안녕하세요, 허재연입니다. 이번에도 Representation Learning 논문을 들고 왔습니다. MoCo는 Kaiming He 등의 저자들이 Facebook AI Research에서 낸 논문으로, contrastive 기법을 이용한 self-supervised learning 방법들 중 SimCLR과 함께 근본으로 꼽히는 논문입니다(시기적으로는 MoCo가 SimCLR보다 약간 이전에 제안되었습니다). 이전에SimCLR에 대해 자세히 리뷰한 적이 있으니, 관심 있으신 분들은 참고하시면 좋을 것 같습니다 : SimCLR리뷰
Self-Supervised learning은 부족한 데이터셋의 한계점을 해소하고자 하는 분야입니다. 1. unlabeled dataset만을 이용해서 self-supervised learning 방법을 통해 모델이 데이터 자체에 대한 표현력을 어느 정도 학습하고, 2. 이후 labeled dataset을 이용해 특정 downstream task로 fine-tuning 하는 것을 목표로 합니다. 따라서 self-supervised learning 방법은 ‘어떻게 unlabeled data만을 가지고 데이터에 대한 충분한 표현력을 확보할 것인지’, ‘이렇게 pretrain한 모델이 downstream task에서 얼마나 잘 작동하는지’에 집중합니다. 데이터의 표현력을 학습한다는 의미에서 ‘Representation Learning’이라고 부르기도 합니다. MoCo는 Contrastive Learning을 이용하여 이 목적을 달성하고자 하였고, 상당히 개선된 결과를 보였습니다. 리뷰 시작하겠습니다.
저자들은 본 논문에서 Momentum Contrast (MoCo)라는 unsupervised visual representation learning 방법을 소개합니다. Contrastive Learning방법을 dictionary look-up 문제로 해석합니다. 많은 key가 있는 dictionary에서 query data에 대해 positive key에 대한 유사도는 높이고, negative key에 대한 유사도는 낮춰야 하는데, 이를 위해 queue 구조와 moving-averaged encoder를 이용하여 dynamic dictionary를 설계했습니다. 이를 통해서 크고 일관성 있는 딕셔너리를 구성하고 contrastive unsupervised learning을 수행합니다. MoCo는 ImageNet classification에서 linear protocol로 상당한 성능을 보였습니다. 더욱이, 저자들은 MoCo로 학습된 representation이 downstream task로 잘 transfer된다고 주장합니다. MoCo는 PASCAL VOC, COCO 등 dataset의 7개 detection/segmentation task에서 supervised pre-training 방법을 뛰어넘는 성능을 보였습니다. 이는 다양한 vision task에서 supervised 와 unsupervised representaion learning 사이 gap이 상당히 줄었다는 것을 의미합니다.
Introduction
당시 자연어처리 분야에서 Unsupervised representation learning이 상당히 성공적으로 활용되고 있었지만(GPT, BERT 등), 약간 뒤쳐져있던 컴퓨터비전 분야에서는 여전히 supervised pre-training이 일반적인 방법이었습니다. 저자들은 이 이유를 NLP와 Computer Vision의 신호 공간의 차이에서 비롯된다고 합니다. 자연어 처리에서는 사람 간 소통을 하는 데이터 자체에 discrete signal spaces(words, sub-words units 등)가 있어 unsupervised learning의 기반이 되는 tokenized dictionaries를 쉽게 구축할 수 있습니다. 반면, 컴퓨터비전에서는 raw signal이 연속 신호이고, 고차원 공간에 있으며 단어와 달리 사람 간 소통을 위해 설계되지 않아서 dictionary building이 난이도가 비교적 높습니다.
당시 contrastive loss를 이용한 unsupervised visual representation learning이 준수한 성능을 보이며 제안되고 있었고, 대부분 dynamic dictionaries를 구축하는 방식이었습니다. 딕셔너리의 ‘keys’(token)는 데이터(이미지나 패치)에서 샘플링되며 encoder network를 이용해 표현되었습니다. 여기서 unsupervised learning은 encoder가 dictionary look-up을 수행하도록 훈련시킵니다. encoded된 query가 matching key와는 비슷하게, 다른 것들과는 비슷하지 않도록 하는 것입니다. data가 encoder를 거치면 representation vector가 되는데, contrastive learning을 진행하며 matching 된 key와는 query가 positive pair를 이루어 유사도를 계산해 positive pair끼리는 가까워지게, 매칭되지 않는 key들과는 negative pair를 이루어 서로 멀어지게 학습합니다. 학습은 contrastive loss를 최소화하는 것으로 진행됩니다.
