학습된 카테고리에 대해서는 처리하지 못하였습니다. 이러한 이유로 novel-categorh에 대한 인식 필요성이 증가하고 있습니다.
최근 visual-linguistic robotic grasping(VLG) 분야의 발전으로 사람이 언어를 통해 로봇과 상호작용할 수 있게 되었으며 visual-linguistic 표현의 어려움을 해결하기 위한 다양한 프레임워크가 제안되었습니다. 이러한 프레임워크는 로봇이 언어 안내를 기반으로 물체를 파지할 수 있도록 하였으나 새로운 물체의 위치를 파악하는 데 있어 어려움이 있으며 이를 해결하기 위한 벤치마크도 부족합니다. 또한, Open-Vocabulary Learning(OVL)를 로봇 파지에 통합하는 연구도 이전에는 수행된 적 없다고 합니다.
이러한 한계를 해결하기 위해 본 논문에서는 OVL개념을 grasping에 도입한 OVGNet 프레임워크를 제안하였으며, Open-Vocabulary Grasping(이하 OVG)를 위한 벤치마크인 OVGrasping 데이터 셋을 제안하였습니다. OVGNet은 Open-Vocabulary Foundation 모델의 지식을 활용하여 새로운 객체의 위치와 파지를 위한 정보를 파악하는 데 중점을 둡니다. 제안된 프레임워크는 언어 정보를 기반으로 대상 물체의 위치를 파악하는 시스템으로 이루어지며, 새로운 카테고리에 대한 인식 능력을 향상시키기 위해 Image guided language attention(IGLA) 모듈과 language guided image attention(LGIA) 모듈을 도입하였다고 합니다. IGLA 모듈과 LGIA 모듈은 시각적 특징과 언어적 특징의 align을 보장하기 위해 적용되었으며, base 카테고리에서 novel 카테고리로의 일반화를 촉진하는 역할을 하도록 설계되었습니다. 저자들이 제안한 방법론은 OVGrasping 데이터 셋에서 다양한 실험을 통해 성능을 검증하였으며, 실험 결과에 대한 시각화와 분석을 통해 설명 가능성도 보였다고 합니다.
본 연구의 contribution을 정리하면 다음과 같습니다.
- 로봇이 base 카테고리 뿐만 아니라 novel 카테고리도 고려할 수 있도록 하는, OVG 테스크를 위한 large dataset인 OVGrasping Dataset 제안
- 사전지식과 fine-tuning 기술을 활용하여 로봇이 새로운 카테고리의 물체를 파악할 수 있는 OVL을 OVG 테스크에 통합하는 새로운 프레임워크를 제안
- alignment를 위한 두 모듈을 도입하여 시각-언어 인식 시스템의 일관성을 강화하여 일반화 성능을 개선
Proposed Method
OVGrasping Dataset
기본적인 객체와 새로운 객체 모두 위치와 grasping을 예측하기 위해 새로운 large-scale language-guided 데이터셋인 OVGrasping을 제안합니다. 이는 RoboRefIt, GraspNet과 새롭게 취득된 데이터를 이용하여 구축된 데이터 셋 입니다.
<Dataset Descriptions>
OVGrasping 데이터 셋은 117개의 카테고리와 63,385개의 인스턴스로 구성되며, 이는 RoboRefIt 데이터 셋에서 66개의 클래스, GraspNet 데이터 셋 에서 34개의 클래스, 시뮬레이션 환경에서 17개의 클래스를 모아 구성됩니다. 시뮬레이션 환경은 pybullet 툴을 이용하였으며, 3D 모델은 OmniObject3D로부터 얻을 수 있었다고 합니다. 카메라의 위치는 grasping 평면과 수직이며, 이미지는 480×640 해상도로 이루어지도록 하였다고 합니다.
이렇게 취득된 카테고리는 크게 base와 novel 카테고리로 구성되며, base는 학습에 사용되고 novel은 Open-Vocabulary 평가에만 사용됩니다. 또한, base 카테고리 중 10%의 인스턴스를 랜덤하게 선택하여 평가 set을 구성하였다고 합니다.
