오늘 리뷰할 논문은 transformers for multi model sept supervised to learning from low video, adeo and text라는 papar입니다. 본격적인 리뷰에 앞서 본 논문을 간단하게 소개하자면 vatt는 unlabeled 데이터를 사용하여 multimodal representation learning을 진행하는 연구입니다. 여기서 언급하는 multimodality는 이전 리뷰에서도 많이 다루었다시피 비디오, 오디오, 텍스트를 의미하며, representation learning중 contrastive learning을 transformer기반 architecture에서 진행하였다고 합니다. 특히 raw signal을 직접 입력받아 다양한 downstream task에 유용한 multimodal representation을 추출하였습니다. 모델의 사전 학습은 AudeoSet과 HowTo100M 데이터셋에서 진행되었으며, 약 1억 개의 짧은 비디오로 사전 학습된 multimodal representation learning 모델은 다양한 downstream task에 사용되었는데요, 논문에서는 video action recognition, audio event classification, zero-shot video retrieval을 진행하였습니다. 또한 비디오를 기반으로 학습된 모델을 image classification에도 적용하였으며, 평가는 imagenet1k에서 이루어졌다고 합니다.
Introduction
Transformer는 본래 NLP 분야에서 제안된 구조인데요, transformer의 등장으로 인해 NLP 도메인에서는 backbone architecture와 inductive bias에 대한 paradigm shift가 일어났습니다. 기존에는 RNN, CNN과 같이 relational inductive bias가 강한 모델을 사용하였으나 transformer의 등장 이후 backbone으로 transformer을 사용하는 빈도가 증가하였고, BERT, gpt와 같이 transformer 기반 구조에 self-supervised learning을 이용한 사전 학습 모델들이 범용적으로 좋은 성능을 보이며 현재는 이러한 방향의 연구가 계속 진행되고 있습니다.
NLP연구의 흐름과 비슷하게, Visual 도메인에서도 transformer 구조를 사용하려는 다양한 연구가 이루여졌고, 이러한 연구 중 대표적인 것으로는 ViT가 있습니다. 그러나 이러한 visiual transformer를 학습시킬 때 당시에는 주로 supervised training을 진행하였다고 합니다.
그러나 transformer의 학습에는 큰 규모의 데이터가 필요한데, 논문에서는 transformer의 large-scale supervised training의 문제점을 지적합니다. 바로 “big visual data”의 많은 부분을 베제하고 하고 학습하기에 모델의 편향이 발생한다는 것입니다.
이에 저자들은 한 가지 의문을 제기하게 되는데요, 바로 “large scale의 unlabeled데이터를 입력으로 transformer를 학습시킬 수는 없을까?”라는 것입니다. Natural Language는 순차적으로 단어, 구, 문장이 문맥 내에 놓여져 있고 각각에 의미와 구문을 부여함으로써 Transformer를 학습시킬 만한 그 자체의 supervision이 있어 이러한 학습이 가능합니다. 저자들은 visual 데이터에서 이러한 유기적인 supervision을 확보할 수 있는 것에는 multimodal이 있다고 하며, VAT의 유기적인 상관관계를 바탕으로 contrastive learning을 진행하는 VATT를 제안하였습니다.
Approach
본격적으로 vatt 에 대한 설명을 드리겠습니다. VATT의 overview는 아래의 [그림1]과 같습니다.
