
안녕하세요, 이번에는 김태주 연구원님께서 6D Pose estimation task와 한 번 접목시켜보도록 공부해보라고 하셨던 조언을 듣고, 다들 알고 계실 것 같은 NeRF를 리뷰해봤습니다. 카메라 기반의 방법론이다보니 수식이 되게 많은 것 같습니다.
0. Preliminary
먼저 NeRF의 전체적인 흐름은 다음과 같습니다.
- N개의 이미지가 input으로 들어감
- SfM(Structure From Motion) 과정을 거침
- NeRF 모델을 사용하여 view synthesis를 만듦
해당 과정이 전체적인 파이프라인이 되고, 해당 논문에서 전반적으로 다루는 내용들은 3번 과정의 내용들입니다. NeRF를 수행하기 위해서는 어디에서, 어떤 방향에서 촬영되었는지 알아야 진행할 수 있게 되는데요. 2번 과정을 통해 촬영한 이미지의 카메라 파라미터를 추출해주어야 합니다.
SfM 과정을 간략하게 설명해보면 앞서 얘기했듯이 카메라의 파라미터 값을 추출하기 위해 진행하는 과정입니다. 먼저 2-view의 이미지를 가지고 이미지의 특징점을 추출하고 이때, 비슷한 특징을 갖는 것끼리 Feature Matching을 수행합니다. Feature Matching으로 얻은 feature간의 correspondence를 찾기하기 위해서는 Epipolar Geometry가 필요하게 되는데요. 이때, outlier를 제거하기 위한 RANSAC 과정을 반복하면서 가장 많은 inlier을 가질 때 Fundamental matrix를 최종적으로 사용하게 됩니다. Essential matrix는 구하기 위해 해당 Fundamental Matrix와 Intrinsic Matrix를 곱하면 구할 수 있게 됩니다.
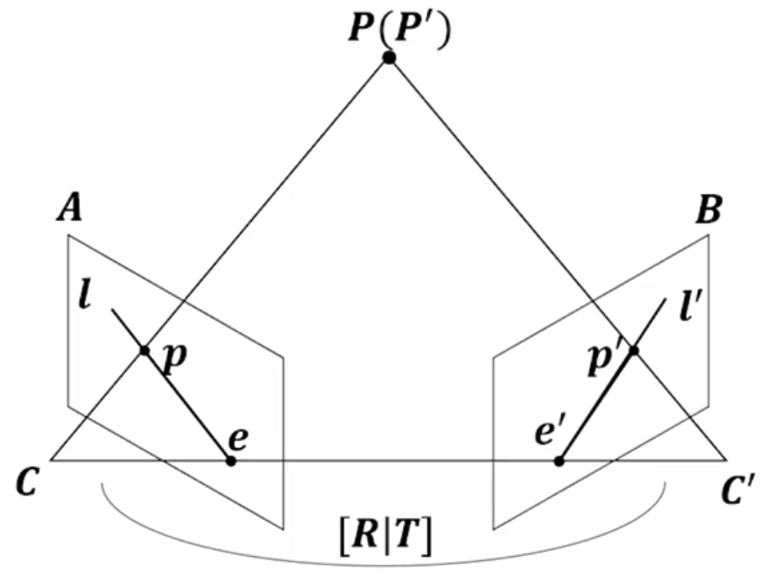
그 다음으로 Triangulation 과정입니다. 두 이미지 간의 Feature에 대한 Correspondence를 추정했으니 이제 3D point를 생성해줍니다.
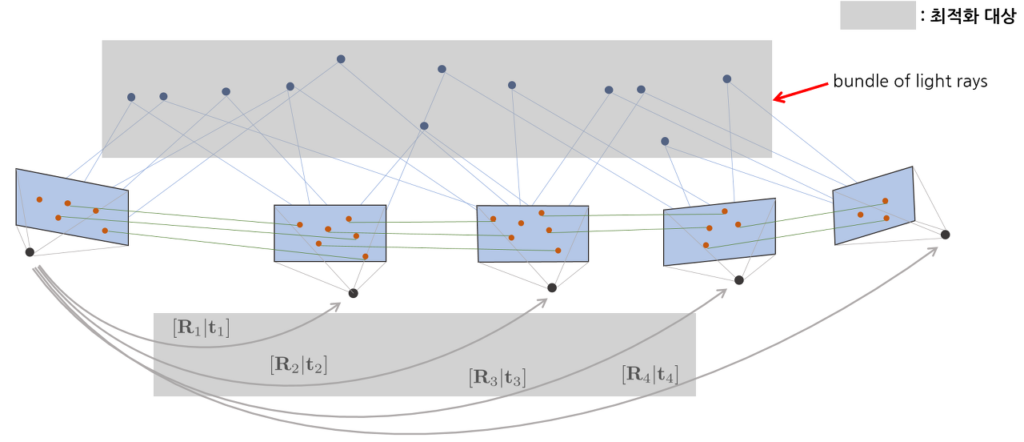
마지막으로 Bundle adjustment 과정을 거쳐 여러 장의 이미지셋을 합쳐 사용하게 됩니다. 해당 과정을 통해 3D point를 생성하고 2D로 reprojection 시켜 기존 2D 특징점과 비교했을 때에 대한 reprojection error를 계산하여 error을 최적화 하는 과정을 수행합니다.
이제 SfM을 통해 카메라의 파라미터를 알아내었으니, NeRF가 동작하기 위한 준비가 다 되었습니다.
NeRF 리뷰 시작하겠습니다.
