
이번에 소개 드릴 논문은 DepthAnything이라는 논문입니다. 논문 및 코드가 공개된지는 몇개월 됐지만 지난 2월 26일날에 CVPR accept list가 공개되면서 본 논문도 CVPR2024에 게재된 것이 확인됐네요. 해당 논문은 Segmentation Anything Model(SAM)과 유사하게 Depth Estimation task에 대한 foundation model을 의미합니다.
그럼 리뷰 시작하겠습니다.
Intro

최근에 GPT, SAM, Sora등과 같이 foundation model의 성공이 vision과 NLP 분야 가리지 않고 나타나고 있으며, 이들의 성공의 주요 원인 중 하나는 방대한 양에 달려있다고 합니다. 저자는 여기서 monocular depth estimation(MDE) 분야 역시 다양한 field에서 활용되는 매우 중요한 기술이기에 foundation model의 필요성이 증대될 것이라고 얘기하죠.
하지만 Depth estimation은 모델 학습을 위한 GT를 취득하는게 상당히 어려워서 foundation model을 만드는 것이 쉽지 않았습니다. 20년도에 TPAMI에 게재된 Midas라고 하는 방법론이 아마도 최초의 foundation depth model로 알려져있는데, 해당 모델의 경우 방대한 양의 학습 데이터를 취득하고자 노력했지만 데이터가 다루는 범위가 제한적이기 때문에 특정 상황에서 처참한 성능을 보여주었다고 합니다.
따라서 저자들은 어떤 상황에서도 깊이를 잘 추정할 수 있는 foundation model을 만드는 것을 목표로 두었으며 그러기 위해서는 모델 학습을 위한 방대한 양의 데이터를 수집 및 가공하는 것에 집중을 했습니다.
옛부터 깊이 데이터셋을 만드는 방식으로는 Lidar/Depth camera와 같은 sensor를 직접 활용하거나, 스테레오 매칭 또는 SfM 등의 알고리즘을 사용했는데 이는 비용적, 시간적 측면에서 단점이었으며 특정 상황에서는 사용하기 어려웠다고 합니다. 즉 foundation model을 만들기 위해서는 몇백만 몇천만의 학습 데이터를 수집해야하는데, 스테레오 이미지, 비디오 시퀀스로 촬영된 이미지 또는 depth sensor와 camera가 동시에 촬영된 데이터들은 쉽게 취득 및 접근하기 어렵다는 것이죠.
저자들은 그래서
뎁스 센서 사용하거나 스테레오 영상 사용하는 것 말고 단일 영상으로 모델을 학습시키는 방향을 고집하였다고 합니다. 단안 영상으로 학습 데이터를 꾸렸을 때의 이점은 첫째로 단안 영상은 구하기가 너무 쉬우며, 둘째로 상당히 다양한 장면들을 다루는 단안 영상들이 많고 마지막으로 그냥 사전 학습된 MDE 모델을 태우면 pseudo label을 취득할 수 있다라는 점이 있습니다.
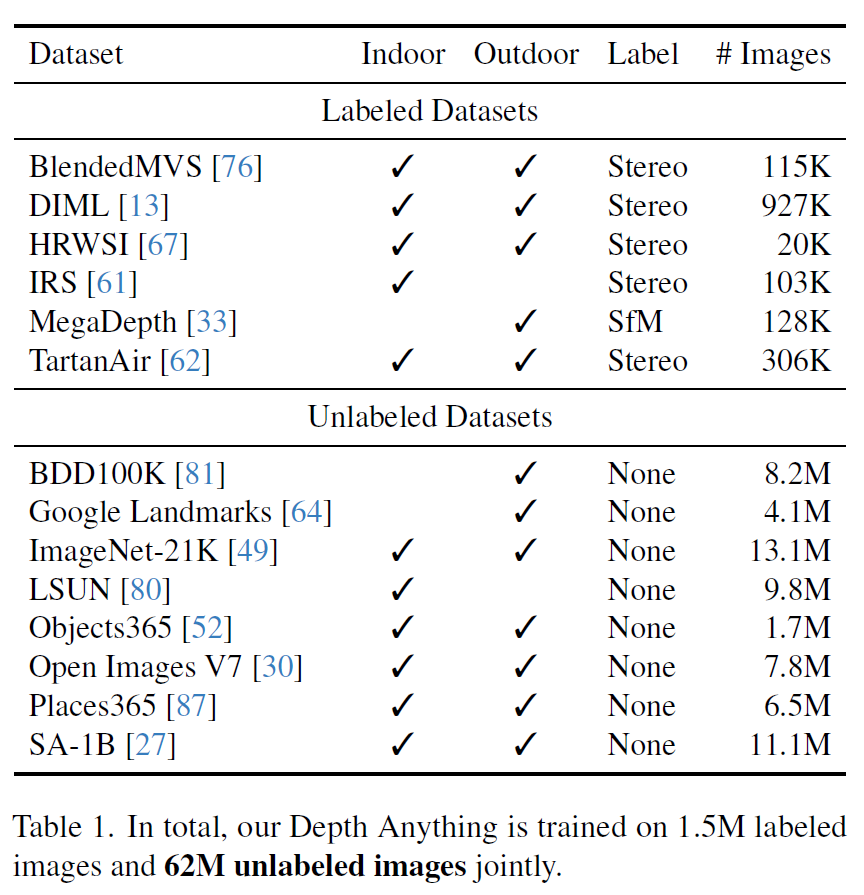
결과적으로 저자들은 SA-1B, Open Images, BDD100K 등 총 8개의 공개된 Large 데이터 셋에서 다양하고 유익한 영상들을 모아 총 62M의 학습 데이터를 구성하였다고 합니다. 물론 해당 데이터들은 Depth Estimation task를 위한 데이터 셋이 아니기 때문에 당연히 영상과 대응되는 Depth GT가 존재하지 않습니다. 즉 Unlabeled image 학습을 위한 Pseudo Depth GT가 필요로 한 것이죠.
