안녕하세요. 이번 주 X-Review에서 소개해드릴 논문의 제목은 <Learning to Prompt for Vision-Language Models>입니다. 22년도 IJCV에 게재되었고, NLP 분야의 학습 기반 prompt learning 방법론을 영상 분야에 최초로 도입한 근본 논문에 해당하여 읽게 되었습니다.

현재 저는 Video task 중 하나인 Weakly-Supervised Temporal Action Localization에서의 제한된 annotation 정보를 극복하고자 가지고 있는 video-level label text값만으로 추가적인 learning signal을 도입하고자 연구중인데, 이러한 learning signal을 받아올 때 본 논문이 영상 분야 task라도 경향성에 대한 정보를 알아보고자 읽어보았습니다. Prompt learning 특성 상 방법론은 represenation adaptation에 가깝기 때문에 매우 간단하고, 이에 대한 실험 결과와 분석에 대해 자세히 알아보는 것이 중요할 것입니다.
리뷰 시작하겠습니다.
1. Introduction
기존 영상 분야에서 어떠한 task이든 이를 수행하는 기본적인 프레임워크는 ResNet이나 ViT 등의 vision model을 통해 영상의 특징을 추출하고, 가지고 있는 discrete label값과 매칭하는 것이었습니다. Discrete label의 예로 “goldfish”나 “toilet paper”가 있다고 했을 때, 지금까지는 단순히 계산의 편의성을 위해 one-hot 또는 multi-hot vector로 매핑시키고 학습을 수행하게 됩니다. 이렇게 되면 “goldfish”나 “toilet paper”라는 단어 자체의 semantic한 정보를 무시하는 것이 되겠죠.
위와 같이 단어의 의미를 무시한 채 수치적 라벨로 학습을 수행하는 방식은 train-test시 데이터셋 클래스가 동일한 closed-set 상황에서는 잘 동작하도록 모델이 학습하겠지만, 새로운 클래스(zero-shot, few-shot 상황)에 거의 대응할 수 없기 때문에 실용적 측면에서 한계를 맞닥뜨리게 됩니다. 기존 방식으로 학습한 모델이 새로운 클래스들에 대응하기 위해선 해당 클래스에 대한 추가 데이터와 추가 학습이라는 cost가 수반될 것입니다.
최근에는 CLIP이나 ALIGN 등의 거대 image-text representation model들이 등장하며 전통적 방식과는 또다른 갈래의 프레임워크가 활발히 연구되고 있습니다. 이 모델들의 visual encoder, text encoder는 이미 거대한 image-text pair로 학습을 마친 상태이기 때문에 일반화된 표현력을 갖고 있다고 볼 수 있고, prompting 방식을 통해 다양한 downstream task에서 좋은 성능을 보여줄 수 있습니다. Prompting은 제가 저번 주에 작성한 리뷰 앞부분에 간단히 소개되어 있으니, 궁금하신 분들은 참고하셔도 좋을 것 같습니다.
그래도 간단히만 다시 정리해보겠습니다. Image classification을 수행한다고 했을 때 먼저 주어진 데이터셋의 특성, 라벨, task에 적합한 문장(prompt)를 만들고 text encoder로 embedding하게 됩니다. 이 prompt는 일반적으로 “a photo of dog”, “a photo of cat”, “a photo of …”, … 이렇게 전체 클래스에 대해 구성됩니다. 여기서 클래스 단어 앞에 들어가는 “a photo of” 부분을 데이터셋, 라벨, task 특성에 맞게 잘 구축하는 것이 중요하겠죠. 이후에는 클래스 개수만큼 생긴 문장을 text encoder에 태워 feature를 추출하고, 영상이 주어지면 image encoder에 태워 feature를 추출하여 두 feature의 유사도를 비교하는 방식으로 image classification이 수행되는 것입니다. 프레임워크 자체는 굉장히 간단하며, CLIP의 사전학습 representation 성능과 직접 설계한 prompt(“a photo of”)가 성능에 큰 영향을 준다고 볼 수 있겠네요.
제가 저번 주에 작성한 리뷰에서도 비디오 분야 task를 수행할 때 드러난 handcrafted prompt(“a photo of”)의 단점을 보완하고자 learnable vector를 클래스 단어 앞뒤에 붙여 임베딩했었는데요, 본 논문이 영상 분야에서 가장 처음 learnable vector를 prompt에 붙여 사용한 논문에 해당합니다. 저번주엔 논문을 읽으며 해소되지 않는, 뭔가 당연히 깔고가는 가정들이 있어보였습니다. 하지만 이번에 리뷰하는 논문을 읽으며 왜 그런 선택을 했었는지나 왜 이러한 가정을 할 수 있었는지에 대한 의문이 어느 정도 풀리게 되었습니다.
우선 여러 의문들 중, 왜 handcrafted prompt가 분야의 전문가들도 세밀하게 설계하기 어렵다고 하는 것인지에 대해 먼저 알아보겠습니다.

그림 1은 4가지 데이터셋에 대해 prompting 기반 image classification을 수행할 때, 해당 prompt를 handcrafted 기반으로 줄 때(파란색 박스)와 저자가 최초로 제안한 방식인 learnable prompt(Context Optimization, CoOp) 기반으로 줄 때(연두색 박스)의 성능 차이를 보여주고 있습니다.
Learnable prompt를 주어 학습 중 prompt를 주어진 데이터셋과 라벨, task에 맞게 최적화하는 방식이 가장 좋은 성능을 낸다는 것은 자명하지만, 그림 1에서 주목할 점은 서로 다른 handcrafted prompt 간의 성능 차이입니다. 언뜻 보면 각 데이터셋에 맞게 handcrafted prompt들이 꽤나 잘 구성되어 있는 것 같지만, Caltech101에서 심하게는 단순히 “a”를 클래스 text 이전에 붙여주는지 안붙여주는지에 따라 약 5%의 성능 차이를 보이고 있습니다.
