안녕하세요,
이번에는 간만에 6D 관련 데이터셋 논문이 아카이브에 올라와서 읽게됐네요. 3월에 올라왔고, 논문 포멧은 RA-L인 것으로 보이나 깃허브에는 under-review 진행 중이라고 합니다.
제가 최근에 zero-shot pose estimation 관련 방법론을 원복 실험을 진행하면서, Foundation 모델 기반으로 하는 방법론을 데이터셋을 제작할 때 CAD 모델도 있고 이미지만 주면 pose를 추정해주니까 이걸 annotation 과정에 쓰면 좀 효율적으로 할 수 있겠다라는 생각을 했었는데 다행인지는 모르겠지만 이번 논문에서는 foundation 모델이 아닌 detection 모델 + pose estimation 모델로 구성해서 annotation 파이프라인을 제안하였네요. 생각한 컨셉은 같아서 흥미롭게 읽었던 것 같습니다.
리뷰 시작하겠습니다.
Introduction

최근 indoor에서의 로봇 내비게이션에 대한 연구는 모바일 로봇이 2D 포인트, 물체의 이미지, 언어 지시 등 다양한 양식을 따라 목표 위치를 탐색하는 우수한 발전을 보여주고 있습니다. 하지만 이러한 로봇의 기능은 탐색을 넘어 주변 환경의 물체와 물리적 상호작용이 필요한 경우 기존의 방법만로는 확장하기 어려울 것 같네요. 따라서, 3차원 상의 환경에 대한 인지와 물체에 대한 6D pose estimation을 수행하는 것은 로봇의 파지 및 조작을 위한 필수적인 사전 작업이라고 볼 수 있습니다.
현재 6D pose estimation 대회인 BOP 챌린지에서는 성능을 최대한 끌어올리기 위해 새로운 모델과 기존의 방법론들의 조합으로 초점이 맞추어져있는데요. 그러나 이러한 패러다임은 6D pose estimation 연구를 촉진하기에는 충분하다고 볼 수 있지만 제공되는 데이터셋들을 보면 로봇 팔이 물체와 가까운 위치에 고정되어있고, 물체가 로봇의 FOV 내에서도 중앙에 위치한 상태로 pose estimation을 수행하는 것에 초점을 맞추고 있다는 점인데요. 기존 데이터셋들은 매니퓰레이터가 실내 환경 중에서도 특히 높은 선반 위를 다룬다거나 냉장고, 전자레인지, 식기세척기, 오븐, 싱크대 등 다양하지만 실제 로봇의 FOV와 관련하여 물체가 아닌 다른 위치에 배치되는 주방 환경에 직면하는 문제에 대해 다루지 않는 것에 대해 문제를 정의합니다. 물체에 대한 위치는 로봇의 카메라와 관련하여 6D pose estimation을 수행하는 것이 어려울 뿐만 아니라 냉장고의 경우에는 음식을 놔두는 투명 선반 같은 것도 있죠. 이러한 challenge 한 주변 환경을 기존의 데이터셋들은 다루지 않고 있습니다.
로봇의 task를 수행하기 위해서는 리소스 또한 고려해야 하는 대상인데요. BOP 챌린지의 리더보드에 제출된 방법론들을 보면 속도 5FPS가 안될정도로 상당히 느린 양상을 보이고 있다는 점입니다. 해당 경우는 제한된 리소스에서 많은 수의 물체를 처리해야 하는 어플리케이션 측면에서는 적용하기 어렵다는 의미로도 볼 수 있습니다. 저자는 이러한 문제로 인해 속도를 벤치마크로 설정합니다.
이번 논문의 contribution은 다음과 같습니다.
- 111개의 물체에 대한 2D bbox, segmentation mask, 6D pose 정보를 제공하는 RGB-D 데이터셋 제안
- 효율적인 annotation 파이프라인 제안
- 벤치마크 대회 도입
The KITchen Dataset
A. Dataset’s Objects
이번 KITchen 데이터셋의 컨셉은 household에서도 kitchen, 주방을 타겟으로 하였는데요. 주방 환경에서 일반적으로 사용되는 물체들을 포함하여 large-scale의 합성데이터가 아닌, 실제(real) RGB-D 이미지를 만드는 것을 목표로 하였다고 합니다. 기존에 제안된 데이터셋들 중에도 물론 일부는 이미 주방에서 흔하게 사용될 수 있는 물체들을 제공하기는 하지만 ‘주방 환경’ 이라는 환경 내에서 다루기에는 물체가 부족하기 기존에 제안되었던 주방 관련 물체들을 재사용하면서, 그외로도 추가적인 주방 물체에 대한 6D pose estimation 관련 연구를 용이하게 하기 위해 KITchen 이라는 데이터셋을 제안하게 되었다고 합니다.
