이번주는 model compression 중 pruning 논문에 대해 다룬 “Pruning Filters for Efficient ConvNets”논문을 읽어보았습니다. 이 논문이 conv에 pruning을 적용한 근본 논문으로 볼 수 있는데요, 당분간 pruning 관련 방법론을 읽어보려고 합니다.
Introduction
지난 몇 년간 CNN의 구조를 설계하는 trend는 층을 깊게 쌓아서 파라미터와 연산량을 증가시키는 것이었다고 합니다. 그러나 이런 방식으로 설계된 모델은 높은 capacity를 가지게 되겠죠. 또한 resource가 제한된 embedded sensor 나 mobile 환경에서는 사용하기 어려울 것입니다.
이에 등장한 것이 model compression인데요, 이는 model의 storage, computation cost를 줄여 inference cost를 감소시키면서도 원본 모델의 정확도 손실을 최소화하는 것입니다. 당시에는 pruning 방법론을 통해 model의 storage cost를 줄이는 연구가 많이 진행되었다고 합니다. 기존의 pruning은 학습된 모델에서 전체 정확도에 대한 영향력이 적은 파라미터들을 제거하는 방식으로 동작하였습니다. 그러나 제거된 파라미터의 대부분이 fc 레이어에 해당하기 때문에 computation cost 자체는 크게 감소하지 않는 문제가 있었다고 합니다. 예를 들어 VGG16의 parameter는 전체의 90%가 fc레이어에 해당하지만 전체 연산량(FLOP)로 따지면 1%정도에 해당한다고 하네요. 또한 기존 pruning은 sparsity를 도입하지 않은 pruning이라 convolution filter에서 일부 파라미터가 제거되는 경우 sparsity연산을 지원하는 특수한 라이브러리가 필요했다고 합니다.
따라서 이 논문에서 저자들은 well-trained CNN의 filter를 pruning함으로써 CNN의 computation cost를 줄이는 것에 집중하고자 하였는데요, 기존 방법론들이 개별적으로 파라미터를 제거하였다면 저자들은 filter 단위로 제거하는 structured 방법론을 제안하였습니다. 이를 통해 FLOPS를 직접적으로 감소시키고 inference time을 증가시켰다고 하며, 자세한 내용은 아래 method에서 설명드리도록 하겠습니다.
Pruning Filters and Feature Maps
먼저 일반적인 conv연산에서 얼만큼의 연산을 진행하는지 계산해보겠습니다. n_i를 i번째 conv 레이어의 input channel, input feature의 높이와 너비를 ℎ_i/w_i라 할 때, conv 레이어는 input x_i \in \R^{n_i×h_i×w_i}를 output x_{i+1}\in \R^{n_{i+1}×h_{i+1}×w_{i+1}}로 변환하며, output은 다음 conv 레이어의 input 으로 사용됩니다. 이는 채널 수가 n_i인 input에 n_{i+1}개의 필터 F_{i,j}\in \R^{n_i×k×k}를 적용하는 것과 같으며, 하나의 필터는 하나의 feature map을 생성하게 됩니다. 이때 각 필터는 n_i개의 2D 커널 K\in \R^{k×k}이겠죠. 즉, conv 레이어는 F_i\in \R^{n_i×n_{i+1}×k×k}의 kernel matrix를 구성하고, 이때 conv 레이어의 연산량은 n_{i+1}×n_i×k^2×h_{i+1}×w_{i+1}입니다.
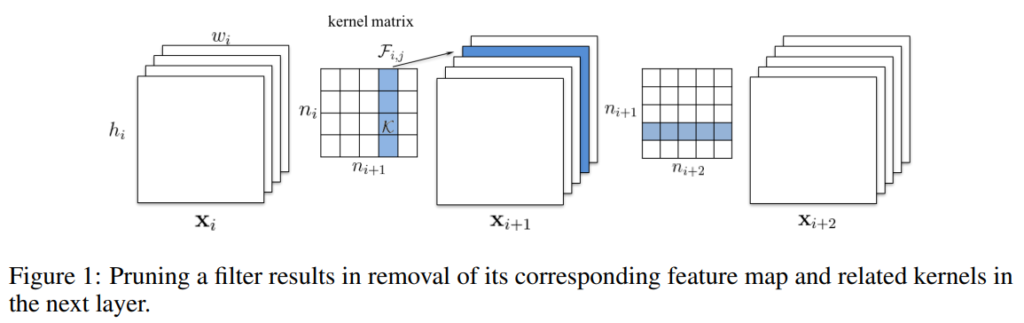
앞서 일반적인 conv 연산의 연산량을 계산하였는데요, 여기에 pruning을 적용하여 filter개수가 줄어들었을 때 연산량 감소량을 알아보겠습니다. 위의 [그림 1]을 보면, 필터F_{i,j}가 pruning 되었을 때, 해당 필터로 계산되는 feature map인 x_{i+1,j}가 제거되고, n_i×k^2×h_{i+1}×w_{i+1}번의 연산이 줄어듭니다. Feature map이 줄어들었으니, 다음 conv에서도 제거된 feature에 적용되는 만큼의 연산량이 줄어들게 되므로 n_{i+2}×k^2×h_{i+2}×w_{i+2}만큼의 연산이 줄어듭니다. 따라서 i번째 conv 레이어에서 m개의 필터를 pruning하면 레이어 i, i+1 레이어의 연산량이 m/n_{i+1}만큼 줄어듭니다.