그림 1의 (b), (c), (d)에서 사용된 데이터셋은 각각 꽃, texture, 위성이라는 특정 도메인에 해당하기 때문에 handcrafted prompt에 그러한 정보를 함께 담아주는 것이 성능 향상을 가져오고 있긴 하지만, 이마저도 데이터셋마다 향상 폭이 다르기 때문에 좋은 prompt로 향하기 위한 통용되는 방향성을 어느 한 곳으로 정립할 수 없다는 문제가 있습니다. 그리고 이렇게 데이터셋 내외부적으로도 prompt에 따른 성능 변동이 큰데, task가 달라지면 그에 맞는 전문적인 prompt tuning이 추가로 필요하게 됩니다.
위와 같은 handcrafted prompt의 불안정성과 단점을 최소화하기 위해 저자는 prompt에 learnable vector를 붙이는 방식을 컴퓨터비전 분야에서 최초로 제안하였고, 이러한 방식을 통해 성능 향상은 물론 domain shift에도 강인하여 일반적 표현력을 갖는 모델을 만들어낼 수 있다고 합니다.
2. Methodology
사실 CLIP의 사전학습 방식이나 prompt를 영상 분야에 적용하는 프레임워크는 이전 리뷰나 Introduction에서 충분히 설명하였다는 생각이 들어, 이제는 저자가 제안하는 learnable prompt를 어떠한 방식으로 클래스 text에 붙이는지 알아보겠습니다.
2.1 Context Optimization
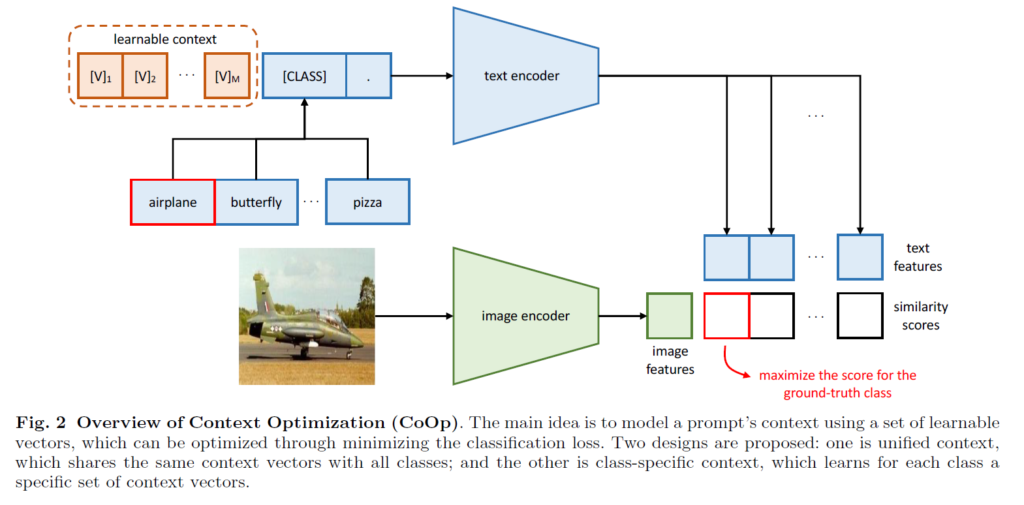
저자가 제안하는 Context Optimization(CoOp)은 handcrafted prompt의 문제점을 보완하고자 그림 2에서 주황색으로 표시된 learnable context를 붙여줍니다. 참고로 그림에서 text, image encoder는 기본적으로 freeze된 상태이며 여러 거대 모델의 encoder가 될 수 있지만 기본적으로는 CLIP을 사용하여 벤치마킹하고 있습니다.
결과적으로 prompt를 구성한 이후의 영상 분류 학습 흐름은 CLIP의 사전학습 방식과 유사하기 때문에, learnable prompt vector가 저자가 제안하는 방법론의 전부입니다. 하지만 클래스 text에 learnable vector를 붙이는 과정에서도 여러 방식이 존재하기 때문에 잘 따져보아야겠죠.
Unified Context
먼저 learnable vector를 데이터셋에 존재하는 클래스마다 따로 초기화하고 최적화할 것인지, 모든 클래스에 대해 균일한 vector를 가져갈 것인지 고민해볼 수 있습니다. Unified context는 모든 클래스에서의 prompt t를 아래 수식과 같이 동일한 learnable vector로 초기화하는 방식입니다.
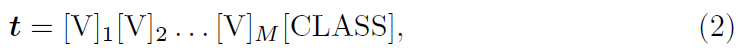
위 수식 2에서의 각 learnable vector [V]_{m}, (m \in{} \{1, \cdots{}, M\})은 word embedding과 같은 차원으로 CLIP을 사용하 경우 512차원이 될 것입니다. M은 사용할 총 learnable vector의 개수로, 하이퍼파라미터입니다. 그림 2를 기준으로 설명드린다면, 수식 2의 \text{[CLASS]} 위치에 데이터셋에 존재하는 클래스인 airplane, butterfly, pizza 등을 넣어주고 각각을 text encoder g(\cdot{})에 태워 feature를 얻게 됩니다.
그러면 총 K개의 클래스를 갖는 데이터셋의 한 영상 샘플 x를 입력받았을 때 x가 i번째 클래스에 속할 확률 p(y=i|x)는 아래 수식 3과 같습니다.
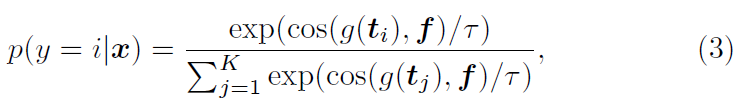
수식 3에서 f = \text{visual\_encoder}(x)이며, 결국 확률은 i번째 text feature g(t_{i})와 image feature f의 코사인 유사도를 기준으로 얻은 softmax score에 해당합니다. 이 score에 대해 GT label과 CE Loss로 분류학습을 수행할 수 있겠죠.
기존의 one-hot 또는 multi-hot vector로 클래스 라벨을 만들어 학습하는 방식은 클래스 라벨 자체의 의미까진 파악하지 못하기에 zero-shot 또는 few-shot inference로의 확장에 어려움이 있지만, 위와 같은 프레임워크는 일반성을 갖는 CLIP text encoder의 힘을 빌려 처음 보는 클래스에 대한 예측 성능도 올라가게 될 수 있습니다.
