
안녕하세요,
이번에도 6D pose estimation 관련 논문입니다.
데이터셋을 취득하기 위해 기존 데이터셋이 어떻게 물체를 정의하였는지, 어떤 시나리오로 구성하였는지, Annotation은 어떻게 했는지에 대해 아이디어를 제공 받기 위해 이번에는 데이터셋 논문을 읽어보았습니다. 최근에 물체에 대한 GT pose annotation을 이미지 25장에 대해서 진행했었는데 3-4시간 정도 걸렸던 것 같습니다. 그래서 이중에서도 가장 궁금한 점은 ‘NVIDIA라면 Annotation을 어떻게 했을까?’ 라는 생각으로 읽어보았습니다. 읽어보니 NVIDIA에서도 직접 라벨링을 한 것 같네요.
리뷰 시작하겠습니다.
I. INTRODUCTION
연구실과 실제 시나리오 사이의 간극을 좁히기 위해 많은 연구자들이 RGB 또는 RGBD 이미지에서 물체를 detection하고 pose를 추정하는 방법을 개발했습니다. 최근 6D pose estimation 문제에 대한 연구가 활발히 진행이 되었으나 여전히 아직 많은 미해결 연구 문제가 남아 있지만 기본은 갖추어져 있습니다. 이 중에서도 저자는 중요한 한계점으로 언급하는 점은 기존의 pose estimator는 대부분의 연구자가 사용할 수 없는 물체에 대해 학습되는 것을 언급합니다. 이러한 한계는 6D pose estimation을 위한 BOP Benchmark Dataset을 보면 확인할 수 있습니다. 데이터셋을 보면 물리적으로 물체를 쉽게 얻을 수 있는 방법이 없기 때문에 해당 데이터셋들을 사용하여 이미 학습된 pose 모델을 가지고 실제 로봇 실험을 수행하지 못하는 경우가 많다고 하네요. 하지만 YCB나 RU-APC는 그나마 가장 접근하기 쉬운 데이터라고 합니다. 하지만 이 데이터셋도 시간이 지나면서 해당 물체들과 일치하는 제품들을 매장에서 찾는 것이 점점 어려워지고 있는 것이 현실적인 문제입니다. 또 다른 문제는 일부 품목이 일반적인 로봇 그리퍼에 적합한 크기, 모양, 무게를 가지고 있지 않다는 것입니다. 이러한 문제를 해결하기 위해 저자는 로봇 조작 연구를 위한 6D pose estimation 데이터셋과 benchmark를 공개합니다.
저자는 데이터셋은 다음과 같이 설계하였다고 합니다.
- Accesible
실제 물건은 전 세계 누구나 쉽게 접근할 수 있어야 하므로 온라인에서 구매할 수 있는 장난감 식료품 물체를 선택했음

- Challenging
occlusion, clutter, 다양한 instance 수, 다양한 pose, 까다로운 light condition
- Accurate
이미지에 GT pose를 신중하게 라벨링을 진행했고, 라벨링된 pose error는 mm정도밖에 나지 않았음
저자는 해당 데이터셋을 HOPE(Hosehold Objects for Pose Estimation)라고 명명합니다. HOPE를 구성한 방법은 어떻게 진행하는지 알아보겠습니다.
II. METHOD
A. Set of Object
이번 데이터셋의 목표는 로봇의 조작에 대한 연구라고 합니다. 저자는 다음과 같은 접근법으로 데이터셋을 구성했다고 합니다.
- 데이터셋이 어느정도 현실적이어야 함.
- 물체가 다양한 로봇의 end-effector가 잡기에 적절한 크기와 모양을 가져야 한다.
- 여러 연구자들이 쉽게 접근할 수 있어야 한다.
