Before Review
안녕하세요 이번 리뷰도 Scene Graph Generation과 관련된 리뷰를 작성하였습니다.
이번 논문 같은 경우는 Weakly Supervised Learning 상황에서 기존 Scene Graph Generation 연구들의 문제점을 극복할 수 있는 새로운 방법을 제안한 논문 입니다.
논문 제목에서도 알 수 있듯, LLM을 적극 활용하여 Weakly Supervised Scene Graph Generation을 고도화 합니다.
리뷰 시작하겠습니다.
Preliminaries
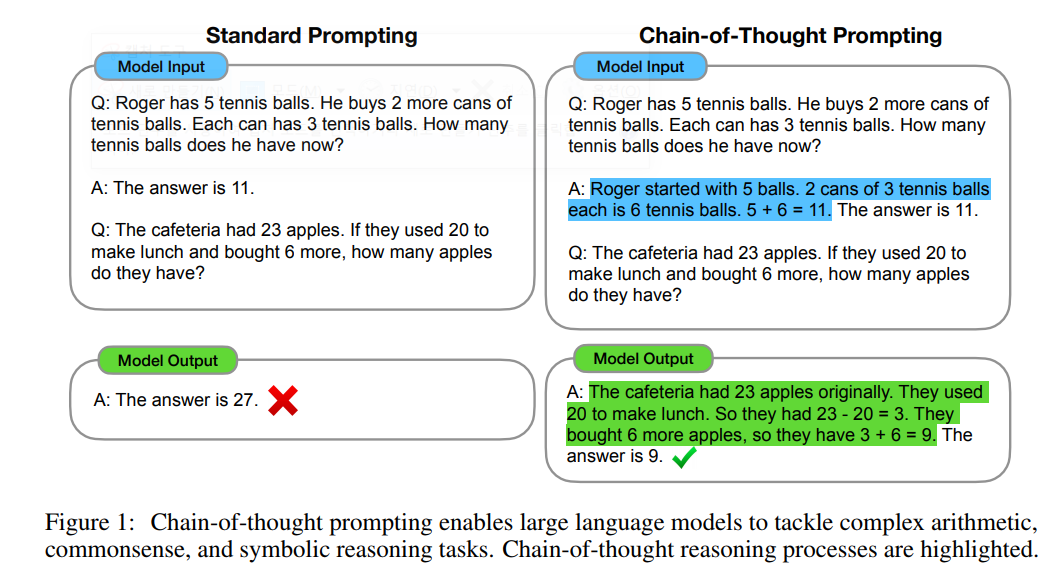
Chain of Thought Prompt (CoT)
저도 이번에 처음 알게 되었는데 LLM을 활용하는 상황에서 Prompt를 어떻게 정의 하는지도 원하는 답변을 얻는데 많은 영향을 끼친다고 합니다. 이 때 Chain-of Thought Prompt는
Introduction
Scene Graph Generation (이하 SGG)은 이미지에 존재하는 객체와 객체들 간의 관계를 예측하는 작업으로 High-level Scene Understanding 능력을 요구로 합니다. SGG는 이미지를 설명할 수 있는 <subject, predicate, object>로 구성된 triplet을 잘 찾는 것이 최종 목적이라 보시면 됩니다. 객체를 잘 찾는 것도 어려운데, 이 객체들 간의 semantic relationship까지 예측해야 하는 SGG는 아직 학계에서 challenging한 task로 정의되고 있습니다.
그 높은 난이도 때문에 기존 연구들은 box annotation과 predicate annotation을 같이 활용하는 fully-supervised 환경에서 연구를 진행하였습니다. 이미지 내의 객체들의 위치와 각 객체들끼리의 관계는 어떤 것들이 있는지 모델에게 알려주고 학습을 시키는 것이죠. Fully Supervised의 경우는 <subject, predicate, object>에서 subject와 object를 나타내는 box 좌표들을 제공하고 그들 간의 관계 정보인 predicate 까지 모델에게 알려줍니다.
당연히 annotation이 있으면 target data에 대해서는 높은 성능을 기대할 수 있지만 확장성 관점에서는 문제점이 존재합니다. 이를 해결하기 위해 연구자들은 Fully Supervised가 아니라 Weakly Supervised 상황에서 SGG를 연구하기 시작했습니다. Weakly Supervised SGG의 경우 박스 좌표와 predicate는 제공되지 않습니다. 대신에 이미지를 설명하는 caption이 제공됩니다. 그리고 이 caption을 가지고 <subject, predicate, object>를 잘 생성하는 것이 목적이죠.
