
안녕하세요, 이번에도 6D pose estimation 관련 논문입니다.
6D pose 데이터셋을 구축하기 위해 계속해서 새로운 데이터셋 논문들을 팔로우업하고 있는데요. 이제 작성 중인 국문 논문을 마무리 하는 과정에 있습니다. 이번 논문을 읽으면서도 문제를 정의하는 부분이나 고찰하는 부분을 중점으로 읽었네요. 아무래도 벤치마크 데이터셋이므로 새로운 평가지표를 제안하는 데이터셋들이 많네요. 평가지표에 대한 개선을 하기 위해 수식적으로 이해가 잘 안돼서 어려움을 겪었지만 새로운 지표를 제안하려면 개선하려는 문제를 수식으로 어떻게 녹여낼 것인지도 중요한 것 같네요.
리뷰 시작하겠습니다.
1. Introduction

카메라를 이용한 비전에서는 3D cue를 활용하여 물체에 대한 pose을 추정하는 것은 여러 분야(AR, manipulator)에서 매우 중요한 부분입니다. 하지만 투명하거나 반사가 잘되는 물체에 대한 pose를 추정하는 것은 여전히 어려운 문제인데요. 이때 최근까지도 계속 나오고 있는 RGB-D 센서나 LiDAR에서 depth를 뽑을 때 사용하는 방식인 TOF(Time of Flight) 또는 Projected light 방식은 특히 문제가 되는 물체들에 대해서 여전히 어려움을 겪고 있습니다. 이러한 문제점들로 인해 mono로 사용하는 RGB-D에 대한 depth는 신뢰할 수 있는가? 에 대한 문제점을 해결하고자 하는 것이 이번 데이터셋 논문의 문제 정의라고 할 수 있겠습니다.
최근 논문들의 트렌드는 많은 데이터를 확보하여 성능을 개선시키는 것도 contribution 중 하나인데요. 딥러닝과 같은 학습을 진행하려면 데이터 양으로도 성능을 개선할 수 있는 게 사실이긴 합니다만 6D pose 에서 사용하는 합성 방법은 주로 렌더링 기반의 합성을 사용하므로 전문적으로 사용하는 렌더링 도구를 사용하는 게 까다롭긴 하죠. 합성 데이터를 사용하게 되면 여전히 서로 다른 도메인에 대한 gap 차이가 존재하는 문제가 있습니다.
이러한 문제들을 저자는 multi-view 기하학을 기반으로 마커보드, 카메라, 물체에 대한 keypoint를 정확하게 찾아내는 파이프라인을 구성하여 데이터셋을 구축합니다.
2. Data Capturing & Labeling Pipeline
3차원에 존재하는 물체에 대한 포즈를 추정하기 위해서는 취득한 데이터를 바탕으로 annotation이 필요하게되는데요. 저자는 기존의 데이터셋들에 대한 한계점을 먼저 지적합니다.
Sensor Modality
- monocular RGB-D만을 3D cue로 사용
- Depth를 잘 뽑지 못하는 투명하거나 반사되는 물체를 처리하지 못함
- IR, LiDAR와 같은 depth를 뽑는 방법은 서로 다른 depth 결과를 도출함
이러한 센서 측면에서 저자는 RGB-D 기반의 데이터셋에서 학습한 어떤 모델이 만약 다른 방법으로 depth를 뽑을 경우에는 학습이 어려울 수 있기 때문에 일반화에 대한 한계점을 언급합니다.
Data Annotation
기존의 annotation 방법은 일반적으로 3D 포인트 클라우드에 해당하는 3D 모델을 이용하여 수동으로 align을 맞추는 경우가 대부분입니다. 하지만 이러한 방법은 데이터가 많아질수록 시간적인 비용이 많이들 수 밖에 없으며 정확성이 떨어진다고 합니다. 기존의 데이터셋들은 많아 봤자 1만장 이내로 제공하기 때문에 딥러닝 기반의 학습 데이터가 부족하다는 것을 지적합니다. 물론 렌더링을 통한 합성 데이터를 사용하는 방법이 대안이 될 수는 있겠지만 서로 다른 도메인에 대한 갭 차이는 여전히 문제로 다루고 있기 때문에 적절한 대안이 아니겠네요.
