안녕하세요. 오늘의 X-Review에서는 GPT 등의 LLM을 활용해 Temporal Sentence Grounding in Video(TSGV) task를 수행하는 논문을 소개해드리겠습니다. 해당 논문은 중국 대학교에서 연구되었으며 24년도 MDPI Applied Science 저널에 게재되었습니다. 처음에는 본 논문의 제목이 지금 제 연구가 나아가고자하는 방향성과 너무나 일치하여 읽기 시작하였지만, 읽을수록 제가 OTT 제안서에 작성하였던 필요성과 저자의 고찰이 일치하여 신기하게 느껴졌던 논문입니다.

리뷰 바로 시작하겠습니다.
1. Introduction

먼저 TSGV task는 위 그림 1-(a)에 나타난 것과 같습니다. 다양하고 복합적인 사건이 발생하는 untrimmed video와 해당 비디오 내 특정 구간을 설명하는 텍스트 쿼리가 쌍으로 입력됩니다. 이후 모델은 긴 비디오 내에서 텍스트 쿼리가 설명하고 있는 특정 구간을 (시작 지점, 끝 지점) 형태로 출력을 내뱉게 되는 것입니다. 위 그림 1-(a)를 예시로 보면, 한 여성이 등장하는 비디오와 함 해당 비디오 내 특정 구간에 해당하는 자연어 문장 “Blonde teenage girl turns off the lights while vlogging alone“이 주어졌습니다. 그럼 이를 입력받아 모델은 실제 상응 구간인 (82s, 150s)과 최대한 일치하는 예측 구간을 내뱉으면 되는 것입니다.
제목에서도 알 수 있듯, 우선 본 논문은 Zero-shot 세팅을 기반으로 심지어는 fine-tuning 과정도 없이 grounding을 수행합니다. 저자는 Introduction에서 먼저 TSGV에 적용할 수 있는 LLM(거대 언어 모델)들에 대해 설명해줍니다. 최근 GPT-4가 등장하며, 자연어 처리 분야에서는 엄청난 발전이 일어나게 되었습니다. 여기서 그치지 않고, GPT-4를 기반으로하는 여러 후속 연구가 진행됩니다. 여러분들도 한 번씩 들어보셨을 메타의 LLaMa 2가 23년 7월에 등장하였고, 중국 스타트업 기업 Baichuan의 Baichuan2 모델도 23년 9월에 등장하게 됩니다. 둘은 비슷한 시기에 등장하였지만, LLaMa 2는 인용수가 3천에 육박하는 반면 Baichuan2는 100 정도라 처음 들어보셨을 분들이 많을 것 같습니다. Baichuan은 좀 찾아보니 Alibaba나 Tencent와 같은 중국 거대 기업으로부터 엄청난 돈을 투자받는 최근 가장 핫한 중국 AI 기반 생성 기술 관련 스타트업이라고 합니다.
위 모델들은 자연어처리 분야에 국한되어있지만, GPT와 이들을 바탕으로 vision 도메인도 함께 다루는 거대 모델들도 등장하고 있습니다. 대표적으로는 MiniGPT4와 LLaVA, 더욱 최근에는 LLaViLo도 등장하게 됩니다. 물론 저도 이 모델들을 모두 알지는 못하기 때문에 어떠한 특성을 가지는지 추후에 알아볼 예정이므로, 이미지-텍스트 간 멀티모달 task를 수행하는 데에 있어 좋은 representation을 추출해주는 거대 모델들이라는 점만 우선 알고 넘어가겠습니다. 아무튼 위와 같은 거대 언어 모델들이 세계적인 대기업들과 연구소를 필두로 연구되고 있는 상황에서, 이들을 비디오 도메인으로 잘 가져와 활용하는 것도 좋은 contribution이 될 수 있다고 생각합니다.
저자가 Introduction에서 꽤나 길게 최근 거대 언어 모델 또는 거대 멀티모달 모델을 설명한 이유는 본 논문에서 fine-tuning도 없는 zero-shot 기반 TSGV를 수행하기위해 이들을 활용하기 때문이었던 것 같고, 이제는 진짜 TSGV task 자체에 대해 이야기를 시작합니다. 이미 TSGV 학계에서는, 벤치마크에 사용되는 데이터 셋인 Charades-STA와 ActivityNet Captions에 대한 편향 문제가 심각하게 다뤄지고 있었습니다. 데이터 셋 내 존재하는 편향에 대해서는 제가 이전에 작성해둔 리뷰에서 설명한 적이 있으니 아래 링크를 참고해주시면 감사드리겠습니다.
