이번 논문은 제목 그대로 모델 무관하게 특징맵의 해상도를 변경 가능하도록 하게 해주는 기법입니다.
Intro
최근 인공지능 분야에서는 foundation model의 등장으로 해당 모델을 고정하여 추출된 특징맵을 활용한 연구들이 활발하게 진행되고 있습니다. foundation model을 보다 잘 사용하기 위해서는 우리가 목표하는 다운스트림에 맞춰 추출한 특징맵을 적응적으로 변경하여 사용해야만 합니다. 이를 위해서, 기존 foundation model 구조와 가중치는 그대로 두되, 추가 레이어(adaptor)를 통해 미세 조정을 수행하기도 합니다. 하지만 해당 기법은 여전히 목표하는 다운스트림을 위해 가공된 데이터를 요구하기 때문에 데이터에 의존적인 한계가 존재합니다. 즉, 가공 데이터의 양과 품질에 따라 다운스트림에서의 성능이 좌지우지 될 수 있기 때문에 효율적인 해결책이 되기는 어렵습니다.
이러한 문제점에 주목하여 최근 ICML에서는 backbone으로부터 추출된 특징맵(~=foundation model의 특징맵)의 품질을 향상시키는 논문들이 등장하고 있습니다. 이번 리뷰 논문 또한, 이러한 흐름에 맞춰 등장한 논문이라고 볼 수 있습니다. 해당 기법이 집중한 방법은 backbone으로부터 추출된 저해상도의 특징맵을 기존 정보를 유지하면서 고해상도의 특징맵을 추출하는 방법을 제시합니다.
해당 기법은 기존 super-resolution task와는 다른 문제를 풀어야만 합니다. super-resolution task에서는 고해상도의 영상을 GT로 활용하며, 해당 영상을 저해상도로 다운 샘플링해 입력 값으로 사용합니다. 허나, 특징맵에 대한 업 샘플링은 GT가 존재하지 않겠죠. 만약에 존재한다고 하더라도 그 값이 명확하게 맞는 답이라고 보기도 어렵습니다.
+ Teacher model이 추출한 특징맵이 GT라고 보기에는 불명확한 부분이 있습니다.
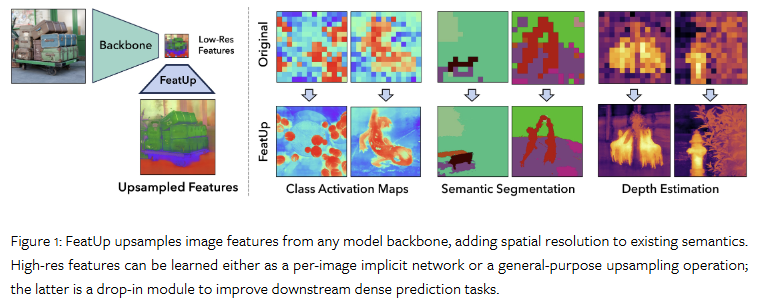
또한, fig 1과 같이 원본 영상 수준으로 영상을 업 샘플링을 수행하는 dense prediction downstream task에서는 backbone의 featuremap이 low-resolution feature map으로 다운 샘플링 되면서 공간적인 정보 손실이 발생합니다. 대표적으로 ResNet50은 224 x 224 입력 영상이 7 x 7로 변경되며, foundation model로 많이 활용되는 ViTs 또한, 해상도가 크게 감소합니다. 이는 dense prediction downstream task를 수행하는데에 있어 해당 태스크를 더욱 도전적으로 만드는 요소가 됩니다.
저자는 이와 같은 문제를 완화하기 위해서 FeatUp을 제안합니다. 해당 기법은 의미론적인 정보는 유지하되, 기존 모델을 변경하지 않고 feature map의 해상도를 향상시키는 프레임 워크를 제안합니다. 저자가 제안하는 기법은 3D reconstruction 중 하나인 NeRF에서 영감을 받아 저해상도 신호의 multi-view consistency을 통해 고해상도로 지도학습을 수행하는 방법을 제안합니다. 좀 더 구체적으로 이야기 하자면, 영상들에 multiple “jittered” (e.g. flipped, padded, cropped)를 수행하여 고해상도의 변화에도 일관성을 유지 가능하다는 점을 이용합니다.
