오늘의 X-Review 또한 Temporal Sentence Grounding in Videos(TSGV) task 방법론으로 가져왔습니다. 23년도 AAAI에 게재되었으며 중국 북경대의 연구 결과입니다.

최근 연구실 전체적으로 제안서 작업이 한창인데요, 저희 팀에서도 OTT 플랫폼에 적용할 수 있는 TSGV를 하나의 요소 기술 삼아 관련 제안서를 작성하고 있는 상황입니다. TSGV 연구 동향 파악을 위해 서베이 하던 중, 저희가 TSGV를 실제 사용자 관점의 서비스로서 제공한다면 무엇이 문제일지 고민했던 포인트들이 몇 가지 있었는데 본 논문이 그 중 한 가지에 대해 잘 짚고있어 리뷰로 남기게 되었습니다.
저희가 짚은 포인트는 무엇이고 본 논문에서 이를 어떻게 해결하는지 천천히 알아보겠습니다.
1. Introduction
개인적으로 TSGV 연구가 산업계 레벨에서 잘 구현된다면, 저희 팀에서 다루던 어떠한 비디오 관련 task보다 가장 실생활과 밀접할 것이라고 생각합니다. 연구원분들 대부분 유튜브를 매일 이용하실텐데요, 알고리즘에 의해 추천되는 비디오를 보는 경우가 대부분일 수 있지만 가끔은 이전에 재밌었던 비디오를 검색해서 보거나 특정 목적을 가지고 원하는 비디오를 검색해야 하는 상황이 오기도 합니다.
여기서 검색이라고 하면, Text-to-Video Retrieval, 즉 text를 입력으로 주었을 때 이에 가장 적합한 비디오를 결과로 표시해줍니다. 하지만 TSGV가 서비스 레벨로 잘 구현된다면 text를 기반으로 더 나아가 하나의 비디오 내 구간을 검색할 수 있게 됩니다. 아직 사용자 관점에서는 어디에서도 볼 수 없는 기술이고, 방송국에서 이전에 방영되었던 자료화면을 텍스트 기반으로 검색할 데이터베이스가 구축되어 활용되는 상황입니다.
이렇게 잘 구현된다면 응용력이 무궁무진한 task인데, 왜 아직 서비스로 적용되지 않고 있는지는 정확히 모르겠습니다만, 이에 대해 저희가 고민해 본 여러가지 포인트 중 한가지는 데이터셋의 텍스트 쿼리와 실제 사용자들이 던지는 텍스트 쿼리의 차이가 있다는 점입니다.
이는 또 두 가지 관점에서 나누어 볼 수 있는데, 첫 번째는 데이터셋 쿼리에 존재하는 단어 분포입니다. 학계에서 사용되는 데이터셋의 텍스트 쿼리에는 특정 동사 위주로 과도하게 편향되어 분포합니다. 전체 텍스트 쿼리의 품사를 분석하였을 때 상위 30개의 동사만으로 ActivityNet Captions 데이터셋에선 전체 action의 52.9%, Charades-STA 데이터셋에서는 무려 92.7%를 커버할 수 있도록 구성되어있다는 연구 결과가 존재합니다. 물론 실제 사용자가 던지는 쿼리 또한 단순한 단어들 위주로 분포할 확률이 높겠지만, 위와 같은 데이터셋으로 학습한 모델이 일반성을 가진다고 이야기하기는 어렵겠죠.
두 번째 포인트는 쿼리 문장 자체의 형식입니다. 학계에서 사용되는 데이터셋의 텍스트 쿼리는 전문 annotator들이 비디오를 보고 생성한 것인데, 이는 대부분 문어체로 작성되어있습니다. 하지만 사용자들이 grounding을 위해 던지는 문장에는 문어체 뿐만 아니라 구어체나 심지어는 오타 등의 비문도 많이 포함되어 있을 것입니다. 마찬가지로 실세계에 적용되기엔 아직 어려운 실정이겠죠.
여기서 저자는 두 번째 포인트를 지적하고 있습니다. 기존 방법론들은 첫 번째에 해당하는 단어 분포 편향만을 다루고 있지만, TSGV 기술이 상용화되기 위해선 두 번째 포인트 또한 간과해서는 안된다는 것이죠. 제안서에 들어갈 내용을 모두 정리한 뒤 이것이 해당 연구에서 지적한 문제점과 꽤나 일치하는 것이 소름이 돋았습니다..
