이번이 읽은 논문은 Interspeech 2021에서 발표된 “Rethinking Evaluation in ASR: Are Our Models Robust Enough?”논문으로, 음성인식 task에 관한 논문입니다. 음성 모델의 일반화 성능을 올리기 위해 음성 데이터에 어떤 조치를 취할 수 있을지 알아보기 위해 읽게 되었고 FAIR의 연구진이 발표한 논문이라고 하네요.
Introduction
Automatic Speech Recognition(ASR)은 사람의 음성을 text형태로 인식하는 task로 우리가 흔히 음성 인식이라고 부르는 대부분의 제품 혹은 서비스에서 활용되고 있는 기술에 해당합니다. 그러나 논문에서는 당시 활용되던 학습 기반의 ASR은 일반화 성능이 좋지 못하였다고 지적하고 있습니다. ASR은 주로 standard 데이터셋에 존재하는 test data의 인식률을 통해 그 성능을 측정하게 됩니다. 그러나 대부분의 음향 모델(acoustic models, AM)은 하나의 데이터셋에 맞게 조정되기 때문에 다른 데이터셋에서는 음성 인식이 떨어지는 현상이 발생합니다. (논문에서는 이를 데이터셋 간의 transfer가 잘 이루어지지 않는다고 표현하였습니다.)
이는 대부분의 큰 standard benchmark가 유사한 도메인과 녹음 조건을 공유하고 있기 때문이라고 하는데요, 학습에 사용되는 데이터셋들이 대부분 비슷한 환경에서 녹음되기 때문에 ASR모델은 특정 조건에서만 잘 동작하도록 정체되는 현상이 발생한다는 것입니다. 논문에서는 ASR이 좋은 일반화 성능을 보여주기 위해서는 다양한 녹음 조건과 소음 환경에서 발생하는 대화, 연설, 낭독 등을 포함한 벤치마크를 구축하는 것이 중요하다고 하였으나 이는 현실적으로 어렵다는 점을 언급하고 있습니다. 이에 저자들은 기존에 사용되던 공개 데이터셋을 활용하여 모델의 일반화 성능을 평가하는 방법을 연구하고자 하였습니다.
논문에서는 다양한 도메인과 조건을 가진 데이터셋에서의 일반화된 모델 성능을 평가하였으며, 이를 통해 ASR 시스템에 대한 real-world 적용 가능성을 높이고자 하였습니다. 또한, 모델의 robustness를 높이기 위해 additive noise 및 reverberation augmentation 기법을 적용하였습니다.
Domain Transfer
논문에서는 다양한 데이터셋과 환경에서의 transfer를 연구하기 위해 체계적인 분석을 수행하였습니다. 모든 실험에서 일관된 결과를 얻기 위해 270M 파라미터를 가진 단일 Transformer 기반 음향 모델 구조를 사용하였고, 각 개별 데이터셋으로 학습한 baseline과 모든 데이터셋을 학습에 사용한 joint model을 구축하였습니다. 학습된 모델들은 모든 데이터의 valid 및 test set으로 평가하여 각각의 in-domain 모델이 out-of-domain 데이터셋으로 얼마나 잘 전이되는지를 측정하였습니다.
이 과정에서 어떤 데이터셋에서 domain overfitting 문제가 더 심각하게 발생하는지를 확인하였으며, 또한, transfer dataset에서 1시간, 10시간, 100시간의 in-domain 데이터로 joint model을 fine-tuning하여 real data로의 model transfer를 분석하였습니다. 이 과정에서 public dataset의 test set 성능이 real-data로의 transfer 성능을 예측하는 데 유용하다는 것을 확인하였다고 합니다.
Experiments
Datasets
먼저 데이터셋에 대해 설명드리자면, 논문에서는 domain transfer를 측정하기 위해 주로 영어로 된 데이터셋을 사용하였다고 하며, 각 데이터셋에는 audio 데이터와 auido의 transcription이 포함되어 있다고 하네요. 각 데이터셋의 validation set은 모델의 configuration을 최적화하고, hyperparameter tuning하는 데 사용되었으며 test set은 최종 평가에만 사용되었다고 합니다.
실험에는 여러 데이터셋이 사용되었는데, ASR이라는 분야 자체가 생소하여 각 데이터셋에 대해 간단히 정리하자면 아래와 같습니다.
LibriSpeech (LS): 오디오북 녹음에서 추출된 낭독 음성으로 구성되어 있으며, dev-clean, dev-other, test-clean, test-other set으로 standard split을 사용하였다고 합니다.
SwitchBoard & Fisher (SB+FSH): 두 데이터셋 모두 전화 대화 음성으로 구성되어 있으며, SwitchBoard와 Fisher 데이터를 결합하여 train set을 생성하였다고 합니다.