<Data Annotation and Samples>
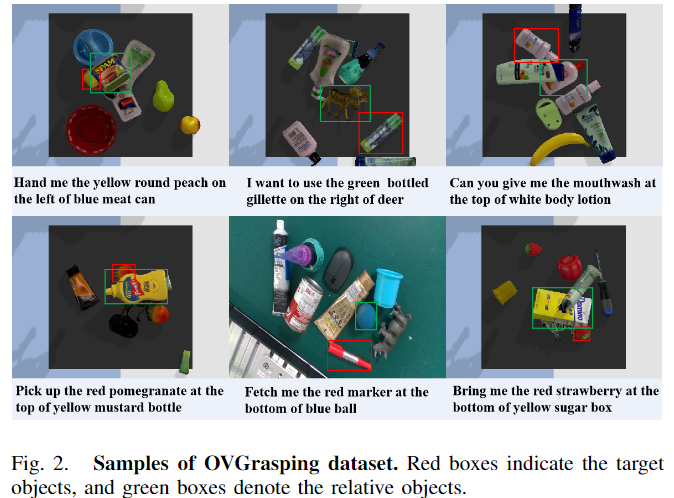
annotation 과정에는 annotation 전문가 6팀과 품질 평가 3팀을 고용하여 정확하고 일관성 있는 annotation을 수행할 수 있도록 하였다고 합니다. 또한, 데이터 셋에 색상, 모양, 위치 정보를 포함하는 이미지의 컨텍스트 정보를 활용하여 각 개체에 대한 포괄적인 설명을 제공합니다. 또한 데이터 셋에 유사하거나 동일한 객체가 포함될 경우를 고려하여, 새로운 annotation 형식을 활용하였으며, 이는 아래와 같이 주변 객체들과 상대적인 관계를 도입하여 두개의 동일한 객체를 식별할 수 있도록 하였다고 합니다.
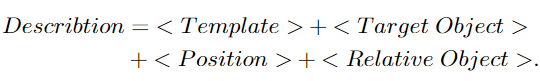
annotation 과정에 대상 객체에 대한 템플릿을 무작위로 생성하며, annotator는 상대적 위치와 해당 객체에 대한 정보만 제공하도록 하였으며, 이에 대한 예시는 위의 [Fig. 2]를 통해 확인하실 수 있습니다. 두개의 동일한 객체가 주어질 경우 대상 객체의 위치에 대한 정보가 제공됩니다.
<Dataset Comparison>
OVGrasping 데이터 셋은 로봇이 base 객체와 novel 객체를 모두 인식할 수 있도록 하는 것을 목표로 하며, 기존 데이터 셋들과 비교를 통해 특징을 어필합니다.
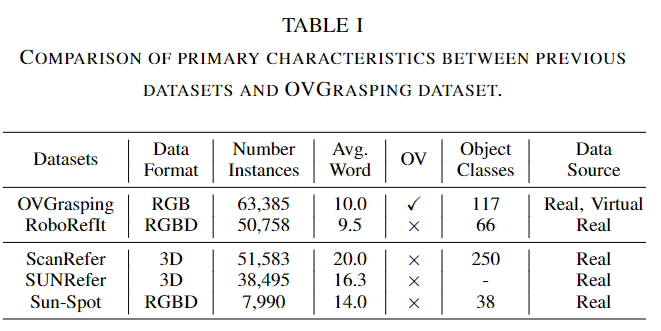
위의 Tabel 1은 그중 가장 유사한 데이터 셋은 RoboRefIt로, OVGrasping 데이터 셋이 평균 단어 수가 더 많으며(설명이 더 자세하다고 어필합니다.. 0.5 단어 차이인데..?), Sun-Spot 데이터 셋과 RoboRefIt 데이터 셋에 비해 객체의 인스턴스 수와 클래스의 개수도 크게 증가하였다고 어필합니다. 마지막으로 가장 중요한 특징은 OV(Open-Vocabulary) 데이터 셋이라고 어필하며 base 카테고리와 novel 카테고리를 명확하게 구분하였음을 이야기 합니다. 또한, 가상과 실제 데이터가 혼합되어있다는 점도 다른 데이터 셋과의 차이점으로 이야기합니다.
OVGNet
Grasping에 Open-Vocabulary를 도입하기 위해 해당 논문은 GroundingDino와 GraspNet에서 영감을 받은 visual-linguistic grasping 프레임워크를 설계하였으며, 이는 시각-언어에 대한 인식과 grasping 시스템이라는 두가지 구성 요소로 이루어집니다.
