안녕하세요. 이번 주 X-Review는 23년도 CVPR에 게재된 <You Can Ground Earlier than See: An Effective and Efficient Pipeline for Temporal Sentence Grounding in Compressed Videos>입니다. 마찬가지로 Temporal Sentence Grounding in Videos(TSGV) task를 수행하는데, 압축된 형태의 비디오에서 바로 수행된다는 점에서 효율성을 갖는 방법론입니다. 이번 리뷰는 기존 방법론들과 scheme이 다르지만 효율성을 중시하기에 방법론 자체가 어렵지는 않으실 것입니다.

리뷰 시작하겠습니다.
Preliminaries
본 방법론을 이해하기 위해, 압축된 비디오 형태에 대해 간단히 살펴보고 넘어가겠습니다.
Video compression
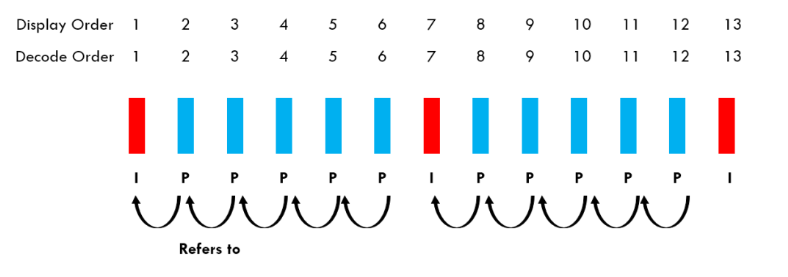
비디오 압축은 효율적 전송을 위해 컴퓨터 비전 분야에서 근본적으로 연구되는 task입니다. 비디오를 압축하기 위해 가장 먼저 비디오를 Group of successive Pictures(GoPs)로 분할되게 됩니다. 분할된 하나의 그룹인 GOP는 I-frame(Intra-frame)과 P-frame(Predictive frame)으로 구성됩니다. GOP의 첫 번째 프레임은 I-frame, 그 이후 프레임은 모두 P-frame으로 압축됩니다. 또 그 다음 GOP의 시작이 I-frame, 이후 P-frame으로 구성되는 형태인 것입니다. 이러한 GOP들이 모여 하나의 비디오가 압축된 형태로 저장되는 것이죠. 압축 방식이나 표준에 따라 B-frame도 있는데, 본 방법론에서는 I-, P-frame만 고려하는 것으로 보입니다.
먼저 I-frame은 원본 비디오의 한 프레임과 동일하게 모든 RGB 픽셀 정보가 압축 없이 저장되어있는 프레임을 의미합니다. 이어 등장하는 P-frame은, I-frame 다음 프레임도 똑같이 원본을 저장하면 압축의 의미가 없으니 효율성을 위해 I-frame과 차이를 가지는 값만을 저장하게 됩니다. 간단하게 설명하자면, 원본에 해당하는 I-frame을 기준으로 temporal prediction을 수행해 P-frame으로 만들 프레임의 motion vector를 추정하게 됩니다. 여기서 추정하는 방식은 코덱 표준에 따라 다르고, 이 추정을 잘하는 것이 비디오 압축 task의 일부에 해당하는 것입니다. 이렇게 추정된 motion vector를 활용하면 P-frame 원본과 유사한 프레임을 복원해낼 수 있을 것이고, 이렇게 motion vector를 활용해 복원한 P-frame과 기준이 되었던 I-frame과의 차이를 residual 값으로 저장하게 됩니다.
정리하자면, 비디오를 압축하기 위해 먼저 장면이 크게 바뀌는 것으로 보이는 I-frame을 정하여 원본으로 저장하게 됩니다. 이후 I-frame과 다음 I-frame 사이에 존재하는, 즉 temporal redundancy가 큰 P-frame들은 효율적으로 저장하기 위해 motion vector를 예측하게 됩니다. 그리고 예측한 motion vector로 복원한 P-frame과, 같은 GOP에 속하는 I-frame과의 차이를 residual 값으로 갖고있게 됩니다. 다시 말해 I-frame은 원본 프레임 정보, P-frame은 같은 GOP에 속하는 I-frame으로부터 추정된 Motion Vector와 Residual값으로 구성되는 것이라고 생각하시면 됩니다. 아래 그림 1-(b)를 참고하시면 이해하기 편하실 것입니다. 완전하지는 않지만, motion vector는 temporal 축에 대한 정보, residual 값은 spatial, temporal 정보를 둘 다 고려하고 있다고 볼 수 있습니다.