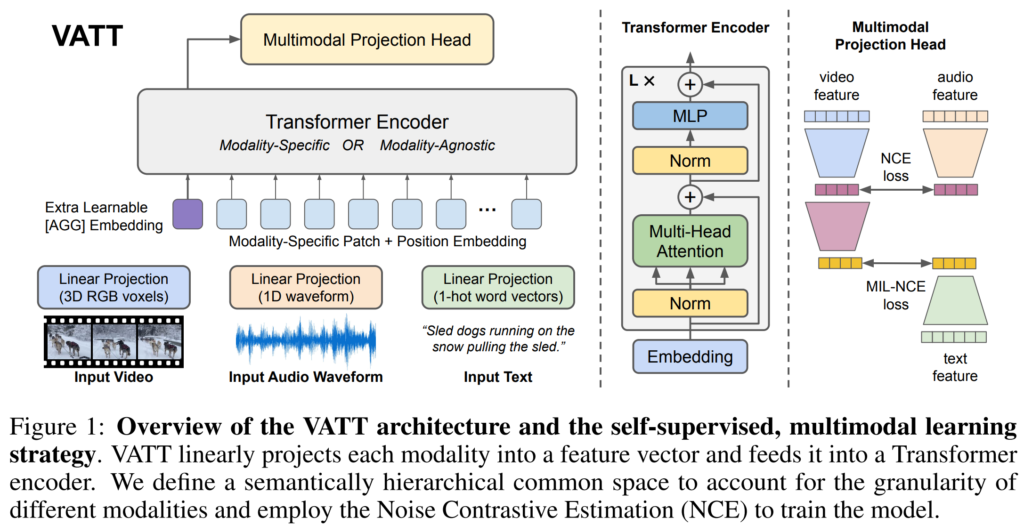
위 그림을 보면 VATT는 V, A, T의 input을 사용하는 것을 볼 수 있는데요, VATT는 세 모달리티의 representation을 각각 추출한 뒤 contrastive learning을 진행하는 것이 이 방법론의 주요 approach라고 할 수 있습니다. 이때 transformer를 이용하기 때문에 모달리티에 상관없이 하나의 archirecture를 사용할 수 있다는 장점이 있습니다. 이에 따라 모델을 설계할 때는 두 가지 선택지가 있을 수 있는데요, (1)modality-specific 즉, 동일한 transformer encoder를 모달리티의 수 만큼 생성하여 각 모달리티별 고유한 weight를 가지거나, (2)modality-agnostic하게 모든 모달리티에 대한 feature를 하나의 encoder가 처리하도록 할 수 있습니다.
Tokenization and Positional Encoding
VATT는 raw signal을 다루기 때문에 transformer backbone에 데이터가 들어가기 전 각 모달리티 별로 tokenization을 진행해야 합니다. 또한 각 token의 위치 관계를 나타내는 positional encoding또한 진행되어야 하며 이때 각 모달리티 간에는 고유한 positional encoding을 진행합니다.
비디오 데이터는 4D Tensor데이터로 RGB 이미지의 H,W,3에 시간축인 T가 추가된 형태로 구성되어 있습니다. 이를 Transformer의 입력으로 사용하기 위해서는 patch 단위로 나눠 주어야 하며, 논문에서는 T\times H\times W\times 3의 크기를 가지는 비디오 클립을 \lceil T/t\rceil \cdot \lceil H/h\rceil \cdot \lceil W/w\rceil 개의 patch로 구성하였습니다. 이때 각 patch는 t\times h\times w\times 3의 voxel을 가지며 이를 flatten 후 d차원으로 projection을 진행하였습니다.
video를 tokenization한 뒤에는 각 token에 대해 positional encoding을 진행하였는데요, 아래의 [수식 1]과 같이 Temporal, Horizontal, Vertical 축에 대해 각각 learnable한 position encoding E를 생성한 뒤, 하나의 patch의 position을 구할 때는 temporal, horizontal, vertical각각의 potisional encoding을 더한 encoding으로 사용하였다고 합니다.
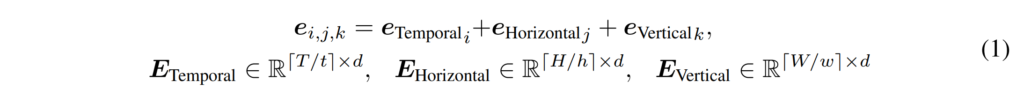
Audio도 video와 비슷한 과정으로 전처리가 이루어지는데요,raw audio가 음성의 길이T’만큼의 크기를 가지는 1차원 벡터로 입력되면, 이를 각 patch가 t’만큼의 길이를 가지도록 분할하고, 비디오와 동일하게 d차원으로 projection을 진행하였습니다. positional encoding 또한 learnable한 embedding을 생성하여 더해 주었습니다.
Text sequence 경우, 먼저 training 데이터셋에 존재하는 모든 단어로 이루어진 단어 사전 v를 생성하였습니다. 그 다음 각 sequence를 v차원의 one hot 벡터로 인코딩한 뒤, d차원으로 projection하였다고 하며 이 과정은 NLP의 embedding dictionary lookup이라 한다고 합니다.
Drop Token
tokenization + positional encoding을 통해 각 모달리티를 동일한 크기의 feature로 만들었다면 이제 transformer에 입력하면 되는데요, 이때 raw video와 audio는 patch의 수가 많아 transformer의 sequence가 길어진다는 단점이 존재합니다. transformer의 sequence가 너무 길어지면 필요한 연산량이 증가하기에 논문에서는 DropToken이라는 방법을 제안하여 학습 시의 연산 복잡성을 감소시켰습니다.