Scene Environment
기존의 데이터셋들은 indoor scene을 주로 다루기 때문에 실제 환경에 대한 다양성이 부족한 것을 지적합니다. 주로 이러한 환경에 대한 문제를 지적하는 내용은 조도에 대한 문제와 반사가 잘 되는 물체에 대한 문제를 푸는 것을 지적하는데 해당 논문 또한 그런 내용들을 다루고 있습니다.
2.1. Data Capturing and Labeling
위와 같은 문제들을 풀기 위해 먼저 monocular RGB-D 센서가 아닌 stereo RGB를 사용했다고 합니다. 라벨링의 경우 IR, LiDAR와 같은 센싱 기술을 이용하여 depth를 뽑는 것이 아니라 Multi-view 기하학을 사용하는 것이 저자만의 철학이라고 하네요. 이제 본격적으로 해당 데이터셋의 취득 방법과 라벨링을 어떻게 진행했는지 알아보도록 하겠습니다. 100만개의 라벨링이라니 벌써부터 궁금하네요.
전체적인 파이프라인은 7단계로 구성되어 있습니다.
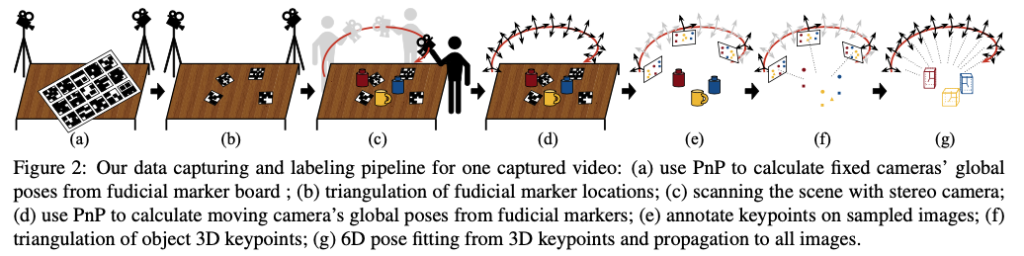
1. Pose Calculation for Static Cameras
고정된 2개의 카메라를 사용합니다. 이때 카메라 포즈를 얻기 위해 그림(2)(a)와 같이 어떤 마커보드를 배치하고 해당 마커보드가 2개의 카메라에 보이도록 합니다. 그럼 각각의 카메라에 대한 world coordinate가 나올텐데, 이때 PnP 알고리즘을 사용하여 카메라의 pose를 계산합니다.
2. Triangulation of Fiducial Markers
앞서 사용했던 마커보드를 제거하고 다른 종류의 마커 몇 개만 올려놓고 이전 스탭과 동일하게 카메라는 정적인 상태로 record를 진행하는데 이때 이전 스탭과 다른 점은 Triangulation을 적용하여 3차원 위치를 좀 더 정밀하게 찾는 것입니다.
3. Scene Construction and Scanning
장면에 대한 구성을 하기 위해 이때 물체를 놓고 카메라를 움직이면서 장면에 대한 스캔을 할 수 있지만 이때 이전 스탭에 구성된 마커 위치는 절대 변경되면 안됩니다. 스캔하는 경로로 가능한 한 많은 시점을 커버할 수 있도록 구성하는 것이 좋다고 합니다.
4. Pose Caculation for moving camera
앞서 고정된 마커의 위치를 활용하여 움직이면서 촬영했던 카메라에 대한 pose를 계산하기 위해 PnP 알고리즘을 다시 한 번 사용합니다. 이때 해당 알고리즘의 error를 줄이기 위해 마커가 2개 이상 나오는 경우와 8개의 corner가 나오는 경우만 취득 데이터로 사용하게 됩니다.