빙금 정의한 문제에 대해 조금 더 정량적으로 살펴보겠습니다.
사실 저자가 두 번째 포인트에 대해 모두 고려하고 있는 것은 아니고, 조금 결이 다르긴 합니다. 사용자들이 불완전한 문장을 던지는 상황에 대해 더욱 대비하고자 하는데요, 불완전한 문장이라 함은 완전한 문장에서 명사나 동사 일부들만 떨어져 나와있는 상태를 의미합니다. 이는 “Phrase”라고 칭할 수 있겠죠. 따라서 저자는 문제 증명을 위해 phrase-level prediction에 대한 실험을 진행하였습니다.
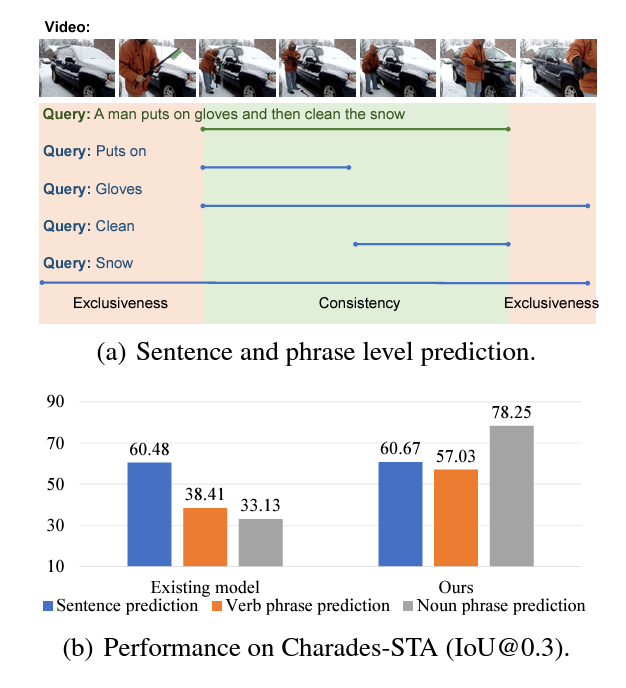
위 그림 1-(a)를 통해 phrase는 문장 내 존재하는 phrase, 즉 명사와 동사(‘Puts on’, ‘Gloves’, ‘Clean’, ‘Snow’)를 확인할 수 있고 전체 문장이 아닌 phrase만을 입력으로 주었을 때 모델이 찾은 구간의 성능을 측정해봅니다. 그림 1-(b) 왼쪽 표를 보면, 기존 방법론은 동사 phrase, 명사 phrase를 주는 경우 각각 성능이 22.07%, 27.35% 하락하는 것을 볼 수 있습니다. 이는 굉장히 큰 하락폭이라고 볼 수 있죠. 반면, 저자의 방법론은 동사 phrase에서 적은 하락폭과 명사 phrase에서의 큰 성능 향상을 이루는 것을 볼 수 있습니다. 물론 파란색으로 표시된 sentence prediction 성능이 기존 베이스라인에 비해 크게 오른 것은 아니지만, phrase-level prediction의 성능을 크게 향상시켰다는 것이 실용적 관점에서 TSGV를 바라보았을 때 큰 기여를 한 것이라고 생각되네요.
Introduction에도 세세한 설명들이 있지만 방법론에서 알아보기로 하고, Contribution을 정리하겠습니다.
Contribution
- We highlight the importance of phrases in video temporal localization and exploit the temporal relationship relevant to phrases and the whole sentence
- We propose phrase-level Temporal Relationship Mining(TRM) framework to investigate phrase-level prediction using sentence-level supervision only
- Experiments on Charades-STA and ActivityNet Captions demonstrate our method’s ability to improve phrase-level performance while performance in sentence-level setting remains stable, achieving better generalization performance
2. Method
본격적으로 저자의 방법론을 설명하기 전 Related Work에 명시된 기존 연구에 대해 짧게 정리하겠습니다.
TSGV에 phrase-level feature를 고려한 연구가 아예 없었던 것은 아닙니다. 하지만 기존 방법론들은 phrase-level이라 하기엔 미약한 local feature 또는 sub-query feature 정도를 모델링하는 수준이었습니다. 명사나 동사로 정확히 나눈 단위의 feature를 사용한 것이 아니었던 것이죠. 그리고 이후에 이야기하겠지만, 본 방법론에서는 phrase-level로 구간 예측을 수행하며 이 예측값을 sentence level 예측 refinement에 활용하기도 합니다. 하지만 기존에는 이렇게 명시적으로 phrase-level feature를 활용하는 연구는 없었습니다.