1. Introduction
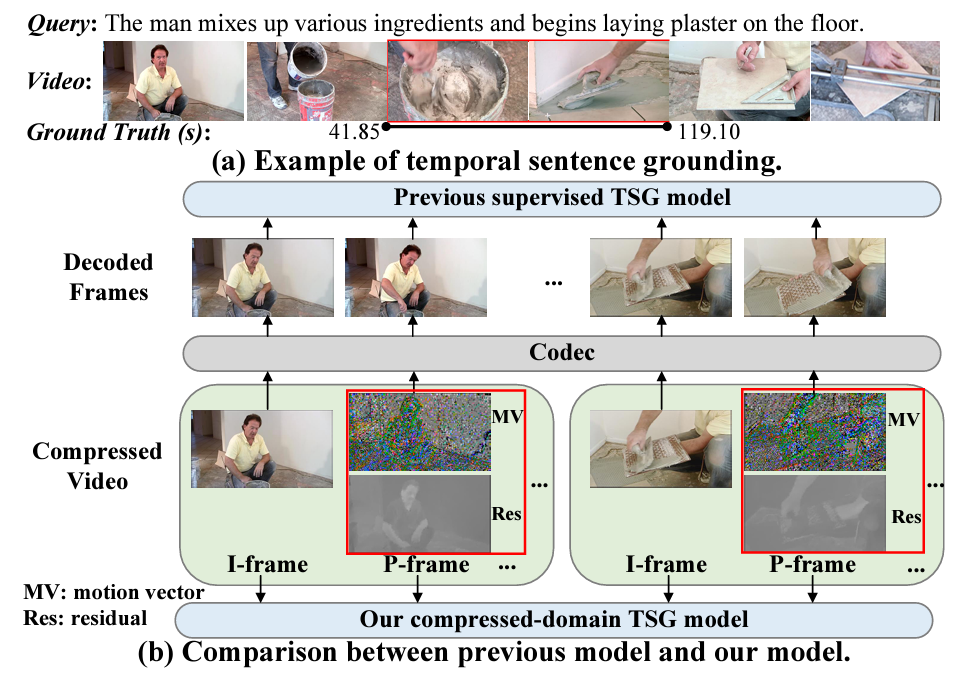
그림 1-(a)는 TSGV task 자체에 대한 설명입니다. 제가 여러 번 설명했기에 다들 아시겠지만, TSGV는 주어지는 free-form text 퀴리에 대해 함께 주어지는 비디오에서의 상응하는 구간을 정확히 localize 하는 것이 목적입니다. 그림 1-(a)에서 text 쿼리는 “The man mixes up various ingredients and begins laying plaster on the floor.”이고, 비디오에서 상응하는 구간이 41.85초에서 119.10초인데, 모델이 이 구간을 잘 찾기를 원하는 것입니다.
본 논문에서 저자가 지적하는 기존 방법론들의 문제점은 단순합니다. 비디오 데이터는 인접한 프레임끼리 중복성이 굉장히 크고, 수천, 수만 장의 영상 묶음으로 구성되어있기에 효율적 통신을 위해 압축됩니다. 그리고 저희가 비디오 task를 수행하기 위해, 즉 맨 처음 feature를 추출하기 위해 압축된 형태로부터 압축이 해제됩니다. 본 논문 이전까지의 방법론들은 모두 압축 해제된 형태로부터 feature를 추출하게 되는데, 이것이 굉장히 오래 걸리며 메모리 관점에서도 비효율적이라는 점을 지적합니다. 그래서 저자는 압축된 비디오 자체에서, 이를 압축 해제하지 않고 TSGV task를 수행하고자 방법론을 설계합니다.
사실 압축된 형태로부터 비디오를 다루거나 task를 수행하는 논문은 비디오 task마다 최소 하나씩은 존재하는 것 같습니다. Self-supervised Video Representation Learning이나 Generic Event Boundary Detection, Temporal Action Localization 등에서 효율성을 위해 압축된 형태의 비디오를 종종 활용하는데, 본 논문도 최초로 TSGV에 위와 같은 파이프라인을 가져온 것이라고 생각하시면 됩니다.
그림 1-(b)를 보시면 기존 방법론들과 다르게 본 논문의 방법론은 압축된 비디오가 코덱을 거쳐 원본 프레임으로 압축 해제되기 이전의 정보들을 grounding에 활용하고 있는 모습입니다. 이렇게되면 압축 해제된 원본 비디오보다 정보량 측면에서 손해를 볼텐데, 이렇게 효율성을 고려했음에도 성능은 기존 방법론들보다 좋았기에 CVPR에 게재될 수 있었던 논문입니다.