5. Keypoint Annotation
스탭4에서 얻은 영상들은 데이터로 사용하기에 적절한 프레임들로 구성되어 있으므로 해당 프레임 중에 몇 개를 선택하면 이미지 위에 투영된 물체의 3D 모델에 대응되는 2D keypoint를 찾을 수 있습니다. FPS를 사용하여 비교적 쉽게 keypoint를 정확하게 찾을 수 있지만 특정한 프레임에서만 전체 키포인트 중에 일부만 annotation을 할 수 있다고 합니다.
→ 해당 부분에 대해서는 정확하게 이해가 잘 되지 않네요.. 연속적인 부분에 대해서 keypoint를 잘 찾는 것이 어렵다는 의미로 이해했습니다.
6. Keypoint Triangulation
스탭5에서 얻은 keypoint에 대한 annotation이 존재하는 프레임을 찾아서 움직이는 카메라의 pose와 2D keypoint를 사용한 triangulation을 계산합니다.
7. Pose fitting
마지막으로 물체의 6D pose를 얻기 위해 Orthogonal Procrustes problem라는 것을 이용하여 3D 모델을 3D keypoint에 맞춰주고 물체의 pose는 카메라 pose의 inverse 변환을 통해 모든 프레임에 적용할 수 있다고 합니다.
Orthogonal Procrustes problem: 두 개의 행렬 간 최적의 rotation을 찾는 것이 목적이며, align을 맞추는 역할을 함.
\min_{R}||A-BR||_{F}주어진 두 행렬 A와 B가 있을 때, 식을 만족하는 Orthogonal 행렬 R을 찾는 것입니다. 이때 ||\cdot||_{F}는 Frobenious norm으로 행렬에 대한 norm의 계산 방법 중 하나이며, 행렬의 각 원소를 제곱하여 모두 더하고 마지막에 sqrt를 계산하는 norm입니다.
3. StereOBJ-1M Dataset

앞서 설명했던 파이프라인을 통해 대규모 데이터셋을 구축했는데요. 해당 데이터셋은 스테레오 카메라만을 사용하므로 단일 RGB 영상만을 제공하는 벤치마크 데이터셋입니다.
3.1. Objects in Dataset
해당 데이터셋에는 총 18개의 물체들로 구성되어있습니다. 그 중에 10개(그림(3)(i) ~ (r))는 바이오케미컬 분야에서 사용되는 플라스틱 기구들로 이루어져있으며, 나머지 8개는 공구로 구성되어 있는 것을 확인할 수 있습니다. 해당 물체들을 보면 앞서 저자가 지적한 기존의 물체들의 구성에 대한 한계인 투명하거나 반사가 잘 되는 물체들도 구성한 것을 볼 수 있네요. 해당 논문에서 사용한 스캐너는 EinScan Pro 2X Plus 모델인데 찾아보니 약 1000만원이 조금 안되는 모델이었습니다. 저희가 업체에 맡긴 스캐너의 가격은 찾아보니 1억정도 하는 모델이네요.. 1000만원 스캐너로도 저런 퀄리티가 나오는구나 생각이 들었습니다. 반사가 심한 메탈 재질들에 대해서는 흰 스프레이를 뿌려서 스캔을 진행했다고 합니다.
이번 데이터셋은 T-LESS 데이터셋의 컨셉과 비슷하게외관적으로는 비슷하지만 실제로는 다른 물체들로 구성한 것이 특징이라고 볼 수 있습니다. 여기서 저자는 비전쟁이들이 ‘그럼 니 말대로 외관적으로 너무 비슷하게생겼어. 근데 실제로는 다른 건 어떻게 할 건데?’ 라는 질문에 대해서 이번 데이터셋으로 하는 앞으로의 연구가 질문에 대한 답변이 될 것이라고 이야기 합니다.
3.2. Data Collection And Annotations

이전 섹션에서는 해당 데이터셋에서 어떤 물체들이 어떻게 구성 되어있는지 알아봤었습니다. 이번 섹션에서는 데이터셋을 어떤 환경에서 취득을 하였는지에 대해 알아보겠습니다.