저자는 two architectures for upsampling을 제시합니다.
(1). a single guided upsampling feedforward network that generalizes across images. 해당 feedforward upsampler는 Joint Bilateral Upsampling (JBU) filter의 파라미터 일반화를 목적으로 설계되어 있습니다. 또한, 메모리와 연산 효율성을 위해 CUDA kernel을 제안합니다. 이를 통해몇 개의 컨볼루션과 비슷한 계산 비용으로 엣지에 정렬된 고해상도 특징맵을 생성할 수 있습니다.
(2). an implicit representation overfit to a single image. 저희의 implicit upsampler는 NeRF와 유사하게 deep implicit network를 오버핏하여 arbitrary resolution features과 low storage costs를 가능하게 합니다.
두 아키텍처 모두에서 업샘플링된 기능은 의미론적 변화 없이 업 샘플링이 되기 때문에 다운스트림 애플리케이션에서 drop-in replacements으로 대체할 수 있습니다. 이러한 특징은 semantic segmentation과 depth prediction을 포함한 dense prediction downstream task을 크게 개선 가능함을 실험적으로 보여줍니다.
Method
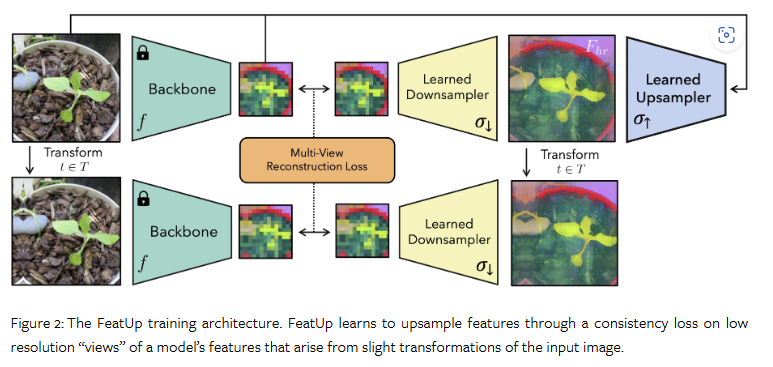
FeatUp의 주된 컨셉은 저해상도 특징의 여러 ‘시점 (view)’가 있다면 이에 대한 일관성을 통해 고해상도 특징을 추론하도록 학습이 가능하다는 점입니다. 저자는 이를 구현하기 위해서 NeRF으로부터 영감을 얻어 프레임워크를 구축합니다. NeRF에서는 scene 내의 여러 시점의 영상 간의 일관성을 학습하기 위한 3D scene의 implicit representation을 구축하는 방법에 영감을 얻어, FeatUp에서는 여러 저해상도 특징 맵에 일관성을 적용하여 업샘플러를 구축합니다.
저자는 위와 같은 아이디어를 기반으로 Joint Bilateral Upsampling (Kopf et al., 2007)에 기반한 lightweight, forward-pass upsampler와 implicit network 기반 업샘플링을 소개합니다. 여기서 implicit network는 영상 별로 학습되며 임의의 해상도에서 쿼리가 가능합니다. fig 2에서 전반적인 FeatUp 아키텍처에 대한 개요를 확인할 수 있습니다.
전반적인 프레임워크의 첫 번째 단계는 시점에서 따른 low-resolution feature를 생성하여 하나의 high-resolution output으로 정제하는 것입니다. 시점에 따른 일관성을 부여하기 위해서 jitter (small pads, scales, horizontal flips)를 통해 입력 영상에 대한 transform을 수행하여 서로 다른 시점의 저해상도 특징 맵 모음을 추출합니다. 이러한 영상 변화을 통해 업샘플러를 훈련하기 위한 하위 특징 정보를 제공할 수 있습니다.
