이번 주 리뷰는 Wav2CLIP이라는 논문으로 Contrastive Language–Image Pre-training (CLIP)에서 파생된 audio representation learning method입니다.
우리가 기존에 알고 있던 CLIP은 image와 text를 동일 feature space로 projection하고 두 모달리티 간의 contrastive learning을 진행합니다.
Wav2CLIP이란 여기에 추가적으로 audio representation을 추가하는 방법론으로, CLIP을 통해 생성된 image-text의 feature space에 audio representation을 projection합니다. 구체적으로는 audio encoder를 통해 feature를 추출하여 CLIP의 image encoder로 부터 추출된 image representation과의 contrastive loss를 계산합니다. 이를 통해 audio, image, text representation을 하나의 shared embedding space에 위치시킬 수 있어 여러 multimodal application에 적용할 수 있다고 합니다.
논문에서는 classification을 비롯하여 retrieval, generation task에서 평가하여 Wav2CLIP이 기존의 여러 pre-trained audio representation알고리즘의 성능을 뛰어넘는 것을 보였습니다.
Introduction
Self-supervised learning은 컴퓨터 비전, 자연어 처리 뿐 아니라 음성 인식 분야에서도 좋은 결과를 가져왔습니다. large unlabeled 데이터를 통한 self-supervised 방식의 사전 학습을 통해 데이터의 내재적 구조를 파악함으로써, supervised learning에서는 필수적은 human annotation 없이도 강인한 representations을 학습할 수 있게 되었죠.
이러한 self-supervised learning 분야에서 주목받고 있는 모델 중 하나는 CLIP인데요, 텍스트와 이미지의 상관 관계를 학습에 활용하여 zero-shot image classification, image retrieval via text 등 여러 task에서 SOTA를 달성하였다고 합니다. CLIP은 인터넷에서 수집된 대량의 이미지/텍스트 쌍에 대해 두 모달리티의 데이터 쌍이 서로 대응되는지를 예측하는 contrastive loss 통해 모델을 학습한다고 하며, 이를 통해 CLIP은 두 도메인에서 일반화된 표현을 학습할수 있다고 합니다.
CLIP이 text와 image간의 대응 관계를 학습하였다면, 저자들은 audio모달리티를 clip에 활용하고자 하였는데요, 이 논문에서 저자들은 CLIP 모델에서 추출하여 학습한 audio-visual correspondence 모델인 Wav2CLIP을 제안하였습니다. Wav2CLIP은 아래 [그림1]과 같이 visual encoder는 사전 학습된 CLIP의 vision 모델을 사용하고, audio encoder를 새롭게 추가하여 audio encoder만을 학습합니다.
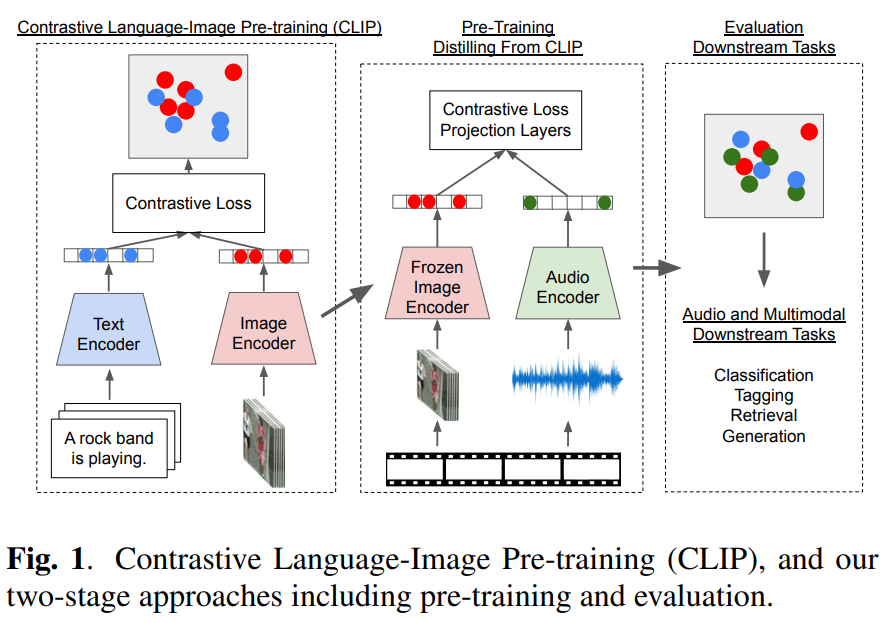
Audio encoder를 학습할 때 CLIP의 visual encoder를 freeze한 채로 학습을 진행합니다. 즉, audio stream에서만 학습이 진행되므로 video, audio stream을 동시에 학습하는 기존 방법론들 보다 학습 recipe가 가벼워졌습니다.