저자는 compressed-domain에서 효과적이고 효율적으로 TSGV를 수행하기 위해, Three-branch Compressed-domain Spatial-temporal Fusion(TCSF) 파이프라인을 제안합니다. 먼저 압축된 형태의 비디오가 주어졌다면, I-frame과 P-frame feature를 각각 추출하여 활용합니다. 근본적으로, 압축 해제된 원본 비디오로부터 feature를 추출하는 기존 방법론들보다 정보량이 부족한 상태이기에, 이를 보완하고자 여러 모델링을 수행합니다.
먼저 I-frame, P-frame 각각 CNN 모델에 태워 feature를 추출한 후, 앞서 이야기하였듯 I-frame은 appearance 정보, P-frame은 temporal 정보를 가지고 있다고 볼 수 있기에 두 정보를 모두 잘 고려하기 위한 spatial attention, temporal attention을 수행합니다. 비디오에는 text 단어에서도 알 수 있듯 fast-motion과 slow-motion이 존재합니다. Fast-motion은 개수가 많고 연속되는 P-frame으로부터, slow-motion은 떨어져 존재하는 I-frame으로부터 얻을 수 있을 것으로 생각되는데, 저자도 이를 모델링하고자 I-frame, P-frame 간 balancing factor를 residual feature로부터 얻어오는 모듈 또한 설계합니다. TSGV task는 결국 text 쿼리와의 상응 구간을 찾는 것이기에 multi-modal fusion 과정도 존재합니다.
Contribution을 정리한 뒤 방법론 부분으로 넘어가겠습니다.
Contribution
- We propose a brand-new and challenging task: compressed-domain TSG, which aims to directly leverage the compressed video for TSG.
- We present a novel pipeline for compressed-domain TSG, which can efficiently and effectively integrate both appearance and motion information from low-level visual information in the compressed video.
- Extensive experiments on three challenging datasets(ActivityNet Captions, Charades-STA and TACoS) validate the effectiveness and efficiency of our TCSF.
2. Proposed Method
2.1 Overview
Problem statement.
압축되기 이전 형태인 비디오의 bit-stream \mathcal{V}가 주어지고, 이는 T개 프레임으로 구성되어 있습니다. \mathcal{V}를 입력받아 최종적으로 text 쿼리 \mathcal{Q}=\{q_{j}\}_{j=1}^{M}과 가장 잘 상응하는 구간 \tau{}_{s}, \tau{}_{e}를 예측하는 것이 목표입니다.
\mathcal{V}는 총 N개의 GoP로 구성되는데, 각 GoP G_{i}는 참조를 위한 I-frame I_{i} \in{} \mathbb{R}^{\mathcal{H} \times{} \mathcal{W} \times{} 3}으로 시작하여 이후 총 L개의 P-frame \{P_{i}^{l}\}_{l=1}^{L}으로 구성됩니다. 다시 하나의 P-frame P_{i}^{l}은 motion vector M_{i}^{l} \in{} \mathbb{R}^{\mathcal{H} \times{} \mathcal{W} \times{} 2}과 residual R_{i}^{l} \in{} \mathbb{R}^{\mathcal{H} \times{} \mathcal{W} \times{} 3} 정보를 포함합니다.
우선 저자는 모든 GoP가 동일한 개수의 P-frame을 가지고 있다고 가정합니다. 이렇게 구성된 \mathcal{V}는 총 T=N\times{}(L+1)개의 프레임을 가지고 있겠죠. 정리하면 \mathcal{V} = \{I_{i}, P_{i}^{1}, P_{i}^{2}, \cdots{}, P_{i}^{L}\}_{i=1}^{N}으로 표현할 수 있습니다. i는 GoP의 인덱스를 의미합니다.