이런 관점에서, 저자들은 (1)크고 (2) 훈련 중 일관성(consistency)을 유지하는 딕셔너리가 이상적일 것이라는 가설을 세웁니다. 직관적으로 연속적인 고차원 visual space에서 더 큰 딕셔너리가 샘플을 더 잘 샘플링 할 수 있을 것이고, 딕셔너리의 keys는 같거나 비슷한 encoder를 통해 표현되어야 query와의 비교에 일관성이 있을 것입니다. 그러나, MoCo 이전 기존의 contrastive loss를 사용하는 방법들은 이 두 가지 지점 중 하나를 놓치고 있었습니다.
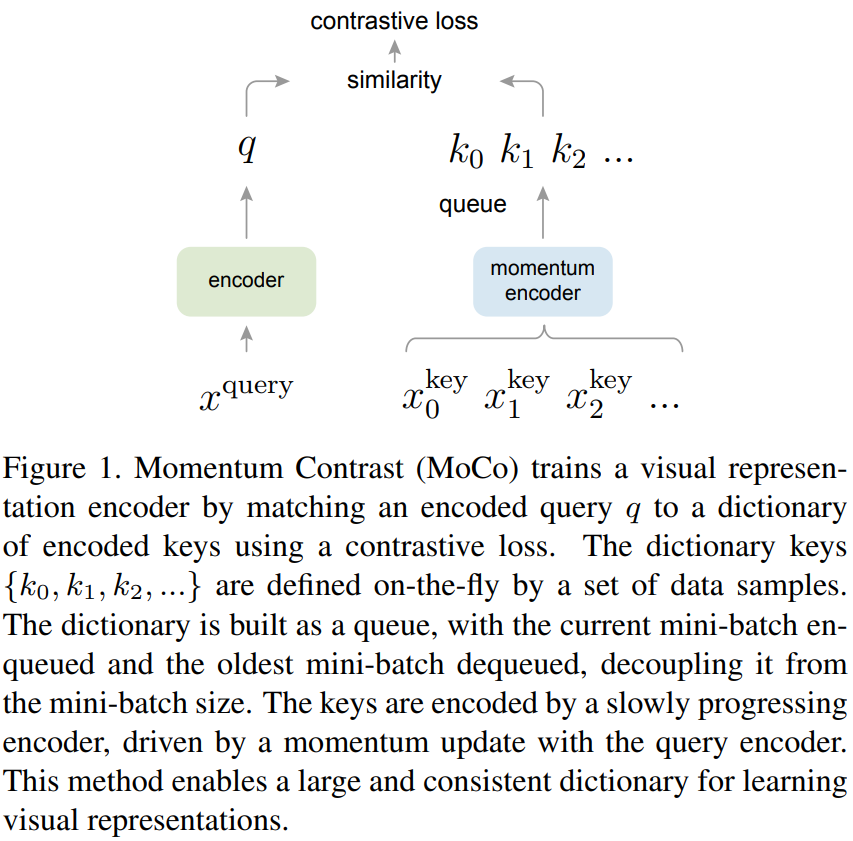
이런 맥락에서, 저자들은 contrastive loss를 이용한 unsupervised learning 방법으로 (1) 크기가 크고 (2) 일관적인 딕셔너리를 구축하는 방법인 Momentum Contrast (MoCo)를 제안합니다. MoCo에서는 딕셔너리를 data sample의 queue로 유지합니다. 현재 mini-batch의 encoded representations는 enqueue되고, 가장 오래된 representations는 dequeue됩니다. 큐를 이용해 딕셔너리 크기를 mini-batch size와 분리할 수 있어 큰 딕셔너리를 만들 수 있습니다. 더욱이 딕셔너리 키가 이전 미니배치들에서 오기 때문에, consistency를 유지하기 위해 쿼리 인코더의 momentum-based moving average로 구현된 slowly progressing key encoder를 제안합니다. 말이 조금 복잡한데, 딕셔너리가 확확 업데이트되면 일관성(consistency)가 유지되지 않으니 momentum을 도입해서 천천히 업데이트했다는 뜻입니다. 이를 통해 일관성을 개선할 수 있겠죠. 결국 MoCo는 contrastive learning을 위한 dynamic dictionary를 만드는 매커니즘입니다.