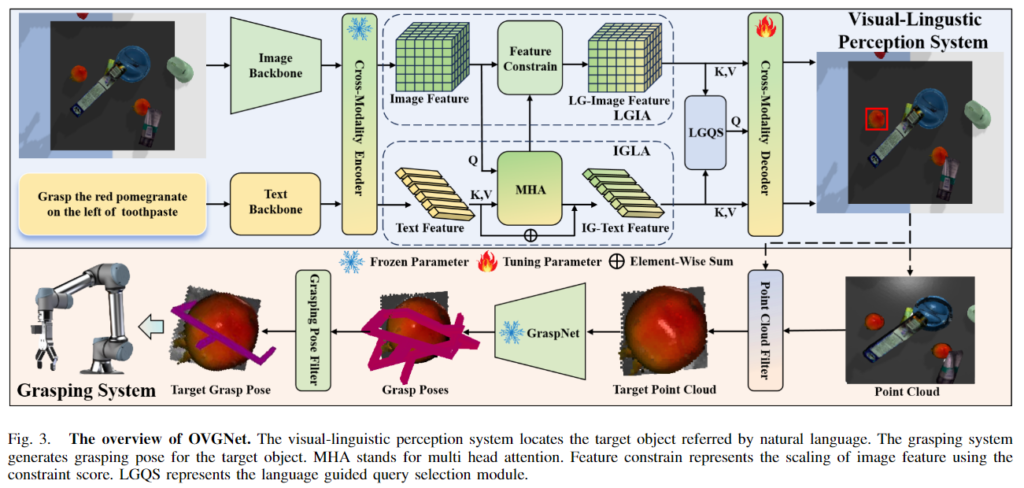
Visual-Linguistic Perception System
언어 입력으로부터 객체의 위치를 추정하기 위해 설계된 시스템으로, 이미지 i와 설명 text l이 주어졌을 때, GroundingDINO를 따라 백본 f_{i}( ) 와 f_{l}( ), cross-modal 인코더인 f_{ce}( ) 로부터 이미지와 text의 특징을 추출합니다. 이때, 인코더들은 freeze하여 사용합니다.
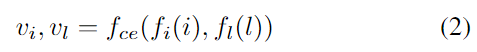
OVGrasping 데이터 셋이 객체와 주변의 관계와 같이 복잡한 언어 구조를 가지고 있으므로, 시각적 특징과 언어적 특징의 align을 맞추기 위해 multi-head attention 기반의 Image Guided Language Attention(IGLA)를 설계하여 text feature를 강화합니다. 이미지 feature v_i를 query, text feautre v_l을 key와 value로 하여 multi-head attention을 통해 이미지 feature를 text feature와 align 맞춘 visuual-linguistic feature v_{il}를 만듭니다.v_{il}에 \alpha를 이용하여 스케일링한 뒤, skip connection을 통해 원본 text feature v_l로부터 image-guiged text feature인 v'_{l}를 생성합니다. 수식으로 표현하면 아래와 같으며, 실험적으로 \alpha는 0.5로 설정하였고, d_{vl}은 v_l의 차원을 의미합니다.
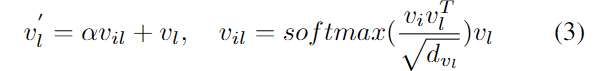
또한, 시각적-언어적 이해를 향상시키고 이미지 내의 언어로 설명된 영역에 집중하도록 하기 위해 Language Guided Image Attention(LGIA)를 설계하여 이미지 feature를 개선시킵니다. fully connected layer와 L2 정규화를 이용하여 v_i와 v'_l를 동일 차원의 공간으로 매핑하여 v_{id}와 v'_{ld}를 얻습니다. 이 feature들을 활용하여 constraint score S_c를 구합니다. constraint score를 구하기 위한 식은 아래와 같이 정의되며, \beta 와 \theta는 학습가능한 파라미터이고, v_{id}(x)^Tv'_{ld}(x)는 벡터 각 point x에 대한 constraint score를 의미합니다.