저번 주에 작성한 리뷰에서도 learnable vector를 왜 굳이 클래스 text의 앞뒤로 붙이는지에 대한 질문이 있었습니다. 사실 해당 논문을 읽으며 저 스스로도 명확히 납득되지 않았던 부분이었는데, 이번에 리뷰하는 논문을 읽으며 이해할 수 있게 되었습니다.
Unified Context의 두 번째 형태로 클래스 text 앞뒤로 learnable vector를 붙이는 방식이 등장합니다.
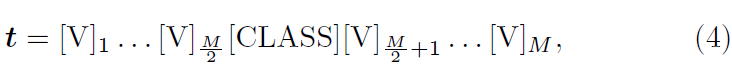
수식 4의 형태는 위 수식 2와 같이 M개의 learnable vector를 붙이되, \frac{M}{2}개씩 나누어 앞뒤로 넣어주고 있습니다. 이런 경우 수식 2와 다르게 클래스 text 뒷부분에도 vector를 최적화할 수 있게 되기 때문에 prompt 뒷부분에 추가 정보를 붙여주며 풍부한 표현을 만들어낼 수 있습니다. 또한 클래스 text 이후 꼭 마지막 M번째 위치가 아니더라도, 모델이 중후반에 full stop(.) 의미의 vector를 스스로 만들어내며 좀 더 유연한 학습을 할 수도 있다고 이야기하고 있습니다.
Class-Specific Context
Class-Specific Context(CSC)는 앞서 이야기한대로 데이터셋에 존재하는 클래스 별 learnable vector를 독립적으로 초기화해주는 방식입니다. i번 클래스에 대한 CSC 방식의 M개 learnable prompt 구축은 아래 수식과 같습니다.
- [V]_{1}^{i}[V]_{2}^{i}\cdots{}[V]_{M}^{i} \ne{} [V]_{1}^{j}[V]_{2}^{j}\cdots{}[V]_{M}^{j} \; \text{for} \; i \; \ne{} \; j
실험 부분에서도 이야기하겠지만, 결론적으로 Unified Context 방식에 비해 CSC 방식은 조금 더 fine-grained한 분류를 요구하는 데이터셋에서 상대적으로 잘 동작한다고 합니다.
사실 여기까지가 방법론의 전부이고, 이제 분석과 함께 실험 부분에서 더 많은 내용을 살펴보겠습니다.
3. Experiments
실험은 CLIP의 image classification에서도 사용된 11개 데이터셋에 대해 수행되었다고 합니다. 각 데이터셋과 데이터셋 별 statistics는 아래 표 6과 같습니다. 표 6 아래 섹션의 4개 ImageNet들은 CoOp의 domain generalization 성능을 평가하기 위한 별도 실험에서 사용된 데이터셋들입니다.
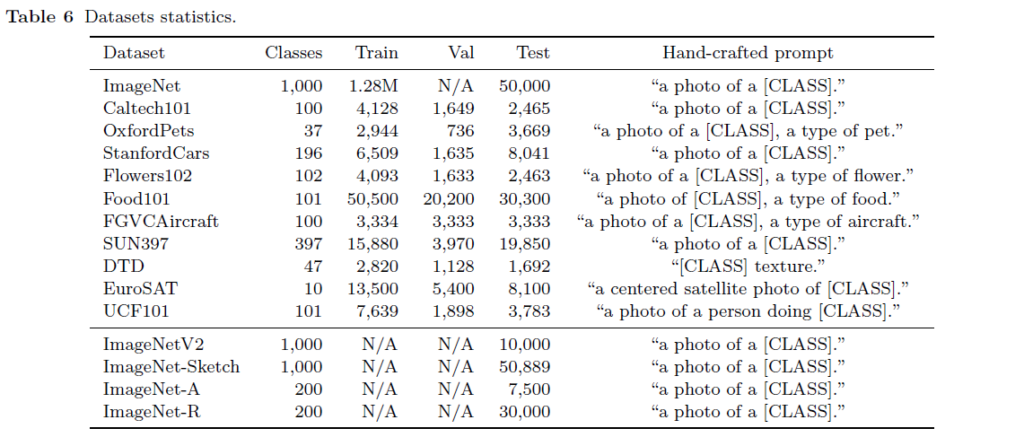
11개 중 generic object나 scene, action을 fine-grained 레벨의 카테고리로 담고 있는 데이터셋도 있고, texture를 인식해야하는 DTD나 위성 영상에 해당하는 EuroSAT 등 특정 도메인에 편향된 데이터셋도 존재합니다.
3.1 Few-Shot Learning
Training Details
먼저 학습 과정 중 세부적 내용에 대해 정리하고 넘어가겠습니다. 앞서 방법론 부분에서 이야기한 바에 따르면, [CLASS] 토큰을 문장 맨 뒤에 둘지, 가운데에 둘지에 대한 경우와 learnable vector를 Unified Context로 둘지, CSC로 둘지에 대한 경우를 조합하면 CoOp에는 총 4가지 버전이 존재할 것입니다. 또한 image encoder는 ResNet50을 사용하였고, learnable vector의 개수 M은 16으로 설정하였다고 합니다. 각 learnable vector들은 평균 0, 표준편차 0.02인 가우시안 분포로 랜덤 초기화된 상태입니다.
Baseline Methods
CoOp과 비교할 베이스라인 방법론은 CLIP이겠죠. 그 중 첫 번째는 handcrafted prompt 기반의 zero-shot CLIP입니다. Fair comparison을 위해, handcrafted prompt는 CLIP과 동일하게 맞춰주었다고 합니다. 각 데이터셋마다 사용된 handcrafted prompt는 표 6에서도 확인할 수 있습니다.