1. Introduction
이번 논문에서는 다양한 viewpoint에 대한 이미지의 rendering error를 최소화하기 위한 연속적인 5D scene representation의 파라미터를 직접적으로 최적화하여 새로운 방식으로 view synthesis의 오랜 문제를 해결합니다. 여기서 말하는 view synthesis란 N대의 카메라를 통한 input이 들어가면 continuous하게 임의의 시점에서 본 대상의 모습을 합성하는 아래와 같은 task를 의미합니다.

이러한 view synthesis에서 가장 중요하게 다루어야 하는 부분은 카메라의 위치가 바뀐다고 해서 이미지를 단순히 crop 하거나 shift 해서 표현하는 것으로 끝나는 것이 아니라 depth에 따라 멀리 있는 대상은 카메라의 이동에도 크게 많이 안 움직이지만 가까이에 있는 물체는 많이 움직이는 것처럼 움직이는 정도가 다른 것을 영상을 통해 확인하실 수 있습니다. 이러한 현상을 Parallax Effect라고 한다고 합니다. 즉, 카메라 입장에서 픽셀 이동이 가까우면 많이 생길 것이고, 멀 경우 적게 생길 것이라는 현상을 가지는 것이라고 이해하시면 되겠습니다. 이러한 현상들을 고려하기 위해서는 3D space에 대한 이해가 필요할 것 같습니다.
전체적인 NeRF에서 제안하는 시나리오를 살펴보면 다음과 같습니다.

N개의 시점에서 찍은 2D 이미지를 입력으로 주게 되고, 이를 continuous 하게 임의의 시점에서 찍은 2D 이미지를 만들어 내고 최종적으로 rendering 해주는 과정을 거치게 되면 저희가 원하는 NeRF representation을 얻을 수 있게 됩니다.
해당 논문에서의 contribution을 정리해보면 다음과 같습니다.
- complex geometry와 물체가 있는 연속적인 장면을 기본적인 MLP로 파라미터화된 5D Neural Radiance Field로 representation 하기 위한 접근 방식을 제안함
- 당시에 사용되었던 고전적인 volume redering 기법과는 다른 redering 절차를 적용하여, RGB 이미지에서 NeRF representation을 최적화하는 데 사용함 (hierarchical sampling strategy 포함)
- 각 입력 5D coordinate를 고차원 공간에 매핑하는 positional encoding을 통해 NeRF를 성공적으로 최적화하여 높은 퀄리티의 representation을 할 수 있었음
2. Related Work
Neural 3D shape representations
당시 진행되었던 연구들에서는 signed distance function 또는 occupancy field에 xyz 좌표를 매핑하는 딥러닝 네트워크를 최적화하여 level set으로 연속적인 3D shape를 implicit representation하는 방법이 연구되었습니다. 그러나 이러한 모델은 일반적으로 ShapeNet과 같은 합성 3D shape 데이터셋에서 얻은 GT 3D geometry를 고려해야 한다는 제약이 있었다고 합니다. 후속 연구에서는 2D 이미지만을 사용하여 Neural implicit shape representation을 최적화할 수 있는 이전 연구와 다른 rendering 함수 공식화하여 GT 3D shape에 대한 문제를 해결했었습니다. 또 다른 연구에서는 surface를 3D occupancy field로 representation하고 수치적으로 접근하여 각 ray에 대한 surface 교차점을 찾은 다음에, implicit differentiation을 계산합니다. 각 ray의 교차점은 해당 지점의 색상을 예측하는 3D texture field에 입력으로 제공하였습니다. 각 연속적인 3D 좌표에서 단순히 특징 벡터와 RGB 색상을 출력하는 하는 연구도 진행되었습니다.
이러한 기법들은 잠재적으로 복잡한 high-resolution geometry를 표현할 수 있지만, 지금까지는 geometric complexity가 낮은 단순한 shape으로 제한되어 지나치게 부드러운 rendering을 결과로 내었다고 합니다. 저자는 네트워크를 최적화하여 5D radiance field(2D-view에 따라 모양이 달라지는 3D volume)를 인코딩하는 다른 방법을 사용하면 더 높은 해상도의 geometry와 shape을 표현하여 복잡한 scene의 새로운 view를 사실적으로 rendering할 수 있음을 보여 주었다고 합니다.
View synthesis and image-based rendering
volumetric representation을 사용하여 입력 RGB로부터 고품질의 view synthesis task를 처리합니다. volumetric을 사용하여 복잡한 shape과 material을 사실적으로 표현할 수 있고, gradient-based 최적화에 적합하며, mesh-based 방식에 비해 시각적으로 방해되는 artifact를 덜 생성하는 경향이 있습니다. 이러한 volumetric 기법은 새로운 view synthesis에서 인상적인 결과를 얻었지만, discrete sampling으로 인한 시간과 공간의 복잡성으로 인해 고해상도 이미지로 확장하는 부분에 대해서는 제약이 있었다고 합니다.