Determining which filters to prune within a single layer
Pruning을 수행하기 위해서는 filter를 제거할 지 결정해야 하는데요, 모델의 성능 하락을 막기 위해서는 중요도가 적은 filter를 선정하여 제거하는 것이 좋겠죠. 논문에서는 filter에 포함된 parameter의 절대값이 작은 것이 output feature에 미치는 영향이 적을 확률이 높기 때문에 각 filter별로 l_1norm을 계산하여 이를 각 레이어의 중요도로 활용하였습니다.
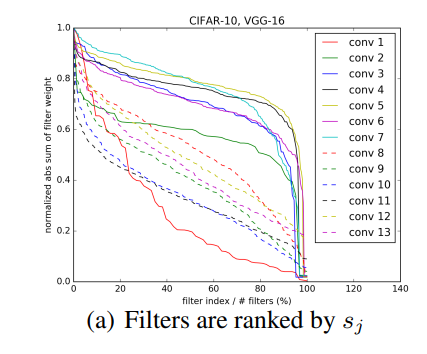
위의 [그림 2(a)]는 CIFAR-10으로 학습된 VGG16의 필터 별 l1 norm 값을 정규화하여 나타낸 것으로 layer마다 distribution의 차이가 큰 것을 확인할 수 있습니다.
정리하자면, pruning을 수행하는 방법은 각 filter의 l1 norm을 측정하여 sorting하고, 작은 순서대로 m개의 filter를 제거하는 것입니다.
Determining single layer’s sensitivity to pruning
저자들은 layer의 pruning sensitivity를 이해하기 위해, 각 layer 마다 독립적으로 pruning한 뒤, validation set에 대한 pruned network의 accuracy를 확인하였습니다.
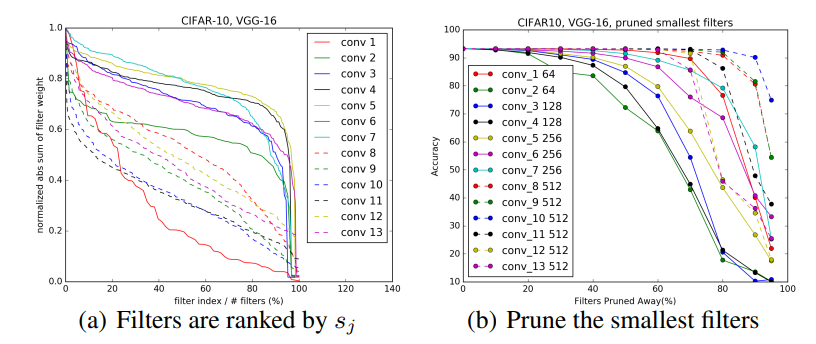
위의 [그림 2(b)]는 CIFAR-10으로 학습된 VGG16에 각 filter에 각각 일정 비율만큼의 pruning을 진행한 것을 나타낸 것입니다. Pruning 비율이 높아질수록 소실되는 파라미터가 증가하므로 성능이 낮아지는 것을 볼 수 있는데요, 저자들이 여기서 중요하게 언급한 것은 각 레이어마다 동일 비율의 pruning을 적용했음에도 민감도가 서로 다르다는 것입니다. 특히 [그림 2(a)]에서 경사가 완만한 layer가 pruning성능이 급격하게 변하는 것을 확인할 수 있습니다.
이를 통해 각 layer 별 sensitivity를 고려하여 경험적으로 pruning filter 수를 설정하였으며 sensitive한 레이어의 경우 매우 적은 비율 혹은 0의 비율로 pruning을 진행하였다고 합니다.
