Before Review
오랜만에 X-Review 입니다. 이번에 리뷰 할 논문은 Scene Graph Generation 논문입니다. 졸업전까지는 해당 연구 분야로 논문 연구를 해보려고 합니다. 논문을 한편 더 쓰고 졸업하고 싶지만 마음대로 될지는 모르겠네요..
우선 오늘 리뷰 하는 논문은 오늘날 SGG 연구의 기반이 되고 있는 논문으로 SGG 문제를 푸는 최초의 논문은 아니지만, 가장 중요했던 bias problem에 대한 훌륭한 insight를 제공한 논문입니다. 동시에 모든 연구에 사용 가능한 protocol을 코드로 잘 공개하여 후속 연구들은 모두 이 코드를 활용하고 있습니다.
논문 자체는 제가 최근 읽어본 논문 중에 이해하기 가장 어려웠던 논문인 거 같네요. 우선, 해당 논문에서 라이팅이 문장을 길게 쓰는 형식이다 보니, 읽기 어려웠습니다. 문장을 끊어서 쓰지 않고 어떻게든 붙여서 서술하는 방식이라 해석하기 조금 어려웠습니다. 또한 논문의 motivation을 psychological 연구 내용 기반으로 하여, 글을 구성하는 단어들도 너무 어려웠고 저자의 말하고자 하는 내용을 파악하는 것도 쉽지 않았습니다.
하지만 연구 내용 자체는 정말 훌륭했습니다. 논문을 읽다 보면, Oral 논문으로 선정된 이유를 알 수 있었습니다.
그럼 리뷰 시작하도록 하겠습니다.
Preliminaries
Scene Graph Generation
Scene Graph Generation (이하 SGG)은 말 그대로 이미지를 입력 받았을 때 이미지를 구성하는 객체 간 관계를 나타내는 그래프를 생성하는 문제 입니다.
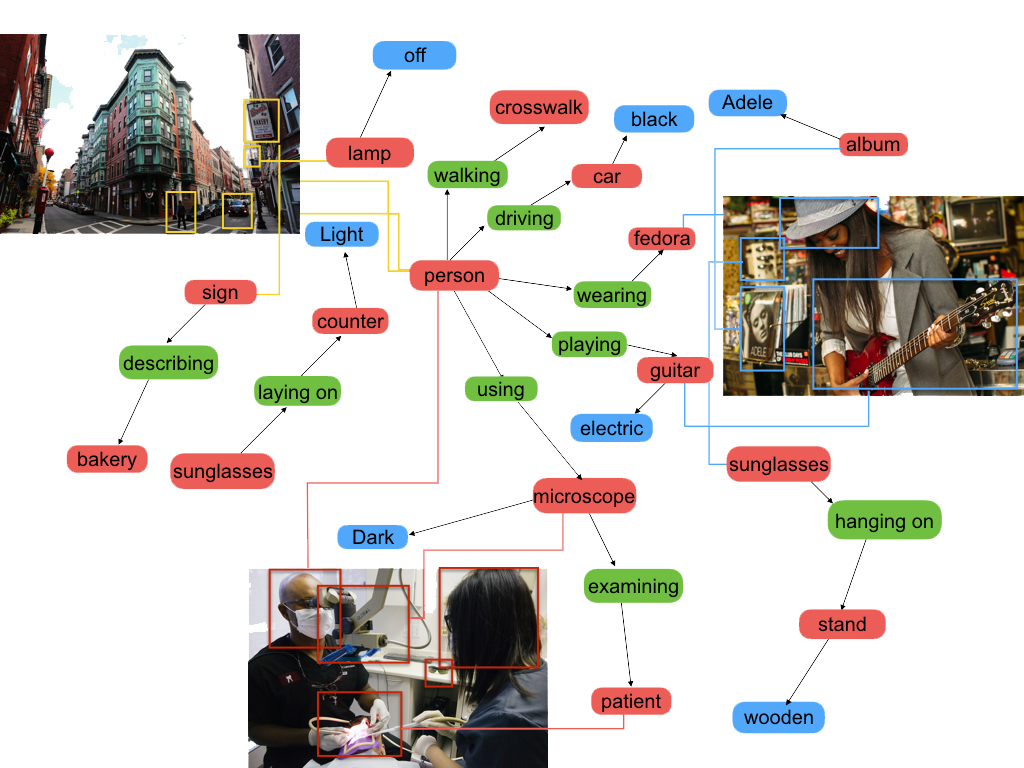
이렇게 표현된 장면 그래프 (Scene Graph)들은 VQA, image captioning, grounding 등 다양한 task에 활용이 가능합니다. 굉장히 high level의 semantic information을 표현한다고 생각하시면 될 거 같습니다.
그렇다면 Scene Graph의 구성 요소는 어떻게 되어 있는지 살펴보도록 하겠습니다. Scene Graph의 구성 요소는 크게 세 가지로 구분이 됩니다. 1) Subject, 2) Predicate, 3) Object 이렇게 세 가지가 존재하게 됩니다. 주어, 서술어, 목적어라 보시면 됩니다. 그래서 Scene Graph에서 우리가 찾아야 하는 최소 단위는 아래와 같습니다.
<subject, predicate, object>
즉, 이미지를 설명할 수 있는, 주어, 서술어, 목적어로 구성된, triplet을 잘 찾는 것이 최종 목적이라 보시면 됩니다.

위의 예시를 보면 <television, on, wall> 이런 triplet도 존재하고, <man, riding, horse>와 같은 triplet도 존재합니다. 즉, 저희는 검출된 객체마다 어떤 관계를 가지고 있는 예측하는 분류 문제를 푸는 것이라 보면 됩니다.
정말 naive한 문제 정의를 살펴봤고 이제는 SGG 연구들의 전반적인 흐름을 알 수 있는 구조도를 한번 살펴보도록 하겠습니다.
