이번에 소개드릴 논문은 21년도 CVPR에 게재된 RobustNet이라는 방법론입니다. 해당 논문은 Semantic Segmentation task의 Domain Generalization 성능을 향상시키기 위한 방법론입니다.
Intro
먼저 Domain Generalization에 대해서 간단히 알아볼까요. Domain Generalization은 Domain Adaptation에서 한층 더 발전된 task로 볼 수 있는데, 말 그대로 어떤 domain에서도 모델이 잘 동작할 수 있는 일반화 성능을 향상시키자는 것이 목표입니다.
조금 더 구체적으로 설명드리면, Domain Adaptation의 경우 source domain의 데이터 셋으로 입력 영상(x_{s})와 GT(y_{s})를 함께 사용을 할 수 있지만 Target domain에 대해서는 GT(y_{t})없이 영상(x_{t})만을 입력으로 사용할 수 있게 됩니다.
하지만 Domain Generalization의 경우에는 학습 과정에서 Target domain의 입력 영상(x_{t}) 마저 사용을 하지 못한 채 오직 source domain의 데이터 (x_{s})와 (y_{s})만을 가지고 학습을 수행해야 함을 의미합니다.
이러한 Domain Generalization(DG)의 목적은 결국 모델이 실제 추론을 수행하는 상황에서 어떠한 domain이 올지 모르는 상황이기 때문에 Domain Adaptation(DA)처럼 특정 도메인을 target으로 간주하여 학습 때 이용 가능하다는 것 자체가 비현실적으로 보고, 따라서 source domain만으로 학습하여 타 도메인을 평가하고자 하는 것입니다.
이러한 Domain Generalization task는 크게 2가지 방식으로 방법론들이 나뉜다고 합니다. 한가지 방식은 source dataset을 여러 개의 target domain으로 구성된, 범용적인 데이터 셋을 구축해서 학습을 시키는 방법이죠. 사실 이 방식으로 접근하는 방법론들을 제가 자세히 보지는 않아서 부정확할 수는 있지만, 다중 도메인 데이터 셋을 구축한다는 방식은 너무나도 단순한 접근이라고 생각되어집니다. 마치 모델의 generalization performance를 보충해주기 위해 세상에 존재하는 모든 데이터로 학습을 시키자는 느낌이 들기도 하고.. 이를 구축하기 위해서는 엄청난 비용이 필요한 법이겠죠.
따라서 최근에는 domain invariant feature를 잘 추출할 수 있도록 방법론들을 설계하는 편입니다. 이는 target domain에 대한 정보를 가져올 수 있는 DA와 달리 DG는 source domain만을 보고 학습을 해야하기 때문에 어떠한 target domain이 오더라도 source domain과 유사한 특징들을 가지는, domain invariance를 잘 설계하고 학습해보겠다는 것입니다.
일반적으로 domain specific한 정보와 domain invariant한 정보를 나누는 방법으로는 영상을 style과 content로 구분을 두는 방식이 존재합니다. 제 예전 리뷰들을 보신 분들이라면 이러한 개념에 대해서 쉽게 받아들이실 수 있을 것으로 생각됩니다.
조금 더 자세히 말씀드리면, 그림1은 여러 CNN 모델과 Human에 대해서 아래 그림을 보여주고 각각이 얼만큼 정확하게 예측을 수행하였는지를 평가한 것입니다. 보시면 제일 좌측에 original부터 시작해서 우측에 texture까지 총 5장의 영상이 존재를 하는데, 기존의 모델들의 경우 똑같은 고양이 사진을 실루엣만 보여주거나(3열), edge만 보여주는 경우(4열) 정답을 맞추는 확률이 매우 떨어지는 것을 볼 수 있습니다.(Resnet50의 경우 정확도가 18%밖에 되지 않음.)