또한 이미 text-image로 학습된 CLIP 모델을 video-audio로 확장시키는 개념이기 때문에 학습이 완료된 Wav2CLIP은 v-a 뿐 아니라 text와도 aligned되어 있게 됩니다. 이로 인해 audio classification, audio captioning, cross-modal audio retrival과 같이 audio-text를 사용하는 task에도 사용 가능하다고 합니다.
Method
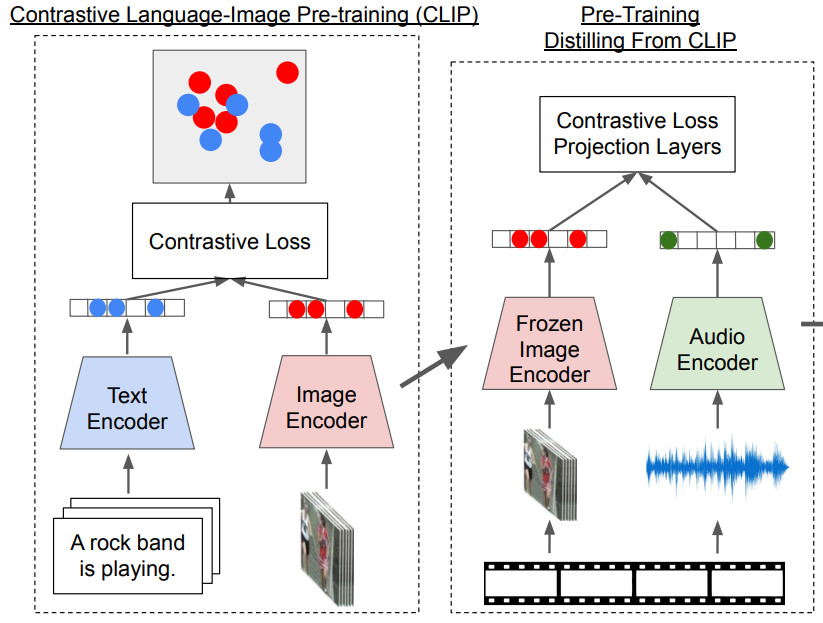
CLIP은 인터넷에서 수집된 대량의 image-text pair를 noise-contrastive estimation을 통해 학습합니다. 이때 같은 sample에서 나온 pair는 positive example로 사용되고, 동일 batch 내의 다른 모든 pair는 negative로 취급하였습니다. [그림 1] 왼쪽과 같이 CLIP의 image와 text representation은 shared embedding space로 투영됩니다. 이러한 방식을 사용했을 때 natural language에 해당하는 text는 flexible 한 prediction space에 mapping되어 knowledge를 일반화하고 전달하는 데 도움이 될 수 있으며, continous한 image는 text의 discrete한 symbolic space에 mapping될 수 있다고 합니다. 결국 서로 다른 모달리티를 동일 space에 위치시키는 것을 통해 각 데이터의 중간 특성을 갖게 된다는 것으로 이해하면 될 것 같습니다. 결과적으로 CLIP은 zero-shot classification과 cross modal retrieval과 같은 task에 큰 성공을 보여주었다고 합니다.
그렇다면 이제 Wav2Clip에 대해 알아보겠습니다. 논문의 방법론 자체는 [그림 1]과 같이 두 단계로 구성되어 있는데, 먼저 CLIP image encoder를 가져와 video로부터 image embedding을 추출하여 audio encoder를 pre-training 합니다. 이때 저자들은 CLIP 논문과 동일하게 contrastive loss를 사용하고, 추가로 MLP를 projection layer로 사용하는 실험을 진행하였다고 합니다. 이때 저자들은 경험적으로 cross projection으로 정의된 CXLoss = L(f(Image), Audio) + L(Image, g(Audio))가 CLIP의 distillation 절차를 안정화하는 데 도움이 되는 것을 발견하였습니다. CXLoss에서 L은 contrastive loss, f()와 g()는 projection funtion을 의미합니다.
