안녕하세요, 열여덟 번째 X-Review입니다. 이번 논문은 2021년도 ICCV에 게재된 Emerging Properties in Self-Supervised Vision Transformers 논문입니다. 그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
Transformer는 visual recognition 분야에서 Convolutional neural networks(이하 convnets)의 대안으로 등장하였습니다. 이 Transformer는 nlp의 학습 전력을 가져온 것으로 방대한 양의 데이터로부터 사전학습을 한 다음 타겟 데이터셋에 대해 파인튜닝을 하는 식으로 사용되었죠. 하지만 ViT는 convnets에 비하여 더 계산량도 많을 뿐더러, 더 많은 학습 데이터셋을필요로 하는 등 convnets보다 나은 명확한 이점을 찾기는 어려웠습니다.
저자들은 NLP 분야에서 Transformer의 성공은 self-supervised 사전학습을 사용한 것 때문이라고 보았습니다. 이 self-supervised 사전학습의 목적은 문장 내의 단어들을 사용하여 pretext task를 생성하도록 하는 것으로 이는 문장 당 라벨이 하나인 지도학습 보다 더 풍부한 학습을 할 수 있도록 합니다. 비슷하게 비전 분야에서도 이미지 레벨의 지도학습은 종종 이미지가 가지고 있는 시각적인 정보들을 놓치게 만들며 단 하나의 라벨에만 집중하도록 하는 특성을 가지고 있습니다.
그래서 저자들은 nlp 분에야서 transformer가 self-supervised로 학습한 것처럼 ViT feature들을 self-supervised으로 사전학습하는 연구를 수행하겠다고 합니다. 여기서 흥미로운 점은 지도학습으로 학습된 ViT나 convnets에서는 발견되지 않았던 몇 특성을 발견하였다는 점입니다.

먼저, self-supervised ViT feature들은 위 Figure 1에서 확인할 수 있는 것처럼 object의 경계를 포함하고 있다는 점입니다. 또, self-supervised ViT feature들은 어떠한 fine-tuning, 데이터 증강 등 없이 좋은 성능을 내는 KNN 분류기가 된다는 것 입니다.
이런 발견들을 하면서 저자는 라벨이 없는 knowledge distillation의 한 형태로 해석될 수 있는 간단한 self-supervised 방식의 프레임워크를 디자인하게 되었습니다. 프레임워크 구조같은 경우에는 아래에서 설명하도록 하겠습니다. 무튼 이 프레임워크는 knowledge distillation with no labels에서 di no를 따 와 DINO라고 부르며, ViT 뿐만 아니라 convnets에도 어떠한 아키텍처 수정 없이 동작한다고 합니다.
2. Related work
Self-supervised learning
DINO는 metric-learning 기법을 사용한 self-supervised 방법론인 BYOL에서 영감을 받아 BYOL의 구조를 사용하였습니다. self-supervised 기반 학습은 augmentation을 한 동일한 이미지를 positive pair로 보아 거리를 가깝게 하도록 학습하며, 다른 augmentation된 이미지와는 negative pair로 보고 거리를 멀도록 하여 학습하는 식으로 초점이 맞춰져 있는데, 이런 학습 기법은 큰 배치 사이즈, 메모리 뱅크가 필요하다는 단점이 있습니다. 이러한 점을 해결하고자 negative pair를 사용하지 않는 BYOL(Bootstrap your own latent)이 등장하였습니다.