Pruning filters across multiple layers
기존 pruning 연구에서는 layer 별로 weight를 pruning하고, 손실된 정확도를 보완하기 위해 반복적으로 fine-tuning 하였습니다. 이러한 방식은 한 layer를 pruning할 때마다 학습을 진행하므로 시간이 오래 걸리게 되는데요, 이에 논문의 저자들은 여러 개의 layer에 동시에 pruning을 적용하여 한 번의 fine-tuning을 진행하는 방법을 제안하였습니다.
먼저 independent pruning으로 각 layer마다 다른 layer에 독립적으로 pruning할 filter를 결정하는 방법으로 그 전 layer에서 제거된 filter를 고려하지만 greedy pruning으로 이전 layer에서 제거된 filter를 고려하지 않고 l1-norm을 계산합니다.
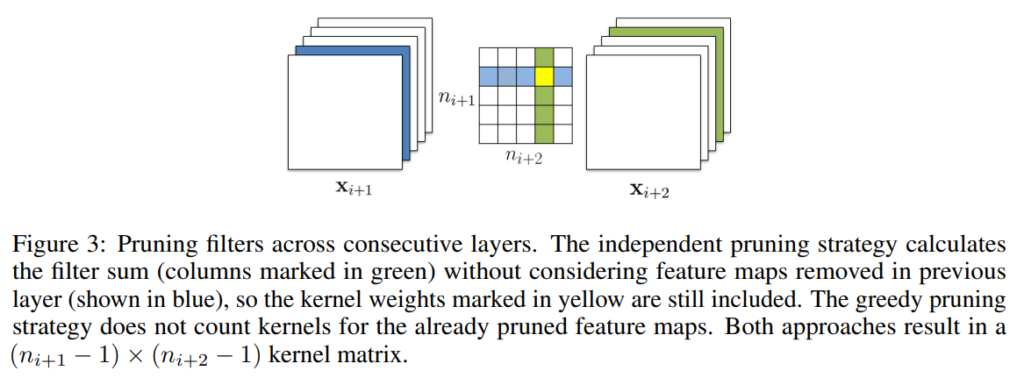
위의 [그림 3]을 보면 independent pruning은 전 layer에서 제거된 파란 색깔의 filter를 정할 때 노란색 부분을 l1-norm 계산에 포함시키지만 greedy pruning은 초록 색깔의 filter를 제거할 때 노란색 부분을 l1-norm 계산에 포함시키지 않습니다.
AlexNet이나 VGGNet 같은 경우 상대적으로 단순한 모델로 각 layer 마다 pruning을 진행하면 됩니다. 하지만 ResNet은 shortcut connection으로 구성된 residual block으로 구성되어 조심스럽게 pruning 되어야 합니다. 아래 [그림 4]는 ResNet의 residual block을 pruning하는 방법을 나타냅니다.
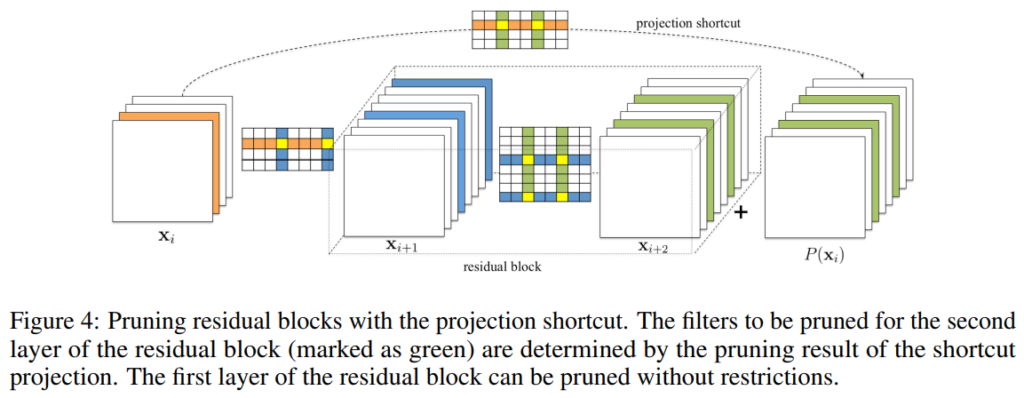
먼저 residual block의 첫 번째 layer는 output feature map 크기에 영향을 미치지 않기에 독립적으로 pruning 됩니다. 하지만 residual block의 두 번째 layer와 identity projection은 최종 output feature map 단에서 더해지기 때문에 residual block의 두 번째 layer에서 제거된 feature map은 projection shortcut feature map에서도 제거되어야 합니다. 이때, identity projection 의 feature map이 의미적으로 더 중요하기 때문에 residual block의 두 번째 layer의 pruning 위치는 identity projection pruning (1×1 convolution에서 pruning) 위치에 따라 결정됩니다.