unsupervised learning의 목적은 fine-tuning을 통해 downstream task로 전달될 수 있는 representation(feature)을 학습하는 것입니다. 저자들은 detection이나 segmentation과 같은 7개의 downstream task에서 MoCo unsupervised pre-training 방법이 ImageNet supervised pre-training 성능을 능가할 수 있음을 보였습니다. 이 결과를 통해 저자들은 MoCo가 많은 컴퓨터비전 작업에서 unsupervised와 supervised representation learning 방법 간 갭을 크게 좁혔고 이제 다양한 도메인에서 ImageNet pretrain 방법의 대안으로 사용될 수 있다고 주장합니다.
Method
Contrastive Learning as Dictionary Look-up
Contrastive learning은 dictionary look-up task를 위한 encoder training으로 생각할 수 있다고 합니다. Encoded query q와 딕셔너리의 키로 이루어진 encoded sample 집합 {k0, k1, k2, …}이 있다고 생각해봅시다. 딕셔너리에 q와 매칭되는 single key k+가 있다고 하면, q가 positive key k+와 비슷하고 k+가 아닌 다른 모든 키(q에 대해 negative key로 간주)와 유사도가 낮을 때 contrastive loss의 값이 낮아집니다. positive key와 유사도가 높고 negative key와 유사도가 낮아야 contrastive loss 값이 낮아지는 것이죠. MoCo에서는 InfoNCE라는 contrastive loss를 고려합니다. MoCo에서 처음 제안된 loss는 아니고, 2018년 Representation learning with contrastive predictive coding이라는 논문에서 제안되었던 loss입니다.
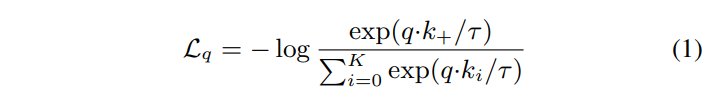
τ는 temperature hyper-parameter인데, 지수함수의 scale을 조정해주는 역할이라고 생각하시면 됩니다. 분모의 summation은 하나의 positive와 K개의 negative sample들에 대한 것입니다. (K+1)-way softmax 기반 classifier의 log loss라고 생각하시면 됩니다.
Contrsative Loss는 쿼리와 키 representation을 출력하는 하는 인코더 네트워크를 훈련시키기 위한 unsupervised objective function으로 사용됩니다. query representation을 q=f_q(x_q)라고 표현하면 x_q는 쿼리 샘플이고, f_q는 encoder network입니다. 쿼리 샘플이 인코더 네트워크를 거쳐 query representation이 나오게 됩니다. contrastive loss를 이용한 학습 대상은 encoder network이고, 이 인코더가 우리가 사전학습하고 싶은 대상입니다(ResNet 등) 쿼리와 키 인코더는 서로 완전히 같거나 다르게 설계할수도, 일부를 공유하게 설계될 수도 있다고 합니다. Fig1을 참고하시면서 보시면 이해가 수월할 것입니다.
Momentum Contrast
앞에서 언급했던것처럼 저자들은 Contrastive learning을 image같은 고차원 conttinuous input에 discrete dictionary를 구축하는 방법으로 보고 있습니다. dictionary는 key가 무작위로 sampling되고, key encoder가 훈련 과정 도중에 업데이트된다는 관점에서 동적입니다. 저자들은 풍부한 negative sample들을 가진 큰 딕셔너리와, 딕셔너리 키에 대한 인코더가 일관성을 유지할 때 좋은 features가 학습될 수 있다는 가설을 기반으로 Momentum Contrast법을 제안합니다.