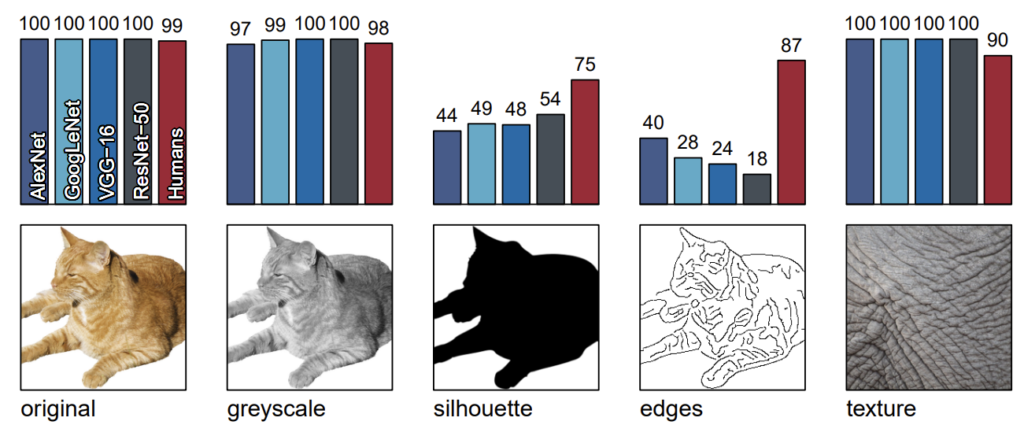
반면에 사람의 경우에는 고양이의 형태를 알고 있기 때문에 실루엣이나 엣지만 보아도 고양이라는 것을 쉽게 유추할 수 있습니다. 제일 우측에 texture의 경우에는 정답이 인도 코끼리이지만 매우 확대해서 촬영한 사진이기 때문에 실제로 코끼리인지 유추가 어려운 편입니다. 하지만 색상이나 질감 정보를 토대로 코끼리일 가능성이 높다고 판단을 할 수 있죠.
여기서 CNN 모델들은 4개의 모델 모두 100%의 정확도로 코끼리임을 예측하였는데, 이는 모델이 shape과 같은 content 정보 보다는 texture와 같은 style 정보에 더 편향되어서 대상을 인식한다는 것을 간접적으로 보여주는 예시입니다.
이러한 관점을 다르게 해석해보죠. 자율주행 관점에서 낮과 밤에 촬영한 영상은 빛의 조도로 인하여 영상의 색감 자체가 매우 상이한 것을 볼 수 있습니다. 하지만 촬영되는 대상의 구조적 형태는 큰 변화가 없죠. 이러한 낮과 밤의 도메인 차이는 밝기와 색상, 질감 등 style information으로부터 비롯된다는 것을 유추할 수 있습니다.
여기서 만약 모델이 style information에 편향되어서 학습을 하게 된다면? source domain의 style과 상이한 target domain이 입력으로 들어왔을 때 좋지 못한 성능을 보일 것입니다. 반대로 domain invariant한 content 정보에 편향되어 모델이 학습된다면 상이한 style 정보인 target domain 데이터가 들어온다 하더라도 그럴듯한 성능을 보여줄 것으로 기대할 수 있습니다.
즉 요약하면, 영상을 style과 content로 구분을 지을 수 있다. 그리고 이때 style 정보는 도메인에 특정된 정보이기 때문에 해당 정보에 편향되도록 모델이 학습을 하게 되면 generalization 성능을 향상시킬 수 없기에, 모델이 domain-specific 정보를 배제하고 invariance 정보만을 토대로 학습을 하도록 유도해야한다는 것이 DG task의 목적이고 본 논문의 목적이기도 합니다.
style 정보를 배제하고, content 정보만을 살린다는 컨셉은 쉽게 이해하셨을 거라고 생각이 됩니다. 그렇다면 이러한 style과 content 정보를 어떻게 구분하고 나타낼 수 있을까요? 일반적으로 style이라고 함은 영상에서 반복적으로 나타나는 색감 정보들을 나타내기 때문에 통계학적인 측면으로 표현할 수 있습니다.
가령 feature map의 평균과 분산과 같은 통계학적인 정보들이 해당 feature map의 스타일을 대표할 수 있다는 것이죠. 여기서 저자는 feature map을 서로 채널 축 사이에 correlation을 나타내는 gram matrix(e.g., CxHW X HWxC –> CxC 꼴의 matrix)로 만들어서 해당 gram matrix의 domain specific information(즉 style 정보)를 제거하는 방향으로 설계하고자 하였습니다.
보다 구체적으로, 채널간에 correlation matrix가 영상의 style 정보를 담고 있다면 해당 matrix에 whitening transformation이라는 기법을 적용하여 style information을 모두 제거한다고 합니다. 이렇게 style information이 제거된 feature map을 가지고 추론을 수행하면 모델의 generalization 성능이 향상된다는 것이죠.
여기서 whitening transformation에 대한 개념은 해당 블로그 글을 참조하시면 좋을 것 같습니다. 결과적으로 whitening transformation을 gram matrix에게 적용한다는 의미는 gram matrix의 대각 행렬 성분을 1, 대각외 선분들을 0으로 만들겠다는 것입니다. correlation matrix의 값이 Identity matrix가 된다면 이는 곧 style 성분이 모두 배제된 행렬이라고 볼 수 있게 되는 것입니다.
이러한 방향성 자체는 크게 문제되는 것은 없지만, 사실 세부적으로 문제가 되는 부분이 몇가지 존재 합니다. 가장 첫번째로 whitening transformation이라는 것은 행렬의 공분산과 eigen value를 계산하는 등 연산량이 무척 많이 들어가게 되며 미분도 불가능하기에 학습 및 추론단계에서 부적합하다는 점입니다.
