안녕하세요, 이번에도 6D pose estimation을 위한 데이터셋을 구성하기 위해 데이터셋 논문을 읽어보았습니다. 이번 논문의 핵심은 GT pose를 구성하였을 때, 좀 더 정확한 GT pose 정보를 주기 위한 방법론을 제안하는 하였고, 해당 방법론을 적용했을 때 좀 더 정확한 GT pose를 제공했다 까지가 전반적인 내용입니다. 데이터셋 촬영을 진행하면서 이론적인 개념이 부족하다고 많이 느꼈습니다. 좌표계에 변환에 대한 개념 복습과 2D-3D matching 알고리즘(PnP), 3D-3D matching 알고리즘(ICP)에 대한 내용들을 좀 더 깊게 공부해보면 데이터셋 취득에 조금 더 이해를 하면서 구성할 수 있을 것 같네요.
리뷰 시작하겠습니다.
I. INTRODUCTION
물체의 texture 정보가 항상 풍부하면 좋겠지만, texture 정보가 없는 경우도 있습니다. 금속과 같은 강체 같은 경우가 이에 해당하는데요. 해당 물체를 통한 pose 추정은 자율 주행, 로봇의 grasp/manimulation, AR(Augmented Reality)등 여러 분야에서 사용되는 task입니다. 이처럼 많은 연구에 사용되는 만큼 중요한 문제라는 것인데요. 실제로 로봇이 투입되어 사용 되고 있는 현장에서는 금속 부품에 대한 pose 추정은 핵심 기술일 것 같네요. 물체의 pose는 RGB, depth, RGB-D에 대한 정보를 통해 얻을 수 있습니다. 단일 RGB만 사용하는 경우는 당연히 깊이 정보 없이 물체의 시각적인 외관만 얻겠네요. depth만 사용하는 경우는 어떨까요? depth를 사용하게 되면 저희가 잘 알고 있는 point cloud 라는 개념을 사용할 수 있겠고 좀 더 고차원적인 정보를 사용할 수 있습니다. 이번 데이터셋의 구성은 RGB-D 센서로 촬영을 진행하였으며, 6D pose estimation 분야에서는 RGB와 Depth의 각각의 장점을 효과적으로 결합한 RGB-D 정보를 통해 물체에 대한 pose 추정을 해결하는 것에 매우 큰 기여를 하고 있습니다. 이러한 대표적인 데이터셋은 LINEMOD, Occlusion LINEMOD, YCB-Video 등이 있습니다.
이번 데이터셋의 contribution은 다음과 같습니다.
- 산업현장을 타겟팅하였고, 금속 부품에 대한 6D pose를 추정하기 위한 multi-object target, occlusion, light-variant로 구성된 데이터셋 제안
- GT pose의 정확도를 올리기 위해서 bi-directional pose optimization을 적용
- single-frame : multi-object pose optimization
- multi-frame : single-object의 상대적인 pose invariance을 활용
- 구성된 데이터셋의 pose의 정확도를 다른 데이터셋들과 비교했을 때, 저자가 제안한 bi-directional pose optimization이 좋은 효과를 보였음
II. RELATED WORK
A. RGB-D Datasets
Single target object dataset
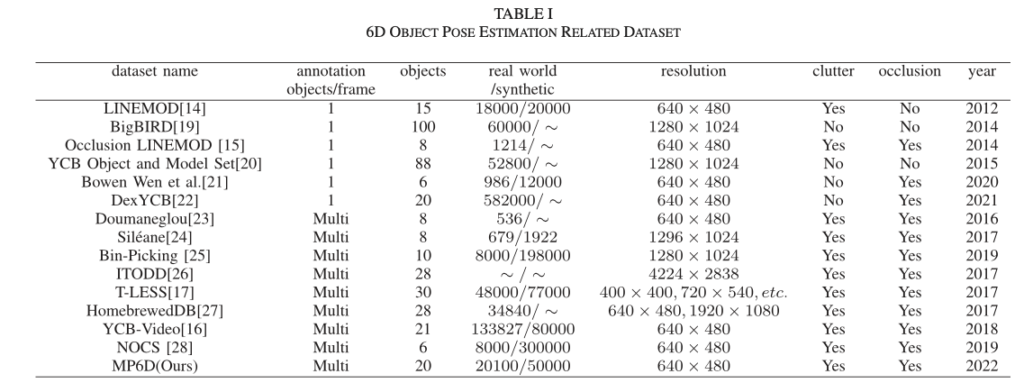
LINEMOD : 해당 데이터셋 같은 경우 모델이 학습하기에 매우 단조롭고 occlusion과 같은 challenge한 상황도 없어서 쉬운 데이터셋입니다.
