제가 이번에 리뷰할 논문도 affordance grounding분야의 논문입니다. 제가 이전에 리뷰했던 Affordance Grounding 관련 논문들은 action이나 대상 object에 대해 단순한 방식이나 정해진 템플릿으로 입력하여 그에 해당하는 영역을 추론하는 방법론이었는 데, 해당 논문은 사람의 목표를 이해하기 위해 자연어 지시를 사용하는 Affordance Grounding 연구입니다. Affordance Grounding이 실제로 적용되는 상황을 고려하여 유연하게 대응할 수 있다는 점이 흥미로워 리뷰하게 되었습니다.(예를 들면, 사람이 ‘갈증을 해소’하기 위해 “물을 달라”는 요청을 했을 때 대응되는 물이 없어도 음료라는 대안을 고려할 수 있도록 합니다.) 해당 논문은 복잡한 사람의 지시를 이해할 수 있도록 Natural Language Instructions 기반의 Affordance Grounding 문제를 새롭게 정의하였으며, 기존 연구들보다 더 복잡한 scene level에서도 affordance 대상 영역을 찾는 연구입니다. 리뷰 시작하겠습니다.
Abstract
Affordance grounding은 객체의 상호작용에 해당하는 영역을 찾는 것으로, embodied AI와 로봇 조작 테스크에서 중요한 기술입니다. 그러나, Affordance grounding을 위해서는 사람의 지시를 이해하고 영상에서 어떤 물체를 어떻게 이용해야 목표를 달성할 수 있을 지에 대한 이해가 필요하므로 어려운 테스크입니다. 최신 연구들의 경우 action label을 입력하여 객체의 영역을 찾아내는 방식으로, 사람의 목적을 놓치는 경우가 발생하며, 또한 주로 단일 객체가 존재하는 상황에서의 affordance 영역을 찾는 방식으로 이루어져 맥락 정보를 고려하지 못하며, 실제 적용 환경인 복잡한 장면에서 여러 객체의 affordance 영역을 localization하는 데 어려이 있습니다. 이러한 어려움을 해결하기 위해 저자들은 처음으로 natural language instructions을 도입하여 이전의 단순 action label을 입력하던 방식을 확장하여 복잡한 사람의 지시를이해할 수 있도록 새로운 프레임워크인 WorldAfford를 제안하였습니다. WorldAfford는 LLM에서 affordance 지식을 보다 정확하고 논리적으로 추론할 수 있도록 새로운 Affordance Reasoning Chain-of-Thought Prompting를 설계하였으며, SAM과 CLIP을 사용하여 이미지에서 affordance와 관련있는 객체를 찾고 affordance region localization모듈을 통해 객체의 affordance영역을 찾아내게 됩니다. 이를 위해 저자들은 LLMaFF 데이터 셋을 구축하여 새로운 작업에 대한 밴치마킹과 프레임워크 검증을 수행합니다. 저자들은 제안한 LLMaFF뿐만 아니라 기존 Affordance Grounding(action label을 입력으로 사용)에서 모두 SOTA를 달성하였으며(AffordanceLLM을 레퍼런스하였는데, 성능에는 리포팅되어있지 않아 비교를 해보니 비슷하거나 조금 더 좋은 성능을 달성한 것을 확인하였습니다.), 특히 WorldAfford는 여러 객체에서 affordance영역을 인식할 수 있으며, 객체 영역에서 정확히 매칭되는 영역이 없을 경우 대안을 찾아 예측 결과를 제공할 수 있음을 확인하였다고 합니다.
Introduction
로봇이 복잡한 장면에서 물체를 잘 조작하기 위해서는 사물의 어떤 영역에서 어떤 상호작용이 일어나는지를 파악하는 것이 중요합니다. Affordance Grounding은 주어진 지시에 해당하는 조작 대상의 특정 상호작용 영역의 위치를 찾는 것을 목표로 하며, 이는 물리적인 환경과 상호작용하는 Embodied AI의 확장과 효율성 및 유연성 증대를 위한 잠재력을 가집니다. 이러한 이유로 최근 Affordance Grounding 분야가 활발히 연구되고 있습니다.
그러나 Affordance Grounding은 사람의 지시에 대한 이해를 통해 능동적으로(affordance grounding 연구들은 수행해야 하는 action에 대응되는 객체와 영역을 모델 스스로 파악하고 인식한다는 점에서 능동적이라 표현하고, detection과 같은 태스크는 수동적이라고 표현합니다) 대상 객체와 상호작용 영역을 찾아야 한다는 점에서 어려운 문제입니다. 또한, 해당 환경에 대한 분석을 통해서 어떤 도구가 적절한 지와 상호작용 영역에 대해 인식해야 합니다. 이에 대해 VLM 모델을 통해 해결이 가능할 것으로 기대되지만, 아직은 충분한 성능을 달성하지 못하였다고 합니다.
최근 연구들은 물체와 사람이 상호작용하는 이미지(=exocentric image, 사람이 물체를 조작하고있음)로부터 학습된 지식을 객체 중심의 이미지(=egocentric image, 객체를 조작하지 않음)로 전이하는 방식으로, 데이터 셋 수집을 쉽게 만들었으며, 다양한 지시에 대응되는 영역을 인식 가능하도록 상당한 발전이 이루어졌습니다. 그러나 기존 방식은 행동에 대한 라벨을 단순한 형태로 제공하므로, 사람의 복잡한 목표를 표현할 수 없으며 객체 중심의 이미지에서 affordance 영역을 식별하도록 학습되므로 객체의 맥락 정보를 고려하거나 복잡한 장면에서 대응 영역을 찾기에는 어려움이 있어 실제 환경에서 적용되기에는 부족함이 있습니다.