저자는 이처럼 3가지 정도의 모티브를 가지고 데이터셋을 구성하였고, 로봇 조작 분야에서 최근에는 세탁실이나 주방에서 일상적인 집안일을 자동으로 하는 가정용 로봇이 뜬다고 하네요. 인구 고량화가 증가하고 있는 현 시대에서의 의료 관련 task로도 해결하려고 하는 것을 보면 어플리케이션 관점에서도 가정용 로봇이 많이 뜨는 것을 이해할 수 있습니다. 저자는 물체를 구성할 때 식료품에 대한 실제 품목을 3D 스캔을 통해 사려고 했지만 이러한 방법은 또 근본적인 문제가 있다고 지적을 합니다. 예를 들어 한국에 있는 콘푸로스트 같은 시리얼이 외국에는 없을 수도 있는 문제가 있습니다. 설령 글로벌한 식료품 같은 걸로 하면 되지 않나? 라는 생각을 할 수 있겠지만 표면을 보여주는 그림(텍스처)는 나라 마다 다를 수도 있고 시즌 마다 달라질 수 있기 때문에 문제가 생길 수 있습니다. 또한, 금속성을 지니는 물체들은 3D 스캔 및 렌더링 과정에서 챌린지한 상황이 될 수 있다고 합니다. 이렇게 저자는 다른 연구자들도 실제 물체를 쉽게 접근할 수 있는 것에 대해 초점을 맞추는 것을 볼 수 있네요.

그래서 저자는 그림(1)과 같이 장난감 식료품 28개를 물체로 선정했다고 합니다. 해당 장난감들은 온라인에서 쉽게 구매할 수 있으며, 총 60달러 미만으로 구입이 가능하다고 하네요. 실제 식료품이 아니라서 내용물의 부패나, 운송에 문제가 없을 것이라고 합니다. 구성된 물체들은 일반적으로 사용되는 로봇의 그리퍼가 잡기에 적절한 크기와 모양으로 물체의 한 면의 길이는 최소 2.4cm – 7.2cm라고 합니다.
B. 3D Textured Object Models
각 물체는 EinScan-SE 데스크톱 3D 스캐너로 스캔하여 텍스처가 있는 3D 물체에 대한 mesh를 만들었다고 합니다. 스캔 과정에서 스캐너가 어느 한 면이 약 20cm보다 큰 물체를 처리할 수 없었기 때문에 물체의 크기와 재질에 제한이 있었다고 하네요. 해당 소프트웨어는 텍스처 맵이 쪼개지면서 생성하려는 경향이 있어 Maya를 사용하여 텍스처를 더욱 세분화했다고 하는데, Maya는 3D 모델링을 해주는 프로그램의 종류로 보이는데, 어떻게 세분화를 했다는 건지는 잘 모르겠네요.

그림(2)는 NViSII를 사용하여 렌더링한 텍스처 3D 모델의 합성 렌더링한 결과를 보여주는 그림입니다.
C. Capturing Real Images
데이터셋의 이미지를 얻기 위해 실제 물체를 10개의 서로 다른 환경에 배치하고 각 환경마다 5개의 물체에 대해 배치하고 해당 배치에 대해 카메라 pose를 적용했다고 합니다.

그림(3)은 서로 다른 환경에 물체를 배치한 것을 나타내고 있고, 그림(4)는 break room에서 물체가 어떻게 배치되어 있는지 보여줍니다. 비닐에 들어가 있는 경우, 박스에 들어가 있는 경우, 넘어져 있거나 분산 되어 있는 경우, 쌓여있는 경우, 깔끔하게 잘 정렬된 경우를 나타냅니다. 이렇게 총 50개 scene은 다양한 background, clutter, pose, light을 보여줍니다. 각 scene에 대해 RGB와 depth 이미지를 모두 RealSense D415 RGB-D 카메라를 사용하여 FHD(1920×1080)의 해상도로 취득을 하였고, 로봇이 물체를 잡을 때 일반적으로 사용되는 0.5 ~ 1.0m 거리에서 capture하였다고 합니다.

