안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 지난번에 이은 Active Learning(AL) 분야의 논문입니다. 하지만 지난 논문들과 같이 방법론을 제안하는 논문이 아니라, 기존 방법론들에 대한 분석과 AL의 파이프라인에서 고려해야 할 다양한 변수(하이퍼파라미터 등)에 대한 실험 및 분석 논문입니다. 따라서 기존 논문에서 흔히 보이는 intro-method-experiment 형식과는 논문의 구성이 사뭇 달랐습니다. 본문은 전반적으로 다양한 실험을 통해 도출한 저자의 해석을 요약 정리한 느낌이고, 세부적인 사항은 supplementary material에 수록되어 있었습니다. 개인적으로 이런 형식의 논문을 읽어보는 것은 처음이라 신선하기도 하고, 이후 AL관련 실험 세팅 할 때 이 논문의 분석을 참고하면 좋을 것 같다는 생각이 드네요. 논문은 전반적으로 현재 AL 연구에 대한 통일된 기준이 없음에 문제를 지적하고, 통일된 실험 세팅이 필요함을 강조하고, 통일되지 않은 다양한 요인에 대한 비교 분석을 제시합니다.
AL은 데이터 취득 및 라벨링에 높은 비용이 소모되는 것에 의한 데이터 부족 문제를 해결하기 위해 연구되고 있는 분야로, unlabeled data 중에 라벨링 효율이 좋은 데이터를 선별하는 것을 목표로 합니다. 학습 초기에 소량의 initial labeled data를 가지고 AL 모델을 학습 시킨 다음, 이를 바탕으로 unlabeled data pool에서 일정량의 데이터를 선별에서 이 데이터들을 라벨링하고, 추가된 데이터들을 활용해서 다시 모델을 학습 시키고 .. 의 과정을 반복합니다. AL 연구에는 크게 두 가지 연구 갈래가 있습니다. 1. 모델이 어려워하는 데이터가 학습 효율이 높을 것이라는 가정에서 접근을 시도하는 uncertainty 기반 연구와, 2. 전체 dataset의 분포를 잘 반영하는 subset을 추출하고자 하는 diversity 기반 방법이 있습니다. AL에 대한 추가적인 설명이나 각 접근법에 대한 추가적인 궁금증이 있으신 분은 저의 이전 리뷰(uncertainty 기반 CEAL, diversity 기반 Core-set)를 참고하시면 좋을 것 같습니다. 리뷰 시작하겠습니다.
Abstract
딥러닝의 큰 단점 중 하나는 양질의 학습 데이터가 많이 필요하다는 것입니다. 딥러닝의 라벨링 효율을 높이기 위한 방법으로 Active Learning(AL)은 점점 더 많은 관심을 받고 있습니다. 하지만, 현재 대부분 실험 세팅에는 몇몇 문제점들이 있고, 이는 대부분 통일된 구현 및 벤치마킹의 부재에서 비롯합니다. 이에 AL 실험 및 성능에 대한 상반된 결과, 주요 factor에 대한 의도적인 배제, Data augmentation이나 SGD같은 중요한 generalization 접근법 미적용, AL의 라벨링 효율과 같은 평가 측면에 대한 연구 부족, AL 이 Random Sampling(RS)를 능가하는 명확성 및 근거 부족이 문제로 지적되고 있습니다. 본 논문에서는 새로운 오픈소스 AL 툴킷 DISTIL1을 통해 이미지 분류 task에서 SOTA AL 알고리즘의 통합 재구현을 제시하고, 위에서 언급한 문제들을 효과적인 평가 측면에서 면밀히 연구합니다. 긍정적인 요인으로는, Data Augmentation을 사용한 AL은 Random Sampling보다 2~4배 라벨링 효율이 좋다는 것을 보였습니다. 놀랍게도 Data augmentation을 적용하면, 당시 SOTA 방법론인 BADGE가 더 이상 단순한 uncertainty sampling보다 좋은 성능을 보이지 못했습니다. 추가적으로 이후 AL을 이용하길 원하는 사람들에게 AL 배치 크기, 초기 라벨 셋 구성, round마다 모델 재교육 등 실무자가 고려해야 할 점들에 대한 insignt를 제공합니다.
Introduction
최근 딥러닝은 다양한 분야에 접목되어 상당히 성공적인 성능을 보여주고 있는데, 이는 신경망을 훈련시킬 방대한 양의 데이터 덕분입니다. 대량의 데이터를 이용하면 딥러닝이 어느정도 성공적인 성능을 보장하지만, 데이터셋을 취득하고 이를 라벨링 하는 과정은 비용 및 시간이 많이 듭니다. 특히 task에 따라 annotation은 데이터 수집보다 훨씬 시간적으로, 비용적으로 cost가 높습니다. Active Learning은 원하는 test accuracy를 달성하는데 필요한 가장 적은 양의 labeled data를 샘플링하여 이 문제를 완화하고자 합니다. 여기에는 uncertainty, diversity, combination 등의 기법을 사용합니다.