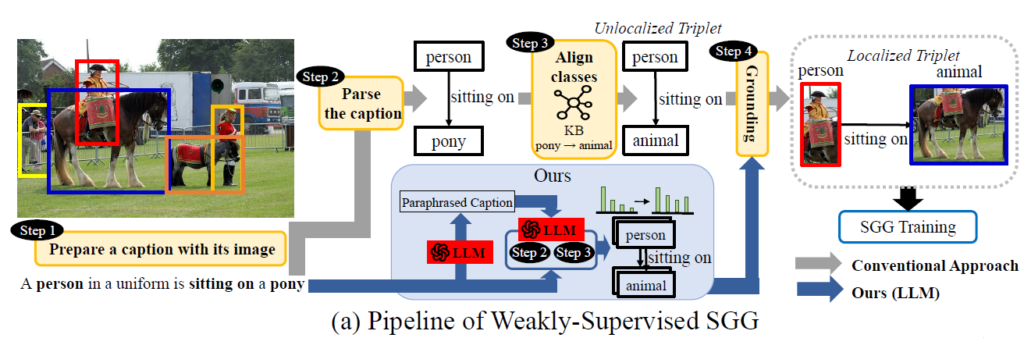
위의 그림은 일반적인 Weakly Supervised SGG의 Pipeline을 나타내는 그림 입니다.
- [Step1] Prepare a caption with its image : 말 그래도 이미지에 대응되는 caption을 준비해야겠죠. 위의 사진의 경우 “A Person in a uniform is sitting on a pony”라는 caption이 제공되고 있네요.
- [Step2] Parse the caption : 여기서는 Parsing tool을 이용해서 문장으로부터 간단한 Scene Graph를 Parsing 합니다. 명사구와 동사구를 추출하여 <person, sitting on, pony> 라는 triplet을 추출할 수 있습니다.
- [Step3] Align classes : 다음으로는 우리가 parsing한 triplet 내에서 우리가 target으로 하는 dataset에 존재하는 단어로 바꿔주는 작업을 진행합니다. 즉, target dataset에 존재하는 유의어로 변경해주는 작업이라 볼 수 있습니다. Pony라는 단어가 target data에 없어서 animal이라는 단어로 변경된 모습입니다.
- [Step4] Grounding : 앞서서 정의된 <person, sitting on, pony> 라는 triplet은 person과 pony가 어디에 있는 지 위치를 알려주지는 못합니다. 따라서 Weakly Supervised SGG는 unlocalized triplet을 각 연구별 제안하는 Grounding 방법을 통해 각 객체들의 위치를 알려주는 localized triplet으로 변환합니다.
그런데 기존의 Weakly Supervised SGG 연구들의 경우 [Step4]에만 집중하는 경향이 강했습니다. 당연히 [Step4]도 중요하지만 unlocalized triplet을 만드는 [Step2]와 [Step3]도 중요한 문제라고 저자는 지적합니다. 저자는 [Step2]아 [Step3] 과정에서 간과하는 두 가지 문제점을 처음으로 지적합니다.
Semantic Over-simplification
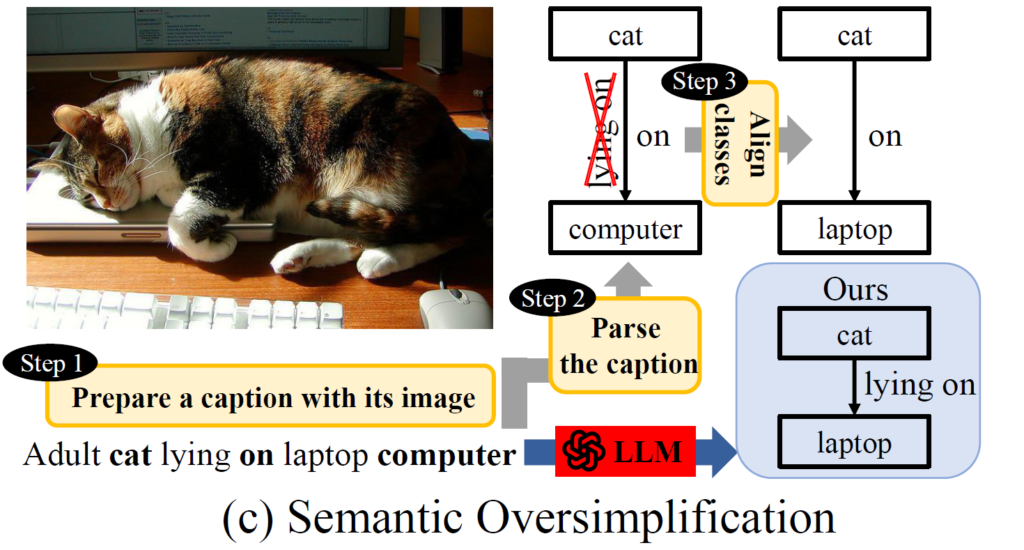
[step2]에서는 “Adult cat lying on laptop computer” 라는 image caption을 <adult, on, computer>로 변환 합니다. 이 과정에서 일반적으로 사용하는 Scene Parser는 내부적으로 heuristic rule 기반으로 동작하여 문장의 context를 제대로 이해하지 못하고 의미론적 내용을 축약 시키는 과정이 빈번하게 발생한다고 합니다.