Occlusion LINEMOD : LINEMOD에서 challenge한 상황을 만들어서 pose 추정을 어렵한 데이터셋입니다. occlusion 객체의 비율을 증가시켜 기존 데이터셋의 확장이라고 생각할 수 있겠네요. 기존 데이터셋에서 사용되었던 물체는 동일하나 8개를 사용합니다.
DexYCB : YCB-Video에서 20개의 물체를 선택하고 8개의 다른 카메라 뷰에서 582000개의 RGB-D 이미지들로 구성되어 있습니다. 6D pose 추정뿐만 아니라 2D detection, 3D hand pose estimation task에서도 사용된다고 합니다.
Multi-target object datasets
Doumanoglou : 8개의 물체로 구성된 산업 현장과 가정 환경을 타겟으로 한 대한 데이터셋 를 제공합니다. 일부 이미지에는 동일한 물체의 여러 인스턴스가 포함되어 있습니다.
Siléane : 대칭 정도가 다른 8개의 물체를 선정한 데이터셋입니다. 각 scene에는 300프레임의 이미지들로 구성되어 있습니다.
위 2가지 데이터셋의 이미지 샘플 수는 딥러닝 기반의 방법론으로 학습하고 평가를 진행하기에는 충분하지 않아보이네요.
Bin-Picking : 520개의 실제 이미지와 206,000개의 합성 이미지로 구성된 2개의 새로운 산업 물체를 도입하여 Siléane 데이터셋에서 확장된 데이터셋입니다.
ITODD : Bin-Picking 데이터셋과 유사하게 대부분 박스를 picking하는 scene들로 구성되어 있습니다. 두 데이터셋간의 차이점은 서로 다른 특성을 가진 28개의 산업 물체와 800개 이상의 scene이 포함되어 있다는 점입니다. 일부 GT pose에 대해서 개선이 있었지만 대부분은 공개되지 않는 상황이라고 하네요.
T-LESS : 30개의 texture-less한 산업 현장에서 사용되는 물체를 타겟으로하여 38,000개의 실제 학습 이미지와 20개의 scene에 대한 10,000개의 테스트 이미지를 제공합니다. 그러나 구성된 물체에는 산업용 부품의 challenge한 상황이면서 특수한 문제인 복잡한 모양, 반사광 등에 대한 문제는 없습니다.
HomebrewedDB : T-LESS에서 좀 더 개선 + 확정된 데이터셋으로 T-LESS와 구조적으로 유사합니다. 차이점은 데이터셋에 33개의 물체(장난감 17개, 가정용품 8개, 산업 관련 물체 8개)와 다양한 난이도의 13개 scene들로 구성되어 있다는 것입니다.
YCB-Video : 92개의 시퀀스로 구성되어 있으며, 133,827개의 프레임이 21개 물체의 정확한 6D pose 정보를 가지고 있습니다. 해당 데이터셋의 금속과 같은 물체는 풍부한 texture를 가지고 있는 반면, 산업 환경의 금속 부품은 texture가 없습니다.
NOCS : 실제 이미지에서 물체를 합성할 수 있는 spatial context-aware mixed reality 기법이 제안되었습니다. 해당 데이터셋에는 물체 6개, 42개의 고유 인스턴스에 대한 18개의 서로 다른 scene과 GT 6D pose의 annotation로 구성되어있습니다.
III. THE MP6D DATASET
A. Dataset Description
RGB-D 카메라로 TuYang FM851-E2 제품을 사용하였다고 합니다. 중국 제품인 것으로 보이나, 다른 제품이 뜨고 해당 카메라는 검색해도 안 나오네요.. 데이터 수집은 2FPS의 속도로 했다고 합니다. 해당 데이터셋의 모든 구성은 해당 프레임으로 구성을 했다고 하네요. 제가 데이터를 수집할 때에는 30FPS로 설정되어 있던 것을 의심하지 않았는데 촬영하는 scene이 정적이므로 낮은 프레임으로도 충분할 것으로 보이네요. 또한, 동기화 측면에서도 빨리 정보를 넘겨주는 것보다 천천히 넘겨주는 게 오히려 동기화 문제가 덜 발생하지 않을까 하는 제 생각입니다.