Overview
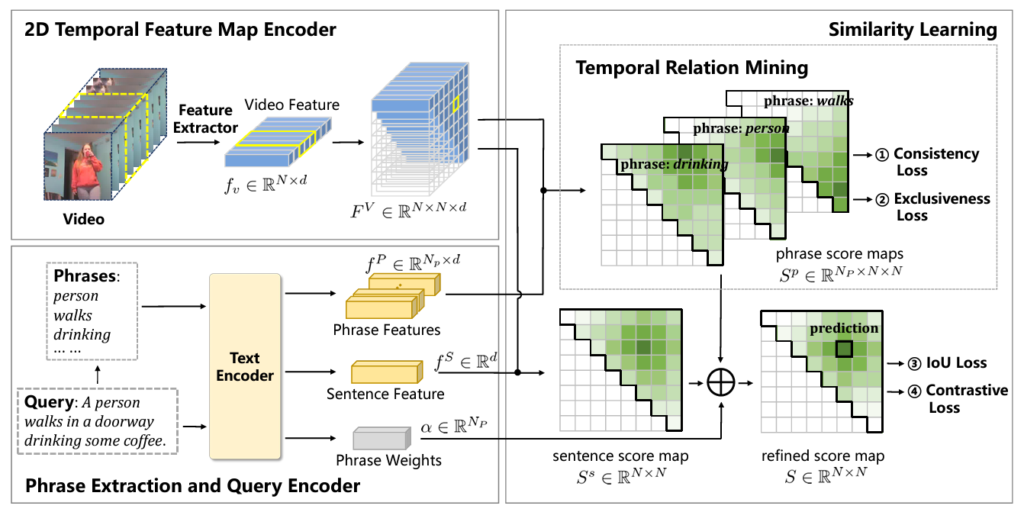
그림 2를 통해 저자가 본 논문에서 제안하는 Temporal Relationship Mining (TRM)의 전체 파이프라인을 볼 수 있습니다.
Model Architecture
우선 비디오 encoder의 역할은 입력받은 비디오를 클립으로 쪼개고, clip-level의 feature를 추출합니다. 데이터셋마다 다르지만 VGG 또는 C3D를 사용합니다. 이렇게 얻은 N개의 특징 \{f_{i}^{V}\}_{i=1}^{N} \in{} \mathbb{R}^{N \times{} d}으로부터 다시 2D proposal feature map F^{V} \in{} \mathbb{R}^{N \times{} N \times{} d}까지 추출해줍니다. 해당 map의 i, j번째 원소 F_{i, j}^{V} 값은 i번째 클립이 시작 지점, j번째 클립이 끝 지점인 구간이 실제 구간일 확률을 의미합니다. 후에 여기에 text query feature를 곱해주어 쿼리에 상응하는 구간 확률을 구할 수 있습니다.
TRM의 핵심은 text 쿼리 모델링입니다. 우선 그림 1에서 본 것과 같이 문장 전체에서 유의미한 명사, 동사인 phrase를 추출해야겠죠. 저자는 문장으로부터 N_{p}개의 phrase [p_{1}, p_{2}, \cdots{}, p_{N_{p}}]를 추출하기 위해 사전학습된 SRLBERT를 사용하였습니다. 쿼리 문장과 이로부터 얻은 phrase들의 feature를 추출하는 데에는 DistillBERT를 사용하였습니다. Sentence feature는 f^{S} \in{} \mathbb{R}^{d}, phrase feature는 f^{P} \in{} \mathbb{R}^{N_{p} \times{} d}로 표기됩니다.
Similarity Learning Module
앞서까지는 단순히 feature 추출 과정이었고, TRM의 모든 핵심 모듈은 본 절에서 언급됩니다.
TSGV에선 두 모달 간 interaction도 중요하지만, 저자의 의도에 맞게 TRM은 추출한 sentence feature와 phrase feature 간 interaction에 집중합니다.
Score Map Generation
앞서 이야기한 바와 같이 두 모달이 모두 고려된 similarity map을 만들어주기 위해 우선 두 feature의 차원을 맞춰줘야 합니다. 이는 아래 수식 1과 같이 수행됩니다.