deep AL에 대한 연구가 활발해지고 다양한 논문이 나오며 많은 발전을 이루었지만, 몇몇 문제가 남아있습니다. 대표적으로는 과거 몇몇 연구에서 특정 베이스라인에 대한 큰 accuracy 차이, 특정 알고리즘의 성능 결과에 대한 모순된 결과(논문마다 random sampling / uncertainty / diversity 방법론들의 정확도 순위가 완전히 뒤바뀐다던지 등) 등이 있습니다. 이 문제들은 대부분 hyperparameter, 학습 알고리즘 등 세부 구현에 많은 차이가 있기 때문입니다. 논문마다 다른 baseline을 사용하거나, 비교에서 주요한 몇 baseline이 사용되지 않기도 합니다. 또한 대부분의 AL 연구는 generalization 성능을 크게 향상시켜 주는 data augmentation을 이용하지 않았고, 심지어 일반화 성능을 저해하는 adaptive optimizer(Adam, RMSProp)를 사용하기도 했습니다(adaptive optimizer는 SGDM보다 일반적으로 수렴이 빠르지만 generalization 성능이 떨어진다고 알려져 있습니다). 이 뿐만이 아니라, 실무자를 위한 여러가지 중요한 세부 사항 및 원칙이 명확하지 않습니다. a) 모델 훈련은 매번 다시 시작해야 하는가, 아니면 현재 모델을 fine-tuning해도 되는가? b) AL에서 세심하게 만들어낸 seed(초기 라벨셋)를 사용하는 효과는 정확히 무엇인가? c) AL에 이상적인 배치 사이즈가 있는가? 실제로 배치 사이즈가 중요한 영향을 미치는가? d) Random Sampling보다 AL이 언제 더 효과적이며, AL알고리즘의 라벨링 효율에 영향을 미치는 요인이 무엇인가? 마지막으로, e) AL 알고리즘은 얼마나 scalable한가? 구체적으로, 모델 훈련에 걸리는 시간과 AL 선택에 걸리는 시간이 얼마나 되며, AL은 실제로 계산적으로, 에너지적으로 더 효율적인가? 저자들은 이 모든 질문들에 대해 image classification task에서 연구를 수행합니다. 이를 위해 대부분의 AL 알고리즘을 통합적으로 module형식으로 재구현했다고 합니다.
실험 수행 결과 주요한 발견 및 이점은 다음과 같다고 합니다 :
- data augmentation 및 다른 일반화 접근법은 라벨링 효율뿐만 아니라 test 성능에도 큰 영향을 미친다. ResNet-18을 CIFAR-10 데이터셋에 적용한 결과, data augmentation을 사용한 대부분의 AL 접근법이 CIFAR-10에서 13k개의 labeled point로 90% 이상의 accuracy를 달성하며, 대부분의 데이터셋에서 2배~4배의 라벨링 효율을 달성함을 보여준다. 데이터 증강 기법은 test 성능을 크게 향상시킬 뿐 아니라 Random Sampling에 대한 라벨링 효율도 향상시킨다.
- 이전 연구들에서 보였던것과 같이, Adam보다 SGD가 AL에서 일관적으로 더 잘 수행되고 잘 일반화된다는점을 보였다.
- data augmentation 과 SGD optimizer를 사용하는 경우, (적어도 대부분의 표준 데이터셋에서) diversity 기반 방법론들은 매우 간단한 uncertainty sampling보다 별다른 이득이 없다. 특히, (당시 SOTA인) BADGE의 성능은 entropy나 leaset confidence같은 uncertainty sampling 접근법보다 일관적으로 높지 않았다.
- (augmentaion을 통해 data point를 반복시키는 방법 등으로) 데이터셋을 인공적으로 반복적으로 만들면, BADGE가 uncertainty sampling성능을 뛰어넘기 시작한다. 반복적인 데이터가 많아질수록 이 격차는 더 커지는데, 이는 비디오 프레임 등 중복이 많은 데이터셋에서는 BADGE와 같은 접근법을 취하는게 좋다.
- class당 instance 수가 AL 알고리즘의 성능에 중요한 영향을 미친다는 것을 알 수 있었다. 클래스당 데이터가 작을수록, AL이 random sampling보다 좋을 여지가 적아졌다(이는 라벨링 효율을 저하시킨다)
- 저자들은 labeled set initialization의 역할과 AL batch size 선택을 연구했다. 결과적으로 labeled seed set의 초기화는(random set과 다양성 혹은 representation seed set) 몇 라운드 이후 AL 성능에 거의, 혹은 전혀 영향을 미치지 않는다는 것을 발견했다. 마찬가지로 AL batch size의 선택도 큰 영향을 미치지 않았다.
- 모델을 처음부터 retrain 하는 것과, 이전 라운드에서 모델을 업데이트 하는 것(fine-tuning)은 early selection rounds에만 성능에 영향을 미친다는 것을 알 수 있었다. 모델이 안정화되면 두 전략 간 성능 차이가 사라진다.