이후, 서로 다른 시점으로 가정하는 저해상도 특징맵으로부터 consistent high-resolution feature map을 구축합니다. 다운샘플링할 때 저해상도 jittered features를 재현하는 latent high-resolution feature map을 학습할 수 있다고 가정합니다. FeatUp의 다운샘플링은 ray-marching과 유사한 메카니즘을 가지고 있습니다. NeRF에서는 3D->2D로 렌더링되는 것처럼, FeatUp의 다운샘플러는 고해상도 특징을 저해상도 특징으로 변환합니다. NeRF와 달리 각 시점에 따른 파라미터를 사전에 추정할 필요가 없습니다. 대신 각 영상의 ‘jitter’에 사용된 파라미터로부터 다운샘플링 전에 학습된 고해상도 특징에 동일한 변환을 적용합니다. 그런 다음 gaussian likelihood loss를 사용하여 다운샘플링된 특징을 기존의 low-resolution feature map과 비교합니다. 이는 고품질의 고해상도 특징 맵은 다른 시점에서 관찰된 특징을 재구성 할 수 있어야 한다는 점에서 착안됩니다.
이를 공식화 한다면, trasform t \in T 으로부터 영상 x가 변화되거나 그대로 사용되며, model backbone f, σ↓는 학습 가능한 downsampler, σ↑는 학습 가능한 upsampler를 의미합니다. 예측된 고해상도 features는 F_{hr} = σ↑(f(x), x)를 의미합니다. 이를 기반으로 multi-view reconstruction loss는 다음과 같이 구성됩니다.
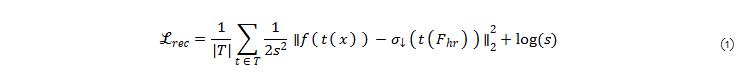
여기서, ∥⋅∥는 L2 norm, s=N(f(tx))로 spatially-varying adaptive uncertainty 파라미터화를 위한 small linear network N에 해당합니다. 이를 term을 통해 MSE loss가 업생플링이 불가능한 outlier features를 적응적으로 파악 가능하도록 한다고 합니다.
Choosing a Downsampler
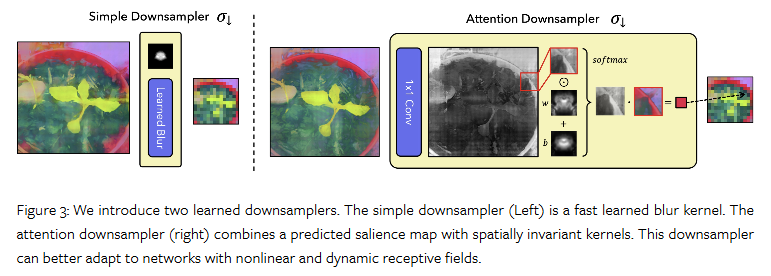
해당 섹션에서는 learned downsampler σ↓을 다룹니다. 여기서 저자는 선택 가능한 2가지 옵션-빠르고 간단한 learned blur kernel과 보다 attention-based downsampler-을 제시합니다. 제안된 두 모듈 모두 nontrivial transformations을 통해 특징의 ‘space’이나 ‘semantics’를 변경하지 않고 가까운 neighborhood 내의 특징만 보간합니다. fig 3에 두 가지 선택 사항을 보여줍니다.
먼저, simple downsampler는 learned blur kernel로 특징을 흐리게 처리하며, 각 채널에 독립적으로 적용되는 컨볼루션으로 구현할 수 있습니다. 학습된 커널은 음수가 아닌 값으로 정규화되고 합이 1이 되도록 하여 특징이 동일한 공간에 유지되도록 합니다. 해당 다운샘플러는 효율적이지만 동적 변화에 따른 물체의 형태를 파악하는 능력이 부족하다는 문제가 있습니다.