물체를 환경에 배치하고 카메라를 세팅한 후 조명을 켜거나 끄고 창 블라인드를 여는 등 다양한 조명 조건으로 여러 이미지를 촬영했습니다. 그림(5)와 같이 scene이 정적이므로 Annotation 정보는 변하지 않아 추가 작업이 필요하지 않습니다. 이러한 방식으로 매우 다양한 조명 조건을 수집할 수 있었다고 하네요.
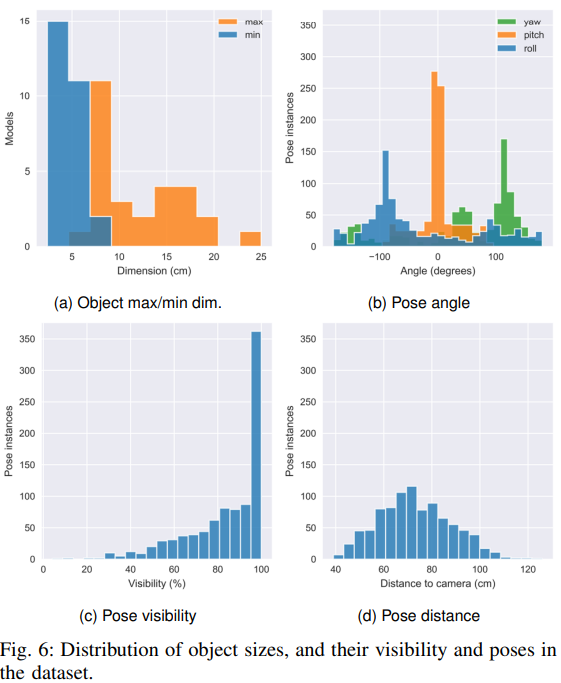
그림(6)은 전체 데이터셋의 모든 instance에 대한 pose 정보들을 의미하며 물체 크기와 다양한 물체 pose, angle, pose visibility, pose distance를 요약한 것입니다. 물체의 최소 크기는 2.4 ~ 7.2cm, 최대 크기는 6.8-25.0cm로 구성되어 있습니다. Average object visibility는 83%이며, 95%이상 visibility를 가지는 경우가 더욱 많은 것을 확인 할 수 있습니다. 물체는 다양한 방향으로 설정되어 있으며, 물체 거리는 최소 39.0cm에서 최대 141.0cm이며 평균 거리는 73.8cm입니다.
D. Annotating Images with Ground Truth
이미지와 3D 모델 간의 corresponding point를 수동으로 찾아서 데이터셋에 GT pose에 대한 annotation을 하였고, 해당 과정은 PnP 알고리즘을 사용하는 Annotation tool에서는 annotator가 물체의 3D 모델과 2D 이미지에 대해서 물체가 존재하는 이미지에서 해당 포인트를 선택한 다음, 3D 모델을 RANSAC 알고리즘을 통해 이미지에 PnP로 정렬하는 법을 사용했다고 하네요. RGB-D를 사용할 경우, 3D 모델과 RGB-D 즉, depth map간의 corresponding이 이루어지며, RGB와 Depth에 대한 align을 맞추는 작업을 진행하게 되며, RGB-D에 대한 annotation tool은 일반적으로 작동 속도가 빠르지만 depth 측정 시 noise나 bias가 발생할 수 있다고 합니다. 대부분의 annotation은 RGB-D tool로 수행되었으며, depth-based annotation이 만족스럽지 않은 경우에만 PnP를 사용했다고 말하는 것을 보아, PnP 과정은 refinement 과정인 것 같습니다. 모든 annotation은 SimTrack에 의해 자동으로 수정을 이루었다고 합니다(?). 이미지와 depth map이 시각적으로 정렬될 때 까지 refinement가 추가적으로 필요한 경우는 수동으로 계속 align을 맞춰주었다고 합니다.
E. Symmetry-Aware Metrics
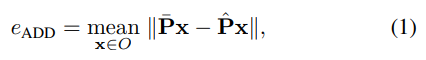
Pose에 대한 추정값을 평가하기 위한 가장 일반적이고 쉽게 해석할 수 있는 지표는 식(1)인 평균 거리 지표인(ADD)입니다. 3D 객체 모델에서 해당 vertex 사이의 mean pairwise distance를 계산합니다. GT는 \bar P, 예측은 \hat P pose를 의미합니다.