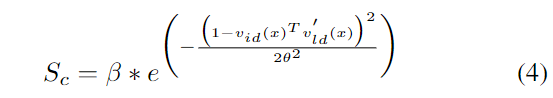
이렇게 constraint score를 구한 뒤, 이를 이용하여 언어와 무관한 이미지 영역의 중요성을 낮추어 language-guided image feature v'_i를 얻습니다. v'_i를 구하는 식은 아래와 같으며, 여기서 \lambda는 균형을 맞추기 위한 파라밑로 실험적으로 0.6으로 설정하였다고 합니다.
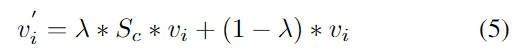
이후 GroundingDINO의 방식을 따라서 language-guided query selection f_{ls}( )를 이용하여 v'_i로부터 900개의 query들인 v_q를 선택하고, v'_i, v'_l, v_q를 corss-modality 디코더 f_{cd}( )에 입력하여 가장 점수가 높은 bounding box y를 출력합니다.
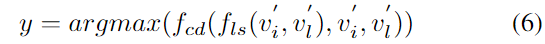
Grasping System
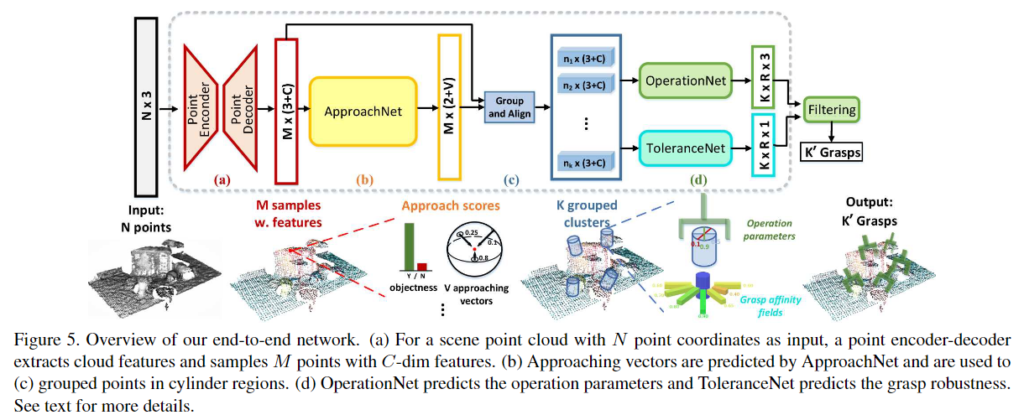
로봇이 목표 물체를 잡을 수 있도록 하는 시스템으로, 저자들은 실험을 통해 작은 물체에 대한 정확한 grasping pose를 구하는 것이 어렵다는 것을 파악하였고, 따라서 visual-linguistic perception 단계에서 얻은 bounding box를 사용하여 해당 영역에 대한 point cloud를 얻고, 이를 사전학습된 GraspNet에 입력하여 6-DoF의 grasping pose를 생성합니다. 여기서 파지 성공률을 높이기 위해 GraspNet으로 얻은 grasp score와 grasp 각도를 임계값으로 사용하여 grasp pose를 필터링하고, 이후 유클리드 distance를 사용하여 Bbox의 중심점과 각 grasping pose의 중심 점 사이의 거리를 비교하여 가장 가까운 grasping pose를 target grasp pose로 선택합니다.
** GraspNet은 2020년도 CVPR에 게재된 논문으로 GraspNet의 파이프라인은 아래의 그림에 해당합니다. 해당 방법론은 포인트클라우드를 입력으로 활용하여, 2지 그리퍼로 물체를 파지하기 위한 그리퍼의 pose를 예측하는 방법론입니다. GraspNet은 10억 개의 그립 포즈가 포함된 데이터 셋을 제공한다고 합니다.
Experiments
저자들이 제안한 OVGrasping 데이터 셋과 가상환경에서 해당 논문이 제안한 프레임워크에 대한 평가를 수행합니다.
Visual-Linguistic Perception
먼저 시각-언어 인식에 대한 평가를 수행하며, 이때 OVGNet은 사전학습되어있는 GroundingDINO로 초기화되며, 10 epoch 정도 fine-tuning을 수행하였다고 합니다.
<Result on OVGrasping Dataset>
OVGNet의 효과를 검증하기 위해 OVGrasping 데이터 셋 뿐만 아니라 기존의 데이터 셋으로도 비교 실험을 진행하였다고 합니다 평가지표는 예측된 Bbox와 GT Bbox의 IoU가 0.5 이상일 경우 정답으로 평가하는 Precision@0.5를 이용하였다고 합니다.
