Introduction
Speech communication system은 speech를 통해 발생하는 발화, 의사소통하는 것으로, 여러 가지 speech 관련 task에서 중요하게 다루어지고 있습니다. 그러나 speech를 마이크 센서를 통해 audio data로 sampling 하는 과정에서 speech signal이 coloration, discontinuity, loudness, noisiness, and reverberation 같은 여러 요인에 의해 왜곡되며 이로 인해 speech signal의 품질이 저하될 수 있습니다.
이러한 음성 품질 저하를 해결하고자 등장한 것이 speech signal improvement이며, 이 task는 왜곡된 speech signal을 입력했을 때 clean speech signal을 출력하는 모델을 설계하여 speech signal의 품질을 개선하는 것을 주 목적으로 하고 있습니다.
논문의 저자들은 이전 연구에서 2-stage 기반 SSI 모델을 제안하였습니다. 해당 모델의 첫 번째 stage는 repairing network로, frequency response, isolated및 nonstationary, 그리고 loudness issue를 다루기 위해 설계하였습니다. 두 번째 stage는 noise 제거를 위한 denoising model을 설계하였습니다.
본 논문에서는 위에서 언급한 repairing network와 frequency network를 개선한 모델을 제안하였습니다. 첫째로, repairing network를 TEA-PSE의 COM-Net로 교체하였고, preliminary denoising과 dereverberation을 위해 repairing network를 적용하였습니다. 다음으로는, speech naturalness를 향상시키기 위해 training 단계에서 multi-resolution discriminators와 multi-band discriminators를 도입하였습니다. 마지막으로, 학습의 수렴 속도를 증가시키 위한 세 단계의 학습 전략을 적용하였다고 합니다.
Method
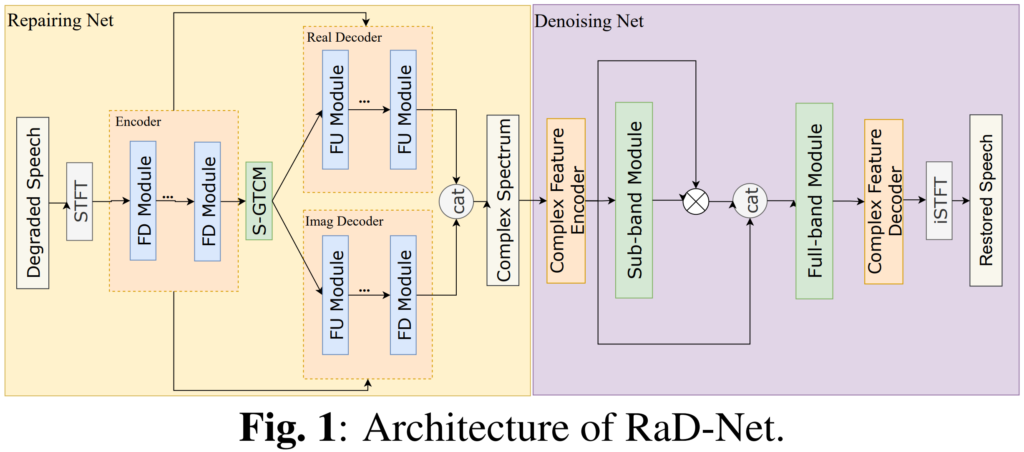
저자들이 제안하는 RaD-Net은 위의 [그림 1]과 같이 구성되어 있으며, 각 network에 대해서는 아래에서 설명드리겠습니다.
Repairing Net
저자들이 제안하는 RaD-Net은 TEA-PSE라는 denoising 모델을 바탕으로 하고 있습니다. TEA-PSE는 ICASSP 2022 DNS challenge에서 좋은 성능을 보인 모델로, personalized speech enhancement에 뛰어난 성능을 보여주었다고 합니다.