3. Neural Radiance Field Scene Representation
해당 논문에서 등장하는 5D representation의 구성은 3D location인 \mathbf x=(x,y,z)와 2D viewing direction을 의미하는 (\theta, \phi)로 되어있습니다. 이러한 정보를 input으로부터 MLP를 통과한 output으로는 color(RGB)를 의미하는 \mathbf c=(r, g, b)와 density \sigma가 되게됩니다. Direction을 의미하는 unit vector를 \mathbf d라고 할 때, MLP 네트워크를 통과하여 continuous한 5D scene representation을 F_{\Theta}:(\mathbf x, \mathbf d) \rightarrow (\mathbf c, \sigma)로 근사할 수 있고, weight를 의미하는 \Theta는 각 5D coordinate에 대해 대응하는 volume density와 directional color에 대한 가중치를 고려하여 최적화를 할 수 있게 됩니다. 즉 NeRF라는 것은 결국 각 위치 (x, y, z)와 direction d가 입력으로 들어왔을 때, RGB와 density를 계산할 수 있도록 하는 모델링 함수를 제안했다고 이해하시면 될 것 같습니다. 앞서 언급한 notation을 좀 더 살펴보면, d는 3D 공간에서 물체를 다양한 시점에서 본다고 생각을 해보면, 물체를 보는 방향에 따라 물체의 색상이 변하게 될 것 입니다. 예를 들면, 저희가 거울을 여러 시점으로 본다고 했을 때, 거울에서 가지는 정보는 시점에 따라 달라지게 됩니다. 이처럼, 물체의 색상 정보가 변하게 되므로 방향 정보도 input에 포함을 시켰습니다.

Density를 설명하기에 앞서 해당 논문에서 중요하게 다루는 Ray에 대한 설명을 먼저 하겠습니다.
다양한 viewpoint 중, 하나의 viewpoint를 보았을 때를 위 그림과 같이 나타내었을 때, 3D point에 대응하는 2D pixel 영역에 projection을 하게 되는데, 이를 논문에서는 Ray라고 정의합니다. 그림에서는 주황색 선을 의미하겠네요.

Ray 위에 있는 하얀점들은 수많은 sample들이고 Ray는 sample들의 집합이라고 해석도 가능할 것 같습니다. 해당 논문에서는 하얀점들을 particle이라고 명시하였습니다. 해당 particle들의 의미는 RGB를 구성하는 요소인데요. 해당 부분에서 density라는 내용이 나오게 됩니다. 이전의 방향 정보를 통해 저희는 해당 지점에 대한 density를 알 수 있는데요. density는 분포 정도를 나타내지만 해당 내용에서는 투명도라고 생각하시면 이해하시는 것에 도움이 될 것 같습니다.
NOTE ; 그렇다고 정말로 투명도를 의미하는 것은 아니고, 이해를 돕기 위한 단어라고 생각하시면 되겠습니다. 저희가 생각하는 분포의 개념이 맞습니다.
즉, 앞에 있는 particle의 density가 큰 경우, 투명도가 적으므로 뒤에 있는 particle 들은 색상이 잘 안 보이게 되고, 앞에 있는 particle의 density가 작은 경우, 투명도가 크므로 뒤에 있는 particle 들은 색상이 잘 보일 것입니다.

이러한 방향 정보를 넣었기 때문에 그림(4)의 GT는 빛 반사가 되는 것을 확인할 수 있는 반면, No View Dependence는 빛 반사가 안되는 것을 확인할 수 있습니다.
4. Volume Rendering with Radiance Fields
이번에는 Volume Rendering을 어떻게 진행을 했는지 살펴보겠습니다.
volume rendering도 사실 대단한 건 아니고 앞서 다루었던 내용과 더불어 색상 정보의 가중치를 어떻게 줄 것인지에 대한 과정이라고 생각하시면 되겠습니다. 앞서 설명드린 Ray가 있었습니다. Ray를 수식으로 정의하면 \mathbf r(t)= \mathbf o + t \mathbf d라고 합니다. Ray의 원점은 초점이므로, 초점으로부터 \mathbf d 방향으로 t만큼 이동한 정도를 의미합니다. 해당 Ray는 결국 particle들이 있는 집합이었는데요. 3D point와 2D pixel을 잇는 직선이었던 것도 확인을 하였습니다. 즉, Rendering은 물체가 주어지면 특정 viewpoint에서 카메라 위치와 pixel 위치가 정해졌을 때, 두 지점을 잇는 직선(Ray)가 정의되고 해당 직선 위의 있는 모든 Particle들이 해당 점의 RGB를 구성하도록 하는 것입니다. 이때, Ray 위에 존재하는 particle들의 weighted sum을 해야 해당 pixel의 색상을 정할 수 있습니다. 그럼 weight는 어떻게 정의할까요?
다음과 같이 정의를 할 수 있습니다.
- Density가 클수록 Weight는 커져야 함 → \sigma(\mathbf r(t))
- 해당 지점을 가로막고 있는 점들의 Density 합이 적을수록 weight가 커져야 함 → T(t)
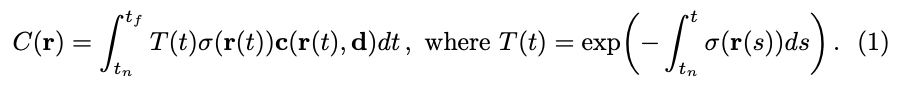
식(1)을 살펴보면 C(\mathbf r)은 저희가 최종적으로 얻는 RGB정보입니다. Ray에서 물체와 가장 가까운 것을 near t_{n},물체와 가장 먼 것을 far t_f로 표현하였습니다. 식 안의 \mathbf c(r(t), d)와 \sigma(\mathbf r(t))는 input으로 들어오는 정보로 MLP를 통과하여 얻을 수 있습니다. weight 정의 중 첫 번째 의미는 뒤에 있는 particle들은 잘 보이지 않게 되므로 해당 particle에는 weight를 크게 주도록 하겠다는 의미입니다. 두 번째는 사람을 찍고 있는 카메라 사이에 벽이 있다고 가정을 해봅시다. 이때, 특정 viewpoint에서는 ray를 projection 했을 때 벽 때문에 뒤에 있는 사람이 보이지 않을 것입니다. 그럼 벽까지의 density가 높을 것인데, 저희는 사람을 타겟으로 하기 때문에 벽쪽에 있는 density가 작아져야 사람이 보이게 된다는 것입니다. 즉, 벽까지의 density의 합이 크면 불투명하므로 weight는 줄이고, density의 합이 작으면 투명하므로 해당 weight는 증가시킵니다. 해당 T(t) 같은 경우, accumulated transmittance라고 합니다. 해당 식을 살펴보면 음수형태의 exponential이므로 density가 클수록 weight가 감소하고 density가 클수록 weight가 증가하도록 설계한 것을 확인할 수 있습니다.