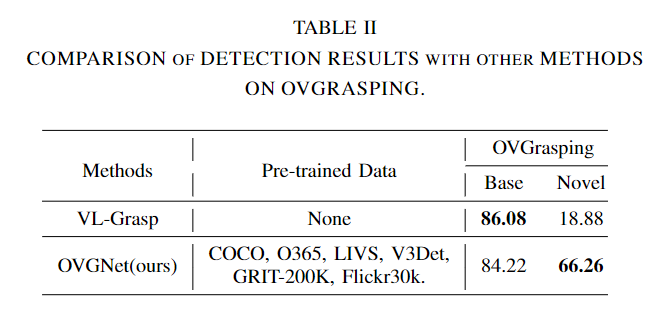
- Table2 는 기존 방법론인 VL-Grasp와 성능을 비교한 것으로, VL-Grasp 방식을 OVGrasping 데이터로 재학습하여 평가를 수행하였다고 합니다. Base에서는 성능이 조금 더 낮지만 이에 대해서는 VL-Grasp 방식이 학습을 더 많이 했기 때문이라고 분석합니다. 그러나 VL-Grasp와 다르게 저자들이 제안한 방식이 Novel Object에 대해서 47.38% 향상된 성능을 보였다는 것을 통해 visual-linguistic perception system이 새로운 객체로의 일반화 효과가 있음을 보였습니다.
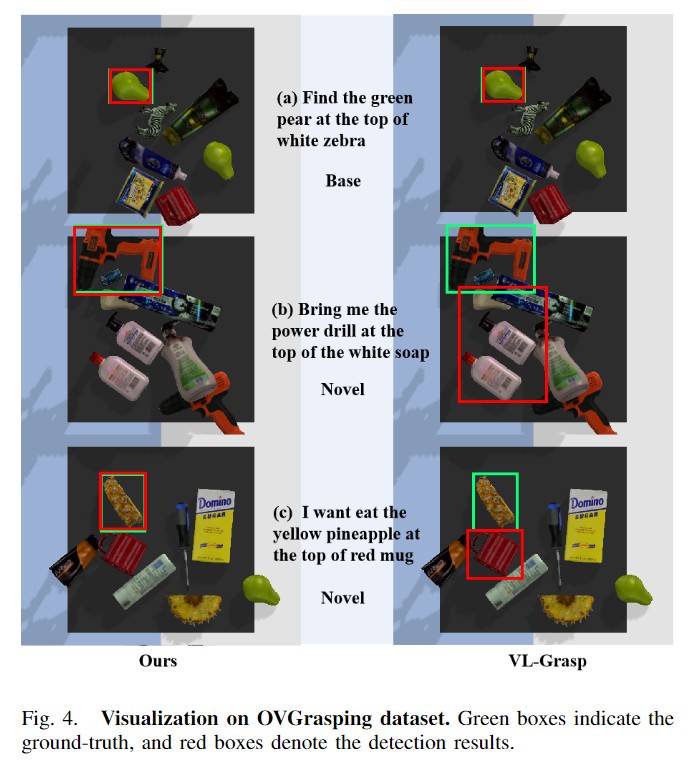
- OVGNet과 VL-Grasp에 대한 분석을 위해 시각화 결과에 대한 분석을 수행하였고, [Fig. 4]의 (a)에서 볼 수 있듯 base 카테고리에 대해서는 두 방법론 모두 잘 작동하는 것을 확인하였습니다.
- [Fig. 4]의 (b)는 새로운 카테고리에 대한 예측 결과로, VL-Grasp 방법론이 새로운 객체를 찾지 못하는 것을 보여주며, 저자들의 방법론은 잘 찾고있음을 보였습니다.
- [Fig. 4]의 (c)도 새로운 카테고리에 대한 예측결과이며, 해당 케이스는 동일 객체(pineapple)가 존재하며 이에 대해 주변 객체와의 정보를 제공하여 특정한 객체를 찾는 것을 목표로 합니다. 신기하게도 해당 케이스에서도 저자들이 찾고자 하는 객체에 대한 정확하게 인식이 가능함을 확인할 수 있습니다.