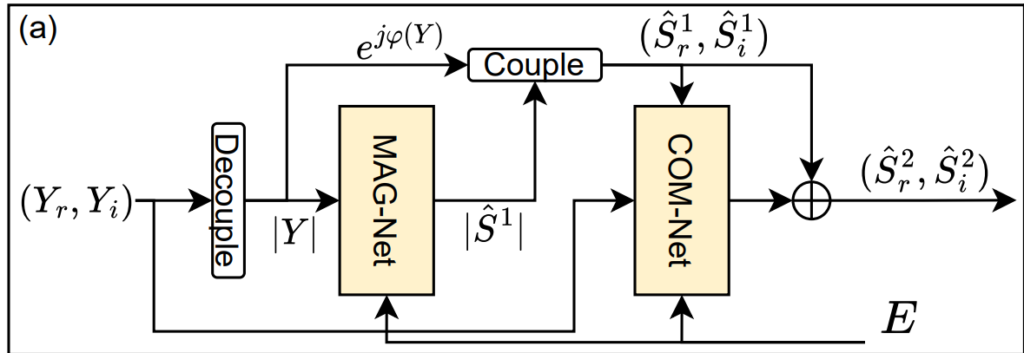
TEA-PSE의 구조는 위의 그림과 같은데, magnitude feature와 complex-valued feature를 각각 처리하는 MAG-Net과 COM-Net을 포함하고 있는 것을 확인할 수 있습니다. 그 중에서 COM-Net은 왜곡된 speech에서 phase 정보를 잘 복원할 수 있었다고 합니다. 이에 저자들은 RaD-Net의 repairing Net에 COM-Net의 구조를 사용하였다고 합니다.
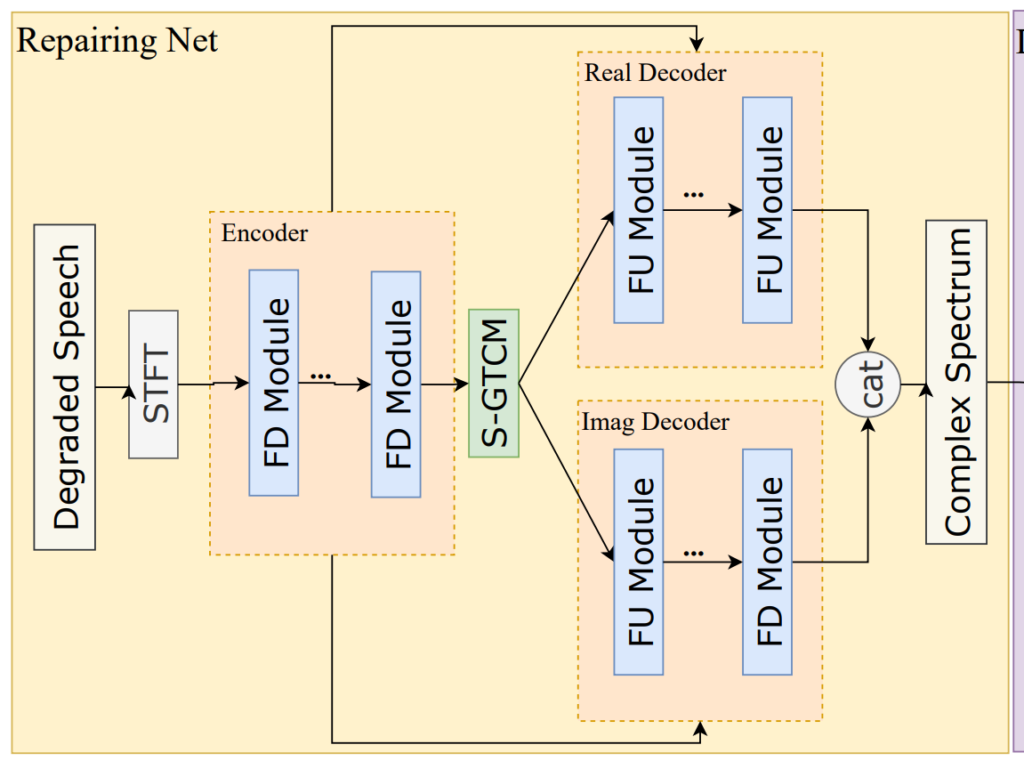
위의 그림은 Rad-Net의 Repairing Net의 구조를 나타내고 있는데요, 보시는 바와 같이 encoder-decoder 구조를 가지고 있습니다. 각 encoder는 세 개의 frequency down-sampling (FD) layer로 구성되어 있고, decoder는 세 개의 frequency up-sampling (FU) layer로 구성되어 있습니다.