하지만, 이러한 과정에도 문제가 있는데요. implementation 과정에서 문제가 발생하게 됩니다. 식(1)과 같은 경우, continuous한 integral이므로 모델링을 위한 implementation을 하려면 discrete한 식으로 변환을 해주어야 합니다.
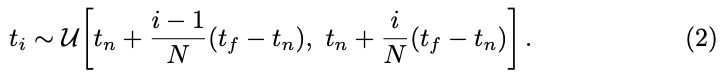
식(2)를 살펴보면 앞서 언급한 ray에서 [t_{n}, t_{f}]를 균등한 간격의 N개의 bin으로 분할한 다음에 각 bin 내에서 1개의 sample을 uniform distribution으로 추출하는 방식을 사용하였다고 합니다.

random sampling을 거친다음에 식(3)와 같이 식을 변환하게 됩니다. integral을 \Sigma형태로 바꾸었고, 앞서 구한 Ray 따라서 적분하는 것을 discrete하게 하도록 하는 term을 [1]논문을 참고하여 적용하였다고 합니다. 즉, i부터 까지 증가하면서 Continuous한 식과 근사한 값이 된다고 합니다. 해당 식이 저희가 원하는 최종적으로 예측한 컬러 정보가 됩니다.
[1] Max, N.: Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics (1995)
5. Optimizing a Neural Radiance Field
기존의 MLP만으로는 성능이 좋지 않았다고 합니다. 이러한 문제를 해결하기 위해 저자는 두 가지의 방법론을 적용하게 됩니다.
5.1. Positional encoding
해당 section에서의 결론은 low-dim을 input으로 사용했더니 성능이 안 좋아서 high-dim으로 넣었더니 성능의 향상이 있었다 라는 것이 핵심입니다. 어떻게 dimension을 확장하였는지 알아보도록 하겠습니다.
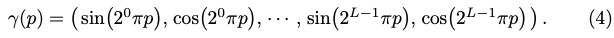
식(4)와 같이 sine과 cosine으로 이루어진 식을 x, y, z를 입력으로 여러 개를 만들어 차원을 증가시켰다고 합니다. 이렇게 차원을 늘리면 선명도에 대한 문제가 어느정도 완화시킬 수 있었다고 하네요. 해당 식에는 L이라는 파라미터가 사용되게 되는데요. 위치 (x, y, z)에 대해서는 L=10을 사용하여 60-dim을 만들었고, 방향 \mathbf d에 대해서는 24-dim을 사용했다고 합니다.
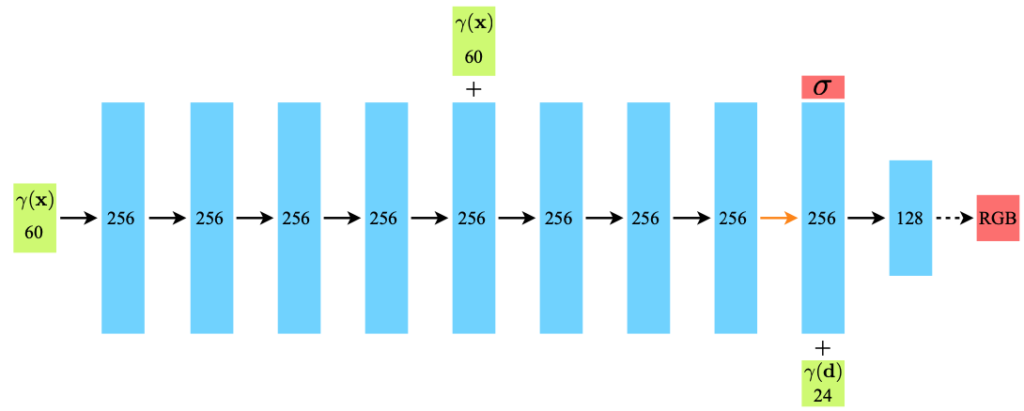
위 그림과 같이 FC layer로 이루어진 network를 사용했다고 하네요.
5.2. Hierarchical volume sampling
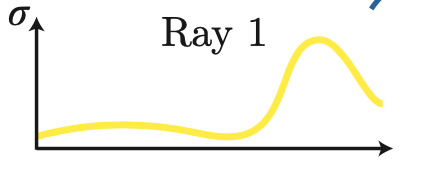
Ray 상의 particle 또한 성능에 영향이 있으므로 저자는 해당 과정에서 2개의 네트워크를 사용하게 됩니다. Coarse Network C_{c}와 Fine Network C_{f}를 사용합니다. 첫 번째로 N_{c}개의 t를 뽑고 Coarse Network를 학습을 시킵니다. 이때 우리는 앞서 식(3)을 보면 T_{i}(1-\exp(-\sigma_{i}\delta_{i}))의 weight를 얻을 수 있게 됩니다. 해당 weight은 c_{i}의 분포라고도 해석을 할 수 있다고 합니다. 이러한 Coarse Network를 통해 아래와 같은 distribution을 얻었다고 할 때, peak지점이 있는 영역이 이미지 내의 타겟이 존재하는 영역이라고 말을 할 수 있습니다. 해당 영역을 추가적으로 더 뽑기 위해 N_f개를 뽑아서 총 N_{c} + N_{f}개의 sample을 이용하여 fine network를 학습시켜서 사용하게 됩니다.
