Abstract
저자들은 cv분야에서 높은 정확도를 보여주는 sota모델들과 실제 사용되고 있는 affordable한 모델 간의 격차가 증가하고 있다고 지적합니다. 논문의 저자들은 이러한 두 가지 타입의 모델간의 격차가 발생하는 것을 문제라고 생각하여 이를 해소하고자 하였습니다. 이 논문은 기존의 방법론을 기반으로 Sota모델을 실제 사용할 수 있을 만큼 affordable하게 만드는 robust하고 effective한 recipe를 찾고자 하는 분석 논문에 해당합니다. 경험적인 실험을 통해 저자들은 knowledge distillation이 올바르게 수행될 경우, 성능 저하 없이 대형 sota 모델의 크기를 줄일 수 있는 강력한 도구가 될 수 있다고 주장하였습니다. 특히, distillation의 효과에 영향을 줄 수 있는 design choice를 밝혔는데요, 논문에서는 이러한 design choice를 명시적으로 밝힌 것을 contribution이라고 하였습니다. 포괄적이고 경험적인 실험을 통해 연구 결과를 뒷받침하고, 광범위한 vision dataset에 대한 설득력 있는 결과를 입증하며, 특히 82.8%의 최고 정확도를 달성하는 ImageNet에 대한 sota ResNet-50 모델을 확보하였습니다.
Preliminary
Knowledge Distillation
Knowledge Distillation이란 model compression technique 방법론에 해당하며, 어떤 task에 대해 충분한 성능을 보유한 large 모델이 있을 때 해당 모델에 비해 가벼운 small 모델로 large 모델의 지식을 전달하는 것을 의미합니다. 이때 지식을 가진 모델을 teacher, 지식을 전달받을 모델을 student라고 합니다. Knowledge distillation으로 인해, 결과적으로는 어떤 task에 대해 처음의 모델(teacher)보다 가벼운 모델(student)에서도 우수한 성능을 내는 방법론이라고 이해하시면 될 것 같습니다.
knowledge distillation의 학습은 아래와 같이 진행됩니다.
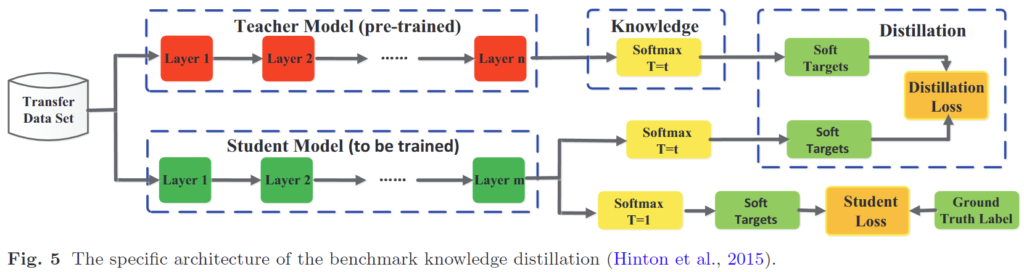
먼저 사전 학습된 teacher 모델이 존재하는 상황에서 student를 학습시키게 되는데요, 이때 student를 학습시키기 위해 student loss와 distillation loss라는 두 가지의 loss를 사용합니다.
우리가 익히 알고 있듯이 어떤 task에 대해 supervised 방식으로 모델을 학습한다고 할 때, 모델의 예측값과 GT간의 loss를 통해 모델을 업데이트합니다. 이것이 가장 아래의 student loss에 해당합니다.
Knowledge distillation은 여기에 추가적으로 large pretrained 모델, 즉, 해당 task에서 이미 준수한 성능을 보이는 teacher network의 knowledge를 학습에 사용합니다.
knowledge에 관한 직관적인 설명을 위해 입력 이미지를 [cat, dog, car]의 세 가지 클래스로 분류하는 task를 수행한다고 가정해 보겠습니다. 이때 고양이 이미지를 모델에 입력한다고 하면 이때의 GT는 [1, 0, 0]의 one-hot encoding 형태를 가지게 될 것입니다. 반면 잘 학습된 teacher 모델은 [0.8, 0.19, 0.01]과 같이 각 class 별 confidence score를 출력할 것이다. 이때 cat 이미지에 대한 결과값인 [0.8, 0.19, 0.01]을 보면 teacher는 cat 이라는 이미지를 보고 0.19의 확률로 dog, 0.01의 확률로 car라고 판단했다고 할 수 있겠죠. 즉, teacher 모델은 “cat은 dog와 car중 dog에 가깝다”라고 판단하였음을 알 수 있습니다. 이러한 teacher 모델의 예측 분포를 teacher모델의 knowledge라고 합니다.
위와 같이, one-hot인 GT에서는 얻을 수 없는 맥락 정보를 얻기 위해 teacher의 output을 학습에 사용하며, student를 teacher의 knowledge에 가까워지도록 학습하기 위해 사용하는 것이 distillation loss라고 이해하시면 될 것 같습니다.
Introduction
Intro에서 저자들은 컴퓨터 비전 분야에서 sota모델의 발전이 real application으로 이어지지 않는다는 점을 지적하였습니다. 많은 비전 연구자들이 뛰어난 성능을 확보하기위해 모델의 크기를 현대 하드웨어의 한계치까지 확장시키고 있으며 실제로 그러한 sota모델들은 좋은 성능을 보여주기는 하지만, 높은 계산 비용으로 인해 실제로는 거의 사용되지 않는다는 것입니다.