FU와 FD는 각각 frequency 데이터를 upsample downsample하기 위한 것이라고 합니다. FD 레이어는 GateConv + cumulative layer norm + time frequency convolution module (TFCM)의 구조로 이루어져 있고, FU는 FD와 대칭적인 구조이며 GateConv 대신 Transposed GateConv를 사용하였다고 합니다. Encoder와 Decoder 사이에는 temporal modeling을 위해 네 개의 stacked gated temporal convolutional module (S-GTCM)을 적용하였다고 하는데요, 해당 모듈에 대한 reference가 없어 정확히 어떤 모듈인지는 잘 모르겠습니다.
Denoising Net
Denoising Net에는 ICASSP 2022의 S-DCCRN을 변형한 S-DCCSN을 사용하였다고 하며 그 구조는 아래의 그림과 같습니다.
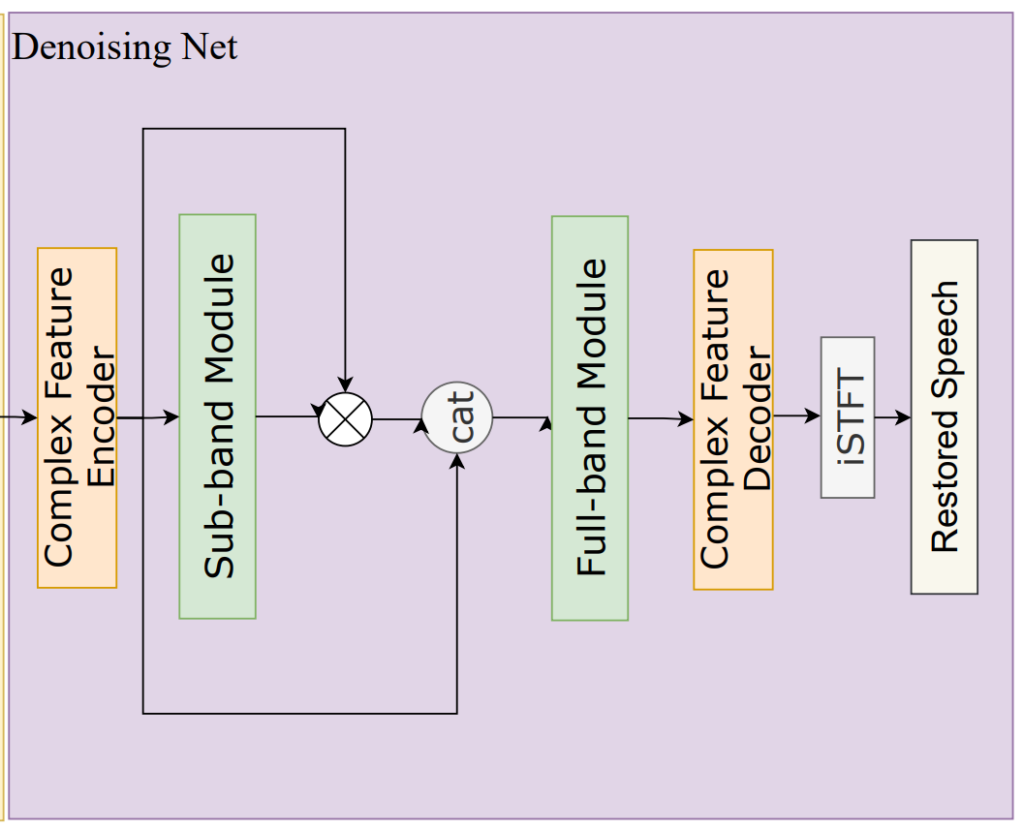
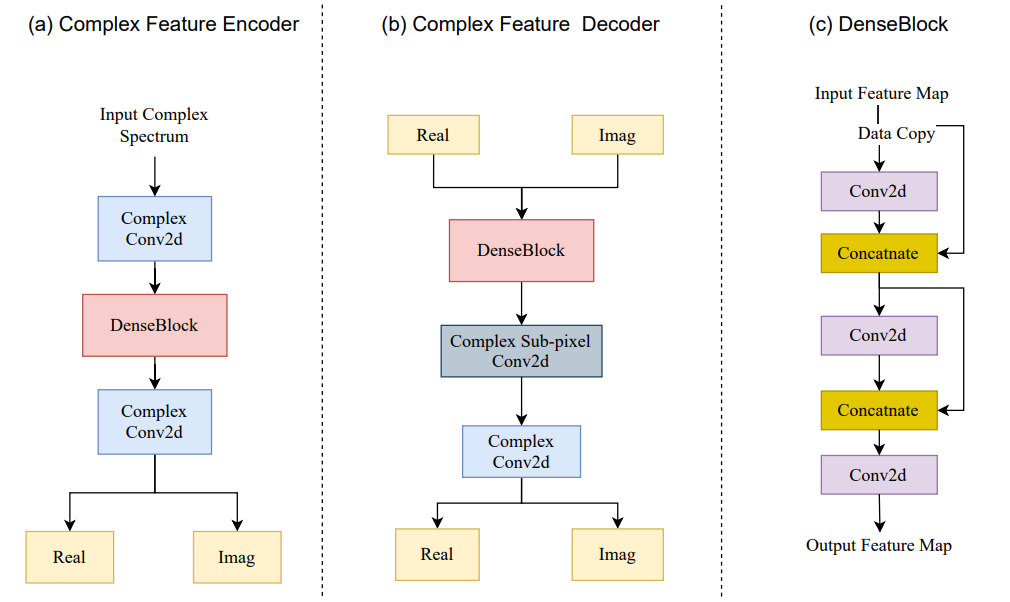
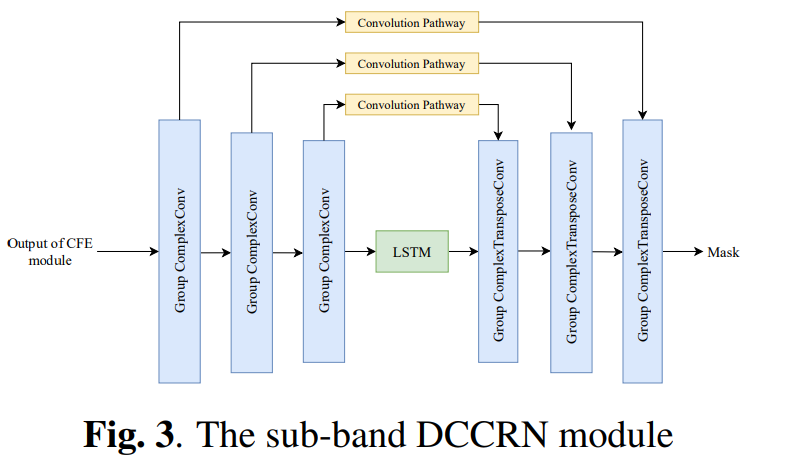
위의 그림에서 가장 위의 [Denoising Net]이 본 논문에서 사용한 모델이며, 그 아래의 두 그림은 ICASSP 2022의 S-DCCRN논문의 complex feature encoder/decoder, sub-band 모듈의 구조입니다.
본 논문의 저자들은 Rad-Net의 Denoising net이 local, global frequency 정보를 효율적으로 처리하도록 하기 위해 sub-band와 full-band 모듈을 연속적으로 배치하였다고 합니다. 또한 성능과 computation cost 간의 균형을 위해 [그림2, 3]의 CFE, CFD, band module에 포함된 conv를 depthwise conv로 단순화하였습니다.