위 리뷰에 담겨있는 편향을 간단히 설명해드리면, 데이터 셋의 텍스트 쿼리에 존재하는 동사가 굉장히 편향되어 분포한다는 것입니다. 편향은 결국 사람이 비디오를 보고 텍스트 쿼리를 annotate하기 때문에 생기는 문제인데요, 여기서 저자는 원인은 동일하지만 분포의 편향과는 조금 다른 두 가지의 문제점을 지적합니다. (기존에 다뤄지던 문제인 동사나 명사의 편향된 분포는 Charades-STA, ActivityNet Captions 데이터 셋을 대상으로 지적되었지만 본 논문에서 이야기하는 아래 두 가지 문제점은 21년 9월에 공개된 새로운 TSGV 데이터 셋인 “QVHighlights“를 예시로 삼아 지적되고 있습니다. 또한 QVHighlights 데이터 셋 구축 과정에서 기존에 나타났던 단어 분포의 편향 문제는 해결된 상태입니다.)

두 가지 문제점은 각각 그림 2-(a)와 2-(b)에서 알아볼 수 있는데요, 첫 번째는 텍스트 쿼리 자체에 오타가 존재한다는 것입니다. 그림 2-(a)를 보시면 “A skeleton ociture ~”라는 문장이 쿼리로 주어져있는데요, 이는 “picture”의 오타로 예상됩니다. 만약 이를 텍스트 encoder에 그대로 넣는다면 표현력을 헤치는 원인이 될 것입니다. 또한 Gronuding을 수행할 때 데이터 셋의 텍스트 쿼리 형태인 문어체보다 구어체나 slang 등을 입력하는 것이 더 편한 사람들이 분명히 존재할 것이라고 주장합니다. 위 문제점과 주장을 다루기 위해, 기존의 쿼리를 올바르게 고치면서 의미를 유지하되 다양하게 표현하는 데에 거대 언어모델을 사용할 것임을 예상해볼 수 있습니다.
두 번째 문제점은 2-(b)에서 확인할 수 있습니다. 비디오가 진행되고 있고, 이 중 특정 구간에 해당하는 텍스트 쿼리로 “Blonde teenage girl turns off the lights while vlogging alone“이라는 문장이 주어집니다. 본 그림만을 통해 알 수는 없지만 저자에 따르면 실제로 저 비디오에서 여자가 직접 “불을 끄는” 행동은 일어나지 않는다고 합니다. 어떠한 이유에서인진 모르겠지만 실제 비디오와 텍스트 쿼리의 내용이 일치하지 않고 있는 것입니다.
이러한 문제점을 갖는 텍스트 쿼리가 데이터 셋에 얼마나 분포하는지 정량적으로 알기는 어려울 것입니다. 하지만 지적되고 있는 두 가지 문제점이 모델의 표현력 학습에 큰 저해를 불러온다는 점은 명확하기 때문에, 이를 해결하기 위해 저자가 어떠한 방법론을 제안하는지 알아보겠습니다.
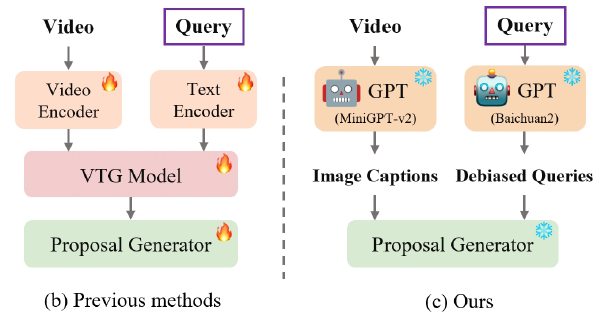
기존 방법론들과의 차별점은 위 그림 1-(b), (c)를 통해 알 수 있습니다. 기존 모델은 Visual encoder와 Text encoder를 따로 두고 가중치를 갱신하며 학습합니다(물론 데이터 셋과 방법론에 따라 Visual encoder를 freeze한 채 수행하기도 합니다.). 이후에는 실질적으로 두 모달의 align을 맞추고 multu-modal interaction 과정을 거쳐 한 쌍의 (비디오-텍스트 쿼리)에 대한 구간을 예측해내는 방식이었습니다. 하지만 저자가 제안하는 방법론은 위에서 언급한 문제들로부터 벗어나고자 거대 언어 모델 Baichuan2와 거대 멀티모달 모델 MiniGPT-v2를 활용하는 모습을 볼 수 있습니다. 학습이나 fine-tuning 과정을 아예 거치지 않고 Grounding을 수행한다는 것이 본 방법론의 장점입니다.
Contribution을 정리한 뒤 방법론을 자세히 알아보겠습니다.
Contribution
- To the best of our knowledge, we are the first zero-shot method to utilize GPT on VTG without training or fine-tuning.
- We present a novel framework, VTG-GPT, which effectively leverages GPT to mitigate human prejudice in annotated queries. Furthermore, VTG-GPT distinctively models debiased queries and video content within the linguistic domain to generate temporal segments.