이 문제를 해결하기 위해 저자들은 ‘Model Compression’, 즉, 특정 task에서 좋은 성능을 보여주는 large 모델을 성능 drop없이 더 작고 효율적인 architecture로 압축하는 것에 집중하였습니다. 대표적인 knowledge distillation 방법론에는 pruning과 knowledge distillation이 있는데요, 그 중에서도 pruning은 현실적으로 사용하는 데 제약 사항이 있다고 지적하였습니다. pruning은 가지치기 기법으로 모델의 가중치 연결 중 성능에 크게 영향을 주지 않는 부분을 제거함으로써 모델을 경량화 하는 기법입니다. 즉, 하나의 모델에서 이루어지는 방식이기 때문에 모델 구조에 dependent하다는 단점이 있습니다. 따라서 저자들은 Knowledge Distillation[12]방식으로 접근하였으며, KD를 robust 하고 effective 하게 사용할 수 있는 recipe를 실험을 통해 밝혀내고자 하였습니다.
위에서 설명했듯이 KD의 메인 아이디어는 teacher model을 작고 효율적인 student model로 ‘증류’시키는 것입니다. 위의 경우에는 크고 복잡한 sota모델들을 작고 가벼운 네트워크인 MobileNet등으로 바꾸는 것에 해당합니다.
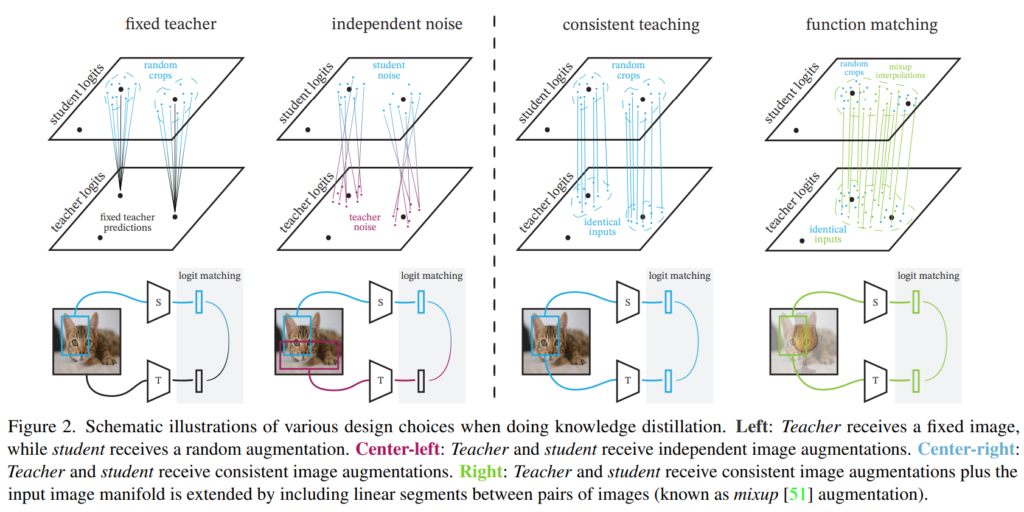
논문에서는 이러한 KD를 [그림 2]와 같이 student의 예측과 teacher의 예측을 일치시키는 것이라고 해석하였는데요, 이러한 관점에서 저자들은 중요한 두 가지 가설을 설정하고, 이를 실험적으로 증명하려 하였습니다. 첫 번째는 teacher와 student가 완전히 동일한 input image를 가져야 한다는 것입니다. 좀 더 구체적으로는 crop과 augmentation까지 동일해야 한다는 것이죠. 두 번째는 student의 일반화 성능을 확보하기 위해 많은 수의 데이터에 대해 teacher와 일치하는 결과값을 확보해야 한다는 것입니다. 즉, teacher와 student의 matching되는 예측 분포가 넓어야 한다는 것입니다. 이를 위해 aggressive한 mixup augmentation을 사용하였다고 합니다.
이러한 가설을 바탕으로, 저자들은 실험을 통해 KD가 실제로 잘 동작하는 데는 (1)이미지의 일관성, (2)aggressive augmentation, (3)긴 training time이 핵심적인 역할을 수행함을 증명하였습니다.
논문의 실험은 ImageNet-21k로 사전 학습하고 각 task의 데이터셋으로 fine tuning된 BiT-ResNet-152×2를 standard ResNet-50으로 distill하는 방식으로 진행되었습니다. 결과로만 놓고 보자면 ImageNet에서 새로운 ResNet-50 SOTA 82.8%를 설정했습니다.
Distillation for model compression
Intro의 [그림2]는 논문에서 비교하는 KD의 네 가지 방식을 나타내고 있습니다. 순서대로 fixed teacher, independent noise, consistent teaching, function matching에 해당하는데요, 결론부터 말씀드리자면 더 효과적인 것은 우측의 두 방법론에 해당하며 각 방법에 대한 설명은 아래에서 진행하겠습니다.
Investigating the “consistent and patient teacher” hypothesis
저자들은 intro의 두 가지 가설을 검증하기 위한 실험을 수행하였습니다. 즉, teacher와 student가 consistent view를 가질 때, 그리고 training time이 길어질 때 KD가 잘 동작함을 보이는 실험입니다.
Importance of “consistent” teaching
먼저 “일관성”이 중요하다, 즉, teacher와 student가 동일한 이미지를 보는 것이 중요하다는 것을 증명하는 실험을 진행하였습니다. 이를 위해 [그림 2]와 같이 총 네 가지의 option을 설정하였습니다.