따라서 저자들은 unlabeled 데이터에 대한 pseudo label을 생성하기 위해서 150만 장의 labeled 데이터 셋으로 모델을 사전 학습 하였습니다. 그리고 사전 학습된 teacher model로 unlabeled data에 대한 pseudo GT를 생성해서 labeled data랑 함께 학습시키는 것이죠.
물론 이렇게만 보면 어 그냥 단순히 방대한 양의 label image로 학습 먼저 하고 그 다음에 훨씬 더 방대한 양의 unlabeled image를 섞어서 semi supervised learning을 했다는 것으로 보여질 수 있습니다. 물론 큰 틀로 놓고 보면 그게 맞긴 한데, 그렇다고 해서 별 문제 없이 쉽게 모델을 학습시켜 foundation model을 탄생시킨 것은 아니었습니다.
labeled data가 1.5M, unlabeled data는 65M이 될 정도로 방대한 양의 데이터를 사용하다보니 적은 데이터로 학습하던 기존 논문들과 달리 예상치 못했던 문제들이 자꾸만 발생했던 것이죠. 예를 들어, 저자들이 처음 실험할 때는 단순히 pseudo labeled images와 labeled image를 섞어서 동시에 학습시켰는데, 이는 그냥 labeled image를 사용해서 학습하는 것보다 성능이 더 낮게 나왔다고 합니다.
또한 기존 연구들에서는 semantic segmentation이 depth estimation과의 multi-task learning을 수행할 때 효과를 본다고 했었는데, 방대한 양의 데이터를 활용하는 본 연구 실험 환경에서는 MDE 모델이 이미 충분히 잘 동작할 경우, 추가적인 테스크로 얻을 수 있는 성능 이점은 제한적이라는 사실도 발견하였습니다.
결과적으로 저자들은 문제의 원인이 무엇일까 고민을 하고 이를 해결하여 generalization performance를 크게 향상시킨 모델을 만들게 됩니다.
그러면 보다 자세한 내용에 대해서는 Method에서 다뤄보도록 하죠.
Method
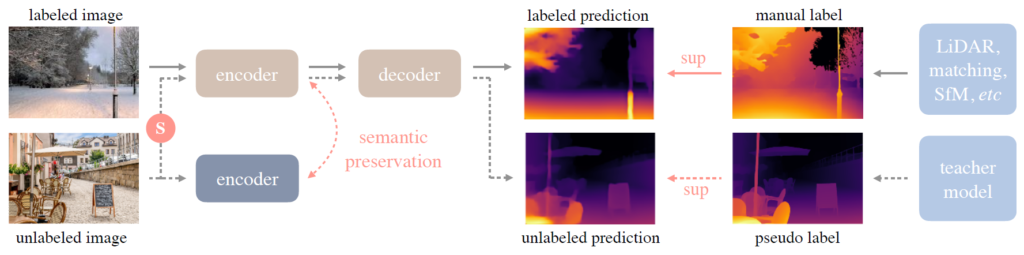
자세한 방법론에 대해 들어가기 앞서 다시 한번 설명드리면, 본 논문에서 수행하는 task는 단안 영상 기반 깊이 추정입니다. 즉 영상 한장으로 깊이를 추정하는 것이며, labeled image에 대해서는 supervised learning을 하고 unlabeled image에 대해서는 pseudo label을 생성하여 마찬가지로 supervised learning을 하는 것입니다.
본 논문에서는 labeled dataset과 unlabeled dataset을 각각 \mathcal{D}^{l}, \mathcal{D}^{u} 라고 표기하며, 먼저 \mathcal{D}^{l} 를 통해 teacher model T를 학습시키게 됩니다. 그리고 이 T 모델을 활용해서 \mathcal{D}^{u} 에 대한 pseudo GT를 생성하고 이를 토대로 \mathcal{D}^{l} + \mathcal{D}^{u} 셋을 모두 섞어서 student model을 학습시키는 framework을 지니게 됩니다.
Framework에 대한 보다 자세한 그림은 그림2에서 확인이 가능합니다.
Learning Labeled Images
그러면 가장 첫째로 labeled set을 활용해서 teacher model을 학습시키는 방법에 대해서 다뤄보죠. 저자들은 depth foundation model의 선구자 격 논문인 Midas의 학습 방식을 전적으로 따랐다고 합니다. 하지만 Midas는 학습 코드를 공개하지 않았기 때문에, 저자들은 이를 reproduce하는 것을 우선으로 수행하였다고 하네요.
먼저 Midas의 학습 방식은 다음과 같습니다. 첫째로 모델 학습에 사용하는 Depth GT는 모두 inverse(즉 역수) 취해서 dispairty map으로 변경해줍니다 (d = 1/t, 여기서 d는 disparity, t는 depth). 그 후에 해당 disparity map에 normalization을 취해서 0~1 사이로 스케일링을 해줍니다.
foundation model을 학습하기 위해 Midas는 다양한 종류의 public data를 섞어서 대용량의 Depth dataset (Mix dataset)을 만들었는데, 이때 outdoor, indoor 그리고 데이터 셋을 취득한 sensor configuration 변화 등으로 인해 각 데이터에서 제공하는 GT Depth (or disparity)가 의미하는 스케일 값이 상이하게 됩니다.