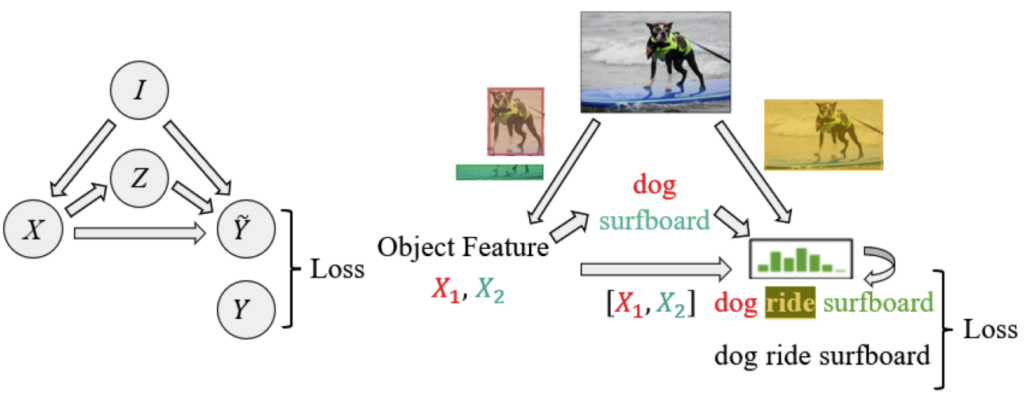
여기서
- I는 Input Image에 해당합니다.
- X는 Object Feature에 해당합니다. 보통 Faster R-CNN을 많이 사용합니다. 하지만 2022년 기준으로는 DETR 구조를 활용하는 연구도 등장하기 시작했습니다.
- Z는 Object Class에 해당합니다.
- \widetilde{Y}는 Predicate에 해당합니다.
결국 \widetilde{Y}을 잘 만드는 것이 중요한 것인데 위의 구조도(그래프)를 보면 \widetilde{Y}을 만드는 과정에 3가지로 표현이 되어 있습니다.
- X \to \widetilde{Y} : object feature를 바탕으로 predicate를 예측합니다. i번 째 object feature x_{i}와 j번 째 object feature x_{j}를 입력으로 넣어서 이 둘의 관계 f(x_{i},x_{j})=p_{i,j} 를 분류하는 문제라고 보시면 됩니다.
- Z \to \widetilde{Y} : object class를 가지고 predicate를 예측합니다. 여기서는 보통 language model을 써서 수행합니다. <person – ??? – horse> 라면 보통 ride를 예측하는 것이 일반적이고 이러한 prior를 바탕으로 예측한다고 보시면 됩니다.
- I \to \widetilde{Y} : 마지막으로 이미지를 가지고 바로 predicate를 예측합니다. 여기서는 Mask R-CNN에서 제안된 RoI Align을 활용하여 두 객체에 대한 joint region에 대한 feature를 추출하고 predicate를 예측합니다. 제가 RoI Align이 무엇인지는 자세히 몰라서 이 정도로만 설명하도록 하겠습니다.
굉장히 복잡합니다. 핵심은 장면 내에 존재하고 있는 많은 정보를 뽑아내서 예측을 수행하겠다 정도로 이해하시면 될 거 같습니다.
Introduction
Scene Graph Generation 자체에 대한 소개는 위에서 이미 했습니다. 그렇다면 SGG가 겪었던 당시 문제들은 뭐가 있었을 까요? 사실 아직도 많은 논문들이 문제 삼고 있는 부분이 바로 biased training 입니다.
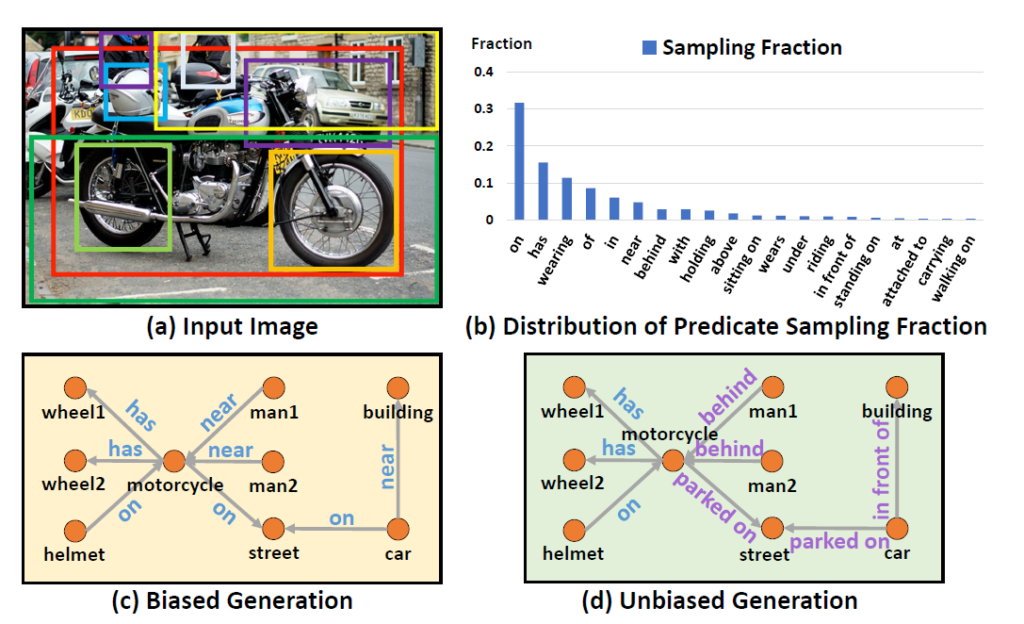
위의 그림에서 (b) Distribution of Predicate Sampling Fraction을 보면 Long-Tail 형태를 보여주고 있습니다. 특정 Predicate에 의존하여 예측 값을 만들고 있는 상황이죠. 이는 당연히 학습 데이터의 편향 문제가 심각하기 때문이죠. 사람이 annotation을 하는 관점에서도 standing on 이라고 하는 것 보다는 on이라고 하는 게 더 편하기 때문이죠. (물론 이건 추측 입니다.)