이를 위해 극복하기 위해 저자는 다운샘플링 커널을 공간적으로 조정하는 보다 flexible attention downsampler를 제안합니다. 간단히 말해, 이 컴포넌트는 1×1 컨볼루션을 사용해 고해상도 특징로부터 saliency map을 예측합니다. 이 saliency map을 learned spatially-invariant weight and bias kernels과 결합하고 결과를 정규화하여 특징을 보간하는 spatially-varying blur kernel을 생성합니다. 이는 다음과 같이 표현 가능합니다.
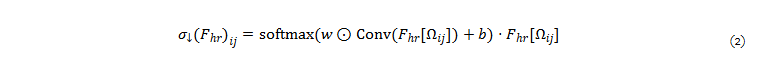
여기서, σ↓(F)_ij는 i,jth 구성 요소, F_{hr}[Ω_{ij}]는 다운샘플링된 특징에서 i, j 위치에 해당하는 고해상도 특징의 패치를 나타냅니다. (w and b are learned weight and bias kernels). 두 다운샘플러의 주요 하이퍼파라미터는 커널 크기이며, receptive fields가 더 큰 모델의 경우 커널 크기가 더 커야 합니다.
Choosing an Upsampler
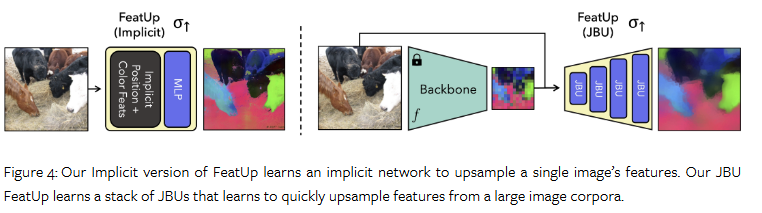
해당 섹션에서는 가장 중요한 upsampler σ↑를 다룹니다. 저자는 두 가지 부류 제시합니다. 먼저, Joint Bilateral Upsamplers (JBU)의 반복으로 구성된 “JBU”는 영상 뭉치로부터 일반화된 업샘플링 전략을 제시합니다. 다음은 “implicit”로 implicit network를 한 영상에 오버피팅 시켜 아주 선명한 고해상도 특징맵을 얻는 방법을 제시합니다. 두 부류 모두 전반적으로 동일한 구조와 loss를 활용합니다. 이는 fig 4에서 확인 가능합니다.
Joint Bilateral Upsampler. JBU의 반복으로 구성된 feedforward upsampler는 다음과 같이 수식화 할 수 있습니다.
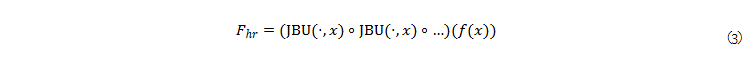
여기서 ∘ 는 function composition에 해당하며, f(x)는 low-resolution feature map, x는 original image에 해당합니다. 해당 구조는 빠르고, 입력 영상의 high-frequency details을 업샘플링 프로세스에 직접 통합하기 때문에 f의 아키텍처와는 독립적인 것이 특징입니다. 정리하자면, 저자는 original JBU (Kopf et al., 2007)을 high-dimensinal sinals이 가능하며, 커널을 학습 가능하도록 변경한 것이라고 보면 됩니다. 해당 기법은 high-resolution signal G를 low-resolution feature map F_lr의 길잡이로 활용합니다.
이 아키텍처는 빠르고, 입력 이미지의 고주파 디테일을 업샘플링 프로세스에 직접 통합하며, f 의 아키텍처와는 독립적입니다. 구체적으로 길잡이는 각 픽셀의 이웃 Ω에 따라 3×3 정사각형으로 설정합니다. k ( ⋅ , ⋅ )는 두 벡터가 얼마나 가까운지를 측정하는 similarity kernel에 해당합니다. 저자가 제안한 joint bilateral filter는 다음과 같습니다.