이러한 데이터 별 스케일 불일치는 모델 학습에 상당히 부정적인 영향을 끼치게 되기에 Midas 논문에서는 스케일 불변성을 지니는, 즉 절대적인 거리를 측정하는 것이 아니라 상대적인 거리(e.g., 뒤에 있는 나무보다 앞에 사람이 상대적으로 더 가까움)을 학습 및 추정하도록 affine-invariant loss라는 것을 제안하게 됩니다.
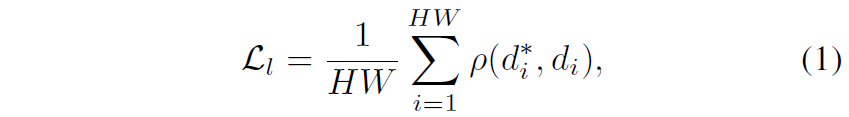
여기서 d^{*}_{i}, d_{i}, \mathcal{p} 는 각각 i번째 픽셀에 해당하는 prediction & GT disparity 값과 affine-invariance mean absolute error loss를 의미합니다. 즉 \mathcal{p} 는 다시 나타내면 \mathcal{p}(d^{*}_{i}, d_{i}) = |\hat{d}^{*}_{i} - \hat{d}_{i}| 이며 여기서 \hat{d} 의 의미는 disparity 값이 정규화(scaled & shifted) 된 것을 의미합니다.
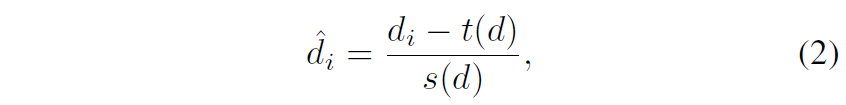
여기서 t(d), s(d) 는 각각 disparity map이 zero translation과 unit scale을 가지도록 하는 align 값으로 수식3과 같이 정의 가능합니다.
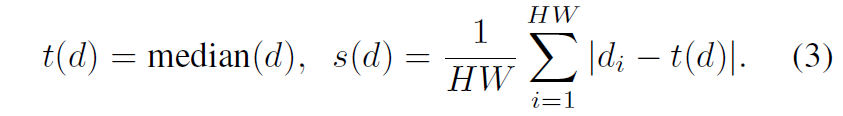
아무튼 위에서 정리한 것과 같이 GT disparity map과 모델이 추론한 disparity map에 대해 정규화 과정을 거친 뒤 affine-invaraint loss로 상대적인 depth를 추론하게끔 모델을 학습시키는 것이 Midas가 제안한 주요 학습 framework입니다.
다시 DepthAnything 논문으로 돌아오면, 저자들은 Midas의 학습 프레임워크를 따르지만 데이터 셋은 Midas가 사용한 총 12 종류의 데이터 셋보다 더 적은 6 종류의 public data를 섞어서 학습을 진행하였다고 합니다.
대표적으로 저자들은 Depth estimation 분야에서 매우 대표적인 두 데이터셋 NYUv2(indoor)와 KITTI dataset(outdoor)를 labeled set에 제외시켰는데, 이는 추후에 foundation model을 평가하는데 있어 진정한 zero-shot evaluation을 수행해야하기 때문에 학습 데이터 셋에서 완전히 배제시켰다고 합니다.
그 외에 일부 데이터는 더이상 사용이 불가능하고, 또 다른 일부 데이터 셋들은 모델 학습에 사용하기에는 해상도 등 퀄리티가 떨어졌기 때문에 학습 데이터로 사용하지 않았다고 하네요.
비록 학습에 사용한 labeled set 수는 Midas 보다 더 적었지만, 다양한 unlabeled 데이터 셋을 학습에 사용할 수 있었기 때문에 모델의 일반화 성능이 더 강해졌다고 저자들은 주장합니다. 또한 teacher model T를 labeled set으로 학습시키기 전에 먼저 DINOv2를 통해 self-supervised learning한 weight을 사용함으로써 보다 시각적 정보를 강화시켰기 때문에 더 정교한 depth를 학습할 수 있었으며, 사전 학습된 segmentation model을 통하여 하늘 영역을 검출하고 해당 영역에 대하여 모델이 disparity value를 0으로 학습할 수 있도록 설계하는 등 학습 방식과 기술에서 조금 더 정교함을 더하였습니다.
Unleashing the Power of Unlabeled Images
지금까지 알아본 supervsied learning 관련 내용은 사실 Midas랑 차이점이 별 다른게 없고, DepthAnything의 가장 핵심 부분은 지금 다루는 unlabeled set에 대한 학습 방식이 아닐까 합니다.
저자들은 요즘 시대에 대용량의 mono image를 (실제 취득 혹은 인터넷 상에서) 구하는 것은 매우 쉬우며 기존의 depth GT를 생성하던 stereo matching이나 SfM reconstruction 방식과 달리 MDE 방식의 경우 단일 영상을 사전 학습된 모델에 태우기만 하면 pseudo label을 간편하게 생성할 수 있어 효율성이 상대적으로 높다고 강조합니다.
반복해서 설명드렸다시피, \mathcal{D}^{l} 를 통해 teacher model T를 학습시키고 해당 teacher model로 \mathcal{D}^{u} 의 pseudo GT를 생성한 뒤 두 데이터 셋을 섞어서 student model S를 학습시키는 것입니다.