이런 bias 문제를 해결해야만 near 이라고 예측하던 것을 behind 혹은 in front of 와 같은 다양한 답변을 내놓게 할 수 있는 것이죠. 하지만 쉽지 않습니다. 저자는 또한 흥미로운 점을 하나 발견합니다. 단순히 Visual Genome benchmark 데이터에 검출된 객체들의 통계적 사전 지식 (statistical prior)만 활용해도 Recall@100에서 30.1%의 성능을 달성하는 것을 확인합니다. 여기서 통계적 사전 지식은 자세히는 모르겠지만 복잡한 구조가 아닌 굉장히 간단한 베이스라인을 의미하는 것 같습니다.
놀라운 점은 저 30.1% 성능이 한참 연구되고 복잡하게 모델링 되고 있는 sota 연구들과 고작 1.1~1.5% 성능 차이 밖에 나지 않는다는 것이죠.
결국 기존의 연구들도 편향 문제를 해결하지 못해서 이러한 병목 현상에 도달했다고 저자는 주장합니다. 기존 SGG 연구들을 보았을 때 대부분 subject와 object 들의 visual feature 들을 content로 정의하고 그들의 클래스나 union region에 대한 visual feature들은 context로 정의합니다.
여기서 본 논문을 이해하기 위해 중요한 것은 content와 context를 제대로 구분하는 것 입니다.
Content는 내부적인 요인으로 인해 결정 되어 집니다. 반대로 Contenxt는 외부적인 요인으로 인해 결정 되어 집니다. 말이 조금 어렵습니다. 그림을 가지고 설명을 해보자면

해당 장면에서 Content는 무엇일까요? 객체의 시각적 특징 그 자체 입니다. Dog의 경우 네 발로 서있고, 꼬리를 가지는 등의 시각적 특징을 가집니다. 다른 환경이나 외부적 요인 없이 Dog를 묘사하는 정보가 바로 Content라는 것 입니다.
반대로 Context는 무엇일까요? Dog의 클래스 이름은 일단 Context로 활용할 수 있습니다. 클래스 이름도 content 아니냐 라고 물어볼 수 있지만 사실 Dog라는 단어는 비단 강아지 뿐만 아니라 다양한 의미를 가지고 있죠. 한국에서도 개~~ 이런식의 서술어를 많이 사용하는 걸 보면 클래스 이름 자체는 Content가 될 수 없습니다. 대신 Context가 될 수 있는 것이죠. 또한 관심 있는 객체를 제외한 모든 것이 Context 입니다. 바닷가, 푸른 하늘 모래사장 등등
자 이제 Content와 Context가 무엇인지 충분히 설명을 했으니 사람과 기계가 의사결정을 할 때의 차이를 살펴보도록 하겠습니다.
본 논문에 따르면 사람들은 의사 결정을 내릴 때 인과관계를 기반(causality-based)으로 한다고 합니다. 즉, content에 집중하고 context는 중요하게 생각하지 않는 다는 것 입니다.
반대로 기계는 의사 결정을 내릴 때 가능성(likelihood-based)을 기반으로 진행합니다. Content와 Context를 동시에 고려한 거대한 가능성 테이블을 바탕으로 가장 그럴듯한 예측을 내놓는 것이죠. 즉, 무엇이 중요한 것인지 main effect 인지 구분을 할 수 없다는 것 입니다.
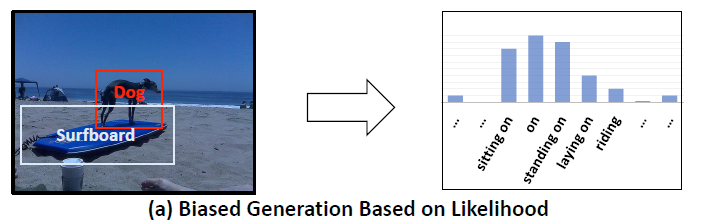
사람은 content가 만들어내는 main effect와 context가 만들어내는 side effect를 구분할 수 있습니다. 하지만 기계는 이런 main effect와 side effect를 구분할 수 없습니다. 이것이 가장 큰 차이점이고 biased prediction을 내놓는 이유라 분석 합니다.
그렇다면 기계도 사람처럼 의사 결정을 하기 위해서 뭐가 필요할까요? 저자는 이를 위해 반-사실적 사고(Counterfactual Thinking)을 활용합니다.
Cotent가 없다고 가정을 하고 의사 결정을 내려보는 거죠. 즉 우리가 변인 통제를 하면서 실험을 하는 것과 동일하다고 보시면 됩니다. 하나의 요인의 영향력을 확인하기 위해서 해당 요인이 있을 때와 없을 때의 결과를 비교하는 것처럼 Content가 있을 때와 없을 때를 가정하고 결과를 비교하는 것 입니다.

위의 그림을 보면 Content를 아예 없앴을 때의 사진입니다. 오른쪽에 있는 사진을 가지고 예측을 진행하면 Content + Context인 상황이라 볼 수 있습니다. 반대로 왼쪽에 있는 사진을 가지고 예측을 진행하면 Context만을 존재하는 상황입니다.
그렇다면 우리가 집중하고 싶은 정보는 Content 이니, 두 예측값의 차이를 계산해보면 더 좋은 결과가 나오지 않을까라는 것이 Counterfactual Thinking 활용하는 것 입니다. Content가 없다는 반 사실적 상황에 대한 예측을 활용하는 것이니까요.
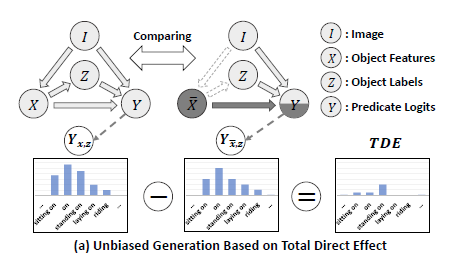
이를 SGG에서 일반적으로 활용하는 인과 그래프 형태로 표현해보도록 하겠습니다.
Y_{x,z}에 해당하는 그래프는 원래 기본 SGG 모델의 예측 형태 입니다. 즉, Content와 Context가 모두 포함된 예측이 Y_{x,z} 인 것이죠.
그리고 Y_{\overline{x},z}는 Cotent가 없다고 가정했을 때 SGG 모델의 예측 형태 입니다. 즉, Context만 고려한 예측이 Y_{\overline{x},z} 이죠.