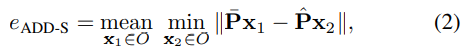
식(1)과 같은 ADD는 물체 대칭을 고려하지 않기 때문에 rotation error와 유사하게 translation error에도 영향을 주므로 예측된 pose를 기반으로 물체에 대한 정보를 제한적으로 제공하게 됩니다. 또한 대칭 물체의 경우 입력 이미지에서 실제 pose를 확인할 수 없는 경우에도 ADD는 예측에 악영향을 줍니다. 이러한 한계를 극복하기 위해 GT 3D 모델의 각 vertex를 예측된 정점과 가장 가까운 pair를 이루는 식(2) Mean Closest Point Distance(ADD-S) 를 사용합니다. 저자는 해당 ADD-S도 비현실적인 pairing으로 인해 pose error를 낮게 평가하는 경향이 있다고 합니다.
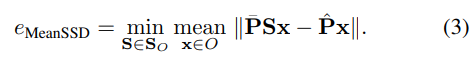
그래서 저자는 MeanSSD라는 식(3)에 대한 평가 지표를 사용한다고 합니다. 대칭을 처리하는 또 다른 방법은 물체에 해당하는 대칭 변환의 S_O 집합을 직접 모델링 하도록 설계합니다. 식(1)의 ADD에서 시작하여 최종적으로 식(3)과 같은 Mean Symmetry-Aware Surface Distance(MeanSSD)를 구할 수 있고 있습니다.
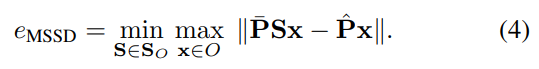
평균 대칭을 계산하려면 주어진 객체에 대해 유효한 모든 (불연속 및/또는 연속) 대칭을 계산하거나 수동으로 찾아야 하므로, 크고 다양한 객체 집합에 대해서는 잠재적으로 cost가 큰 과정이 될 수 있습니다. 식(3)의 평균 연산자를 최대로 바꾸면 Maximum Symmetry-Aware Surface SSD(MSSD)가 된다고 합니다.
(여기까지는 [1]에서 제안된 평가지표를 그대로 사용하는 것 같습니다.)
저자는 부정확한 ADD-S 지표와 수동으로 처리해야 하는 cost가 큰 MeanSSD와 MSSD 지표 사이에 대한 절충안으로 GT와 예측에 대한 vertex 대응을 linear sum assignment problem로 풀어서 만드는 ADD 메트릭의 변형을 제안합니다.
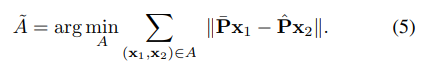
해당 assignment problem에 대한 가장 유명한 해결책은 Hungarian 알고리즘이므로 저자는 이 메트릭을 ADD-H라고 표기하네요. 할당 f_{A} : x_{2} \rightarrow x_{1}은 예측된 pose의 3D 모델에 대한 vertex에서 GT pose의 3D 모델의 vertex로의 bijective mapping을 생성합니다. A = {(f_{A}(x_{2}), x_{2})}를 이러한 대응 집합이라고 하면, pair를 이루는 vertex 사이의 거리의 합을 최소화하는 집합은 식(5)와 같이 계산됩니다.
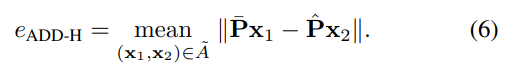
Hungarian 알고리즘을 적용하여 식(5)를 계산한 다음, 식(6)과 같이 assignment된 pair (x_{1}, x_{2}) 사이의 평균 거리를 계산합니다.