Fixed teacher
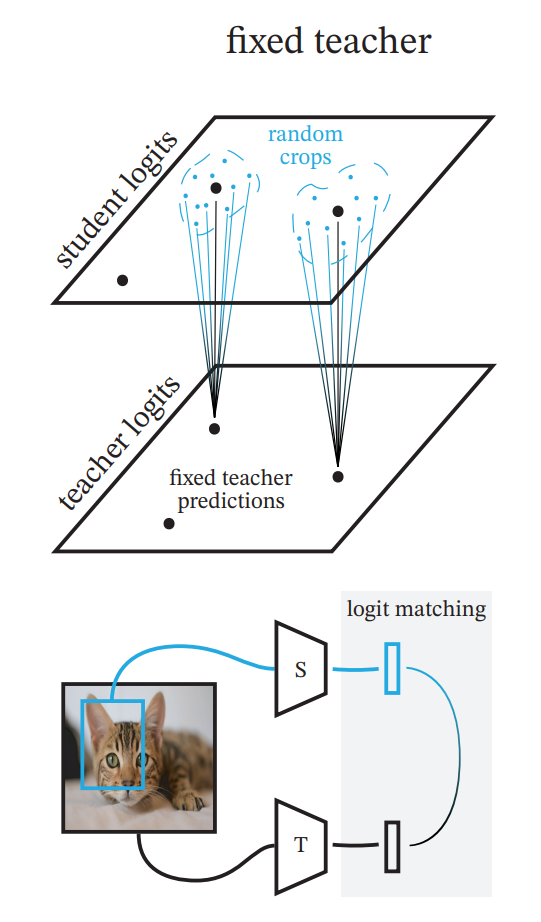
knowledge distilation에서 가장 기본적 방법론이기도 한 fixed teacher는 사전 학습된 teacher의 파라미터를 고정하고, student만 학습을 진행하는 방식입니다. 이때 student를 학습하는 과정에서 teacher의 예측 분포를 추론하는 것이 시간/메모리 측면에서 비효율적이기 때문에 student 학습 이전에 학습 데이터에 대한 teacher의 추론값을 미리 저장하여 학습 시에는 student에 대한 추론만을 수행하게 됩니다. 즉, 이 방법론에서 teacher의 추론값에는 noise가 포함되지 않습니다.
저자들은 fixed teacher에 관해 fix/rs, fix/cc, fix/ic_ens의 옵션으로 실험을 진행했습니다.
- fix/rs: teacher, student 둘 다 동일한 224*224의 이미지 입력. 별도의 augmentation 없음
- fix/cc: student에 mild augmentation(random crop) 적용
- fix/ic_ens: heavy augmentation(inception crop)적용 (inception random cropping은 size는 0.08~1.0, aspect ratio는 3/4~4/3사이에서 random하게 crop하는 것이라고 합니다.)
Independent noise
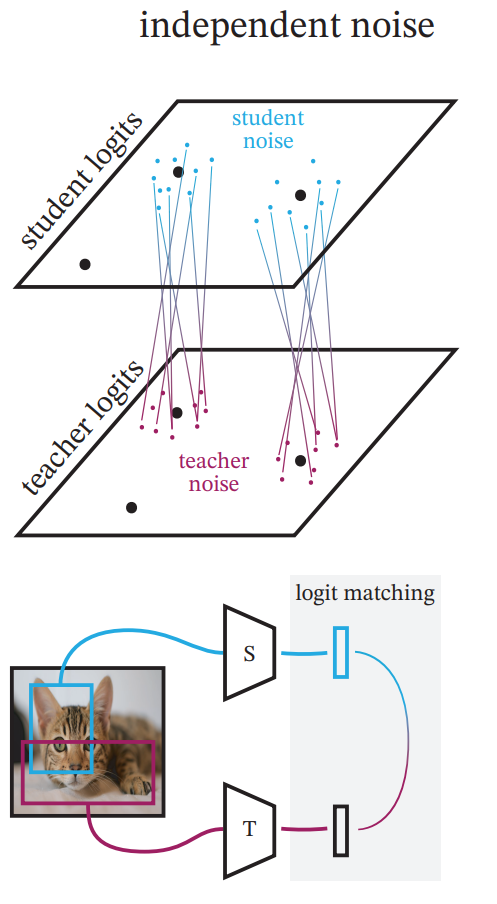
independent noise는 그림에서 알 수 있듯 student와 teacher모두 noise가 포함되지만, 각 noise가 서로 독립적으로 적용되는 방법입니다. 즉, 위 그림과 같이 teacher와 student가 이미지의 서로 다른 부분을 보고 있지만, 동일한 분포의 예측값을 만들어야 하는 상황입니다. 여기서도 위의 fixed와 비슷하게 augmentation의 강도에 따라 두 가지 조건으로 실험을 진행하였습니다.
Consistent teaching & Function matching
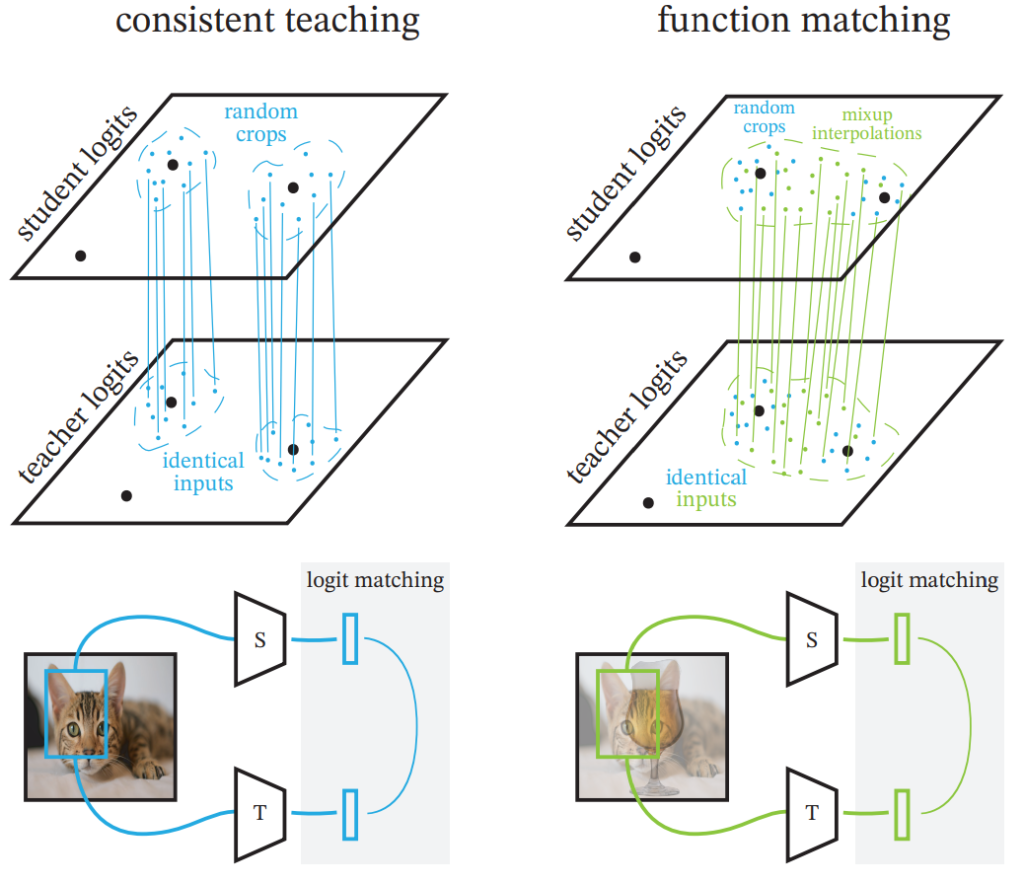
위의 방법들은 teacher와 student에 독립적으로 augmentation을 수행하였다면 consistent teaching과 function matching은 student와 teacher가 동일한 input을 가지는 방법입니다. 이때 function matching이 좀 더 넓은 예측값 분포를 가지는 것을 볼 수 있는데요 이는 mixup의 적용과 다른 도메인의 이미지를 사용하였기 때문입니다. 이러한 방법을 사용한 이유는 다른 도메인이나 학습 데이터에 존재하지 않았던 데이터의 예측값이 동일하게 나오려면 결국 모델의 구조가 동일해야 하므로 student가 teacher의 디테일한 부분까지 학습할 수 있도록 하기 위함이라고 합니다.