Training Strategy
Rad-Net의 학습에는 adversarial learning 방식을 모티브로 하여 multi-resolution discriminators와 multi-band discriminators를 도입하였다고 합니다. 각 discriminator는 여러 개의 2D convolution layer로 구성되어 있고, 각각의 discriminator마다 서로 다른 feature를 입력으로 사용하였는데, multi-resolution discriminators에는 magnitude를, multi-band discriminators에는 complex spectrum을 입력으로 사용하였습니다.
이에 더하여 저자들은 수렴 속도를 높이기 위해 보다 세 단계의 학습 전략을 사용하였습니다. 먼저 repairing network를 discriminator와 함께 학습하고, 학습된 모델의 가중치를 freeze하였습니다. 그 다음으로 denoising network를 사전학습하였는데 이때는 discriminator를 사용하지 않고 학습하였다고 합니다. 두 network에 대해 각각 사전학습을 진행하고 난 뒤에는 학습된 repairing net과 denoising net를 연결하고, discriminator와 함께 denoising net을 fine-tuning하였다고 합니다.
Loss Function
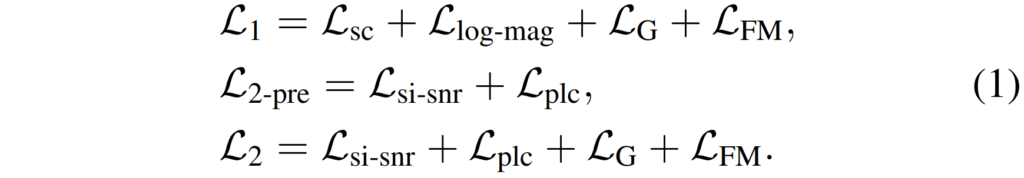
본 논문의 학습에 사용되는 Loss 들은 위와 같습니다. 각 notation에 대해 설명드리겠습니다.
repairing network는 L_1으로 학습되며 L1은, L_{sc}는 [5]의 spectral convergence loss이며, log-scale의 magnitude에 대한 L1 loss, 비대칭 손실인 L_{log-mag}, 생성자 손실인 L_G, 그리고 feature matching 손실인 L_{FM}의 합으로 구성되어 있습니다.
다음으로 denoising network의 경우 사전 학습 단계에서는 scale-invariant signal-to-noise ratio (SI-SNR) loss L_{si-snr}와 power-law compressed loss인 L_{plc}로 구성된 L_{2-pre}를 사용합니다. 이후 L_G와 [latex]L_{FM}을 L_{2-pre}에 추가한 L_2를 통해 denoising network를 fine-tuning하였습니다
L
Experiments
Dataset
본 논문에서 학습과 평가에 사용한 데이터셋은 DNS5 데이터셋으로, clean speech와 noise 구성되어 있어 clean speech에 noise를 추가한 합성 데이터 (이하 noisy 데이터)를 생성하여 최종적으로는 약 1200시간 분량의 데이터를 사용하였다고 합니다. 해당 데이터의 합성 방식은 ICASSP의 DNS challenge와 동일한 방식을 사용하였다고 하네요.