두 번째 베이스라인은 linear probe few-shot learning CLIP입니다. 첫 번째 베이스라인인 zero-shot CLIP이 현재 평가할 데이터셋을 전혀 보지 않은 채로 inference를 수행하는 것이라면, 두 번째 베이스라인은 데이터셋 내 클래스 별 1, 2, 4, 8, 16개의 샘플을 사용해 CLIP encoder 이후 linear layer만을 fine-tuning하고, 나머지 모든 샘플에 대해 평가를 진행하는 경우의 성능입니다. 아무래도 CoOp 방법론 자체가 CLIP encoder는 freeze한 채 prompt를 학습하는 것이니, zero-shot 성능이 있을 수가 없을 것입니다.
직관적으로는 많은 샘플을 사용할수록 성능이 높아질 것으로 예상되는데요, 데이터셋마다 다르긴 하지만 CLIP 논문에 나와있는 바에 따르면 적은 샘플로 few-shot 학습을 하는 것이 오히려 zero-shot 성능보다 안좋은 경우도 생긴다고 합니다. 이러한 점을 고려하여 아래 CLIP zero-shot 성능과 방법론 별 few-shot 성능을 보시면 좋을 것 같습니다.
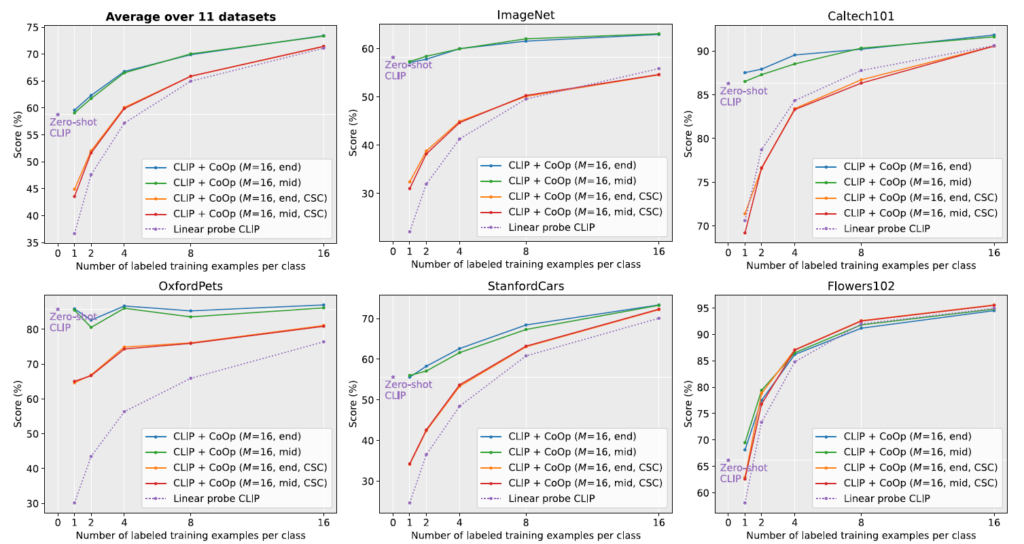
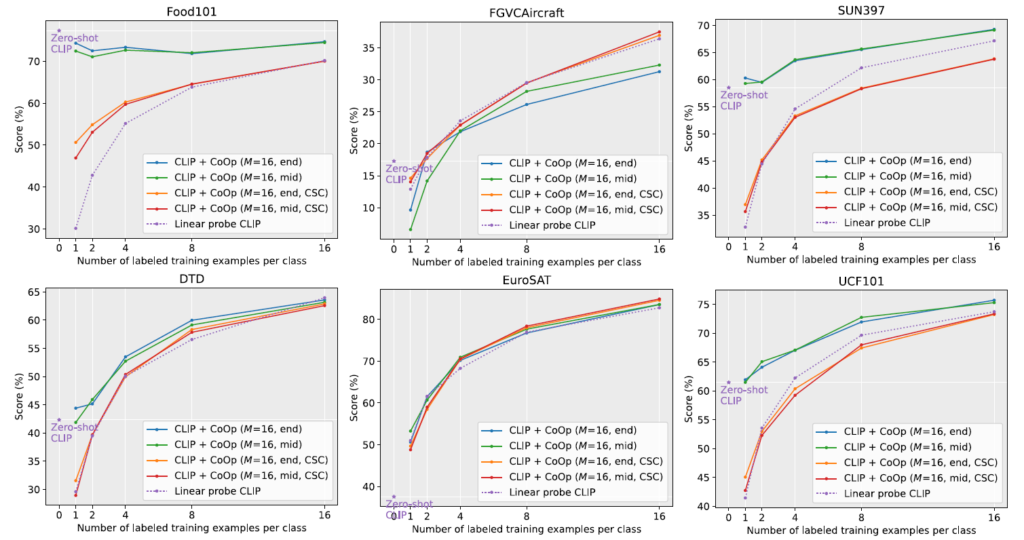
우선 각 실험마다 앞서 말씀드린 4가지 버전의 CoOp, linear probe(few-shot) CLIP, zero-shot CLIP의 성능이 나타나 있는 것을 볼 수 있습니다. (4가지 버전의 CoOp<->zero-shot CLIP)을 비교할 수 있고 (4가지 버전의 CoOp<->linear probe CLIP)을 비교해볼 수 있겠죠.
Comparison with Hand-Crafted Prompts
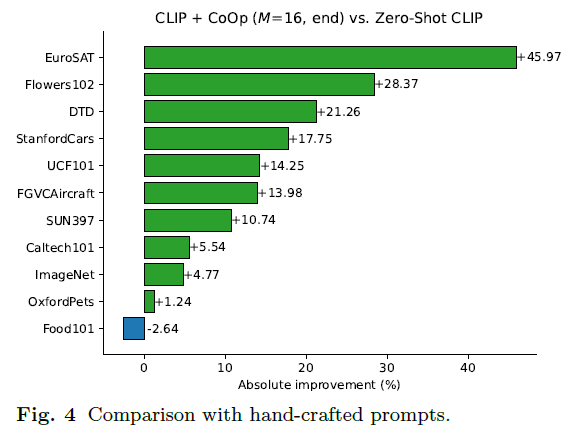
이 절에선 먼저 CoOp과 zero-shot CLIP의 성능 차이를 살펴봅니다. 성능을 보았을 때 우선 CoOp에서 learnable vector를 클래스 text 앞에 줄지, 앞뒤로 줄지 여부에 따른 성능 차이는 크지 않아보입니다. 좌상단의 모든 데이터셋 평균 그래프를 보시면 CSC 방식보단 Unfied Context 방식이 일반적으로 높은 성능을 보이고 있네요.