- Comprehensive experiments demonstrate that VTG-GPT significantly surpasses SOTA (State-of-the-Art) methods in zero-shot settings. More importantly, this method achieves competitive performance comparable to supervised methods.
2. Methods
방법론은 아래와 같이 총 4단계로 구성되어있습니다.
- Query Debiasing
- Image Captioning
- Proposal Generation
- Post-Processing
2.1 Overview
하나의 비디오 V \in{} \mathbb{R}^{N_{v} \times{} H \times{} W \times{} 3}와 상응하는 텍스트 쿼리 T \in{} \mathbb{R}^{L_{t}}가 주어집니다. N_{v}, L_{t}는 각각 비디오 내 프레임 개수, 문장 내 단어 개수를 의미합니다. 이들을 모델의 입력으로 주어 구간에 대한 예측 [t_{s}, t_{e}] \in{} \mathbb{R}^{N_{s} \times{} 2}를 예측하는 것이 목표입니다. N_{s}는 예측해낸 segment 구간의 개수입니다. 전체 파이프라인은 아래 그림 3에서 확인할 수 있습니다.
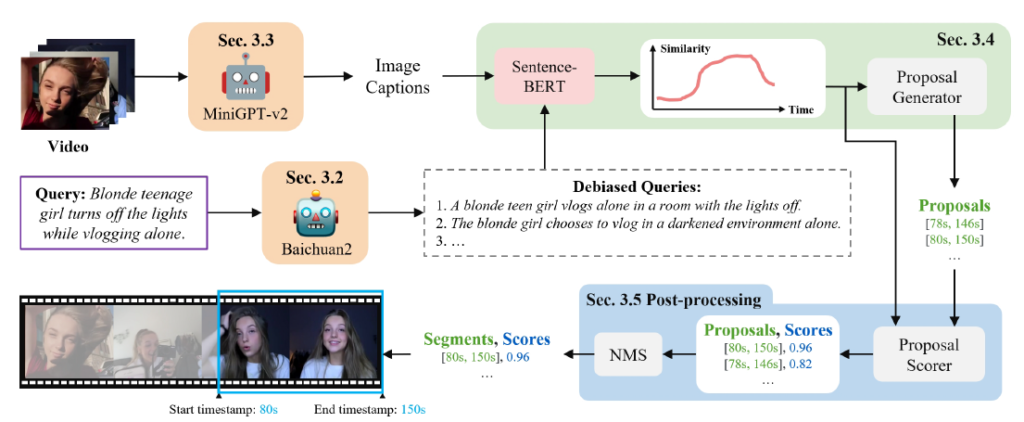
그림 3과 함께 파이프라인에 대한 추가적 설명을 더 드리자면, 먼저 기존 데이터 셋에 존재하는 biased query(보라색 테두리)를 Baichuan2 모델을 통해 모두 refine하여 \mathcal{Q} \in{} \mathbb{R}^{N_{q} \times{} L_{t}}를 얻어줍니다. 이후에는 비디오로부터 프레임을 샘플링하고 샘플링된 프레임을 대상으로 image captioning을 수행해줄 거대 멀티모달 모델인 MiniGPT-v2를 활용하여 caption C \in{} \mathbb{R}^{N_{v} \times{} N_{q}}를 얻습니다.
여기까지 수행했다면 기존 텍스트 쿼리는 Baichuan2 모델을 통해 오타나 문법적 오류가 수정된 상태이고, 비디오는 프레임으로 변환되고 각각은 MiniGPT-v2를 거쳐 자연어로 변환된 상태입니다. Grounding을 위해 정제된 쿼리와 프레임 caption은 SentenceBERT의 입력으로 들어가 feature로 만들어지고, 이후에는 각 feature 간 유사도를 구할 수 있게 됩니다. 이 유사도를 통해 최종 예측 구간을 어떻게 만드는지와 단계 별 세부 사항은 뒤에서 알아보겠습니다.
2.2 Query Debiasing & Image Captioning
사실 본 방법론은 학습 과정이 없기에 설명해야할 loss가 없습니다. 또한 모듈들도 직접 고안한 것이 아니라 거대 모델을 가져다 쓰기 떄문에 간단간단하게 설명하겠습니다.