저자는 Y_{x,z} - Y_{\overline{x},z}이 (Content+Context)-(Context)이니 Content에 집중한 예측이라 주장합니다.
즉, 원래대로 Y_{x,z} 이렇게 예측을 했다면 아래의 likelihood 대로 올바른 standing on이 아니라 편향된 on 이라는 예측을 했을 테지만,
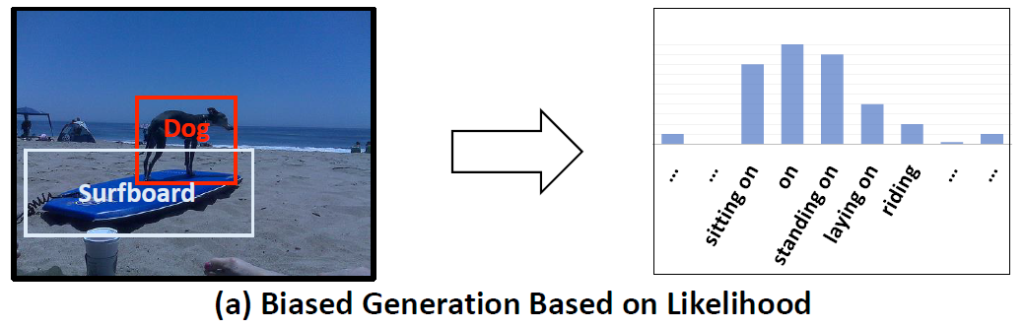
Counterfactual thinking에 기반하여 Y_{x,z} - Y_{\overline{x},z} 이렇게 예측을 수행하면 context에 biased 된 예측이 아니라 content에 집중한 unbiased 예측 결과 (standing on)를 얻을 수 있다는 것 입니다.
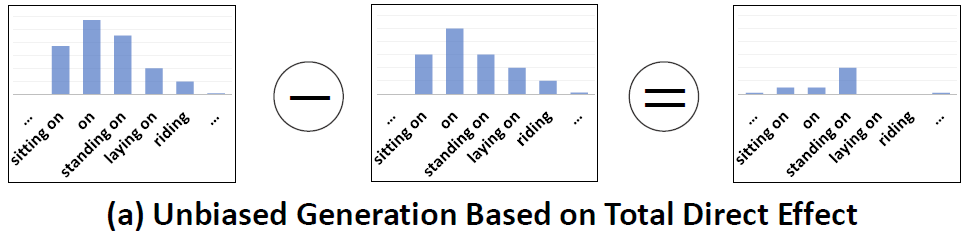
실제로 이렇게 제안하는 방식대로 예측을 수행하면
위의 그림처럼 더 이상 예측이 Long-Tail 분포를 따르지 않는 것을 확인할 수 있습니다.
저자는 이렇게 Counterfactual thinking에 기반하여 bias problem을 해결하는 방식을 제안합니다. 저자가 제안하는 이 방식은 어떠한 추가 파라미터 없이 기존 SGG 방법론에 모두 적용 가능한 방법이라 주장합니다. 굉장히 general한 solution을 제안 했다는 점에서 contribution이 크게 작용하는 것 같습니다.
또한 저자는 새로운 SGG diagnosis toolkit을 제안합니다. 이를 통해 기존의 방법들의 편향 문제가 얼마나 심각했고 제안하는 방법이 편향 문제를 얼마나 잘 해결할 수 있는 지를 증명합니다.
Introduction 분량이 조금 길어졌는데 실제로 본 논문의 Introduction 분량이 3페이지 입니다. Method 부분은 사실 이미 Intro에서 설명한 내용을 조금 더 구체적으로 서술하는 것 뿐이니 가볍게 보시면 될 거 같습니다.
Method
Biased Training Models in Causal Graph
아래의 그림을 보면 기존의 SGG 연구들의 학습 과정을 일반적으로 나타낸 그림을 확인할 수 있습니다.
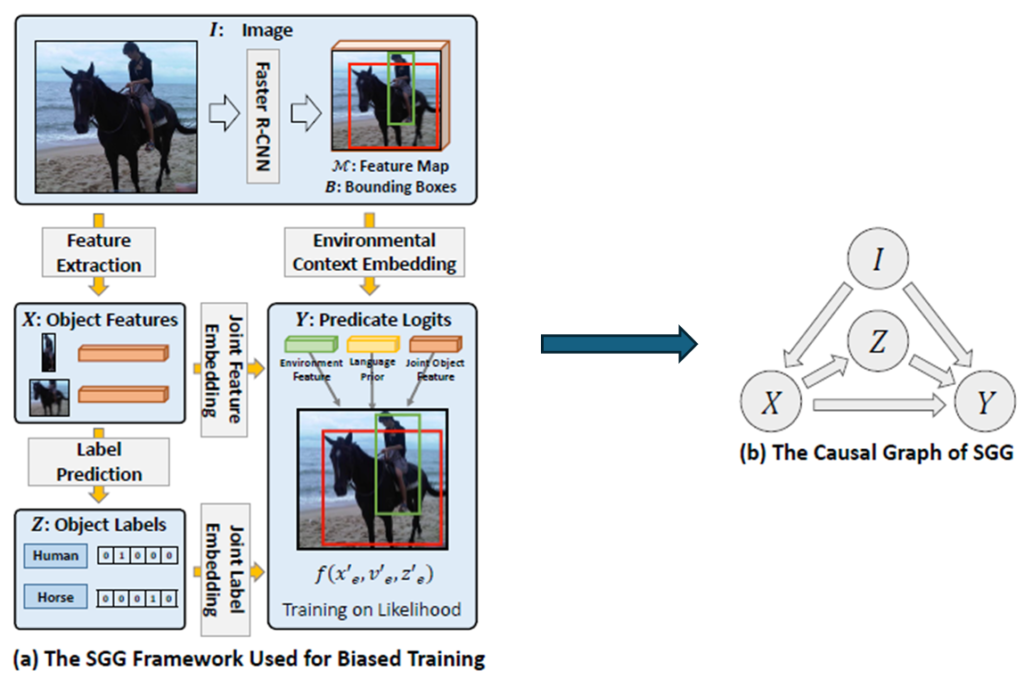
아까 Preliminaries에서 설명한 것과 동일 합니다.