Results
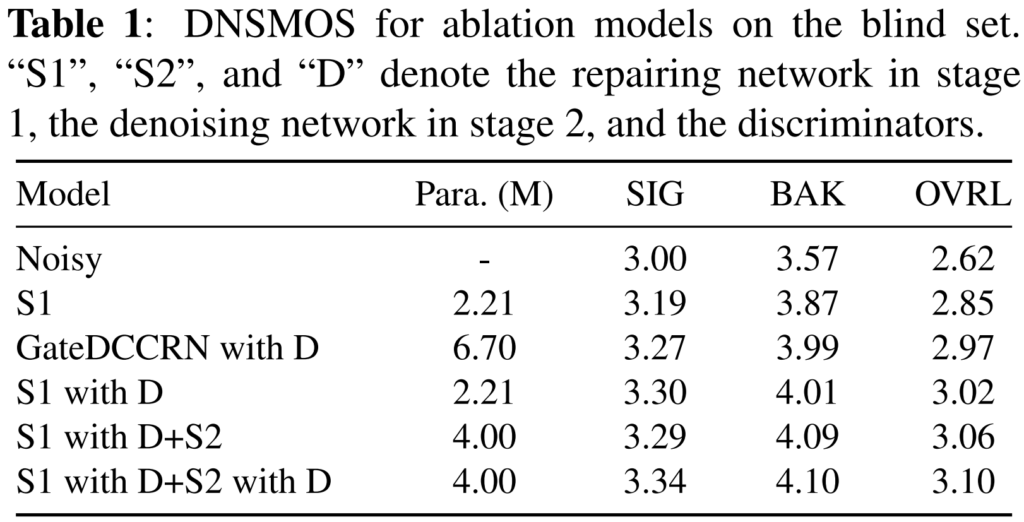
본 논문의 실험 결과는 [표1]에서 확인할 수 있는데요, 사용된 평가 지표는 DNSMOS로 (1~5)의 점수로 나타나고, 5에 가까울수록 좋은 결과를 의미합니다. SIG는 denoised signal의 왜곡 정도, bak는 배경 소음 포함 정도, ovrl은 신호의 전체적인 품질을 나타낸다고 이해하시면 될 것 같습니다.
[표 1]을 보면, repairing net의 gateDCCRN을 Com-Net으로 교체한 모델이 보다 좋은 결과를 달성한 것을 확인할 수 있습니다. 또한 [표 1]의 결과는 multi-resolution discriminators와 multi-band discriminators를 사용한 adversarial training 전략이 repairing network와 denoising network의 speech enhancement성능을 효과적으로 향상시킬 수 있음을 나타낸다고 하네요.
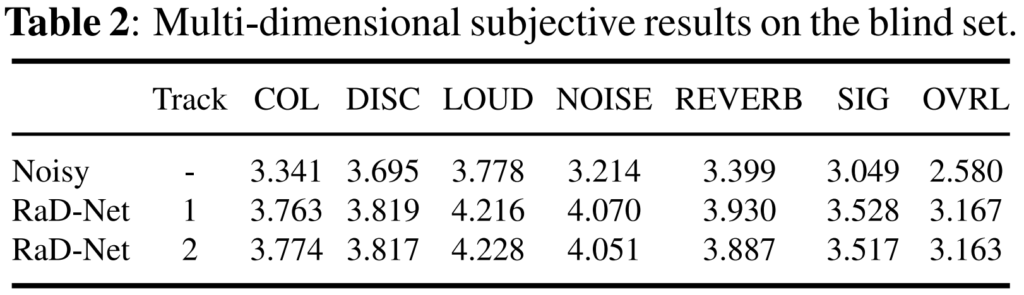
[표 2]는 dns challenge의 공식 test dataset의 정성적 결과로 모든 공류의 augmenttion에 대해 좋은 speech 품질을 보여주고 있습니다. 본래의 noisy에 비해 RadNet을 적용하였을 때 신호의 품질이 향상된 것을 확인할 수 있습니다.
안녕하세요. 혜원님 리뷰를 읽다가 궁금한 점이 있어 질문 남깁니다.
FD와 FU 계층을 거치며 downsampling-upsampling을 진행하는데 이런 U자형 구조의 대칭적인 구조가 갖는 이점이 뭔가요? 노이즈가 줄긴하지만 기존 정보 손실도 클 거같은데 이러한 구조를 저자가 사용한 이유가 궁금하네요. 그리고 loss fuction에서 notation의 각 loss들에 대해서도 설명해주실수 있나요?
감사합니다.
댓글 감사합니다.