앞선 “Adult cat lying on laptop computer” 에서 중요한 단어인 lying을 놓쳤기 때문입니다.
기본적으로 사용하는 Scene Parser는 rule-base라 다양한 predicate를 capture 하는 능력이 떨어져서 결국에 [Step2] 과정에서 만들어지는 predicate 분포가 long-tail 형태를 가지게 됩니다.
특히 50가지의 predicate 중에서 12개의 predicate는 원래 caption 내부에 존재함에도 Scene Parser가 capture하지 못해 아예 0개의 predicate를 가지는 것으로 파악되었습니다. 즉, 모델은 해당 predicate를 아예 예측할 수 없게 되는 것이죠.
Low-Density Scene Graph
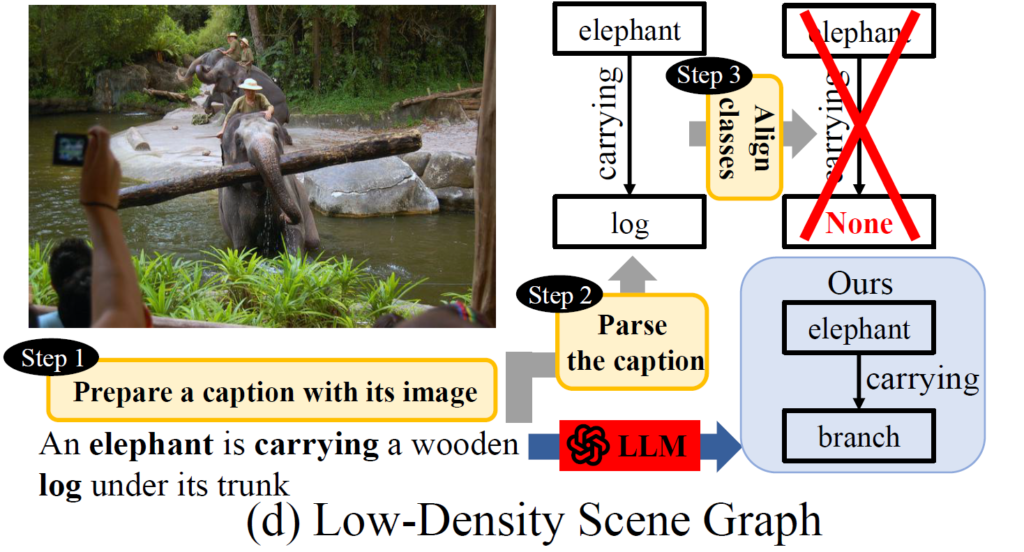
다음으로는 Scene Graph를 Parsing하고 우리가 원하는 target dataset에 존재하는 단어로 변환하는 과정에서 발생하는 문제 입니다.
앞서서 “An elephant is carrying a wooden log under its trunk” 에서 <elephant, carrying, log> 이라는 triplet을 추출했다고 했을 때 object에 해당하는 log의 유의어가 우리가 target으로 하는 dataset에 존재하지 않을 때 기존 [Step3] 과정에서는 해당 triplet을 학습에 사용하지 않는다고 합니다.