Pipeline
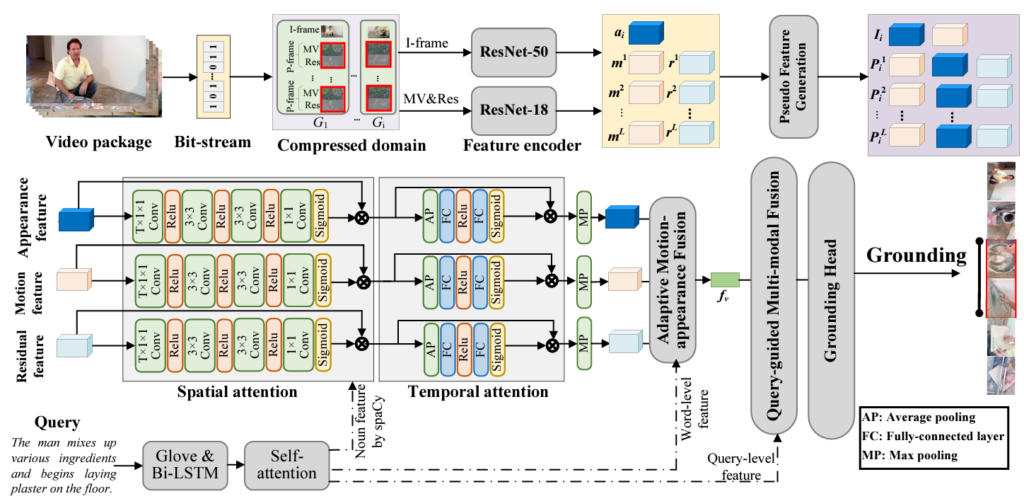
그림 2는 TCSF의 전반적 파이프라인을 나타내고 있습니다. \mathcal{V}를 입력받고 entropy decoding approach를 통해 GoPs로 쪼개개 됩니다. Entropy decoding은 기존 표준인 MPEG-4 decoder를 활용한 GoP 분할 방식에 해당합니다. 우선 그림 2를 통해 크게 Pseudo feature generation, Three-branch Spatial-temporal Attention, Adaptive Motion-Appearance Fusion, Multi-modal Fusion and Grounding Head 단계가 있다는 정도만 정리하고, 자세히는 아래에서 알아보겠습니다.
2.2 Multi-Modal Encoding
우선 본 절을 통해 feature 추출 과정을 알아보겠습니다.
text 쿼리는 300-dim GloVe embedding에 대해 Bi-GRU 네트워크를 태워 얻게됩니다. 이후 MHSA를 한 번 더 거쳐 최종 text feature Q=\{q_{j}\}_{j=1}^{M} \in{} \mathbb{R}^{M \times{} d}를 추출합니다. Q는 word-level text feature에 해당하고, Bi-GRU의 마지막 hidden unit을 concat한 뒤 FC layer에 한 번 태워 sentence-level text feature q_{global} \in{} \mathbb{R}^{d}를 얻어줍니다.
다음으로 I-frame은 ResNet-50에 태워 appearance feature a^{t} \in{} \mathbb{R}^{H \times{} W \times{} C}를 추출하고, P-frame은 ResNet-18에 태워 motion feature m^{t} \in{} \mathbb{R}^{H \times{} W \times{} C}와 residual feature r^{t} \in{} \mathbb{R}^{H \times{} W \times{} C}를 추출합니다.
Pseudo feature generation
정확한 grounding을 위해, 부족한 정보량을 보완해줄 수 있는 모듈이 필요한 상황입니다. 현재 N개의 I-frame, N \times{} L개의 P-frame을 가지고 있는 상태인데, appearance와 motion 관점에서 부족한 정보를 pseudo feature로 만들어주어야 합니다.
이를 위해 t-frame이 I-frame이라고 했을 때, n번째 P-frame에 대한 appearance feature a^{n+t}는 아래 수식 1과 같이 추출할 수 있습니다.
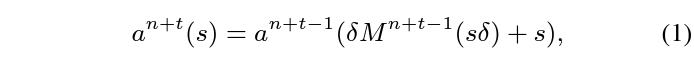
수식 1에서 \delta{}는 scaling factor, s는 feature의 spatial 좌표를 의미합니다. Motion vector를 고려하여 P-frame의 appearance feature를 추정하는 과정에 해당하는 것입니다.
Appearance 정보가 없다고 볼 수 있는 P-frame의 appearance 정보를 추정하였으니, 반대로 motion 정보가 없다고 볼 수 있는 I-frame의 motion 정보도 추정해주어야 합니다. 수식 1에서 얻은 nrodml P-frame의 appearance feature a를 모두 concat하여 V^{t} = [a^{t}; \cdots{} ; a^{n+t}] \in{} \mathbb{R}^{H \times{} W \times{} C \times{} n}을 만들어주고 이에 1\times{}1 Conv를 적용하여 얻은 V_{*}^{t}에 대해 아래 수식 (2)를 적용하여 I-frame의 motion vector m^{t}를 얻을 수 있습니다. 결론적으로 현재 I-frame을 참조하는 모든 P-frame의 appearance 정보에 1\times{}1 Conv + ReLU를 적용한 것이라고 볼 수 있습니다.