Experiments
Importance of ‘consistent’ teaching
먼저 저자들은 위의 네 가지 distillation 방식에 대한 비교 실험을 진행하였습니다.
저자들은 confounding factor를 제거하기 위해 [그림3]의 실험에서는 아래와 같이 하이퍼파라미터의 선택지를 미리 정의하고, 모든 경우의 수를 샘플링하여 실험을 진행하였다고 합니다.
- learning rates: {0.0003, 0.001, 0.003, 0.01}
- weight decays: { 1 \times 10^{-5}, 3 \times 10^{-5}, 3 \times 10^{-4}, 1 \times 10^{-3}}
- distillation temperatures: {1, 2, 5, 10}
총 80(4 * 5 * 4)가지 경우의 수의 실험을 수행하였고 그 결과를 [그림 3]의 연한 선으로 표시된 부분과 같습니다. 각 method에 대한 실험 결과 중에서 가장 validation acc가 높은 것을 해당 방법론의 최종 성능으로 리포팅하였으며, 굵은 선으로 표시된 부분에 해당합니다.
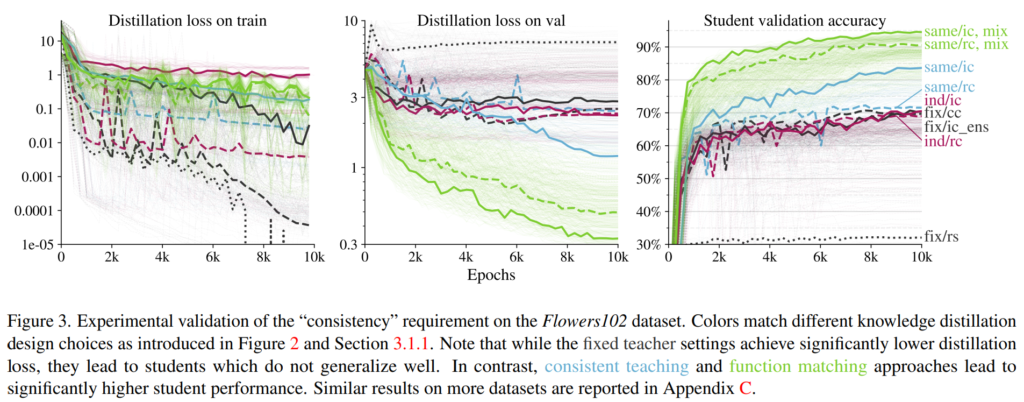
[그림3]의 세 그래프는 Flowers102 데이터셋에서 [그림2]의 네 가지 방법론에 대한 실험 결과입니다. 왼쪽부터 train의 distillation loss, validation의 distillation loss, student의 validation accuracy에 해당합니다.
[그림 3]의 실험은 knowledge distillation에서 “consistency”즉, student와 teacher가 동일한 input을 가졌을 때 성능이 좋음을 보이는 것입니다. “inconsistent”한 방법(fixed teacher, independent noise)으로 학습한 student는 “consistent”한 방법(consistent teaching, function matching)보다 낮은 score에서 수렴하는 모습을 보이고 있습니다.
가장 오른쪽의 그래프에 나타난 student validation accuracy를 통해 이를 확인할 수 있는데, student와 teacher의 input이 달라지는 Fixed teacher, Independent noise 방법론보다 student, teacher의 input을 동일하게 한 consistent teaching, function matching의 성능이 더 좋은 것을 확인할 수 있습니다. 왼쪽과 중앙의 그래프는 fixed teacher의 overfitting이 발생하는 것을 보여주고 있습니다. training loss를 보면 검은 색의 fixed teacher는 가장 낮아지는 것을 볼 수 있는데 validation loss를 보면 해당 방법에서 가장 높은 것을 볼 수 있습니다.