MoCo의 핵심은 딕셔너리를 데이터 샘플의 queue로 유지하는 것입니다. 이를 통해 바로 이전 미니배치에서 인코딩된 key를 재사용 할 수 있습니다. 큐를 도입하면 사전의 크기와 미니 배치 크기를 각각 독립시킬 수 있기에 사전 크기를 미니배치와 별개로 크게 키울 수 있습니다. 딕셔너리 내부의 sample들은 점진적으로 교체됩니다. 현재 미니배치는 사전에 enqueue되고, 가장 오래된 미니배치는 큐에서 제거됩니다.
큐를 사용하면 딕셔너리를 크게 만들 수 있지만 역전파를 통해 키 인코더를 업데이트 하는것을 어렵게 만듭니다(gradient는 queue의 모든 샘플에 전파되어야 한다고 합니다). 저자들은 여기에 나이브한 솔루션을 채택하는데, 이 그래디언트를 무시하고 쿼리 인코더를 키 인코더에 복사하는 것입니다. 하지만 이 방법은 결과가 좋지 못했는데, 저자들은 실패 이유가 encoder의 급변으로 key representation의 일관성이 감소되었기 때문이라고 가정합니다. 따라서 이 문제를 해결하기 위해 Momentum Update를 제안합니다.
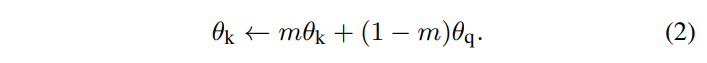
θk는 키 인코더의 파라미터, θq는 쿼리 인코더의 파라미터입니다. 위 수식을 통해 키 인코더를 업데이트합니다. 모멘텀은 옵티마이저에 자주 등장하는 개념이기 때문에 다들 익숙하실텐데, 요점은 모멘텀을 도입해서 너무 빠른 업데이트를 방지하는 것입니다. m ∈ [0, 1] 은 모멘텀 계수이고, θq(쿼리 인코더 파라미터)만 역전파에 의한 업데이트 대상입니다. 실험을 통해, m=0.999와 같은 큰 momentum이 작은 값(m=0.9)보다 훨씬 잘 작동했다고 합니다. 이는 키 인코더를 천천히 업데이트되는 것이 queue를 사용하는데 핵심임을 뜻합니다.
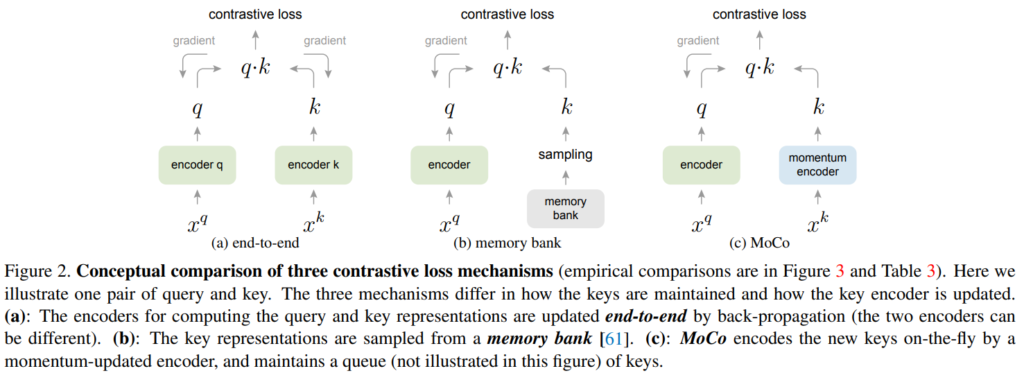
저자들은 MoCo를 end-to-end 방식, memory bank 방식과 비교하는데 end-to-end 방법은 현재 미니배치를 dictionary로 사용해서 key들이 일관적으로 인코딩되지만 dictionary size가 mini-batch 사이즈에 의해 결정되어서 GPU memory issue가 있다고 하고, 배치가 커서 large mini-batch optimization 문제가 있다고 합니다. memory bank는 데이터셋의 모든 샘플들의 representation으로 이루어져 있고, 각 미니배치의 딕셔너리는 역전파 없이 메모리 뱅크에 의해 무작위로 샘플링된다고 합니다. 이 방법은 MoCo와 비교해 메모리 효율이 좋지 않다고 합니다.