B. Dataset Recording

위 그림(2)와 같이 서로 다른 2개의 주방 환경에서 ARMAR-6이라는 휴머노이드 로봇을 사용하여 recording을 진행하였다고 합니다.

KIT(Karlsruhe Institute of Technology)이라는 독일의 공과대학교에서 만든 로봇인가 봅니다.
해당 그림에서의 좌측은 ‘Main kitchen’으로 냉장고, 서랍이 있는 조리대, 테이블, 싱크대, 전자레인지, 식기세척기, 오븐과 같은 일반적인 주방 가전제품으로 구성되어 있는 것을 확인할 수 있습니다. 우측은 ‘Mobile kitchen’으로 메인과 동일하게 테이블~식기세척기까지는 동일하나 냉장고, 테이블 3개정도가 배치되었다고 합니다. 배경에 대한 다양성을 높이기 위해 테이블 위에 깔려있는 식탁보의 색상 종류를 4가지(빨간색, 흰색, 회색, 파란색)로 구성합니다.

위 그림(3)은 ARMAR-6의 몸통 부분에 대한 높낮이를 조절할 수 있나 봅니다. 이를 이용하여 카메라의 높이를 150cm, 177cm, 185cm로 다양한 뷰포인트를 주었다고 합니다.

또한, 그림(4)는 로봇의 목에 대한 앵글을 10, 37, 49도 만큼 회전시켜 추가적인 뷰포인트를 주었으며 6가지의 다양한 조도 변화를 주어 recording을 진행합니다. 해당 recording 과정에서 FPS가 빠르면 반복되는 프레임이 발생하게 되므로 이러한 문제를 막기 위해 속도는 5FPS로 제한을 두었다고 하네요. 여기서 저자는 이정도로 다양한 로봇의 FOV를 포괄적으로 커버하는 데이터셋은 처음으로 제안하는 것이라고 합니다.
C. Annotation Pipeline

실제 6D pose를 annotation하는 것은 매우 시간 비용이 큰 작업인데요. 이러한 과정을 최소화 하는 것도 데이터셋을 구성하는 것에 중요한 부분이라고 생각합니다. 저자는 annotation 과정을 간소화 하기 위해 semi-auto 방식으로 annotation을 진행하는 파이프라인을 제안하는데요. 해당 파이프라인을 통해 3가지 타입(2D bounding box, 2D segmentation mask, 6D pose)의 annotation 결과물을 얻게 됩니다.
1) 2D Objects Bounding Boxes
먼저 bbox는 어떻게 얻었는지 살펴보면, 위 그림(5)에서 YOLOv5 쪽을 보시면 각 물체에 대한 3D CAD 모델을 이용하여 BlenderProc을 사용하여 2D bbox가 있는 약 10만개의 annotation 정보가 있는 데이터를 생성하고, 이를 YOLOv5의 사전 학습된 모델을 fine-tuning 하는 데에 사용합니다. 이후 학습된 해당 모델을 실제 이미지에 적용하여 사람이 직접 수동으로 분류된 이미지를 보고 라벨링이 잘 되었는지 판단하는 방식으로 진행합니다. 모든 실제 이미지에 대해 bbox에 대한 라벨링이 정확하게 부여될 때까지 모델을 반복적으로 fine-tuning을 진행하였다고 합니다. annotation 정보가 10만개라고만 하고 정확히 몇장으로 학습을 진행하였는지는 언급을 안해놨네요.
2) 2D Objects Segmentation Masks
물체에 대한 segmentation mask는 간단한 방법을 통해 생성할 수 있는데요. 그림(5) 2D Labels라고 되어 있는 부분과 같이 이전에 생성된 bbox의 입력을 SAM의 입력으로 태워주어 생성할 수 있었다고 합니다.
3) 6D Object Poses

대망의 6D pose를 생성하는 방법입니다.