Importance of “patient” teaching
Distillation을 psudo-label을 이용한 supervised learning으로 해석할 수도 있습니다. 그러나 이러한 관점은 standard supervised learning의 문제점들을 그대로 계승하게 되는데요, 예를 들어 과도한 data augmentation를 적용하면 원본 이미지의 특징이 소실되어 student가 잘못된 라벨을 학습할 수도 있고 augmentation 강도가 낮은 경우 overfitting 문제가 발생할 수 있습니다.
그러나 distillation을 teacher와 student의 function matching이라 해석하면, 동일한 input을 사용하였을 때 강한 augmentation을 주어 학습할 수 있게 됩니다. Function Matching 자체가 student를 teacher에 fitting시켜 어떤 입력을 주더라도 두 모델의 출력이 같게 되도록 하는 것이기 때문이죠.
그렇다면 저자들은 teacher의 정보를 student가 가지고 있도록 하기 위해서는 오랜 시간에 걸친 학습이 필요할 것이라고 생각하여 이에 관한 실험을 진행하였습니다.
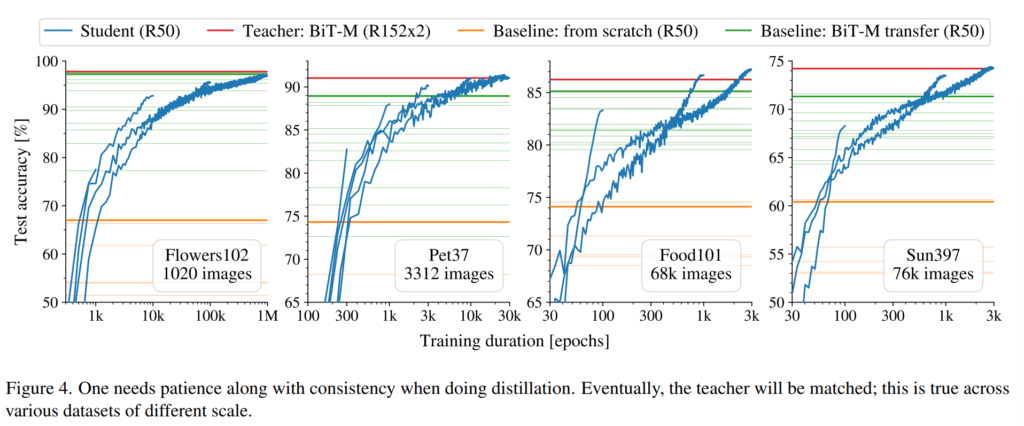
[그림4]는 서로 다른 4가지 데이터셋으로 hard augmentation을 적용하여 학습시킨 결과입니다. 즉, function matching으로 학습시켰을 때 student의 정확도 변화를 나타내었는데요, 충분한 학습을 거치게 된다면 student가 teacher의 성능에 도달할 수 있다는 것을 보여주고 있습니다. 인상적인 점은 Flowers 102에서는 100만 epoch를 학습시킬 때까지 꾸준한 성능 증가를 보이고 있습니다. 즉, 많은 수의 epoch로 학습을 진행해도 overfitting sign이 발생하지 않았다는 것을 확인할 수 있습니다.
Scaling up to ImageNet
아래의 [그림5]는 ImageNet데이터셋으로 실험한 결과를 나타낸 것으로 [그림4]에 사용한 데이터셋보다 더 challenge한 데이터로 실험을 수행함으로써 teacher와 student간의 consistency를 확보하는 것이 범용적으로 유용한 방법임을 보였습니다.
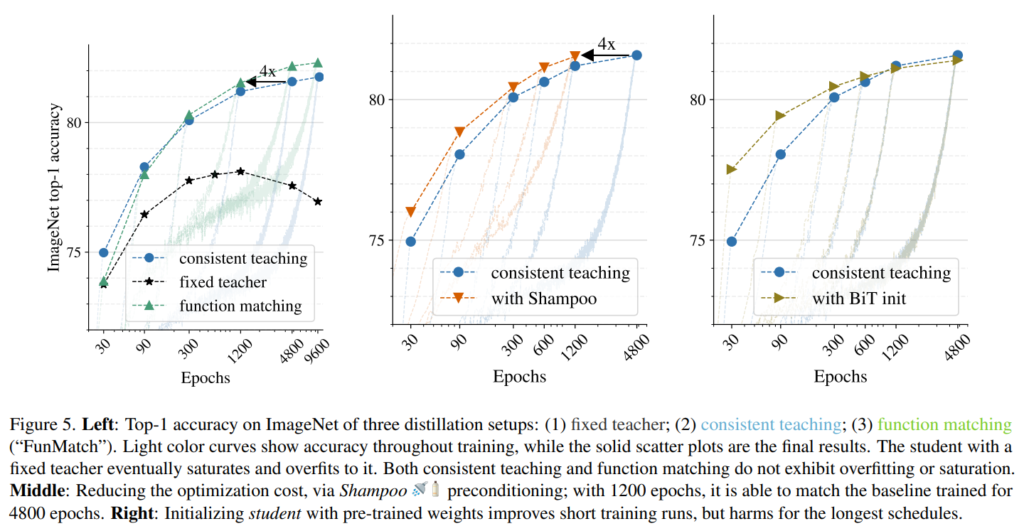
Top-1 acc on ImageNet of three distillation setups
왼쪽의 그래프는 Fixed teacher, consistent teaching, function matching 방식으로 각각 distillation을 수행한 결과로, 각 epoch 별 ImageNet의 validation accuracy입니다.