Retraining pruned networks to regain accuracy
앞서 filter의 pruning 이후 낮아진 정확도를 보완하기 위해 fine-tuning을 진행다고 언급하였는데요, 여러 레이어의 filter를 pruning할 때, 일반적으로 다음과 같은 두 가지 학습 전략을 사용합니다.
- Prune once and retrain: 여러 layer의 filter들을 한 번에 pruning한 뒤, 원래의 acc가 복구될 때까지 retraining
- Prune and retrain iteratively: layer 혹은 filter별로 pruning + retraining 진행
논문에서는 1번 방법, 즉, 한 번의 pruning과 retraining을 진행하였습니다. 이를 통해 적은 retraining을 진행할 수 있었다고 합니다. 그러나 pruning에 sensitive한 레이어를 pruning할 경우 매우 큰 정확도 손실을 가져올 수 있으므로 layer 별 sensitivity를 고려해야 한다고 언급하였습니다.
Experiments
저자들은 simple CNN인 VGG16과 residual network인 ResNet에서 실험을 진행하였습니다.
이때 대부분 CIFAR-10에서 실험을 진행하였으며, [표 1] 마지막 행의 ResNet-34은 ImageNet 성능을 나타냅니다.
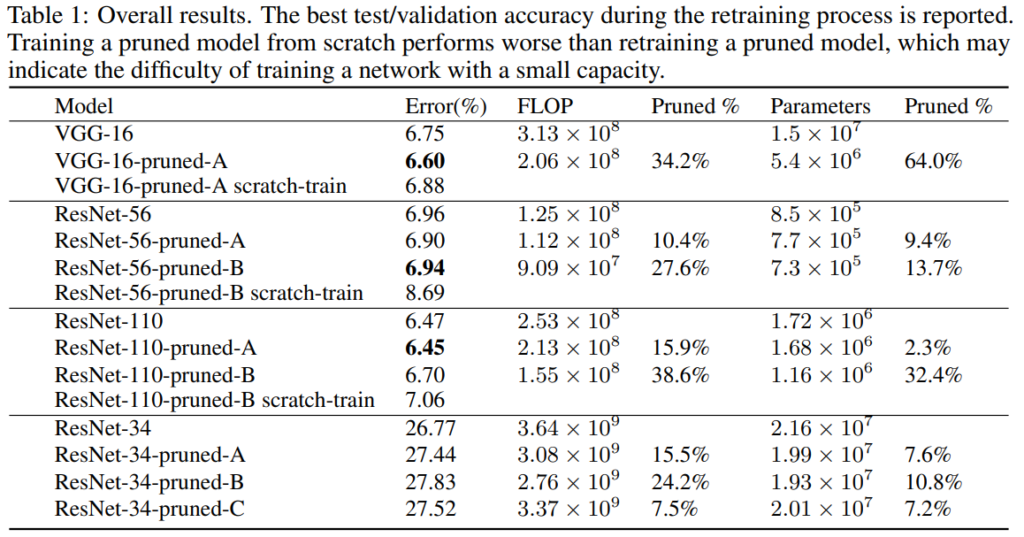
위의 [표 1]은 원본 모델, Pruned 모델의 성능을 리포팅하였는데요, -scratch-train이 붙은 것은 pruning 이후 filter 개수가 변경된 모델을 새롭게 초기화하여 scratch로 학습시킨 결과를 나타냅니다.
전체적으로 FLOP과 Parameter 둘 다 줄어든 모델이 원본 모델과 비슷한 성능을 달성한 것을 확인할 수 있습니다.
Comparison with pruning random filters and largest filters
[그림 8]은 pruning할 filter를 l1 norm이 작은 순으로 정하는 것이 유효한지 검증하는 실험으로, 레이어 별 pruning을 수행 시, (a)는 l1 norm이 작은 순서로, (b)는 랜덤, (c)는 큰 순서로 제거한 결과를 나타냅니다.