- 마지막으로, 저자들은 AL의 총 처리 시간과 에너지 소비를 연구한다. 저자들은 AL loop대서 대부분의 시간 및 에너지 비효율성은 모델 (재)학습에서 비롯된다는것을 발견했다. 저자들은 AL batch size와 finetuning의 영향에 대한 저자들의 발견을 적용하여 AL의 요소를 발전시키는게 가능한 전략을 제안하고, 모델 훈련을 가속화하기 위해 Data Subset Selection (DSS)기법의 사용에 대해 알아보았다. 그리고 이 방법이 매우 미미한 정확도의 희생을 동반하며 훈련 시간을 3배 발전시킴을 보였다.
이에 따라 저자들은 AL에 대한 효과적인 평가 측면에서 단점을 해결하는데 도움이 될 수 있는 관찰 결과를 공유합니다.
Facets of Effective Evaluation
주요한 발견의 맥락을 이해하기 위해 AL에 대한 효과적인 평가 측면 몇 가지를 살펴보겠습니다.
P1: Unified Experimental Setting.
효과적인 AL selection 알고리즘 비교를 위해서는 당연히 실험 세팅에 신경써야 합니다. optimizer, learning rate, scheduler, AL batch size, labeled set initialization, 그리고 다른 파라미터들은 지금까지 나온 논문들에서 전혀 통일되지 않은 채 선택되었습니다. AL 접근법들을 적절히 비교하기 위해서는 통일된 세팅이 필요합니다. 여기서 저자들은 DISTIL이라는, 당시 대부분의 SOTA AL 접근법들의 통일된 재구현 코드를 활용해 실험을 진행했다고 합니다.
P2: Emphasis on Labeling Efficiency.
대부분 AL 연구들은 test accuracy를 labeled data 수에 따라 그 결과를 비교합니다(가로축을 labeled data 수, 세로축을 test accuracy로 놓고 그래프를 그리는 형식). 이런 방법이 baseline과 비교하여 해당 알고리즘의 이점을 강조할 수는 있지만, random sampling과 비교해 해당 알고리즘의 라벨링 효율을 직관적으로 나타내 주지는 않는다고 합니다. AL 알고리즘은 가능한 한 적은 라벨을 가지고 target test accuracy를 달성하는 것을 전제로 하기 때문에, random sampling과 비교하여 얼마나 적은 라벨로 달성했는지가 명확히 보여야 한다고 합니다. 저자들은 여기에서 라벨링 효율성 플롯을 사용해서 이를 강조하고, 향후 작업에서는 이를 고려한 연구가 수행되기 기대한다고 합니다.
P3: AL with Data Augmentation.
저자들은 data augmentation의 영향에 대해서도 연구를 수행했습니다. data augmentation이 딥러닝 전반에 걸쳐 매우 일반적인 도구임에도 불고하고, AL 연구에서는 잘 사용되지 않고 이에 관한 report도 부재하다고 합니다. 예를 들어, (당시) SOTA 인 BADGE라는 접근법은 AL이 끝날 80%(아마 test accuracy를 말하는것 같습니다)을 약간 넘는 수준에 그친 반면, data augmentation을 적용한 SOTA 훈련으로는 대부분의 모델에서 90%이상을 달성했다고 합니다(정확도 향상과 더불어 라벨링 효율도 향상시킨다고 합니다). 한가지 놀라운 점은, 데이터 증강을 적용했을 때 BADGE와 같은 diversity 기반 접근법이 더 이상 simple entropy sampling을 능가하지 못했다고 합니다. 이에 저자들은 data augmentation이 일반적으로 학계에서 사용되는 데이터셋에서의 low-redundancy setting에서 선택된 데이터 인스턴스에 diversity를 제공하는데 도움을 줄 수 있다고 가정합니다.
P4: AL with SGD and Other Generalization Approaches.
AL에서의 optimizer 효과를 분석했습니다. 일반적으로 Adam이 SGD보다 generalization 측면에서는 약점이 있다고 알려져 있는데, 대부분의 AL 접근법이 Adam 및 RMSProp과 같은 adaptive optimizer를 사용한다고 합니다. 이에 저자들은 Adam 대신 SGD를 선택하는것이 (data augmentation을 추가하는것처럼) 일반화 성능을 향상시키는지 궁금증을 가졌다고 합니다. Adam과 SGD가 어떻게 다른지 실험해보고, Adam이 SGD보다 수렴이 빠르지만 일반적으로 라벨링 효율과 일반화 성능이 떨어진다는것을 발견했다고 합니다.
P5: Redundancy.