따라서 해당 논문은 최초로 Natural Language Instructions 기반의 Affordance Grounding이라는 작업을 정의하여, 단순한 action label을 사용하던 기존 연구(Fig.1의 2행과 같이 “write”, “catch”, “hold”라는 단순한 action을 사용함)를 복잡한 자연어 로 확장(Fig.1의 3행과 같이 이미지에 대해 자연어 지시가 사용됨)하였습니다. 이를 위해 저자들은 LLM(해당 논문은 GPT-4를 이용합니다)과 SAM, CLIP을 통합한 새로운 프레임워크 WorldAfford를 제안하였습니다. 먼저 LLM을 통해 자연어 지시를 처리하였으며, 이때 Affordance에 대한 지식을 보다 정확하고 논리적으로 추론하기 위해 Affordance Reaoning Chain-of-Thought Prompting(AARCoT)을 새로 디자인하였습니다. 이후 SAM과 CLIP을 활용해 LLM이 추론한 행동과 관련된 객체를 인식하도록 하며, Weighted Context Broadcasting(WCB)모듈을 제안하여 affordance 영역을 착는 모듈에 통합하므로써 풍부한 정보를 제공하는 객체에 집중하고 여러 객체들의 영역을 인식할 수 있도록 하였다고 합니다. 저자들은 Natural Language Instruction 기반의 Affordance Grounding 문제를 새롭게 정의하며 이에 대한 벤치마킹과 제안한 프레임워크를 검증하기 위해 이미지-자연어 지시문-수동 라벨링된 affordance maps로 이루어진 새로운 데이터 셋 LLMaFF를 구축하였으며, 실험을 통해 기존의 Affordance Grounding 연구의 벤치마크 데이터 셋인 AGD20K와 새로 제안한 데이터 셋인 LLMaFF에서 기존 연구를 능가함을 보였습니다.
해당 논문의 컨트리뷰션을 정리하면
- Natural Language Instruction 기반의 Affordance Grounding 테스크를 새롭게 정의하여 affordance grounding을 단순 action 지시에서 자연어 지시로 확장
- 새로운 테스크를 위한 LLM과 Vision 모델을 통합한 프레임워크 WorldAfford 제안하였으며, 해당 프레임워크는 LLM에서 Affordance 정보를 추론하기 위해 Chain-of-Thought 프롬프트 방식을 도입하였고 다중 객체로부터 affordance 영역을 추론하기 위해 weighted Context Broadcasting 모듈을 제안함
- 새로운 테스크의 벤치마킹을 위한 데이터 셋 LLMaFF 구축
- 다양한 실험을 통해 WorldAfford가 기존 데이터 셋인 AGD20K와 새로운 데이터 셋인 LLMaFF에서 모두 SOTA를 달성함을 검증
Related Work
LLM and Chain-of-Thought
Chain-of-Thought(CoT)는 질문에 대한 답을 구하는 과정에 단계별 추론을 수행하도록 하는 방식으로 최근 연구들을 통해 CoT는 복잡한 작업을 처리함에 있어 LLM이 성능을 크게 향상시킬 수 있음이 입증되었다고 합니다. 저자들은 이러한 CoT 방식을 Affordance Grounding에 최초로 도입하였으며, LLM과 Affordance Reasoning Chain-of-Thought(ARCoT)를 통해 open-world에서 사람의 지시를 이해하고 다양환 환경의 사물에 대한 추론이 가능하도록 하였다고 합니다. (Chain-of-Thought 논문은 재찬님의 X-Review에 자세하게 나와있습니다..?)
Task Definition and LLMaFF Dataset
Task Definition
이미지 \mathbf{I}와 자연어 지시문 t가 주어졌을 때 자연어 지시문 기반의 affordance grounding은 scene 레벨의 이미지에서 객체의 상호작용 영역들을 찾는 것을 목표로 합니다. 기존 연구에 비해 영상 내 객체의 수와 입력되는 지시문의 복잡도에 제한이 없다는 점에서 현실 세계로의 적용을 고려한 세팅 입니다.
LLMaFF Dataset

새로운 문제 정의에 대한 연구와 벤치마킹을 위해 저자들은 550개의 복잡한 scene 이미지와 영상에 대응되는 자연어 지시문과 수동으로 라벨링된 affordance map으로 구성된 데이터 셋 LLMaFF를 제안합니다. 데이터 셋 수집 파이프라인은 위의 이미지 Fig. 2와 같으며, Sparse한 GT 포인트로부터 가우시안 커널을 적용하여 GT를 생성한 AGD20K와 다르게 LLMaFF는 지시문에 대한 여러 객체의 affordance map을 제공하기 위해 dense point를 사용하였다고 합니다.(Fig. 2의 3번 이미지를 확인하시면 객체 영역에 여러 점을 찍어 GT를 생성하는 것을 확인하실 수 있습니다.) 데이터 수집 과정은 여러 객체가 존재하는 real-world의 이미지를 수집한 뒤, 어노테이터가 영상에 대한 상호작용을 고려하여 지시문을 자유롭게 생성합니다. 이후 지시문에 해당하는 영역에 dense한 점을 찍어 json 파일을 만든 뒤, annotation 프로그램을 통해 가우시안 필터를 적용하여 GT mask를 만들어 냅니다. 마지막으로 이에 대해 시각화하여 어노테이터가 지시문에 대응되는 지 검토하고, 조정이 필요하면 3번으로 돌아가 지시문에 해당하는 점을 다시 찍고 이후 과정을 반복합니다. 이러한 어노테이션 방식은 결국 사람의 주관이 들어가게 되는데, 이에 대한 검증은 따로 없어보입니다. (AGD20K도 마찬가지로 어노테이터의 주관이 들어가며, 이를 인정을 받을 수 있을지는 해당 논문이 어디에서 accept 되는 지를 보고 파악해야할 것 같습니다.. 아직은 어디에 붙었다는 정보를 찾지 못했습니다..)