두 번째로는 whitening 기법을 통해 대각 행렬 성분만을 1로 만들고 그 외의 성분들을 0으로 만드는 것이 domain specific 정보만을 제거하는 최선의 방법이냐는 것입니다. 비록 채널 축의 correlation matrix 내 대부분의 성분들이 style information을 가지고 있음은 부인할 수 없지만, 이 중에서도 일부는 domain invariance한 정보를 가지고 있을 수 있기 때문에 모두를 제거하기 보다는 부분적으로 제거해야할 필요성이 존재합니다.
따라서 본 논문에서는 첫번째 문제를 해결하기 위해 직접적인 whitening transformation 계산을 하는 것이 아닌 whitening transformation이 적용되었을 때의 결과값을 모델이 직접적으로 추론할 수 있도록 하는 loss function을 적용하여 학습하는 방식을 채택합니다.
둘 째로, gram matrix 내에서 domain specific한 정보만을 추출해서 0으로 만드는 마스크를 추출하는 방법에 대하여 새롭게 제안합니다. 해당 방법론의 컨셉은 그림2에서 확인하실 수 있으며 보다 자세한 설명은 밑에서 드리겠습니다.
Preliminaries of Whitening Transformation
우선 Whitening Transformation(WT)에 대하여 어떻게 계산이 되는지 수식적인 부분을 알아보도록 하겠습니다. 입력에 대한 feature map X \in R^{C \times HW} 에 대하여 WT 연산을 적용하였을 때의 결과 값 \tilde{X} \in R^{C \times HW} 는 다음과 같은 수식으로 계산이 됩니다.
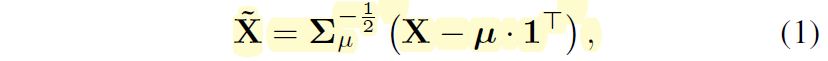
여기서 \Sigma, \mu 는 각각 역 제곱근된 공분산 행렬과 평균 벡터를 의미하며 이들은 다음과 같이 계산할 수 있습니다.
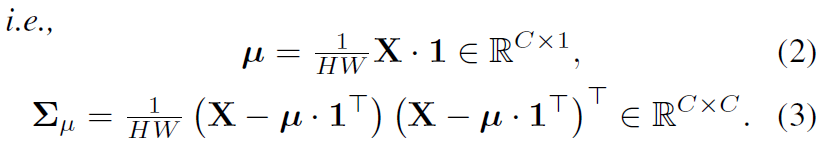
즉 공분산은 원래의 feature map에 평균을 뺀 값끼리 내적을 한 후 전체 크기로 나누면 계산을 할 수 있습니다. 이렇게 수식3을 통해 계산된 공분산에 eigen decompsing Q \Lambda Q 을 수행해주게 되는데 여기서 Q는 CxC 크기를 지니며 공분산의 eigen vector의orthogonal matrix로 보시면 됩니다. 그리고 \Lambda 의 경우에는 matrix Q의 eigenvector와 대응되는 eigen value들이 대각 행렬 꼴로 표현되는 대각행렬로 이해하시면 됩니다.
위와 같이 공분산 행렬을 eigen decompsing한 후 공분산의 역제곱근을 계산하기 위해서는 아래 수식꼴로 표현하여 계산을 한다고 합니다.
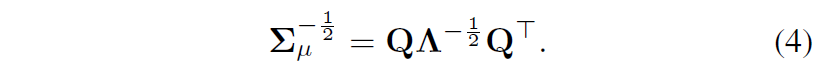
수식 4를 통해 계산한 공분산의 역제곱근이 whitening transformation matrix이며 이를 적용해주면 WT를 수행할 수 있게 됩니다. 다만 이러한 역제곱근을 계산하기 위해 공분산 행렬에 eigen decompositio을 수행하는 과정은 매우 연산량이 많이 들기에 추론 단계에서 부적합하며, 기울기의 역전파 계산도 되지 않아 학습에 사용하기도 어렵다고 합니다.
이러한 문제를 해결하고자 기존 방법론 중 GDWCT라는 방법론은 Feature map의 covariance matrix가 identity matrix가 되도록 하는 loss를 주어서 학습을 시켰다고 합니다.
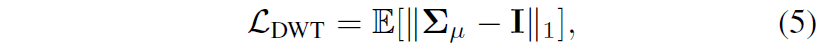
즉 모델이 직접 WT된 feature map을 encoding하도록 학습을 시켰다는 것이죠. 이렇게 할 경우에 domain specific한 정보가 제거되어 content 정보만이 유지된 feature map을 만들 수 있지만, 사실 feature map의 공분산 안에 domain specific한 정보와 invariance한 정보가 한데 섞여 어울릴 수도 있기 때문에, 이를 disentangle해주어야 한다고 저자는 주장합니다.