딥러닝의 발전으로 redundant dataset(중복이 많은 데이터)이 많아졌지만, AL 알고리즘 성능 평가 실험에서는 고려되지 않았다고 합니다. 이는 실제 상황 적용에서 성능 저하로 이어질 수 있습니다. 저자들은 CIAFAR-10 데이터셋을 점진적으로 복제하여 중복 효과를 검토했다고 합니다. (중복은 augmentation과 비슷하게 수행되어 비슷한 데이터가 많아지게 하는 것으로 받아들였습니다. 비디오 데이터 같은 경우에는 비슷한 프레임이 많으므로 redundant한 데이터라고 할 수 있겠네요). 결과적으로 BADGE와 같은 다양성 기반 방법은 중복 데이터에 강건한 반면, entropy sampling같은 uncertainty 기반 방법은 중복 데이터르 제대로 처리하지 못했다고 합니다.
P6: When does AL offer benefit compared to random sampling?
대부분 과거 AL 연구는 언제 AL이 random sampling보다 이점을 갖는지 가이드라인을 제시하지 않았습니다. 저자들은 클래스 당 데이터 수가 AL이 얼마나 큰 이점을 가질 수 있는지와 관련있다는 가설을 가지고 실험을 수행했습니다. 실험은 클래스당 인스턴스 수를 제한해서 수행되었습니다.
P7: AL Batch Size and Seed Set Initialization.
AL batch는 이전에 너무 다양하게 설정되었습니다. AL의 효과적인 평가를 위해서는 적절한 AL batch 크기에 대한 효과도 고려되어야 합니다. AL 배치 크기가 달라지면 실제 적용에서 정확도에 차이가 있을지에 대한 실험이 수행되었습니다. 또한, 초기 라벨 셋을 어떻게 설정하는지에 대한 효과도 연구되었습니다. 저자들은 실험을 통해 AL 배치 크기나, 초기 라벨 셋 설정이 (일정 이상의 데이터가 추가되면) 크게 주요한 영향을 미치지 않는다는 결론을 내립니다
P9. Model Updating versus Model Retraining.
라운드마다 모델을 처음부터 재교육 하는 것과, 이전 라운드 모델을 fine-tuning하는것의 차이를 살펴봅니다. 학습 초기에는 모델 업데이트가 모델 재학습보다 성능이 떨어지는 것을 확인했지만, 모델이 성숙해지고 안정되면 이러한 차이는 사라진다고 합니다. 또한 Adam을 사용하고 data augmentation을 사용하지 않으면 모델 업데이트가 모델 재학습에 비해 일관되게 성능이 저하된다는것을 발견했다고 합니다.
P9: Scalability.
AL은 데규모 데이터셋에서 수행될 수 있으므로, 확장 가능성과 이에 고려할 요소를 살펴봅니다. AL에서 소요되는 대부분의 시간은 sampling보다 모델 훈련이라는것을 확인합니다. 따라서 AL 배치를 크게 만들어서 모델 훈련 수를 줄이거나, 모델 재학습보다는 모델 업데이트로 학습에 소요되는 시간을 줄이는 방법을 고려할 수 있다고 합니다. 이런 방법으로 성능에 대한 희생은 거의 없이 모델 학습 시간을 단축시킬 수 있다고 합니다.
Experiments
여기서는 위에서 언급한 사항들에 대한 실험 결과를 보여줍니다. data augmentation으로 flipping과 random cropping, image padding, data normalization을 적용했다고 하며, 데이터셋은 CIFAR10/100, MNIST, Fashion MNIST, SVHN이 사용됐다고 합니다.
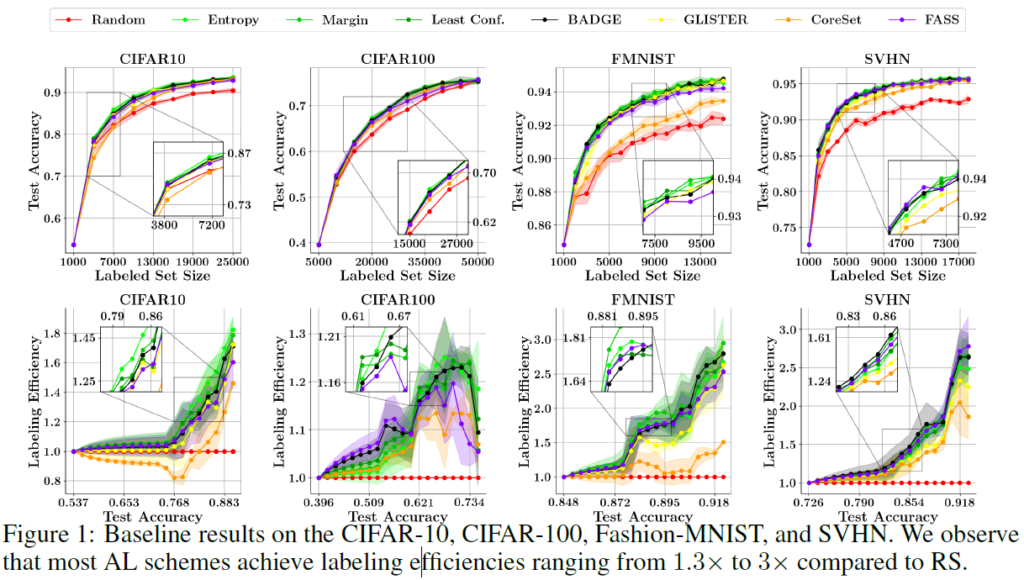
우선 베이스라인과 라벨링 효율성에 대한 그래프입니다. 아까 위에서 기존 논문들은 test accuracy만 보고하고 labeling 효율을 random sampling과 비교하지 않았다고 언급했는데, 아래 있는 그래프가 효율성을 나타냅니다. 라벨이 효율이 1.3x(CIFAR100)에서 3x(SVHN)까지 높아지는 것을 확인할 수 있습니다.