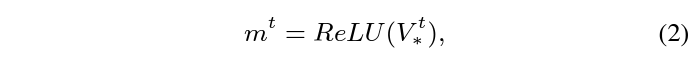
여기까지 수행하면 I-frame, P-frame 각각의 motion feature와 appearance feature를 모두 얻은 것입니다. 이제 이 feature들을 어떻게 활용하는지 보아야 할 것입니다.
2.3 Three-branch Spatial-temporal Attention
TSGV는 결국 쿼리에 상응하는 비디오 내 구간을 찾는 것이므로 두 모달간의 관계 modeling이 중요합니다. 이를 위해 앞서 얻은 low-level visual feature appearance, motion, residual feature에 대한 query-relevant temporal-spatial information modeling이 필요합니다.
Spatial attention
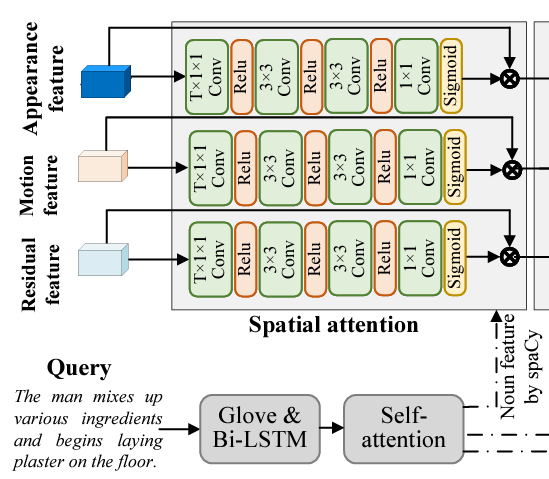
유의미한 query-relevant spatial attention을 위해 저자는 text 쿼리 내 명사에 주목합니다. 비디오 공간 축은 보통 쿼리에 존재하는 명사와 관련이 깊다는 의미입니다. 자연어처리 모델 SpaCy를 활용해 문장 내에서 명사를 찾아내고, 해당 명사 feature를 함께 활용해 그림에 나타난 연산을 거쳐 attention score를 얻어줍니다. 사실 논문에도 “we exploit nouns to enhance three visual features via an attention mechanism…”이라고만 나와있어 정확히 어떠한 연산이 수행되는지는 모르겠습니다. 이렇게 얻은 attention score를 고려한 region attentive (appearance, motion, residual) feature는 각각 a_{*}^{t}, m_{*}^{t}, r_{*}^{t},로 표현됩니다.
Temporal attention
앞서 spatial modeling이 완성되었다면, 해당 feature에 대한 temporal modeling도 수행됩니다. 여기서도 결국은 temporal 정보를 고려한 attention score w를 만들어주는 것이 목적입니다. 우선 appearance feature만을 기준으로 설명드리면, I-frame으로부터 연속되는 K개의 프레임들을 고려해 temporal attention score를 만들어냅니다. 현재 보고있는 t번째 I-frame으로부터 K개의 프레임에 대한 appearance feature를 모두 concat해주고, average pooling을 거쳐 K차원의 attention score S를 만들어줍니다. 이후에는 아래 수식 3을 통해 w가 생성됩니다.
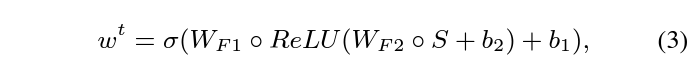
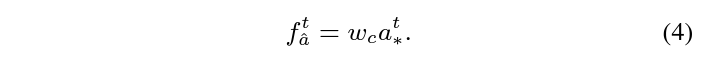
이후에는 수식 4와 같이 element-wise multiplication을 통해 f_{\hat{a}}^{t}, f_{\hat{m}}^{t}, f_{\hat{r}}^{t}를 얻어줍니다. 이 3가지 feature들이 spatial-temporal attention modeling을 마친 feature들이라고 볼 수 있습니다.
2.4 Adaptive Motion-Appearance Fusion
앞서 feature를 얻었으니, 이를 쿼리와 관련된 구간 예측에 사용하면 됩니다. 그 이전 조금 더 activity content와 관련된 모델링을 수행하기 위한 모듈이 Adaptive Motion-Appearance Fusion인데요, 비디오에는 다양한 temporal change가 존재합니다. 이는 주어지는 text 쿼리로부터 정보를 얻어볼 수 있는데, 예를 들어 “run”이라는 단어와 “walk”라는 단어가 존재할 때 “run”의 경우는 빠르게 변화하므로 appearance feature의 가중치를 더 높게, “walk”의 경우는 motion feature의 가중치를 더 높게 주어 fuse 해야합니다. 이를 위해 먼저 쿼리를 기반으로 appearance, motion 정보를 enhance해주고, residual feature를 기반으로 두 정보의 balancing weight를 추출합니다.