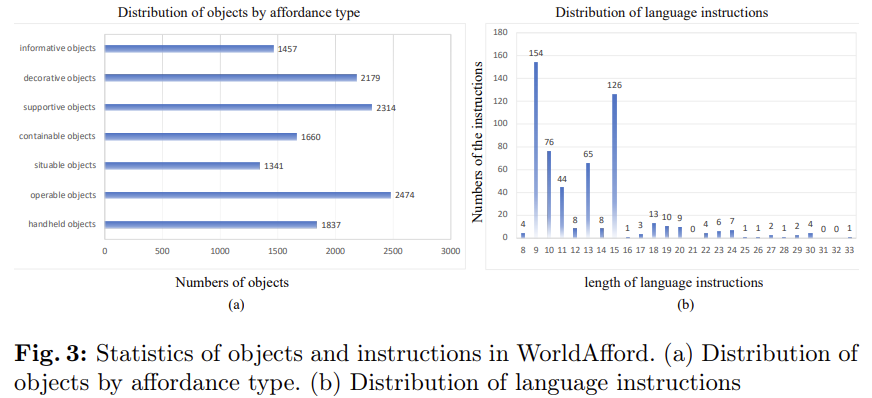
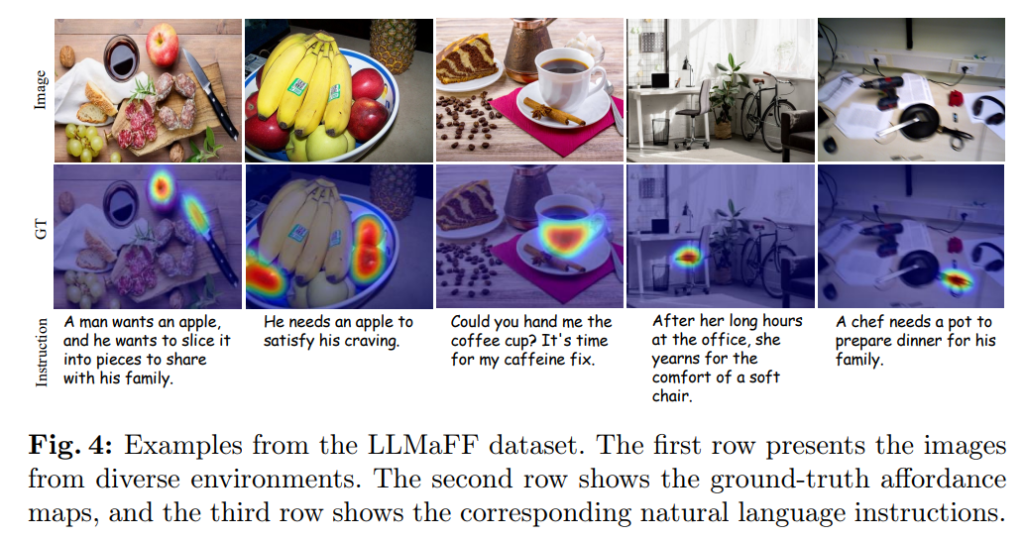
사물은 affordance에 따라 크게 8가지 유형으로 분류하였으며(handheld objects, operable objects, sitable objects, containable objects, supportive objects, decorative objects, and informative objects), Fig. 3은 8가지 유형에 해당하는 객체의 수와 데이터 셋에서 사람의 지시어 길이에 대한 그래프로, 지시문의 길이가 다양하다는 것을 확인하실 수 있습니다. 아래의 Fig. 4는 LLMaFF 데이터 셋의 예시로, 다중 객체들로 이루어진 이미지에 대하여 지시문과 그에 해당하는 객체들의 영역이 표현된 것을 확인하실 수 있습니다.(AGD20K 예시와 비교해보시면 조금 더 객체의 영역이 정밀하게 활성화되어있는 것을 확인하실 수 있는 데, 이는 여러 점을 찍고 반복해서 검토하는 방식을 적용하므로써 보다 정밀한 affordance map을 만들 수 있었던 것으로 보입니다.)