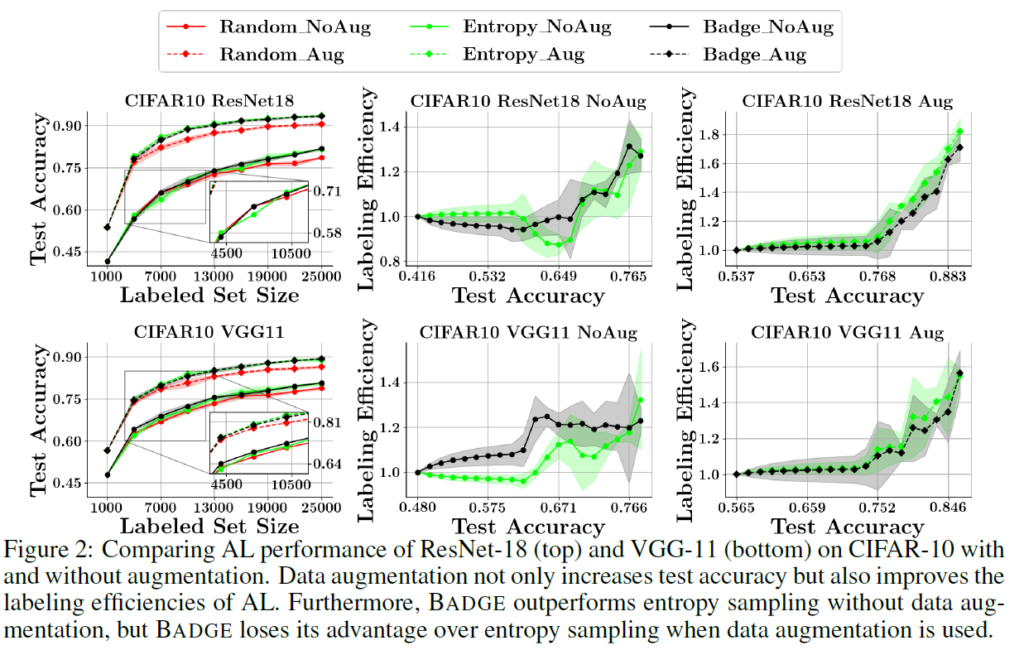
data augmentation에 대한 효과를 살펴보기 위해 실험을 진행했습니다. 결과적으로 augmentation이 일관적으로 labeling 효율과 accuracy를(10%가까이) 올리는데 기여한다는 것을 확인했습니다. BADGE는 augmentation이 도임되면 uncertainty 기반 방법론에 비해 이점을 많이 잃게 되늗데, 저자들은 여기서 augmentation이 diversity를 증가시켜준다는 해석을 하게 됩니다.
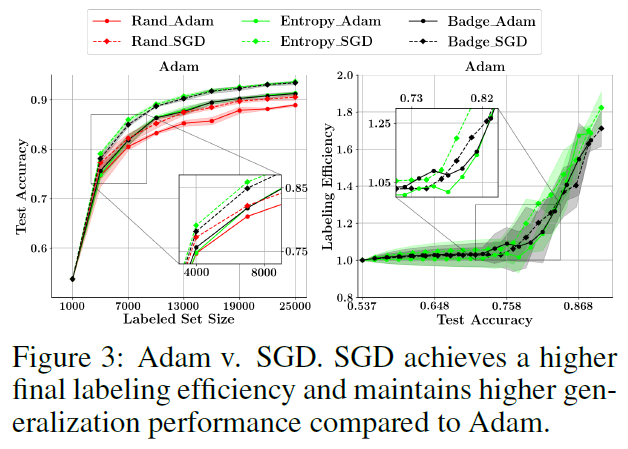
기존의 많은 AL 연구에서 Adam을 optimizer로 사용하는데, Adam은 일반적으로 SGD보다 generalization 효과가 떨어지는 것으로 알려져 있어서 optimizer에 대한 실험이 수행되었습니다. SGD는 momentum=0.9, weight decay=0.0005가 사용되었고, 스케줄러로는 cosine anealing scheduler가 사용되었습니다(사인파의 최고점에서 최저점으로 내려오는 형식으로 스케줄링 해주는 기법입니다. 완벽하진 않지만 PyTorch에도 구현되어 있습니다). Adam에는 weight decay 없이 b1,b2를 0.9dhk 0.999로 설정해주었고, 양쪽 다 LR=0.01로 진행되었다고 합니다. 그래프를 보시면 아시겠지만 SGD가 더 좋은 일반화 성능과 정확도를 달성했다고 합니다(수렴은 Adam이 빨랐다고 합니다). augmentation과 SGD외에도 추가적으로 generalization을 위해 stochastic weight averaging (SWA)와 shake-shake regularization을 고려할 수 있다고 하는데.. 