논문에는 CX Loss가 추가적인 learnable MLP layer를 제공하여 더 많은 flexibility를 부여하기 때문이라고 합니다. 이러한 추가적인 MLP 레이어는 multimodal consistency를 강화하며 audio embedding을 학습된 audio embedding projection layer를 통해 CLIP image embedding으로 복원할 수 있다고 합니다. 학습 과정에서 원래 CLIP 모델의 가중치는 고정된 상태로 유지되며, audio encoder의 학습이 완료되면, audio와 video encoder는 고정된 feature extractor로 사용됩니다.
Experimental Design
제안하는 방법론이 self-supervised로 audio encoder를 사전 학습시키는 것이므로 downstream task의 성능을 측정하였습니다. 실험은 크게 사전 학습된 CLIP을 바탕으로 audio encoder를 사전 학습시키는 pre-training 부분과 학습된 Wav2CLIP을 fine tuning하여 downstream task를 수행하고 그 성능을 평가하는 evaluation 부분으로 나뉘며 각각은 아래와 같이 설계하였습니다.
Pre-training: Distilling from CLIP
우선 audio encoder는 VGGSound논문의 base 모델을 baseline으로 설정하여 해당 모델의 feature extractor인 ResNet-18을 사용하였다고 합니다. Audio 데이터는 1차원의 raw audio waveform을 2차원의 spectrogram으로 변환한 후 ResNet에 입력하고, average pooling을 사용하여 전체 오디오에 대해 512 차원의 emgedding을 출력하였습니다. Audio retrieval이나 audio captioning과 같이 frame level의 embedding이 필요한 경우, 1초 간격의 non-overlapping window로 input segment를 취하여 시간 축에 따른 embedding을 뽑아냈다고 합니다.
사전 학습에는 VGGSound 데이터셋을 사용하였습니다. 당연히 label은 사용하지 않고 audio-video 만을 사용하였다고 합니다.
Evaluation: Downstream Tasks
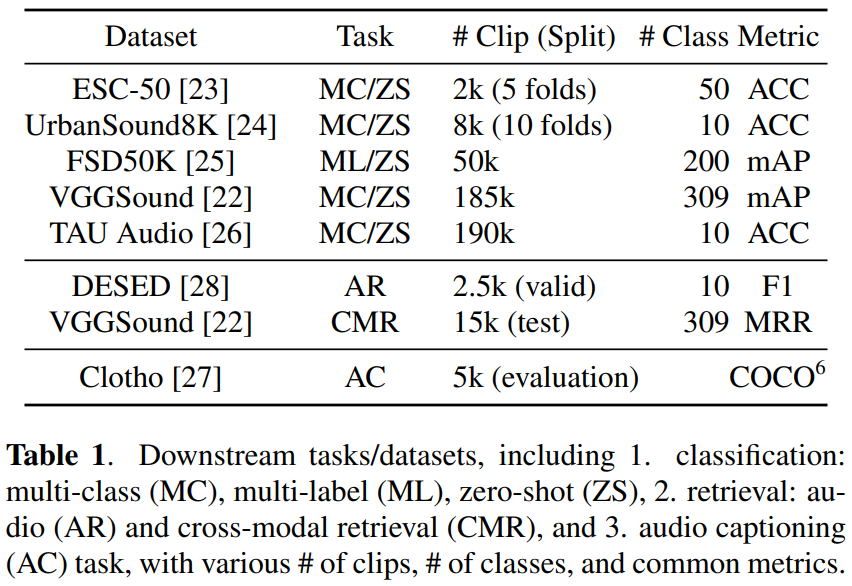
사전 학습이 완료된 Wav2CLIP의 가중치를 고정시켜 여러 downstream task에서 feature extractor로 사용하였습니다. 크게 audio classification, audio retrival audio captioning을 수행하였으며, 각 task별 fine-tuning에 사용된 데이터셋은 아래의 [표 1]과 같습니다.
Results and Discussions
이제 실험 결과에 대하 알아보겠습니다.
저자들은 audio classification, audio retrieval, audio caption을 실험하였고, 아래의 [표2]는 그 중 방법론에 따른 classification과 retrieval 성능을 나타낸 표입니다.