Experiments
저자들은 ImageNet-1M과 Instagram-1B에 대해 unsupervised training을 연구했습니다. 훈련에 SGD(weight decay 0.0001, momentum 0.9)를 사용했고, 미니배치 사이즈 256으로 진행되었다고 합니다.
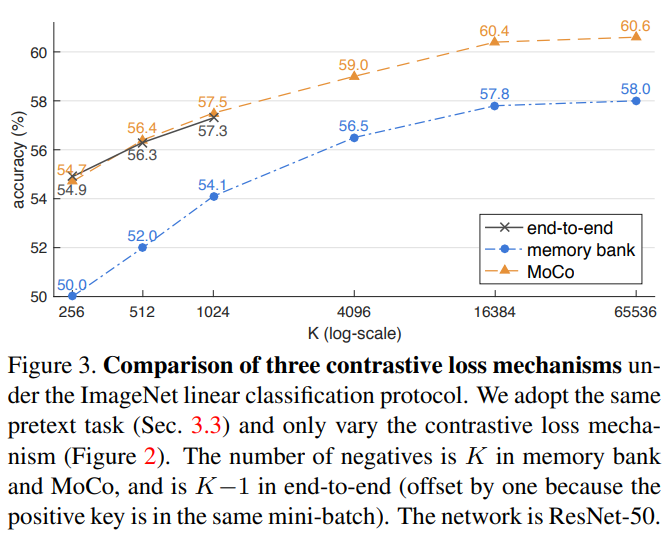
linear evaluation은 학습된 모델을 freeze 시키고 끝에 분류를 위한 fc layer(분류기)만 추가해 학습시킨 뒤 평가하는 방법입니다. 저자들은 ResNet50의 global average pooling 위에 분류기를 달아 학습했습니다. 표를 보시면 negative sample 수를 늘릴수록 성능이 상승하고, MoCo가 기존 방법보다 우수한 성능을 보이는것을 확인할 수 있습니다.
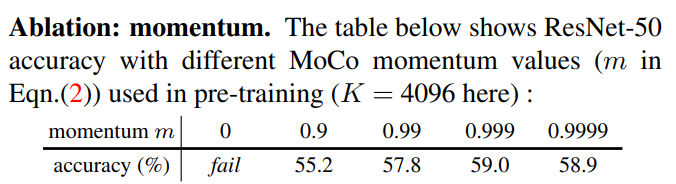
Momentum에 대한 Ablation study입니다. momentum이 없으면 딕셔너리가 너무 빨리 업데이트되어 일관성이 전혀 유지되지 않으므로 학습에 실패한 것을 확인할 수 있습니다(training loss가 진동하며 수렴에 실패했다고 합니다). momentum이 0.999일 때 가장 성능이 좋은 것을 확인할 수 있습니다.
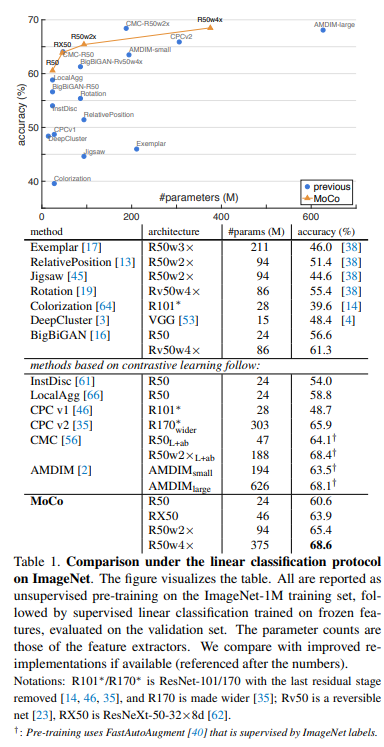
이 표는 기존 방법론들과의 비교입니다 (linear classification으로 비교되었습니다) 기존 방법론보다 파라미터 수 대비 정확도가 높습니다.