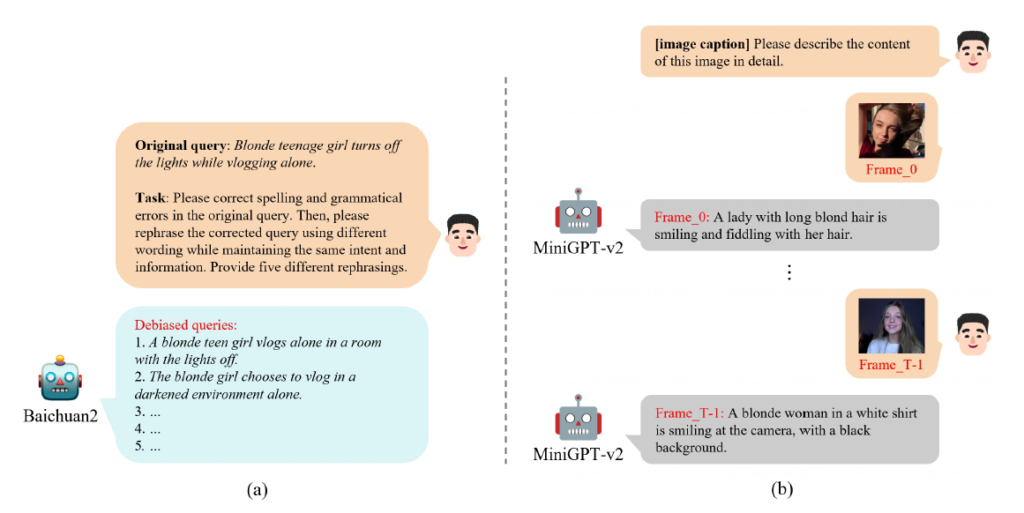
그림 4-(a)는 Query Debiasing 과정, 그림 4-(b)는 Image Captioning 과정을 나타내고 있습니다.
Query Debiasing 과정의 역할은 데이터 셋에 존재하는 biased query T를 입력받아 debiased query T_{C}를 출력하는 것입니다. 그림 4-(a)를 보면 Baichuan2 모델에게 Original query T와 Task를 입력해주고 있습니다. Task는 저희가 ChatGPT를 이용하는 것과 동일하게 모델에게 주는 요청사항인데요, 내용은 T의 오타나 문법적 오류를 수정해주고, real-world 쿼리에 대응하고자 수정된 문장을 기준으로 의미는 동일하되 표현이 조금씩 다른 5개의 rephrase 된 문장을 달라는 것입니다. LLM 연구에 따르면 거대 모델에게 요청사항을 한 가지씩 주는 것이 효과적이라고 하지만, 저자는 한 가지씩 주는 것과 그림 4-(a)에서처럼 한 번에 주는 것을 비교했을 때 한 번에 주는 것이 더욱 효과적이었다고 합니다.
이 부분이 제가 리뷰 맨 처음에 언급하였던 OTT 제안서에 작성한 내용과 동일한데요, 저도 데이터 셋의 텍스트 쿼리는 문어체이지만 사람들이 던지는 문장은 구어체 또는 단어, 비문일 확률이 높기에 이에 대응하고자 GPT 등을 활용해 내용은 동일하되 여러 방면으로 문장을 표현하여 학습에 사용하자는 아이디어를 낸 적이 있었는데, 사람들 생각이 다 똑같은 것 같습니다..ㄹ
다음으로 Image Captioning 과정은 앞서 얻은 쿼리와 유사도를 구할 프레임 별 caption을 구하는 과정에 해당합니다. 원래는 Visual feature를 추출해 텍스트 쿼리 feature와 유사도를 구하는 것이 기존 연구의 흐름이었지만 본 연구에서는 프레임을 text로 내려 (텍스트 쿼리-frame caption) 간 유사도를 구하는 방식인 것입니다.
이는 거대 멀티모달 모델인 MiniGPT-v2를 통해 이루어지며 그림 4-(b)를 보았을 때 모델에 던지는 prompt 앞 [image caption]이 들어가있는 것을 볼 수 있습니다. 이렇게 문장 앞 []에 수행해야 하는 task를 넣어주면 이것이 모델에게 할 일을 좀 더 명시적으로 밝혀줌으로써 성능을 높이는 역할을 해줍니다. 이렇게 프레임 별 자연어 caption을 얻었다면, 앞서 얻은 쿼리와 유사도를 계산해주면 되겠죠.
Baichuan2 모델로부터 얻은 정제된 쿼리와 MiniGPT-v2로부터 얻은 image caption은 사람이 보았을 때는 의미론적으로 굉장히 유사하게 됩니다. 저자는 먼저 CLIP의 text encoder(CLIP-T)를 활용해 유사도를 구하고, 뒤에 설명할 proposal generation 방식을 통해 수행한 Grounding 성능을 아래 표 1에서 보여줍니다.