여기서 성능이 그래프로 나타나있어 잘 감이 안올 수도 있지만, 실질적으로 16-shot의 EuroSAT 데이터셋 기준 약 45%이상의 성능 향상을 일으키고, 클래스가 1000개인 ImageNet에서도 4.77%라는 큰 성능 향상을 만들어냈다는 점도 주목하시면 좋을 것 같습니다. 반대로 OxfordPets나 Food101 데이터셋에선 오히려 16-shot CoOp이 성능 향상이 미미하거나 오히려 떨어지는 상황입니다. 성능 그래프가 2-shot에서 한 번 꺾이는 것을 볼 수 있는데, 저자는 이것이 overfitting 때문으로 학습 중 별도 조정을 해주면 더욱 향상될 수도 있지 않을까, 하는 분석을 내놓고 있습니다. 특히 Food101은 학계에서 어느정도 noisy한 샘플이 많다고 인정되고 있는 데이터셋이라는 점도 첨언해주고 있습니다. 전체적으로는 성능이 많이 오르고 있기 때문에 이 정도는 괜찮다고 말하려는 뉘앙스가 느껴지네요. 추가적인 데이터셋 별 성능 증감 폭은 그림 4를 참고하시면 됩니다.
또한 Unified Context 방식의 성능은 zero-shot CLIP보다 1-shot에서도 평균적으로 높은 성능을 보여줍니다. 이게 직관적으론 특정 데이터셋에 해당하는 샘플을 학습했으니 당연해보일 수 있지만, 1-shot 또는 2-shot CLIP의 성능을 보시면 EuroSAT 데이터셋을 제외하곤 모두 zero-shot의 성능이 더 높은 것을 볼 수 있습니다. CLIP 논문에서도, 이와 관련해 적은 개수에 대한 linear fine-tuning이 오히려 CLIP의 일반성을 헤쳤다고 이야기하고 있습니다. Linear probe CLIP은 거의 8-shot, 16-shot 정도는 되어야 zero-shot의 성능보다 높아지는데, CoOp의 경우 평균적으로 1-shot부터 바로 zero-shot CLIP의 성능을 뛰어넘으며 강력한 few-shot learner임을 입증하고 있습니다.
Comparison with Linear Probe CLIP
이젠 4가지 버전의 CoOp과 클래스 별 1, 2, 4, 8, 16개의 shot만으로 linear classifier만을 학습한 few-shot CLIP의 성능을 비교해보겠습니다. 그림 3의 각 그래프에서 5개의 꺾은선끼리 비교하는 것입니다. 우선 좌상단 그림만 봐도 Linear Probe CLIP보다 Unified Context 방식의 CoOp이 평균적으로 모든 shot에서 큰 성능 향상을 만들어내고 있습니다.
이 와중에도 DTD, EuroSAT, Flowers102, FGVCAircraft 데이터셋에선 CoOp과 few-shot CLIP이 유사한 성능을 보여주고 있습니다. 이에 대해 저자는 CLIP이 워낙에 강력한 표현력을 자랑하는 모델이다보니 그럴만한 상황이라고 이야기하고 있습니다. 저자의 주장이 조금 당황스럽긴 하지만, 나머지 데이터셋에선 큰 성능 차이를 보여주며 평균적으로 많이 올랐기 때문에 납득 못할만한 정도는 아닌 것 같습니다.
Unified vs Class-Specific Context
또 하나 살펴볼만한 점은 DTD, Flowers102, EuroSAT, FGVCAircraft 데이터셋과 같이, 특정 도메인에 국한되며 클래스 라벨이 fine-grained한 경우 클래스 별 learnable vector를 독립적으로 초기화하는 CSC 방식이 16-shot에서 Unified Context 방식보다 잘 동작한다는 것입니다. 당연한 이야기일 수 있지만 CSC 방식은 Unified Context 방식보다 최적화할 vector들이 많으니, 8-shot 이하에선 좀 낮은 성능을 보이고 있습니다. 결론적으로는 학습 샘플이 충분하면서 데이터셋의 클래스가 fine-grained하게 나뉘어져 있는 경우 CSC 방식을 사용하는게 도움될 것 같습니다.
3.2 Domain Generalization
CoOp은 특정 도메인의 데이터에 대해 learnable prompt를 “학습”해버리기 때문에 few-shot 또는 zero-shot 상황에서나 domain shift가 발생했을 때 제대로 대응하지 못할 수도 있다는 문제점이 있습니다. 기존 CLIP text encoder의 경우 굉장히 광범위한 분포의 샘플들로 학습을 마쳤기 때문에 zero-shot, few-shot 상황에서 domain이나 distribution shift에 강인하게 대응한다는 장점이 있었는데, 본 논문의 저자도 CoOp이 CLIP과 유사하게 domain이나 distribution shift에 강인한지 확인해보는 실험을 수행합니다.
Datasets
우선 사전학습을 위한 source 데이터셋으로는 ImageNet이 사용되었고, domain shift가 발생했다는 상황을 가정하기 위한 target 데이터셋은 ImageNet-V2, ImageNet-Sketch, ImageNet-A, ImageNet-R이 사용되었습니다. -V2는 test set을 같은 방식으로 다른 source에서 모은 것이고, -Sketch는 원본 ImageNet과 동일한 1000개의 클래스의 스케치 이미지들을 모아둔 것이고, -A와 -R은 1000개의 원본 클래스 중 200개의 subset만을 조금씩 다른 도메인으로 모아둔 데이터셋입니다.