5.3. Implementation details
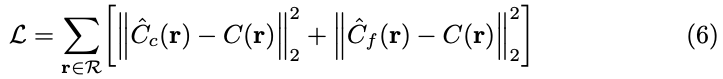
학습은 식(6)과 같이 이루어지게 됩니다. 이전에 구한 coarse 단계에서 volume sampling 추정한 값과 GT를 빼고 fine 단계에서 volume sampling을 추정한 값과 GT를 뺀 값에 대한 각각의 l_{2} loss를 구하고 더한 값을 loss function으로 사용합니다.
6. Results

그림(4)는 모든 모델을 사용했을 때와 positional encoding을 사용했을 때의 성능 변화를 볼 수 있습니다.
6.1. Comparisons


결과들을 보면 당시 view synthesis를 다루던 논문들과 비교해봤을 때 많이 개선된 것을 확인할 수 있습니다.
6.2. Ablation study
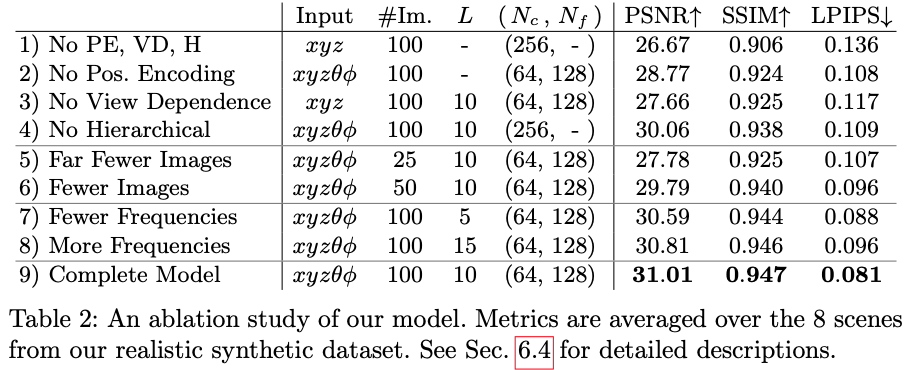
마지막으로 저자가 제안한 방법을 적용하는 것과 이미지의 개수, frequency에 대한 ablation study를 진행한 표입니다. 저자가 제안한 방법론들을 모두 적용한 맨 마지막 행의 성능이 가장 좋은 것을 확인할 수 있습니다.
7. Conclusion
이번 논문에서는 MLP를 사용하여 물체와 scene을 continuous한 function으로 표현하는 이전 논문들의 문제들을 직접적으로 해결합니다. 저자는 scene을 5D Neural Radiance Field(3D location 및 2D viewing direction의 함수로 volume density와 view에 따라 projection시키는 Ray를 출력하는 MLP Network)로 표현하는 것이 discrete된 voxel 표현을 출력하기 위한 CNN을 훈련하는 기존 방식보다 더 나은 rendering을 생성한다는 사실을 입증했습니다. 저자는 rendering의 sample 효율을 높이기 위해 Hierarchical volume sampling을 제안했지만, NeRF를 효율적으로 최적화하고 rendering하는 기술을 연구하는 데는 아직 더 많은 진전이 있어야 한다고 하면서 논문을 마칩니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Bundle adjustment는 여러 쌍의 스테레오 뷰에서 구한 3차원 포인트에 대해서 에러를 최적화하여 하나의 통일된 점을 구하는 것이라고 이해했는데요 서로 다른 스테레오뷰에서 구한 포인트를 하나의 최적화된 포인트로 만든다는 것이 잘 이해가 되지 않아 Bundle adjustment 과정에 대해 조금만 더 설명해주시면 감사하겠습니다.
또한 particle이라는건 한 뷰에서 한 포인트에 대한 RGB를 구성하는 요소의 샘플들이라고 말씀해주셨는데 요소의 샘플이라는 것이 정확하게 무엇인가요 ? ? 색상 정보가 여러개로 나누어져 분포해있는것인지 어떤 의미인지 궁금합니다. 렌더링할 때 Ray 위에 존재하는 모든 particle이 해당 점의 색상 정보를 구성하도록 한다는 것으로 보아 원래는 그저 색상 후보일 뿐인 것인지 .. 헷갈려 질문 드립니다
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 먼저 bundle adjustment 과정에 대해 조금 더 덧붙여 보면 각 이미지에 대한 viewpoint에 대해 3D 포인트들이 reconstruction 될 것입니다. 저희는 이러한 reconstruction 된 포인트들에 대한 error를 계산해주어야 좀 더 정확한 결과를 얻을 수 있으므로 이러한 3D 포인트를 최적화 하기 위해 Levenberg-Marquardt 최적화 알고리즘과 같은 방법을 통해 reconstruction error 를 최소화하는 방향으로 조절을 한다고 합니다.