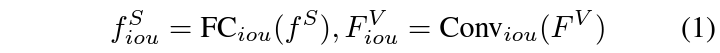
Text feature는 FC layer, 비디오 feature는 1D Conv를 타고나와 각각 f_{iou}^{S} \in{} \mathbb{R}^{d^{H}}, F_{iou}^{V} \in{} \mathbb{R}^{N \times{} N \times{} d^{H}}로 임베딩됩니다. 이후에는 두 모달의 feature 간 유사도 map S^{S} = F_{iou}^{V}f_{iou}^{S} \in{} \mathbb{R}^{N \times{} N}를 얻어줍니다. 정규화 과정은 명시되어있지 않지만 cosine similarity라고 하네요. 이제 S^{s}_{i, j}의 i, j 원소는 비디오-text 간 상응할 확률값이겠네요.
Temporal Relation Mining
여기까지는 sentence-level의 유사도만 고려되었고, 이제 TRM의 main contribution인 phrase-level feature를 고려해줄 필요가 있습니다. 이 때 문제는 phrase-level의 temporal annotation이 없다는 것입니다. 전체 문장에 대한 temporal annotation은 있지만 한 동사나 명사가 정확히 어느 구간에 상응하는지에 대한 정보는 없죠. 그래서 저자는 몇 가지 가정을 통해 phrase-level prediction에 대한 constraint를 주게 됩니다. 두 가지 가정은 아래와 같습니다.
- consistency
- 문장 GT 구간에 해당하는 영역에는 반드시 N_{p}개의 phrase-level prediction이 최소 한 클립씩이라도 모두 activate 되어야 합니다.
- 매칭되지 않는 문장과 비디오(배치 내 다른 pair를 의미)의 GT 구간을 보았을 때, 해당 GT 구간에서는 절대 모든 phrase가 동시에 activate 되면 안됩니다.
- exclusiveness
- 매칭된 문장-비디오 쌍에서 GT 구간이 아닌 영역에서는 절대 모든 phrase가 동시에 activate 되면 안됩니다.
이렇게 크게 두 가지 constraint를 두었고, 설명에서 activate라는 단어가 실제로 쓰이진 않았지만 이는 대략 tIoU가 특정 threshold \theta{} 이상이라는 의미입니다. 이 가정들을 loss로서 잘 표현해 학습하는 것입니다.
구체적으로, i번째 phrase feature f_{i, iou}^{P} \in{} \mathbb{R}^{d^{H}}를 수식 (1)에 적용하면 phrase에 대한 비디오와의 유사도 map S_{i}^{p}를 얻을 수 있습니다. 이 S_{i}^{p}를 이용해 consistency loss를 계산하고, 배치 내 다른 query를 랜덤으로 하나 가져와 동일한 방식으로 \hat{S}_{i}^{p} 또한 얻어줍니다. 이를 이용해 exclusiveness loss를 계산해주는 것입니다.
Loss를 구축하기 위해 먼저 threshold \theta{}에 따른 영역을 정의해줍니다. 이는 아래 그림 3과 같습니다.
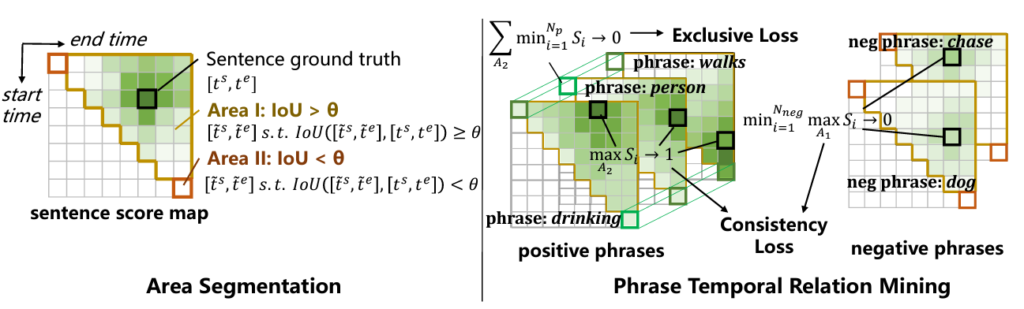
그림 3에서 왼쪽 부분을 보면 되는데, 우선 score map에서 대각선을 기준으로 좌하단은 시작 지점이 끝 지점보다 느려 존재할 수 없는 proposal 영역이기에 우상단만 고려합니다. 영역 1은 GT와의 tIoU가 \theta{} 이상, 영역 2는 \theta{} 이하인 영역입니다.