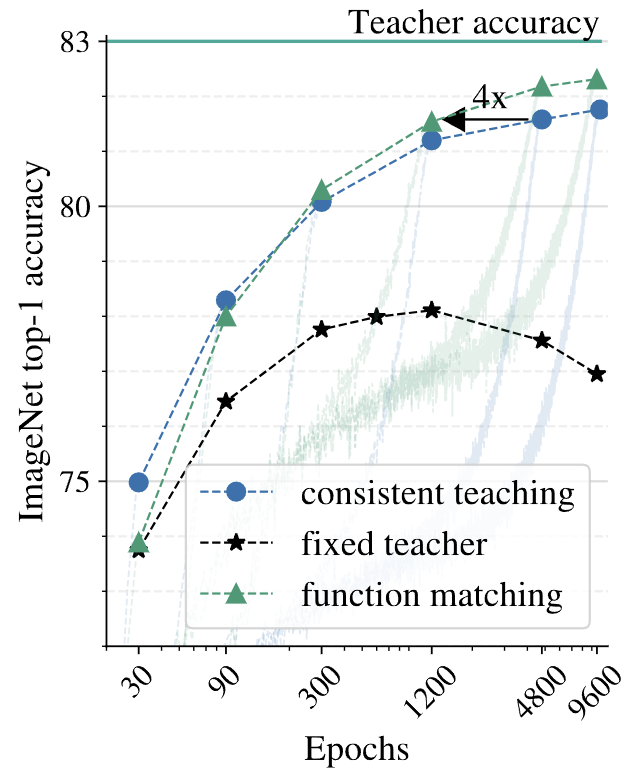
이때 teacher는 위와 동일한 resnet152x2이며 imagenet1k 기준으로 83%의 top1 acc를 달성한 모델입니다.
위의 사항을 바탕으로 결과를 확인해 보면 fixed teacher는 약 600epoch이후부터는 overfitting에 의해 정확도가 낮아지는 것을 볼 수 있습니다. 반면에 teacher와 student가 consistent한 input을 가지는 consistent teaching, function matching은 600epoch 이후에도 꾸준한 성능 향상을 보여주고 있는 것을 확인할 수 있다.
점으로 표시된 부분은 각각 30, 90, 300, 1200, 4800, 9600에서의 imagenet 성능을 나타내며, 흐리게 표시된 부분은 각 epoch 까지 학습하는 동안의 accuracy 변화를 나타낸 것이다.
Reducing the optimizing cost via shampoo preconditioning
저자들은 앞선 실험들이 매우 긴 epoch 동안 학습이 이루어진다고 하며 이 과정에서 optimization의 computation에 bottleneck이 발생한다고 언급하였습니다. 특히 function matching은 고정된 이미지의 라벨값을 맞추는 것이 아니라 teacher의 output을 맞추는 것이므로 최적화가 더 어려워진다고 합니다.
이에 저자들은 optimizer를 변경하여 optimization bottleneck을 해소하고 학습 시간을 단축시키고자 하였습니다. [그림3]의 중간 그래프는 각각 function matching 방식으로 distillation을 수행할 때, 서로 다른 optimizer인 adam과 shampoo optimizer를 사용한 결과를 비교한 것이다.
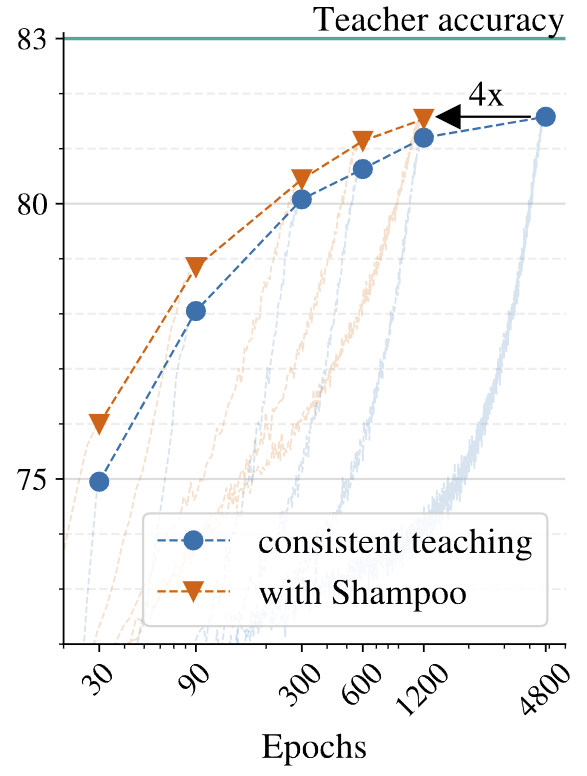
위의 결과를 보면 adam을 사용한 것 보다 shampoo를 사용한 경우 4배 더 빠르게 학습이 진행되는 것을 확인할 수 있다.
Initializing Student
앞 실험과 마찬가지로 원활한 최적화를 위해 저자들이 실험한 부분으로, 이 부분에서는 가중치 초기화를 사용합니다.
transfer learning은 사전 학습된 모델의 가중치로 모델을 초기화하고, 추가적인 학습을 통해 빠르게 높은 성능을 달성할 수 있도록 하는 방법론이죠. 이에 저자들은 student모델을 pretrained BiT-M-ResNet50의 가중치로 초기화하여 distillation을 진행함으로써 scratch로부터 학습한 기존 결과와 비교하였다.