{kind=link}
WorldAfford Framework
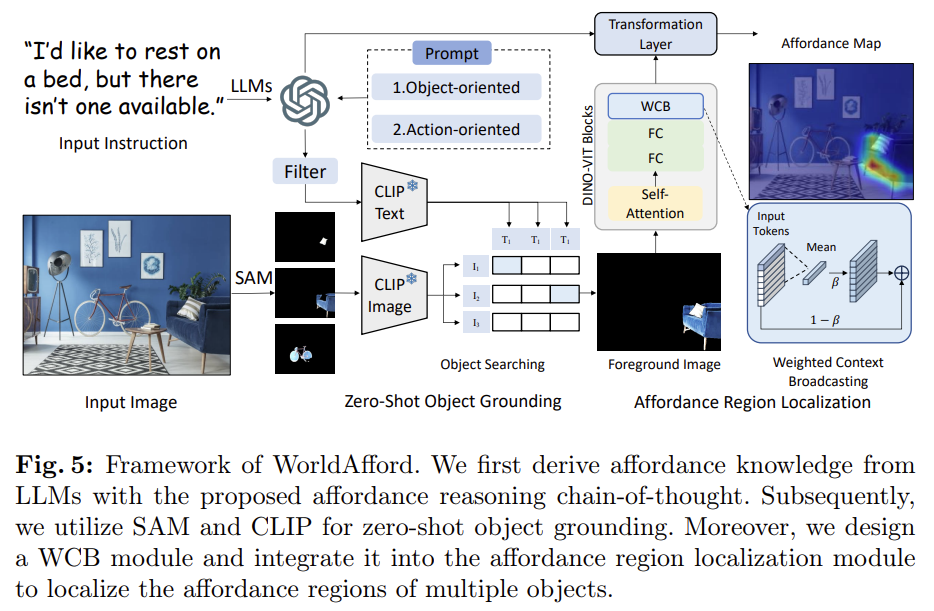
본 논문은 낮은 training cost를 들여 복잡한 지시문을 이해하고 다중 객체의 affordance 영역을 인식하기 위한 WorldAfford 프레임워크를 제안하였습니다. 위의 Fig. 5를 통해 해당 프레임워크를 확인하실 수 있으며, WorldAfford는 먼저 LLM을 통해 사용자의 지시문을 분석한뒤, Chaion-of-Thought 프롬프트를 통해 affordance에 대한 지식을 구합니다. 이후 SAM과 CLIP을 활용하여 zero-shot 기반의 다중 객체의 위치를 인식을 수행한 뒤, LLM이 제공하는 지식과 관련된 객체에 대한 segmentation과 선택을 수행합니다. 또한 Weighted Context Broadcasting(WCB) 모듈을 affordance region localization 모듈에 통합하므로써 다중 객체의 affordance 영역을 인식합니다.
1. Affordance Reasoning Chain-of-Thought Prompting
사람은 지시가 주어질 경우 먼저 어떤 객체를 작업에 활용 가능한 지 고려한 뒤, 복잡한 지시를 수행하기 위한 과정을 일련의 간단한 동작들로 분해합니다. 저자들은 이러한 사람의 인지 과정을 모방하고 대규모 데이터에서 학습된 광범위한 지식을 활용하기 위해 LLM을 통해 affordance 영역을 추론하고자 하였으며, 이때 직접적으로 affordance 영역을 추론하기보다 Chain-of-Thougth(CoT) 프롬프트 방식을 도입하여 LLM의 기능을 향상시킵니다.
해당 논문에서 제안된 CoT는 (1)객체 지향적인 추론 프롬프트와 (2)행동 지향적인 프롬프트라는 두가지 방식으로 구성되며, 이를 통해 중요한 객체나 동작에 대한 정보를 제거한 뒤 가장 적절한 객체가 없을 경우 대체할 수 있는 도구를 인식할 수 있도록 하여 다양한 시나리오에서 적응적으로 작동 가능함을 입증할 수 있었다고 합니다.

(1) Object-Oriented Reasoning Prompting
먼저 LLM을 활용하여 주어진 지시를 수행할 수 있는 객체에 대해 추론합니다. 이때 작업을 수행함에 있어 여러 객체가 필요할 수 있음을 고려하여 LLM은 객체의 카테고리 집합 \mathcal{O}=LLM(k,t,p_{obj})을 추론하며, 여기서 k는 객체 집합의 크기, t는 주어진 자연어 지시문을 나타내며 p_{obj}는 객체 지향적 추론을 위한 프롬프트로 아래와 같이 설계되었습니다.
- Prompt: “What are the [#k] most common objects that can be used if [#t]?”
- Output: Chair…, Hammock…, Blanket and Pillows… (k개의 객체)
객체 지향적 추론을 통해 LLM이 지시를 수행하기 위해 다양한 객체를 고려할 수 있도록 하며, 이를 통해 최적의 객체가 존재하지 않을 경우에도 대체 가능한 객체를 연결하여 명령을 수행할 수 있도록 하였으며, 이렇게 추론된 객체의 카테고리 집합은 이후 행동 지향적 추론에 활용됩니다.
(2) Action-Oriented Reasoning Prompting
복잡한 자연어 명령을 다루는 해당 연구는 LLM의 사전지식을 활용하여 복잡한 명령을 여러 개의 하위 작업(행동)으로 분해합니다. 사전에 정의된 predicate list 중 적절한 predicate를 선택하여 객체 집합 \mathcal{O}에 할당하여 하위 행동 집합 \mathcal{A}=LLM(\mathcal{O},l_p,t,p_{act})를 생성합니다. 여기서 l_p는 사전에 정의된 predicate list, t는 지시문이며, p_{act}는 행동 지항적 추론 프롬프트로 아래와 같이 설계되었습니다.
- Prompt: “Select skills from [#lp] to interact with the above [#O] to help me if [#t]?”
- Output: sit on the chair…, lie on the hammock…, hold the blanket and pillows… (k개의 행동 집합으로, 객체와 predicate로 이루어짐
이렇게 추론된 행동들은 이후의 affordance localization 모듈의 입력으로 활용되며, LLM을 통해 객체 수준의 지식과 작업 수준의 지식을 통합할 수 있게 됩니다.
2. Zero-shot Multiple Object Grounding
LLM으로 구한 affordance에 대한 지식을 시각 정보와 통합하기 위해 저자들은 SAM과 CLIP을 활용합니다. SAM과 CLIP은 zero-shot 기반의 다양한 테스크에서 안정적인 성능을 보여주어 광범위하게 활용되고 있습니다. 저자들은 먼저 SAM에 이미지를 입력하여 N개의 segment mask를 생성합니다. 이러한 마스크는 의미론적 정보가 부족하며, 객체의 관련 여부를 고려하지 못합니다. 따라서 지시에 대응되는 객체 mask만을 얻기 위해 CLIP을 적용하여 마스크의 형태와 앞서 LLM으로 구한 객체 카테고리 사이의 유사성을 계산합니다. 구체적으로는 segmentation mask에 해당하는 영역에 해당하는 시각 정보만을 원본 이미지에서 추출하여 cropped regions \mathbf{m}을 CLIP image Encoder E_{image}로 인코딩하고, 객체의 카테고리 정보 \mathbf{o}는 CLIP의 text encoder E_{text}로 인코딩 한 뒤, 해당 마스크가 i번째 객체 카테고리로 분류될 확률은 아래의 식(3)을 통해 구합니다.