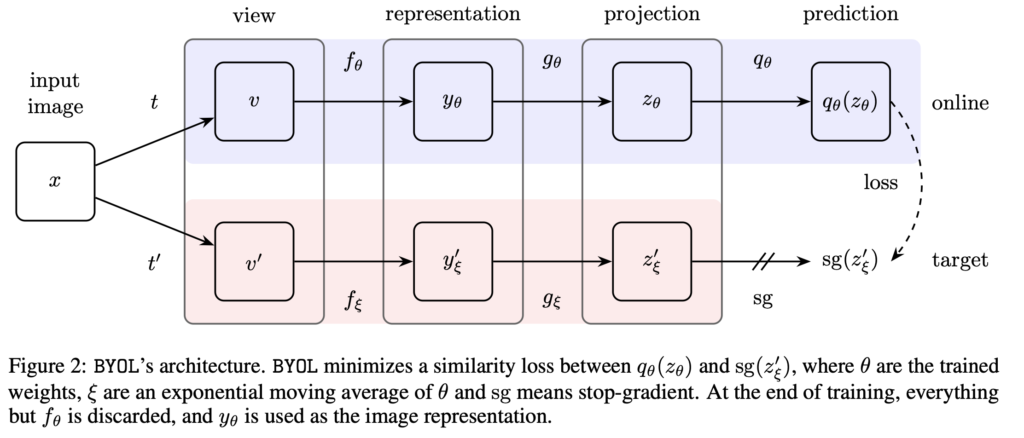
위 Figure는 BYOL의 아키텍처 입니다. 간단히 설명하자면 target network와 online network 이 두 개의 네트워크를 이용하여 반복적으로 네트워크의 출력을 bootstrap하는 식으로 동작합니다.
본 논문과 BYOL의 차이점이라고 하면 다른 loss를 사용했다는 점과 student와 teacher 네트워크의 구조가 완벽하게 동일하다는 점입니다. 즉, 본 논문은 self-supervised 학습 기법으로 동작하는 BYOL을 라벨 없는 상황에서의 mean teacher self-distillation의 한 형태로 해석한 것이라고 볼 수 있습니다.
Self-training and knowledge distillation
DINO 이전에도 self-supervised 기반으로 동작하는 knowledge distillation 학습 기법들이 존재했습니다. 이전 방법론들은 사전학습한후 fixed된 teacher를 사용하였던 것에 반해 DINO는 사전학습 되지 않은 teacher를 사용하지 않는다는 차이점이 있습니다.
3. Approach
3.1. SSL with Knowledge Distillation
DINO는 방금 언급했던 것과 같이 self-supervised 방법론들과 전반적인 구조는 동일하지만 차이점이라고 하면, knowledge distillation의 형태를 띈 다는 것입니다.

DINO pytorch pseudo code입니다. 아래 Figure와 함께 DINO 동작 과정에 대해 살펴보도록 하겠습니다.
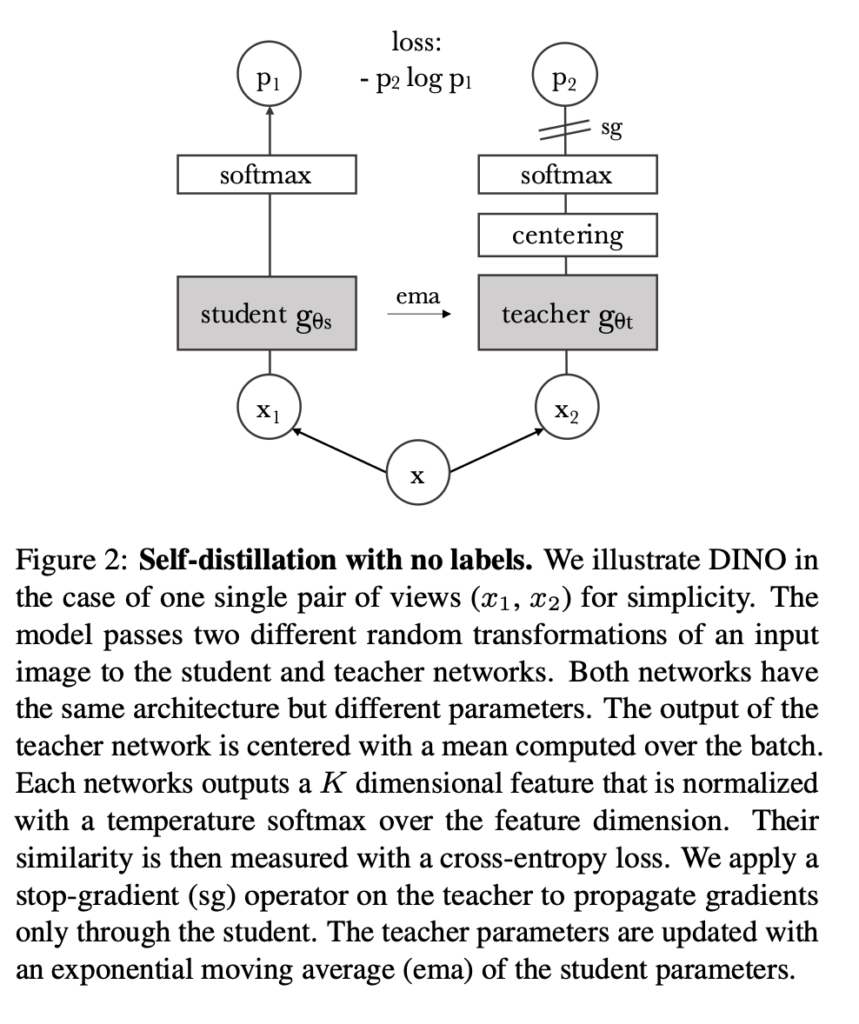
DINO 구조는 단순하게 student 네트워크가 teacher 네트워크의 출력을 예측하는 것이라고 보면 되는데, 한 이미지 x에 대해 서로 다른 augmentation 기법을 적용한 x1, x2를 각각 student teacher에 통과시켜 softmax를 취한 output을 cross-entropy loss를 사용하여 최적화 시키는 것입니다.