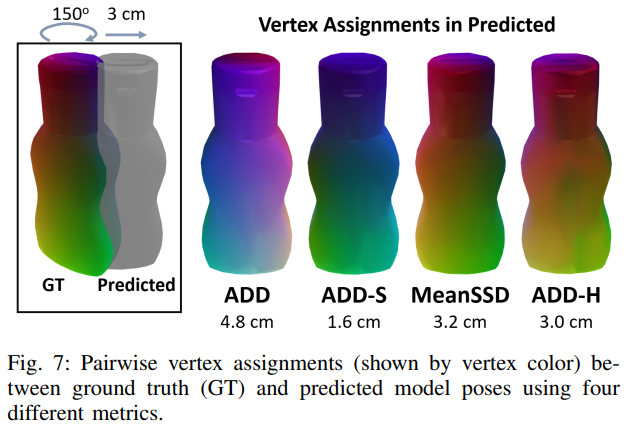
그림(7)은 병에 대한 GT pose와 pred pose에 대한 error를 계산할 때 각 metric에서 사용하는 vertex correspondence를 시각화한 것을 나타냅니다. 제일 좌측에 보이는 렌더링은 pred pose(반투명 회색)가 GT pose(컬러)에서 수직축을 중심으로 150도 만큼 회전하고 물체 너비의 약 절반(3cm)을 수평으로 이동하여 offset된 scene을 나타냅니다. 각 모델의 vertex x_{2}는 GT 3D 모델에 대해 pair를 이룬 vertex x_{1} 따라 색상이 지정됩니다.
ADD는 원래의 vertex 순서를 기반입니다. 다시 말해 고정된 편향적 assignment를 사용하기 때문에 error가 큽니다.
ADD-S는 각 target에 가장 가까운 GT vertex를 assignment하므로 전체 target인 mesh의 녹색과 보라색에 반영된 것처럼 GT의 오른쪽에 있는 점만 사용하는 non-injective mapping이 발생합니다. MeanSSD는 ADD와 동일한 vertex assignment를 사용하지만 error를 최소화하는 symmetry-preserving rotation을 명시적으로 선택하는 과정이 있기 때문에 geometry를 더 잘 나타내는 rotation alignment를 생성하게 됩니다.
ADD-H는 pose 간 bijective mapping을 최적화하여 error를 최소화하고, MeanSSD와 유사하게 pose 대칭을 반영하는 vertex assignment를 달성합니다.
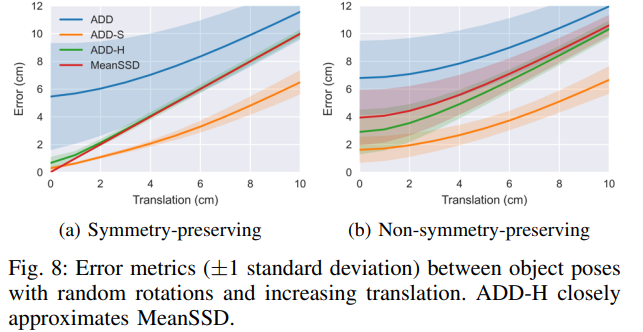
메트릭을 더 비교하기 위해 그림(8)은 각 물체가 초기 위치에서 1cm 단위로 translation될 때 28개의 물체 각각에 대해 5번의 시도에서 평균화된 error를 보여줍니다(Linear한 모습을 다른 지표에 비해 보이는 것을 말하는 것 같네요). 그림(8)(a)에서는 각 물체가 먼저 symmetry-preserving transformation 중 하나에 의해 무작위로 회전 되는 반면, 그림(8)(b)에서는 각 물체가 먼저 임의의 변환에 의해 무작위로 회전됩니다. ADD-H는 특히 rotation이 symmetry-preserving인 경우, 객체 대칭에 대해 직접 설정하지 않고도 MeanSSD error와 거의 일치하는 것을 볼 수 있습니다.