여기서 student model과 teacher model이 서로 같은 모델 구조를 가질 수도 있고 아닐수도 있는데, 설령 같은 구조를 가진다고 하더라도 teacher model의 weight (i.e., labeled set으로 사전학습한 가중치)를 student model이 가지고 finetuning하는 것이 아닌, 처음부터 re-initialization을 하여 student model을 학습시킨다고 합니다.
이러한 방식이 더 좋은 성능을 달성한다는 이전 연구가 있었어서, 그것을 그대로 활용한 것으로 보이며, 그래서 student model의 경우 encoder는 teacher model이 처음 학습할 때 그랬듯이 DINOv2로 self-sup 학습한 가중치를 사용하며, depth decoder는 random initialization을 하여 학습시킨다고 합니다. 참고로 teacher와 student model 모두 DPT라는 depth foundation model의 구조를 활용하는데 ViT기반의 encoder를 활용합니다. (그림3 참조)
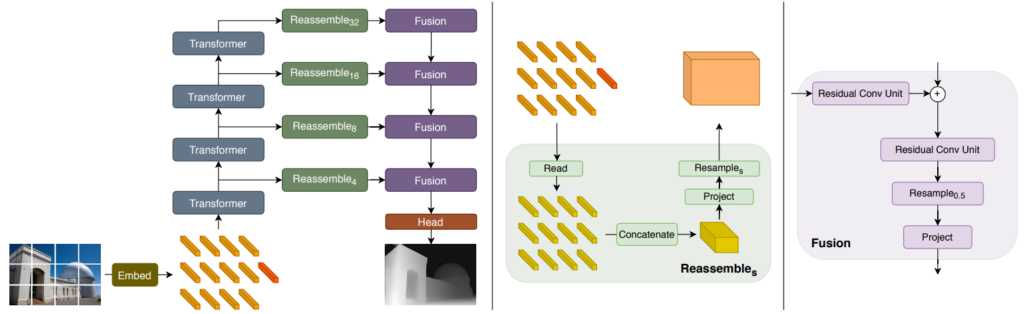
아무튼 student model을 학습하는 단계에 대한 실험 초기에 저자들은 예상과 달리 unlabeled set 통한 self-training 방식으로 어떠한 성능의 이점을 얻지 못하였다고 합니다. 이는 적은 라벨 영상들만 존재할 때의 unlabeled set과 함께 학습하던 기존의 연구들과는 모순된 결과였습니다 (즉 label이 적은 경우는 잘 되던 학습 방식이었는데 라벨이 많은 경우에는 학습이 안됨).
저자들은 label이 너무 충분한 경우에는 추가적인 unlabeled image에서 부터 취득한 여분의 지식들이 제한적이라고 가정하였는데, teacher와 student의 모델이 동일한 pre-training(DINOv2) 과정을 수행하고 모델의 architecture design도 같다보니 유사한 정답값을 만들 가능성도 높고 unlabeled set의 경우에는 잘못된 예측을 동시에 할 가능성이 있다는 것이었습니다.
결국 새로운 데이터에 대한 새로운 시각적 관점을 배우지 못하는 것이 문제라고 판단하여, student 모델 학습시에는 더 최적화가 어려운 target을 만들어서 추가적인 시각적 지식을 학습할 수 있도록 하였습니다. 이를 위해서 저자들은 unlabeled image에 강한 perturbation을 주었는데, 대표적으로는 color jittering과 gaussian blurring과 같은 style 관련 perturbation과 동시에 Cutmix와 같은 spatial distortion을 적용하였다고 합니다.
Cutmix의 경우 많은 분들이 아시겠지만, ICCV2019에 제안된 data augmentation 방법론으로 image classification을 위한 augmentation으로 처음 소개되었습니다. (그림4 우측 참조)
![Paper] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (Image Classification) | by Sik-Ho Tsang | Medium](https://miro.medium.com/v2/resize:fit:1400/1*IR3uTsclxKdzKIXDlTiVgg.png)
이러한 cutmix가 depth estiamtion 분야에서는 잘 활용되지 않다보니 논문에서도 나름 디테일하게 어떻게 학습에 적용했는지 나타내는 모습입니다. 먼저 Cutmix를 수행하기 위한 영역을 나타내는 mask M이 주어질 때, 해당 마스크를 적용하여 아래 수식과 같이 Cutmix image를 생성합니다.
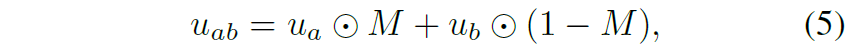
여기서 u_{a}, u_{b} 는 각각 unlabeled image a와 b를 의미합니다. 그럼 이제 이렇게 생성된 augmented image를 depth network에 태워서 depth map을 추론합니다. 이때 중요한 것은 student model에서는 a와 b가 cutmix된 이미지를 넣지만 teacher model에서는 정확한 GT를 제공해야하기 때문에 a와 b 온전한 영상을 각각 넣어주어야 합니다.
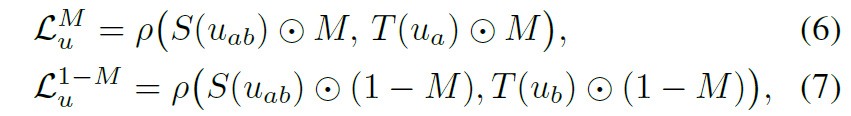
결과적으로 a에 대한 depth 결과, b에 대한 depth 결과를 뽑은 다음에 loss 계산은 a만 존재하는 부분과 b만 존재하는 부분에 대해서 loss 계산을 수행 후 아래와 같이 더해주면 됩니다.