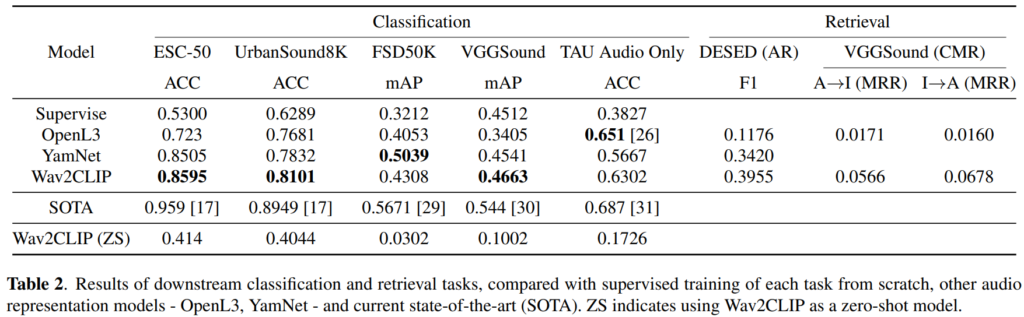
[표 2]을 보면 surpervise, OpenL3, YamNet, Wav2CLIP에 SOTA의 평가 결과를 비교한 것을 볼 수 있는데요, 이때 supervise를 제외한 OpenL3, YamNet, Wav2CLIP은 서로 다른 pretext task로 학습된 self-supervised 방식의 사전 학습 모델이며, SOTA는 각 데이터셋에서 가장 좋은 성능을 낸 모델로 각 task의 upper bound와의 비교를 위히 리포팅하였다고 합니다.
먼저 classification 결과를 살펴보겠습니다. [표 2]에서 볼 수 있듯, Supervised baseline은 VGGSound를 제외하고 모든 task에서 성능이 좋지 않습니다. VGGSound는 다른 데이터셋과 달리 대량의 annotated 데이터로 구성되어 있는데, 이를 통해 pre-trained 모델이 labeled 데이터가 제한된 task에 특히 유용하다는 것을 보였다고 합니다. Wav2CLIP을 다른 audio representation과 비교하면, Wav2CLIP이 거의 모든 task에서 YamNet과 OpenL3와 비슷하거나 더 나은 성능을 보이는 것을 확인할 수 있습니다.
다음으로는 retrieval 결과를 살펴보겠습니다. [표 2]의 오른쪽 부분을 보면 Audio Retrieval (AR) task에서도 Wav2CLIP은 frame-level feature extractor로 좋은 성능을 내는 것을 확인할 수 있습니다. OpenL3은 audio-visual로 사전 학습된 모델임에도 불구하고, shared embedding space로 projection 되지 않아 성능이 떨어진다고 합니다. 아래 그림이 OpenL3의 구조인데 각 모달리티의 feature를 fusion한 뒤 audio와 비디오의 correspondence를 분류하는 방식으로 학습하는 것 같네요.
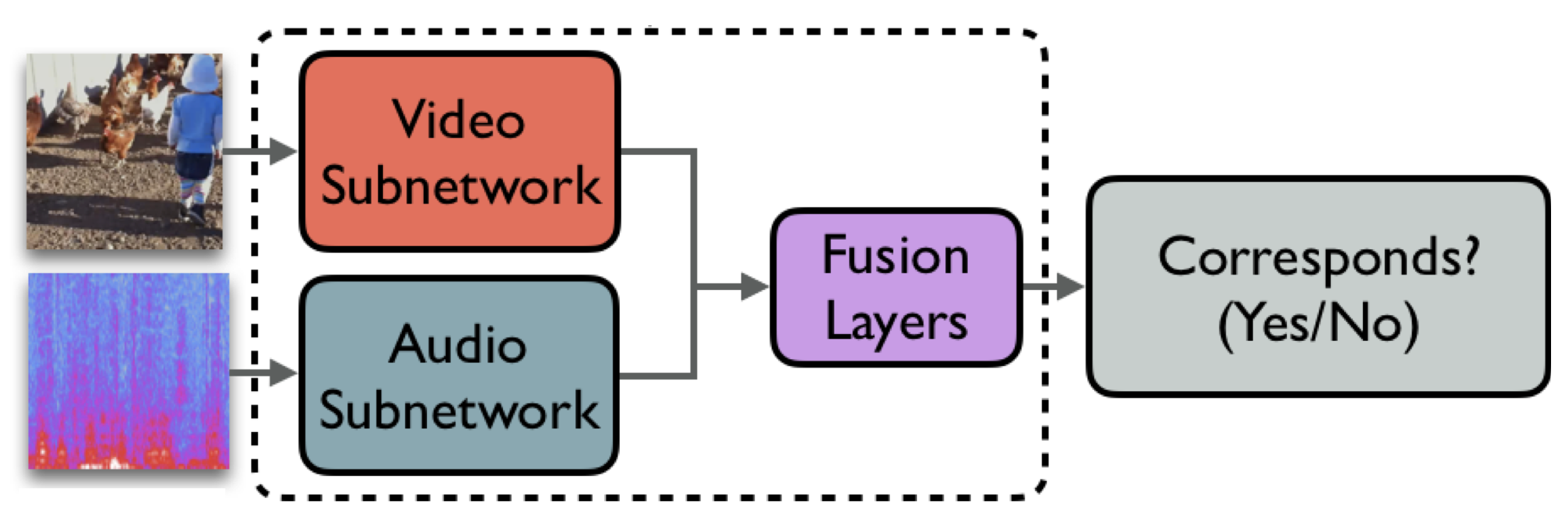
마지막으로 audio captioning 결과를 살펴보겠습니다.