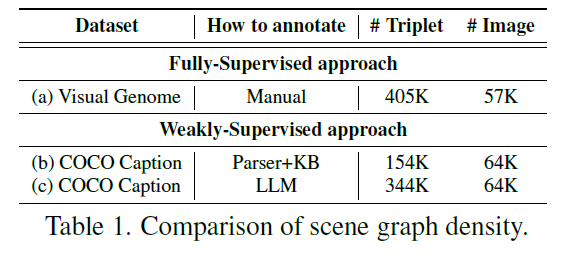
위의 테이블을 한번 살펴보도록 하겠습니다.
Fully Supervised SGG의 상황을 나타내는 (a) Visual Genome의 경우 57K 이미지에 대해서 405K의 triplet을 활용합니다.
다음으로 Weakly Supervised SGG 상황에서 (b) COCO Caption을 활용할 때 기존 Scene Parsing과 KB를 이용한 단어 변환을 진행하면 64K 이미지에 대해서 154K triplet 밖에 생성되지 않는다고 합니다.
기존 파이프라인대로 Weak Supervision을 만들면 정말 그 개수가 부족했다고 볼 수 있습니다.
저자는 위에서 정의한 Semantic Over-simplification와 Low-Density Scene Graph를 해결하기 위해 Large Language Model (LLM)을 활용하기로 합니다.
자세한 내용은 method로 넘어가서 얘기하는 것으로 하고 저자가 제안하는 방식으로 LLM을 활용한다면, 위에 테이블에서 154K의 triplet이 344K 까지 증가되는 것을 확인할 수 있습니다.
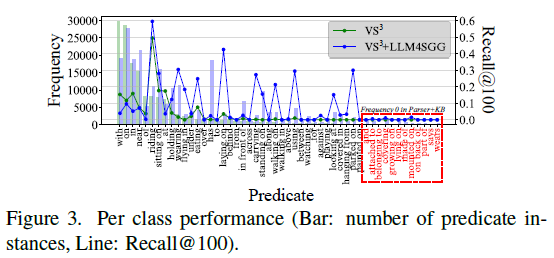
[Step2]와 [Step3]를 통해 생성되는 Predicate 분포를 비교해도 이전 Parser + KB 방식은 특정 predicate에 대해서는 빈도수가 아예 0으로 찍혀버리는 문제가 있었지만 저자가 제안하는 LLM 방식을 활용한다면 tail 쪽 분포에 대해서도 어느정도 대응이 가능하다는 것을 보여주고 있습니다.
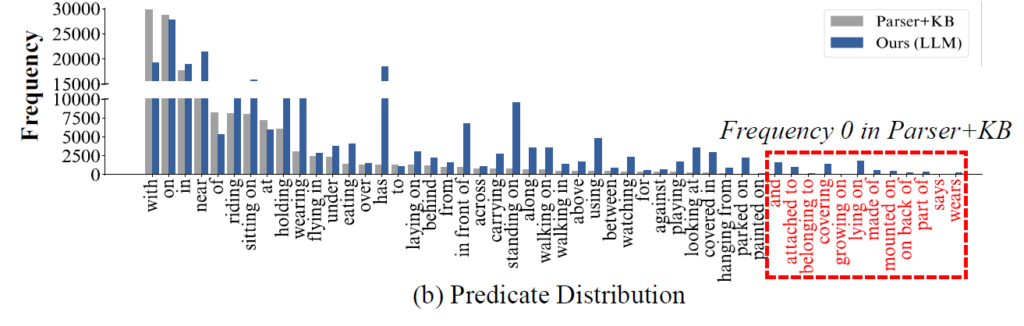
저자는 이렇게 Semantic Over-simplification와 Low-Density Scene Graph에 대한 문제 정의를 처음으로 진행하였고 LLM을 통한 고도화 방식을 Weakly Supervised SGG 전반적인 방법에 적용할 수 있는 방법을 제안하였습니다.
그렇다면 LLM을 어떻게 활용하여 두 가지 문제를 해결하였는지 method 부분에서 확인해보도록 하겠습니다.