이 regularization들은 처음 보는 기법들이네요. 추가적인 generalization 기법들을 도입한 실험에서 (효율성의 희생 없이) 추가적인 test 성능을 달성할 수 있었다고 합니다
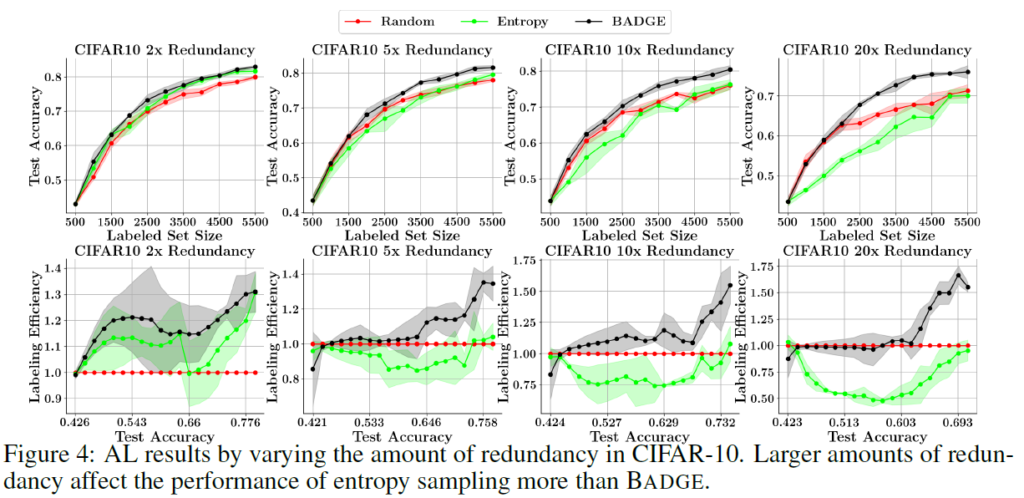
CIFAR-10 데이터를 이용한 Redundancy 분석 실험입니다. redundancy가 높을수록 BADGE(diversity)보다 entorpy(uncertainty)가 더 영향을 많이 받는것을 확인할 수 있습니다. 안 좋은 방향으로요.. BADGE는 이에 강건했을 뿐만 아니라, 끝으로 갈수록 라벨링 효율도 올라갔다고 합니다. 데이터셋에 따라 어떤 방법론을 선택할 때 data redundancy를 고려해야 한다는 결론이 나옵니다. BADGE같은 diversity 방법론들이 redundant 데이터를 훨씬 잘 다룰 수 있다고 합니다.
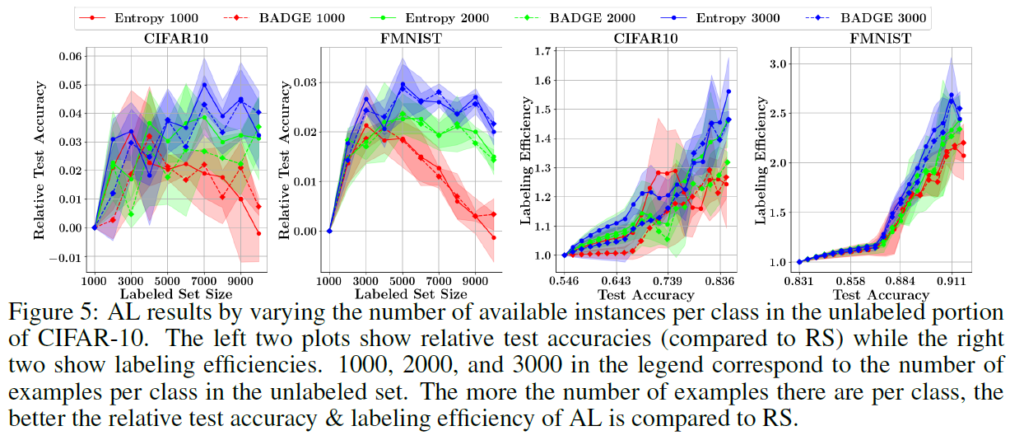
CIFAR-100(1.3x)보다 CIFAR-10(1.8x)에서 라벨링 효율이 높은 것에서, 저자들은 클래스당 데이터 수가 라벨링 효율에 영향을 미치는지에 대한 실험 동기를 얻고 수행했습니다. 결과적으로 unlabeled data에서 class당 instance가 많을수록 Active Learning 방법이 Random Sampling보다 효율이 높아지는것을 확인했습니다.