이를 토대로 앞서 정한 consistency를 먼저 따져보겠습니다. Consistency는 다시 두 가지로 구성되었는데, 첫 번째 목적부터 영역 1과 엮어볼 수 있습니다. 그림 3 오른쪽 검은 박스 쳐진 구간이 영역 1에서의 최대 score를 의미할 때 모든 검은 박스가 영역 1에 존재해야 합니다. 앞서 말씀드린 activate가 곧 영역 1에 포함됨을 의미하겠네요. 또한 두 번째 목적을 달성하기 위해 negative pair 간 유사도 map S_{i}^{p}의 영역 1에 존재하는 구간은 전체 phrase 중 하나라도 빠질 수 있도록 최대값들 중 최소값을 0에 가깝게 줄여줄 필요가 있습니다.
Exclusiveness와 관련해서는, positive pair 간 유사도의 영역 2를 살펴봅니다. 여기서는 모든 phrase-level prediction이 동시에 activate 되는 상황을 방지하고자 영역 2에 존재하는 값 중 최소값이 0에 확실히 가까워지도록 수식을 설계합니다.
결국 두 constraint를 모두 고려한 Consistency loss \mathcal{L}_{con}과 Exclusiveness loss \mathcal{L}_{ex}는 각각 아래 수식 (2), 수식 (3)과 같습니다.
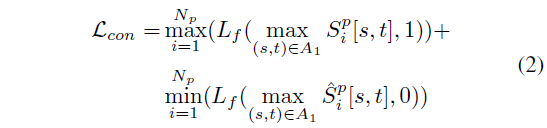
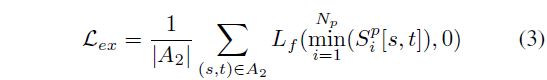
Sentence Score Map Refinement
TRM에서 얻은 fine-grained level의 phrase prediction이 sentence prediction S^{s}의 refinement에 도움을 줄 수 있다고 이야기합니다. 정제된 최종 score S \in{} \mathbb{R}^{N \times{} N}은 아래 수식 (4), 수식 (5)와 같이 얻을 수 있습니다.
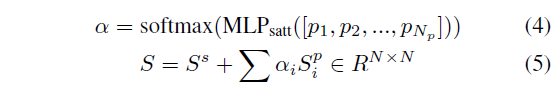
\alpha{}는 각 phrase의 중요도를 나타내는 attention weight에 해당하고, 이에 대한 attentive pooling과 residual 연산을 통해 최종 score map을 만들어주는 모습입니다.
최종 score map S를 얻었으니 가지고 있는 GT 라벨과 학습을 진행할 수 있겠죠. 이는 아래 수식 (6)과 같은 BCE Loss로 수행됩니다.
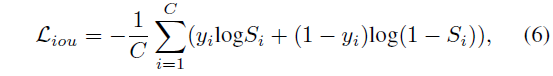
참고로 라벨값 y_{i}는 20년도 연구 2D-TAN의 방식을 따라 실제 GT만 1, 나머지는 0인 hard binary score 형태가 아니라, 아래와 같이 결정됩니다.
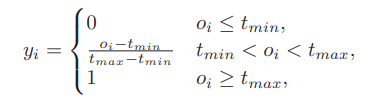
2D-TAN 논문에서 가져온 수식이다보니 notation이 좀 다른데, 먼저 o_{i}는 특정 구간과 GT의 IoU를 의미합니다. 그리고 t_{min}, t_{max}는 0~1 사이의 값으로 사전에 정의한 두 threshold입니다. 라벨 y_{i}는 결국 hard label이 아닌 실제 GT와의 IoU를 scaling하여 고려하는 형태라고 볼 수 있습니다.
Sentence-level Contrastive Learning
여기서는 기존 연구를 따라 간단한 contrastive learning이 수행됩니다. 이는 아래 수식 (7)과 같습니다.
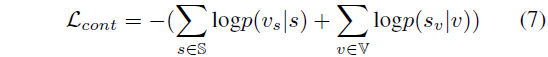
수식 (7)에서 v_{s}, s_{v}는 각각 서로의 positive matching pair를 의미하며, \mathbb{S}, \mathbb{V}는 각각 배치 내 존재하는 문장과 비디오 집합입니다. 일종의 배치 단위 NCE Loss에 해당하는 것입니다.