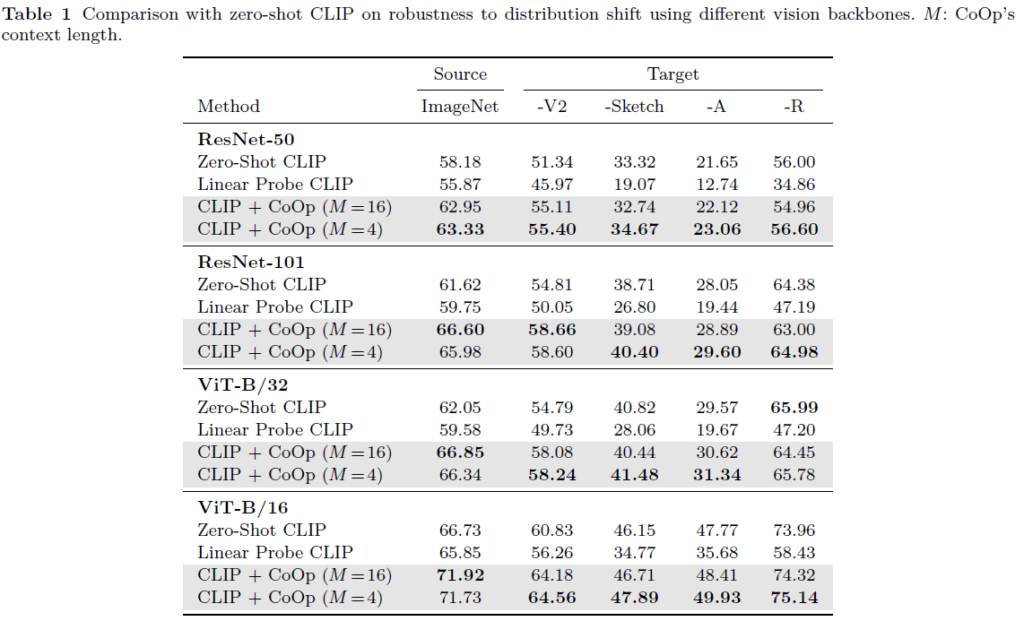
표 1에서 해당 실험의 결과를 볼 수 있습니다. 일반적으로 적은 개수의 learnable context를 붙이는 것이 더욱 도움된다는 것을 알 수 있습니다. 여기서도 zero-shot CLIP보다 few-shot CLIP이 일부 샘플에만 fitting되며 더 낮은 일반성을 갖게 됨에도 불구하고, CoOp은 유사한 조건에서 seen 샘플에만 fitting되지 않고 일반성을 갖는 prompt를 학습하며 높은 성능을 보여준다는 점을 알 수 있습니다.
여기까지가 CoOp의 강력한 일반성을 보여주는 메인 실험 결과들이었고, 이제부턴 세부 ablation들을 살펴보겠습니다.
3.3 Further Analysis
Context Length & Visual Backbones
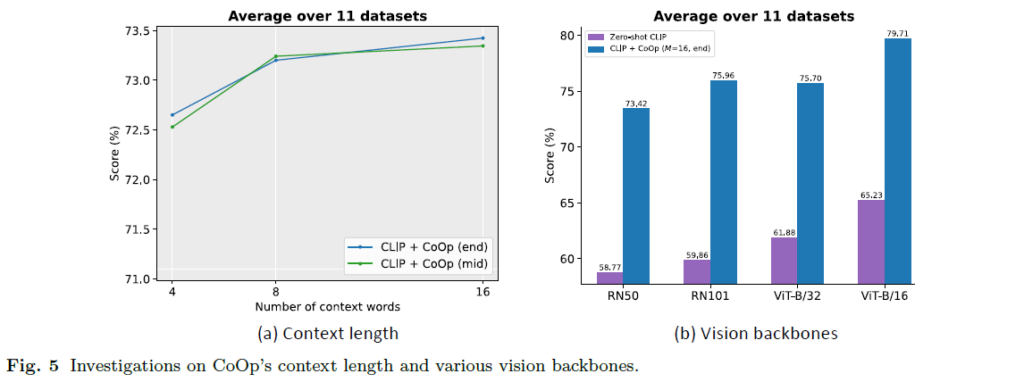
Prompt를 구성할 learnable vector의 개수 M에 대한 ablation과 visual encoder 모델에 대한 ablation 실험은 위 그림 5를 통해 확인할 수 있습니다.
먼저 그림 5-(a)에서 벤치마킹한 11개 데이터셋에 대한 평균 성능을 통해 M을 어떻게 결정할지와 클래스 text를 중간에 둘지, 마지막에 둘지 생각해볼 수 있습니다. 일반적으로 11개 데이터셋에 대해서는 M이 커질수록 성능이 높아졌지만, 3.2의 실험에선 또 M을 4로 두는 것이 더욱 높은 성능을 보였었습니다. 그리고 클래스 text를 중간에 두는 경우 직관적으로는 학습의 유연성을 불러올 것으로 기대했지만 M에 따라 중간에 성능이 한 번 꺾이며 최적은 아닌 것으로 보입니다. 이에 대해 저자도 결론적으로 golden rule은 없고 데이터셋과 task에 따라 잘 balancing 해야 한다고 이야기하고 있습니다.
그림 5-(b)에서 Visual backbone에 따른 성능의 경우, ViT-B/16의 성능이 가장 좋았으며 모든 백본에 대해 handcrafted feature보다 월등히 향상된 성능을 보여주고 있습니다.
Comparison with Prompt Ensembling

기존 CLIP에서는 하나의 task를 수행할 때 handcrafted prompt를 하나만 두는 것이 아니라 여러 방면에서 데이터를 살펴본다는 관점으로 여러 handcrafted prompt를 설계하고, 이들을 앙상블하여 성능 향상을 불러온다는 점을 이야기하였었습니다. 사실 CoOp에서 랜덤으로 초기화되는 learnable prompt를 어떻게 다양하게 주어 앙상블 할지 고민하는 것은 좀 어렵습니다. 그래서 저자는 단순히 CLIP zero-shot, CLIP zero-shot ensemble과 CoOp의 성능을 표 2와 같이 비교하고 있습니다. 결론적으론 CLIP의 handcrafted prompt들을 앙상블하여도 학습 기반 하나의 CoOp prompt가 더 좋은 성능을 보이고 있네요.