2. Particle에 대한 개념은 이번 NeRF에서 매우 중요한 역할 중 하나이며, 이를 구성하고 있는 집합체가 Ray입니다. 해당 Ray 위에 있는 수 많은 particle들은 RGB 색상 정보를 가지고 있는 샘플들로 이해하시면 좋을 것 같습니다. 각각의 particle들이 가지고 있는 색상에 대한 정보는 각각 다를 것이고 내용에 나오는 density와 연관지어 생각해보면 색상 후보라고 이해하셔도 무방할 것 같습니다.
감사합니다.
안녕하세요. 리뷰 잘 보았습니다. 몇가지 질문이 존재하는데,
1. 먼저 Triangulation 과정이 정확히 무엇을 의미하나요? two view에서 대응되는 matching point로부터 depth 정보를 추정하는 것을 의미하나요? 그렇다면 이 3차원 depth 정보는 어떻게 추론이 가능한지 간단하게 설명할 수 있나요?
2. 그리고 bundle adjustment 과정에서도 3d point를 생성한다고 하셨는데, Triangulation 과정에서 3d point를 생성하는 것이 아닌가요? 무언가 비슷한 표현이 반복적으로 나오는데 각 명칭이 어떠한 목적을 수행하고 그 목적을 수행하기 위한 동작이 어떻게 되는지를 명확하게 할 필요가 있어 보입니다.
그리고 리뷰 내 비디오가 실행이 안되는 것 같은데 확인 한번 해주시면 감사하겠습니다.
3. 5D radiance field를 모델링하는 방식으로 3D location(x, y, z)과 2d viewing direction(세타 널)로 표현한다고 적어주셨는데, 여기서 2d viewing direction에 대해 구체적으로 설명해주실 수 있나요? 실제로 세타와 널 값이 어떤 scale을 지니는 값으로 표기하면 되는 것인지 잘 모르겠네요. 가령 x, y, z는 3D location 좌표라는 것이 명확한데 2d viewing direction이라 함은 카메라가 어디를 바라보고 있는지를 나타내는 것이라면 보통 Rotation과 translation의 행렬로 표현하지 않나요? 2개의 scalar값으로 시점 방향을 표현하는 것에 대해 쉽게 머릿속에서 떠오르지가 않네요.
3.5 Ray를 수학적으로 모델링할 때 ray = o + td라고 하셨는데, 여기서 d는 방향을, t는 이동한 정도를 나타낸다고 하셨습니다. 여기서 t 값은 sfm을 통해 계산된 해당 viewpoint의 외부파라미터 R|t로 계산이 가능한가요? 그러면 방향도 마찬가지로 R|t에서 뽑을 것 같은데.. 아 그리고 o값에 대한 정의는 안적어주셔서 o값이 무엇인지도 알려주시면 좋겠습니다.
4. 그리고 리뷰 내용 중 “이전의 방향 정보를 통해 저희는 해당 지점에 대한 density를 알 수 있는데요.” 라는 문장에 대해서 추가적인 설명이 가능하신가요? 이전의 방향정보라고 함이 무엇을 의미하나요? 모델 입력으로 들어오는 viewing direction을 의미하는건가요?
5. 애초에 density라는 것을 수학적으로 어떻게 정의하나요? 일단 제가 리뷰를 보면서 정리한 내용이 다음과 같은데 결국 density는 해당 지점의 RGB 값을 정하는 weight로 보는 것으로 이해했어요.
—-
Ray 위에 있는 무수히 많은 점들을 particle이라고 함.
여기서 particle 하나하나는 고유의 density를 가지게 됨.
density가 크다 == 뒤에 particle이 잘 안보임,
density가 작다 == 뒤에 paritcle이 잘 보임.
RGB 값을 지정하기 위해서는 Ray 위에 particle들 간에 weighted sum이 이루어져야 함.
—-
여기서 density 자체를 weight으로 보고 모델의 learnable paramter로써 학습을 통해 결정된다고 보면 되는 것인가요?
마지막으로 리뷰 글에 설명이 조금 모호해서 제가 제대로 이해했는지 몰라서 리뷰 내용 중 일부를 정리해봤어요. 혹시 제가 제대로 이해한게 맞는지, 제가 잘못 이해했다면 정정 좀 해주세요.
리뷰 내용 중에 가중치에 대한 정의를 2가지로 나타낼 수 있다고 하였으며 그중 첫번째가 “뒤에 있는 particle들은 잘 보이지 않기에 해당 particle의 weight을 크게 주겠다.” 라는 문장이었어요.
해당 문장의 의미가 구체적으로 n번째의 particle에 대한 density가 클수록 해당 픽셀의 RGB 값을 대표할 가능성이 높기에 weight 값이 커져야만 하며, 그렇게 되면 n+1~이후의 particle들의 가중치는 줄어들어야만 한다는 내용으로 이해하면 되나요? 기존의 문장에서는 대상을 지칭하는 명사들이 분명하지 않아서 (가령 뒤에 있는, 해당 이라는 단어들이 정확히 무엇을 의미하는지 모르겠음.) 정확한 기준을 제시한 뒤(가령 n) 설명을 보충해주면 좋을 것 같아요.
마찬가지로 두번째 정의에 대해서도 설명할 때에도 “벽까지의 density의 합이 크면 불투명하므로 weight는 줄이고, density의 합이 작으면 투명하므로 해당 weight는 증가시킵니다.” 라는 의미가 정확히 무엇의 weight을 줄인다는 의미인지 모호한 것 같아요.