Method
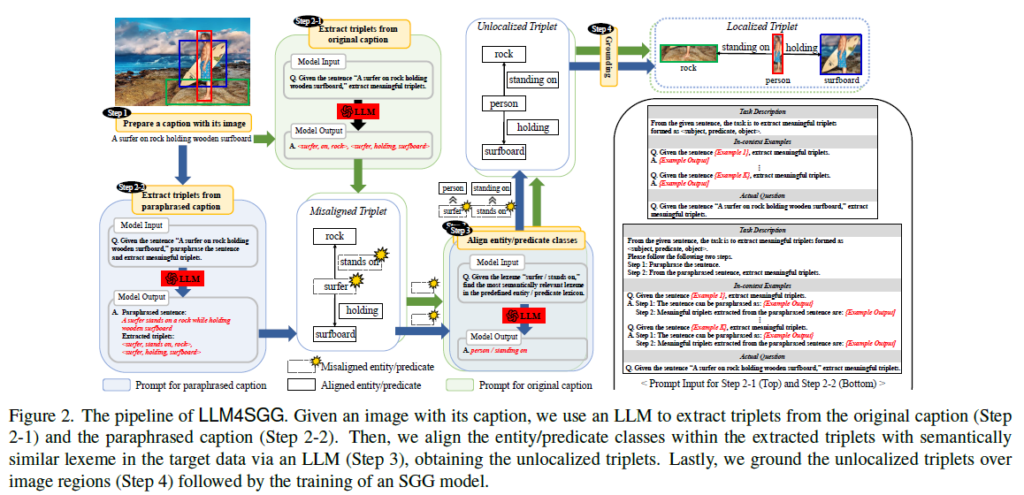
저자는 CoT prompt를 통해서 우리가 원하는 답변을 LLM에게 물어본다고 합니다.
먼저 Semantic Over-simplification 문제를 위해서는 LLM에게 주어지는 caption을 paraphrasing 시킵니다. 새롭게 생성된 paraphrasing caption을 바탕으로 다시 triplet을 추출하는 과정을 통해서 기존에 가지고 있는 caption 말고도 의미론적으로 다양한 triplet을 구성할 수 있도록 하였습니다.
다음으로 Low-Density Scene Graph 문제를 위해서, 생성된 triplet을 바탕으로 LLM에게 우리가 target으로 하는 dataset class 들과 유사한 단어들을 변환하는 과정을 맡깁니다.
우선 LLM에게 전달할 prompt를 어떻게 정의하는지부터 같이 알아보도록 하겠습니다.
Prompt Configuration
전체적으로 Prompt는 Task description, In-context examples, Actual question으로 구성되어 있습니다.

말 그대로 우리가 어떤 task를 물어볼 것 인지에 대한 자세한 설명과 그 task에 대한 몇 가지 예시 그리고 실제 우리가 물어볼 질문으로 구성됐다고 볼 수 있습니다.
Chain-1 Triplet Extraction via LLM (Step2)
앞서서 Scene Parser를 사용하면 heuristic rule 기반으로 작동하기 때문에 semantic 정보가 없어지는 문제점이 종종 발생했습니다. 이를 보완하기 위해 저자는 기존에 가지고 있는 caption 문장에 대해서 LLM에게 paraphrasing을 시킵니다.

위의 Prompt 예시는 두 가지가 있습니다. 위쪽 부분에 나와 있는 Prompt 예시는 original caption으로 부터 의미 있는 tripelt을 추출해 달라는 것으로 보입니다. 아래쪽 부분에 나와 있는 Prompt 예시는 original caption을 paraphrasing 후 의미 있는 triplet을 추출해 달라는 것으로 보입니다.
각 Prompt 마다 In-Context Example이 나와 있는데 이는 triplet 추출을 위해 LLM을 finetune 할 필요 없이 어느 정도 정확한 task 수행을 위한 장치라고 볼 수 있습니다.
이렇게 Task Description과 In-context Example 들이 정의되면 마지막으로는 실제 어떤 caption에 대해서 질문 할 것인지를 정해주고 LLM에게 답변을 받는 구조이네요.
상당히 간단합니다. 제가 직접 얘기하는 것 보다는 Supple에 나와 있는 실제 예시를 한번 같이 보는게 더 이해가 잘 될 거 같습니다.

Chain-2 Alignment of Classes in Triplets via LLM (Step3)
앞선 Chain1을 통해 의미 있는 triplet을 추출 했다면 이제 triplet에 존재하는 단어들을 다시 우리가 target으로 하는 dataset에 존재하는 단어로 변환하는 과정을 거쳐야 합니다.
이것도 LLM에게 바로 부탁할 수 있습니다.