저자는 이번 데이터셋의 구성을 occlusion 및 light-variant으로 하였는데, 총 77개의 시퀀스로 구성되어 있고 총 20100장이라고 합니다.

앞서 이번 데이터셋의 특징들을 먼저 언급을 하였습니다. 구성된 금속 물체들은 그림(2)와 같이 구성되어 있으며, 자세히 보면 색이 좀 다른 것을 볼 수 있는데 이는 01~15까지 알루미늄 소재, 16~20까지 구리 소재라서 그렇다고 합니다. 물체의 규격 또한 중요한 역할을 하게 되는데 17~125mm로 다양하게 구성했다고 합니다.

취득한 이미지들을 살펴보면 그림(3)과 같이 촬영을 진행했다고 합니다. 계속 언급되고 있는 light-variant가 다양하도록 구성되었고, 1~11까지는 실제 촬영된 데이터, 12~15는 합성 데이터입니다. 합성 데이터의 구성은 BlenderProc을 이용하여 PBR(Physically Based Rendering) texture와 함께 실제와 같은 효과를 주는 합성 데이터를 제공해주는 툴을 사용하였다고 합니다.
B. Acquisition Step
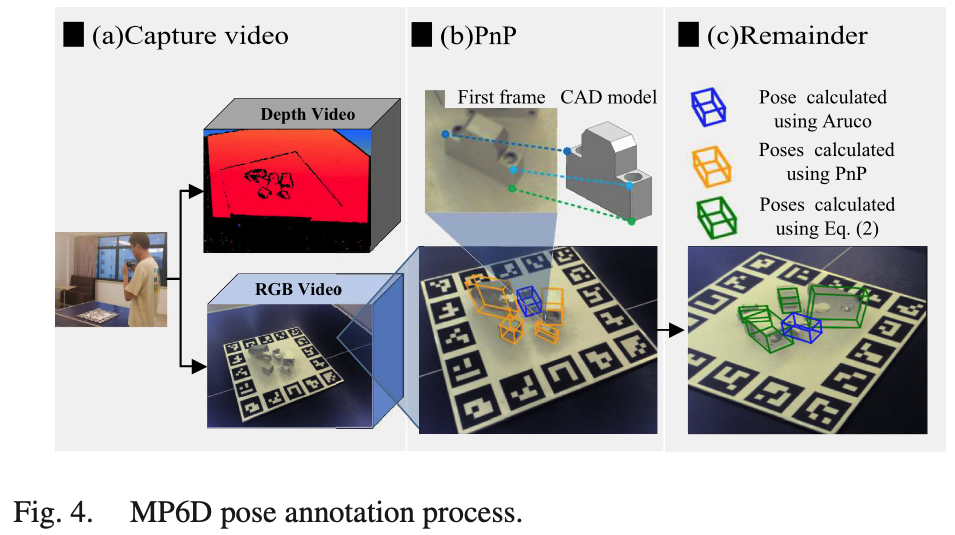
데이터셋을 구성하기 위해 먼저 calibration을 진행한 후 그림4(a)와 같이 마커를 구성하여 녹화하여 해당 시퀀스에서 사용된 첫 번째 프레임을 annotation 과정에 사용합니다. 그림(b)와 같이 각 부품 마다 첫 번째 프레임에서 3개의 키포인트가 선택되고 PnP(2D-3D matching) 알고리즘을 진행하는 방식이라고 합니다. 파란색 상자 안의 물체는 그림 4(b)와 같이 중간 부분을 나타냅니다.