총 8가지의 실제 indoor 환경에서 데이터를 취득했으며 indoor 환경 외에도 배경에 대한 풍부함을 주기 위해 outdoor 환경에 대해서도 추가적으로 진행하였다고 합니다. 각 환경에 대해선 occlusion과 clutter를 주도록 scene을 구성하여 총 183개의 시퀀스로 구성되어 있으며 시퀀스마다 2분~7분 정도의 길이로 되어 있어 15프레임으로 샘플링하여 총 396509장을 생성했다고 합니다. 이처럼 그림(6)과 같이 데이터셋의 annotation은 물체에 대한 6D pose이므로 이를 통해 mask, 2D/3D bbox, normalized map을 생성할 수 있다고 하네요.
3.3. Benchmark and Evaluation
Train/Validation/Test split.
해당 데이터셋에서의 평가 데이터에는 대부분의 환경을 포괄적으로 구성하여 물체가 다양한 환경에서 구성되어 진행합니다. 학습 데이터로 사용되는 이미지들은 대규모의 데이터를 사용하게 되므로 합성 데이터를 따로 만들지 않아도 되므로 렌더링을 추가적으로 진행하지 않았지만 향후 데이터셋을 사용하는 사람들을 위해 선택적으로 합성 데이터를 사용할 수 있도록 했다고 하네요.
Evaluation Metrics.
단순하게 6D pose에 대한 ADD/ADD-S를 사용하여 성능을 측정합니다.
4. Experiments
4.1. Baseline Methods
해당 논문에서는 6D pose estimation에서는 나온지 꽤 된 방법론이지만 여전히 성능 비교를 위해 사용되고 있는 PVNet과 KeyPose를 사용했다고 합니다. 이 둘의 공통점은 keypoint 기반의 방법론이라는 점입니다. 간단하게 각각의 방법론에 대해 알아보겠습니다
PVNet
단일 RGB 영상을 이용하는 keypoint 기반의 방법론으로, 2D direction field를 사용하여 keypoint를 representation하게 되는데, 이때 RANSAC 기반의 voting 방식으로 2D에서의 keypoint를 추정합니다.이때 6D pose는 PnP 알고리즘을 적용하면 알 수 있습니다.
KeyPose
해당 방법론은 처음 보는 방법론인데요. stereo 기반의 RGB 영상을 사용한 keypoint 기반의 방법론입니다. 앞서 설명드린 PVNet과 다른 점은 두 stereo 이미지에 대한 히트맵을 예측하여 좀 더 정밀한 물체의 keypoint를 찾는 방식이라고 합니다. 해당 방법론에서 최종적으로 사용하는 6D pose를 추정하는 방법은 이전에 데이터 취득 과정에서 6, 7과정을 적용하여 계산하게 됩니다.