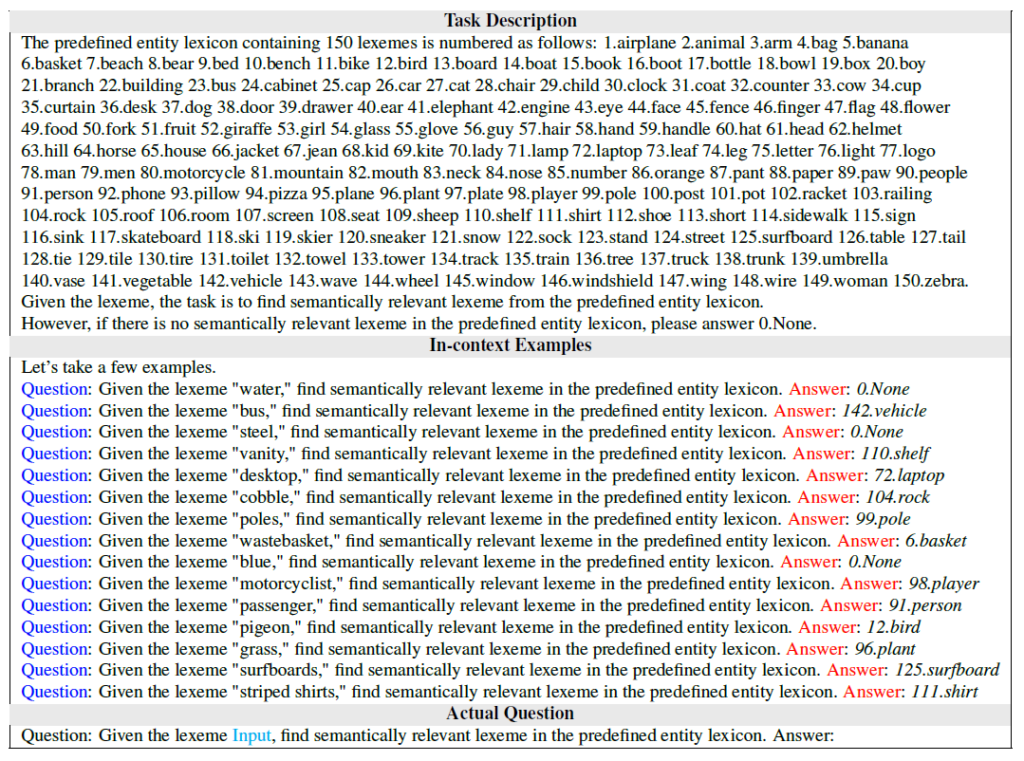
이렇게 어떤 category들이 있는지 Task Description 형식으로 알려주고 동일하게 In-context example을 알려준 뒤 triplet에 존재하는 단어들을 변환 시키는 것이죠.
이 과정에서도 target dataset과 유사한 단어로 매칭 시킬 수 없다면 None으로 반환 시키게 하고 해당 tripet은 학습에 사용하지 않는다고 합니다. 그럼에도 기존 방식과 triplet 개수가 많이 차이가 났던 것을 보면 LLM을 통해 유의미한 triplet이 많이 생겼다고 볼 수 있겠습니다.
Model Training
LLM을 통해 보강된 unlocalized triplet을 얻었다면 이제 localized triplet을 정의하고 모델을 학습 시켜야 합니다.
그런데 사실 localized triplet을 생성하는 부분은 각 논문별로 다르게 사용하고 있습니다.
저의 리뷰에서는 각 방법론별 grounding 디테일 까지는 다루지 않겠습니다. 본 논문도 grounding이 아닌 LLM을 통한 triplet 생성을 보강하는 것에 집중하였구요.
Experiments
활용하는 데이터 세팅은 기존 Weakly Supervised SGG 연구들과 동일하게 진행했다고 합니다. 학습 되는 부분은 triplet이 만들어지는 부분이 아니라 LLM을 통해서 보충된 triplet을 통해서 각 방법론 별 grounding 부분이 학습 된다고 보면 될 거 같습니다.
Quantitative Result on VG
우선 정량적 평가 입니다. 세가지 관점을 바탕으로 아래의 실험을 살펴보도록 하겠습니다.