Training and Inference
최종 loss는 이전까지 언급한 loss들을 모두 더한 \mathcal{L}입니다.
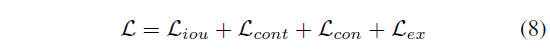
중요한 점은 phrase-level prediction에 대한 실제 annotation이 없음에도 문장으로부터 supervision을 잘 만들어냈다는 것이겠죠.
Inference 때는 수식 (5)와 동일하게 phrase-level prediction으로 refinement를 수행한 similarity map S를 사용하게 됩니다. 해당 map에서 score가 가장 큰 구간이 예측값으로 내뱉어질 것입니다.
3. Experiments
벤치마킹 데이터셋은 Charades-STA와 ActivityNet Captions를 사용합니다. TSGV에서 대표적으로 사용되는 데이터셋이며, 쿼리 하나 당 이에 상응하는 비디오 구간 또한 하나라는 특징을 가지고 있습니다.
평가지표는 R@1, IoU=m, m=\{0.3, 0.5, 0.7\}입니다. 즉 S에 존재하는 가장 큰 원소의 인덱스가 곧 최종 예측 구간을 의미하였는데, 해당 구간과 GT의 IoU가 m보다 커 TP로 고려되었을 때의 Recall 값을 의미합니다. 2D Map 방식 특성 상 여러 개의 proposal을 뽑아내기 어려워 R@1을 고려하는 것이겠죠. TP proposal들의 평균 IoU인 mIoU도 같이 리포팅하고있습니다.
Feature 추출을 위한 backbone의 경우 Charades-STA는 VGG, ANet은 C3D를 사용했습니다. Text encoder는 앞서 언급한 바와 같이 DistillBERT를 사용하였습니다. DistillBERT는 학습 중 freeze 되지 않는다고 하네요.
Evaluation for phrase
데이터셋과 평가지표에 대해 간단하게 설명드렸고, 특히 TRM에서는 phrase-level prediction을 생성했기에 이에 대한 정량적 평가도 진행되는 것이 논리적으로 보입니다. 기본적으로 sentence-level feature와 phrase-level feature는 동일 text encoder로부터 추출되기 때문에 위에서 이야기한 것과 동일한 흐름으로 예측값을 만들어내는 것이 가능한 상황입니다. 하지만 데이터셋에는 어디까지나 문장 단위의 GT 구간만 존재할 뿐 추출해낸 phrase-level의 GT 구간은 없어 평가가 어려운 상황입니다.
Phrase-level GT는 noun과 verb로 다시 한 번 나뉠 수 있는데, 저자는 verb GT 구간을 얻기 위해 Temporal Action Localization의 GT 구간을 차용해옵니다. Action 클래스 명에 대한 TAL task 데이터셋의 GT 구간을 동사 phrase의 GT로 삼는다는 것입니다. 또한 noun GT 구간은 Charades-STA 데이터셋에 존재하는 object의 등장 구간을 활용합니다. 이렇게 noun, verb에 대한 GT 구간을 얻었다면 이에 대해 기존과 동일한 평가지표를 적용할 수 있을 것입니다. 해당 성능은 벤치마크 표에서 함께 리포팅하고 있습니다.