- X \to Y : object feature를 바탕으로 predicate를 예측합니다. 여기서 X는 Content에 해당합니다.
- Z \to Y : object class를 가지고 predicate를 예측합니다. 여기서 Z는 Context에 해당합니다.
- I \to Y : 이미지를 가지고 바로 predicate를 예측합니다. 여기서 I는 Context에 해당합니다.
Y에 들어오는 예측 값이 다양하니 (X, Z, I) 이를 fusion하는 방식도 다양하다고 합니다. 제가 다른 논문들을 읽어본 건 아니라 해당 논문을 기준으로 삼으면 Sum 혹은 Gate 연산을 통해서 fusion을 진행한다고 합니다. 자세한 내용은 다루지 않고 그냥 선택지가 있다는 정도만 알고 넘어가면 될 거 같습니다.
전체적인 학습은 CrossEntropy Loss를 토대로 진행됩니다. Predicate가 원래 어떤 관계였는지 분류 문제를 푼다고 보시면 됩니다.
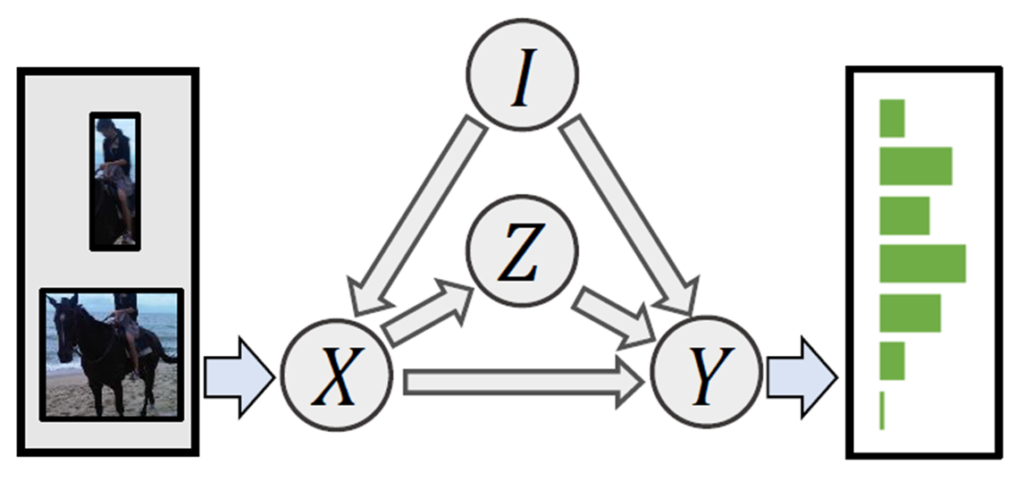
Unbiased Prediction by Causal Effects
위의 방식대로 학습을 마치고 나면 분명 학습 파라미터에 causal dependency가 남아 있는 상태로 마치게 됩니다. 편향이 존재한다는 것이죠. 이 때 Biased prediction은 Causal Graph 전체를 입력으로 받고 그대로 출력을 내놓은 상태를 의미합니다.
우리는 Content에 해당하는 X의 영향력을 확인해보고 싶으니 I \to X 로 가는 링크를 잘라서 없애버린 후 Counterfactual thinking을 해봅니다. 즉, X는 dummy data를 넣는 것이죠. 하지만 우리는 Content의 영향만을 확인해야 하기 때문에 Z는 그대로 유지가 된다는 가정을 합니다.
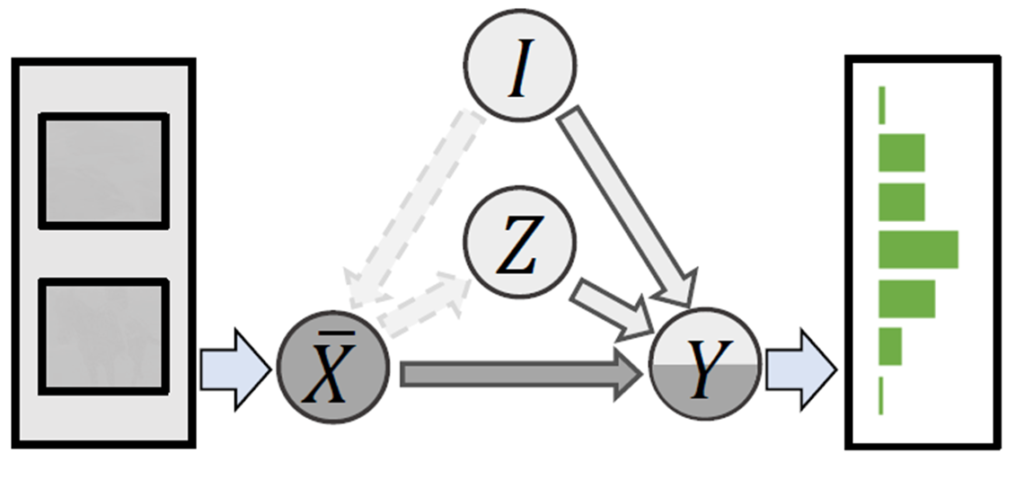
위의 그림처럼 말이죠.
원래의 예측과 Counterfactual thinking을 하고 나서 예측의 차이를 계산하면 이제 Content에 집중할 수 있다는 것이 본 논문의 아이디어 입니다.
이를 좀 더 명확하게 표현하기 위해 간단한 notation 먼저 정의 하겠습니다.
Intervention : 말이 어려워서 저도 사전에 검색 해봤는데, 간섭이라는 의미의 단어입니다. do(\cdot)로 정의하고 있고 do(X=\overline{x})라는 말은 X로 들어오는 모든 입력을 끊고 임의의 값으로 대체하는 것이라고 하네요. 아래의 그림을 보면 간섭이 일어났기 때문에 Object Class에 해당하는 Z 에도 변화가 발생합니다. 이런 방식은 온전히 X의 영향력을 파악하기에는 무리가 있습니다.