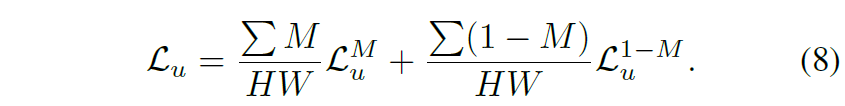
CUT mix는 50% 확률로 수행이 되며 teacher model의 경우에는 pseudo label을 잘 만들어야 하기 때문에 cutmix 외에도 colorjitter 등과 같은 어떠한 왜곡을 적용하지 않고 깨끗한 영상만을 추론하였다고 합니다.
Semantic-Assited Perception
Depth Estimation에 Semantic Segmentation을 함께 학습시키면 깊이 추정 성능에 더 긍정적이지 않을까? 라고 저자들은 믿었습니다. 사실 이러한 생각은 오래 전부터 multi-task learning이 떠오를 때 많이들 하던 생각이었으며 실제 기존 연구들이 depth와 segmentation의 multi-task learning을 통해 좋은 성능을 달성하곤 했습니다.
그래서 저자들은 unlabeled dataset에 대하여 depth network를 학습시킬 때 semantic segmentation에 대한 추가적인 학습 시그널을 전달하면 unlabeled set의 유익한 시각적 정보를 더 배울 수 있지 않을까 했습니다. 이러한 관점에서 저자들은 RAM이라는 방법론과 GroundingDINO, 그리고 HQ-SAM 모델을 조합하여 unlabeled image에 대한 pseudo segmentation label을 생성하게 됩니다.
결과적으로 4K 클래스를 포함하는 pseudo segmentation GT를 생성하였으며 이를 Depth network를 학습할 때 함께 사용했습니다. 조금 더 구체적으로는 shared encoder와 2개의 분리된 decoder 구분을 통해 각각 Depth/Segmentation estimation을 수행한 것이죠.
하지만 많은 시행착오에도 불구하고, 그냥 Depth estimation만 학습했을 때보다 더 낮은 성능을 달성하였다고 합니다. 저자들은 왜 성능이 안오를까에 대해 고민한 결과, 이산적인 클래스 공간으로 영상을 디코딩하다 보니 너무 많은 의미론적 정보를 실제로 잃어버린다고 가정하였습니다. 이러한 이산적인 semantic mask 만으로는 깊이 추정 모델 성능을 향상시키기는 어려우며, 특히 깊이 추정 모델이 좋은 성능을 내고 있을 때 더더욱 성능 이점에 제한적인 것 같다고 판단한 것이죠.
저자들은 그래서 다른 대안으로 DINOv2의 feature map의 semantic information을 적극 활용하고자 하였습니다. DINOv2의 경우 따로 fine-tuning을 하지 않더라도 image retrieval이나 semantic segmentation을 잘 수행한 것을 미루어보아 이 녀석의 feature map에는 뚜렷한 semantic 정보들이 존재하며 이러한 고차원적이고 연속적인 값은 이산적 마스크의 문제를 효과적으로 제거해줄 것으로 생각한 것이죠. 결과적으로 저자들은 아래 수식을 통해 DINOv2의 feature map과 Depth Network의 Encoder feature map 간에 유사도를 계산합니다.
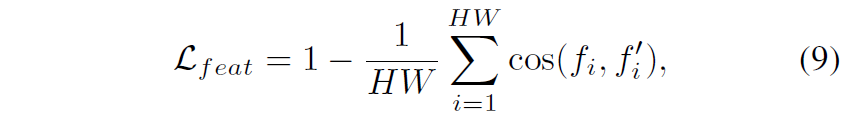
여기서 cos는 cosine 유사도를 의미합니다. 저자들은 서로 다른 두 feature들의 alignment를 위해 fc layer를 통하여 새로운 공간으로 투영시키는 과정을 적용하지 않았다고 하는데, 이는 학습 초기에 random 초기화된 projector가 방대한 alignment loss를 가지다보니 학습 초기에 해당 loss가 모델 학습에 지배적인 문제가 발생한다고 합니다.
그리고 사실 Depth Encoder와 DINOv2의 encoder 간에 feature alignment를 너무 강하게 하면 안되는 이유가 하나 있는데, segmentation 같은 경우에는 동일 대상 혹은 영역 내 픽셀들이 모두 동일한 semantic category로 묶이지만, depth estimation에서는 아무리 동일 대상 혹은 영역 내 픽셀들이라도 서로 다른 depth value를 가질 수 있기 때문에 너무 segmentation을 위한 feature map과 같아지도록 하는 것은 depth estimation 관점에서 좋은 영향을 주지 않을 수 있습니다.
따라서 저자들은 feature map 간에 alignment를 맞추기 위해서 허용 오차 \alpha 값을 설정해서, 만약 cosine 유사도가 해당 \alpha 값을 넘을 경우 해당 픽셀은 loss계산에서 사용하지 않도록 하였다고 합니다. 이러한 과정을 통해 결과적으로 DINOv2의 semantic-aware representation 뿐만 아니라 part-level discriminative representation까지 함께 학습을 할 수 있었던 것이죠. 참고로 알파 값은 구현 시 0.15로 설정하였다고 합니다.
Experiments
드디어 실험 섹션이네요. ablation study와 정량적/정성적 결과 비교 후에 리뷰 마무리 짓도록 하겠습니다.
먼저 실험에 사용한 데이터 셋은 Depth estimation의 대표적인 6개의 데이터 셋으로 KITTI, NYUv2, Sintel, DDAD, ETH3D, DIODE 라는 데이터 셋들입니다.
비교 방법론으로는 depth foundation 모델 중 유명한 Midas 방식으로 학습한 DPT-BeiT large 모델을 주로 활용했다고 하네요.