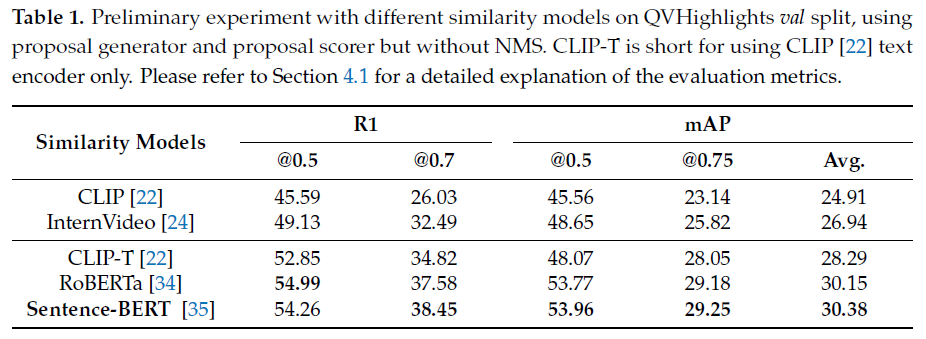
3번째 행을 보면 CLIP-T(text encoder only)의 성능인데, NMS를 적용하지 않았음에도 기존의 CLIP이나 대용량 video foundation 모델인 InternVideo보다 Grounding(R1)에서 훨씬 높은 성능을 보여주고 있다는 점이 놀랍습니다. 거대 언어 및 멀티모달 모델의 힘이 굉장하다는 것을 보여주네요.
2.3 Proposal Generation
Computing query-frame similarity
앞서 뽑은 정제된 쿼리와 프레임 별 caption은 자연어이기에 CLIP의 text encoder를 거쳐 feature로 만들 수 있었는데, 두 모달 모두 현재는 text로 내려와있는 상태입니다. 기존 연구에서 Image-text 멀티모달 모델인 CLIP보다 language-specific 모델을 활용하는 것이 text 단일 모달 상황에서는 더욱 성능이 높다는 것을 보여주었는데요, 저자도 이에 맞춰 RoBERTa나 Sentence-BERT를 선택하였고 각 성능은 표 1에서 확인할 수 있습니다. 모델을 통해 얻은 쿼리와 caption의 feature는 각각 f_{q} \in{} \mathbb{R}^{N_{q} \times{} d}, f_{c} \in{} \mathbb{R}^{N_{v} \times{} d}입니다.
이후 아래 수식 (1)을 통해 각 프레임에 대한 caption 별 유사도 S_{s}를 구해줍니다.
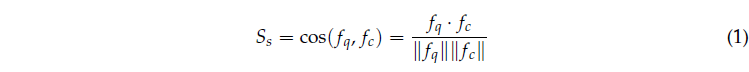
처음으로 등장한 수식인데 단순한 코사인 유사도를 표현하고있습니다. 이렇게 구한 유사도의 shape은 S_{s} \in{} \mathbb{R}^{N_{q} \times{} N_{v}}가 될 것입니다. 각 쿼리에 대해 각 비디오 프레임들이 상응할 확률을 의미한다고 볼 수 있겠네요.
Proposal generator
쿼리들과 각 프레임에 대한 유사도 S_{s}를 얻었으니, 이제는 상응 구간에 대한 예측 proposal P \in{} \mathbb{R}^{N_{p} \times{} 2}를 생성해줘야합니다. 가장 쉬운 방법은 유사도 S_{s}에 고정된 값으로 thresholding을 거쳐 구간을 만들어내는 것일텐데, 모든 비디오와 쿼리에 대해 고정된 값을 사용한다면 최적이라 보기 어려울 것입니다. 추출한 코사인 유사도의 스케일이 아무리 -1 ~ 1이라고 해도 비디오 마다, 쿼리마다 세심하게 다를 것이기 때문에 이 방식은 최적의 proposal을 만들기에는 너무 naive하다고 볼 수 있습니다.
Proposal 후보들을 만들기 위해서 저자는 동적인 threshold를 찾는 방식을 한 가지 제안합니다. 먼저 S_{s}에서 하나의 쿼리, 즉 i번째 쿼리에 대한 각 프레임들 간의 유사도를 S_{s}^{i} \in{} \mathbb{R}^{N_{v}}라 칭합니다. 이후 이 값을 이용해 히스토그램을 만들고 가장 높은 k개의 유사도 값을 포함하는 bin을 dynamic threshold \theta{}로 사용하게 됩니다. 이는 아래 수식 2와 같습니다.
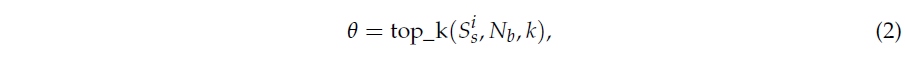
Bin의 개수 N_{v}와 k는 하이퍼파라미터입니다. 이제 threshold \theta{}를 정했으니 이 값을 이용해 프레임들을 묶어 구간으로 만들어주면 됩니다. i번째 쿼리에 대한 각 프레임들 간의 유사도를 S_{s}^{i} 중 j번째 프레임에 대한 유사도 값은 S_{s}^{i, j} \in{} \mathbb{R}^{1}입니다. 이 값들에 대해 \theta{}로 thresholding을 하면 되는 것입니다. 첫 프레임부터 쭉 보다가 특정 프레임의 S_{s}^{i, j} 값이 \theta{}를 넘는다면 그 지점은 구간의 시작 지점으로 사용합니다. 이후 계속 뒷 프레임을 보다보면 언젠가 \theta{}보다 낮은 유사도 값을 가지는 S_{s}^{i, j}가 등장할 것입니다. 낮은 프레임이 연속해서 \lambda{}개 등장하면, 구간이 확실히 끝났다고 판단하여 마지막으로 \theta{}를 넘은 프레임이 끝 지점으로 사용됩니다. 이 과정을 여러 개의 쿼리와 threshold에 대해 진행해주면 여러 개의 proposal 후보들 집합 P \in{} \mathbb{R}^{N_{p} \times{} 2}을 만들어줄 수 있게 됩니다.