이 student와 teacher 네트워크의 구조는 동일하지만 서로 다른 파라미터를 가지고 있습니다. teacher 쪽을 보면 centering이라고 적혀져 있는데 teacher 네트워크의 출력은 batch내에서 평균을 취한 centered 값이라는 것입니다. 또한 sg라고 하는 부분은 stop-gradient operator로 teacher 네트워크의 gradient는 동결시킨 후, parameter는 오직 student에 의해 업데이트되게 되는 구조입니다.
이때 ema(exponential moving average) 방식을 사용하여 teacher 네트워크의 parameter가 update되게 됩니다. ema는 시간에 따른 가중치를 계산하는 방식으로 오래된 데이터에 대한 가중치는 지수적으로 감소하도록 하는 방식입니다. 즉, 최근 데이터에 대한 가중치는 크게 주고, 이전 데이터에 대한 가중치는 작도록 하는 방식입니다.
정리하자면, student network gθ_s가 teacher network gθ_t의 출력을 가지고 학습을 하는 것입니다.
가장 먼저 input 이미지 x가 존재할 때 두 네트워크는 K 차원의 확률 분포인 P_s와 P_t를 뱉게 되는데 이 P는 아래 softmax function을 통과해 normalizing되어 구해집니다.
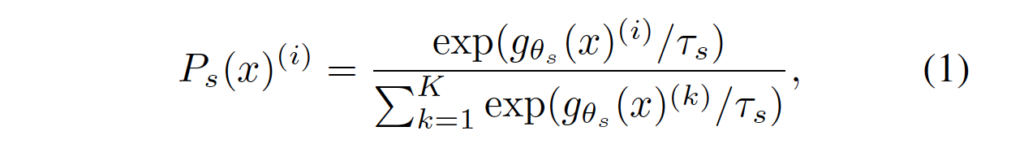
이렇게 구해진 student 확률 분포와 teacher의 확률 분포간의 차이를 구하기 위 cross-entropy loss를 사용합니다.
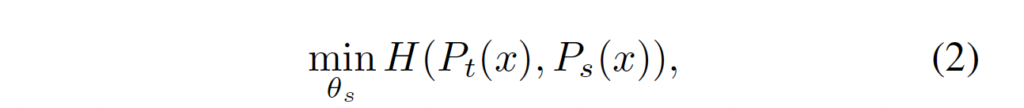
- H(a, b) = -alogb
이를 self-supervised learning에 적용하기 위해 이미지에 대해 multi-crop 방식을 사용하였습니다. 한 이미지에 대해 V개의 서로 다른 view 집합을 생성하는 것인데, 이는 2개의 global view인 x^g_1과 x^g_2와 작은 해상도를 갖는 몇 개의 local view를 포함합니다. crop된 모든 이미지들 즉, global view와 local view는 모두 student 네트워크를 통과할 수 있지만, teacher 네트워크는 오직 global view만 통과합니다. 저자들은 이걸 “local-to-global”을 장려한 것이라고 합니다. 그래서 최종적으로 사용되는 loss는 아래와 같습니다.