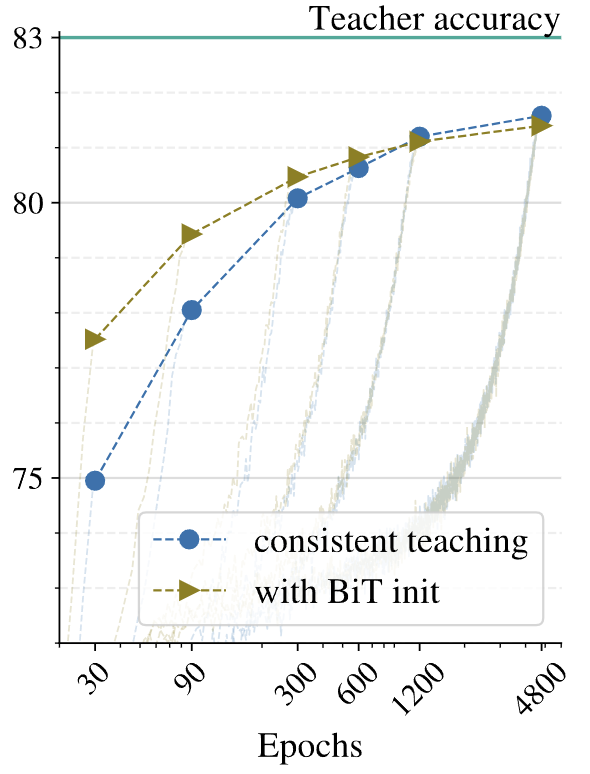
위의 그래프는 해당 결과를 나타내는 것으로, 결과적으로는 가중치 초기화를 적용한 것이 초기 30epoch 정도에는 약 2% 앞선 성능을 보였으나, 학습이 충분히 이루어질수록, 성능 차가 줄어든 것을 볼 수 잇습니다. 즉, 충분한 학습 시간이 주어지면 초기화의 이점이 점차 사라지며, 긴 학습 기간 동안 초기화 없이도 비슷하거나 약간 더 나은 성능을 달성할 수 있음을 실험적으로 증명하였습니다.
Distilling across different model families
저자들은 KD가 서로 다른 family일 때, 즉, ResNet시리즈가 아닌 다른 모델을 student로 설정하였을 때도 효과가 있음을 입증하기 위해 MobileNet을 student로 설정하여 실험하였습니다.
Finetuning ResNet-50 with augmentations
[그림3]의 실험으로 저자들은 실험을 통해 knowledge distillation에서 teacher와 student에 입력되는 이미지가 동일할 때, 그리고 입력 이미지에 강한 augmentation을 적용할수록 student가 좋은 성능을 달성할 수 있음을 보였습니다. 또한 [그림4]의 실험을 통해 긴 training schedule을 가질 때 student가 좋은 성능을 달성할 수 있음을 확인하였습니다. 이때, 저자들은 위의 recipe에 의한 성능 향상에서 distillation의 효과에 관한 의문을 제기하였습니다. 따라서 strong augmentation을 적용하여 긴 training schedule로의 학습을 수행한다면 distillation이 아닌 baseline resnet또한 성능이 향상되는 것은 아닌지 실험하고자 하였습니다.
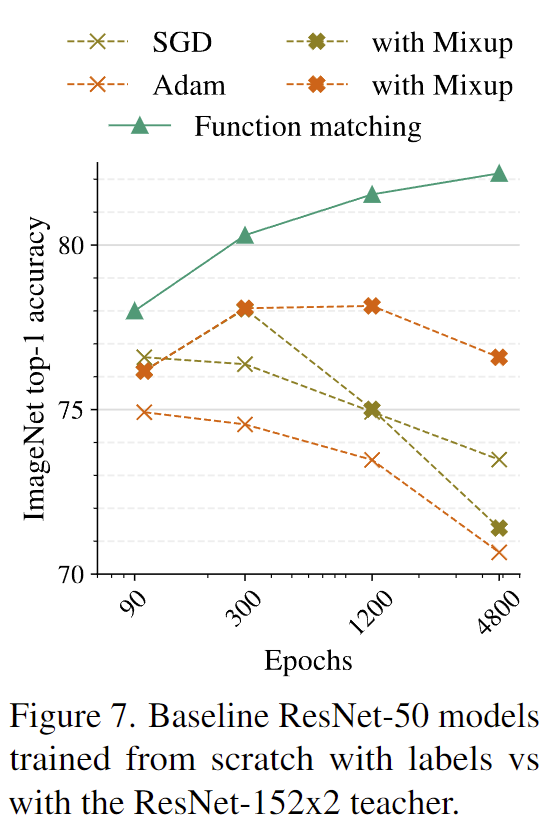
[그림7]은 baselie resnet50 모델을 scratch로 학습시킬 때 long training epoch와 mixup을 적용한 것과 distillation 방법론인 function matching간의 결과를 의미합니다. distillation 없이 단순히 training recipe만으로는 성능 향상이 이루어지지 않고 오히려 overfitting에 의해 점차 성능이 하락하는 것을 보여줌으로써, 앞선 실험에서의 성능 향상은 distillation이라는 요소가 크게 작용하였기에 발생한 것임을 확인하였습니다.
안녕하세요, 천혜원 연구원님, 좋은 리뷰 감사합니다. 좋은 Knowledge distillation을 위해서 student와 teacher모델이 어떻게 학습을 해야 하는지 잘 분석한 논문이네요. 특히 student와 teacher모델이 완전히 동일한 input을 가져야 하는 부분이 인상깊었습니다. 실험적으로 augmentation까지 동일한 이미지를 넣어주는것이 좋다는것을 보이기는 했는데, 왜 이러한 가설을 세웠는지, 혹은 왜 이게 좋은 성능을 냈는지에 대한 저자의 분석이 있나요? 어떻게 이런 아이디어가 나온건지 궁금합니다.
감사합니다.
안녕하세요 허재연 연구원님! 댓글 감사합니다.
우선 논문에 따르면 해당 부분의 idea는 distillation을 student와 teacher의 function matching으로 해석한 것을 base로 가설을 설정한다고 언급되어 있습니다. Function이 동일하다, 즉, 동일한 x값이 주어졌을 때 동일한 y값을 출력한다는 것을 전제로 해당 가설을 설정한 것으로 보입니다.
안녕하세요. 좋은 리뷰 감사합니다.
teacher와 student에 대해서 본 논문만의 가설 설정을 가져가며 실험으로 딱딱 증명해내는 것이 대단하다고 생각이 들은 논문인 것 같습니다. fine tuning된 BiT-ResNet-152×2를 standard ResNet-50으로 distill하는 방식으로 진행하였다고 하였는데 다른 모델로의 실험은 없는 걸까요? 논문 실험들을 보면 모든 teacher와 student에 적용될 수 있을 것처럼 들리는데 그런것 치고는 teacher가 Bit-ResNet, Student가 Resnet인 모델만 실험해본거 같아 질문드립니다.\
감사합니다.