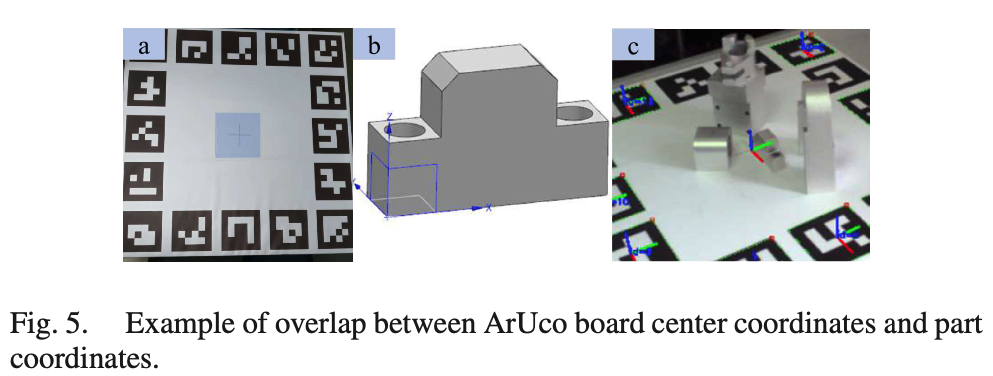
그럼 중간 물체에 대한 좌표계와 ArUco 보드의 좌표계가 겹쳐져있을텐데, 이걸 좀 더 자세히 살펴보면 그림 5(a)에는 ArUco 마커가 있고 그림 5(b)는 그림 5(c)에 표시된 ArUco 마커 중심의 좌표계와 겹치게 되는 중간 부분 좌표계를 확인할 수 있습니다. 이처럼, 중간 물체에 대한 pose(M_{cb})는 주변 ArUco 마커로부터 계산할 수 있습니다. 하지만, ArUco 마커를 통해 얻은 중간 물체의 pose는 정확하지 않으며, 수동으로 배치하거나 카메라 해상도가 낮으면 상당한 오차가 발생할 수 있다는 것입니다. 이를 보완하기 위해 노란색 상자 M_{co_i}에 있는 물체의 pose는 PnP에 의해 계산됩니다.

첫 번째 프레임의 부분 사이의 상대적인 pose인 M_{bo_i}는 식(1)을 사용하여 계산됩니다. 이를 아래의 식(2)에 대입하면 그림4(c)와 같이 나머지 프레임 M_{co_i}의 객체 i의 pose를 구할 수 있습니다. M_{bo_i}는 첫 번째 프레임에서 물체와 중간 물체의 상대적인 pose를 나타냅니다. M_{cb}는 카메라 좌표에 대한 첫 번째 프레임에서의 중 물체에 대한 의 pose를 나타내고, M_{bc} 는 M_{cb}의 역행렬이며, M_{co_i}는 첫 번째 프레임에서 노란색 박스에 해당하는 물체를 i라고 할때 해당 물체에 대한 pose를 의미합니다.
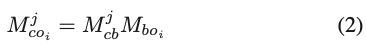
위의 notation을 토대로 M_{co_i}^j는 j 프레임에서 물체 i의 pose를 나타냅니다. M_{cb}^j는 j 프레임에서 ArUco 보드에 의해 계산된 중간 물체의 pose를 나타냅니다.
C. Bidirectional Fusion Optimization
저자는 B섹션에서 얻은 GT pose는 카메라 기하학적인 방법을 적용하여도 결국 noise가 많은 RGB-D 정보를 토대로 수행하며, 사람 손을 거쳐 수동적인 배치를 하게 되므로 비교적 정확도가 떨어지는 것을 문제로 정의합니다.

먼저 결과를 먼저 보면 그림(7)에서 노란색 박스는 B섹션에서 얻은 초기 GT pose(init pose)입니다. 그리고 저자가 제안한 최적화를 적용하면 파란색 박스와 같은 정확한 GT pose를 얻을 수 있다고 합니다. 사진으로 보기에는 정확하게 식별하기에는 좀 어려운 것 같습니다. 여튼 개선이 있었다고 하니, 최적화 방법은 어떻게 진행되는 건지 알아보겠습니다. 저자는 어떤 두 가지 측면에 대해서 fusion을 하여 정보를 전달하는 것에서 insight를 얻었다고 하네요. contribution에서 언급했을 때는 정확하게 이해는 안됐었는데, single-frame의 multi-object 타겟에서 얻은 pose(M_{cb})와 single-object 타겟에서 multi-frame으로 계산한 pose(M_{bo_i})에 대한 정보를 fusion한다는 의미였습니다. 다시 정리하면 single-frame에서 여러 개의 물체에 대해서 최적화를 수행하여 이전처럼 중간 물체에 대한 pose를 얻고 multi-frame에서 single-object를 최적화하여 상대적인 pose를 얻습니다. 이렇게 두 가지 정보를 t_{end}횟수 만큼 fusion하여 정확한 중간 물체의 pose(M_{cb}^{t_{end}})와 상대적인 pose(M_{bo_i}^{t_{end}})를 얻습니다. 해당 알고리즘은 아래의 그림(6)을 통해 살펴보겠습니다.