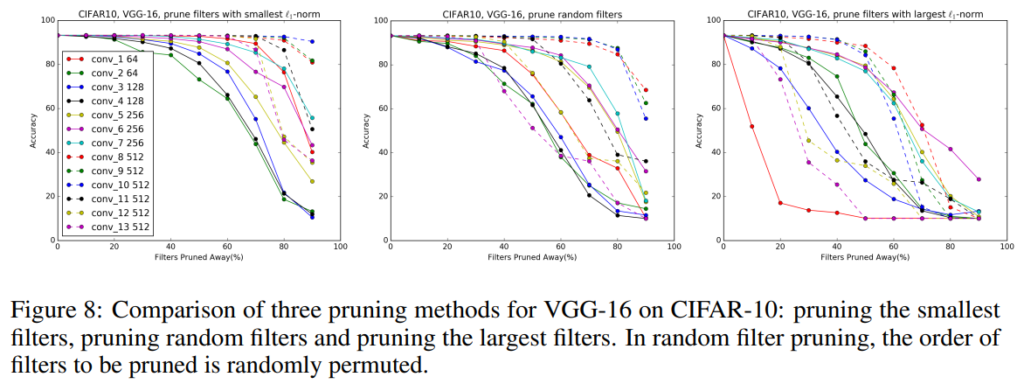
실험 결과를 통해 대부분의 layer에서 smallest l1 norm을 가지는 filter를 pruning하는 것이 가장 좋은 성능을 보이는 것을 알 수 있습니다.
안녕하세요 좋은 리뷰 감사합니다.
Pruning 이후 기존 성능을 복원하기 위해 fine-tuning 전략을 제시하긴 했지만, 단순히 feature map의 l1-norm을 기준으로 pruning 하는 방식 자체가 예전 논문이라 그런지 단순해 보입니다.
이 때 저자가 왜 l1 norm을 정량적 기준으로 설정하였는지나 추후 고도화 된 방법론들은 무엇을 기준으로 pruning을 진행하는지 궁금합니다.
좋은 리뷰 감사합니다.
Pruning이라는 게 뭔지만 알았지 자세한 내용은 처음 알게되었습니다. 그중에 pruning이 작동할 때 어떤 conv를 없애는 건지 궁금했는데 기준이 있었네요.
2가지 질문을 드립니다.
1. L1 norm을 구하여 정렬한 후 제거를 하는 방법은 결국 값이 가장 작으면 결과에 영향이 적으므로 사용을 하지 않는 걸로 이해를 했습니다. 만약 정렬을 했을 때 값이 작다는 건 비교적 작다는 의미인 것 같은데, 값의 편차가 작은 경우(비슷비슷한 경우)는 어떻게 동작하나요? conv filter가 결과에 모두 영향을 준다면? 에 대한 질문이었습니다.
2. sensitivity을 고려하기 위해서는 그 당시에는 경험적으로 튜닝을 해야 pruning을 할 수 있는 것으로 보입니다. 그럼 매번 하니의 튜닝 과정으로 sensitivity를 고려하기 위해서는 매번 학습과 예측을 통해 진행하는 것으로 이해하면 될까요?
감사합니다.
안녕하세요, 천혜원 연구원님, 좋은 리뷰 감사합니다.
이전 퀄컴 연구원님께서 모델 경량화를 다룰 때 pruning을 언급했던 것으로 기억하는데, 해당 리뷰를 읽고 pruning이 뭔지 좀 더 감을 잡게 된 것 같습니다. 재밌네요. 읽다보니 궁금한 점이 몇가지 있어 질문 드리겠습니다.
1. introduction에서 fc layer가 parameter는 많지만 연산량(FLOP)이 많다고 하셨는데, 더 구체적인 설명이 가능하실까요? 직관적으로 생각했을때는 학습 대상인 파라미터가 많아지면 연산걍이 많아질 것이라 생각되는데, 그렇지 않다는 점에서 이유가 궁금합니다.
2. Figure 1에서 pruning 할 filter를 선택할 때, convolution kernel(filter)에서 열벡터 하나를 삭제한 것으로 보이는데 맞나요? 그럼 3×3 con filter를 pruning하면 3×2 filter가 되는 건가요? 필터의 shape이 달라지면 output feature map의 크기가 달라질 것 같은데, 이는 어떻게 맞춰주게 되나요?
감사합니다.
안녕하세요 좋은 리뷰 감사합니다
저는 여쭤보고 싶은 부분이 왜 이 논문을 읽었고 왜 리뷰를 작성했는가 인데요. 이 논문 같은 경우 comb filter에 최초로? pruning을 적용한 방법론이라 생각되어 읽은 듯 한데 너무 옛날 방법론이 나닌가 합니다. 최근에는 더 참신하게 pruning을 적용한 방법론이 많을 것이라 생각이 드는데 굳이 이 논문을 고르고 굳이 리뷰까지 작성한 부분이 궁금합니다