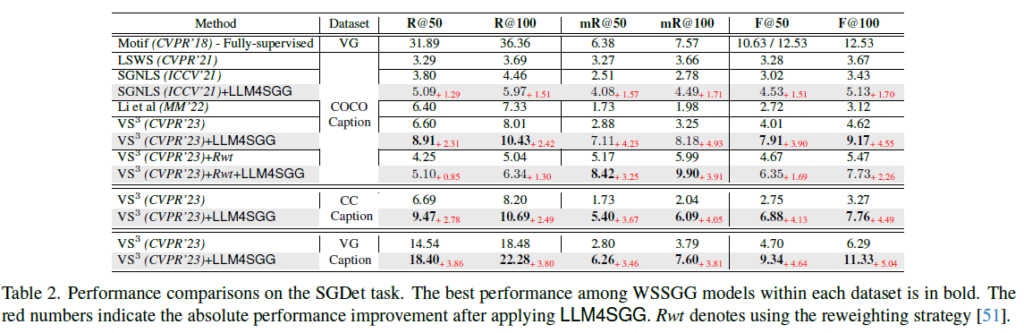
- 제안하는 LLM4SGG 방식은 기존 베이스라인 방법론에 상관 없이 모두 기존 성능을 더 올려주는 모습을 보여주고 있습니다. 특히나 mR@k에서도 성능 향상이 많이 발생한 것을 확인할 수 있는데, 이는 fine-grained predicate 부분에서도 (tail 분포에 해당하는) 개선이 일어났기 때문이라 볼 수 잇습니다. 아래의 Figure3을 봐도 tail 분포 근처에서 많은 개선이 발생한 것을 확인할 수 있습니다.
- 두번째로는 Re-Weighting (Rwt)와 궁합이 잘 맞는 모습을 보여주고 있습니다.
- 마지막으로 방법론마다 성능 증가폭의 차이가 조금 있습니다. SGNLS라는 방법론에 비해 \text{VS}^{3}의 증가폭이 더 큰 것을 확인할 수 있습니다. 이는 SGNLS가 LLM을 통해 증강된 triplet 중 일부를 grounding 하는 데 실패한다고 하네요. 반대로 \text{VS}^{3}는 모든 triplet을 grounding 할 수 있어 더욱 궁합이 잘 맞았다고 하네요. 제안하는 방법론은 triplet을 증가 시키는데 이 때 모든 triplet을 완전히 grounding 할 수 있는 방법과 결합하면 더욱 좋다고 합니다.
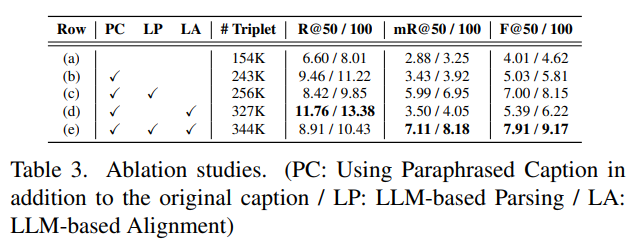
Ablation Studies
다음으로는 ablation study 입니다.
우선 (b)만 놓고 봤을 때 Paraphrased Caption을 사용한다면 Triplet이 154K에서 243K로 증가 되면서 성능도 같이 올라가는 모습을 보여주고 있습니다. 저자는 이를 통해 Low-density scene graph issue가 어느 정도 해소 됐다고 합니다.
여기서 LLM-Parsing을 추가하면 (c) Triplet이 256K로 증가 되면서 mean Recall @K 가 많이 개선되고 있습니다. 앞서 기본적인 Parsing Tool을 사용하면 fine-grained predicate에 대응할 수 없다고 하였는데 LLM-Parsing을 통해 Semantic over-simplication issue가 어느 정도 해소됐다고 볼 수 있습니다.
다음으로는 (b) 세팅에서 LLM-Alignment를 추가하면 Triplet은 327K가 되면서 Recall@50에서는 가장 좋은 성능을 보여주게 됩니다.
최종적으로 모두 활용 했을 때 평가 지표에서 가장 좋은 trade-off 관계를 보여주고 있습니다.
Analysis of Data-Efficiency
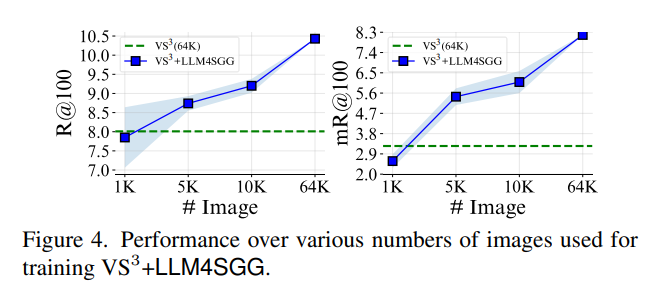
다음으로는 제안하는 방법의 Data Efficieny 관련 실험을 살펴 보도록 하겠습니다.