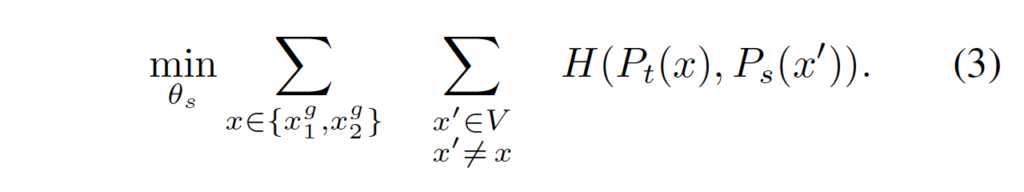
teacher와 student 네트워크는 서로 같은 아키엑처 g를 가지며 서로 다른 파라미터 θ_s, θ_t를 갖는다고 하였습니다. 이 student의 파라미터 θ_s는 식 (3)을 최소화하는 방향으로 업데이트 됩니다.
Teacher network.
DINO의 teacher 네트워크의 파라미터는 지난 iteration 동안의 student 네트워크로부터 업데이트 된다고 하였습니다. 저자는 여러 방식으로 student의 wieght를 이용해 teacher 네트워크의 파라미터를 업데이트 하는 것에 관한 여러 연구를 진행했는데, EMA 방식을 사용하는 것이 가장 효과가 좋았다고 합니다.
EMA 방식을 사용하여 업데이트 하는 식은 아래와 같습니다.
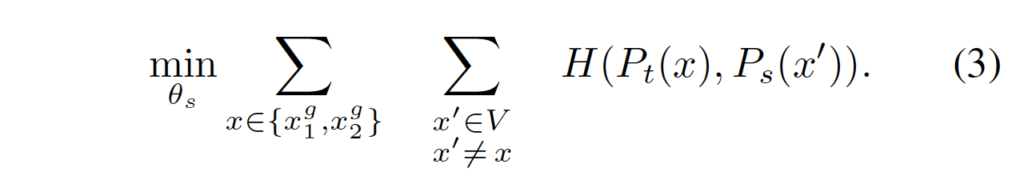
EMA 방식은 식에서도 확인할 수 있듯이 이전의 정보도 고려하는 방식입니다. 저자들은 이러한 방식을 사용하면서 teacher 네트워크의 성능이 student 네트워크보다 좋았다고 하며 이는 앙상블의 효과로 인한 것이라고 합니다.
Avoiding collapse.
몇 몇 self-supervised 방법론은 여러 다른 방법들을 사용하여 collapse 문제를 해결하려고 합니다. collapse는 입력에 대해 동일한 embedding을 출력하는 현상으로, 본 논문에서는 teacher 네트워크와 student 네트워크가 균형있게 학습되지 못하는 것을 의미합니다. 저자들은 model collapse를 막기 위해 moment teacher의 output에 centering과 sharpening을 사용했습니다. centering은 한 개의 dimension이 dominate되는 것을 막을 수 있지만, output이 uniform해지게 됩니다. 반면에 sharpening은 반대의 효과를 가지고 있죠. 그래서 이 두 operation을 적용함으로써 밸런스를 맞추며 momentum teacher의 collapse를 피하도록 하였습니다.
여기서 centering이란 잘 이해하지 못했지만, , 첫 번째 배치 통계에만 의존하는 것으로 teacher에 bias인 c를 더하는 것으로 해석할 수 있다고 합니다.
g_t(x) ← g_t(x)+ c 와 같이 표기할 수 있겠죠. 여기서 c는 center 값으로 ema(exponential moving average) 방식으로 업데이트됩니다. ema는 앞에서도 언급했듯이 이전 데이터도 고려하는 대신, 현재 데이터에 비해 가중치를 적게 부여하는 방식으로 동작한다고 하였습니다. 이 ema 방식으로 업데이트되는 c는 아래 식(4)와 같이 나타낼 수 있습니다.