Drop Token이란 token의 일부를 일정 비율만큼 무작위로 sampling하여 transformer에 입력하는 것입니다. Video, audio는 인접한 부분에서 중복성을 가진다는 특징이 있으므로, 논문에서는 token의 수를 줄이기 위해 원본 입력의 해상도를 줄이는 것 보다 token의 일부를 누락하는 것이 더 효율적인 방법이라고 주장합니다.
Common Space Projection
Transformer encoder로 각 모달리티의 fearute를 뽑은 다음에는 모달리티 간의 contrastive learning을 진행하는데요, 그러기 위해서는 서로 다른 모달리티의 feture가 동일한 feature space에 존재하여야 합니다. 이를 위해 common space projection을 진행하였고, 여기에는 [NeurIPS 2020]Self-Supervised MultiModal Versatile Networks에서 제안된 FAC를 사용하였으며, 아래의 [수식3]과 같이 정의하였습니다.
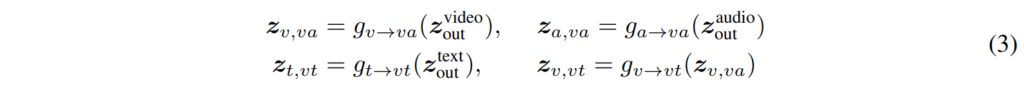
먼저 g_{v \rightarrow va}, g_{a \rightarrow va}를 통해 video feature와 audio feature를 video-audio의 공통 space인\mathcal{S}{va} 로 projection합니다. 그 다음에는 g_{t \rightarrow vt}, g_{v \rightarrow vt}를 통해 text transformer의 출력과 \mathcal{S}_{va}내의 video embedding z_{v, va}를 video-text의 공통 space인 \mathcal{S}_{vt}로 projection합니다.
모든 modality가 동일한 space에 있는 것이 아닌 V-A, V-T가 각각 다른 space에 있는 것을 확인할 수 있는데요, 각 modality의 semantic granularity가 서로 다르기 때문에 이러한 구조를 사용하였습니다. 예를 들어 video, audio는 text에 비해 dense한 정보를 담고 있어 1차로 projection해서 VA간의 비교를 먼저 진행한 후 2차로 projection을 진행하여 text와의 비교를 하게 되는 것입니다.
Multimodal Contrastive Learning
이제 unlabeled multimodal data로 VATT를 self-supervised 방식으로 pre training하는 것만 남아있는데요, 논문에서는 {V, A, T}쌍이 주어졌을 때, V-A에는 Noise Contrastive Estimation(NCE)를 사용하고, V-T에는 Multiple Instance Learning NCE(MIL-NCE)를 사용하였습니다.
training query는 {video, audio, text}의 stream에서 (v,a)(v,t)와 같이 생성되는데요, positive pair는 두 modality가 같은 video clip에서 선택되고, negative pair는 video, audio, text가 video의 non-matching location에서 선택됩니다.
contrastive learning은 [그림1]의 오른쪽과 같이 두 모달리티간의 유사도를 비교하는 방식으로 이루어지며, 각 space에서의 loss 함수는 아래의 [수식4, 5]와 같이 나타낼 수 있습니다.
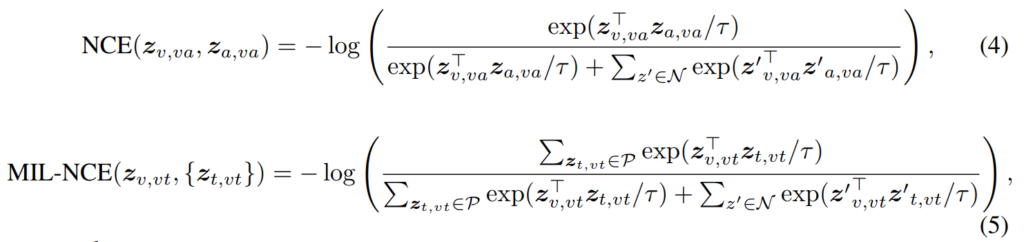
위 수식들에 대해 설명드리자면, B는 batch size이며, 각 iteration에서 B개의 v-a 쌍을 하나의 positive pair로 구성합니다.
[수식5]의 P(z)와 N(z)는 각각 video clip z_{v,vt} 근처의 positive/negative text clip을 나타냅니다. 구체적으로 P(zv,vt)는 video clip과 가장 가까운 5개의 text clip입니다.