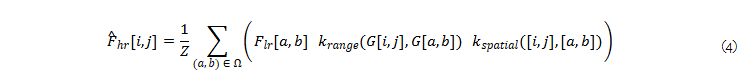
여기서, Z는 kernel이 합 1이 되도록 하는 normalization factor이며, σ_{spatial}의 Euclidean distance 내의 학습 가능한 Gaussian kernel k_{spatial}는 다음과 같이 도식화 가능합니다.
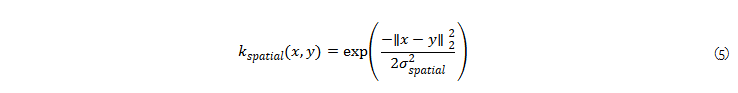
+ 말이 복잡한데 두 공간 정보 간의 L2 norm을 하이퍼 파라미터 σ_{spatial}에 따라 수치화한 것이라고 보면 됩니다.
k_{range)는 temperature-weighted softmax를 활용합니다. 이는 MLP태운 guidance signal G에 따른 inner products로 구성됩니다. 이는 다음과 같습니다.
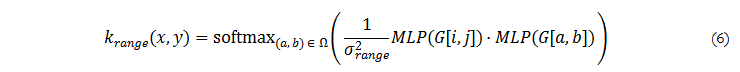
여기서 σ_{range}^2는 temperature로서 동작합니다. 저자가 밝히길 기존 JBU는 고정된 Gaussian kernel로 동작합니다. 허나, 일반화된 동작을 수행하기 위해 데이터에 따라 MLP를 통해 적응적인 업샘플러를 만들 수 있었다고 합니다. 해당 논문에서는 MLP는 two-layer GeLU (30-dimensional hidden and output vectors)로 구성했다고 합니다. 만약에 guidance pixel이 low-resolution feature와 일치하지 않는 경우에는 bilinear-interpolated features를 했다고 합니다. 또한, resolution independence을 위해 spatial kernel에서 [ – 1 , 1 ]로 정규화된 좌표 거리를 사용합니다.
추가로 JBU를 적용하는 경우에는 저조한 속도와 메모리 효율성을 보이는 문제가 있었다고 합니다. 이를 해결하기 위해서 저자는 torch.nn.Unfold를 활용해 CUDA 프로그램으로 JBU를 직접 구현했다고 합니다. 이를 통해 메모리 효율성과 속도는 10배 이상 향상 시켰다고 합니다.
Implicit. 두번째 upsampler architecture는 NeRF와 매우 유사하며, single image의 high-resolution features를 implicit function F_hr=MLP(z)로 파라미터화 시킵니다. small MLP를 통해 영 좌표와 강도를 주어진 위치에 대한 high-dimensional feature에 매핑합니다. 그런 다음, Fourier features를 사용하여 암시적 표현의 공간 해상도를 개선합니다. 또한, 공간 측면의 Fourier features에 Fourier color features 추가하여 모델이 원본 영상의 high-frequency color information을 활용 가능하다는 것을 보입니다.
이를 수식화 하면 다음과 같습니다. 먼저, h(z, ^ω)은 frequencies ^ω의 벡터와 함께 input signal z의 component-wise discrete Fourier transform을 의미합니다. 여기서, e_i와 e_j는 범위 [-1, 1]에서의 two-dimensional pixel coordinate fields을 의미합니다. 추가로 :는 concatenation을 의미합니다. 해당 프로세스에서의 high-resolution feature map은 다음과 같이 표현 가능합니다.
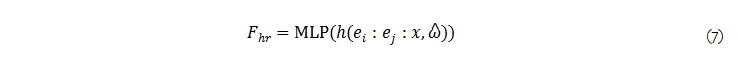
여기서 MLP는 dropout(p=.1)과 layer normalization이 가해진 3-layer ReLU 구성됩니다.