앞서 이미지 내의 물체에 대한 6D pose를 생성하기 위해 입력 이미지 함께 검출된 물체에 대한 3D CAD 모델과 함께 fine-tuning 과정을 거친 YOLOv5 모델을 사용하여 얻은 2D bbox 정보를 MegaPose로 전달하게 되는데요. MegaPose의 입력은 bbox만을 사용할 수 있다는 한계을 보완하기 위해 CNOS가 제안되었는데, 저자가 당시 논문을 작성할 때에는 CNOS에서 좀 더 나아가 pose estimation을 수행한 연구가 없지 않았나 하고 조심스레 예상합니다. NVIDIA에서 만든 MegaPose는 이미지 내에 존재하는 물체에 대한 3D CAD 모델과, 2D bbox의 정보가 있으면 해당 물체에 대한 추가적인 학습 없이 pose를 예측할 수 있는 unseen object pose estimation에 대해 고안한 논문이라고 이해하시면 되겠습니다. 그렇게 출력된 결과로 6D pose를 얻으면 해당 pose에 대한 검수 작업이 있어야 하겠네요. 이 또한 수동으로 진행하게 되는데 6D pose가 있으면 이미지에 contour와 mesh를 디스플레이 할 수 있으므로 이러한 용도로 검수를 하였다고 하네요. 해당 MegaPose 모델 또한 모든 이미지에 대해 정확하게 annotation을 할 때까지 반복적으로 fine-tuning 됩니다.
annotation 결과는 그림(6)과 같습니다.
D. Comparison to Existing Datasets
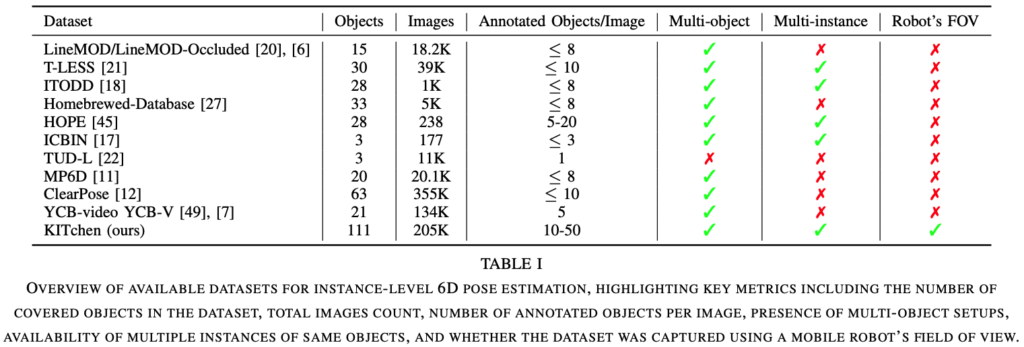
기존의 데이터셋들과 비교하는 섹션인데요. 다른 데이터셋들과 비교했을 때, 위 표(1)은 제안한 KITchen 데이터셋만의 두드러진 차별점이 존재하는 것을 보여주는 표입니다. 111개의 다양한 물체들로 구성된 해당 데이터셋은 기존의 데이터셋들보다 비해 매우 우세하게 많은 것을 볼 수 있습니다. 많다는 것은 다양한 범위의 물체들로 구성되었다고 봐도 되겠네요. 이전에 설명한 다양성의 측면에서도 차별점이 존재하는데요. 이러한 다양성은 데이터를 보고 학습 및 예측을 수행하는 것에 매우 중요한 역할을 하게 됩니다. 다음으로, KITchen 데이터셋의 이미지는 약 20만장 넘게 제공을 합니다. 수치상으로는 ClearPose 라는 데이터셋이 더 많으나 이미지 내에 존재하는 물체가 최소 10개에서 최대 50개가 존재한다고 하니 어마어마 하긴하네요. 이를 통해 instance-level에서의 학습 및 평가 목적으로도 기존 데이터셋들보다 다양한 물체에 대해 데이터를 제공할 수 있긴 하겠네요.
기존의 데이터셋들은 사람이 직접 손으로 센서를 움직이며 촬영을 하거나, 로봇팔을 이용한 촬영을 하는 방식으로 진행하였습니다. KITchen 데이터셋은 촬영도 기존의 데이터셋들과 다르게 휴머노이드를 이용하여 높이, 카메라 각도, 조도 조절에 대해 로봇의 FOV를 고려하여 촬영을 진행한 유일한 데이터셋이라고 하네요. 기존의 데이터셋들은 주로 테이블 위에 초점을 맞추었다면 KITchen 같은 경우 냉장고, 오븐, 싱크대, 높은 선반, 전자레인지, 식기세척기 등등 주방 환경에서 까다로운 위치를 촬영하였으므로 pose estimation 연구를 위한 좀 더 나아간 실제 시나리오를 제공한다고 볼 수 있습니다.