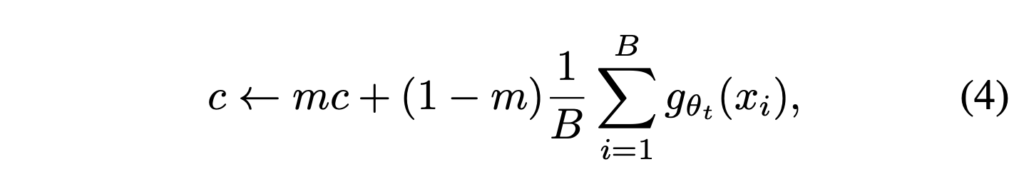
- m : rate parameter로 양수의 값을 가집니다.
- B : 배치 사이즈
또, sharpening 같은 경우에는 teacher softmax normalization의 τ_t를 낮은 값을 줌으로써 적용할 수 있습니다.
3.2. Implementation and evaluation protocols
Evaluation protocols.
self-supervised learning에서의 표준 evaluation protocol은 linear classifier를 학습하는 것이거나 다운스트림 테스크에서 피쳐를 finetuning하는 것이 있습니다. 여기서 linear classifier를 학습하는 linear evaluation은 random init 후 freeze 시킨 뒤에 feature extractor 뒤에 한 개의 linear를 붙여 학습시킨 후 평가하는 것입니다.
저자는 이런 기존의 evaluation protocol은 learning rate과 같은 하이퍼 파라미터에 민감하다는 것을 발견하였습니다. 그렇기에 추가적으로 간단한 k-NN classifier로 feature의 quality를 평가하도록 하였습니다. 이는 사전 학습 모델은 freeze시킨 후 downstream task의 학습 데이터를 입력으로 넣었을 때의 feature를 저장해 둔 다음 nearest neighbor classifier가 test 이미지의 feature에 대해 k개의 nearest neighboring feature를 뽑아내어 이 feature의 label의 majority를 test image의 label로 예측하는 형식으로 동작합니다. 이건 하이퍼마라미터 튜닝이나 데이터 증강이 필요없으며 downstream 데이터셋에 한 번의 forward 과정만으로도 실행할 수 있다는 점에서 feature evaluation을 단순화 했다고 볼 수 있겠습니다.
4. Main Results
실험 결과에 대해 알아봅시다. 먼저, ImageNet에서의 결과입니다.
4.1. Comparing with SSL frameworks on ImageNet
다른 Self-supervised learning 방법론들과 비교할 때 본 DINO와 같은 구조를 가지는 것들, DINO내부 구조를 다르게 한 것들로 나눠 두 가지 다른 측면에서 비교를 하였습니다.
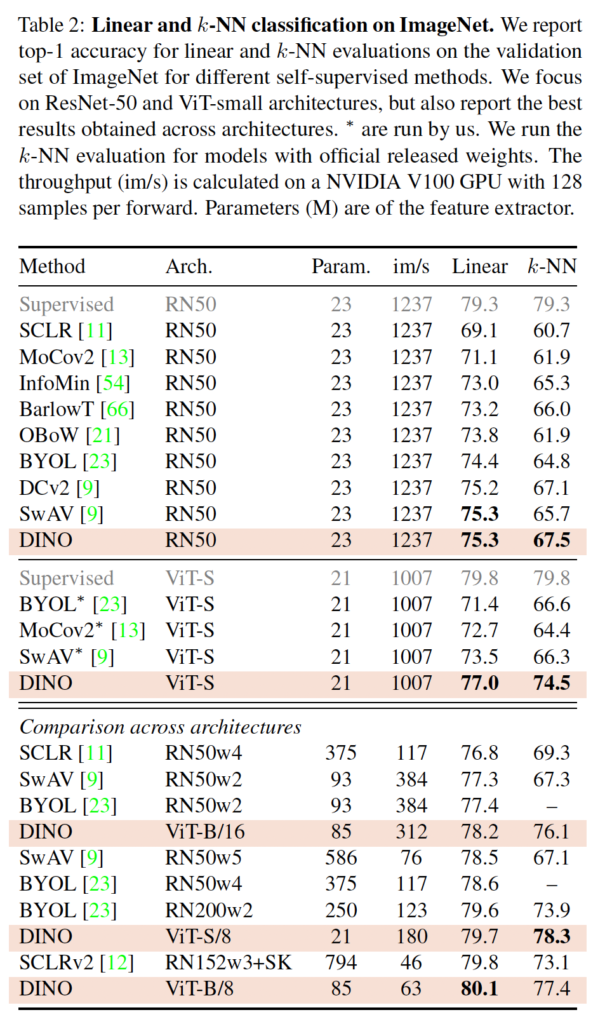
먼저 같은 구조를 가지는 방법론들과의 비교입니다. 위 표2의 상단부분이 이에 해당하는데, resnet50을 사용한 것과 ViT-small을 사용한 것으로 나뉘어 있는 것을 확인할 수 있습니다. 결과를 보면 ResNet50에서는 아주 작은 차이로 DINO가 SOTA를 달성하였지만 ViT-S의 경우에 특히 KNN evaluation에서 큰 성능 차이를 보였습니다.