Initialization
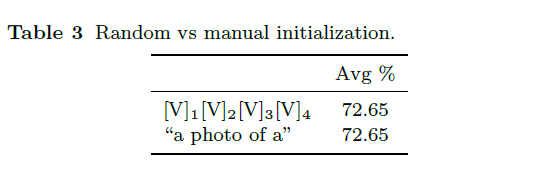
표 3은 CoOp에서 사용할 learnable vector의 초기화 방식에 대한 ablation 성능입니다. 가우시안 랜덤 벡터로 초기화하는 첫 번째 방식과 기존 CLIP에서 잘 고안하여 만들어낸 “a photo of a”를 임베딩한 값으로 초기화하고 학습하는 두 번째 방식이 사실 상 유사한 성능을 보여주며 저자들은 좀 더 구현하기 단순한 첫 번째 방식을 선택했다고 합니다.
Interpreting the Learned Prompts
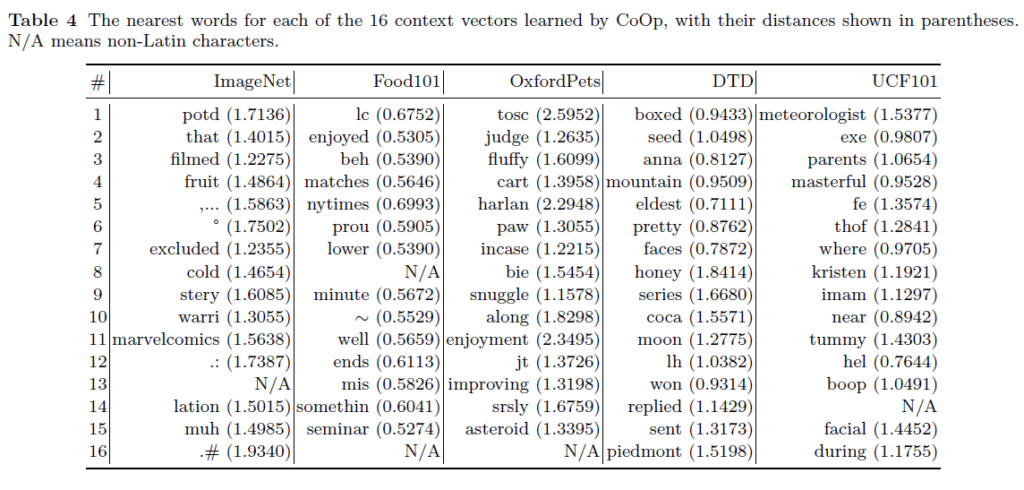
사실 학습 기반으로 prompt를 만들어내고 좋은 성능을 냈다면, 그 prompt가 어떻게 만들어졌는지에 대한 분석을 바탕으로 좀 더 좋은 handcrafted prompt를 만드는 방식도 생각해볼 수 있을 것입니다. 그런 상황 속 저자들은 CoOp 모델이 만들어낸 prompt가 어떻게 학습되었는지 알아보았습니다.
CLIP에서 Byte Pair Encoding(BPE)으로, 즉 subword 단위로 단어를 tokenize하기 때문에 표에는 사람이 제대로 해석할 수 없는 ‘lc’, ‘jt’, ‘lh’ 등의 단어가 등장하게 됩니다. 아무튼 CoOp에서 학습을 마친 learnable vector와 word embedding space 상에서 nearest word를 가져오는 방식으로 순위를 매겼다고 합니다.
나름 OxfordPets 데이터셋에선 동물과 관련된 ‘fluffy’, ‘paw’와 같이 사람이 해석할 수 있는 단어가 등장하긴 하지만, 대부분 그렇지 않기 때문에 저자들은 학습된 prompt가 embedding space상에서는 사람들이 실생활에서 사용하는 단어 이상의 의미를 내포하고 있을 것으로 생각한다고 합니다. 또한 학습된 prompt는 continuous vector로, embedding space상에서 정확히 딱 떨어지는 것이 아닌 nearest word이기 때문에 표 4만을 바탕으로 명확한 분석을 하기엔 좀 조심스럽다고 이야기하고 있습니다.
4. Conclusion
본 논문은 자연어 처리에서 사용되던 prompt learning 기법을 영상 분야에 적합하도록 학습 기반으로 적용한 최초의 논문입니다. 이는 거대 image-text 쌍으로 학습한 강력한 multi-modal representation을 갖는 CLIP이 있었기에 가능한 방법론이었고, 이후 Image classification을 수행한 CoOp을 시작으로 dense prediction, video understanding 등등에 prompt learning이 downstream task에서 좋은 성능을 낼 수 있도록 발판을 마련해준 논문입니다. 수많은 실험들을 통해 조금은 애매했던 지점들이 시원하게 이해되었던 것 같습니다.
이상으로 리뷰 마치겠습니다.
읽어주셔서 감사합니다.
안녕하세요. 김현우 연구원님.
좋은 리뷰 감사합니다.
oxford 데이터셋에서 fluffy와 같은 단어로 학습이 되었다는 것이 새삼 신기하네요.
더불어 이전에 learnable prompt에 대해 언급하셔서 이게 어떤 것인지 궁굼하였는데, 많은 의문이 풀리는 리뷰였습니다.
가볍게 궁굼한 점이 있는데요. CLIP이 text encoder로 트랜스포머 구조를 사용하여 텍스트에 굉장히 많은 토큰을 입력할 수 있는 것으로 알고 있는데, 논문 상에서 설정한 learnable vector의 수 M은 많아야 16인 것이 조금 의아합니다. 혹시 M을 더 크게 하여 실험하지 않는 이유가 있을까요?
감사합니다.