Query-guided feature enhancement
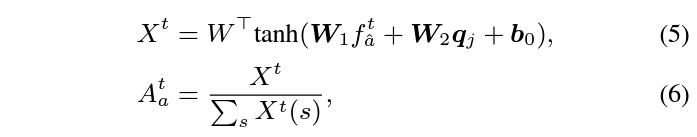
Enhancement는 결국 attention score A_{a}^{t}를 곱해줌으로써 이루어지는데, 해당 score는 위 수식 5와 같이 추출됩니다. 단순히 FC layer로 구성되어있어 효율성 측면에서는 유리할 것으로 보입니다.
Residual-guided feature fusion
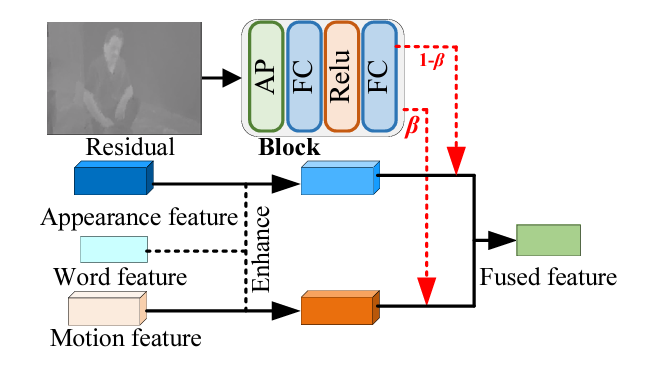
여기서는 쿼리 단어에 맞게 appearance, motion feature 둘을 어떻게 합칠지, 즉 balancing weight \beta{}를 추출하는 것이 목적입니다. 이 과정은 위 그림 3과 아래 수식 7, 8을 통해 확인할 수 있습니다.
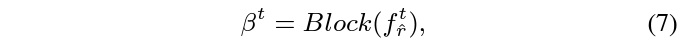
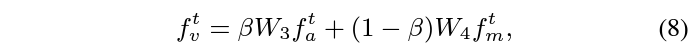
수식 7에 나타난 Block은 위 그림 3에 나타난 것과 같습니다. 전반적으로 어려운 내용은 없고 계속 FC layer를 태워 얻은 attention score를 곱해주고 있습다.
2.4 Multi-modal Fusion and Grounding Head
앞서 과정까지는 두 모달의 명시적인 fusion보다는 guidance 느낌이었는데, 본 절에서 최종적인 grounding을 위해 두 모달을 합쳐주게 됩니다.
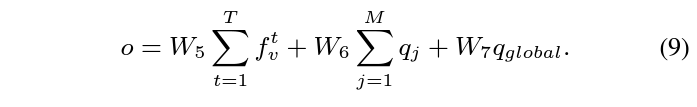
수식 9의 출력인 o는 grounding에 활용될 multi-modal feature입니다. 마찬가지로 linear projection의 연속이며, 아까 추출했던 sentence-level feature q_{global}도 함께 사용되고 있습니다.
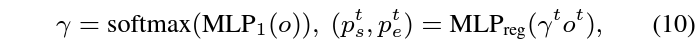
최종적인 예측은 수식 10과 같이 수행되며, 그 이전 o를 활용한 snippet-wise attention score \gamma{}를 또 한번 추출하고 곱해주는 것을 볼 수 있습니다.
학습은 두 가지 loss로 수행됩니다.
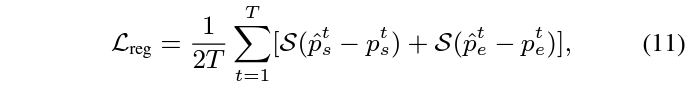
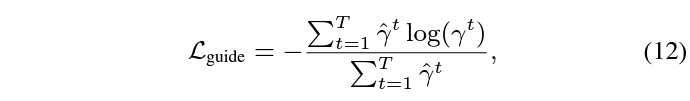
수식 11은 가지고 있는 GT 구간과의 CE Loss를 의미하고, 수식 12는 수식 10에서 뽑은 snippet-wise attention score를 guide 해주기 위한 loss로, 실제 GT 구간 내 포함되는지 여부에 따라 0 또는 1로 guide 됩니다.
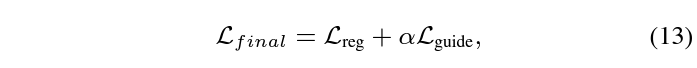
방법론은 여기서 마치고 실험 부분으로 넘어가겠습니다.