Wall Street Journal (WSJ): 표준 하위 집합인 si284, nov93dev 및 nov92를 훈련, 검증 및 테스트용으로 각각 사용합니다. 훈련용으로 사용될 때는 si284 전사본에서 모든 구두점 토큰을 제거합니다.
Mozilla Common Voice (CV): 다양한 언어로 구성되어 있으며, 발화자들이 Wikipedia의 텍스트를 녹음한 데이터셋이라고 합니다. audio의 품질과 발화자의 다양성이 크다는 특징이 있으며 논문에서는 영어 데이터셋만을 사용하였다고 합니다.
TED-LIUM v3 (TL): TED conference 비디오를 기반으로 생성된 데이터셋으로, Kaldi[14]의 data partition recipe를 따랐다고 합니다.
Robust Video (RV) : 논문의 저자들이 생성한 영어 비디오 데이터셋으로, public social media video에서 샘플링하여 다양한 발화자, 억양, 주제 및 음향 조건을 포함하고 있다고 합니다. test set는 clean, noisy 및 extreme 조건으로 구성되며, 그 중에서도 extreme 조건은 가장 acoustically challenging한 subset이라고 합니다.
Unifying Audio
앞서 저자들이 여러 데이터셋을 하나의 모델에 학습시킨 joint model을 구축하였다고 말씀드렸는데요, 아래는 해당 학습 데이터를 구축하는 과정입니다. 즉, 여러 오디오 데이터를 하나의 통일된 형식으로 전처리하는 것이라고 이해하시면 될 것 같습니다.
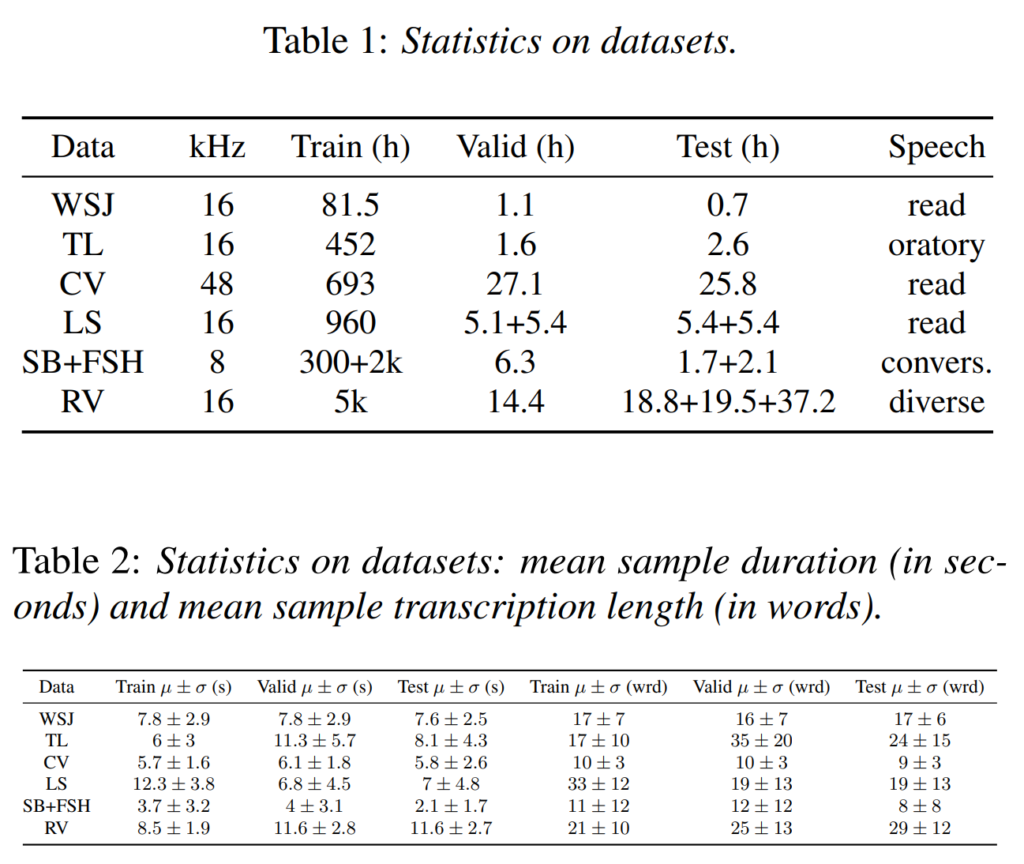
[표1], [표2]는 논문에서 사용된 데이터셋의 정보를 나타낸 것으로, 각 데이터셋이 서로 다른 sample rate와 input duration을 가지는 것을 확인할 수 있습니다. 이러한 차이 때문에 여러 데이터셋의 오디오로 joint model을 학습할 때 filterbank의 주파수 범위를 결정하는 것이라고 합니다. 예를 들어, SB+FSH 데이터셋은 가장 낮은 sample rate인 8kHz를 가지고 있는데, filterbank는 최대 4kHz까지 확장될 수 있고, 그 이상의 주파수에서는 spectrogram의 feature을 정확하게 결정할 수 없다고 합니다.