Comparison with Other Methods
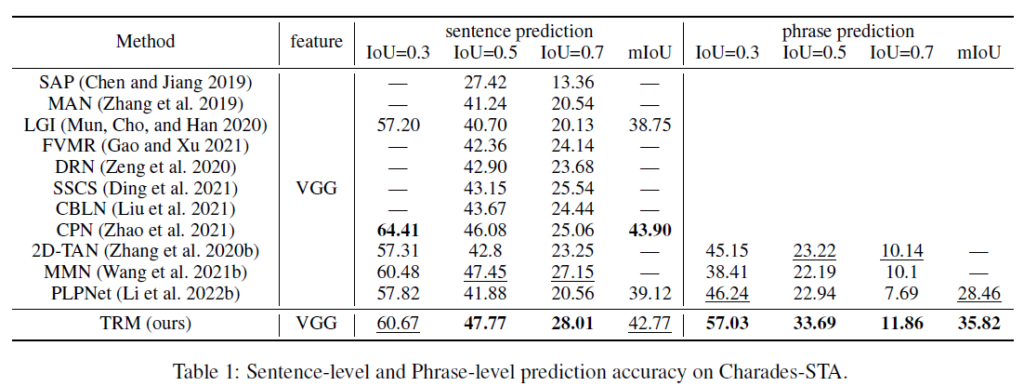
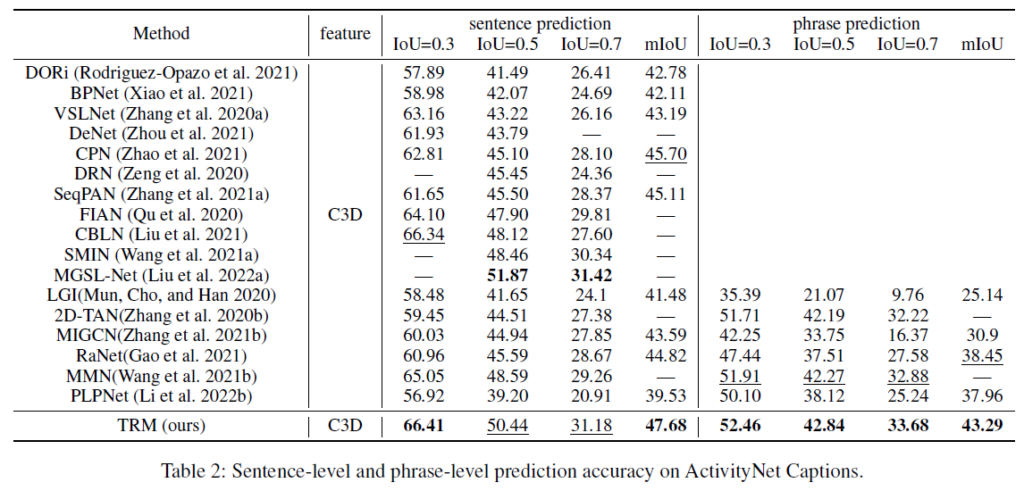
표 1, 2는 각 데이터셋에 대한 벤치마크 표입니다.
학계에선 데이터셋에 따라 다른 backbone을 사용하는데, fair comparison을 위해 동일 backbone을 사용한 방법론들과 비교하고 있습니다. Introduction의 그림 1에서도 말씀드렸듯 본 방법론이 sentence-level prediction에 대한, 즉 TSGV task 자체의 성능을 크게 올렸다고 보긴 어렵습니다. 하지만 실세계에 TSGV가 적용될 때 사용자들의 자유롭고 불완전한 입력을 무시할 수는 없는 상황인데, 그러한 관점에서 task를 바라보았을 땐 TRM의 phrase prediction 성능 향상이 충분히 유의미하다고 생각합니다.
이렇게 일반성에 관련된 맥락으로 contribution이 흘러가고 있는데, 이와 관련된 추가 실험을 하나 더 살펴보겠습니다.
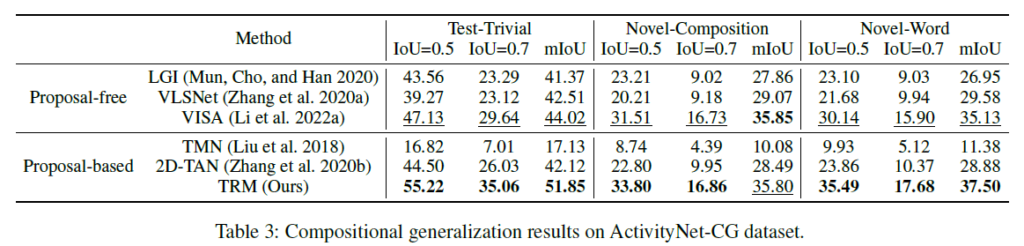
이전 연구에서 ActivityNet Captions 데이터셋에 존재하는 편향 문제를 지적한 적이 있습니다. 이를 데이터 관점에서 해결하고자 ActivityNet Captions 데이터셋의 composition을 섞어 ActivityNet CG(Compositional Generalizability), 이에 대한 성능을 측정함으로써 모델의 일반성을 좀 더 명시적으로 평가할 수 있게 만든 것입니다. CG 데이터셋은 training, novel-composition, novel-word, test-trivial이라는 네 가지 split으로 나뉘게 되는데, 이에 대한 자세한 설명은 기존 연구의 논문을 참고하시거나 질문 주시면 답변 드리도록 하겠습니다. 결과적으로 모델이 학습 때 보지 못했던 문장 내 단어 또는 phrase에 잘 대응할 수 있는가에 대해, 기존 모델들보다 일반성 있는 성능을 보이고 있습니다.