Instance Whitening Loss
먼저 instance level에서의 whitening loss에 대해서 알아보죠. \Sigma_{\mu (i,i)} 를 feature map의 공분산에 행렬 내에서 대각 행렬의 원소들이라고 보고, \Sigma_{\mu (i,j)} 를 대각이 아닌 모든 원소들로 볼 수 있습니다.
여기서 수식 5에 대한 loss를 아래 수식 2개로 쪼개서 볼 수 있게 됩니다.
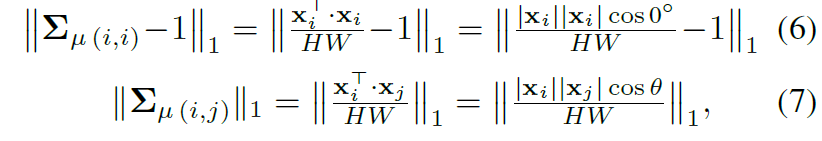
즉 수식 6은 대각행렬 값들을 1로 만들어 주기 위함으로 대각행렬에만 적용되며, 그 외에 값은 7번의 수식에 적용됨을 알 수 있습니다. 그런데 이때 수식 6과 7을 loss function으로 삼아서 이를 최소화하도록 학습을 하게 될 경우 각 채널의 크기 \root(HW)만큼 feature map의 값이 커지게 됩니다.
이것이 무슨 말이냐면, 수식6에서 learnable parameter는 x_{i} 에 해당하는데, 이때 해당 값들의 scale이 HW만큼 커지게되면 HW로 나누어줄 때 당연히 1의 값을 가지게 되고 1-1은 0이 되어서 학습 방향성은 대각행렬들의 원소 값들이 HW가 되도록 학습이 진행됩니다.
근데 수식7의 경우에는 0이 되기 위해서 x_{i}, x_{j} 가 모두 0에 가까운 값이 되도록 학습을 할 것입니다. 즉 수식6과 수식7을 동시에 optimizing하게 되면 두 수식이 서로 충돌하게 되어 동시에 최적화를 하기 힘든 상황이 발생하게 됩니다.
이 문제를 해결하기 위해서 저자는 feature map X에 대하여 instance normalization을 수행해주었다고 합니다.
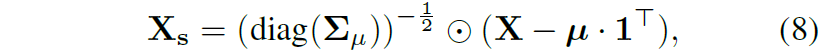
이것은 저희가 아는 BatchNorm, LayerNorm과 비슷하게 pytorch의 InstanceNorm2D로 구현을 할 수 있습니다.
아무튼 이렇게 instance normalization을 수행하게 되면 해당 normalization은 HW scale에 대하여 단위 값으로 스케일을 조정했기에, 이러한 정규화된 feature map으로 계산한 공분산 행렬의 대각 원소 값들이 모두 1의 값을 가지게 된다고 합니다.
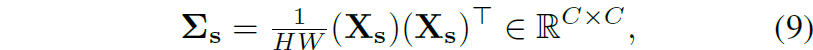
따라서 수식6에 대한 loss는 계산할 필요 없이 대각 원소 외에 값들이 0이 되도록 loss를 계산하면 되는 것이죠. 여기서 공분산 행렬은 대칭 행렬이기 때문에 loss 계산은 대각 행렬을 기준으로 위쪽 혹은 아래쪽 면에 대해서만 수행하면 됩니다.
따라서 이러한 instance level에서의 whitening loss는 아래 수식과 같습니다.
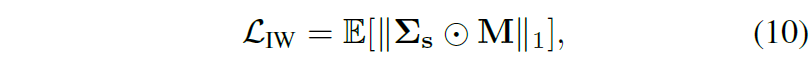
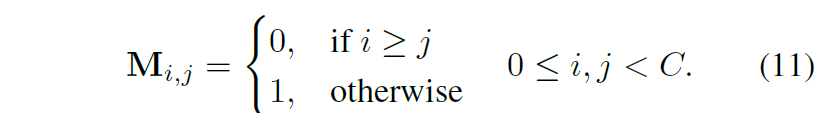
수식 11의 마스크는 대각행렬 여부를 판단하는 것으로 대각 행렬이 아닌 지점은 1이며 해당 값들에 대해 0이 되도록 regularization을 적용해준 것으로 이해하시면 됩니다.
Margin-based relaxation of whitening loss
그런데 위에 수식 10과 같이 반대각 성분들을 모두 0으로 만들어버리면 feature map의 discrimination 성능이 저하가 된다고 합니다. 따라서 저자는 특정 margin 값 보다는 더 큰 상태에서 WT loss가 적용되었으면 하는 바람으로 다음과 같은 형태로 수식 10을 조정했다고 합니다.