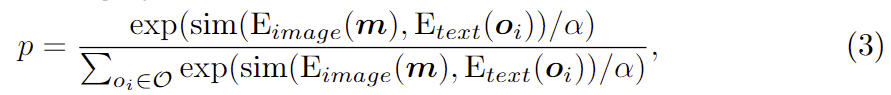
- sim(,): cosine 유사도 함수
- \mathcal{O}: LLM으로 구한 객체 카테고리 집합
- \alpha: 스케일링 계수로, 실험적으로 0.1로 설정
이렇게 구한 확률은 특정 마스크가 i번째 카테고리에 대항할 확률로, 임계값 이상일 경우에만 유효하다고 판단하여 해당 마스크 영역을 전경으로 간주하고 나머지는 배경으로 간주하는 full-view(크롭된영역만이 아니라) segmentation mask를 생성합니다. 이는 입력 이미지 크기로 affordance region loalization에 추가정보로 사용됩니다.
3. Affordance Region Localization
주어진 지시문에 해당하는 affordance 영역의 위치를 찾기 위해 LOCATE를 베이스로 사용하며, 2가지 개선을 통해 Grounding 성능을 향상시켰다고 합니다. (LOCATE Affordance Grounding을 위해 객체를 활용하는 영상으로 학습한 지식을 객체 중심의 영상으로 전이하는 방법론으로, 해당 방법론에 대한 자세한 정보는 제가 이전에 작성한 X-Review를 참고해주세요!); (1) Zero-shot multi-object grounding과정에서 구한 전경 영역만 남긴 full-view mask를 이용하며, (2) Weighted Context Broadcasting(WCB) 모듈을 제안하여 DINO-ViT에 통합하므로써 모델이 객체의 우선순위를 지정할 수 있도록 하였다고 합니다.
해당 과정은 앞서 구한 full-view mask를 활용해 이미지에서 객체와 관련 없는 부분은 모두 마스킹을 하고 관련된 이미지만 DINO-ViT로 전달하여 객체 파트에 대한 feature를 추출합니다. 여기에 WCB 모듈을 설계하고 Fig. 5에서 확인할 수 있듯 WCB를 DINO-ViT에 통합하여 N개의 패치 토큰 시퀀스가 주어졌을 때 평균 context 토큰과 input 토큰에 가중치를 주어 결합하며, 이는 아래의 식 (4)로 정의됩니다.
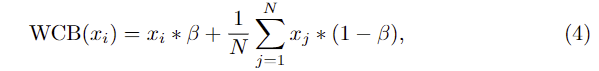
- \beta: 경험적으로 결정된 하이퍼파라미터
WCB는 모델이 학습할 때 정보를 많이 제공하는 객체에 집중할 수 있도록 하며, 이후의 실험 파트에서 WCB를 도입하므로써 기존 연구보다 성능 개선이 가능함을 입증하였습니다.
DINO-ViT로 생성된 feature map은 feed-forward 레이어와 2개의 conv 레이어로 이루어진 Transformation 레이어를 통해 정제된 뒤, LOCATE의 학습 방식을 따라 affordance를 학습합니다. affordance region 예측을 위해 1×1 convolution 레이어를 사용하여 채널수를 사전에 정의된 predicate list의 action 카테고리 수로 투영합니다. LLM에서 제공한 action 카테고리에 해당하는 affordance map을 집계하여 normalization을 수행한뒤 0~1 사이의 값으로 만들어 최종 output을 생성합니다.
Experiments
Dataset and Metrics
저자들이 제안한 데이터 셋 LLMaFF 뿐만 아니라 기존의 벤치마크 데이터 셋인 AGD20K를 이용하여 저자들의 방법론을 검증합니다. AGD20K는 학습을 위한 20,061장의 객체 활용 이미지와 6,060장의 객체 이미지로 구성된 Affordance Grounding을 위한 유일한 대규모 데이터 셋으로, 평가를 위해 1,675개의 이미지로 구성된 test set을 활용하여 단일 action label이 주어졌을 때의 affordance grounding 성능을 확인합니다. LLMaFF 데이터는 550장의 복잡한 환경에서 이미지와 자연어 지시문, affordanc map으로 구성되었으며, LLMaFF를 통해 자연어 명령어 기반의 Affordance Grounding에 대한 평가를 수행합니다. 평가지표는 기존 연구를 따라 KLD, SIM, NSS를 이용하며, 각 지표에 대한 간단한 설명은 아래와 같습니다.(이에 대한 자세한 설명은 이전 리뷰를 참고해주세요.)