MoCo는 contrastive learning을 이용한 representation learning에 효율적이고 성능 높은 방법을 제시했습니다. 이후 나온 contrastive representation learning 방법들이 모두 SimCLR와 MoCo를 기반으로 하고 있어 읽어봐야하겠구나 생각하고 있었는데, 이번 기회에 읽어볼 수 있었습니다.
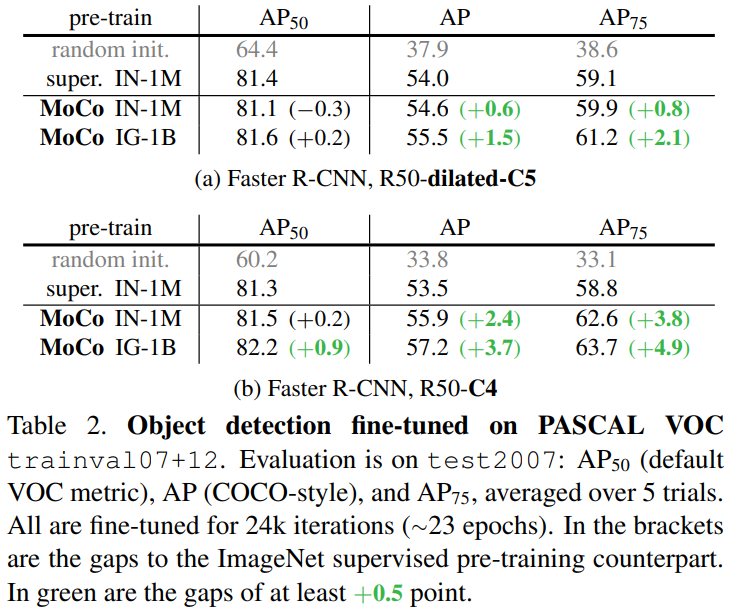
Classification 뿐만 아니라 object detection에 대해서도 reporting 되어 있습니다. detector로는 Faster R-CNN이 사용되었습니다. BN을 적용해서 보든 layer를 end-to-end로 fine-tune 했다고 합니다. ImageNet supervised pre-training 방법과 비교할만한 성능을 보이는것을 확인할 수 있습니다.
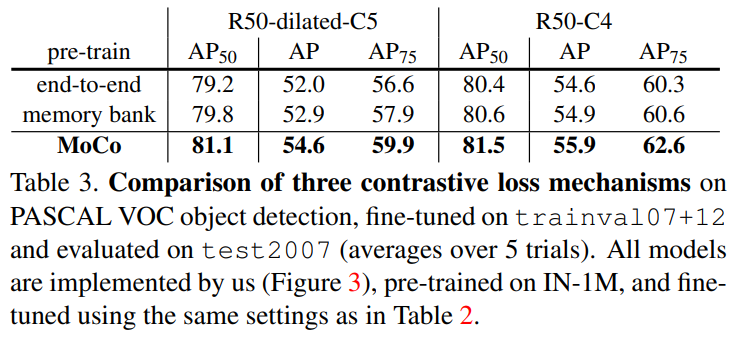
기존 다른 contrastive learning mechanism과의 비교입니다. 이전에 나온 방법들보다 소폭 높은 성능을 보이는것을 확인할 수 있습니다.
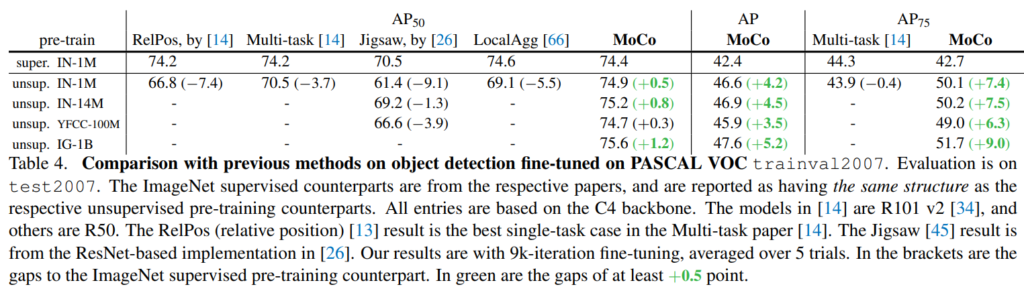
기존 pretext task 기반 pre-training 방법들과의 비교입니다. supervised 방법과 비교하고 있는데, 기존보다 높은 AP를 보여주었습니다. 이외에도 다른 downstream task에 대해서도 짤막하게 report 되어 있습니다.