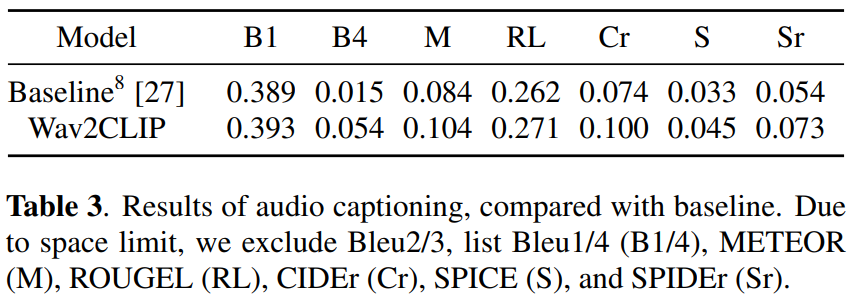
Audio Captioning (AC)에 대한 결과는 위의 [표 3]에서 확인할 수 있는데요, 모든 metric에서 baseline을 약간 앞선 성능을 달성한 것을 볼 수 있습니다. 논문에서는 encoder와 decoder의 구조가 다르기 때문에 성능만을 비교하는 것이 공정한 비교가 아니라고 언급하였으나, Wav2CLIP을 다양한 task에 쉽게 적용할 수 있으며 여러 task에서 합리적인 성능을 보인다는 것에 의의가 있다고 하였습니다.
안녕하세요 혜원님 좋은 리뷰 감사합니다. Audio encoder를 학습할 때 CLIP의 visual encoder를 freeze함으로써 학습 recipe가 가벼워졌다고 하셨는데 학습 recipe가 가벼워졌다는 게 무슨뜻인지 궁금합니다. 또 freeze하지 않는다면 freeze했을 때와 결과에는 차이가 없는지 궁금합니다. 그리고 Clip의 image와 text representation은 같은 embedding space로 투영되는 것이 각 데이터의 중간 특성을 갖게 되는 것으로 이해하면 된다고 해주셨는데 각 데이터의 중간 특성을 갖는 것이 왜 중요한지 궁금합니다.
안녕하세요 박성준 연구원님 댓글 감사합니다.
학습 recipe가 단순해졌다는 의미는 말 그대로 학습이 간단하고 효율적으로 진행될 수 있음을 의미하는데요, [그림 2]의 CLIP과 같이 두 모달리티의 encoder를 동시에 학습하게 된다면 Wav2CLIP은 video, audio의 encoder를 동시게 학습하게 되기 때문에 audio encoder만을 학습하는 것 보다 많은 연산 비용이 들고 최적화가 조금 더 복잡해지겠지요.
두 번째 질문 같은 경우 애초의 논문의 컨셉이 CLIP의 지식을 distill한다는 것이기 때문에 visual encoder를 freeze하였습니다. 따라서 scratch에서의 학습 결과는 없는 것 같네요.
마지막 질문은 데이터의 중간 특성을 갖는 것이 중요하다기 보다는 CLIP에서 이미지와 텍스트를 같은 임베딩 공간으로 투영했기 때문에 sparse한 text는 보다 dense하게, dense한 video는 sparse한 방향으로 feature가 추출된다는 의미입니다.