- Kullback-Leibler Divergence (KLD)
- 두 확률 분포의 차이를 측정하며 작을수록 예측 분포와 실제 분포가 유사함을 의미
- Similarity (SIM)
- 예측 분포와 실제 분포의 유사도를 측정하며, 값이 클수록 예측과 실제 분포가 유사함을 의미
- Normalized Scanpath Saliency (NSS)
- GT와 예측 사이의 분포의 유사성 및 대응성을 평가하며, 값이 클수록 높은 일치도를 의미
<AGD20K>
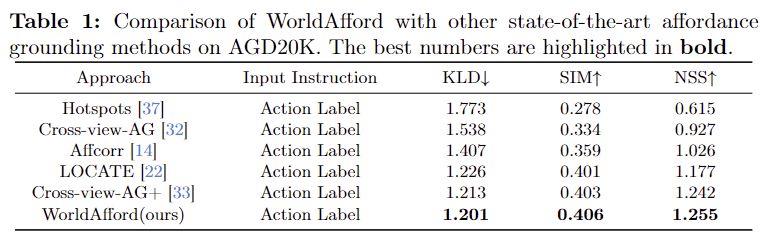
- 위의 Table 1은 기존의 Affordance grounding 방식과 비교를 위해 AGD20K 데이터 셋에서 성능을 비교한 결과입니다.
- 기존 방법론과 다르게 WorldAfford는 자연어 지시문을 입력으로 사용하므로 직접적인 비교가 어려우므로, affordance region localization 모듈의 입력으로 action label만 사용하도록 변경하여 평가를 하였다고 합니다.
- 기존 방법론과 비교했을 때 WorldAfford의 성능이 가장 뛰어남을 확인할 수 있습니다.
- 아래의 Fig. 7은 정성적 결과로, GT와 가장 유사하고 국소적인 영역에 집중된 결과를 확인하실 수 있습니다.

<LLMaFF>
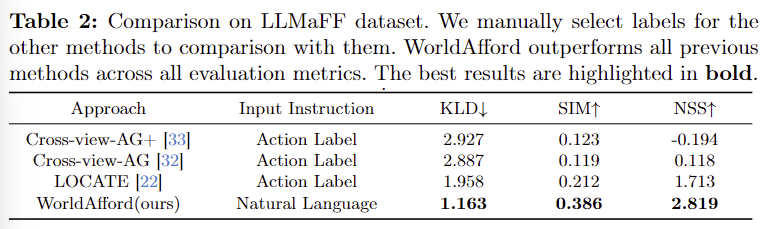
- Table 2는 해당 논문에서 새롭게 제안한 자연어 지시문 기반의 Affordance Grounding에 대한 평가를 위해 LLMaFF 데이터 셋에서 평가를 수행한 결과입니다.
- 기존 방법론들은 action label만으로 학습하였으므로 지시문에 action GT 라벨을 제공하고, WorldAfford는 자연어 지시문을 입력으로 사용하였다고 합니다.
- 실험 결과 저자들이 제안한 방식이 복잡한 장면 이미지에서 affordance 영역을 효과적으로 예측할 수 있음을 확인할 수 있습니다.
- 특히 AGD20K에서 좋은 성능을 보였던 Cross-view-AG+가 NSS에서 마이너스 값을 달성하였으며 이는 affordance 영역을 제대로 인식하지 못하고 있음을 나타냅니다. 이에 대한 저자들은 1) 새로운 테스크의 복잡성과 2)AGD20K에 과적합 되었을 가능성을 언급합니다.
- Cross-view-AG와 LOCAE도 성능이 상당히 하락하였으며, 이러한 실험을 통해 기존 방법론들이 복잡한 scene 이미지에서 affordance 영역을 찾는 데 어려움이 있음을 보였습니다.
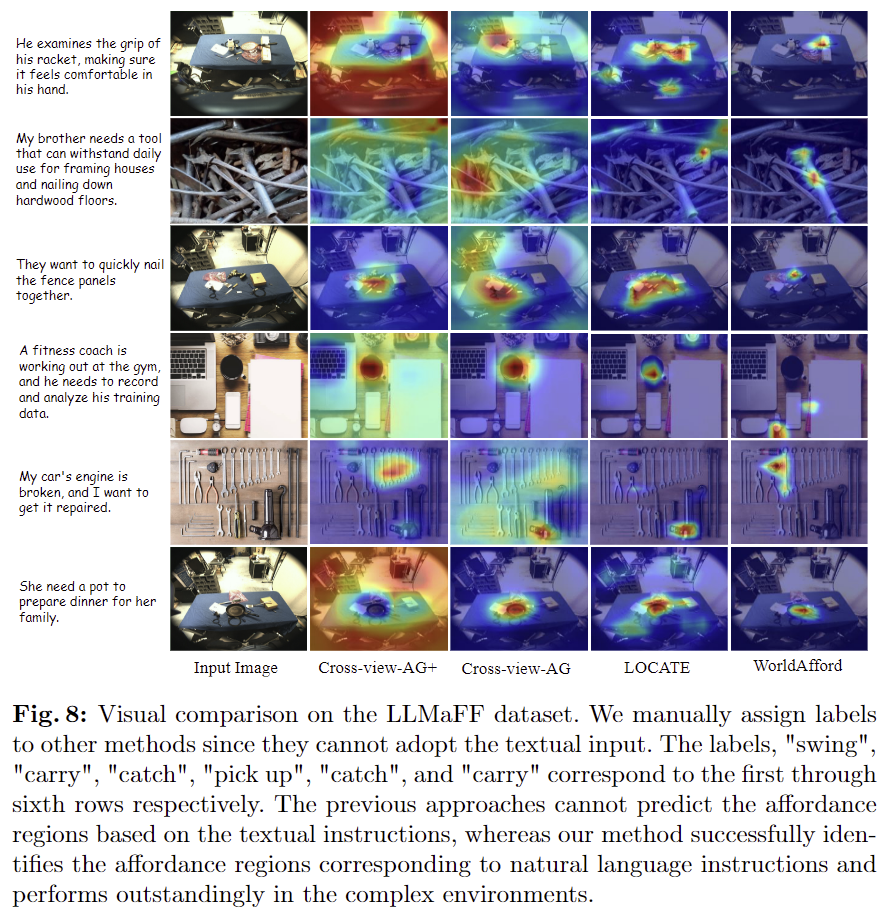
- 아래의 Fig. 8은 정성적 결과로 Cross-view-AG+는 영상 내의 여러 객체에 대한 affordance 인식이 잘 이루어지지 않고 있음을 확인할 수 있으며, LOCATE의 경우 대체로 일부 객체에 집중하고 있으나 여러 객체를 구분하여 인식하지 못하며(3행의 경우 뭉터기로 예측되어있음) 이러한 기존 방법론과 비교했을 때 WorldAfford가 자연어 지시문에 적절한 영역에 국소적으로 예측됨을 확인할 수 있습니다.