[수식4, 5]를 모두 포함하는 VATT의 Loss는 아래의 [수식6]과 같습니다.
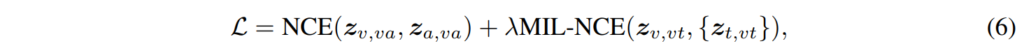
Experiments
실험은 사전 학습한 VATT를 여러 downstream task에 적용하는 것으로 진행하였습니다.
사전 학습에는 HowTo100M 데이터셋을 사용하였다고 합니다. HowTo100M은 약 백만 개의 오디오-비디오를 포함하고 있으며, 여기에 비디오에 대한 음성 나레이션이 존재하는데요, 음성 나레이션을 ASR을 이용하여 텍스트로 변환 후 사용하여 결과적으로는 A, V, T의 세 모달리티를 사용하였습니다.
Network Setup in VATT
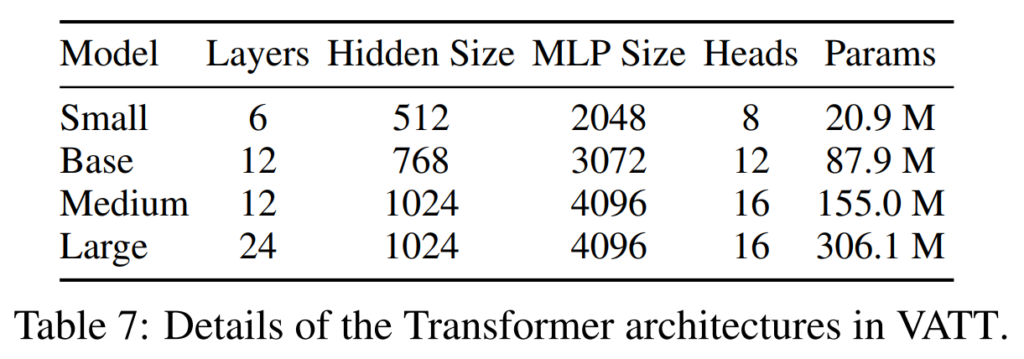
[표 7]은 실험에 사용된 서로 다른 VATT의 종류와 그 구조를 나타내고 있습니다.
총 네 가지 서로 다른 크기의 모델을 사용하였고 Large 모델의 파라미터를 보면 Large가 300M, Medium이 약 150M으로 상당히 큰 모델임을 알 수 있는데요, 논문에서는 이러한 모델은 비디오 task를 위한 모델이라고 언급하였습니다. 비디오를 처리하기 위해서는 모델 자체가 클 수밖에 없고 다양한 모달리티의 표현을 충분히 학습하기 위해서라도 큰 사이즈의 모델을 사용하는 것이 적합하기 때문인 것 같습니다. 반대로 text, audio task에는 small과 base 모델을 사용하였다고 하는데요, text의 경우 모델이 입력되기 전에 이미 tokenization이 진행되어 있으므로 좀 더 작은 모델을 사용할 수 있다고 하였고, 오디오는 비디오에 비해 복잡성이 덜한 데이터이기 때문인 것 같습니다.
다음으로는 여러 downstream에 대한 실험 결과를 살펴보겠습니다.