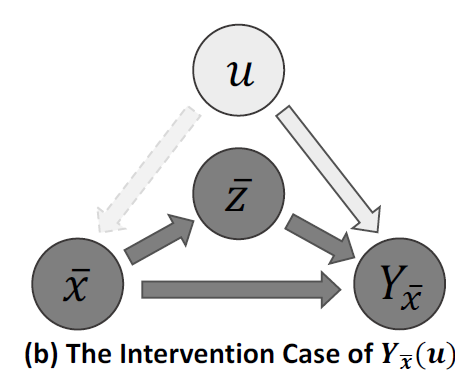
Counterfactual : 이건 반 사실적이라는 의미의 단어 인데, 반 사실적이라는 것은 말 그대로 일어나지 않은 사실에 대한 가정을 하는 것 입니다. 예를 들어 “내가 그 때 술을 먹지 않았더라면…” 이라는 말은 술을 먹었으니 반 사실이지만 먹지 않았을 때의 상황을 가정하고 생각하기 때문에 반 사실적 사고라고 표현합니다.
이걸 intervention이랑 같이 활용하면 do(X=\overline{x}) 즉, 간섭이 일어나서 X에 대한 정보는 없지만 X가 있었더라면…. 가정을 해서 Z는 그대로 유지가 되는 상황을 생각해볼 수 있습니다.
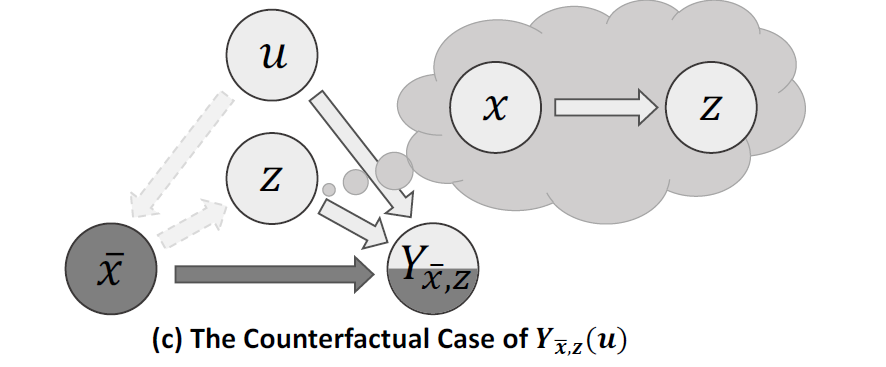
즉, X에만 변화를 주고 나머지는 동일하게 가져가고 예측을 수행하고 원래의 예측과 차이를 확인하는 것이 저자가 제안하는 unbiased framework 입니다.
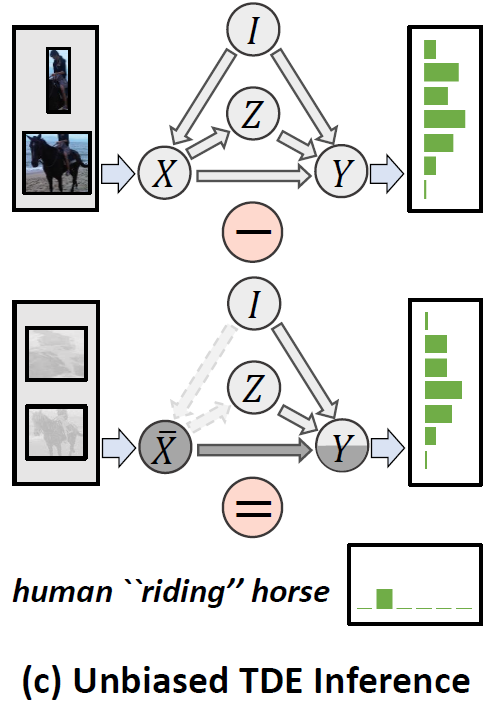
다시 정리하지만
- 원래의 예측 (Content + Context) – 반 사실적 예측 (Context) = 편향 되지 않은 예측 (Content)
이렇게 설계 했다고 보시면 됩니다.
여기서 Counterfactual을 고려하면 Total Direct Effect (TDE), Intervation만 고려하면 Total Effect (TE)라고 하네요. 해당 용어는 Causal Inference 분야에서 많이 사용하는 용어라고 하는데 둘의 차이에 대해서는 본 리뷰에서 다루도록 하지는 않겠습니다.
무튼 저렇게 두 예측의 차이를 최종 예측으로 가져가는 것이 저자가 제안하는 unbiased framework라고 합니다. 해당 방법은 어떠한 추가 학습 파라미터 없이 모든 SGG 모델에 범용적으로 활용 가능한 방법이기 때문에 저자는 3가지 베이스라인 방법론을 가지고 실험을 진행했다고 합니다.
Experiments
저자는 제안하는 Unbiased Framework의 우수함을 입증하기 위해 세가지 베이스라인(VTransE, MOTIFS, VTree)을 활용합니다. 아래 실험에서 해당 방법론이 나오면 plug and play 방식으로 비교하기 위함이라 생각하시면 될 거 같습니다.
Scene Graph Generation Diagnosis
저자가 제안하는 SGG diagnosis는 세가지 평가 방식으로 구분되어 있습니다.
Relationship Retrieval (RR) : Predicate를 예측하는 건데 여기서도 세가지 sub-task로 구분이 됩니다. Inference 과정에서 사용하는 annotation 정도에 따라 난이도 차이가 있다고 보시면 됩니다.
- Predicate Classification (PredCls) : ground truth box와 label을 입력으로 넣어서 predicate를 예측합니다.
- Scene Graph Classification (SGCls) : ground truth box만 입력으로 넣어서 predicate를 예측합니다.