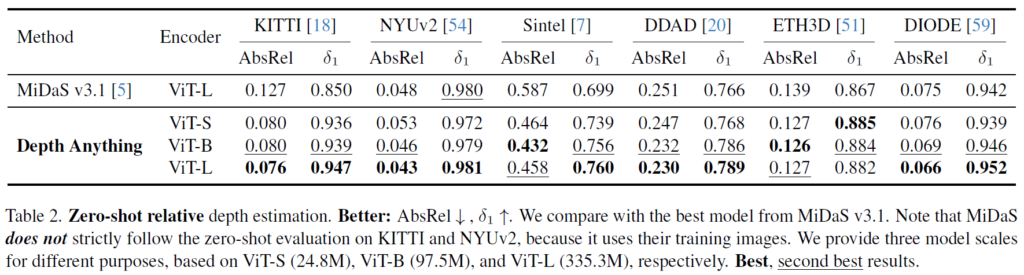
먼저 Table2는 zero-shot relative depth estimation 관련 성능입니다. scale이 다른 데이터 셋을 섞어서 학습하다보니 depth foundation model들은 fine-tuning 없이는 직접적으로 절대적인 depth 추론을 할 수 없기에 상대적인 depth값에 물리적 metric을 적용해서 평가한 것으로 보입니다.
MiDAS와 동일한 ViT-L encoder를 사용하는 경우는 물론이며 ViT-S를 사용하더라도 NYUv2와 DIODE 데이터 셋을 제외하고는 항상 DepthAnything이 더 좋은 성능을 보여주는 모습입니다. (참고로 abs_rel은 값이 낮을 수록 좋은 것이며 델타 값은 값이 클수록 성능이 높은 것입니다.)
ViT Small과 ViT-Large의 모델 파라미터 차이는 24.8 vs 335.3 M 이므로 모델 파라미터 수가 압도적인 차이인 것을 미루어 보았을 때 depth anything이 더 좋은 성능을 내고 있는 것이 한눈에 보입니다.
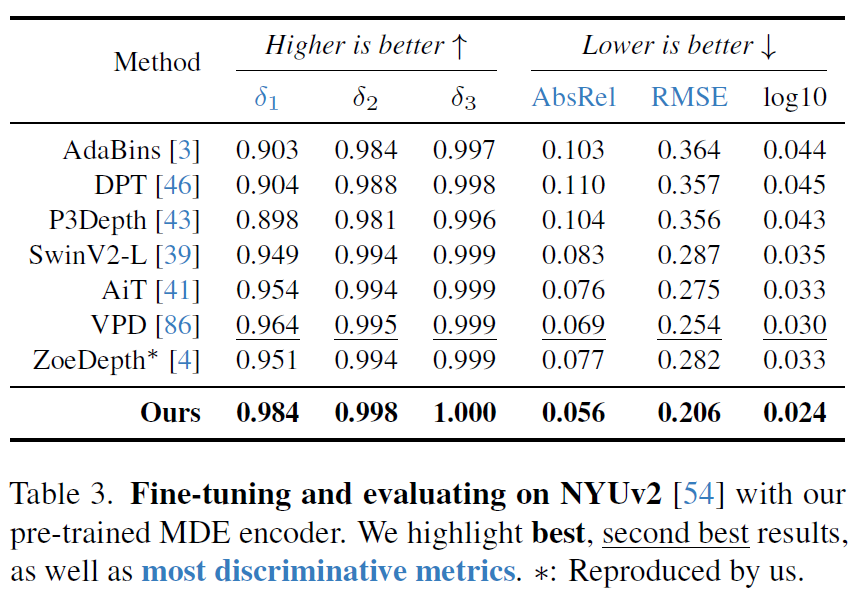
다음은 DepthAnything model이 target data로 fine-tuning한 후 target data로 평가한 결과를 의미합니다. NYUv2라는 indoor 데이터 셋에서 Depth Anything이 상당히 큰 폭의 성능 향상으로 좋은 모습을 보여주고 있습니다. 실제로 delta 3의 경우에는 100%를 달성하는 모습이네요. 물론 위에 비교대상으로 올라온 supervised 방법론들은 NYUv2 셋으로만 학습하고 평가를 했기에 학습에 사용한 데이터 총량만 놓고보면 DepthAnything이 압도적인 성능을 보여주는 것이 당연합니다.
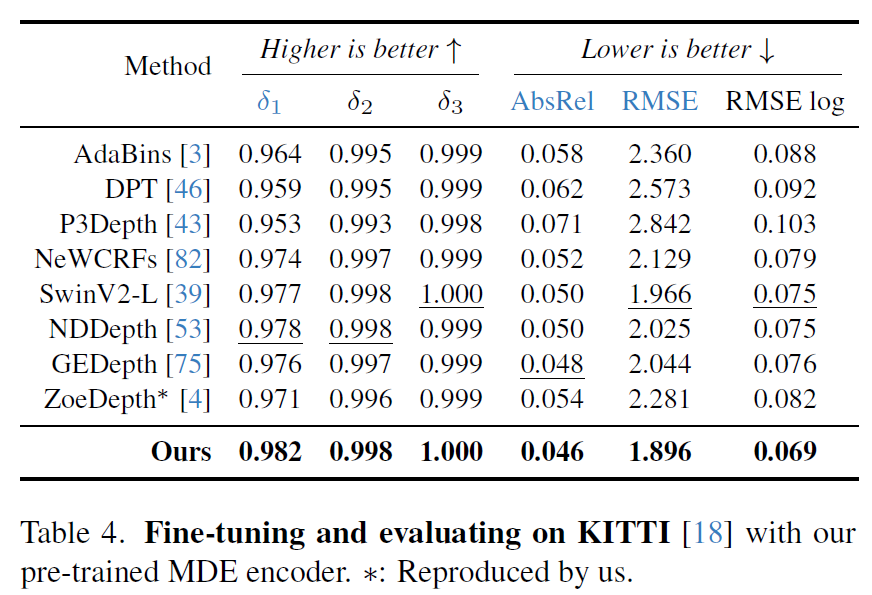
마찬가지로 KITTI outdoor 데이터 셋에서 학습하고 평가한 경우에도 역시 DepthAnything이 모든 metric에서 좋은 성능을 달성하는 모습입니다.