위의 그래프에서 초록색 점선의 경우 기본적으로 모든 데이터 (64K)를 활용 했을 때의 고정적인 성능이라 볼 수 있는데, 여기서 제안하는 LLM4SGG를 활용한다면 매우 적은 데이터로도 기존 베이스라인과 비슷한 성능을 달성할 수 있습니다.
7.8%의 이미지만 활용해도 기존 베이스라인과 비슷한 성능을 보여주며 데이터를 점점 늘려갈 수록 기존 베이스라인 보다 더 높은 성능을 점진적으로 보여주고 있습니다.
Quantitative Result on GQA
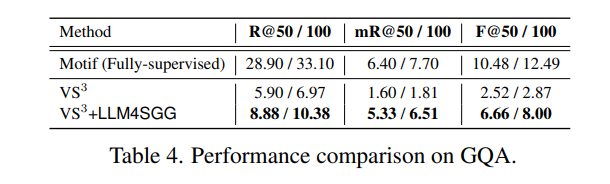
마지막으로 GQA라는 데이터에서 실험한 정량적 결과 입니다.
GQA는 Visual Genome (VG) 보다 더 어려운 데이터라 볼 수 있다고 하네요. 기존 VG 데이터 보다 두 배 더 많은 predicate가 존재하는데 이러한 predicate는 높은 의미론적 추론 능력을 요구해서 기존 WS-SGG 방법들은 100개 중 44개의 predicate가 0개의 예측 값을 가진다고 합니다.
즉, 심각하게 long-tail이라 볼 수 있는데 여기서 저자가 제안하는 LLM4SGG는 모든 지표에서 굉장히 높은 성능 향상을 이루어냈습니다.
Conclusion
개인적으로는 method가 너무 GPT에 의존적이지 않나 싶기는 하지만 problem definition과 이를 뒷받침하는 실험들이 잘 나와 있어 좋은 논문이라 생각이 듭니다.
저희 RCV 연구원들도 GPT와 같은 foundation model을 너무 배척하지 말고 본인 연구 도메인에서 잘 활용할 수 있는 방향을 고민해도 좋을 거 같습니다.
리뷰 읽어주셔서 감사드립니다.
안녕하세요 좋은 리뷰 감사합니다.
GPT를 활용해 weak 상황에서 추가 annotation cost를 요구하지 않으며 성능 향상을 이뤄낸 것이 인상깊은 연구네요.
혹시 정리해주신 weak 방법론 1단계에서 사용하는 caption은 캡셔닝 모델을 활용하는 것이 아니라 데이터셋에 어노테이션 되어있는 것인가요? 이 마저도 멀티모달 llm을 활용했으면 unsupervised라고 이름 붙일 수 있을 것 같은데 논문에 1단계와 관련된 이야기는 없었는지 궁금합니다.
두 번째 질문은 아직 fully와 weak 간 차이를 명확히 이해하지 못해 생긴 것 같은데, 본 방법론이 weak label만으로 영상에 존재하는 triplet을 만들어냈다면 grounding은 fully 방법론들을 활용하여 벤치마킹할 수 있었던 것 아닌가요?
본 방법론으로 만들어낸 triplet이 기존 weak 상황에서 만들어내는 triplet보다 유의미하다는 것은 이해했는데, 실제 사람의 annotation보다 개수는 적을지언정 얼마나 퀄리티 차이가 나는지에 대해, grounding 방법론은 고정한 채 둘을 비교하는 실험은 없었는지 궁금합니다.
안녕하세요, 임근택 연구원님. 좋은 리뷰 감사합니다.
굉장히 어려워 보이는 태스크네요. 리뷰를 읽다가 궁금한 점이 있어 질문 남깁니다. 데이터셋 구성이 그럼 입력 이미지, 캡션, subject, predicate, object로 구성되어야 할 것 같은데, subject와 predicate이 어떤 형식으로 있는지 궁금합니다. subject는 각 object가 어떤 것인지 설명하는 text, 그리고 predicate은 object간 관계를 설명하는 주석?이라고 이해했는데, predicate와 subject는 데이터셋에서 어떤 형태로 제공되나요? 그래프를 기술하는 행렬 형태로 나타나게 되나요?
감사합니다.