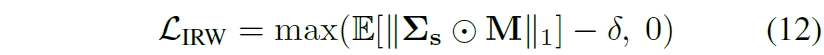
그냥 쉽게 말해서 0이 되도록 하지 않고 margin 값 이상은 유지하도록 하는 loss 입니다.
Separating Covariance Elements
다음은 본 논문에서 가장 중요한 domain specific 정보와 domain invariance 정보를 분리하는 것에 대한 내용입니다.
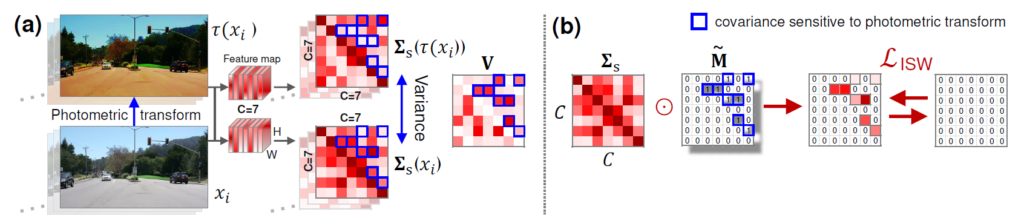
저자는 feature map에서 domain specific한 정보와 invariance한 정보를 선택하기 위해서, 입력 영상에 원본 이미지와, 다양한 photometric distortion을 적용한 영상을 각각 모델에 태워서 feature map을 뽑았다고 합니다. 즉 domain specific한 정보를 영상의 texture, color 등으로 보게 된다면, 원본 영상과 photometric distortion이 적용된 두 feature map의 covariance matrix 성분이 상이한 부분이 존재할 것입니다.
이렇게 상이한 부분은 domain-specific한 정보로 볼 수 있게 되고, 반대로 두 공분산 행렬끼리 서로 유사한 요인들에 대해서는 domain-invariance한 content information으로 간주할 수 있을 것입니다.
먼저 저자는 n epoch 동안은 WT loss를 적용하지 않은 채로 학습을 시켜 모델이 정상적인 domain specific한 정보를 잘 담을 수 있도록 내버려두었다고 합니다. 그 이후에 어느정도 domain에 편향된 정보를 담기 시작하면, photometric distortion이 적용된 영상과 원본 영상을 각각 태워서 나온 feature map으로 부터 공분산을 계산하고 각각의 공분산의 차이를 다음과 같이 계산하였다고 합니다
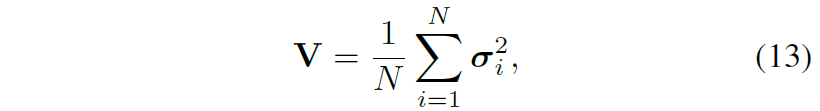
여기서 는 i번째 photometric 영상과 원본 영상 간에 공분한 행렬의 차이를 나타내는 분산을 의미합니다.
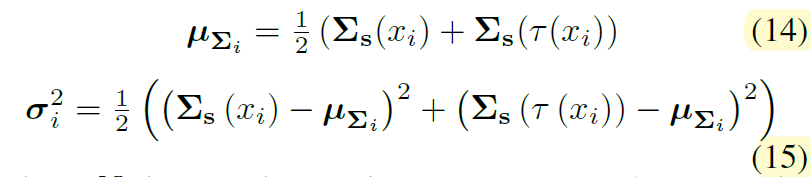
즉 수식 14에서 두 영상의 공분산을 더해서 나누는 공분산의 평균을 계산하고, 이렇게 계산된 공분산 평균을 각각의 공분산 행렬에 적용함으로써 공분산 행렬의 분산을 계산한 것입니다. 즉 수식 13번의 V는 N개의 서로 다른 Photometric distortion을 적용한 영상과 원본 영상과의 공분산 행렬의 분산을 가지는 값이다 라고 이해하시면 됩니다.
여기서 저자들은 이러한 분산 행렬 V가 photometric transformation에 상당히 민감할 것으로 가정을 하였는데, 이는 곧 높은 분산 값을 지니는 공분산 원소는 domain-specific한 정보를 지니고 있다는 가능성이 큰 것을 의미합니다.
따라서 저자는 해당 V 행렬에 대하여 k means clustering을 수행하였고 이를 통해 low group과 high group으로 V 행렬을 나누게 됩니다. 여기서 high group에 속하는 값들은 domain specific한 성분들을 의미하며, low group으로 묶인 값들은 domain invariance한 값으로 볼 수 있는 것이죠.