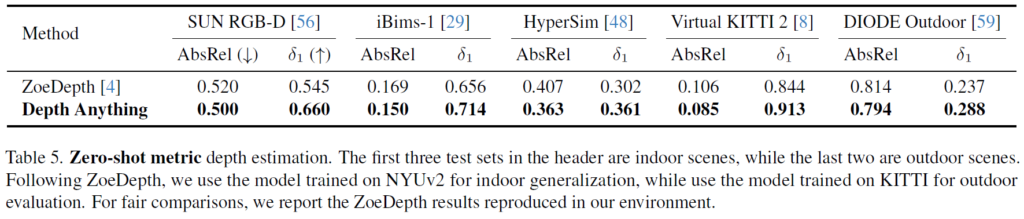
다음에 테이블5는 Indoor set의 경우 NYUv2로 fine-tuning한 다음에 SUN-RGB D, iBims-1, HyperSim과 같은 unseen indoor set으로 평가한 결과이며, 뒤에 outdoor set은 KITTI로 먼저 fine-tuning한 다음에 어떠한 학습 없이 평가한 결과를 나타냅니다. 즉 generalization performance를 본 실험인데 여기서도 유의미한 성능 이점을 보여줍니다.
Ablation study
다음은 ablation study 관련 실험입니다.
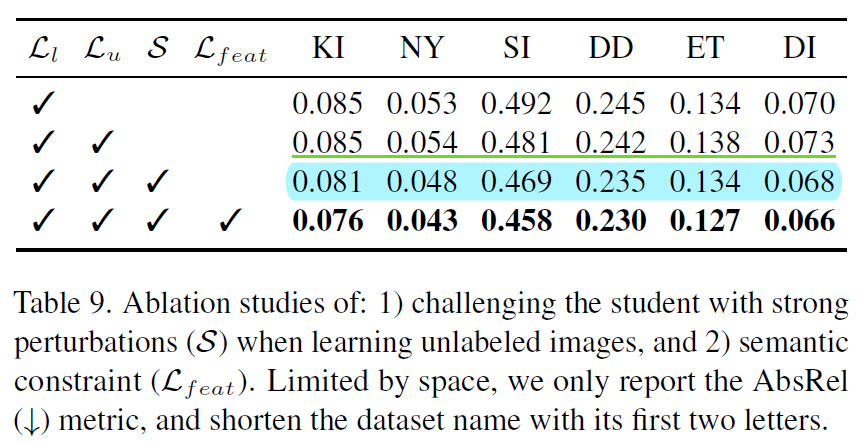
첫번째와 두번째 행은 각각 labeled/unlabeled loss를 의미합니다. 즉 2번째 행은 unlabeled set으로 학습을 했을 경우를 말하는데, unlabeled set으로 곧바로 학습을 하는 경우 첫번째 행보다 depth 성능이 더 안좋아지는 경우가 종종 발생합니다(error 값이 더 커짐.)
따라서 3번째 행과 같이 unlabeled set에 strong perturbation을 적용하게 되는 경우 모든 데이터 셋에서 성능의 향상이 이뤄진 것을 확인할 수 있으며 마지막으로 DINOv2 feature와의 cosine 유사도를 loss로 활용하는 feat loss를 적용했을 때 또 한번의 큰 성능 향상이 발생하는 것을 확인할 수 있습니다.
다음은 정성적 결과입니다. 보시면 탑뷰 영상과 상당히 일상 생활에서 볼법한 영상이 대한 depth 결과인데, Midas와 달리 DepthAnything은 대상의 구조적 정보를 잘 담아서 추론하는 것을 확인할 수 있습니다. 참고로 맨 마지막 행은 예측한 Depth map을 활용해 ControlNet?이라는 방법론으로 새로운 영상을 합성한 것이라는데 depth가 부정확하면 합성된 영상도 이상하다라는 것을 보여주려고 나타낸 결과 같습니다.

결론
어찌보면 방법론은 단순한 것 같지만, 데이터의 규모가 매우 방대해지면서 기존에는 없던 문제들이 속속 발생한다는 점 그리고 이를 해결하기 위한 저자들의 생각을 엿볼 수 있다는 점에서 재밌게 읽은 논문입니다. 물론 문제 정의에 대하여 실험적인 증명보다는 단순히 가정?(아마 이럴 것이다.)을 깔고 진행한 것이 아쉽긴 하지만 결과적으로 문제-해결을 반복하여 좋은 결과를 계속해서 보여주었기 때문에 납득이 강제로 되는 상황이 연출되던 것 같네요.
안녕하세요, 좋은 리뷰 감사합니다.
SAM 말고도 Depth를 뽑아주는 foundation model도 있었네요.
unlabeled 데이터셋에는 사전학습된 MDE(Monocular Depth Estimation) 모델을 태우고 pseudo label을 생성하는 것도 같이 학습을 한다면, 어느정도 MDE 모델에 의존적일수도 있겠다는 생각이 듭니다.