3. Experiments
3.1 Comparison with SOTA
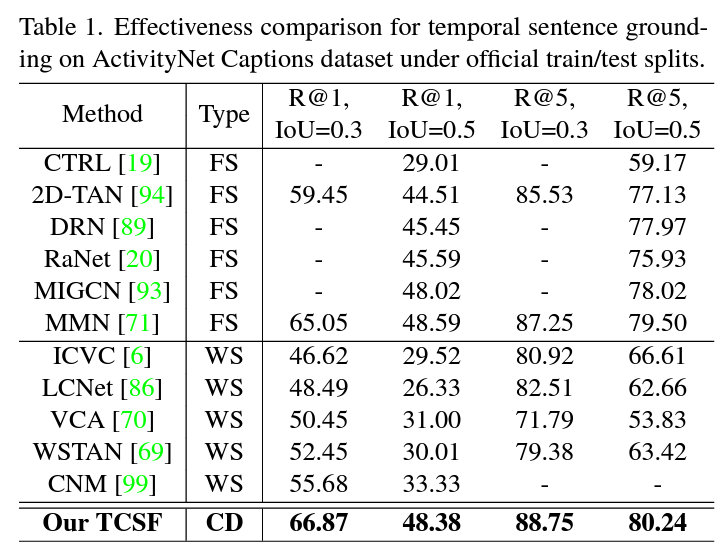
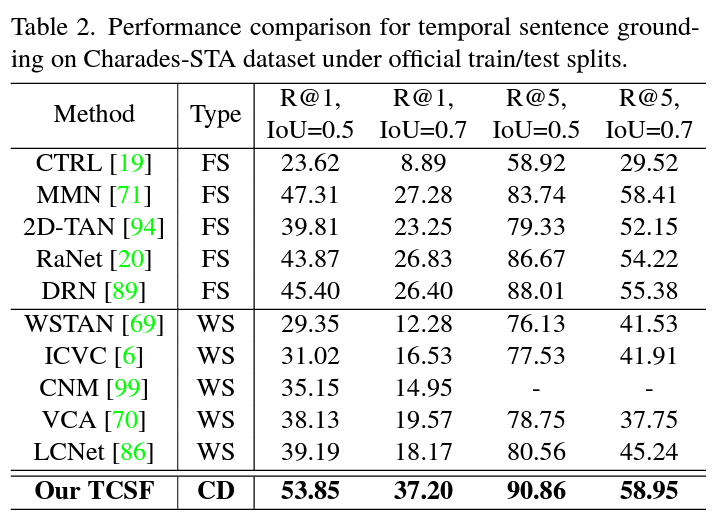
표 1, 2는 각각 ActivityNet Captions, Charades-STA 데이터셋에 대한 벤치마크 표입니다. 일반적으로 compressed-domain 방법론들이 다른 task에서는 성능이 좀 낮더라도 효율성을 중시하는 경우가 많은데, 본 논문은 다른 방법론들보다 성능 측면에서도 압도적인 것을 볼 수 있습니다. 그래서 비교 방법론들이 예전 논문은 아닐까 하고 찾아보니, 22년도 방법론들과의 공정한 비교를 수행하고 있었습니다. 효과적이면서 효율적이라는 저자의 주장 중 효과적이라는 이야기는 충분히 입증된 것으로 보입니다.
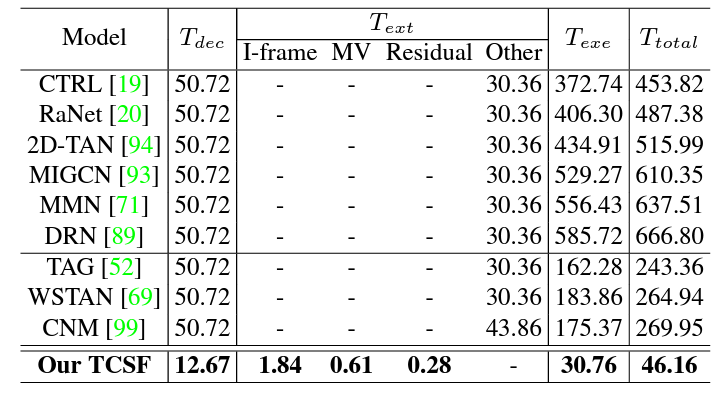
이제 효율성에 대해 알아봐야 합니다. 효율성은 메모리나 연산량 측면도 있겠지만 수행 시간을 보는 것이 중요하겠죠. 우선 표 3에서 각 열은 decompressing, feature extraction, model execution에 소요되는 시간을 의미합니다. 우선 저자가 제안하는 TCSF의 T_{total}이 타 방법론들에 비해 압도적으로 적은 것을 볼 수 있습니다. 저자가 언급하고있진 않지만 T_{dec}이 적은 이유는 아마 아예 다른 codec을 사용했기 떄문으로 보입니다. 모든 단계에서 획기적으로 시간이 줄은 것을 볼 수 있습니다. 빠르게 추출할 수 있는 feature로부터 FC layer와 MLP로 구성된 효율적 모델로 좋은 성능을 보여주고 있는것이 인상깊은 부분입니다.