다음으로 표의 하단 부분이 다른 구조를 사용하여 실험한 결과인데, 이 실험을 하여 확인하고자 한 것은 더 큰 아키텍처로 이동할 때 DINO로 학습한 ViT의 한계를 보고자 한 것입니다. DINO로 더 큰 크기의 ViT를 학습하게 되면 성능이 향상되지만 patch크기를 16에서 8로 줄인 경우가 성능에 더 큰 영향을 미치는 것을 볼 수 있습니다.
4.2. Properties of ViT trained with SSL
여기서는 downstream task에서의 trasferability를 평가하고자 하였습니다.
Image Retrieval
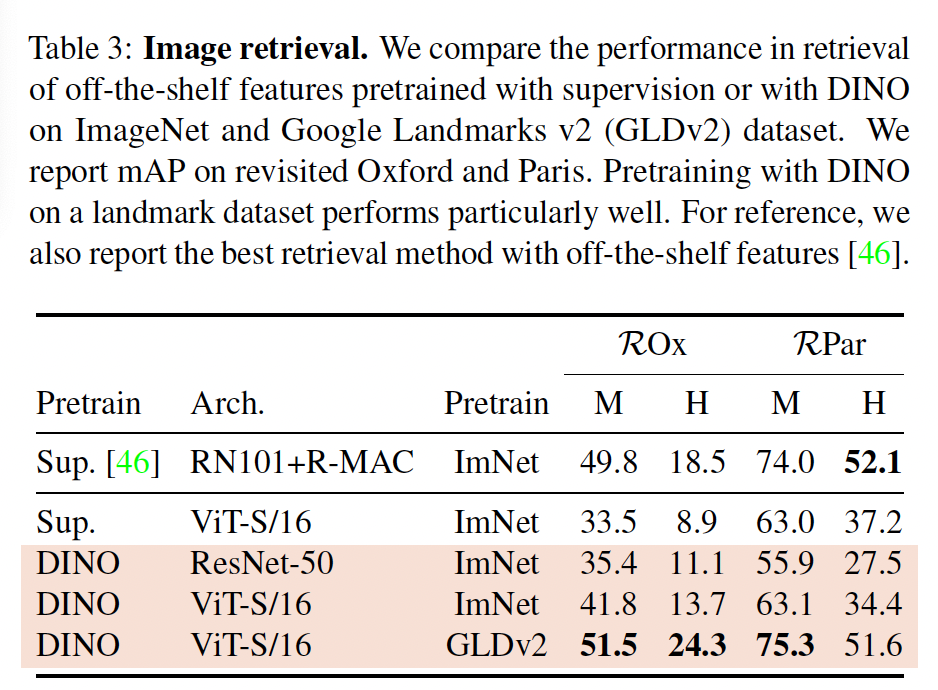
Oxford와 Paris 이미지 retrieval 데이터셋을 사용하여 실험을 진행했습니다. 이 데이터셋은 쿼리/데이터베이스 쌍을 포함하고 점차 어려워지는 3개의 subset으로 구성되어 있으며 Medium(M)과 Hard(H) subset에 대해서만 실험을 수행하였습니다. 여기서는 ImageNet에서 label을 사용하여 학습한 다른 방법론과 DINO를 비교하였는데, Paris 데이터셋에서 Hard subset을 제외하고는 DINO가 더 성능이 좋은 결과를 보였습니다.