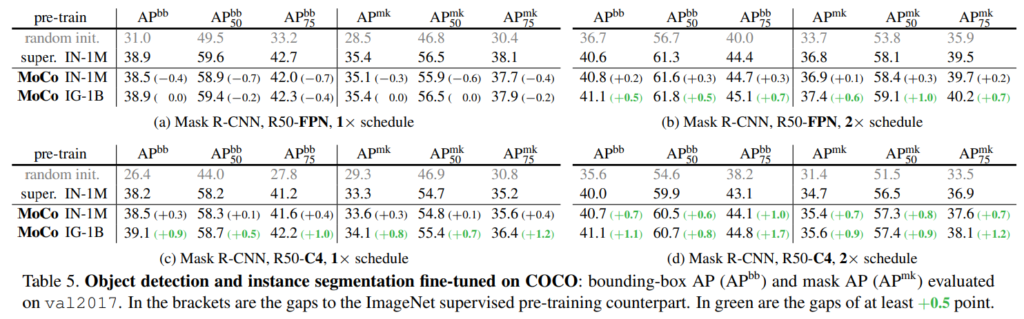
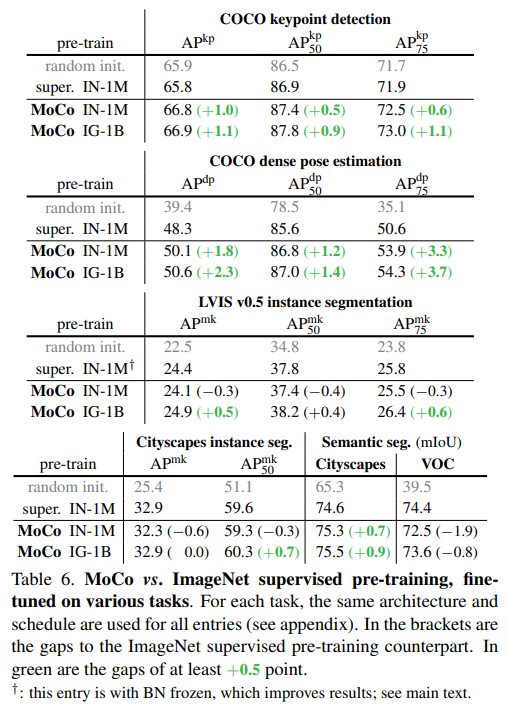
각 실험에 대한 자세한 설명이 있는것은 아니고, 짤막하게 언급되어 있습니다 . 설명이 대부분 기존보다 x.xx% 개선된 결과를 보인다.. 이런 식입니다.
결국, MoCo는 unsupervised 기법임에도 불구하고 기존의 ImageNet supervised pre-training 방법을 7개의 detection / segmentation task에 능가하는 성능을 보인다로 요약됩니다.
Conclusion
MoCo는 다양한 computer vision task및 dataset에 대해 unsupervised learning에 대한 긍정적인 결과를 보여주었습니다. 결말 부분에서는 단순 instance discrimination task를 넘어 MoCo를 masked auto-encoding 등 pretext task에 결합해 이후 더 발전될 수 있음을 짚고, 이후 더 개선되길 기대한다고 합니다.
contrastive learning 기반 representation learning 논문들을 읽다 보면, 전부 SimCLR과 MoCo에 기반하거나, 비교대상으로 삼기 때문에 MoCo를 언젠가를 읽어봐야지 생각하고 있다 이번 기회에 읽어 보았습니다. 이후에도 다양한 self-supervised learning 기법을 차례로 follow-up 할 계획인데, 많은 참고가 될 것 같습니다.
안녕하세요. 허재연 연구원님.
좋은 리뷰 감사합니다.
질문드리고 싶은 것이 하나 있는데요.