Fine-tuning for video action recognition
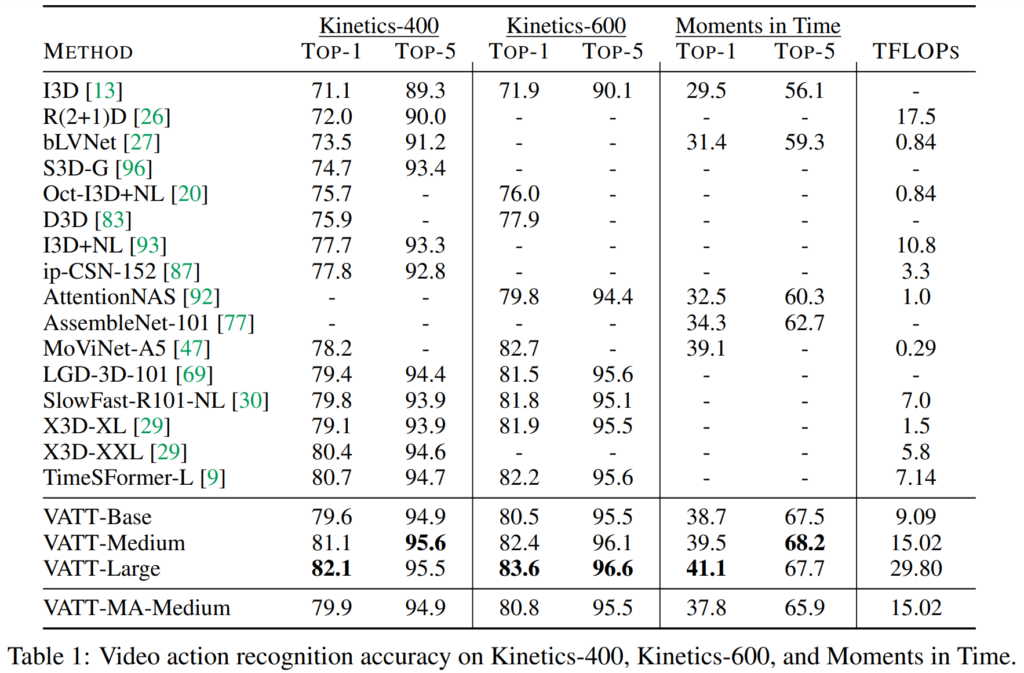
[표1]은 Video Action Recognition task의 sota 방법론들과 VATT의 성능을 나타내고 있는데요, 일단 accuracy만 보았을 때는 sota를 달성하였습니다. 그러나 TFOPS가 크게 증가하였습니다. 특히 X3D-XL과 VATT-Base를 비교해 보면 비슷한 성능을 보임에도 연산량이 6배 가량 증가한 것을 볼 수 있습니다.
Fine-tuning for audio event classification
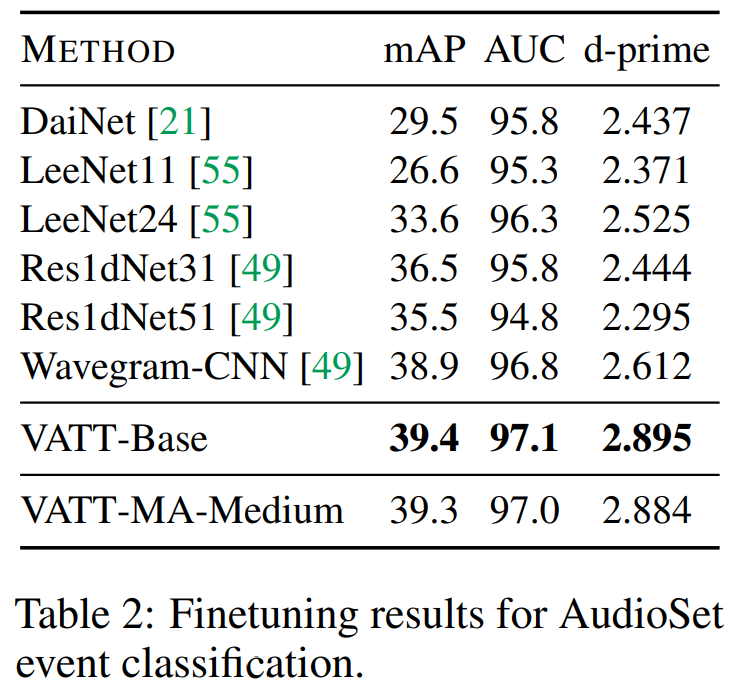
d-prime은 신호 분석에서 사용되는 평가 지표로 audio detection에서 target과 input이 일치하는 정도를 나타내는 것이라고 합니다. 여기서는 AEC 모델의 정확도를 나타내기 위해 사용되었으며 높을수록 좋은 성능을 보이는 것이라고만 생각하시면 될 것 같습니다.
[표2]를 보면 audio event classification에서도 sota를 달성하였습니다. 여기서 논문에 언급되기로는 VATT가 audio event classification task에서 CNNbased 모델의 성능을 뛰어넘은 첫 transformer 모델이라고 합니다. 또한 VATT는 audio의 handcrafted feature(MFCC, Mel-spectrogram 등)가 아닌 raw audio waveform에서 직접 동작한다는 점도 contribution에 해당한다고 볼 수 있습니다.
Fine-tuning for image classification
multimodal로 사전 학습되 모델이지만 image classification성능을 리포팅하였는데요, 실험을 진행할 때 원본 모델에 어떠한 변형도 하지 않았다고 하며, 이로 인해 ImageNet으로 fine tuning을 진행할 때, video embedding을 적용하기 위해 이미지를 4회 복사하여 네트워크에 입력하였다고 합니다.