4.2. Monocular Image Experiments
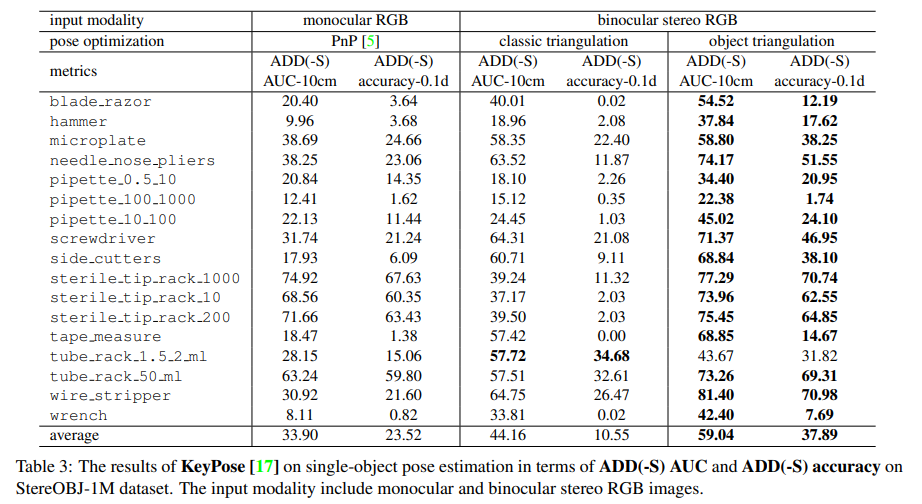
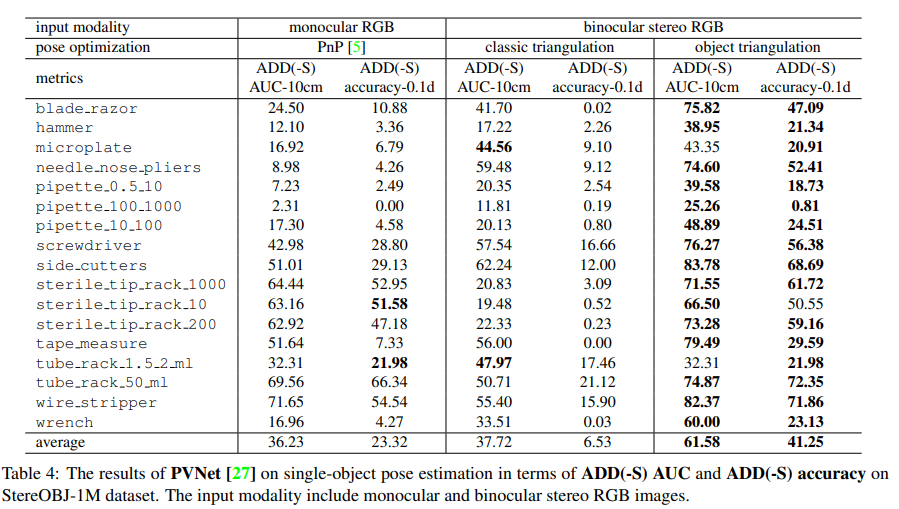
KeyPose에 대해서 stereo의 입력이 아니면 동작하지 않을 줄 알았는데 왼쪽 이미지만 입력으로 사용하여 monocular 이미지에 대한 실험을 진행할 수 있었다고 합니다. keypoint에 대한 히트맵을 사용하여 예측하고 마지막으로 PnP를 통해 최종적인 6D pose를 구합니다. 해당 결과는 표(3)의 1-2열을 참고하시면 될 것 같습니다. 성능면에서는 mono에 대한 성능면에서 비슷한 결과를 보면 특히 pipette 물체에 대해 매우 성능이 떨어지는 것을 확인할 수 있는데 이는 시각적으로 유사하지만 실제로는 서로 다른 물체의 pose를 추정하는 것이 실제로는 어려운 것임을 입증할 수 있는 결과입니다.
4.3. Stereo Image Experiments
여기서는 Stereo에 대한 성능을 뽑기 위해 PVNet에 개별적으로 예측된 keypoint에 대해 stereo에 맞게 조정이 된다고 합니다.triangulation 을 이용하면 두 카메라 사이의 기하학적인 관계를 이용하기 때문에 예측된 keypoint에 대해 3D 위치가 조정이 된다는 의미인 것 같네요.
두 stereo 이미지에 대해서 keypoint를 예측하고 최종적으로 6D pose를 계산하는 방법을 알아보겠습니다.
Classic Triangulation
stereo 이미지를 통한 3D 위치를 찾기 위한 triangulation 이후 앞서 계속 등장하는 Orthogonal Procrustes Problem(OPP)을 이용하여 물체에 대한 3D keypoint를 이용하여 pose를 계산하는 방법입니다.