Ablation Studies
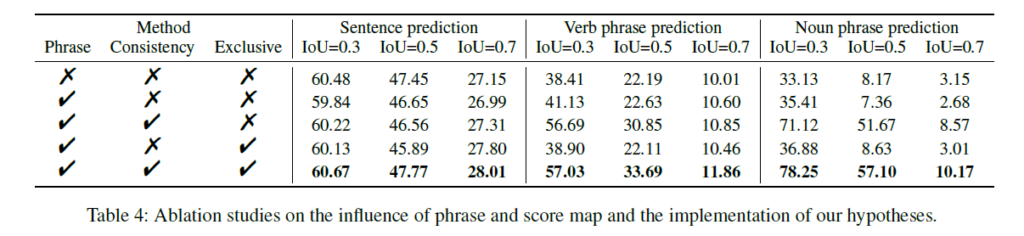
표 4는 구성 요소 별 ablation 성능입니다. Introduction의 그림 1에서 보았던 것과 같이, 문장 예측보다는 phrase 예측에서 기존 방법론들이 제대로 짚고 있지 못하던 점에 대해 좋은 성능을 보이는 것이 인상깊습니다.
Qualitative Results
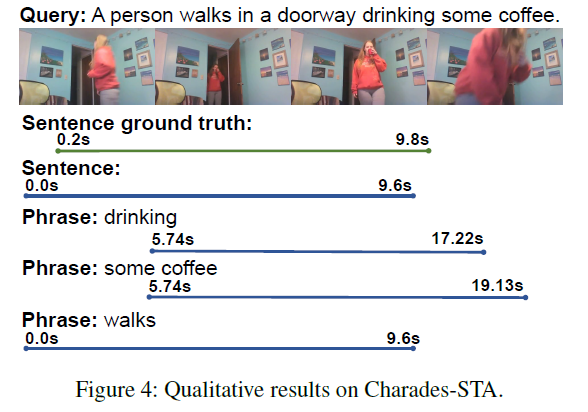
마지막으로 정성적 결과입니다. 문장 단위의 예측을 정확히 하였지만, 더욱 놀라운 것은 명사의 등장 시기나 동사의 실행 시기가 꽤나 잘 맞아 떨어진다는 점입니다. 그래서 체리피킹이 아닌가, 싶었는데 저 여자가 커피를 마시는 비디오가 왜인지는 모르겠지만 꽤 많은 TSGV 논문의 정성적 결과로 뽑혀 등장하고 있기에 믿을 만한 결과라고 생각됩니다.
Conclusion
개인적으로 저저가 설정한 두 가지 constraint인 consistency와 exclusiveness는 타당하였지만, 이를 구현하는 방식을 조금 더 고도화하여 더욱 다양한 constraint를 줄 수 있을 것 같기도 하고, 문장 내 phrase의 의미론적 관계는 명시적으로 고려되지 않았으며 왜 2D Map 방식을 선택했는지에 대한 설명이 없어 조금 아쉬움이 남긴 합니다. 사실 가장 크게는, 끌어 올린 phrase-level prediction을 토대로 sentence-level prediction의 성능까지 올려줄 수 있었다면 좋았을 것 같네요.
이상으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요. 김현우 연구원님.
좋은 리뷰 감사합니다.
성능 향상이 크지 않음에도 phrase에 대한 일반화 성능이 다른 모델에 비하여 크다는 것을 추가 실험으로 보이고 contribution으로 인정받은 것이 인상적이네요.
그림 3 부분이 약간 이해하기 어려운데요. 그림에 있는 각 map들이 어떤 phrase에 대응되고 map 속 각 pixel이 영상 속 s~e 구간에 해당하는 것으로 이해하였는데, threshold 이상의 IOU를 가진 영역1이 map의 좌하단과 끝단 픽셀 2개를 제외하고 모든 영역에 해당하는데 이는 단순히 예시이기에 그런 것이고, 실제로 threshold 이상의 IOU를 갖는 영역은 저 map에서 일부에 해당하는 것이 맞을까요?
감사합니다!