Learnable vector 하나를 hand-crafted prompt 상의 한 단어(또는 음절?)에 매칭시키려는 의도라고 보시면 좋을 것 같습니다. 리뷰에 담진 않았지만 실제로 ablation 실험에서도 “a photo of a” 라는 단어를 임베딩하여 초기화하고, 이 prompt로부터 학습을 시작했을 때와 기존처럼 가우시안 초기화된 learnable vector로부터 학습을 시작했을 때의 성능을 비교하는데요,
이 때 hand-crafted prompt가 a / photo / of / a인데, 이와 성능을 비교할 learnable vector를 v1, v2, v3, v4로 준 것으로 보아 일반적으로 한 learnable vector는 한 단어에 대응한다고 보는 것 같습니다. 학계에서 통용되는 handcrafted prompt의 길이가 보통은 16단어 이상을 넘지는 않으니, 그와 어느정도 맞춰주며 학습 파라미터 개수 관점에서도 효율성을 위해 암묵적으로 위와 같은 선택을 한 것으로 보입니다. 참고로 방금 말한 실험에서 둘의 성능은 소수점 둘째 자리까지 동일합니다.
안녕하세요. 김현우 연구원님 리뷰 잘 읽었습니다.
지난번 리뷰도 재밌게 읽었는데요. 오늘도 관련된 내용이네요.
지난번 리뷰에서는 learnable context를 문장 앞뒤로 주는 궁금함이 있었는데. 이번 리뷰에서 다루셨군요. 근데 Full stop 의미라고 하면 어떤 말일까요? 처음 들어봐서 어떤 의미인지 궁금합니다.
전반적으로 일반적이지 않은 상황에서 활용하기 좋아보이네요. 성능 향상 폭도 그렇고요. 학습 기반이라 도메인 변화에 취약할거라고 생각하면서 읽었는데, 그렇지도 않은 부분도 인상깊고요. 텍스트는 불변하기 때문에 영향을 덜 받는 것 같네요.
그리고 학습된 프롬프트 분석도 제가 보고싶던 실험 내용인데 딱 있네요. 결국 사람이 해석할 수 있는 부분은 아니라는 것이 결론이네요. 재밌게 잘 읽었습니다.
Full stop에 대해 찾아보니, 어떤 학술적인 의미를 담는게 아니라 단순히 마침표를 의미하는 단어라고 합니다. Learnable vector들이 클래스 text 뒤 임의 위치에서 직접 마침표의 의미를 갖는 vector를 만들어내며 learnable vector의 개수까지 유연하게 조절하는 상황이라고 생각해볼 수 있을 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽으며 이전 리뷰에 있었던 의문점을 덕분에 같이 해소할 수 있었던 것 같습니다. prompt가 어떻게 구성이 되는지에 따라 성능이 달라진다는 말은 많이 봤지만 구체적으로 어느정도로 달라지고 그래서 왜 prompt를 잘 넣는것이 중요한 것인지 알 수 있었던 논문 이었던 것 같습니다.
읽으며 간단히 궁금한 것이 있는데 prompt ensembling은 어떻게 구성이 되어 있는 건가요? 뭔가 구체적으로 어떻게 입력이 들어가는지 그려지지 않아 질문 드립니다
Prompt ensembling은 동일 task의 동일 데이터셋의 클래스들에 대해 하나의 handcrafted prompt만을 넣어 text feature를 만들어내는 것이 아니라 여러 관점에서 샘플을 바라보는 handcrafted set을 구축하고, 각각을 embedding하여 마지막에 가중합을 사용하는 등의 방식으로 최종 text embedding을 사용하는 기법입니다.
Prompt ensembling은 다양성 관점에서 prompt를 설계해준 것이 성능 향상에 도움을 주는 것 같습니다.
안녕하세요, 김현우 연구원님, 좋은 리뷰 감사합니다.
해당 리뷰를 ‘CLIP 등 visual-language model에서는 사람이 모델에게 던져주는 text인 prompt가 중요한데, handcrafted로는 최적의 prompt를 얻기 힘들다. 따라서 prompt 앞에 learnable vector를 붙여 이를 학습시키자’ 라고 이해했는데, 제가 올바르게 이해한건지 모르겠네요.
질문은, 그럼 결국 learnable vector를 text 앞뒤에 붙여 image-text 각각 인코더를 태워 feature vector를 얻은 뒤 이에 contrastive learning을 진행하는것으로 보이는데, 그럼 결국 학습을 통해 learnabel vector를 얻기 위함이 목적인가요? 그럼 학습이 완료된 후에 learnable vector에 대한 text를 얻을 수 있는 것인지 헷갈립니다. learnable prompt의 목적과 학습 과정과 결과를 제가 올바르게 이해한건지 궁금합니다.
안녕하세요.
먼저 말씀해주신, 이해하신 컨셉이 맞습니다. 다만 prompt는 (template + [CLS])를 의미한다고 생각하시면 되어, prompt 앞에 learnable vector를 붙여주기보단 [CLS] 앞에 붙여준다고 보시는게 맞을 것 같습니다.
CoOp의 방식대로 text 주변에 붙은 learnable vector들의 학습을 마치면, 이제 해당 데이터셋의 모든 대해서는 적합한 prompt를 얻었다고 볼 수 있습니다. 그럼 마치 학습을 마친 백본 모델의 checkpoint를 저장해두었다가 inference할 때 쓰듯, prompt도 마찬가지로 inference할 때 그대로 가져와 text encoder에 던져 기존 CLIP 방식대로 few-shot inference를 수행하는 것입니다. CoOp의 zero-shot 실험이 있을 수 없는 이유는, 가우시안 분포로 초기화하고 아무 학습도 하지 않은(zero-shot) prompt는 데이터셋이나 task에 전혀 도움을 줄 수 없기 때문입니다.
추가로, 학습을 마친 연속적 vector를 굳이 단어 형태로 변환시켜 이해해보려 한 것이 표 4의 결과입니다. 표 4로부터 얻을 수 있는 결론은 마치 이미지 분류를 위해 잘 학습한 resnet이 내부적으로 어떻게 동작하는지까진 명확하게 알 수 없듯, 학습을 마친 vector들이 사람이 이해하긴 어렵지만 prompting 관점에선 잘 동작했다는 것이라고 이해하면 될 것 같습니다.