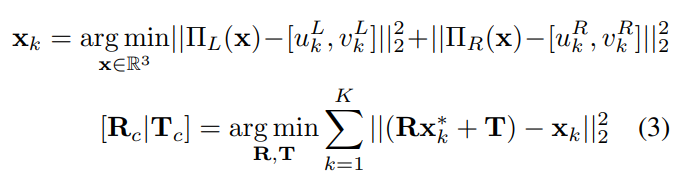
식(3)의 x_{k}가 triangulation을 진행한 k번째 3D 포인트의 위치를 나타냅니다. 최적화 과정인 OPP를 적용하기 위해 \Pi는 좌우에 대한 카메라에 대한 projection을 의미하며 여기서 예측된 2D keypoint를 각각 빼주어 최적화 과정을 진행하고 앞선 평가지표인 ADD에 따라 최종적으로 R, T값을 도출하게 됩니다.
Object Triangulation
저자는 triangulation에 대해 새로운 베이스라인을 제공하게 되는데요. 3D 포인트에 대한 위치를 최적화하는 OPP와 다르게 두 이미지에 대한 2D keypoint 예측 결과를 가지고 6D pose를 직접 최적화하는 과정을 적용합니다. 즉 앞서 (3)의 과정을 한 번에 진행한다는 의미인 것 같네요.
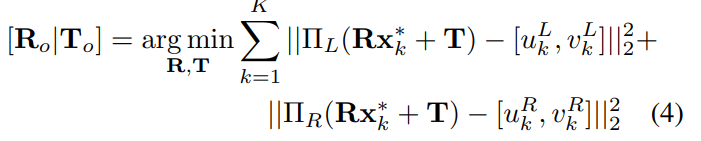
식(4)와 같이 한 번에 최적화를 진행하게 되면 표(3), (4)의 binocular 쪽을 보시면 성능이 classic 보다 크게 개선되는 것을 확인할 수 있었다고 합니다.
5. Conclusion
이번 논문에서는 stereo 기반의 카메라 기하학을 이용한 데이터 취득의 전체적인 파이프라인을 다루었으며 기존의 triangulation을 좀 더 개선하는 방법을 제안하는 것까지 주된 내용이었습니다. depth를 사용하지 않는 점에서 신박하다고 생각을 하였지만 대부분의 데이터셋과 또 다른 면모를 보여주는 논문이었습니다.
이상으로 리뷰 마치겠습니다.
감사합니다.
좋은 논문 리뷰 감사합니다.
몇 가지 질문 드리고 물러나도록 하겠습니다… ㅋㅋ
1. 기존 데이터 셋의 문제점이 다양한 환경으로 구성되지 못한 점을 지적했는데요… 촬영 환경으로 아웃도어 추가된 것이 끝인가요? 저자가 어떻게 어필하는지 궁금하네요.
2. 해당 데이터 셋의 파이프라인의 특성상 캘이 굉장히 중요해 보이네요. 이에 관련된 실험은 따로 없었나요?
데이터 셋 논문은 데이터의 신뢰를 주는 것이 중요하다고 생각해요. 그렇기에 해당 논문도 유사한 실험이 있었을 거라고 보입니다. 있다면 공유 부탁드립니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 어필하는 부분이라고 느낀 부분을 나타낸 게 본문에 작성 해놓은 것처럼 타 데이터셋은 전부 실내에서만 촬영을 진행해서 배경에 대한 다양성말고는 딱히 없었던 것 같습니다.
2. 캘리브레이션과 관련된 내용으로는 RMSE를 측정하는 것 정도가 있긴합니다. RGB-D 센서로 Azure Kinect의 depth map의 실제 에러율 정도가 1.7cm 이상이네요. 이걸 베이스로 잡고 multi-view geometry로 찾은 keypoint를 가지고 3D 모델에 대한 3D point(GT)의 라벨링 에러율 측정하는데 이때 0.23cm로 우세한 면모를 보여주긴 하는데 비교하는 내용이 다른 데이터셋 논문(TOD)에서 리포팅 된 성능을 제안한 데이터셋에 적용만 한 것으로 보입니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
파이프라인의 2번째 단계인 triangulation of fiducial markers에서 triangulation을 적용하여 3차원 위치를 좀 더 정밀하게 찾는다고 하셨는데, triangulation이 무엇인지 궁금합니다. pose optimization에 classic triangulation과 object triangulation이 써져있는데,,, 둘은 무슨차이인가요 ?