두 번째 업샘플러 아키텍처는 단일 이미지의 고해상도 특징을 암시 함수 ? ℎ ? = MLP ( ? )로 파라미터화하여 NeRF와 직접적인 유사성을 도출합니다.
+ 저자가 말하길, 기존 연구들도 inference-time training approach 사용하는 경우가 있다고 하네요.
++ 말로는 엄청 복잡한데 쉽게 말하면 ^ω는 low-resolution feature이고, e는 positinal encoding, x = Fourier color features라고 보시면 됩니다.
Additional Method Details
Accelerated Training with Feature Compression. FeatUp’s implicit network의 메모리와 학습 속도를 향상시키기 위해서 spatially-varying features를 k=128로 주성분 요소로 압축합니다. 저자가 밝히길 128 components가 주 정보의 ~96%를 가진다고 하네요? (출처가 없어서 아쉽네요) 이를 통해 ResNet-50은 학습 시간을 60배 줄였다고 합니다. [TODO] JBU에서는 배치 내에서 PCA 대신해서 random projection matrices을 적용했다고 하는데 코드를 봐야 자세한 방법을 알 것 같습니다.
Total Variation Prior. implicit feature의 high resolution features의 spurious noise를 피하기 위해서 small total variation smoothness prior (λtv=0.05)를 추가합니다. 이는 다음과 같습니다.
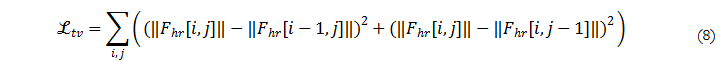
해당 기법은 feature 자체에 정규화 기법을 적용 하는 것보다 빠르기도 하며, 개별 구성 요소들이 과도하게 규제되는 것을 방지하는 것을 목적으로 합니다. JBU에는 오버피팅이 발생하지 않기 때문에 해당 기법을 적용하지 않습니다.
Experiment
해당 실험에서는 여러 업생플링 기법과 여러 백본 모델 (지도학습, 자기 지도 학습)에서 비교를 수행합니다. 또한, dense prediction downstream인 semantic sementation(ADE20k)과 mono depth estimation (MegaDetph)에서 비교 실험을 보입니다.

Visualizing upsampling methods. fig 5에서 드라마틱한 향상 결과를 보여줍니다. 해당 결과는 PCA로 시각화한 결과물에 해당합니다.

Robustness across vision backbones. 다양한 백본 모델에서 강인한 결과물을 보여줍니다. fig 6
Transfer Learning for Semantic Segmentation and Depth Estimation
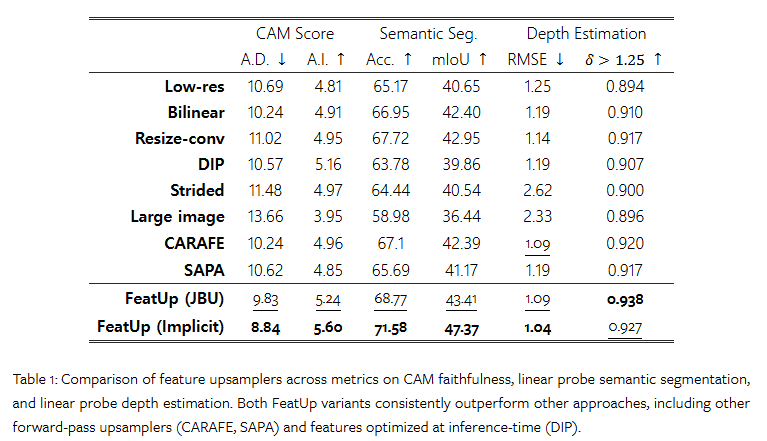

Tab 1과 fig 7, tab 2에서 Semantic Segmentation and Depth Estimation에서의 성능을 보여줍니다. 해당 실험에서 linear probing을 재학습 시키지 않고 입력값만 변경하여 적용한 결과물에 해당합니다. 모든 결과에서 향상된 결과를 보여줍니다.