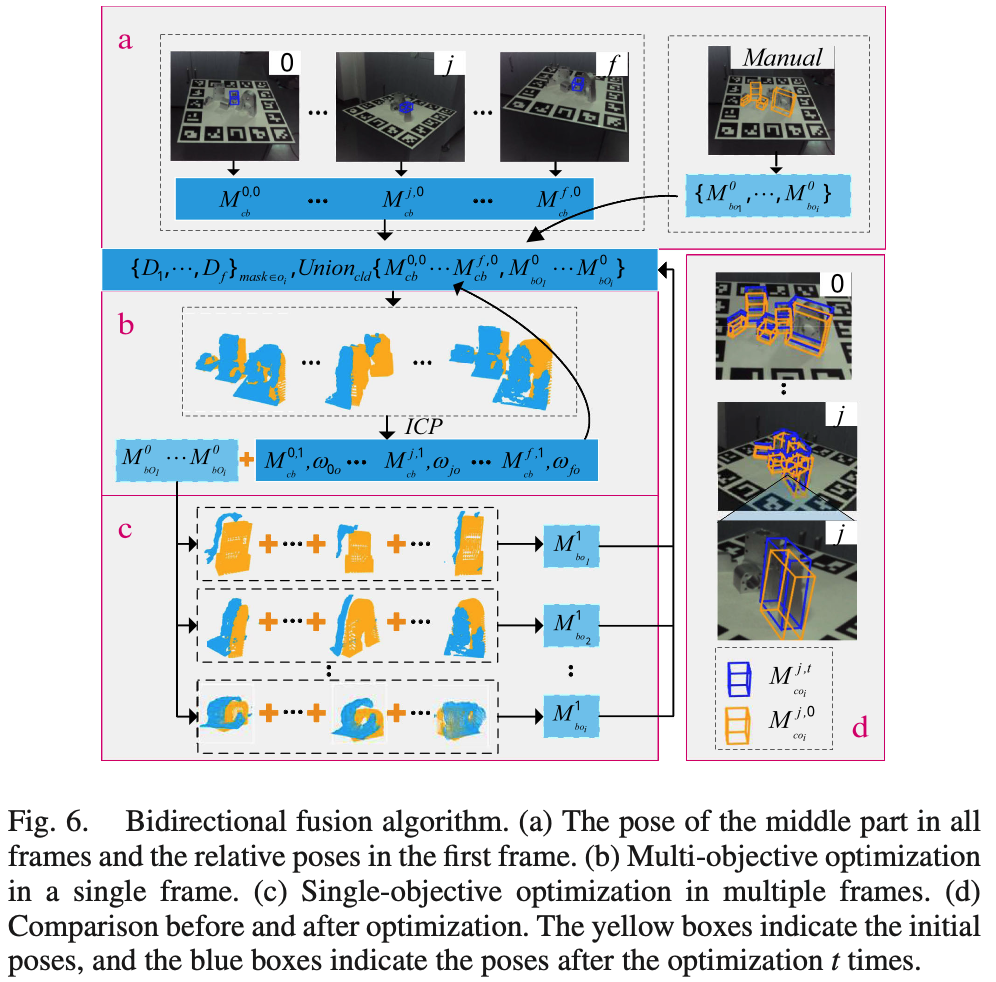
(a)섹션B에서 수행했던 중간 물체에 대한 pose를 모든 frame 대해서 뽑고 그때, 첫 번째 frame의 init pose를 가지고 (b)single-frame에서 multi-object(다른 물체)에 대해 최적화를 수행하고 (c)multi-frame에서는 single-object에 대해서만 최적화를 수행합니다. 이처럼 init pose와 (b), (c)의 정보를 fusion하였을 때의 비교를 (d)에 나타내었습니다. 점선 안에 있는 notation에 따라 이전과 동일하게 노란색 상자는 초기 pose를 나타내고, 파란색 상자는 최적화 과정을 t 회 이후의 pose를 나타냅니다.
