
논문: A Simple Framework for Contrastive Learning of Visual Representations
이번 논문 포스트는 Google Research에서 발표한 SimCLR (Simple framework for Contrastive Learning of visual Representations)입니다. 논문에서 언급한 핵심 방법과 성과는 (1) 심플한 data augmentation 방법을 조합하여 효율적인 예측을 하였고, (2) non-linear layer 2개를 추가하여 contrastive loss를 통해 성능을 올린 점, 마지막으로 (3) self-supervised learning에서는 batch의 크기와 훈련 step을 늘릴 경우 성능이 점점 향상된다는 것입니다.
SimCLR이 주목을 받은 이유는 세 가지로 볼 수 있습니다. 첫째, supervised learning의 한계점으로 지적된 labeled 데이터 확보의 어려움을 해결하기 위해 self-supervised learning 방법을 사용한 점. 둘째, 효율성이 높은 방법을 증명하기 위해 다양한 ablation 연구를 한 점. 마지막으로, 현대 AI의 거장 Hinton 교수님이 참여한 논문이라는 점입니다.

Google Research의 블로그에 있는 SimCLR에 대한 그림 설명(그림 1.)은 해당 framework가 어떻게 동작을 하는지 파악하는데 도움을 줍니다.
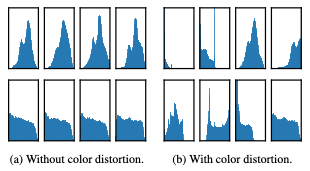
본 논문에서 제안하는 data augmentation 방법에서 color distortion의 중요성을 강조하고 있습니다. Data augmentation 방법은 두 단계로 수행하게 되는데 첫 번째 단계에서는 random cropping을 하고 원본 사이즈에 맞게 resize를 수행합니다. 그리고, 두 번째 단계에서 random color distortion과 random Gaussian blur를 수행합니다. 이렇게 두 단계로 나눈 이유에 대해 저자는 단순히 cropping을 한 것으로는 image의 histogram 분포가 그림2. 의 왼쪽과 같이 같은 경향성을 가지고 있어 다양성을 학습하기 어렵지만 color distortion을 적용한 경우 그림2. 의 오른쪽과 같이 다양한 분포를 보여주므로 성능을 향상시키는데 도움이 된다고 말합니다.
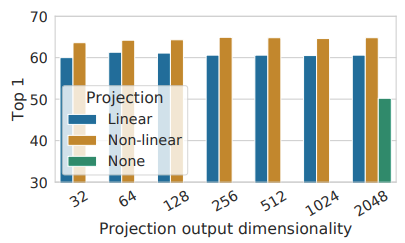
Data augmentation 단계를 수행한 후에 이미지의 특징을 추출할 때는 기존 supervised learning에서 학습한 pre-trained 모델을 가져와서 사용합니다. 이 논문에서는 ResNet-50[2]을 사용하며 추출한 특징을 가지고, 2개 층의 MLP를 학습하기 위해 NT-Xent라는 loss(수식1.)를 제안하고 있습니다. 그림 3. 은 각 MLP 사이에 non-linear한 ReLU를 사용하는 것이 더 성능이 좋은 ablation 연구를 보여주고 있습니다. 뒤에서 자세하게 설명하겠지만 batch 중에서 1개의 정답 이외의 다른 image들은 contrastive 하기 때문에 negative 예제이므로 아래와 같이 similar function(본 논문에서는 cosine distance)을 사용하여 loss를 계산하게 됩니다.
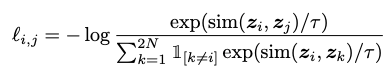
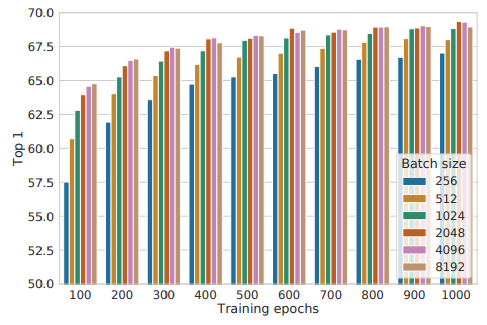
본 연구가 Google Research에서 진행되었기 때문에 역시 TPU를 사용한 결과를 보여주고 있는데요. 주목할 점은 supervised learning 학습은 step이 늘어날 수록 최고 성능에서 점점 낮아지는 것을 볼 수 있는데 그림 4. 와 같이 self-supervised learning은 학습 step이 늘어날 수록 그리고 batch가 늘어날 수록 성능이 점점 더 좋아지는 것을 보여주고 있습니다.
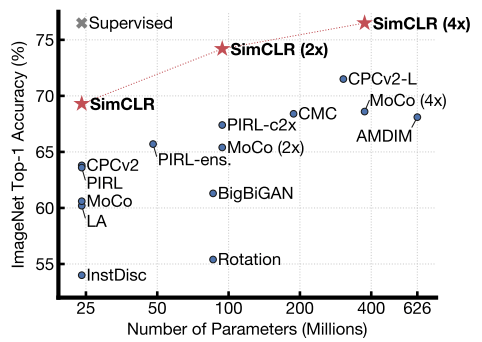
그 결과 그림 5. 와 같이 SimCLR은 self-supervised learning 방법 중에서 SOTA를 달성했으며 SimCLR(4x)의 경우 ResNet-50의 supervised learning 성능과 비슷한 성능을 보여주고 있습니다.
개인적으로 supervised learning에서 좋은 성과를 나타내는 AutoAugment[3] 가 self-supervised learning에서 효과를 나타내지 못하며 self-supervised learning에서 효과적인 augmentation 방법을 제시하는 근거에 대한 분석이 인상 깊었습니다. 단순하게 여러가지 방법을 시도해보고 가장 성능이 좋은 방법이라는 결과보다 본 논문이 제시하는 방법(color distortion)이 성능을 향상시킬 수 있는 원인에 대한 논리적인 분석 덕분에 설득력있다고 생각합니다.
참고:
[1] Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
[2] Deep Residual Learning for Image Recognition
[3] AutoAugment: Learning Augmentation Policies from Data