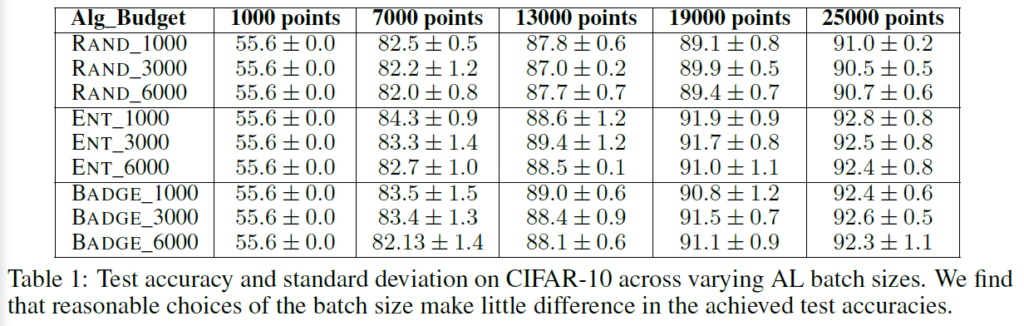
저자들은 배치 사이즈가 성능에 영향을 미치는지 알아보고자 실험을 진행했고, 결과는 위와 같았습니다. 결과적으로는 배치 크기는 test accuracy와 labeling efficiency에 큰 영향을 미치지 않는다는 결론을 내립니다.(Table1을 보시면 배치 크기마다 유의미한 차이를 찾을 수 없습니다.)

제가 흥미롭게 읽은 부분 중 하나입니다. 보통 AL에서 초기 셋 구성이 매우 중요하다고 알고 있는데, 저자들은 학습 초기에는 학습 셋 구성을 의미있게 하는 것 vs Random sampling에 따른 성능 차이가 있지만, 이러한 차이가 금방 좁혀지므로 유의미한 차이가 없다.. 로 결론을 내립니다.
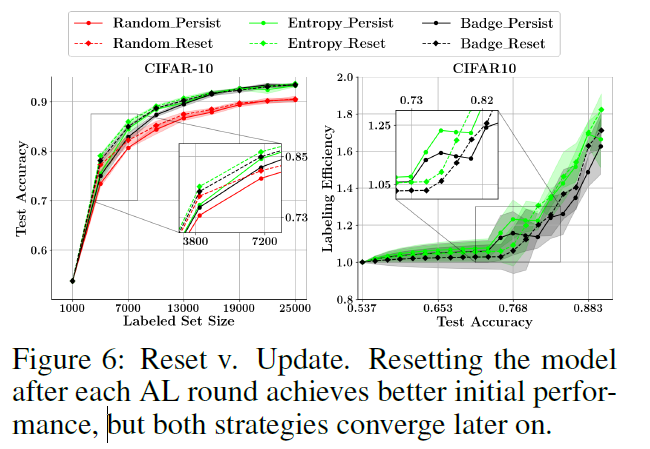
모델을 매 round마다 reset해야 하는지, 아니면 update하는게 좋은지에 대한 실험입니다. reset하는것이 초반에는 좋은 성능을 보여주지만, 뒤로 갈수록 이러한 차이가 줄어든다고 합니다. 추가적으로 Adam과 data augmentation을 적용하지 않으면 model updating이 일관적으로 reset보다 성능이 떨어지는것을 확인했다고 합니다(SGD와 augmentation을 적용하면 차이가 사라집니다). update하는것으로 크게 generalization 성능이 떨어지지 않으니, 학습 시간을 생각하면 reset보단 update를 고려하는것을 추천합니다.
뭔가 읽기도 힘들고 실험과 소주제도 많아서 정리하기 힘든 논문이었습니다.. 그래도 나중에 실험 세팅 할 때 이러한 요소들을 일일히 다 고려해야 하는데 그에 대한 가이드라인을 정리하는 느낌으로 읽었습니다. AL에서는 계속 일관적인 실험 세팅을 위한 프로토콜이 요구되는데, 그런 맥락에서 다른 논문들과 비교해 볼 예정입니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다!
1. AL 연구에서는 Data Augmentation이 잘 사용되지 않고 이에 관한 report도 부재하다고 하셨는데 AL 자체가 데이터 부족 문제를 해결하기 위해 연구되고 있는 분야이니까 데이터가 부족한 상태에서 연구를 진행하는게 더 의미있는 연구라고 생각이 드는데 재연님은 이 부분에서 어떻게 생각하시는지 궁금합니다. 그리고 혹시나 AL 연구에서 Data Augmentation을 잘 사용하지 않는 이유가 있는지도 궁금합니다
2. Adam과 SGD을 비교한 논문을 추후에 읽어볼 계획인데 그 전에 몇 가지 궁금한게 생겨서 질문을 드리고 싶습니다. AL 분야에서는 Adam이 SGD보다 안 좋은 이유가 adaptive optimizer를 사용해서 과적합으로 인해 성능이 떨어지는 건가요?? 그리고 AL 분야 말고도 Adam이 SGD보다 일반화 성능이 떨어지나요?