III. EXPERIMENTS
A. Annotation Validation Experiment

GT Pose에 대한 error를 추정하기 위해 3개의 정적 scene을 Orthogonal View(직교된 viewpoint) (카메라 축 간 90도)로 캡처를 했다고 하는데, 정리하면 각 독립된 scene이 존재하는데 첫 번째 scene의 카메라 축이 수직으로 있으면 두 번째 scene의 카메라 축은 첫 번째 카메라 축에 대해 수직이며, 세 번째 카메라의 scene은 앞의 첫 번째, 두 번째 scene과도 수직이라는 것을 의미합니다. 그림(9)와 같이 2개의 독립적인 view에서 annotation을 진행한 것을 확인할 수 있습니다. annotation된 물체에 대한 pose 하나를 제외한 모든 pose에 대해 two view에 대한 extrinsic을 추정했고, 앞서 pose 하나에 대해서 물체의 pose를 첫 번째 view에서 두 번째 view로 projection하고, projection된 pose와 두 번째 view에서 직접 annotation 사이의 ADD error를 계산했다고 합니다. 각 물체를 차례로 이 과정을 반복하여 scene의 모든 물체에 대한 annotation error를 추정했다고 하네요.
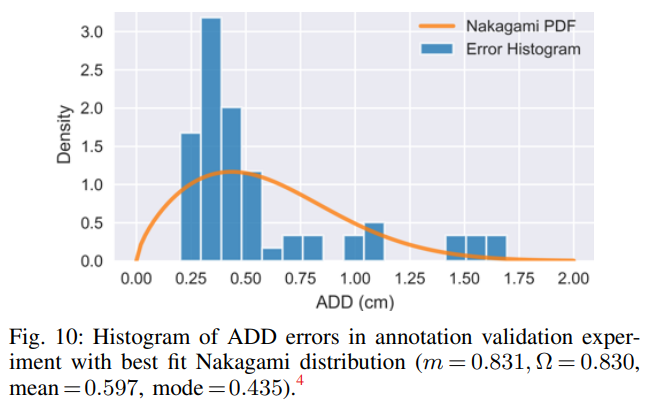
그림(10)은 3개의 scene에 대해 포함된 64개의 instance에 대한 ADD error를 의미하는 histogram인데요. 해당 scene에 대해 mean과 median은 각각 5.7mm와 4.3mm입니다. 따라서 GT 데이터는 단 몇 mm정도의 오차가 있었다고 합니다. 어떤 scene을 사용했는지는 리포팅을 하지 않아 가장 잘 나온 성능을 보여주는 것 같아 조금 아쉽네요.
IV. CONCLUSION
이번 논문에서는 pose estimation을 위한 benchmark 데이터셋을 다루었습니다. 데이터셋에 포함된 3D texture mesh를 사용해 합성 이미지를 렌더링하여 28가지 물체에 대한 pose 추정 모델을 학습할 수 있도록 설계하였습니다. 학습된 모델은 매우 정밀하게 annotation이 된 실제 이미지를 사용하여 평가할 수 있습니다. 저자는 실제로 pose예측을 할 수 있도록 온라인에서 쉽게 구할 수 있는 동일한 물체를 검출하고 조작하기 위해 실험실에서도 직접 사용할 수 있는 것을 강조합니다.
이상으로 리뷰를 마칩니다.
안녕하세요 양희진 연구원님 좋은 리뷰 감사합니다.
해당 논문은 6d pose 데이터셋을 구축하는 논문으로 이해하였는데요, 데이터의 수집 과정을 정리하자면 1)실제 물체를 스캔하여 3d textured model을 생성하고, 2)[그림4]와 같이 해당 물체를 포함하는 rgbd 이미지를 촬영하여 3)이미지와 3d모델의 keypoint matching하여 최종적으로 6d pose데이터셋을 생성하는 것으로 이해하였습니다.
real이미지에서 수집된 instance의 pose 정보에서 궁금한 점이 있는데 pose visibility는 무엇을 의미하는 것인가요? occlusion을 의미하는 것일까요?
안녕하세요, 천혜원 연구원님.
리뷰 읽어주셔서 감사합니다.