End-to-end Semantic Segmentation
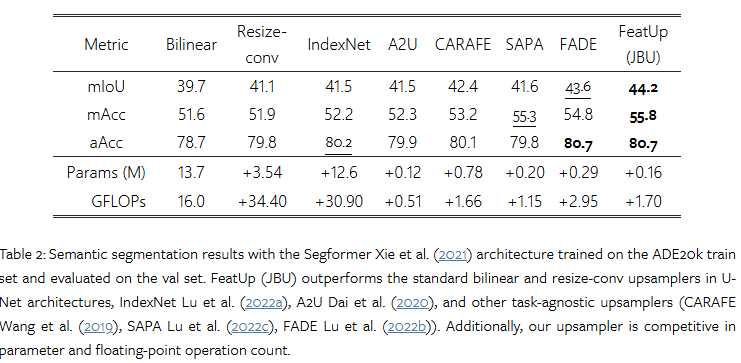
tab 2에서는 Semantic Segmentation에서 활용된 베이스 모델의 업샘플링 모듈을 JBU로 대체하여 학습을 진행했을 때의 결과를 보여줍니다. 실험 결과, 모든 기법 대비 향상된 결과를 보여줍니다.
+ 애매한 점이 베이스라인 모델 대비… 성능은 하락되었습니다. 베이스 라인 성능과 비교하자니 뭘 말하고 싶었는지… 애매해지는 것 같습니다…
————————-
흠… 논문이 뭔가 말을 엄청 부풀려서 작성했네요… 간단한 말을 너무 어렵게 말해서… 이것도 필요한 스킬인지 긴가민가한 논문이긴 했습니다.
해당 논문을 읽게 된 계기는 ‘jitter’로부터 일관성을 학습하는 컨셉이 평행한 구조의 프레임에 놓여진 컬러-열화상 간의 도메인 갭을 줄이는 데에 큰 힌트가 될 것이라고 판단하여 읽긴 했는데 읽을 수록 확신이 들지 않는 방법론인 것 같습니다. 가장 큰 이유는 “implict”는 학습된 단일 영상에서만 기능하고 “JBU”는 정성적 결과에서 보이는 바와 같이 상대적으로 떨어지는 결과물을 보입니다… 쩝… 고민을 많이 해봐야 겠네요…
좋은 리뷰 감사합니다.
Jitter를 이용하여 low-resolution에서 feature의 일관성을 부여한다는 점은 이해가 가지만, 이를 고해상도에서는 어떻게 학습을 위한 정보를 생성하는 지 잘 이해가 되지 않습니다. Upsampler에 의존하는 것이며, Upsampler는 이미지의해상도를 유지하여 생성해낸 feature를 GT로 삼아 학습된 것으로 이해하였는데, 그렇다면 복잡한 정보가 임베딩되어있던 low-resolution의 feature의 표현력이 유지가 되는 지 궁금합니다.
좋은 질문 감사드립니다.
Q1. 복잡한 정보가 임베딩되어있던 low-resolution의 feature의 표현력이 유지가 되는 지 궁금합니다.
A1. 진짜 좋은 질문인데요. 제 생각에는 해당 질문이 해당 논문의 한계를 지적하는 질문이라고 생각합니다. 업샘플링하면서 디테일 생기는 부분들에서는 새로운 특징 표현력이 생기는 것이 아니라 적응적으로 bi-linear 된다고 봐도 무방합니다. 즉, 유지가 된다는 표현은 정확한 표현은 아닙니다. 로컬한 정보가 생명인 태스크에서는 오히려 저조한 성능을 보이겠죠. 허나, 업샘플링으로 새롭게 생긴 픽셀들에는 유사한 정보들이 배치되기 때문에 주변 정보와 유사한 정보가 출력되는 픽셀 레벨의 태스크, segmenation or depth estimation에서는 어느정도 효과가 있는 것 같습니다.