The KITchen Benchmark
저자는 컴퓨터 비전과 로봇공학 분야의 연구자들이 로봇에 대한 리소스의 제약을 고려하면서 clutter한 환경에 존재하는 다양한 물체가 존재하는 데이터셋을 제공함으로써 연구한 방법들을 적용하는 것을 장려하도록 목표로 하여 벤치마크를 제안합니다. 실제 적용 가능성을 보장하기 위해 리더보드 제출에 대한 구체적인 가이드라인을 적용할 예정이라고 하네요. 리더보드에 제출할 submission 파일에는 모든 물체에 대한 단일 모델을 사용해야 하며 inference 시간은 5FPS를 유지해야 합니다. 이러한 기준을 BOP benchmark의 기준에 맞추면 큰 차이를 발견할 수 있는데, BOP 챌린지의 리더보드를 보면 데이터셋 마다 단일 모델을 사용하는 요건을 만족하는 방법론은 많이 없는데요. 5FPS 성능을 달성하지 못한 여전히 방법론들도 많으며 이러한 속도 측면에서는 생각해보았을 때, 시간이 중요한 로봇 애플리케이션의 요구 사이에 중요한 격차가 있음을 강조합니다.
Datasets
휴머노이드 로봇의 관점에서 촬영된 데이터셋이며, 주방 환경에서의 로봇의 조작 시나리오를 다루기 위해 적합합니다. 해당 데이터셋의 비중은 전체 데이터셋에서 train(70%), val(20%), test(10%)의 비율로 분리하였다고 하네요. 해당 벤치마크 데이터셋은 주로 KITchen 데이터셋에 초점을 맞추고 있지만, 다른 데이터셋을 만드는 연구자에게도 annotation 파이프라인을 활용하여 효율적으로 annotation을 진행할 것을 권장한다고 합니다.
Pose Error Calculation
기존의 BOP 챌랜지에서 사용하는 평가지표를 그대로 사용한다고 합니다.
- GT pose P, 예측 pose \hat P 간의 pose error 함수 e가 특정 threshold \theta_{e}보다 낮으면 올바른 pose로 간주
- e는 e_{VSD}, e_{MSSD}, e_{MSPD}를 의미함
- e_{VSD} : 물체의 보이는 부분에 초점을 맞춰 색상 정보를 무시하고 형태를 구별할 수 없는 pose를 동일한 것으로 평가하는 Visible Surface Discrepancy 오차 함수
- e_{MSSD} : 3D 모델에서 vertex 간 표면 편차를 계산하는 Maximum Symmetry-Aware Surface Distance로, 모델의 vertex 간 최대 거리를 계산해 파지 성공 가능성을 파악하는 데 중요
- e_{MSPD} : eMSPD는 Maximum Symmetry-Aware Projection Distance로 물체의 대칭성을 고려해 X, Y 축의 차이를 계산하는 방식으로 RGB 데이터에만 의존하는 방식에 적합
- AR : Recall(모든 물체에서 총 pose error가 특정 threshold \theta_{e}보다 낮으면 올바르게 추정된 pose의 비율)을 다양한 thershold 값에 따른 결과를 평균
Conclusion
이번에는 로봇의 FOV에서 단안으로 촬영된 KITchen 데이터셋을 살펴보았습니다. 이는 데이터셋 이름 그대로 주방환경에서 물체에 대해 pose estimation을 수행할 수 있도록 맞춤 제작된 데이터셋이었는데요. 해당 데이터셋의 벤치마크는 실시간성의 유무를 중점으로 보는 것 같네요. 해당 벤치마크를 세팅하기 위해 저자는 휴머노이드 로봇 관점에서 촬영을 진행한 최초의 데이터셋을 제공하였으며, 다양한 조도 변화와 다양한 환경에서 구조적으로도 어려운 배치로 물체를 두어 촬영을 진행하였습니다. 마지막으로 annotation의 시간 비용을 최소화 하기 위해 새로운 annotation 파이프라인을 제안하였습니다.
이상으로 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
해당 연구는 환경에 초점을 둔 데이터 셋 논문으로 보입니다.
해당 데이터셋은 네트워크를 합성 데이터를 이용하여 fine-tuning 하는 방식을 통해 annotation cost를 줄였다고 이해하였습니다.