이해하신 부분 중에 조금만 수정을 하자면, 3)의 과정은 GT pose를 annotation하는 과정 중으로 matching 통해 2D 이미지와 3D 모델에 대한 correspondence point에 대해 PnP + RANSAC을 통해 최종적으로 pose(R|t)를 구할 수 있게 됩니다.
질문해주신 부분에 대해서는 물체의 실제 보이는 정도를 의미하니 occlusion의 반대라고 보면 될 것 같습니다.
감사합니다.
좋은 리뷰 감사합니다.
6D Pose Estimation 데이터 셋을 구성하기 위하여 고민한 내용이 잘 담겨있는 논문인 것 같습니다.
해당 논문의 검증 방식을 가져오면 데이터 셋의 신뢰도를 높일 수 있을 것 같습니다.
또한, 데이터 셋 취득 뿐만 아니라, symmetric object에 대한 평가지표 설명과 분석, 새로운 평가지표 제안까지 있어 흥미로웠습니다.
평소에 대칭인 객체를 위한 평가지표인 ADD-S에 대하여 모든 정점의 min을 구하는 것이 적절한가에 대한 의문이 있었는데, 이에 대해 대칭 변환 집합을 이용하는 MeanSSD와 MSSD를 이용할 수 있다는 것과,
대응되는 S_o집합을 구하기 위해 수동으로 처리해야 하므로 cost가 많이 드는 문제를 해결하기 위해 ADD-H라는 평가지표를 제안한 것이 인상적입니다.
이와 관련하여 ADD-H에 대한 검증 실험 결과가 Fig.7과 Fig.8에 해당하는 것으로 이해하였습니다.
해당 파트와 관련하여 몇 가지 질문이 있습니다.
1. Fig. 7을 자세히 보면 MeanSSD의 3D object만 180도 회전한 것으로 보이는 데, 이는 Symmetric한 object이므로 상관이 없는 것인가요?
2. Fig. 7을 통해 각 metric의 시각화 결과가 어떻게 나오는 것이 적절한 것이며, 각 metric 아래의 숫자는 무엇을 의미하는 지 설명해주실 수 있나요?
3. MeanSSD가 symetric에 대하여 가장 정확한 평가지표라고 이해하면 될까요?
안녕하세요, 이승현 연구원님.
리뷰 읽어주셔서 감사합니다.
1. 대칭인 물체라 상관없다기 보다는 error를 최소화하는 symmetry-preserving rotation을 명시적으로 선택하는 과정이 있기 때문에 정확하게 몇도만큼 회전을 했는지는 모르겠지만 이승현 연구원님의 말씀대로 180도만큼 회전을 해야 저정도의 성능을 낼 수 있었던 것으로 보입니다.
2. 그림(7)을 기준으로는 가장 오른쪽에 있는 그림이 적절한 것이며, 아래의 숫자는 error distance를 나타냅니다. ADD-S가 error가 가장 낮지만 비현실적인 pairing을 통해 pose error를 낮게 평가하는 경향을 보이는 것을 보이는 것을 증명한 것이라고 봅니다. GT와 유사한 색을 띄는 MeanSSD와 ADD-H에 비해 error pose가 낮은데도 불구하고 pair를 이루는 vertex의 수가 적어 GT와 비교했을 때 색상의 차이가 나는 것을 볼 수 있습니다.
3. 상황에 따라 다를 것이라고 판단은 들지만, 해당 데이터셋에 대해서는 저자가 새롭게 제안한 ADD-H가 가장 정확한 지표라고 볼 수 있습니다. 물론 MeanSSD가 정확할 때도 있겠지만 매번 수동으로 rotation 정도를 명시적으로 나타내야 하기 때문에 이러한 cost를 들이지 않도록 설계한 ADD-H는 비슷한 성능을 보이는 것뿐만 아니라, 오히려 좀 더 좋은 성능을 보이는 것을 보아 ADD-H가 좀 더 정확한 지표라고 할 수 있을 것 같습니다.
감사합니다.