최종적으로 high group이 domain generalization을 위해서 제거해야할 성분들이기 때문에 high에 해당하는 인덱스를 1 그외에는 0으로 두는 마스크를 생성해서 수식 11의 loss를 계산하였다고 합니다.
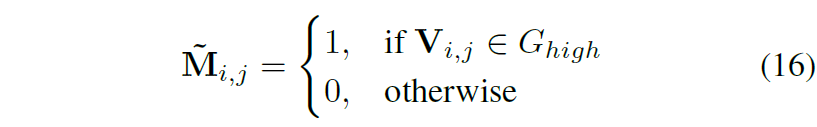
따라서 최종 loss는 다음과 같습니다.
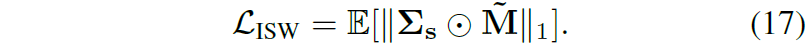
너무 수식만 나열하면서 설명을 해서 감이 잘 안잡히실 수도 있을 듯 합니다. 하지만 컨셉 자체는 간단 명료하며 수학적인 부분도 엄청 복잡한 것은 아니기에 차근차근 따라가면 어느정도 이해는 하실 수 있을 것으로 생각됩니다. 위에서 다룬 이야기를 그림으로 나타내면 아래와 같습니다.
Network Architecture with Proposed ISW loss
다음은 저자가 제안하는 ISW loss를 어디에 적용하는지에 대한 구조적인 설명입니다.
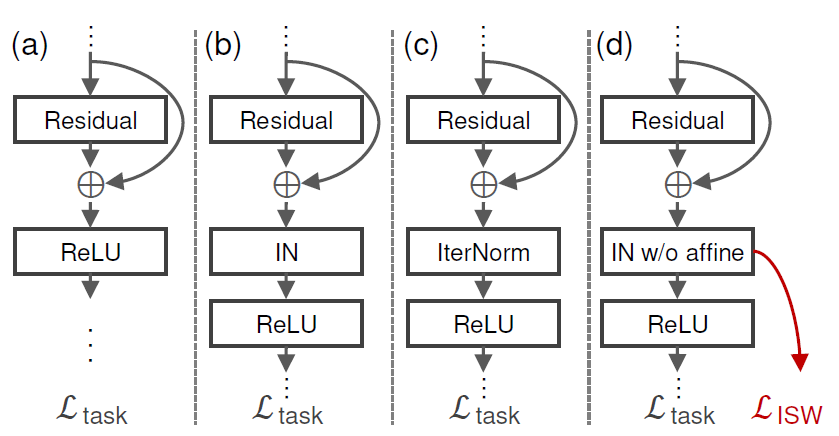
그림4-a의 경우 가장 기본적인 resnet 모델을 나타내는 것이며, 여기서 기존의 Domain Generalization을 수행하고자 WT 기법 유사하게 적용한 논문들이 b와 c입니다. 저자도 이들과 결을 비슷하게 하기 위해 d처럼 Residual 연산이 마친 뒤 Instance Normalization을 수행한 후 ISW loss를 계산하였다고 합니다.
게다가 ResNet을 backbone으로 하였을 때 Stage를 크게 1~4로 볼 수 있는데, convolution 3개로 구성된 stage 1과 residual block이 존재하는 stage2에서만 ISW loss를 계산하였다고 합니다. 이는 이전 방법론에서 early stage에 적용하는 것이 가장 좋은 성능을 보였다고 해서 이를 따랐다고 합니다.
Experiments
그럼 실험 섹션에 대해서 다뤄보고 리뷰 마무리 짓도록 하겠습니다.
일단 DA와 DG semantic segmentation task에서는 주로 사용하는 데이터 셋으로 source domain을 GTA5 dataset으로 하고, 그 외에 Cityscape, SYNTHIA, BDD-100K 등을 target domain으로 보고 평가를 하는데, 본 논문도 이와 비슷하게 진행한다고 합니다.
그리고 해당 논문은 Domain Generalization이기에 앞서 intro에서 설명드린대로 target domain에 대해서는 학습 때 전혀 보지 않았음을 인지하고 계시면 됩니다.
Effectiveness of instance selective whitening loss
일단 다른 normalization 방법론들과 저자가 제안하는 ISW loss에 대한 비교 실험입니다.