2.4 Post-Processing
앞서 얻은 proposal의 집합 P에는 중복되는 예측들이 많을 것입니다. 따라서 최종적인 예측 구간을 만들기 위해 NMS를 적용해줍니다. Proposal들에 대한 NMS를 진행하려면 각 proposal에 대한 score가 필요한데, 단순하게 proposal 내 score들을 평균내거나 생성된 구간 내의 유사도를 또 thresholding하여 score를 만드는 방식을 사용하지 않습니다. 저자들의 관찰에 따르면 GT 구간 내 포함되는 장면 전환 지점에서는 특출나게 높은 유사도를 보여주기 떄문에, 평균내거나 thresholding 하는 경우 장면이 전환되는 지점을 기준으로 짧은 proposal들만 살아남아 제대로된 구간이 생성되지 않는다고 합니다. 그래서 저자들은 proposal의 길이가 길수록 좀 더 높은 score를 갖는 scoring 방식을 제안합니다. 이렇게 GT 구간을 활용해 분석한 점을 방법론 고찰에 담았다는 점이 조금 찝찝하긴 하지만, 어떤 방식을 통해 최종 score S_{f} \in{} \mathbb{R}^{N_{p}}를 구했는지 아래 수식 3을 통해 알아보겠습니다.
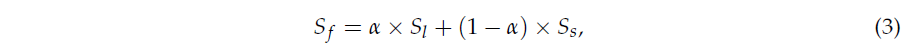
수식 3을 보면 하이퍼파라미터 \alpha{}를 통해 기존 유사도 S_{s}와 어떤 값을 weighted sum 해주고 있습니다. 해당 값 S_{l} = L_{p}/L_{n}인데, 여기서 L_{p}는 proposal 내에서 \theta{}를 넘는 score의 개수이고, L_{n}은 전체 비디오 중 \theta{}를 넘는 score의 개수입니다. 이 값은 proposal의 길이가 길수록 높을 것이니 기존에 구해둔 유사도 S_{s}와 함께 고려해주고 있는 것을 볼 수 있습니다. 이후에는 NMS를 적용하여 중복되는 proposal을 삭제하고 최종 예측 Seg \in{} \mathbb{R}^{N_{s} \times{} 2}를 만들어냅니다.
방법론은 여기서 마치고 세부사항과 실험 결과에 대해 알아보겠습니다.
3. Experiments
벤치마크에 사용되는 데이터 셋은 Charades-STA, ActivityNet Captions, QVHighlights입니다. QVHighlights와 Charades-STA는 초 당 0.5개의 프레임을, ActivityNet Captions는 비디오 길이가 길어 초당 1개의 프레임을 샘플링하여 사용했습니다. 거대 모델과 관련하여 MiniGPT-v2는 LLaMa-2-Chat-7B 기반 모델을, 마찬가지로 Baicuan2-7B-Chat 또한 LLaMa-2 모델 기반입니다. 하나의 기존 쿼리 당 5개의 debiased 쿼리를 생성하였고, 문장 간 유사도를 구할 feature를 추출하는 데에는 최종적으로 SentenceBERT를 사용하여 성능을 리포팅하였습니다. 또한 proposal generation을 위한 히스토그램의 bin은 10, 살펴볼 상위 score의 개수 k는 8로, 구간을 만들기 위해 연속되는 프레임 개수 \lambda{}는 6으로 설정되었습니다. Scoring을 위한 계수 \alpha{}는 0.5입니다.