[표3]의 결과를 보시면 별도의 사전 학습 없이 학습한 것과 사전 학습된 VATT간의 성능 차이를 확인할 수 있습니다. 또한 VIT와 VATT의 성능을 비교하자면 ViT가 앞서고 있으나 Vit의 경우 Large Scale 데이터셋인 JFT로 supervised learning을 진행한 것에 비해 VATT는 unlabeled 데이터를 사용하여 사전 학습하였다는 차이점이 있습니다. 이를 통해 large scale pretraining에서 supervised에 competetive한 성능을 도출한 것을 보였다고 합니다.
안녕하세요. 좋은 리뷰 감사합니다.
audio, video, text를 모두 입력으로 받는 pre-trained model은 조금 신선한 면이 있네요. 간단한 질문이 있습니다. 각 V-T, V-A space를 가지는 이유가 modality의 semantic granularity가 서로 다르기 때문에 라고 하셨는데 이 부분이 이해가 잘 가지 않습니다.
또한, 이 모델은 사전학습 모델로 일종의 백본으로 사용되길 바라기 위해서 나온 것이라 저는 이해하였는데요. 그렇다기에는 다운스트림 task를 일부만 보여준것이 아닌가 싶습니다… 다른 예가 또 있을까요?
댓글 감사합니다.
1) 우선 semantic granularity는 의미론적 단위로 각 모달리티에서 유의미한 의미를 가진 채 분할되는 단위를 의미하며, text데이터의 경우 띄어 쓰기로 구분된 단어, video나 audio는 고정 개수의 frame으로 구성된 clip등을 의미한다고 합니다. 사실 위 concept는 본문에도 기재된 이 논문에서 나온 것으로 간단히 설명드리자면 modality의 feature space를 어떻게 가져갈 것인지에 관한 연구로 모든 modality를 동일 space에 projection하는 shared, V-A와 V-T를 별개의 space로 보내는 disjoint방식, V-A를 동일 space에서 비교한 뒤 V-A space의 feature를 한 번 더 V-T space로 projection하는 세 가지의 방식을 비교하였고, 그 중 마지막 방법론이 가장 좋은 결과를 보였습니다. 이에 대해 저자는 세 모달리티 간의 의미론적 단위의 차이에 의해 발생하였으며 그 중에서도 audio와 video는 text에 비해 더 세분화되어있다고 설명하였습니다.
정리하자면 frame단위의 audio와 video가 단어로 구성된 text에 비해 더 세부적인 정보를 가지므로 이 둘을 V-A space에서 비교하는 것이라고 생각하시면 될 것 같습니다.
2) 리뷰에서 언급한 세 task이외에도 Zero-shot text-to-video retrieval을 진행하였습니다.
안녕하세요 혜원님 좋은 리뷰 감사합니다!!
이 논문은 Approach에 나와있는 것처럼 동일한 transformer encoder를 모달리티의 수 만큼 생성하여 각 모달리티별 고유한 weight를 가지게 하는 방법으로 모델이 설계된 것 같은데 (2) 방법처럼 모든 모달리티에 대한 feature를 하나의 encoder가 처리하도록 설계한 모델에 대한 비교는 없는 건가요? 일반적으로 방법 1,2 중 더 자주 사용되는 방법이 있는지도 궁금합니다.
감사합니다!
안녕하세요 정의철 연구원님, 댓글 감사합니다.
우선 첫 번째 질문은 각 모달리티 별 고유의 가중치를 가지는 modality-specific 모델과 모든 모달리티를 하나의 공통괸 가중치를 사용하는 modality-agnostic 모델의 비교 성능에 대한 것으로 이해하였습니다. 답변 드리자면 해당 결과는 [표 1]에서 확인할 수 있는데요, VATT-로 표기된 모델은 specific, VATT-MA로 표기된 모델은 agnostic 입니다.
VATT-Medium과 VATT-MA-Medium을 비교하자면, agnostic 모델이 약간 더 낮은 성능을 보이는 것을 볼 수 있습니다. 논문에서는 두 결과가 거의 비슷함을 언급하며 VATT-MA를 통해 여러 모달리티에서도 동작하는 단일 transformer backbone의 가능성을 확인할 수 있었다는 해석을 덧붙이고 있네요.
일반적으로는 어떤 방법이 주로 사용되는지는 잘 모르겠습니다…