Image Retrieval Tesk를 하다보니 Triplet loss 외에 어떠한 loss가 최근 Metric learning으로 나오고 있나 싶어서 서칭하다 보니 작년 ICCV 에 R2D2 저자의 좋은 논문이 있어서 가지고 와봤다.
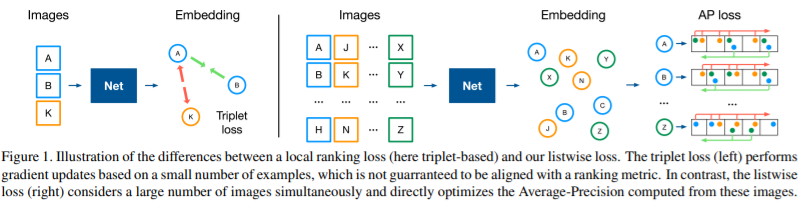
먼저 이 논문의 키 컨셉을 정리하면 다음과 같다:
- mAP(meat Average Precision) Loss를 Retrieval에 적용하여 최종 eval metric인 MAP 성능에 직접적인 영향을 끼치서 최종적으로 좋은 성능을 이뤄 냈다.
- 큰 배치 사이즈와 큰 resolution 의 영상을 관리하며 학습하는법을 제시한다.
MAP Loss를 적용시킨 List Loss를 적용하여 여러 벤치마크에서 SOTA의 성능을 기록하고 있다.
# Listwise Loss
기존 많이 쓰이는 Triplet loss는 [그림 1] 에서와 같이 단 세개의 영상을 가지고 Query image 와 Positive image는 가깝게 Negative image 와는 멀게 Descriptor를 학습한다. 하지만 이렇게 3개의 영상만을 보면서 학습하면 비교해야할 영상들이 너무 많아져 학습이 오래걸리게 되며 학습의 수렴은 계속 진행 된다. Triplet loss는 이렇지만 제시하는 listwise loss는 많은 배치의 영상을 한번에 비교하며 학습이 진행된다는 이점을 가진다. 그리고 mAP loss를 적용하여 최종 eval metric에 직접적인 성능향상을 이뤄낸다.
# 학습 방식
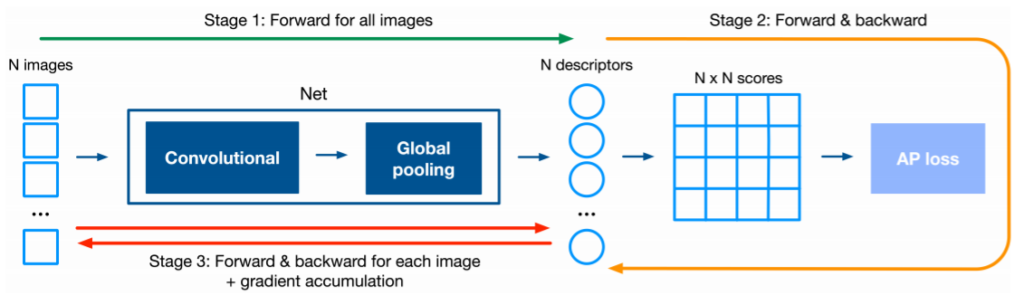
총 세번의 stage로 학습이 진행된다.
- Batch 내에 있는 모든 영상의 Descriptor를 계산한다.
- 추출한 Descriptor 를 Label활용하여 AP loss를 계산하고 Backward 전에 모든 영상의 미분값을 갖고있는다.
- 다시 Descriptor를 추출하고 영상 하나하나 Gradient를 누적시킨 후 마지막에 Network를 업데이트 합니다.
위 방식대로 학습이 진행되고 위 방식을 따르면 메모리와 시간을 단축시킬 수 있다고 한다.
Batch size가 4096 이라 하고 영상 사이즈를 800×800 이라 하니 위 방식이 얼마나 계산 메모리를 줄여주는지는 수도코드를 보고 확인 해야 할 듯 하다.
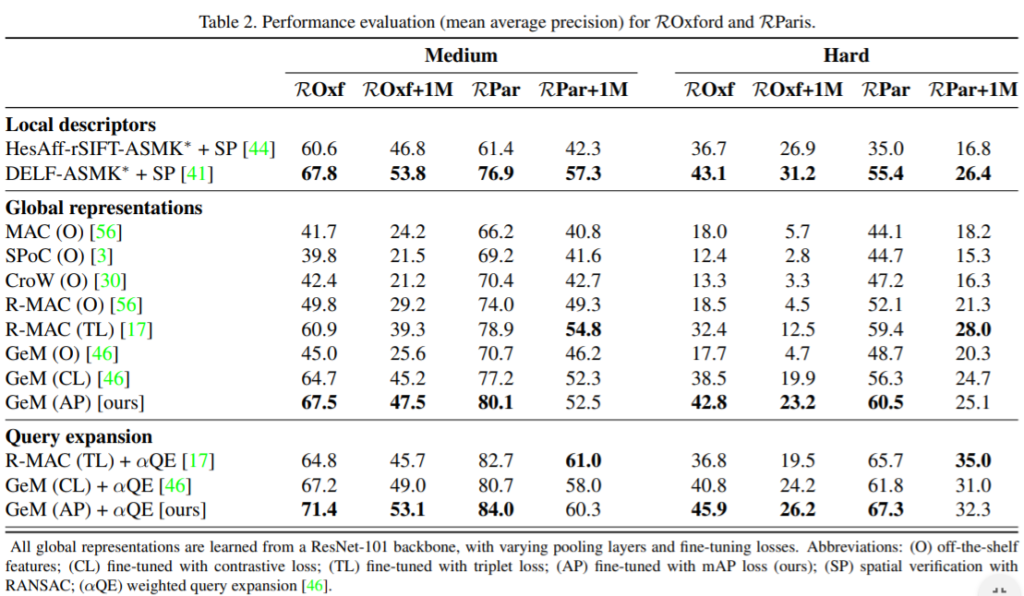
Oxford and Paris 데이터셋에서 Global representation 에서와 Query expansion을 추가한 결과에서 또한 성능이 SOTA인 것을 확인 할 수있다.