<Ablation Study>
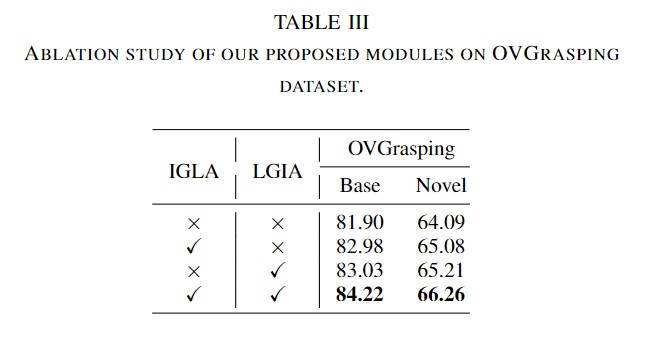
- Table 3은 해당 논문에서 제안된 모듈의 효과를 확인하기 위한 ablation study 결과로, IGLA와 LGIA를 포함할 경우 base 카테고리에 대해 각각 1.08%와 1.13%의 성능 개선이 이루어짐을 확인할 수 있습니다. novel 카테고리에 대해서도 각각 0.99%와 1.12%가 개선되었으며, 두 모듈을 추가할 경우 base와 novel 카테고리에서 각각 2.32%와 2.17%의 성능 개선이 이루어짐을 확인할 수 있습니다.
- 이러한 실험을 통해 제안한 모듈이 시각 feature와 언어 feature를 효과적으로 맞추어 정확도 향상에 도움이 되었다 분석합니다.
Grasping in Virtual Environment
다음은 가상 환경인 pybullet에서 UR5arm과 ROBOTIQ-85를 이용하여 대상 물체에 대한 Grasping 평가를 수행하였다고 합니다. 이때 Realsense L515를 이용하여 이미지를 취득하였으며, 135개의 grasping scene을 생성하여 65개는 base와 novel에 대한 평가에 사용하고 나머지 70개는 다른 task를 평가하는 데 사용하였다고 합니다. 또한, 프레임워크가 동일 객체에서 대상 객체를 찾을 수 있는 지 평가하기 위해 동일 객체가 없는 single-grasping 장면과 동일(혹은 유사한) 객체가 존재하는 multi-grasping으로 시나리오를 나누어 평가하였습니다. 파지 시도 횟수는 3번으로 설정한다고 합니다.
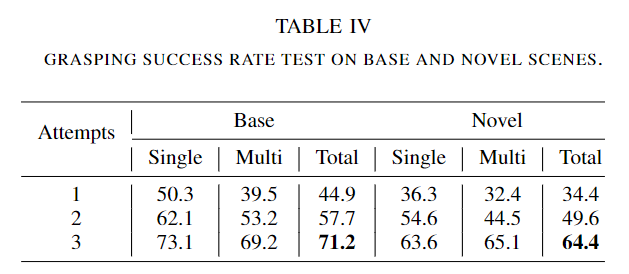
- 65개의 scene에서 novel과 base 객체에 대한 파지 성공률을 평가한 결과로, 첫번째 시도부터 높은 성공률을 달성하였다고 합니다. 3번 시도한 결과 base에 대해서는 71.2%, novel에 대해서는 64.4%의 성공률을 달성하였습니다.
- 동일하거나 유사한 객체가 존재하여 파지가 어려운 multi 케이스에 대해서도 높은 성공률을 보였으며, 이러한 실험 결과를 통해 저자들이 제안한 프레임워크가 좋은 성능을 달성하였다고 이야기합니다.(파지 성공률의 기준이 정확히 제시되어있지는 않지만, novel 객체에 대해서도 base만큼의 성능을 달성하였다는 것과, 유사한 객체가 존재하여 파지가 어려운 multi 케이스에서도 파지 성공률이 어느정도 보장되었다는 점을 들어 본 논문의 목적은 달성하였다고 볼 수 있을 것 같습니다.)