3. 이 논문에서 제시한 통일된 실험 세팅 방법들이 최근 AL분야에서도 적용이 되고 있나요??
감사합니다!!
정의철 연구원님, 안녕하세요. 질문에 하나씩 답변 드리도록 하겠습니다.
1. 저희는 Data augmetation을 object detection이라는 task에서, 심지어 이미지 데이터에 대해서 맨 처음 접했습니다. 이런 저희에게 data augmentation은 컴퓨터 비전 분야에서 너무 당연하게 사용되는 기법이라 AL에 활발히 사용되지 않는다는 것이 언뜻 생각하면 이상하기까지 합니다. 저는 그 이유가 task별로, domain별로 데이터를 대하는 관점이 다르기 때문이라고 생각합니다. 일반적인 CNN 백본에 input image를 통과시키는 관점에서 데이터를 보는 것과 달리 AL같은 ML core분야에서는 데이터를 feature space상의 data point, 하나의 벡터와 같은 것으로 취급합니다. 데이터 증강을 통해 유사한 이미지를 만드는 것은 고차원 feature space 상 유사한 data point(벡터라고 생각하셔도 될 것 같습니다)를 새롭게 생성하는것에 비유할 수 있습니다. 각 data point의 가치를 판별해 선별하고자 하는 Active Learning 문제를 풀고자 고민하는 연구자에게 새로운 data point를 생성하는 것은 언뜻 생각하면 전혀 관련 없는 작업으로 비춰질 수 있다는 생각이 드네요. 하지만 N개의 labeled data를 갖고 있는 상황에서 data augmentation을 통해 새로운 이미지 데이터를 3개씩만 더 생성한다고 해도 4N개의 labeled data를 얻을 수 있는 것과 같으므로 데이터 증강 기법은 분명 적절히 사용하면 긍정적인 효과를 볼 수 있을 것입니다.
추가적으로 AL이라는 분야가 데이터 부족 문제를 해결하기 위해 연구되는 분야라고 해서 활용 가능한 데이터를 활용하지 않는 것은 옳지 않다고 생각됩니다. budget이 한정되어 있는 환경을 가정해 labeled data의 수를 제한했다가 점차 늘려가도록 하기는 하지만 각 상황에서 unsupervised 방법을 사용하든 semi-supervised learning을 사용하든 최대한 가지고 있는 정보를 활용해서 추가적인 정보를 추출하고자 해야 합니다. data augmetation이 labeling cost를 더 필요로 하는 것은 아니므로, 이를 이용해 데이터를 추가시키는 것은 적절한 접근법 같네요.
2. 일반적으로 AdaGrad, RMSprop, Adam과 같은 adaptive gradient method들은 빠르게 딥러닝 학습 과정에서 빠르게 수렴하는 그 특징 덕분에 널리 사용됩니다. 하지만 일반적으로 over-parameterized된 신경망에서는 SGD계열보다 generalization performance가 좋지 않다는 것이 계속 관측되고 있다고 합니다(저도 예전에 contrasitve learning 실험을 많이 돌려볼 때 Adam을 썼을 때는 빠르게 training accuracy가 수렴하지만 test 성능은 SGD보다 좋지 않은 것을 여러 번 경험했습니다). 일반적으로 그렇다는 거지 절대적인 것은 없으며, Adaptive optimizer와 SGD와의 이러한 차이는 non-convex한 loss landscape의 구성에 크게 영향을 받을 것이므로 task별로, data별로, 모델 별로 상이 할 수 있습니다. 이러한 adaptive optimizer의 한계를 개선하기 위해 지속적으로 새로운 optimizer가 제안되고 있는 것으로 알고 있습니다. 아쉽지만 제가 관련 분석 논문을 꼼꼼히 찾아보면서 정독한 것은 아니라 이 이상 자세한 정보를 드리기는 어려울 것 같네요. 저도 추후 여건이 된다면 convex optimization 이론 쪽을 한번 들여다 볼 생각입니다. 혹시 관련 논문을 서베이 해 볼 생각이시라면, 다음 논문을 소스로 찾아보시는게 좋을 것 같습니다. 기존 adaptive optimizer의 한계를 지적하며 새로운 optimizer를 제안하는 논문입니다 : https://proceedings.neurips.cc/paper/2020/hash/08fb104b0f2f838f3ce2d2b3741a12c2-Abstract.html
3. 아쉽게도, 해당 논문에서 제안하는 프로토콜을 이후 연구자들이 준수하는것 같지는 않습니다. 초기 설정으로 성능 차이가 크게 날 수 있는 분야이다 보니 본인들이 제안하는 방법론의 성능을 높게 보이고자 체리픽을 약간씩 하지 않나 생각이 드네요.
좋은 질문 감사합니다.