1. u자형의 대칭 구조를 통해 입력 음성과 동일한 크기의 repaired 음성을 재구성할 수 있다는 장점이 있습니다. 그리고 본문의 [Repairing Net of Rad-Net] 그림을 보시면 encoder에서 decoder로 두 가지의 정보를 전달하는 것을 확인할 수 있는데요, 이 중 encoder에서 decoder로 직접적으로 전달하는 부분은 skip connection으로 이를 통해 high resolution feature를 전달함으로써 decode시 정보의 손실을 최소화하였습니다.
2. loss function의 notation을 본문에 추가하였습니다.
안녕하세요 혜원님!
좋은 리뷰 감사드립니다.
리뷰를 읽던 중 궁금한 점이 있어서 댓글 남깁니다.
1. Repairing Net에서 degraded speech가 인코더에 들어가기 전, STFT라는 과정을 거치는 데 해당 과정은 무엇을 하는 것인가요? 단순 전처리 과정인 건가요?
2. Repairing Net에서 디코더 부분이 real과 Imag로 나뉘어, 다른 조합의 모듈 연산을 수행하는 것 같은데 각각 담당하는 역할이 무엇인지 궁금합니다!
감사합니다.
댓글 감사합니다.
1. 넵 단순 전처리 과정이라고 볼 수 있습니다. stft란 short-time-fourier-transform연산으로, 여기서 frouier transform이란 time domain을 frequency domain으로 변화시켜 음성 신호의 주파수 정보를 취득하는 것을 말하는데요, stft는 전체 신호가 아닌 일정 구간씩 푸리에 변환를 적용함으로써 시간에 따른 주파수 정보를 취득하는 것이라고 이해하시면 될 것 같습니다.
2. stft를 수행하면 음성 signal은 [batch, n_samples, n_frames, 2(real + imag)]형태로 출력되는데요, 이때 실수부는 음성의 amplitude 정보를, 허수부는 음성의 phase 정보를 포함하고 있으며 이들이 각각 real과 imag 디코더로 들어가게 됩니다.
안녕하세요 혜원님, 좋은리뷰 감사드립니다!
궁금한 점이 있어 댓글 남깁니다!
1. sub-band 모듈과 full-band 모듈이 무엇이고 그 둘의 차이점이 무엇인가요?
2. speech naturalness를 향상시키기 위해 training 단계에서 multi-resolution discriminators와 multi-band discriminators를 도입한다고 하셨는데, 자세한 이런 multi 방식을 사용하는 이유가 무엇때문이고, 이것이 RaD-Net 아키텍쳐 figure의 어느 부분에 해당하는 것인지 궁금합니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
제가 해당 task를 잘 몰라서 질문 드리는 거일 수도 있는데 처리하고 있는 magnitude와 complex-vlaued feature는 주어지는 speech 데이터에서 무엇을 의미하나요 ??
말씀하신 S-GTCM은 reference가 없다고 말씀해주시긴 했는데 논문에서 모듈이 어떤 구조로 구성되어 있는지도 설명이 없었을까요 ??
마지막으로 현재 speech 관련 데이터셋에서 기본적으로 여러 요인으로 인해 왜곡되어 품질이 저하될 수 있다고 하셨는데 이러한 improvement 연구 말고 데이터셋 자체를 노이즈 없는 품질이 향상된 데이터로 구축하는 방향의 연구는 없는지 궁금합니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
speech를 마이크 센서를 통해 audio data로 sampling하는 과정에서 coloration, discontinuity, reverberation 등의 요인에 의해 왜곡된다 하셨는데 이 셋이 무엇인지 설명해주실 수 있나요 !?1 또,, frequency response, isolated, nonstationary 이슈가 무엇인지 궁금합니당.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문의 경우 이전에 리뷰한 논문과는 다르게 감정 인식 task가 아니라 classification으로 성능을 측정하기 어려울 것으로 예상합니다. DNSMOS으로 평가 지표를 가져가셨다고 하셨는데 이 평가 지표가 어떤식으로 설계되었는지 궁금합니다. 나중에 비슷한 연구를 하실 것 같은 때 써먹으면 좋을것 같아 더 궁금하네요.
감사합니다.