Results on Comptex Language Instructions

- 복잡한 언어 지시를 기반의 affordance grounding에 대한 분석으로, 저자들이 제안한 문제는 단순 명령어와 다르게 사람의 지식에 대한 이해가 피료앟ㅂ니다.
- WorldAfford는 복잡한 affordance 영역을 성공적으로 인식하고 칼과 사과를 함꼐 slice하는 등 물체 사이의 상호작용을 여러 하위 작업으로 나누는 과정에서 고려할 수 있음을 보였습니다.
- 또한, 나무 판자와 못으로 의자를 제작하는 예시를 통해 WorldAfford가 톱질, 측정, 조립에 필요한 affordance 영역을 체계적으로 식별하고 활성화하여 여러 단계의 작업에 대한 전반적인 과정을 고려할 수 있음을 보였습니다.
- 이러한 결과를 통해 로봇으로의 적용을 위한 연구임을 어필하였습니다.
Generalization ability and learnable parameters
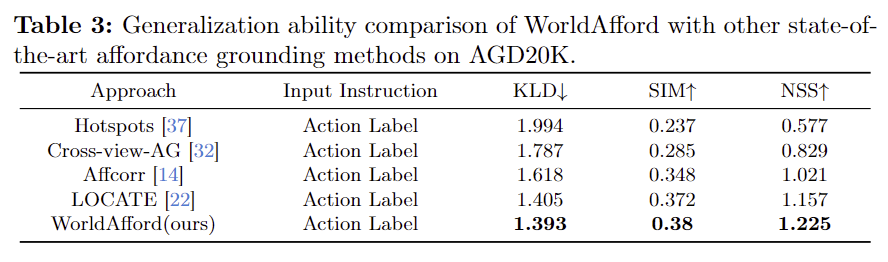
- Table 3은 일반화 성능을 보이기 위한 것으로, AGD20K에서 unseen test set에 대한 결과를 나타낸 것입니다.
- 일반화 성능도 기존 방법론보다 우수함을 보였습니다.
Ablation Study
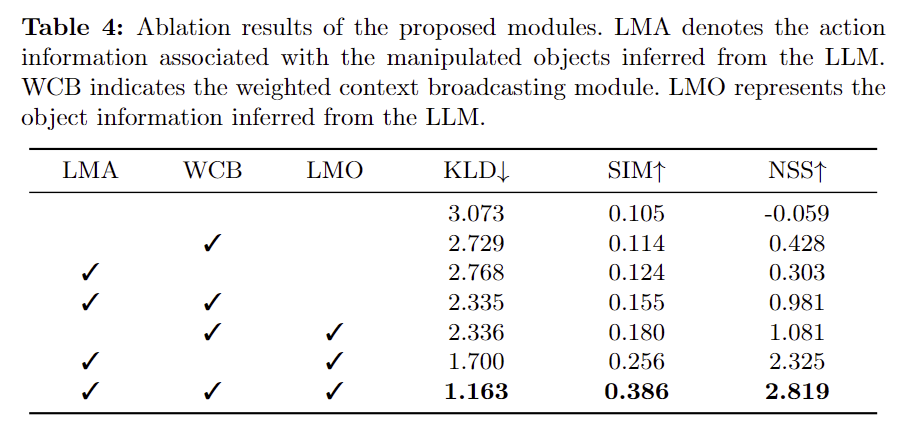
- Table 4는 Ablation study 결과로, ARCoT를 통해 LLM으로 추론된 객체에 대한 정보(LMO)와 행동에 대한 정보(LMA)가 모두 성능 개선에 도움이 되었음보였습니다.
- 또한 WCB 모듈을 도입하므로써 모델이 정보가 풍부한 객체에 집중하여 성능 개선이 이루어졌음도 보였습니다.

- Table 5는 배경 영역에 마스크를 적용하였을 때의 성능 개선 정도를 실험한 것으로, 객체와 무관한 시각 정보를 제거하므로써 성능이 크게 개선됨을 입증하였습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
AGD20K의 경우 Sparse한 GT 포인트로부터 가우시안 커널을 적용하여 GT를 생성한다고 하셨는데 GT 포인트를 Sparse하게 생성하는 이유가 궁금하고 여러 객체의 affordance map을 제공하기 위해서는 왜 sparse point가 아니라 dense point를 사용했는지 궁금합니다.
감사합니다.
질문 감사합니다.
우선 AGD20K가 sparce하게 GT 포인트를 생성하는 이유에 대한 내용은 따로 본 적이 없습니다. 데이터 셋 구축 과정에서 annotation cost를 줄이기 위한 것으로 추측됩니다. (AGD20K 는 Affordance Grounding 에서 유일한 large dataset 이라고 합니다. 실제로 본 논문에서 제안한 LLMaFF는 550개이며 AGD20K는20K 개 이상의 데이터로 구성되어있어 규모에 차이가 있습니다.)