또, 4번째 단계에서 8개의 corner가 나오는 경우만 취득 데이터로 사용할 수 있다고 하셨는데, 이는 마커의 corner인가요 ???
마지막으로, 평가지표인 ADD와 ADD-S가 무엇인지 궁금합니다 ㅠ .. accuracy-0.1d에 d는 무엇인가요 ?
감사합니다 !!
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 먼저 triangulation 과정은 multi-view를 통해 Feature matching 된 어떤 포인트(2D)에 대해 3D 포인트를 찾는 과정입니다. 좀 더 정밀한 과정은 optimization인데요. 해당 부분이 OPP(Orthogonal Procrustes Problem)과정입니다. 이렇게 최적화까지하는 과정을 해당 논문에서 말하는 triangulation의 과정인 것 같고 classic이 기존의 OPP는 식(3)과 같이 첫 줄의 x_k를 구하고 pose를 구하는 것이고 이러한 방법보다는 바로 pose를 구하는 하나로 통합된 식(4)가 저자가 새롭게 제안한 pose를 구하는 방법입니다.
2. 넵 코너는 마커의 corner를 의미합니다. 최소 2개의 이상의 마커를 사용하므로, 마커는 사각형이니 4개의 corner*2 하여 8개의 코너를 사용한다고 표현한 것 같네요.
3. ADD는 예측된 pose와 예측된 pose에 대한 [R|t]의 차이를 계산하고 특정 threshold 내 에러율을 가지는 경우 옳은 pose로 계산하는 방식입니다.
ADD-S는 ADD의 변형이라고 생각하시면 될텐데, 대칭 물체인 경우 해당 메트릭을 적용하여 성능을 측정합니다. accuracy-0.1d의 d는 3D 모델의 diameter를 나타냅니다.
감사합니다.
좋은 리뷰 감사합니다 !!
리뷰와 관련하여 몇가지 질문이 있습니다.
1. 굉장히 많은 양의 데이터를 제공한 것으로 보이는데, keypoint annotation은 100만장의 이미지에 대하여 모두 진행하는 것인가요??
2. 기존 데이터 셋에 대한 한계를 지적하였다는 부분에서 ‘monocular RGB-D만을 3D cue로 사용’하는 것이 어떠한 문제인지 추가적으로 설명해주실 수 있을까요??
3. 해당 논문의 저자들이 라벨링 과정에는 ‘Multi-view 기하학을 사용하는 것이 저자만의 철학’이라고 하셨는데 혹시 이에 대한 이유는 따로 언급되어있지 않았는지 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 전체 시퀀스는 182개의 시퀀스가 존재하며 해당 시퀀스에는 39만장의 프레임이 존재합니다. 해당 프레임에 대해 18개의 물체에 대해 annotation된 게 총 150만개가 넘는다고 하네요. 해당 100만장으로 리뷰를 하여 혼동을 드렸네요. 내용 정정하였습니다.
2. 예를 들면 RealSense 455 하나만 사용한 경우라고 생각하시면 됩니다. 카메라는 하나인데 IR Projector 를 통한 depth를 뽑으니 monocular RGB-D입니다. 센서마다 다른 기법(IR/TOF)을 통해 depth를 뽑으니 이에 문제를 제기한 것입니다.
3. 철학이라고 표현을 한 게 제 생각에는 저자가 본문에 있는 파이프라인을 따로 만들어서 수행을 한 것은 아닙니다. 이미 존재하는 파이프라인을 그대로 사용하는 것으로 보이는데, 저자는 해당 파이프라인을 고수하려는 것처럼 보이긴 합니다만 선행 연구로 제안된 데이터셋 논문인 TOD에서 수행한 파이프라인과 흡사하며 해당 논문을 좀 많이 따라간 느낌이 있습니다. 철학이라는 말의 뒷받침으로는 depth를 뽑는 센싱 기술에 대한 문제점 언급 외에는 없습니다.
감사합니다.