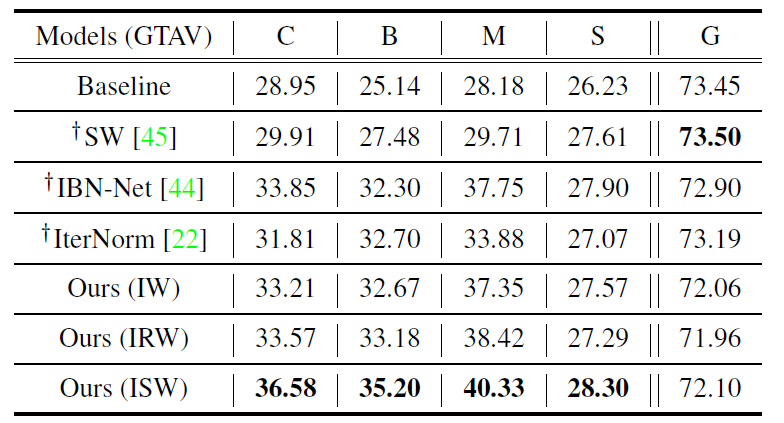
위에 테이블은 GTA5로 학습한 모델을 CittyScape(C), BDD-100k(B), Mapillary(M), SYNTHIA(S), 그리고 GTA5 validation set(G)로 평가한 것을 의미합니다.
보시면 제안하는 방법론(ISW)가 source domain G를 제외하고는 모두 SOTA를 달성할 것을 볼 수 있습니다. 특히나 학습에 사용한 데이터 셋이 합성 데이터 셋임에도 불구하고 Real world인 C,B,M에서 좋은 성과를 이룬다는 점은 상당히 매력적임을 저자는 주장합니다.
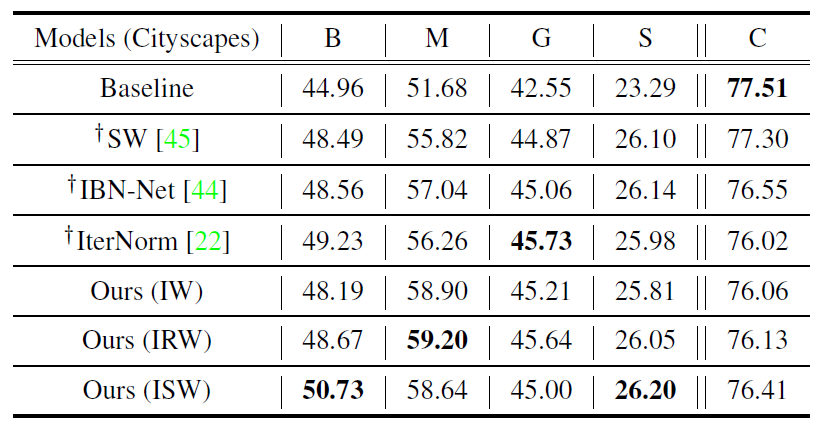
다음은 ResNet50 백본 모델을 CityScape로 학습해서 다른 타 데이터 셋들에게 평가한 결과입니다. 해당 결과에서는 제안하는 방법론(ISW)가 GTA5 데이터셋 기준 IterNorm보다 좋지 못한 성능을 보여주긴 하지만, 그외에 타 데이터 셋에서는 모두 긍정적인 성능을 보여주고 있습니다.
또한 Switchable Whitening(SW) 방법론과 IBN-Net이라는 명칭의 방법론은 모두 Source domain에서 좋은 성능을 보여주고 있는데, 이는 곧 overfitting이 잘 일어난다는 의미이며 domain generalization 관점에서는 좋지 못한 상황이라고 지적합니다.
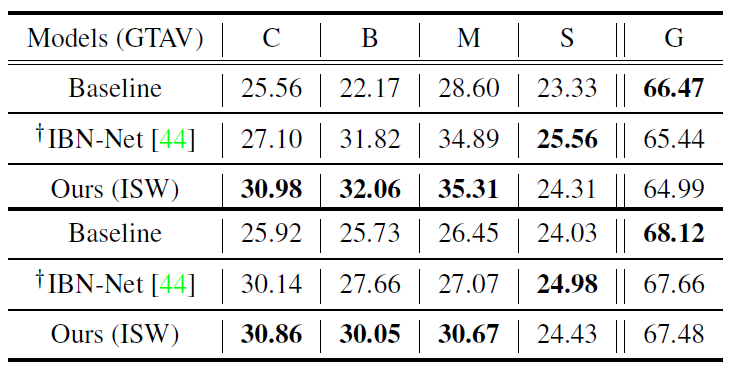
다음 테이블은 GTA5 train set을 각각 ShuffleNetv2와 MobileNetV2에 학습시킨 뒤 평가한 것을 의미합니다. 해당 실험에서 저자가 주장하고 싶은 것은 다양한 백본 모델에 자신들의 방법론을 쉽게 적용할 수도 있으며 성능 역시도 더 좋다는 것을 주장하기 위해서입니다.
마지막으로 제안하는 방법론은 학습에만 사용하는 방법론이기 때문에 해당 방법론의 학습 가능한 파라미터 수와 추론 시간 등에 대한 표를 확인해보면 baseline과 비교해서 더 작거나 같은 것을 볼 수 있습니다.