이때 사용되는 loss function은 전체 temporal한 sequence에 대한 최적화 상태를 나타내는 데에 사용된다고 합니다.
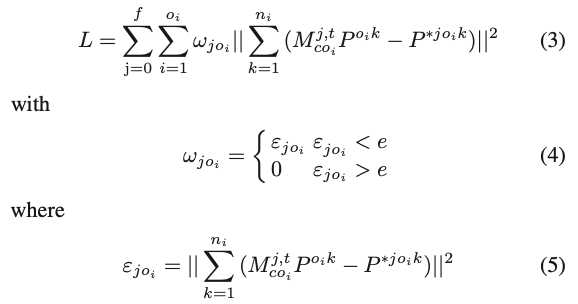
수식 정리를 하면 j번째 프레임 j, t번째 최적화 t, \omega_{jo_i}는 j 번째 프레임에서 i 번째 물체(1~20개의 클래스)의 최적화된 정도를 나타냅니다. P^{o_{i}k}는 i 번째 물체에 대한 물체 좌표계에서 선택된 n_{i} 개의 3D 포인트를 나타냅니다. P^{∗o_{i}k}는 카메라 좌표계에서 i번째 물체에 해당하는 3D 포인트를 나타냅니다. \epsilon_{jo_{i}}는 j번째 프레임에서 i번째 물체의 pose mas를 의미하며, e는 비정상 pose에 대한 threshold입니다. 즉 정리하면 최적화된 pose에 대한 3D point와 카메라 좌표계에 대한 3D point에 대한 오차에 대한 값들을 누적합하고 최적화된 정도를 곱해주어 loss를 계산하는 방식으로 동작하네요.
IV. EXPERIMENTS
A. Accuracy of the Ground Truth Poses
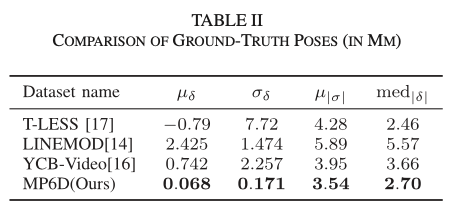
저자는 제안한 최적화 방법에 대한 유효성을 검증하기 위해 T-LESS에서 사용한 GT pose 평가 지표를 사용합니다. T-LESS에서 사용한 것과 동일하게 \delta=D_c - D_r를 사용하여 differences를 계산하는데 D_c는 마스크 영역의 depth, D_r은 최적화된 pose와 CAD모델을 물체의 visible surface을 선택하도록 하는 함수(Z_{buffer})를 사용하여 projection 했을 때의 depth를 의미합니다. 이때 5cm를 초과할 경우 이상치으로 간주하여 제거합니다. 또한, 해당 평가 지표를 사용하여 저자는 LINEMOD와 YCB-Video의 GT pose도 별도로 평가합니다. T-LESS에서는 \mu\delta는 앞서 설명한 differences의 평균, \sigma\delta는 differences의 표준편차, \mu|\delta|는 differences의 절댓값에 대한 표준편차, med|\delta| 절댓값에 대한 중앙값일 때, 해당 값들 중 가장 나은 셋을 선택합니다. 이렇게 했을 때 MP6D 데이터셋에서 가장 정확도가 좋은 이유는 제안한 최적화 과정이 카메라 정확도에 지나치게 의존하지 않기 때문이라고 합니다. 카메라에 대한 오차를 증폭시키지 않고 프레임당 중간 물체에 대한 pose와 상대 pose의 오차만 줄입니다. 이 두 가지 유형의 정보의 정확성만 보장된다면 정확한 GT pose를 얻을 수 있습니다.