5. Ablation study
Ablation study에 사용된 모델은 ViT-S입니다.
Importance of the Different Components
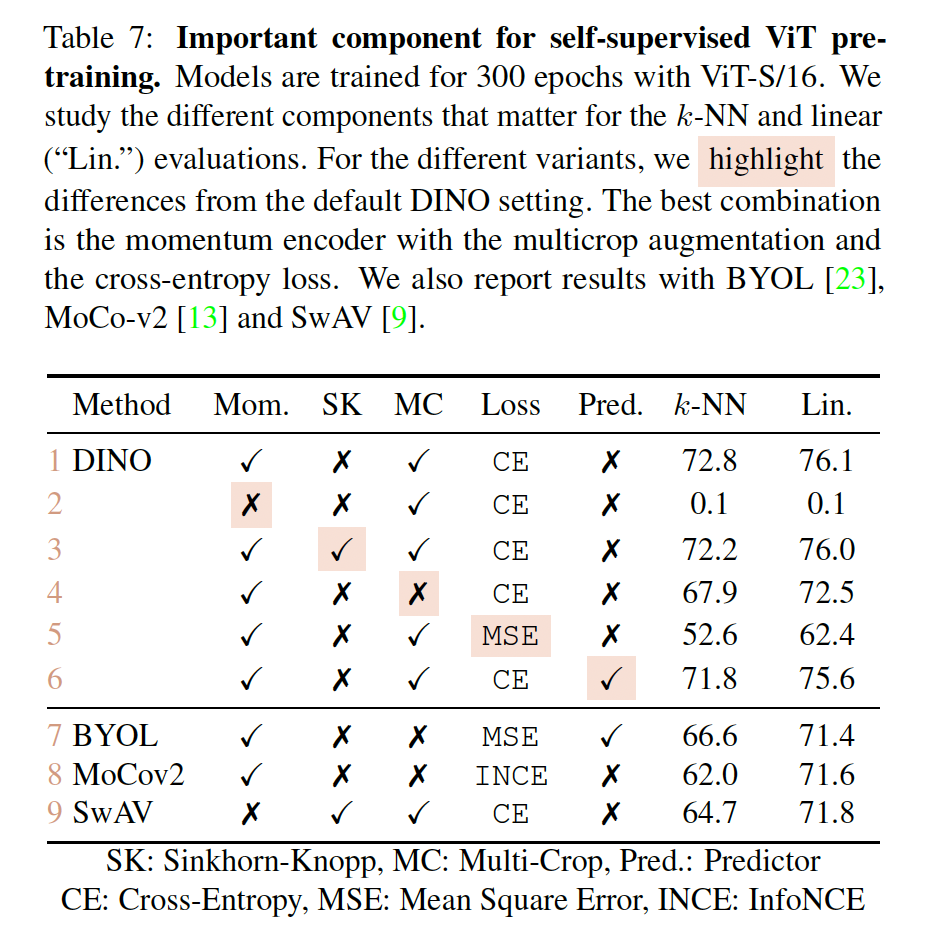
위 Table 7을 보면 momentum이 없는 경우에는 모델이 동작하지 않는 것을 볼 수 있습니다. (mom) 즉, momentum이 없으면 모델이 converge하지 못한다는 것입니다. 하지만 9번째 행에서 동일하게 momentum이 없는 경우에 SK(swirling kernel)을 적용한 경우 모델이 collapse 문제를 직면하지 않은 것으로 보입니다. 하지만 DINO에 경우에는 momentum이 있기에 SK를 적용한 것과 적용하지 않은 것과 큰 차이는 없는 것을 볼 수 있습니다. 또, 4 5행간의 비교를 통해 DINO에서는 multi-crop 기법과 cross-entropy loss가 성능에 많은 영향을 미치는 것 같네요.