또한 dense point가 필요한 이유에 대해서는 dense point들을 이용하여 더 정밀하게 affordance 영역에 대한 GT를 만듦으로써 여러 객체의 affordance가 근접한 경우에도 둘을 구분하여 GT를 생성하기 위한 것으로 이해하시면 좋을 것 같습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
GT mask를 annotation할 때 사람의 주관, 즉 bias가 들어가게 되는 것은 사실 affordance grounding이라는 태스크 자체의 성격(?)때문에 어느정도 인정해줘야되지 않을까라는 개인적인 생각이 듭니다.(물론 제가 이것을 인정하자 안하자 왈가왈부할 입장은 아니지만…) affordance 자체가 물체에 대한 사람의 상호작용이 있었던 부분에 대한 representation이기 때문에 GT도 왠지 사람의 주관(상식)이 들어가는 게 당연한 게 아닐까… 조심스럽게 생각합니다. 대신 그 상호작용의 방식이 사람마다 너무 다양하기에 획일화되지 않을 거라는 점이 또 양날의 검이 아닐까 싶기도 하네요. 이런 점이 generalized하게 잘 해결이 되려면 역시 승현님 말씀처럼 그냥 어디에 accept이 되는지를 동향을 지켜보는 게 맞을 것 같습니다.
추가로 GPT-4 + ARCoT, SAM, CLIP 등의 FM을 모두 짬뽕해버린 단순하면서도 강력한 아키텍쳐 모습이 좀 인상이 깊은데요, GPT-4에 ARCoT를 사용한다고 한들, zero-shot prompting 이기에 할루시네이션 문제를 무시할 수 없을텐데,
만약 prompting을 통해 제시된 잘못된 object들로 인해 SAM을 통해 생성된 N개의 segment mask에 해당하는 이미지 내 객체와 연관이 하나도 없을 시가 가장 큰 문제가 될 것 같습니다. 그렇게 돼서 마스킹된 부분의 객체와 object 이름 간 아예 다른 매칭이 이루어지거나, 전경이라 할 만한 어떤 것도 없이 그냥 background로만 넘어가버리면 학습에 문제가 좀 클 것 같은데 그런 부분에 대한 저자들의 고찰은 없을까요?
질문 감사합니다.
LLM이 잘못된 예측을 제공하거나 재찬님이 언급하신바와 같이 잘못된 매칭이 이루어지거나, 유의미한 전경이 전달되지 않았을 때에 대한 별도의 분석은 없었습니다. 기존의 다양한 연구에서 Foundation 모델이 좋은이해력을 가지고 있음을 보였다는 것을 기반으로 수행된 연구로 보입니다. 재찬님이 이야기하신바에 대한 보충 및 분석이 있었다면 좋을 것 같네요.
안녕하세요 좋은 리뷰 감사합니다 !
affordance 데이터셋에 대해 잘 몰라서 그럴 수 있지만 Fig.4의 예시에서 커피를 들어달라 할 때 커피 컵의 몸통 보다는 손잡이를 나타내야 할 거 같고, 사과를 자르는 데이터셋에서도 칼의 칼날보다는 손잡이를 표현하는게 적절하다는 생각이 듭니다. 이런 affordance map이 생성하는게 말씀하신거처럼 어노테이터의 주관적인 의견이 들어가기 때문일까요 ? 그럼 만약 모델이 예측한게 손잡이 부분을 예측한다면 이 결과가 GT와 다르다고 해서 정말 affordance를 잘못 예측했다고 판단하는 것이 맞을까라는 의문이 드는데 이에 대해서 승현님은 어떻게 생각하시는지 궁금합니다 !
그리고 affordance grounding에서 SAM을 사용할 때는 어떤 프롬프트를 사용하나요 ?? SAM의 사용 의도는 단순히 이미지에서 최대한 많은 물체에 대한 마스크를 얻기 위함이 맞을까요 ??
감사합니다.
질문 감사합니다.
우선 affordance는 특정 작업에 적절한 영역을 찾는 것으로, 여기서 적절이라는 판단은 어노테이터의 주관에 따를 수 밖에 없다고 생각합니다. 잡아야 하는데 칼날에 affordance 영역을 설정할 정도로 잘못 어노테이션 하면 그건 연구하려는 방향과 맞지 않다고 봅니다. 추가로, affordance segmentation과 같은 이전 연구는 픽셀수준으로 annotation을 제공하던 방식은, 작업을 크게 몇 가지(grasping, support, cutting 등)로 사전에 정의하여 학습을 수행하기도 하였습니다. AGD20K같은 경우는 sparse한 point를 찍고 그에 대한 가우시안필터를 적용하여 대략적으로 활성화를 시키는 방식으로 affordance 영역을 커버하였고, 해당 논문은 보다 세밀한 annotation을 하고자 여러 점을 찍고 그 영역을 다 포함하고자 한 것으로 보입니다. 따라서 해당 논문에서는 특정 affordance에 해당하는 영역이 누락되지는 않을 수 있을 것이라고 생각합니다..(이 의미가 아니라면..다시 질문주세요..하하)
또한, 여기서 SAM은 prompt를 설정하지 않고, 전체 영역에 대해 whole/part/subpart 수준의 output을 임의로 추출합니다. SAM을 사용하는 이유는 “많은 물체에 대한 마스크를얻는 것”이라기보다는 객체 영역에 집중하기 위한 것이 적절할 것 같습니다. 객체 영역에 집중하고 싶은데 일단 sam으로 여러 후보를 만들어두고, CLIP을 이용해서 지시문에 해당하는 객체에 집중할 수 있도록 설계된 것으로 이해하시면 될 것 같습니다.