이에 대하여 예측 결과를 수동으로 검수하고 fine-tuning을 수행하셨다고 되어있는데, 사용하는 Megapose 알고리즘도 성능이 제한적이다보니, 이러한 예측값에 대한 추가적인 검수가 있어야 하지 않았을까 합니다. 미세한 오차일 수 있으나 6D Pose Estimation용 라벨에 대한 결과(Fig.6)를 보면 contour가 어긋나는 예시가 상당수 있는 것으로 보입니다.(4번째 행의 국자와 냉장고 문쪽에 있는 우유?, 마지막 행의 뒤집개와 냉장고 문 상단에 있는 원통형 물체 등) 이에 대한 희진님의 의견이 궁금합니다.
그리고 Pose Error Calculation에 대한 지표에 해당하는 표가 누락된 것으로 보입니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 제 생각에도 데이터셋에 대한 추가적인 검증이 있었으면 싶긴 하네요. 여러모로 아쉬운 점이 많은 논문이나, under review 중이라고 하니… 결과가 나오면 데이터셋을 한 번 살펴보고 싶긴하네요.
2. 해당 지표는 제안된 데이터셋을 통해 사용할 평가지표를 의미하고 따로 벤치마크를 본인들이 만든 건 없습니다. 리더보드를 만들 예정이라고 하네요.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
이 논문의 주요 contribution이 새로운 데이터셋을 제공했다는 것도 있지만, 그것보다 속도에 대해서 중요성을 강조하고 이를 경쟁하기 위해서 속도를 벤치마크로 설정한 것이 주요 contribution이라고 생각했습니다. 또한 https://bop.felk.cvut.cz/leaderboards/를 통해서 BOP 챌린지의 리더보드를 보면 속도가 같이 표기되어 있는 것을 알 수 있는데, 궁금한 점은 리더보드에는 submission 파일을 만들어 제출하는 것으로 이해했는데 이것을 통해서도 inference 시간을 측정할 수 있나요? 아니면 인퍼런스 시간을 따로 기입을 해야하는 것인지 궁금합니다. (만약 따로 리더보드에 기입하는 것이라면 거짓으로 기입할 수도 있을 거 같은데 그러면 어떻게 속도를 가지고 벤치마크를 만들 수 있는지가 조금 의문이네요)
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신대로 submission 파일에 inference 시간을 기입하는 것이긴 합니다. 각 테스트 이미지에 대해 inference time을 측정하고 평균을 취하는 것으로 알고 있습니다. 조작이야 모든 테스크에서도 발생할 수 있는 사례이긴 하나, 각 메소드마다 method에 대해 자세한 description을 작성해야 제출을 할 수 있기 때문에 터무니 없는 속도라면 의심하긴 하겠네요.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
ARMAR6 굉장히 귀엽게 생겼네요 ㅋㅋ 본 논문이 2024년 아카이브에 공개된 논문인데 중간에 저자가 당시 논문을 작성할 떄에는 CNOS에서 좀 더 나아가 pose estimation을 수행한 연구가 없지 않았나 예상해주셨는데, 엄청 최근에 그런 연구가 나온건가요 ?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
pose estimation까지 수행한 연구가 논문으로 publication까지 된 것은 작년 11월 정도 되었을 무렵이고 MegaPose는 22년 12월 논문이므로 그 사이에 zero-shot 기반의 방법론이 없었을 시기이긴 합니다. BOP challenge도 23년 6월쯤부터 unseen object pose estimation을 새롭게 개최한 것으로 알고 있습니다.
감사합니다.
안녕하세요, 희진님
좋은 리뷰 감사드립니다.
글을 읽던 중 질문이 2가지가 생겼습니다.
1. 3d meshes가 object에 대한 CAD모델인 건가요?
2. BlenderProc이란 것이 파이프라인에서 2d bbox로 annotation된 합성 데이터셋을 만들어주는 역할을 하는데,
6d pose estimation 혹은 로봇 파지 연구 분야에서는 real world 데이터 셋보다는 시뮬레이션 단에서 데이터셋을 구축을 하는 상황이 일반적인 것인지 궁금합니다!
감사합니다!
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 네 맞습니다.
2. 최근 나온 데이터셋 논문들의 추세는 대규모 형태로 제공을 하는데요. 규모가 커진 만큼 annotation 과정 자체가 워낙 오래 걸리기도 하고 사람이 하는 것보다 시뮬레이터를 사용하는 게 정확하므로 합성데이터를 많이 사용하는 것으로 알고 있습니다. 주로 학습할 때는 합성데이터, 평가할 때는 실제데이터로 많이 제공하고 있으며 학습할 때도 몇몇 데이터는 실제데이터를 사용하기도 합니다.
감사합니다.