이에 저자들은 모든 데이터셋에서 동일한 filterbank를 사용하기 위해, 가장 낮은 sample rate인 8kHz를 기준으로 설정하고, 이를 사용하여 개별 데이터셋의 baseline과 joint model을 학습하였씁니다. 이를 통해 각 데이터셋의 모든 샘플에 대한 filterbank의 mean normalized energy 분포를 비슷하게 하였습니다 .또한 25ms의 sliding window로 80개의 log-mel spetrogram feature를 계산하며, 모델에 입력하기 전에 시퀀스 당 평균이 0이고 분산이 1이 되도록 정규화하였다고 합니다.
Acoustic Model Transfer
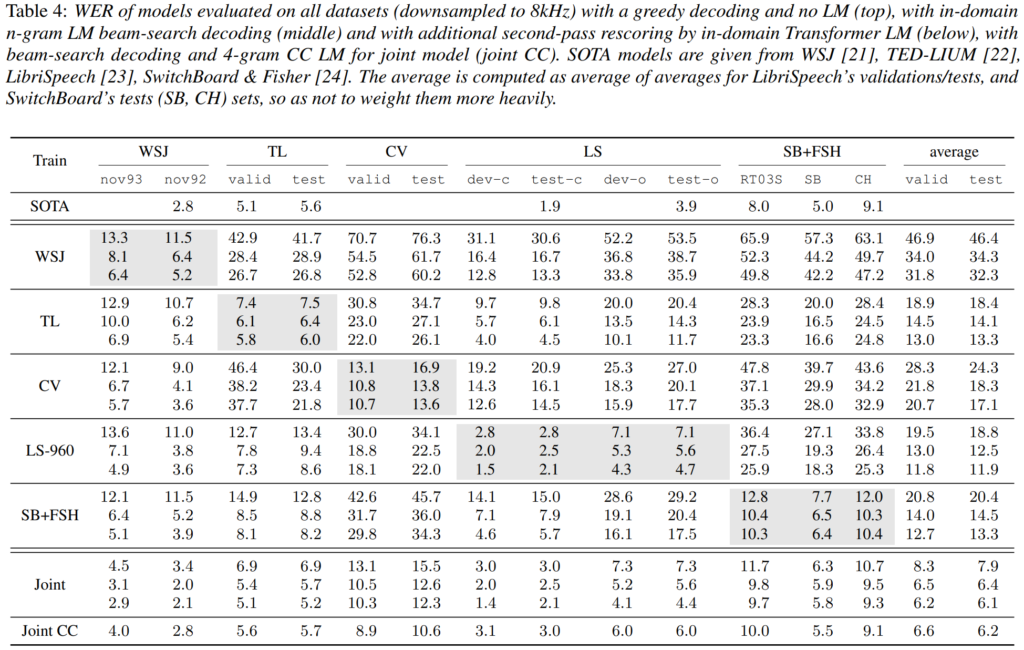
[표4]의 실험 결과는 학습된 모델을 모든 데이터셋의 test set으로 평가한 것으로, ASR에서 보편적으로 사용되는 WER를 나타내고 있습니다. 여기서 WER(Word Error Rate)는 인식된 text와 정답 text를 단어 단위로 오차를 측정하는 것으로 낮을수록 좋은 성능을 보이는 것입니다.
다시 [표4]를 보면, 대체적으로 단일 데이터셋으로 학습된 모델은 다른 데이터셋에서 성능이 좋지 않은 것을 확인할 수 있습니다. WSJ에서 학습된 모델은 transfer 성능, 즉, 다른 데이터셋으로 평가했을 때 성능이 크게 낮아지는 것을 볼 수 있는데, 논문에서는 WSJ의 학습 데이터가 적은 것을 원인으로 분석하였습니다. 또한 모든 모델은 CV로 평가했을 때 가장 낮은 성능을 보이고, CV에서 학습된 모델 또한 다른 데이터셋에서의 성능이 낮은 것을 보아 CV는 다른 데이터셋과 domain gap이 큰 것을 의미합니다. LS, TL, SB+FSH의 결과에서 LS와 TL, LS와 LB+FSH는 서로에게 transfer가 원활히 나타나는 것을 통해 데이터에 상당한 유사성이 있다는 것을 확인할 수 있습니다.