벽까지의 density 합이 크면 해당 픽셀의 RGB 값이 벽을 표현할 가능성이 높기 때문에 “사람에 해당하는 particle”의 weight는 줄이고, 벽의 density의 합이 작으면 “해당 벽에 대한 particle이” 투명하므로 “사람의 particle의” weight는 증가시킵니다. 라는 식으로 무엇의 가중치가 늘어나고 줄어드는지 명확하면 리뷰를 읽고 이해하는데 더 도움이 될 것 같네요.
NeRF라는 분야가 3년전부터 매우 핫하고 지금까지도 논문이 계속해서 나오는 것으로 알고 있는데, 해당 분야를 공부하기 위해서는 카메라 기하학에 대하여 많은 공부가 필요한 것으로 알고 있어요. 그런 관점에서 가장 기본이 되는 이번 논문 외에도 꾸준히 공부하셔서 NeRF의 최신 방법론들까지 쭉 리뷰를 할 수 있게 되면 좋겠어요:)
안녕하세요, 리뷰 읽어주셔서 감사합니다.
리뷰 영상에 대해서는 링크로 수정을 해두었습니다.
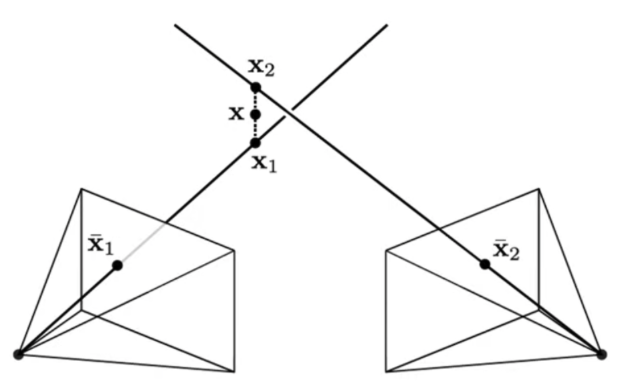
1. 정확하게는 3D point를 추정하는 단계입니다. depth정보를 활용하는 것처럼 보이나 Triangulation에 첨부한 이미지를 보면 x_{1}와 x_{2}는 각각에 대응되는 \bar x_{1}와 \bar x_{2}의 픽셀에 대응되는 두 이미지로부터의 viewpoint로부터의 위치가 되게 됩니다. 오차가 없으면 x_{1}과 x_{2}는 일치하겠지만, 일반적으로는 맞지 않으므로 x_{1}과 x_{2}를 연결한 중심점을 의미하는 x를 구하여 3D point를 구한다고 합니다.
2. bundle adjustment과정도 3D point를 구하는 과정이긴 하지만 reprojection된 좌표와 비교하여 error(3D point들을 대응되는 이미지에 투영시킨 위치와 해당 영상에서 실제 관측된 위치의 차이)를 최적화하는 과정으로 앞서 구한 3D point를 좀 더 정교하게 구하는 과정이라고 생각해주시면 되겠습니다.
3. θ는 Ray가 물체 surface에 입사할 때의 수직각도를 나타내고, φ는 Ray의 수평 각도를 나타내는 것이라고 합니다.즉, 어떤 위치에서 Ray가 projection 됐는지를 의미합니다. 이렇게 사용하는 이유는 렌더링 과정에서 표면에 대한 reprentation을 좀 더 유의미하게 하려고 설계하지 않았을까 하는 생각이 듭니다.
3.5. r(t) = o + td일때, 해당 식에서 의미하는 t는 Ray를 따라 이동하는 거리라고 생각하시면 되겠습니다. o는 원점으로 Ray의 시작점을 의미합니다.
4. 내용을 조금 정정하자면, Density는 입력정보를 가지는 5D representation에 대한 정보로부터 얻을 수 있습니다.
5. 빈약한 설명으로도 잘 이해해주신 것 같습니다. 감사합니다.
6. 신정민 연구원님께서 말씀하신 추가적인 부분에 대해서도 픽셀에 대한 RGB를 나타내는 particle일 경우, 확률분포의 관점에서 해당 부분에 대해 weight를 크게 주는 것이 맞습니다.
7. 해당 경우는 제가 벽을 예시로 들었는데, 앞에 가려진 density가 클수록 해당 weight는 작아지도록 exponential term으로 구성했다고 이해를 했습니다.
처음으로 NeRF를 읽고 리뷰를 써봤는데, 확실히 많이 어려운 것 같습니다.
카메라 기하학에 좀 더 많은 시간을 투자해보겠습니다.
조언 감사합니다.
좋은 리뷰 감사합니다.
particle의 density는 정말 빛의 양 이라고 생각하면 되는 것일까요??
또한, ‘weight 정의 중 첫 번째 의미는 뒤에 있는 particle들은 잘 보이지 않게 되므로 해당 particle에는 weight를 크게 주도록 하겠다는 의미’라고 하셨는데, 이 부분은 sigma(r(t))에 대한 설명인지 궁금합니다. 그리고 해당 항을 이용하여 뒤에 있는 particle이 잘 보이지 않도록 하는 것인지 혹은 잘 보이지 않으므로, 조금 더 집중할 수 있도록 가중치를 주어 어떻게보면 density에 대한 영향을 줄이는 것인지 궁금합니다.
positional encoding은 차원을 늘려 성능 향상을 이뤄냈다고 하셨는데, 이 부분이 잘 와닿지 않는 것 같습니다. 차원을 늘리는 것이 어떠너 이유로 선명도 문제를 완화하는 것인지 추가적으로 설명해주실 수 있을까요??
감사합니다
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 우선 density는 빛의 양이라기보다는 투과율, 투명도정도로 생각하시면 될 것 같습니다. 투명도가 클수록 뒤의 paricle이 보일 것이고 투명도가 낮을수록 뒤의 particle이 덜보이는 식으로 이해해주시면 되겠습니다.