3.2 Ablation Studies
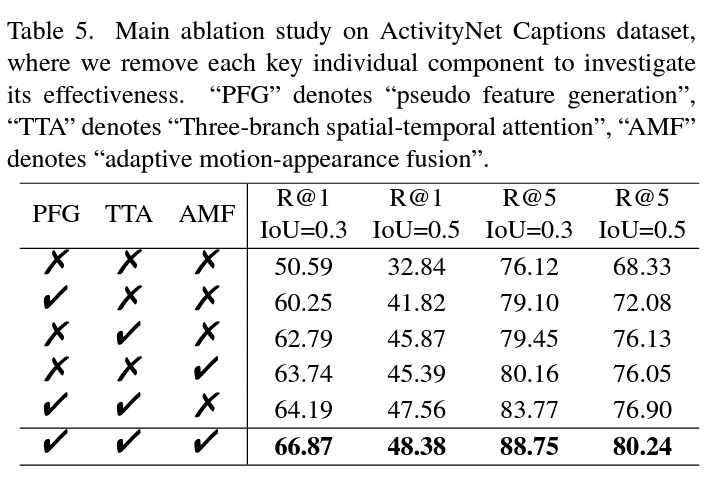
표 5는 가장 기본적인 module-wise ablation 성능입니다. 놀라운 것은 기본적으로 compressed-domain 모델의 베이스라인 성능이 굉장히 낮다는 것입니다. 표 1과 비교해보면 거의 2021년도 방법론들과 비슷한 상황인데, 각 모듈을 통해, 특히 pseudo feature generation 과정이 naive함에 큰 성능 향상을 불러왔음을 알 수 있습니다.
나머지 실험들은 구성 요소별, hyperparameter에 대한 ablation으로 직접 찾아보시면 좋을 것 같습니다.
마지막으로 정성적 결과 보며 리뷰를 마치겠습니다.

체리피킹의 결과이기에 타 방법론들에 비해 TCSF가 잘하고 있는 모습을 볼 수 있고, 다시 한 번 효율성을 강조하기 위해 저자는 붉은 글씨로 inference time을 함께 적어두었습니다. 이렇게 보니 제목의 You can ground earlier than see라는 말이 조금 더 와닿네요.
Conclusion
압축된 비디오로부터 각종 비디오 task를 수행하는 논문은 많이 봐왔지만, 본 논문처럼 간결하면서 성능까지 좋은 논문은 많이 보지 못했던 것 같습니다. 일전에 Action localization을 위해 압축된 비디오의 motion vector로부터 정보를 얻어올까 하다가 optical flow가 있기에 방향성을 접어두었던 적이 있었는데, grounding에서는 이것이 잘 동작한다는 점이 추후 하나의 큰 연구 방향으로 발전할 수 있겠다는 희망을 준 논문이었습니다.
이상으로 리뷰 마치겠습니다.
감사합니다.
안녕하새요. 김현우 연구원님.
항상 비디오 연구가 모든 이미지를 RGB로 복원하고 수행하여 고사양이라고 생각하고 있었는데, 압축된 상태로 비디오를 활용할 수 있는 이러한 연구가 굉장히 중요하고 흥미로운 것 같습니다. 추후에 저도 동영상 압축을 다시 공부해봐야 겠습니다.
1. 본 논문에서 I-frame은 ResNet-50으로, P-frame은 ResNet-18로 feature를 뽑았는데, 이 모델들은 사전학습 모델인가요? 그리고 두 프레임에 다른 깊이의 ResNet을 쓴 이유에 대한 언급이 있었을까요?
2. 중간에 단어에 따라 motion feature와 appearance feature에 다른 가중치를 부여하는 아이디어가 흥미로웠는데, 이게 단순히 어텐션으로 수행하게 되면 학습 시 많이 등장하지 않은 단어들에서는 잘 작동하지 않을 것 같은데 이에 관련한 이야기가 있었나요?
감사합니다!