마지막 행에 존재하는 joint training model은 모든 데이터셋을 한꺼번에 학습시킨 모델로 각각의 단일 데이터셋 baseline에 비해 성능이 향상되거나 비슷한 성능을 보여주는 것을 확인할 수 있는데, 이러한 결과는 모든 벤치마크에서 잘 작동하는 강력한 모델의 존재 가능성을 나타낸다고 합니다. 즉, 어떤 잘 훈련된 모델은 어떤 환경에서도 잘 적응할 수 있다는 것이죠.
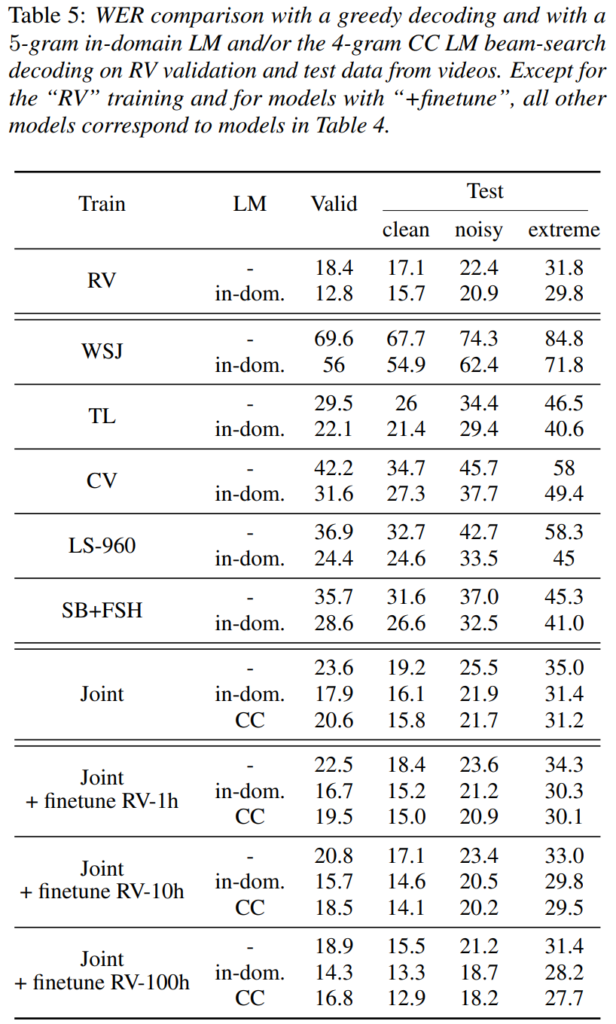
[표 5]는 공개 데이터셋에서 학습한 모델을 저자들이 구축한 RV 데이터셋으로 평가한 transfer 결과입니다. 또한, 총 5000시간의 in-domain training set으로 학습된 standard system의 결과를 나타내고 있습니다. 다른 benchmark와 마찬가지로, 단일 데이터셋으로 학습했을 때는 in-domain 데이터로의 전이에서 성능이 낮지만, TL 모델에서는 가장 좋은 결과를 보이는 것을 확인할 수 있습니다.
동시에 [표4]에서 각 benchmark에 대해 좋은 성능을 보였던 joint model은 RV 데이터에서도 좋은 성능을 보이는 것을 확인할 수 있는데, 저자들은 이를 통해 public dataset이 real-world ASR을 위한 좋은 training proxy될 수 있다는 것을 나타낸다고 합니다. 즉, 하나의 데이터셋이 아닌 여러 benchmark의 평균 성능을 향상시키게 되면 그만큼 real-world에서도 강인하게 동작한다는 것이죠.
마지막으로, joint training model을 전체 데이터 중 1시간 분량의 음성으로 fine-tuning하면 RV standard model과의 격차가 줄어들고, 10시간 혹은 100시간의 데이터로 fine-tuning한 후 Common Crawl 언어 모델로 decoding하면 보다 좋은 성능을 낼 수 있었다고 합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
제가 음성 도메인의 데이터셋에 대해 잘 몰라서 그러는데, 기존의 데이터셋들은 보통 어떤 환경과 상황이 포함되어 있나요 ?
그리고 method 부분을 간략하게 설명해주셨는데, 실험을 위한 joint model은 어떤 구조로 이루어져 있는지 궁금합니다. 또한 음성 데이터 학습에 있어서 filterbank의 주파수 범위를 결정해야 한다고 말씀하셨는데, 여기서 filterbank는 무엇이고 학습에서 주파수 범위를 동일하게 가지고 가야 하는 이유는 무엇인가요 ??