2. 정확하게는 color에 대한 weight를 주는 요소가 2가지가 있는데, Transmittance와 density입니다. 말씀하신 첫 번째 정의는 density은 sigma에 대한 설명이 맞습니다. density는 F_theta에 의해 나오게 되는데요, input 정보에 대해 volume density와 directional color에 대한 가중치를 고려하여 최적화를 진행합니다. 해당 방법들에 대한 설명은 section 4.에 해당하는 내용들이 되겠습니다.
3. 사실 식(4)을 Fourier Feature라고 하며 해당 식에 대해 정확하게 아는 건 아니지만, 이름 그대로 Feature 이기 때문에 사전에 정의된 파라미터 L에 의해 sine, cosine으로 정의되어 있는 해당 Feature를 input에 대해서 차원을 확장시키게 되는데, 공간에 대한 정보를 고차원으로 늘려서 성능을 올린 것으로 이해하시면 좋을 것 같습니다.
감사합니다.
안녕하세요 양희진 연구원님. 좋은 리뷰 감사합니다.
논문의 task를 간단히 요약하면 여러 장의 2d 이미지를 기반으로 카메라 파라미터를 추정하여 3D로 mapping한 뒤 임의의 방향에서의 이미지를 추정하는 것이라고 이해하였습니다.
리뷰를 읽다가 궁금한 점이 있는데요, 본문에서 3d공간에서 물체를 보는 방향에 따라 물체의 색상이 변하게 된다고 언급하셨는데요, 물제와 조명이 고정된 상황에서 viewpoint가 달라지게 되면 색상 자체가 달라진다는 의미인가요? 아니면 2d이미지 기준으로 동일 크기의 이미지 내에서 해당 위치의 픽셀값이 달라진다는 의미인가요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
전자는 맞지만 후자는 이미지의 크기가 달라질 수 있을 것 같고 해당 내용 뿐만 아니라 접근하기 위해 고려해야 될 점이 많을 것 같다는 생각이 듭니다. 단일 2D 이미지 기준으로 생각하면 사실 해당 task는 상당히 어려운 문제이지만, multi-view geometry이기 때문에 view synthesis task를 수행할 수 있지 않았나 싶습니다.
감사합니다.
어려운 논문인데도 불구하고 꼼꼼한 리뷰 작성해주셔서 감사합니다.
정민이가 질문을 너무 잘해줘서… 겹치는 내용 외에 질문만 할게요!
1. 5.2의 t는 무엇을 의미하는 건가요?
2. 최종적으로 fine network만 사용하는 것 같은데 맞나요?
3. coarse와 fine을 나눠 들어가는 입력 정보에 대해서 보다 자세한 설명 부탁드립니다.
4. GT 정보는 어떻게 취득된 정보 일까요?
마지막으로 저희는 캐드 모델이 있어서 정확한 3차원 정보를 얻어 내는 것이 가능한 상황이죠.
nerf는 3차원 정보를 토대로 시점에 따라 변동되는 컬러 정보들에 대한 이해를 모델이 배우는 것으로 이해할 수 있습니다.
그러면 역으로도 가능하지 않을까 싶어요. 시점에 따른 컬러 정보를 기반으로 캐드 모델이 가진 5d radiance field를 찾는 것이 가능하지 않을까 싶습니다. 해당 방법을 토대로 패치 단위로 임베딩 할 수 있다면 영상 레벨에서 3차원 모델링에 대한 국소적인 특징점을 얻을 수 있고 영상에서 3차원 캐드 모델의 특성을 알 수 있는 특징 정보를 계산 할 수 있을 것 같아요.
이를 역으로 수행하면 3차원 캐드에서 영상 간의 특징 정보 추출이 가능해지고 두 정보 간의 일치 할 수 있는 매칭 모델을 설계하면 영상과 캐드 모델 간의 정밀한 매칭이 이뤄지지 않을까 싶습니다.
너무 낮은 수준의 아이디어라서… 기억해두었다가 나중에 이야기 해보면 좋을 것 같아요.
안녕하세요,
부족한 부분이 많은 리뷰인데도 불구하고 조언까지 해주셔서 감사합니다.
1. 5.2에 나오는 T도 이전에 나온 continuous의 Termittance term을 의미합니다. 학습을 위해서는 Discrete한 형태로 맞춰주어야 하기 때문에 sampling이 되었고 해당 과정 때문에 인덱스가 붙은 것을 의미합니다.
2. coarse + fine 둘 다 사용합니다. 저자는 coarse만으로는 sampling이 부족하다고 느껴 추가적으로 fine에 대한 sampling을 추가적으로 진행을 했습니다. 식(6)을 보시면 C_{c} : coarse이며, C_{f}: fine을 나타냅니다. 해당 loss function을 보시면 이해하실 것이라고 생각합니다.
3. Coarse는 sampling된 density의 정보가 들어가게 됩니다. 다음으로 Fine은 Coarse로부터 얻은 distribution에 대해 peak지점에 해당하는 sample들을 추가적으로 입력받아 coarse에서 얻은 sample들과 더해서 사용한 것으로 이해를 하고 있습니다.
4. Synthetic data에 대해서는 GT camera pose, intrinsic parameter를 사용했다고 합니다. 정확하게 나와있지 않아 이슈를 살펴보니 blender와 같은 툴을 사용한 것으로 보입니다.
덕분에 좋은 논문을 리뷰해보는 시간을 가졌습니다.
감사합니다.