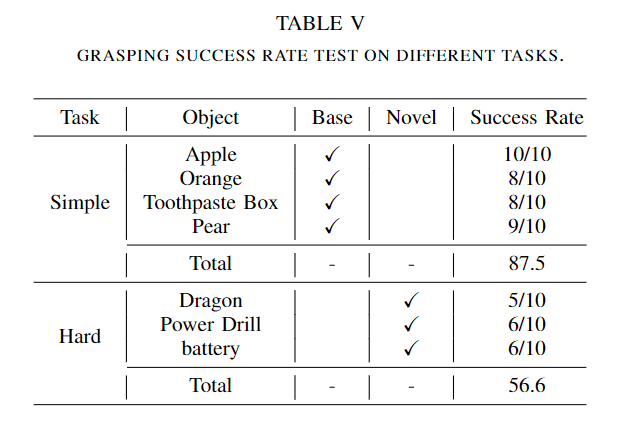
- 추가적인 실험으로 4개의 단순한 객체와 3개의 어려운 객체를 선택하여 파지성공률을 평가하였으며, 위의 Table 5는 이에 해당하는 결과입니다. 10개의 scene에서 각 scene마다 최대 3번의 시도가 가능하며, 실험 결과 단순한 base 객체에 대해서 87.5%의 성공률을 보였다고 합니다.
- 어려운 novel 객체에 대한 파지 성공률은 56.6%하였으며 이를 통해서도 프레임워크의 일반화를 검증하였다고 합니다.(성능 차이가 어느정도 존재하므로 simple에 대한 novel과 hard에 대한 base 성능도 있었다면 좋을 것 같습니다.)
<Case Analysis>
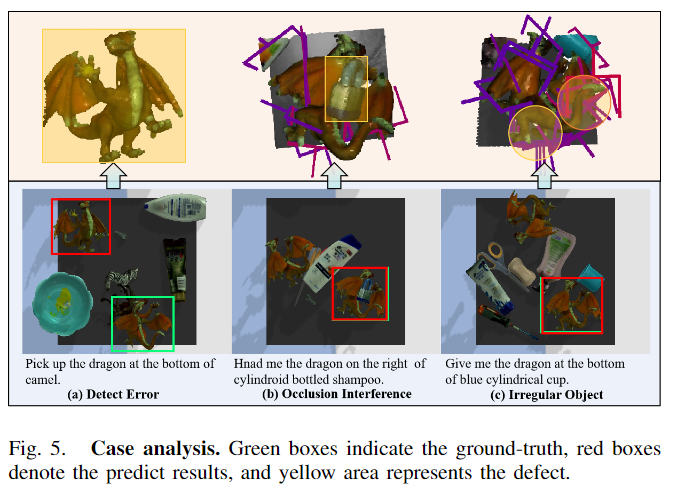
- [Fig. 5]는 파지에 실패한 경우에 대해 분석을 위한 것으로, (a)에서 볼 수 있듯 예측 결과가 잘못되었을 경우 실패하며, (b)와 같이 대상 객체 영역을 제대로 인식하더라도 대상 객체의 point cloud에 occlusion이 발생할 경우 pose 예측에 실패하는 것을 확인할 수 있습니다.
- 또한, (c)에 대해서는 객체의 구조가 복잡한 경우 최적의 grasping pose를 찾지 못하여 실패한다고 분석하였습니다.
안녕하세요 이승현 연구원님 좋은 리뷰 감사하니다
제가 때마침 Grounding DINO를 리뷰했는데, 소개글에 Grounding DINO를 개선시켰다는 얘기가 있어 반가워서 읽게되었네요
궁금한 점은, Grounding DINO은 open-set 환경에서의 Detection을 제안하였는데, 해당 논문에는 Unseen object에 대한 성능이 있을까요?
질문 감사합니다.
저도 마침 리뷰하려는 데 GroundingDINO리뷰를 해주셔서 내용 이해에 도움이 되었습니다.
Unseen object들을 해당 논문에서는 Novel 카테고리로 묶어서 평가를 수행하였습니다. 실험 결과 novel 카테고리에서도 안정적으로 예측이 되는 것을 확인하실 수 있습니다.
좋은 논문 리뷰 감사합니다.
몇 가지 질문 남기고 가겠습니다.
Q1. Tab 1에서 보면 OVG의 data format은 RGB로 되어 있는데 point cloud는 어디서 나오는 거죠?
Q2. Grounding은 어떤 모듈이 해주는 건지 모르겠습니다… Grounding-DINO에 완전 의존하는 건가… 근데 저자가 제안한 IGLA와 LGIA에 있을 것이라고 추측합니다. 맞다면 IGLA와 LGIA 둘 중 누가 이를 강화 시켜 주는 것이고, 어떤 원리인지 설명 부탁드립니다.