Importance of the patch size
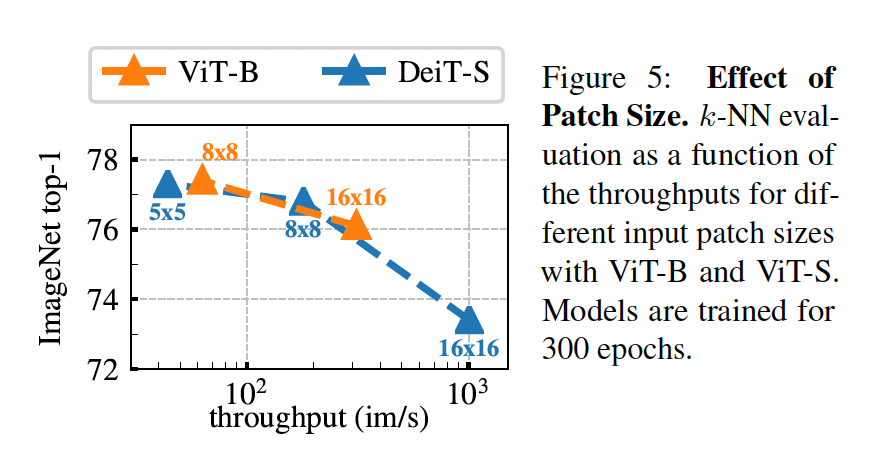
patch 크기에 따른 ablation study로 ViT-S 모델에서 K-NN 분류 성능을 비교하였습니다. 결과를 보자면 patch 크기를 줄인다고 해도 파라미터 수는 늘어나지 않는데, 성능이 크게 향상되고 있습니다. 하지만 패치 수가 작아질수록 throughput 양이 줄어드는 양상을 보이네요.
안녕하세요 정윤서 연구원님 좋은 리뷰 감사합니다.
[그림2]에서 teacher와 student는 서로 동일한 구조, 다른 파라미터를 가지고 있다고 하셨는데 teacher가 사전 학습되지 않은 것이라면 initialize를 다르게 해준 것으로 이해하면 되나요?
그리고 collapse문제에 대해 언급해 주셨는데요, ‘입력에 대해 동일한 embedding을 출력하는 현상’이 왜 본 논문에서는 ‘teacher와 student의 학습이 불균형적으로 이루어짐을 의미하는지 잘 모르겠습니다. 애초에 teacher와 student가 동일한 output을 내도록 학습하는 것이 distillation이라고 이해하였기에 해당 부분이 문제가 되는 이유를 이해하지 못했는데요, 좀 더 자세히 설명해 주실 수 있을까요?
안녕하세요 ! 좋은 리뷰 감사합니다.
본 방법론은 일반적인 knowledge distillation 방법들과 달리, 사전 학습된 teacher network를 사용하지 않고 student 네트워크의 past iteration으로부터 teacher를 업데이트 하는 것 같은데 이런 방법을 선택한 저자의 의도가 궁금합니다. 또한 multi-crop 방식으로 2개의 global view와 몇 local view를 생성한 후 네트워크의 입력으로 넣는 것 같은데 이 때 왜 global view와 local view는 student의 입력으로 모두 들어갈 수 있는 반면에 teacher 네트워크에는 오직 global view만 통과할 수 있는 건지 궁금합니다. 저자가 장려하는 local-to-global의 의미가 무엇이고 이로 인해 얻을 수 있는 이점이 뭔가요 ? 이와 반대로 global-to-local로 했을 때의 실험 결과가 있는지 궁금합니다.
감사합니다.
안녕하세요, 꼼꼼한 논문 리뷰 감사합니다.
제 얕은 지식으로는 Knowledge Distillation 관련 논문들에서 loss function으로 Teacher와 Student 모델에 대해 KL-divergence loss를 사용하는 것으로 알고 있습니다. 이번에 리뷰하신 DINO는 KL loss를 사용하지 않는 것으로 보이는데, KL loss 대신 EMA를 사용하는 게 맞나요? Knowledge Distillation라고 해서 제가 언급한 loss를 무조건 사용하는 것이 아닌 건지 궁금합니다.
감사합니다.