3.1 Comparisons to the State-of-the-Art
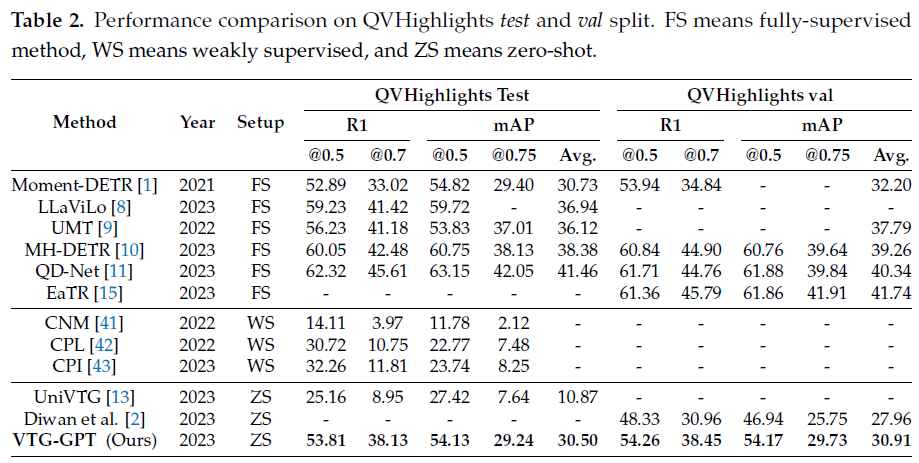
기존에는 Charades-STA와 ActivityNet Captions 데이터 셋에 대해서만 벤치마크가 진행되었지만, 최근에는 21년 말에 공개된 QVHighlights 데이터 셋에 대한 벤치마크도 활발히 찍히고 있습니다. Fully-supervised, Weakly-supervised, Zero Shot 세팅을 나눠서 리포팅하고 있는 모습이네요.
볼만한 점은 Zero-Shot 방법론들 중 압도적인 성능을 보여주고 있다는 것입니다. UniVTG는 multi-task 모델이기에 성능만이 장점은 아니지만, 저자가 제안하는 VTG-GPT가 훨씬 높은 성능을 보여주고 있고, 가장 최근 SOTA인 Diwan [2] 방법론보다도 높은 성능을 달성하고 있습니다. 또한 QVHighlights 데이터 셋과 함께 제안된 방법론인 Moment-DETR은 Fully-supervised 기반인데, 연도의 차이가 좀 있긴 하지만 Zero shot 기반의 VTG-GPT가 유사하거나 높은 정확도를 보여준다는 점이 놀랍습니다.
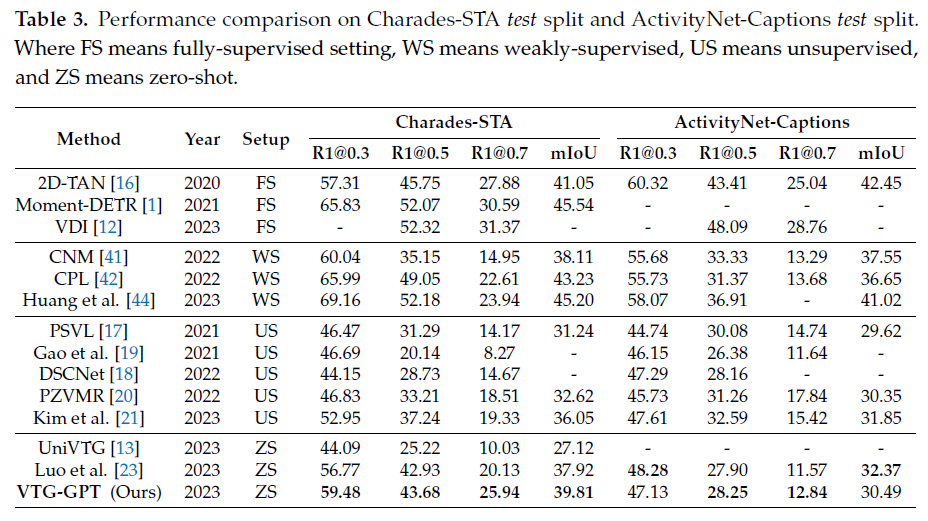
기존에 벤치마킹되던 데이터 셋에서도 높은 성능을 보여주고 있네요. 다만 같은 Zero shot 방법론인 Luo [23] 보다는 ActivityNet Captions 데이터 셋에서의 성능이 조금 낮은데, 저자는 프레임 샘플링 레이트가 더 커서 (더 띄엄띄엄 샘플링) 위와 같은 결과를 얻은 것이 아닌가 생각해본다고 합니다. 경험적으로 보았을 때 프레임 샘플링 레이트가 두 배임에도 이 정도의 성능 하락이면 VTG-GPT의 방법론 자체는 굉장히 좋다고 볼 수 있을 것 같습니다. 또한 문제점 자체가 새로 제안된 데이터 셋인 QVHighlights를 기준으로 제기되었기 때문에 크게 기대는 안하였음에도 불구하고 예상보다 높은 성능을 보여준다는 점이 인상깊습니다.
3.2 Ablation Studies
본 논문에서의 모든 ablation study는 QVHighlights val split으로 진행되었습니다.