안녕하세요 김주연 연구원님 댓글 감사합니다.
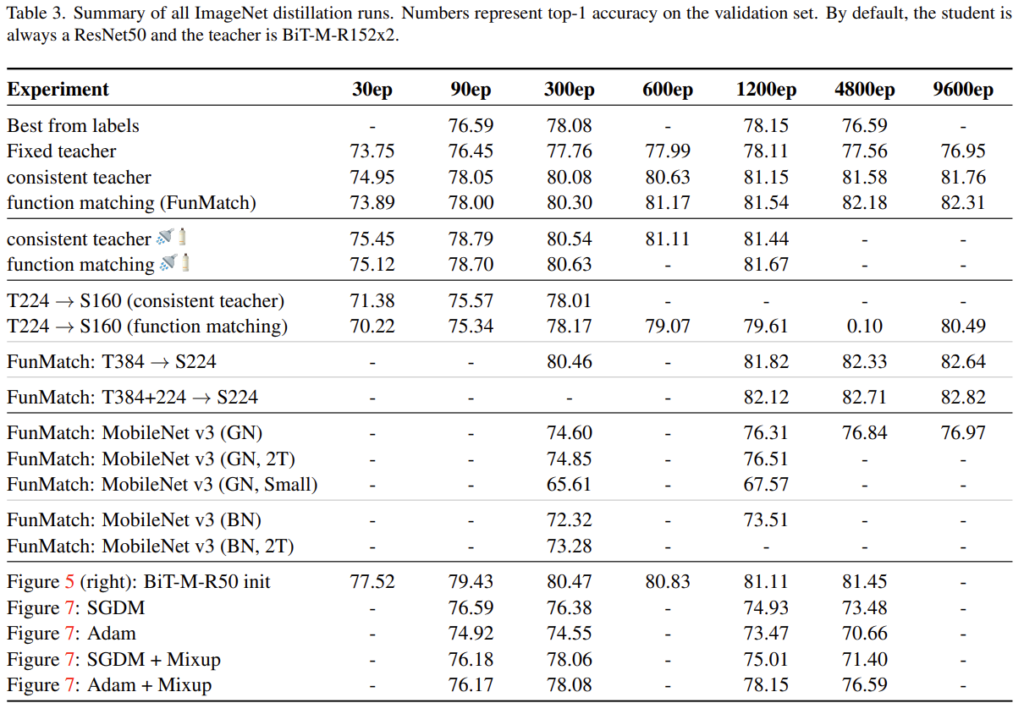
논문에서는 추가적으로 MobileNetV3모델을 student로 사용한 실험을 진행하였습니다. 본문 하단에 [표3]을 추가해 두었습니다.
질문해 주신 실험은 [표3]의 FunMatch: MobileNet v3에 해당하는데요, Batch Norm대신 GroupNorm을 사용하고, 5M 225M의 파라미터와 연산량을 가지는 가벼운 모델에 대해 76.97의 imagenet분류 성능을 달성하였다고 합니다. 해당 성능은 MobileNetv3의 sota성능이라고 하네요.
좋은 리뷰 감사합니다.
본 논문을 통해, 적절한 knolwedge distillation을 위한 design choice를 명시적으로 밝힌 것이 본 논문의 contribution으로, 정리하자면 teacher와 동일한 데이터로 학습시키고 강한 augmentation을 적용하여 오래 학습시켜야 한다는 것으로 이해하였습니다.
리뷰와 관련하여 몇가지 질문이 있습니다.
우선 pruning은 현실적으로 사용하는 데 제약 사항이 있다고 하셨는데, 모델에 dependent하다는 것이 현실적으로 어떤 제약을 의미하는 것인지 궁금합니다. 동일한 네트워크이더라도 학습된 모델이 모두 다른 방식으로 pruning을 진행한다는 의미인가요?
또한, Figure 5를 비롯하여 다른 실험 결과에서도 independent noise에 대한 비교를 확인하기 어려운데, 혹시 independent noise에 대한 실험 결과가 따로 없었거나 논문에서 관련한 분석은 없었는지도 궁금합니다.(추가로 aggressive augmentation은 어떤 실험을 통해 입증하였는지도 설명 부탁드립니다.)
안녕하세요 이승현 연구원님! 댓글 감사합니다.
1. model dependent 의미
Pruning의 model dependency의 의미는 초기 모델 architecthue에 dependent하다는 것입니다. pruning은 large model에서 가중치의 중요도를 산정하고, 일정 비율만큼의 가중치를 잘라내는 것을 의미하는데요, 때문에 완성된 모델의 기본 틀 자체는 처음 모델의 것을 그대로 가져가게 됩니다. 구조 자체가 크게 달라지지 않는다는 것이죠. 예를 들자면 ResNet152를 pruning하게 되면 가중치가 일부 제거된 ResNet152가 될 뿐 MobileNet이 될 수는 없다는 의미입니다.
2. independent noise 실험
independent noise는 Figure 5이외 별다른 실험을 수행하지는 않았습니다. 논문에서 언급된 것도 해당 부분이 전부였는데요, 제 생각에는 fixed 역시 independent의 한 case를 의미하기에 input의 augmentation이 다른 경우는 fixed teacher에서만 실험을 수행한 것이 아닌가 합니다.
3. aggresive augmentation
Figure 3를 통해 augmentation을 aggressive하게 주는 것이 더 좋은 성능을 보이는 것을 입증하였습니다. 추가로 그래프에서 각 option의 점선은 weak augmentation, 실선은 hard augmentation을 나타내는데요, 각 option간의 결과를 비교해보면 강한 augmentation을 준 경우에 더 좋은 성능을 보이는 것을 확인할 수 있습니다.