모멘텀으로 키 인코더를 업데이트하여 업데이트의 속도를 늦춤으로써 일관성을 유지하는 개념은 이해하였으나, 모멘텀으로 0.999와 같은 값이 사용된다면 키 인코더는 쿼리 인코더에 비해 1/1000 속도로 업데이트 되는 것이고, 이게 몇 사이클 돌면 쿼리 인코더와 학습의 수준이 매우 크게 차이날 것인데, 이로 인해 어떤 문제가 발생하지는 않을지 궁굼합니다.
감사합니다.
결국 쿼리 인코더는 벡터를 더 잘 임베딩하는 방향으로 학습을 하게 될 것입니다. 지오님 말씀처럼 모멘텀 인코더가 쿼리 인코더를 따라가는 형태가 되어 두 인코더 간 차이가 생기고 그로 인한 비효율성이 생길 수 있지만, 그보단 queue 내부 key 값들의 일관성이 깨지는게 학습에 더욱 부정적인 영향을 미친다고 이해하였습니다. 결국 업데이트를 반복하면 두 인코더 모두 올바른 벡터 임베딩을 하게 될 것을 기대할 수 있을 것입니다.
리뷰 잘 읽었습니다. 두 가지 궁금증이 존재하네여.
초기 65536의 sample은 랜덤으로 선택되는걸까요?? queue의 초기 학습 세팅이 궁금합니다.
그리고 loss에서의 temperature가 scale을 조절해준다고 하셨는데 정확히는 지수함수의 스케일을 조절해줘야 하는 이유는 뭔가요??
queue는 random sampling된다고 생각하시면 됩니다. 초기부터 꽉 찬 큐를 사용합니다. temperature parameter는 해당 질문을 고려해서 세미나에서 자세히 다뤄드렸는데, 이 스케일을 조정해줘서 positive와 negative 간 confidence 분포를 조정해줄 수 있습니다.
안녕하세요 허재연 연구원님, 좋은 리뷰 감사합니다.
MoCo가 unsupervised 분야의 근본 방법론이기도 하고 방법론을 잘 설명해 주셔서 이해하기 어렵지 않었던 것 같습니다.
실험 파트의 [표3]의 implementation detail이 어떻게 되는 지 궁금합니다. ImageNet-1M과 Instragram-1B로 사전 학습된 모델을 classification으로 fine tuning하였다고 하셨는데 그렇다면 표에 리포팅된 성능은 어느 데이터셋의 성능인지, k는 negative의 수 라고 나와 있기는 한데 end-to-end에서 1024이후의 성능이 없는 이유도 궁금하네요.
Fig3에서 end-to-end가 중간에 끊겨있는 이유는 mini-batch size입니다. end-to-end 방식으로 하려면 데이터를 모두 메모리에 올려야 하는데, 이 때 너무 K를 늘리려고 하면 제약이 생깁니다. 다른 방법은 이 점에 대해서 비교적 자유롭습니다. 학습은 imagenet linear classification protocol을 사용했습니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
본문에서 키 인코더를 업데이트하는 방법중 쿼리 인코더를 키 인코더에 복사하는 것에 대해 설명해주셨고 이 방법의 실패 이유에 대해 encoder의 급변으로 key representation의 일관성이 감소되었기 때문이라고 하셨는데 이게 쿼리 encoder의 경우 그래디언트가 하나의 이미지에 대해서 변하기 때문에 변화가 크다라고 이해를 하면될까요?
그리고 key representation의 일관성이 감소된게 문제라고 하셨는데 왜 key representation은 일관되어야 하는건가요??
감사합니다.
사실 논문에서는 momentum update에 대한 설명으로 그렇게 작성하긴 했는데, 이후에 나온 다른 논문들에서 queue를 사용하지 않아도 비대칭적인 구조에서 momentum encoder를 사용하기때문에 해당 설명이 정답인지에는 회의적입니다. 따라서 정의철 연구원님이 남겨주신 두 질문 모두에 논문에 나와있는 답변이 의미있는지는 의문입니다.
논문의 설명으로는 queue dictionary의 구성이 급변하면 feature의 출력이 일관되지 못하기 때문에 성능에 악영향을 끼친다고 합니다. dictionary의 구성이 일관적이어야 대조 비교를 할 때 표현력 학습에 유리하다고 생각하시면 좋을 것 같습니다.