결론
DG 분야에서 style과 content로 나누어 접근하는 개념은 사실 해당 논문 이전부터 많이들 존재했었는데, 이를 Whitening Transformation과 엮어서 설계하다보니 진부하지 않게 내용도 탄탄하고 성능도 좋게 나왔기에 Oral paper가 되지 않았나 싶습니다.
안녕하세요 신정민 연구원님, 좋은 리뷰 감사합니다. CNN이 사물을 인식할 때 어느 부분에 집중하는지는 알 잘지 못했는데, 실루엣보다 질감에 더 집중한다는 것을 처음 알았습니다. 모델이 1. content 보다는 style에 집중하는 경향이 있고 2. style에 집중하다보면 domain 일반화 성능이 떨어지기에 기존에는 whitening transformation 등으로 style 특성을 제거하는 방법을 사용했다면 3. 해당 방법은 연산량이 많고 미분 불가능하다는 단점이 있으니 whitening transformation을 직접 적용하기보다는 결과값을 추론하자 라는 흐름으로 이해했습니다.
특히 domain specific/invariance 정보를 추출하는 부분이 인상깊었습니다. photometric distortion을 적용한 각 이미지의 공분산 행렬에서 상이한 부분을 domain specific한 정보로, 공분산 행렬에서 유사한 부분을 domain invariance한 content information으로 간주하는데, transformation 전후 영상에 내제된 의미론적 표현을 추출하는 방법으로 유용하게 사용될 수 있을 것 같습니다.
여기 부분에서 질문이 있는데, photometric distortion 이외에 crop/flip/affine 등 기하적 변환한 부분을 사용하는지 궁금합니다. 만약 그렇지 않다면 그 이유가 궁금하네요. style 정보는 photometric transformation에 해당하고 기하적 변환은 content 정보에 해당하기 때문에 그런건가, 분포가 너무 많이 달라져서 그런걸까 하는 생각도 드는데 색상 변환도 데이터 분포가 상당히 달라지니 그런 점을 생각하면 기하적 변환도 사용할 수 있을 것 같은데.. 혹시 그런 부분이 언급되어 있는지 알고 싶습니다.
감사합니다.
안녕하세요.
질문을 요약해보면 photometric distortion 부분 외에도 geometric distortion을 적용하였는지에 대한 내용으로 보여집니다. 결론부터 말씀드리면 geometric distortion은 적용하지 않았으며 실제로 적용해서도 안된다고 생각이 됩니다.
그 이유는 영상을 구성하는 정보로 style과 content로 구분을 짓는다고 설명을 드렸는데, 이때 style이 photometric information, content는 geometric information이라고 볼 수 있습니다. 여기서 모델이 style information 부분은 효과적으로 제거하고, content information은 유지하도록 하는 것이 본 목적이라고 보시면 됩니다.
이러한 관점에서, 저자는 두 영상의 feature map 간에 분산 값이 큰 요소들을 style information, 분산 값이 작은 요소들을 content information으로 보았는데 그 이유는 두 영상은 모두 동일한 장면(즉 동일한 scene structure, content)이며 단지 한쪽 영상에게 강한 photometric distortion을 주었기 때문에 style 정보만이 다르다라는 가정이 있기 때문입니다.
하지만 만약 말씀해주신 대로 geometric information에 대해서도 왜곡을 주게 될 경우에는, 두 영상 사이에 분산이 상이해지는 이유가 style information의 차이 때문에 발생하는 것인지, 혹은 geometric information이 상이해서 발생하는 것인지를 구분할 수 없게 됩니다. 이는 곧 저자가 원했던 공분산 내의 feature map 정보를 style과 content로 disentangle 하려는 목표와 거리가 멀어지게 됩니다.
감사합니다.
안녕하세요 신정민 연구원님 리뷰 잘 읽었습니다.
이런 종류의 리뷰를 항상 가져오면 재밌게 읽고 있습니다.
근데, 왜 gram matrix를 만들면 이게 style infomation을 나타내는 것인지에 대한 motivation에 대한 이해가 잘 가지 않습니다. 내부 행렬에 대한 곱셈을 하면 self-similarity 형태가 나오게 되는데, 이를 통해서 이미지 내에서 동일한 위치에 유사도만 향상시키는 방향으로 이해를 했는데요. 이를 통해서 조도같이 변하는 특성이 아니라 특정 픽셀과 픽셀간의 표현력의 차이를 증대시켜서 컨텐츠에 집중하는 방향이 motivation 인가요?
photometric distortion을 적용하는 부분도 결국은 임의로 영상을 바꿔서 공통적인 특성을 추출한다고 생각하니… 결국은 부족한 데이터를 augmentation을 통해 보충한다는 느낌으로 생각되네요.
감사합니다.