1. unlabeled + labeled 데이터를 합쳐 학습을 했을 때 성능이 좋지 않아 일반화 하는 방식으로 하는 모델을 제안하는 것으로 보입니다. labeled 데이터를 학습하기 위해 teacher 모델을 학습하기 위한 과정 중 affine-invariant loss에 들어가는 d*_{i}는 예측된 disparity인데 이 또한 같은 MDE 모델로 수행하는 것인지 궁금합니다.
2. 실험을 결과에 대한 평가지표에 대해 궁금합니다. GT 대비 오차율을 의미하는 것 같은데, 델타가 여러 개를 보는 게 있고(표3,4), 하나만 보는 게 있네요(표2,5) threshold 같은 것인지 궁금하네요. 델타3은 특히 1에 거의 수렴하는 정도를 보여서 궁금합니다.
감사합니다.
안녕하세요.
질문에 대한 답변을 드리자면
1. disparity라는 의미가 시차라는 것 때문에 stereo image를 쉽게 떠올리실 수 있는데, 사실 monocular depth estimation에서도 depth를 곧바로 추론하지 않고 disparity라는 개념으로 추론을 합니다. 여기서의 disparity는 depth의 inverse(즉 역수)의 개념으로 실제 disparity와 focal length, baseline을 통해 depth를 계산하는 관계를 다시 생각해보시면 depth와 disparity는 반비례 관계이기 때문에 MDE에서 disparity라는 표현은 그냥 inverse depth구나 라고 생각하시면 될 것 같네요. 이러한 관점에서 affine-invariant loss에 들어가는 예측된 disparity는 MDE 모델로 추론한 결과입니다. (본 논문에서는 stereo image를 전혀 사용하지 않음.)
2. 평가 메트릭 관련해서는 말씀하신대로 delta 밑에 숫자는 threshold 값을 의미하며, delta 밑 숫자의 값이 커질수록 threshold 기준이 훨씬 커지기 때문에 성능에 1(100%)에 가깝게 나올 가능성이 높습니다. 그래서 delta_{3} 보다는 delta_{1}을 기준으로 평가하는 것이 더 엄격하게 평가하는구나 라고 이해해주시면 좋겠습니다. 참고로 delta_{1}의 평가 방식은 (percentage of max(d*/d, d/d*) < 1.25) 입니다.
안녕하세요. 신정민 연구원님.
좋은 리뷰 감사합니다.
확실히 depth estimation을 위한 데이터는 취득이 워낙 어렵다보니, pseudo labeling을 활용한 저자들의 방법이 이해가 가면서도, task를 잘 모르는 입장에서는 teacher 모델의 성능이 신뢰할만한가에 대한 의문이 좀 드는 것 같습니다.
리뷰를 읽으면서 살짝 의아했던 것이, 단안 상황에서의 depth estimation은 쌍안 상황에서의 feature 간의 disparity와 같이 깊이를 추정할 물리적인(?) 단서가 없으니 그만큼 결국 이미지 전체의 semantic한 정보에 집중해야할 것 같은데, cutmix를 사용하게 되면 이미지들이 이어붙여지는 영역에서 이런 정보에 noise가 많이 발생할 것 같다는 생각이 듭니다. 저자들이야 성능이 더 오르니 썼겠지만, 혹시 cutmix를 쓰는 것에 대한 저자들이나 정민님의 생각은 어떤지 궁굼합니다.
감사합니다!
안녕하세요.
우선 teacher model의 성능 신뢰성에 대해서 답변드리면 물론 teacher model의 추론 값을 전적으로 신뢰하는 것이 아쉽다고 느껴지겠지만, 그래도 150만장이라는 나름 큰 데이터로 모델을 학습했기 때문에 몇만장, 몇십만장 학습한 수준 보다는 더 신뢰성 있는 추론 값을 뱉지 않을까 기대하고 있습니다.
그리고 cutmix 관련해서는 이어붙여지는 영역에 대해서는 noise가 물론 발생할 수 있습니다만, 반대로 생각하면 이러한 노이즈를 발생시키는 것이 저자들이 의도한 것이라고 볼 수 있겠습니다. 예시로 cutmix가 아니더라도 color jitter와 gaussian blur 역시 영상에 노이즈를 넣는 행위이기 때문에 모델의 추론에 어려움을 주는 것을 의도했다고 보시면 될 것 같아요.
그리고 cutmix 관련해서 결국 하고 싶은 것은 모델이 A라는 영역과 B라는 영역이 서로 다른 영상임을 인지하고, 각각에 대해서 깊이 추정을 잘 수행할 수 있는가?에 대해 학습시키는 것이기 때문에 보다 의미론적인 부분을 모델이 완벽히 이해하고 깊이를 추론할 수 있다고 생각하시면 좋을 것 같습니다.
보통 일반적인 영상의 경우 영상의 가장자리 부분이 매번 depth가 가깝고 영상에 중앙에 갈수록(즉 소실점 부근) 거리가 멀어지는 경향을 보이는데, 그런 데이터로 매번 학습하다보면 항공뷰나 벽면만을 촬영한 영상 같이 모든 영역의 거리가 거의 일정한 영상에서 깊이 추정이 잘 안되는 경우가 발생합니다.
이러한 측면에서 제 추측으로 cutmix 증강 기법의 경우 모델이 무지성으로 가장자리는 항상 깊이가 가깝게, 중앙부에 위치할수록 멀리 추론하는 편향을 깨버리고 의미론적인 부분을 보려고 노력하지 않을까 생각합니다.