- Scene Graph Deteciton (SGDet) : predicate를 scratch level로 예측합니다. 즉, box와 label을 직접 예측하고 그 다음 predicate를 예측하는 것이죠
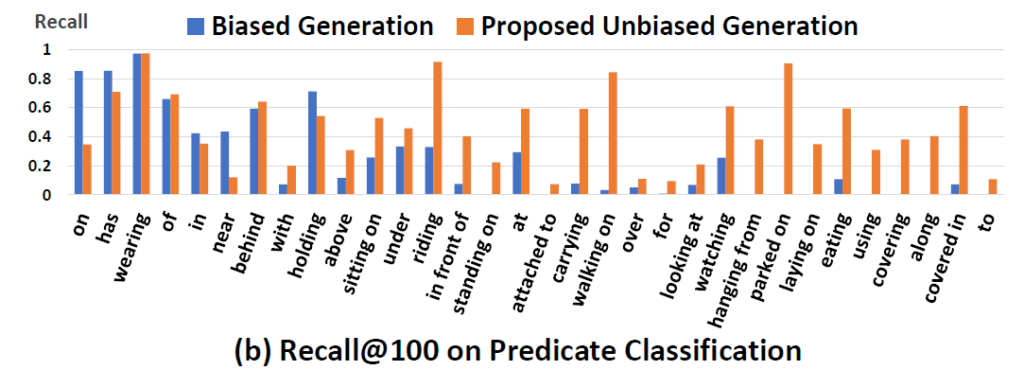
기존의 평가 메트릭은 Recall@K (R@K)를 활용했었는데 이게 Head 쪽에만 초점을 맞추고 있고 Tail 쪽은 고려를 잘 못한다고 합니다. 아래의 그림을 보면 on이나 has와 같이 자주 나오는 head predicate에 대해서는 Recall이 높은데 parked on, laying on와 같은 tail predicate에 대해서는 Recall@100이 0.0으로 산출된다고 하네요.
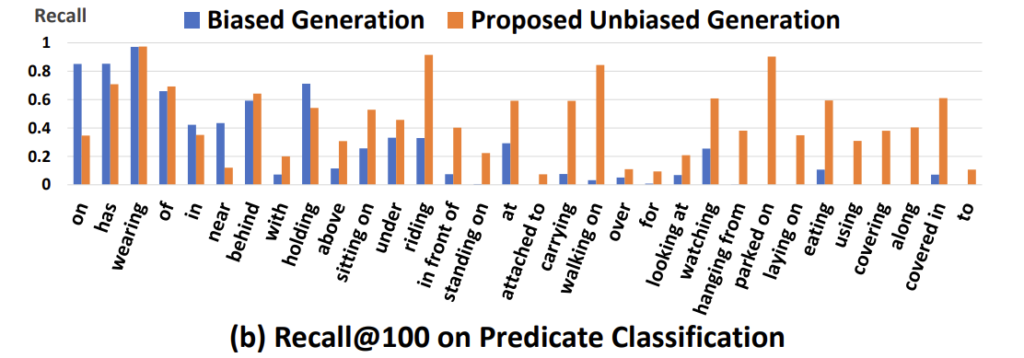
그래서 이러한 문제를 해결하기 위해 최근에 제안된 mean Recall@K (mR@K)라는 것을 새롭게 채택하여 사용한다고 하네요.
Zero-Shot Relationship Retrieval (ZSRR)
Lu et al 이 제안한 Zero-Shot Recall@K를 바탕으로 Visual Genome 데이터셋에 처음으로 평가를 진행했다고 하네요. 즉, 학습때 본 적 없는 <subject-predicate-object> triplet에 대한 Recall@K를 측정하는 것이죠.
ZSRR 역시 Relation Retrieval (RR)과 마찬가지로 세가지 sub-task (PredCls, SGCls, SGDet)가 존재한다고 합니다.
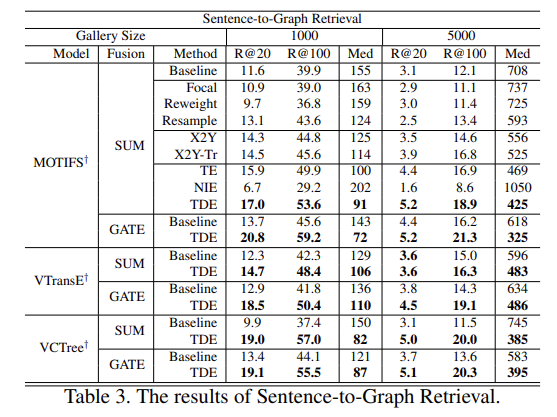
Sentence-to-Graph Retrieval (S2GR)
이미지 caption을 query도 던져서 scene graph로 표현되는 이미지를 찾아준다고 합니다. retrieval 자체는 image caption과 scene graph간의 유사도를 기반으로 진행되고 이에 따라 이미지도 같이 확인할 수 있는 것 같습니다.
즉, human description을 통해서 Scene Graph를 찾는 것을 평가한다고 보면 됩니다.
아마도 목적 자체는 기존의 2D Encoder를 통해서 나오는 visual feature 들은 black-box 인 반면 graph 같은 경우는 사람이 시각화를 하고 해석을 해볼 수 있기 때문에 중요한 task라고 볼 수 있습니다.
Ablation Studies
Ablation Study는 결국 편향을 제거하는 다양한 방법들에 대해서 비교하고 있습니다.
- Focal Loss : Focal Loss 입니다. Hard Sample에 좀 더 집중할 수 있도록 하여 bias 문제를 해결한다고 보시면 됩니다.
- Reweight : Weighted Cross Entropy Loss 입니다. 불균형, 편향 문제가 심할 때 보통 사용한다고 합니다.
- Resample : Tail 쪽에 해당하는 데이터(몇개 없는)를 더 자주 뽑아서 학습 균형을 맞추는 방법이라 보시면 됩니다.
- X2Y : 결국 unbiased effect는 object feature X로 부터 기인 했습니다. Content 였기 때문이죠. 그래서 예측을 X \to Y로 바로 하는 방식이라 합니다. 학습 자체는 biased 되었지만 그래도 Content로만 예측을 했을 때 베이스라인 대비 성능을 비교하여 Object feature가 정말로 예측에 중요한지 보기 위함이라 보시면 됩니다.
- X2Y-Tr : 학습 때 다른 branch를 다 자르고 X \to Y만 사용했다고 합니다.
- TE : 앞서 설명한 Total Effect 입니다.
- NIE : Total Effect(TE) – Total Direct Effect(TDE) 라고 합니다.