표 4는 기존 데이터 셋의 쿼리를 debiasing 하지 않고 바로 SentenceBERT를 통해 유사도를 구하여 proposal을 생성했을 때와 본래 방법론의 비교 실험입니다. 우선 Debiasing을 진행함에따라 성능이 크게 오르는 것을 볼 수 있고, Debiasing을 하지 않아도 거대 모델들의 힘을 빌려 기존 방법론 Moment-DETR보다 높은 성능을 보여주고 있네요. UMT보다 낮은 mAP를 보이는 이유에 대해 저자가 딱히 언급한 점은 없습니다. 왜 QVHighlights에서 Highlight Detection만 하고 Grounding 성능은 보여주지 않는지가 궁금하긴 하네요.
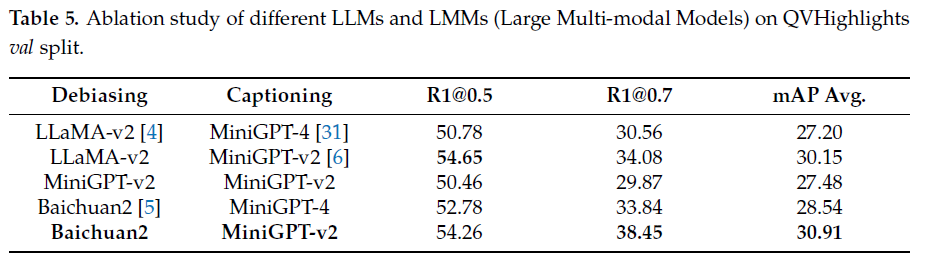
표 5는 거대 언어모델 ablation 성능입니다. Debiasing에는 Baichuan2, Image captioning에는 MiniGPT-v2가 최종적으로 사용되었는데요, 생각보다 거대 모델의 조합 별 성능 차이가 심한 것을 알 수 있습니다. 보아하니 MiniGPT-v2는 단일 모달의 언어 모델링에도 사용되고 멀티 모달 모델링에도 활용할 수 있는 것 같네요.
4. Conclusion
이 논문을 읽게 된 이유는 추후 논문 작업을 위해 GPT 또는 거대 foundation 모델을 기반으로 추가적인 learning signal을 받아올 수 있을지, 또는 받아온다면 코드 레벨로는 어떠한 api를 사용할 수 있는지 알아보기 위해서였습니다. 저자들이 깃허브 링크를 공개하긴 했지만 아직 비어있는 부분이 많아 바로 활용하기는 어려울 것 같습니다.
결국 이 방법론은 학습 하나 없이 거대 모델만을 이용해 inference를 수행하는데요, inference를 위해 거대 모델로부터 문장을 받고 freeze 된 SentenceBERT를 통해 feature로 만들어주어 후처리를 해주기 때문에 꽤나 효율적이면서 성능이 높은 깔끔한 방법론이라는 생각이 들었습니다. 이전부터 위와 같은 거대 모델을 grounding에 붙여보고자 하는 생각을 가지고 있었는데, naive한 방법론으로 높은 성능을 보여주어 좋은 baseline으로 삼을 수 있을 것 같습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요. 김현우 연구원님. 좋은 리뷰 감사합니다.
비디오를 text caption 형태로 변환해서 사용한다는 점이 신선한 논문 같습니다. 특히 video captioning도 아니고 image captioning을 수행해서 temporal한 정보는 거의 다 사라졌을텐데도 성능이 상당히 높네요…
특히 VTG-GPT의 성능이 QVHighlight에서는 약지도학습이나 일부 지도학습 방법보다 좋아서 놀랐는데, 막상 Charades나 ANET에서는 또 낮은 것은 해당 데이터셋들의 편향이 QVHighlight보다 훨씬 심하기 때문인 건가요? 모델 내부에 편향을 잡아주기 위한 query debiasing 과정이 있음에도 성능이 일관적이지 않아 의외입니다.
감사합니다.
저자가 QVHighlights 데이터 셋을 대상으로 이야기하는 편향과 기존 학계에서 지적되던 ActivityNet Captions, Charades 데이터셋의 편향과는 조금 다릅니다. 저자들이 문제 정의 자체를 QVHighlights에서 하기도 했고, 사실 몇 년 전 연구라고 하더라도 Zero shot 방법론이 fine-tuning도 없이 Fully-supervised보다 높기는 쉽지 않기에 Zero shot 내 SOTA인 것만으로도 큰 contribution이라고 개인적으로는 생각합니다.
안녕하세요. 좋은 리뷰 감사합니다.
Image Captioning 모델의 경우는 finetune의 과정 없이 RGB 프레임을 입력으로 넣어주면 대응되는 캡션을 생성해주는 것인가요? 단일 프레임이 아니라 클립이나 샷 단위의 입력도 지원하나요?
이미 거대 데이터셋으로 사전학습을 마쳤기에 fine tuning 과정은 필요 없는 것이 맞습니다.
아직 거대 모델들이 비디오 분야로 넘어오지는 못한 것으로 알고 있는데, 워낙 빠르게 연구되는 분야다보니 최신 논문에 대한 서베이가 필요할 것 같습니다.