B. Baselines of the State-of-The-Art Methods
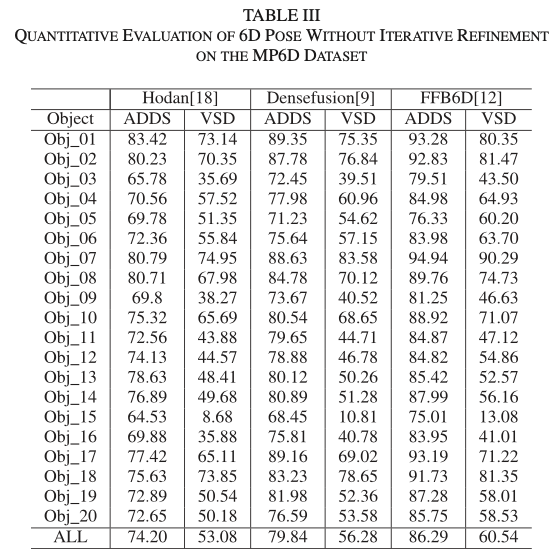
베이스라인으로 3개의 모델을 사용하였는데요. 지금도 FFB6D 성능이 LINEMOD 데이터셋에서 SOTA인 상태라 이번 데이터셋에서도 어느정도로 나오는지 관심있게 보았습니다. 역시나 가장 좋은 성능을 보이긴 하네요. 베이스라인에는 실제 데이터셋의 70% + 합성데이터를 학습할 때 사용하였고, 실제 데이터셋의 나머지 30%를 테스트로 사용했다고 합니다. ADD 메트릭은 자주 언급됐었던 지표이니 다른 리뷰를 참고해주시면 감사하겠습니다. VSD(Visible Surface Discrepancy) 평가지표가 좀 낯설텐데 해당 평가지표는 6D pose estimation 분야에서 진행되고 있는 BOP challenge에서 사용되고 있는 평가지표입니다. 6D pose에서의 recall은 물체의 올바른 pose가 추정된 비율을 의미합니다. 해당 비율에서 visible한 물체만 고려했을 때, 구별하기 어려운 물체에 대해서 올바르게 추정하도록 하는 지표라고 이해해주시면 될 것 같습니다.
제안한 데이터셋에 대해서 다음과 같은 한계를 극복해야 한다고 합니다.
- occlusion 상황이 너무 많기 때문에, 학습에 매우 까다로움
- 금속 부품이라 쉽게 반사되며 복잡한 모양을 가진 경우, depth에서 point cloud가 누락되는 경우가 있어 학습에 방해됨
하지만 이러한 한계가 오히려 산업 현장에서도 자주 발생하므로 제안한 데이터셋은 특히 산업 환경에서 물체의 포즈 추정 방법을 연구하는 데 유용할 것 같다고 얘기합니다.
V. CONCLUSION
이번에는 MP6D라는 산업 현장을 타겟으로 한 금속 물체들로 구성된 데이터셋을 살펴보았습니다. MP6D의 핵심은 센서 측면보다는 GT pose를 어떻게 잘 구성하는지에 초점을 맞추었네요. bidirectional한 정보를 fusion하여 모델을 학습시켜 pose를 개선시키는 것이 인상적이었습니다. 코드를 공개하면 좋을텐데.. 그점이 좀 아쉽습니다. 이상으로 리뷰 마치겠습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
이전에 object를 구매할 때도 들었던 생각이데 물체의 규격이라는 것이 꽤나 중요하게 작용하는 것 같습니다. 규격이 데이터셋에서, pose를 추정할 때 정확히 어떤 면에서 영향을 미치는지 좀 더 자세하게 알 수 있을까요? scale 관점에서 depth의 측정 정도가 달라지는 것과 관련이 있는 것인지도 궁금합니다.
그리고 ArUco 보드의 좌표계는 어떻게 구성되어 있는것인가요 ?? 해당 마커보드로 pose를 구하는 것으로 알고 있는데, 2D-3D 좌표의 변환과 같은 과정이 가능해야할텐데 어떤 축으로 구성되어 있는 것인지 궁금하여 질문 드립니다.
감사하니다 !
안녕하세요 ! 좋은 리뷰 감사합니다.
마커는 왜 저렇게 생긴건가요 ? 근본적으로 마커의 존재 이유가 궁금합니다. . ㅎ . ㅎ
또, 2D-3D matching 알고리즘인 pnp의 동작과정에 대해 간단히 설명해주실 수 있으실까요 ?
마지막으로 Figure 4에서 파란색 상자가 중간 부분을 나타낸다고 하였는데, 중간 부분이 .. 5개의 물체 중 중앙에 위치한다는 것을 의미하는 걸까요 ? 중간은 왜 찾나욤 ?
감사합니다 !!