Quantitative Studies
우선 Relationship Retrieval에서 정량적 결과 입니다. 아래 테이블을 보시면 연두색으로 칠해진 부분이 베이스라인 부분이라 보시면 됩니다. Relationship Retrieval 기준으로는 Focal, Reweight, Resample 등 기존의 방식들이 베이스라인 대비 조금 더 좋은 성능을 보여주긴 합니다.
X2Y와 X2Y-Tr의 경우는 베이스라인 보다 성능이 좀 오르긴 하지만 그 폭이 크지가 않습니다.
TE의 경우는 TDE와 거의 비슷한 성능을 보여주면서 최종적으로는 TDE가 가장 높은 성능을 보여 줍니다.
3가지 방법론과 3가지 sub task 상황에서 모두 baseline 대비 높은 성능 향상을 이끌어내는 점이 인상 깊습니다.
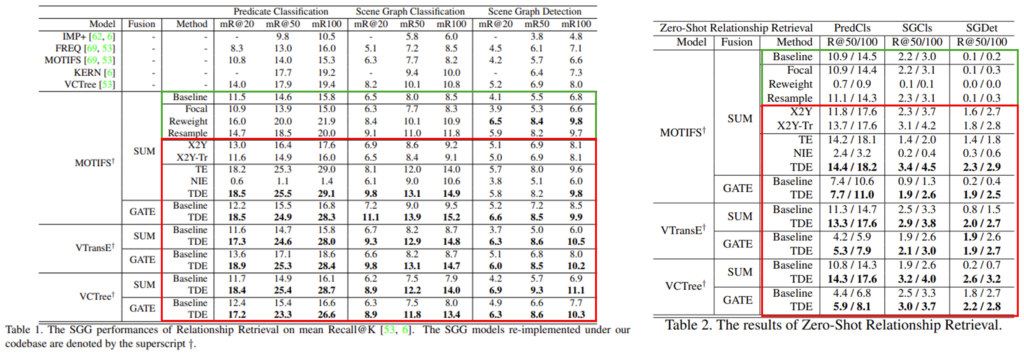
Sentence to Graph 상황에서도 비슷합니다. TDE가 모든 평가 상황에서 안정적인 모습을 보여주고 있습니다.
Qualitative Studies
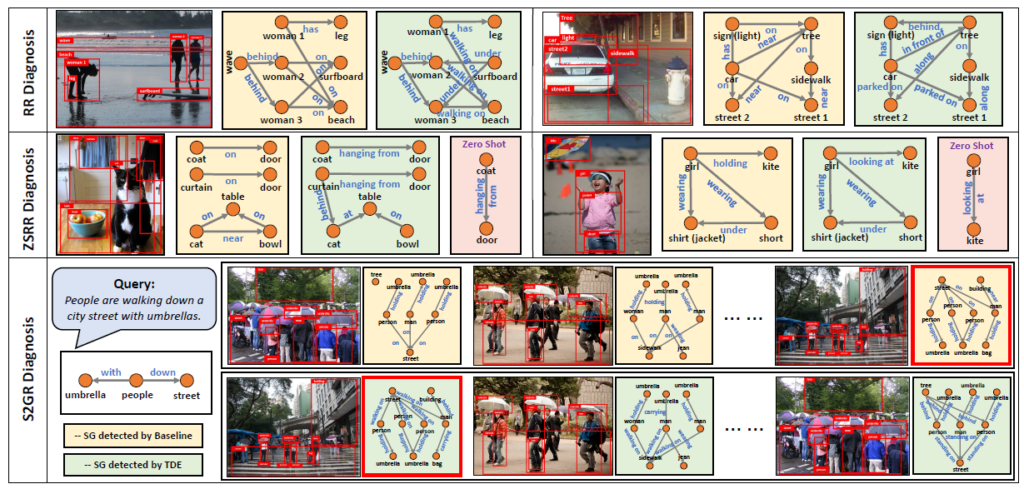
노란색이 베이스라인이고 연두색이 MOTIF-SUM에 대한 TDE 세팅에서의 결과입니다.
아마 좀 자세히 비교를 해봐야 느낄 수 있는데 비교적 표현이 뚜렷해지는 것을 볼 수 있습니다. 기존의 베이스라인 예측은 on이라고 하는 trivial prediction이 조금 많았는데 제안하는 TDE를 활용하면 조금 더 의미 있는 predicate를 생성하고 있습니다.
전반적으로 하나씩 비교를 해보면 베이스라인 대비 제안하는 TDE 방식이 좀 더 관계에 민감하게 반응하여 정교한 예측을 수행하고 있는 모습을 확인할 수 있습니다.
Conclusion
네 우선 이것으로 리뷰를 마치겠습니다. CVPR oral 페이퍼는 Simple 하면서도 General 하면서도 성능적인 기여도가 매우 강하네요. 대단합니다.
앞으로는 좀 더 다양한 SGG 연구들을 소개할 수 있도록 공부해보겠습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
논문이 굉장히 철학적인 아이디어를 해당 분야로 잘 가져온 것과 같은 느낌이 드네요…
보통 counterfactual한 정보를 활용하는 방법론의 경우 softmax를 타고 나온 예측 결과에 대해 <원래의 예측 (Content + Context) – 반 사실적 예측 (Context) = 편향 되지 않은 예측 (Content)> 과정을 거치는 것 맞나요?
그렇다면 이를 softmax를 타고 나온 예측 결과이 아니라 feature level 또는 모델 자체에서 구현하는 방법론들도 있는지 궁금합니다.
안녕하세요 근택님 좋은 리뷰 감사합니다.
counterfactual 기법을 사용하여 bias 문제를 해결하는 방법을 SGG방법론이 아닌 다른 multimodal 관련 방법론에서 본 기억이 있는데 해당 논문에서 제안된 방법이라는 것이 신기하네요.
평가지표에서 궁금한 점이 있습니다. A 앞에 B가 있는 이미지에서 infront of 라는 predicate가 정답일때, 모델이 만약에 near라고 예측한다면 near의 단어의 뜻이 infront of를 내포한다고 볼 수 있는데 이런 경우에는 어떤식으로 평가되는지 궁금합니다.
감사합니다.